数据结构:
1.数组结构 - 方便查询
2.链式结构 - 方便增加和删除
链式结构分为两种,单链和双链。
- 单链:一个节点不但保存了自己的数据,同时还保存了下一个节点的地址。使之前后相关联。
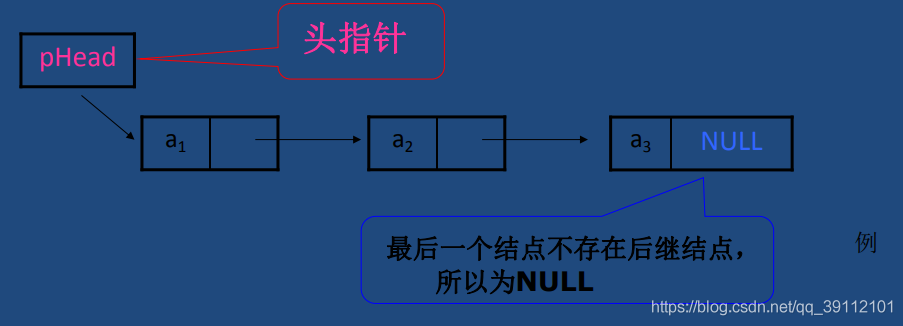
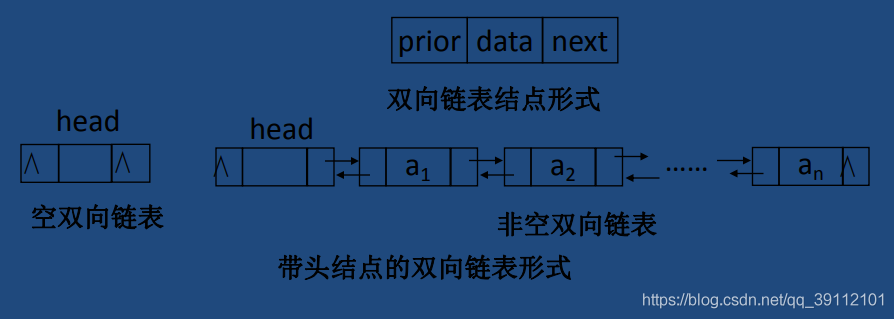
- 双链:后一个节点也记住前一个节点的地址不就可以了吗(机智),这样就可以前找后,也可以后找前,这样形成的结构就叫做双向链表。保存自身的值和前后两节点的地址。
LinkedList
特点
- LinkedList是一个集合,是一个链式结构的集合,删除和增加效率高,因为提供了大量的首尾操作。
常用方法:
- void addFirst(E e) - 添加首个元素
- void addLast(E e0 - 添加末尾元素
- E getFirst() - 获取首个元素
- E getLast() - 获取末尾元素
支持栈结构
Stack:
- 栈结构:遵循先进后出的原则 - 理解:第一课装进去的子弹是最后一个打出来的
对应的方法:
- push:压栈
- pop:弹栈
- peek:查询即将要弹出的元素 - 检查栈中还有无元素:只看不弹出。
- empty():判断栈中是否为空,true空
LinkedList是支持栈结构的
java中专门提供了一个结构 - stack
**
支持队列结构
队列:队列结构遵循先进先出原则
LinkedList支持队列结构
因为这个LinkedList本身是链式结构,所有添加和删除比较的灵活,而队列与栈都是数据结构中的操作,所以利用LinkedList支持比较方便
队列用的方法:
- offer:加入队列
- poll:离开队列 - 该元素已经不在当前队列中了
- peek:查询即将离开队列的元素 - 只看不走
HashSet
HashSet:无序且不可重复集合
HashSet是一个集合,不包含重复的元素和相同的元素,无序的,不提供索引(下标)所有不能通过下标获取元素。
- 只能通过迭代器访问 - 增强for循环
HashSet怎么做到不重复的?
- 1.首先在元素存放进这个集合之前会通过HashCode()方法算出哈希值(int类型)
- 2.比较当前这个哈希值在集合中是否已经存在,如果存在就不保存
forEach的底层就是一个迭代器
import java.util.HashSet;import java.util.Iterator;public class HashSetDemo {public static void main(String[] args) {//创建集合对象HashSet<String> set = new HashSet<>();//向集合中添加元素set.add("洪七公");set.add("黄药师");set.add("梅超风");set.add("黄药师");set.add("梅超风");set.add("黄药师");set.add("梅超大风");set.add("陈玄风");set.add("金轮法王");//打印结果System.out.println(set);//获取元素 - 只能使用迭代器,因为它是无序的Iterator<String> iter = set.iterator();while (iter.hasNext()){//推荐向下转型 - 就是强类型转换 - 目的:为了增强代码的健壮性 - 转成最后需要接收的类型String thisName = (String) iter.next();System.out.println(thisName);}//forEach的底层就是一个迭代器for(String name:set){System.out.println(name);}}}
HashSet去除原理
请简述HashSet去除重复元素的原理:
1.调用被添加元素的hashCode()和HashSet中已有元素的hashCode值比较是否相同
2.如果不同,直接存储
3.如果相同,调用equals方法比较是否相同
4.不相同,直接存储
5.相同,认为是同一元素,不存储
重写equals和hashCode方法
public class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
//重写equals() - 比较的地址值
@Override
public boolean equals(Object obj){
System.out.println("equals。。。衣扣死。。");
//this:表示contains方法的参数对象
//obj:集合中原有的对象
//将Object类型的obj强制转换为子类类型
Person otherP = (Person)obj;
//重写比较规则
//比较的是当前的对象的属性:名字,年龄
if(!this.getName().equals(otherP.getName())){
return false;
}
if(this.getAge() != otherP.getAge()){
return false;
}
//如果上面两个都不是false,则返回true
return true;
}
// 重写hashCode() - 生成的哈希值
@Override
public int hashCode(){
System.out.println("hashcode。。。哈希扣的。。");
//定义一个变量
int thisHashCode = 0;
//自定义测试的算法
//张三 18 | 56*系数+18 = 74
//李四 56 | 18*系数+56 = 74
//获取name属性的hashCode值
thisHashCode += this.name.hashCode()*17;
//获取age属性的hashCode值,就是age本身
thisHashCode += this.age;
return thisHashCode;
}
}
import java.util.HashSet;
/**
* HashSet集合中,添加元素的方法在执行添加的时候会判断元素是否已经存在:
* HashSet判断元素的唯一性规则:
* 1.把对象加入到hashSet的时候,会先使用对象的hashCode方法来生成一个哈希值,来判断对象加入的位置
* 2.如果比较的位置没有其他对象存在,则判断元素不同,可以加入新对象
* 3.如果比较的位置有其他对象存在,接着比较hashCode值和equals比较结果
* 返回true则相同,不能存入新的对象,如果是false则不同,添加新的对象
*
*
* 需求:
* 要求比较两个对象的属性和内容是否相同,而非比较对象的地址值
* 此时我们可以重写Person类中的hashCode和equals方法,将Object类中的方法重写
*
*/
public class HashSetAddDemo {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
//创建对象
Person p = new Person("武松",25);
Person p2 = new Person("西门庆",29);
Person p3 = new Person("潘金莲",22);
//添加到集合中
set.add(p);
set.add(p2);
set.add(p3);
System.out.println(set);
//再次调用add方法添加新的元素
set.add(new Person("西门庆",29));
System.out.println(set);
}
}

若有收获,就点个赞吧
0 人点赞
