2022/3/19
学习要点:ReLU激活,逐层预训练;Pytorch里练习 batch_size, shuffle, Softmax;练习使用 LeNet5 进行 CIFAR10 分类。
1、背景知识

深度学习三巨头:Yann LeCun, Geoffrey Hinton, Yoshua Bengio
Yann Lecun的贡献:是1989年发明了卷积神经网络(Convolutional Neural Networks, CNN),九十年代用于手写数字识别相当成功。但是当时当时计算机性能不行, Vapnik的SVM占了业内主流,一直到2012年。
Yoshua Bengio的贡献:2011年发明了 ReLU 激活函数,计算简单,显著缓解了神经网络的“梯度消失问题”
Hinton的贡献:尽管外界普遍不看好,但是他仍然坚持研究神经网络,并最终取得成功。美国学者组织了ILSVRC大规模图像识别竞赛,2012年,Hinton带领两个学生用 CNN+Dropout + ReLU激活函数,错误率只有15.3%。全世界沸腾了,这是神经网络首次大幅度击败了传统机器学习方法,也是人工智能火起来的一个转折点。 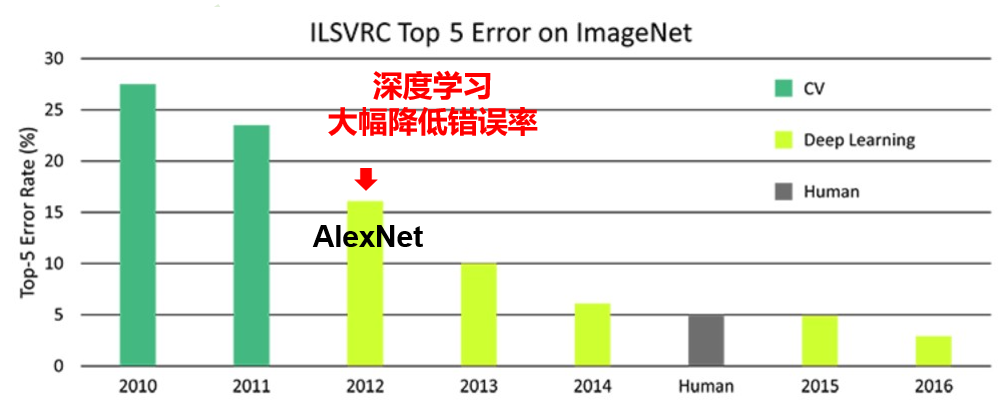
2、重点概念
2.1 激活函数
2011年以前,神经网络用的激活函数为 sigmoid,因此网络不能很深,容易出现梯度消失现象。ReLU的提出有效缓解了这一现象。这里演示:http://playground.tensorflow.org/
2.2 设计网络时,更宽还是更深?
在神经元总数相当的情况下,增加网络深度可以比增加宽度带来更强的网络表示能力。如果是CNN,更深就是增卷积层的数量,更宽就是增加每个卷积层的生产的通道数,两种方式都可以提升性能。
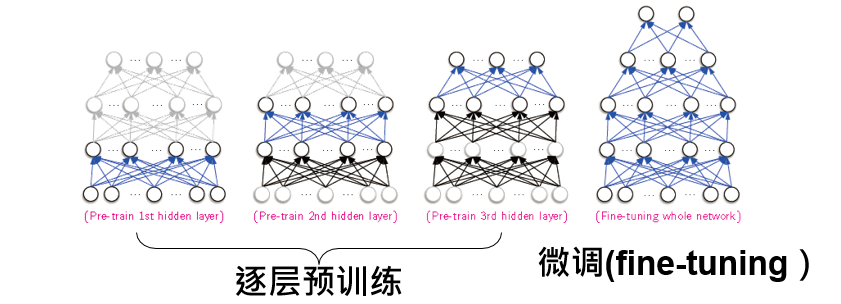
2.3 逐层预训练
神经网络是非凸优化(有多个极小值),容易落到一个比较差的极小值里出不来。 
同时,容易出现梯度消失现象,解决方法就是:寻找一个比较好的初始值。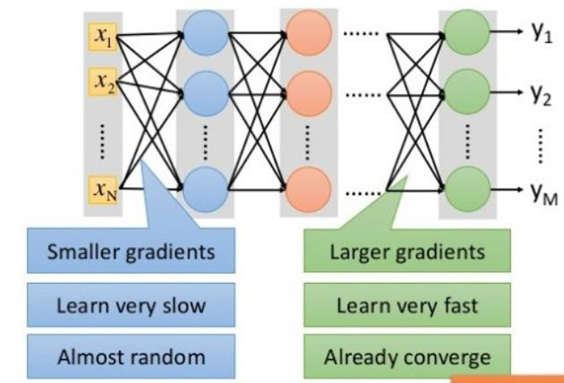
3、代码练习
同学们不要单纯的跑代码,建议大家要积极的“玩”代码,体会神经网络的神奇之处。
3.1 螺旋分类
代码地址:https://github.com/OUCTheoryGroup/colab_demo/blob/master/03_Spiral_Classification.ipynb
- 一开始,网络没有使用激活函数,效果非常差,为什么?
- 使用nn.Sigmoid() 作为激活函数,效果开始有提升,但收敛的非常慢
使用 nn.ReLU() 作为激活函数,效果提升,同时神经网络收敛的非常快
3.2 分类
代码地址:https://github.com/OUCTheoryGroup/colab_demo/blob/master/05_01_ConvNet.ipynb
train_loader里面,batch_size是越大越好吗? shuffle=True 有什么影响?
- 把神经网络的最后一层替换为:self.Softmax = nn.Softmax(dim=1) ,然后损失函数替换为:loss = F.cross_entropy(output, target) ,用下面的代码把一个随机生成的样本输入神经网络,观察结果:
结果为:tensor([0.1195, 0.0803, 0.1038, 0.1061, 0.0956, 0.1084, 0.0824, 0.0886, 0.1155,image = torch.randn(1, 1, 28, 28)cnn = CNN(input_size, n_features, output_size)y = cnn(images)print(y)
0.0999], grad_fn=)
说明什么?(思考Softmax 的作用)
在此基础上,鼓励大家练习用LeNet-5进行CIFAR10分类:
https://github.com/OUCTheoryGroup/colab_demo/blob/master/05_02_CNN_CIFAR10.ipynb
有任何问题大家可以随时联系我。
螺旋分类
sigmoid:存在梯度消失
- 未使用激活函数,拟合是线性的,这是因为神经网络=矩阵相乘,只能拟合线性平面
优化方法
- SGD=>Adam
- Sigmoid=>ReLU
05_01_ConvNet
- Normalize:均值=>0,方差=>1
- shuffle:每次小批量随机顺序,增加神经网络多样性
batch_size:越大越好,可基于硬件环境(GPU) | 归一 | 损失函数 | | —- | —- | | log_soft | nssloss | | softmax | cross_entropy |
softmax:所有概率为正,和为一
AlexNet
- DropOut:减少过拟合
- 一般池化层没有参数,因此不算入计算神经网络复杂度时的总层数
VGG
- 通过堆叠多个3x3,替代大尺度的卷积核
- 2个3x3<=>5x5卷积核
- 3个3x3<=>7x7卷积核
- 卷积核参数量:卷积核大小n x 3 x 输入Ci x 输出Co
GoogLeNet
- ResNet出现之前,使用逐层预训练减少梯度消失
- 1x1卷积核作用:升/降维,减少通道数
2022/3/26
ResNet
- shortcut:直接连接,可以提升性能,此时神经网络仅需要拟合差值
- BN:加在卷积层之后,调整特征,使得均值为0,方差为1
ResNeXt
- 特征分组(32组),从不同空间学习
- 可以提升性能,降低参数量,便于计算,类似于多头注意力机制
- 分组数可以等于通道数
下一周:MobileNet:DepthWise Conv(DW卷积)

若有收获,就点个赞吧
0 人点赞
