一、机器学习的分类
- 监督学习 supervised learing
- 数据有标签,一般为回归或分类等任务
- 无监督学习 un-surpervised learning
- 数据无标签,一般为聚类或若干降维问题
- 半监督学习
- 强化学习 reinforcement learing
- 序列数据决策学习,一般从环境交互中学习
二、监督学习
1. 标注数据
2. 学习模型
3. 损失函数


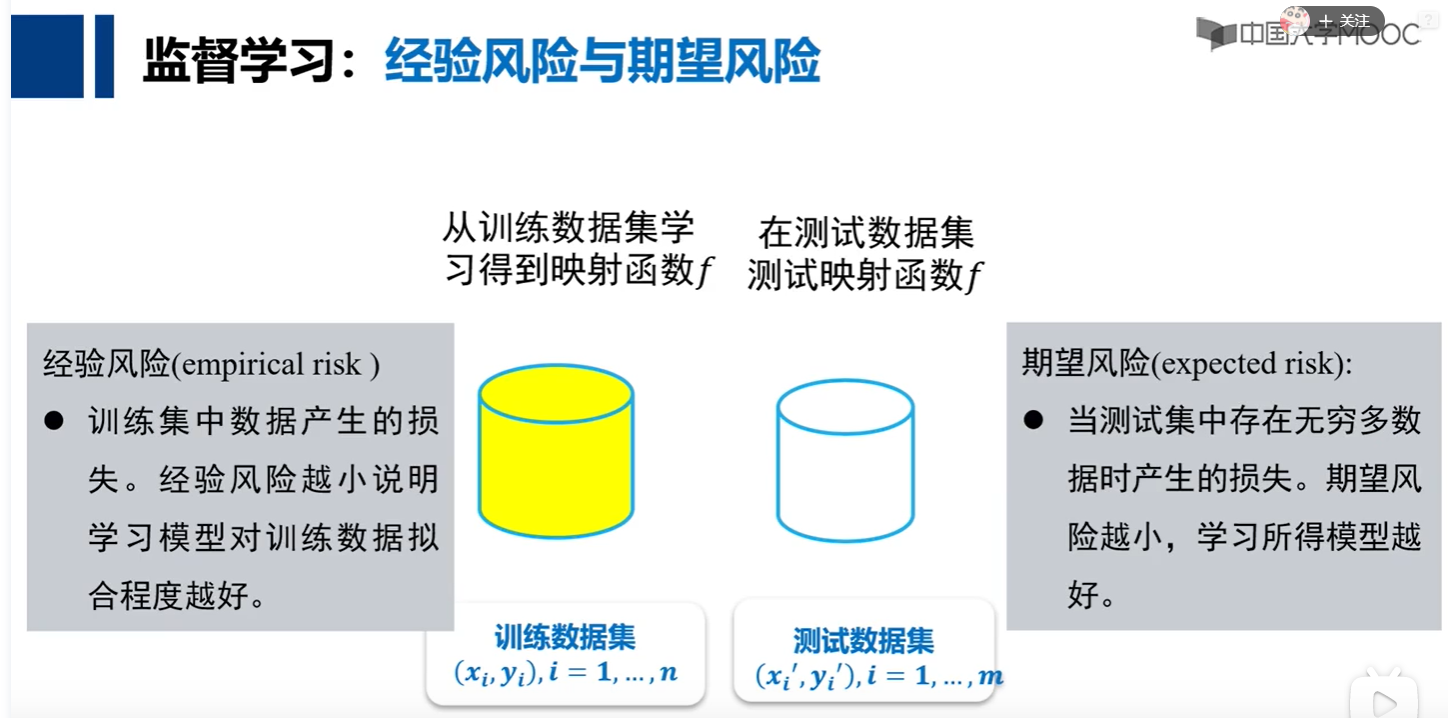
4. 经验风险与期望风险
5. 过拟合over-fitting和欠拟合under-fitting

三、监督学习-线性回归
四、监督学习-提升算法
五、无监督学习
- 输入:n个数据(无任何标注数据)
- 输出:k个聚类结果
- 目的:将n个数据聚类到k个集合(也称为类簇)
- 算法描述:
- K-means算法过程:
- 在新聚类质心基础上,根据欧氏距离大小,将每个待聚类数据放入唯一一个聚类集合中
- 根据聚类结果、更新聚类质心
- 聚类迭代满足如下任意一个条件,则聚类停止:
- 已经达到了迭代次数上限
- 前后两次迭代中,聚类质心基本保持不变


若有收获,就点个赞吧
0 人点赞
