From Research to production.
从PyTorch的官网slogan 可以看出,PyTorch也逐渐要向工业应用领域进发了!
这是莫大的好消息,按照之前的大家的认识,PyTorch和TensorFlow有着以下的几项对比:
PyTorch 有着简洁且稳定的api接口,在科研界受到了认可和应用。
而Tensorflow随着版本变化变动的接口和高封装度的接口,导致代码调试比较困难,这一点一直被诟病。但是其提供了较tfserving等工业化的配件,所以在工业界一直是TensorFLow应用较为广泛。
最近几年,Pytorch逐渐占据了市场的上风,引起了科研界和开发届的使用热潮,因此非常有学习的必要!
1. PyTorch 核心功能
计算层
本章我们介绍Pytorch中5个不同的层次结构:即硬件层,内核层,低阶API,高阶API。
Pytorch的层次结构从低到高可以分成如下五层。
- 第一层为硬件层,Pytorch支持CPU、GPU加入计算资源池。
- 第二层为C++实现的内核。
- 第三层为Python实现的操作符,提供了封装C++内核的低级API指令,主要包括各种张量操作算子、自动微分、变量管理.
如torch.tensor,torch.cat,torch.autograd.grad,nn.Module. - 第四层为Python实现的模型组件,对低级API进行了函数封装,主要包括各种模型层,损失函数,优化器,数据管道等等。 如:torch.nn.Linear,torch.nn.BCE,torch.optim.Adam,torch.utils.data.DataLoader.
核心功能
PyTorch 主要提供了以下两种核心功能:
1,支持GPU加速的张量计算。2,方便优化模型的自动微分机制。
优点
Pytorch的主要优点:
- 简洁易懂:Pytorch的API设计的相当简洁一致。基本上就是tensor, autograd, nn三级封装。学习起来非常容易。有一个这样的段子,说TensorFlow的设计哲学是 Make it complicated, Keras 的设计哲学是 Make it complicated and hide it, 而Pytorch的设计哲学是 Keep it simple and stupid.
- 便于调试:Pytorch采用动态图,可以像普通Python代码一样进行调试。不同于TensorFlow, Pytorch的报错说明通常很容易看懂。有一个这样的段子,说你永远不可能从TensorFlow的报错说明中找到它出错的原因。
- 强大高效:Pytorch提供了非常丰富的模型组件,可以快速实现想法。并且运行速度很快。目前大部分深度学习相关的Paper都是用Pytorch实现的。有些研究人员表示,从使用TensorFlow转换为使用Pytorch之后,他们的睡眠好多了,头发比以前浓密了,皮肤也比以前光滑了。
PyTorch 安装
PyTorch与Tensorflow相比还有一个较大的优点就是安装简单,特别是安装支持GPU的版本,Torch简直好TensorFlow太多。
进入官网,选择你的下载方式和系统版本等信息,PyTorch会自动生成下载命令。
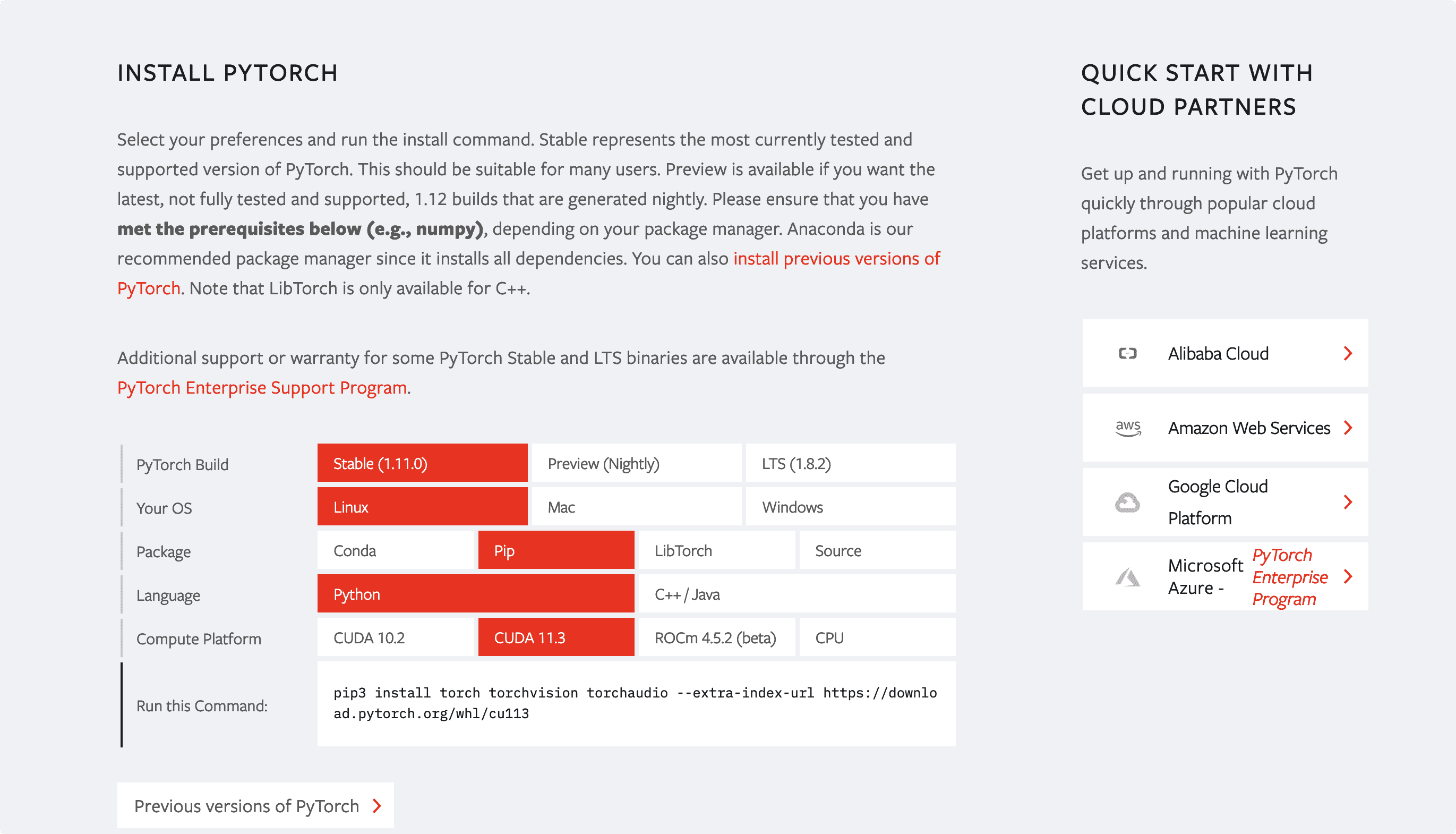
这里记录一下Ubuntu系统下pyenv的torch虚拟环境创建和安装
# 创建虚拟环境
python3 -m venv env_torch
#激活虚拟环境
source ./env_torch/bin/activate
# 更新pip 安装pillow
python3 -m pip install --upgrade pip
python3 -m pip install --upgrade Pillow
# 安装torch
pip3 install torch torchvision
2. PyTorch 核心概念—张量数据
Pytorch底层最核心的概念是张量,动态计算图以及自动微分。
2.1 张量数据结构
torch的数据类型与numpy的array基本一致,但是不支持str 类型
torch.float64(torch.double),
torch.float32(torch.float),
torch.float16,
torch.int64(torch.long),
torch.int32(torch.int),
torch.int16,
torch.int8,
torch.uint8,
torch.bool
一般神经网络使用的都是torch.float32类型。
import torch
import numpy
# 自动推断数据类型
i = torch.tensor(1)
print(i,i.dtype)
x = torch.tensor(2.0)
print(x,x.dtype)
b = torch.tensor(True)
print(b,b.dtype)
#---------输出 ------------
tensor(1) torch.int64
tensor(2.) torch.float32
tensor(True) torch.bool
#---------输出 ------------
# 指定数据类型
i = torch.tensor(1,dtype = torch.int32);print(i,i.dtype)
x = torch.tensor(2.0,dtype = torch.double);print(x,x.dtype)
#---------输出 ------------
tensor(1, dtype=torch.int32) torch.int32
tensor(2., dtype=torch.float64) torch.float64
# 使用构造函数 创建数据
i = torch.FloatTensor([32])
print(i)
# tensor([32,])
# 切换数据类型
i.type(torch.int)
# tensor([32], dtype=torch.int32)
2.2 张量的维度
xx = torch.Tensor(np.ones((4,4,4)))
xx.dim()
# 3
xx.shape
# torch.Size([4, 4, 4])
2.3 Tensor 和 Numpy 转换
# --------从numpy转为 tensor
xx = torch.from_numpy(np.ones((3,3))) # numpy变量改变 tensor变量也会改变
### 可以用clone() 方法拷贝张量,中断这种关联
tensor = torch.zeros(3)
#使用clone方法拷贝张量, 拷贝后的张量和原始张量内存独立
arr = tensor.clone().numpy() # 也可以使用tensor.data.numpy()
#-------- 从tensor转numpy
xt = xx.numpy()
3. PyTorch 核心概念—自动微分
深度学习框架最重要的一个部分就是能够实现自动微分,Pytorch一般通过反向传播 backward 方法 实现这种求梯度计算。该方法求得的梯度将存在对应自变量张量的grad属性下。除此之外,也能够调用torch.autograd.grad 函数来实现求梯度计算。
3.1 利用backward方法求导
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c的导数
x = torch.tensor(0.0,requires_grad = True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a*torch.pow(x,2) + b*x + c
y.backward()
dy_dx = x.grad
print(dy_dx)
3.2 利用autograd.grad方法求导
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c的导数
x = torch.tensor(0.0,requires_grad = True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a*torch.pow(x,2) + b*x + c
# create_graph 设置为 True 将允许创建更高阶的导数
dy_dx = torch.autograd.grad(y,x,create_graph=True)[0]
print(dy_dx.data)
# 求二阶导数
dy2_dx2 = torch.autograd.grad(dy_dx,x)[0]
print(dy2_dx2.data)
3.3 利用自动微分和优化器求最小值
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c的最小值
x = torch.tensor(0.0,requires_grad = True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
optimizer = torch.optim.SGD(params=[x],lr = 0.01)
def f(x):
result = a*torch.pow(x,2) + b*x + c
return(result)
for i in range(500):
optimizer.zero_grad()
y = f(x)
y.backward()
optimizer.step()
print("y=",f(x).data,";","x=",x.data)
4. PyTorch核心概念- 动态计算图
Pytorch的计算图由节点和边组成,节点表示张量或者Function,边表示张量和Function之间的依赖关系。
Pytorch中的计算图是动态图。这里的动态主要有两重含义。
第一层含义是:计算图的正向传播是立即执行的。无需等待完整的计算图创建完毕,每条语句都会在计算图中动态添加节点和边,并立即执行正向传播得到计算结果。
第二层含义是:计算图在反向传播后立即销毁。下次调用需要重新构建计算图。如果在程序中使用了backward方法执行了反向传播,或者利用torch.autograd.grad方法计算了梯度,那么创建的计算图会被立即销毁,释放存储空间,下次调用需要重新创建。

若有收获,就点个赞吧
0 人点赞
