算法思想
由哈夫曼树的定义可知,初始森林中共有n棵只含有根结点的二叉树,将当前森林中的两棵根结点权值最小的二叉树合并成一棵新的二叉树;每合并一次,森林中就减少一棵树,产生一个新结点。显然要进行n-1次合并,所以共产生n-1个新结点,它们都是具有两个孩子的分支结点。由此可知,最终求得的哈夫曼树中一共有2n-1个结点,其中n个结点是初始森林的n个孤立结点。并且哈夫曼树中没有度数为1的分支结点。可以利用一个大小为2n-1的一维数组来存储哈夫曼树中的结点。
算法实现
- 定义结构体类型
char hmfcode[MAX];typedef struct {char data; //结点字符int weight; //权值int parent; //双亲结点int lchild; //左孩子结点int rchild; //右孩子结点} HTNode;
- 根据设计要求和实际需要定义的类型如下:
typedef struct {char cd[N]; //存放哈夫曼码int start; //从 start 开始读 cd 中的哈夫曼码} HCode;
- 字符数统计函数:
int Statistics(char *s,int cnt[],char str[]) {char *p;int i,j,k;for(i=1; i<=256; i++)cnt[i]=0;for(p=s; *p!='\0'; p++) {k=*p;cnt[k]++;}j=0;for(i=1,j=0; i<=256; i++)if(cnt[i]!=0) {j++;}return j;}
- 哈夫曼树创建函数:
void CreateHT(HTNode ht[],int n,char str[],int cn[]) { //创建哈夫曼树函数for(int input=1; input<=256; input++) {str[input]=input;}int l=0;for(int output=1; output<=256; output++) {if(cn[output] !=0) {ht[l].data=str[output]; //按字母顺序将出现的字母依次存入数组 ht[]ht[l].weight=cn[output];l++;}}int i,k,lnode,rnode;int min1,min2;for (i=0; i<2*n-1; i++)ht[i].parent=ht[i].lchild=ht[i].rchild=0; //所有结点的相关域置初值 0for (i=n; i<2*n-1; i++) { //构造哈夫曼树min1=min2=MAX; //int 的范围是 -32768-32767lnode=rnode=0; //lnode 和 rnode 记录最小权值的两个结点位置for (k=0; k<=i-1; k++) { //选出每次外层循环最小权值的两个结点if (ht[k].parent==0) { //只在尚未构造二叉树的结点中查找if (ht[k].weight<min1) { //比 min1 小时min2=min1;rnode=lnode;min1=ht[k].weight;lnode=k;} else if (ht[k].weight<min2) { //比 min1 大,比 min2 小min2=ht[k].weight;rnode=k;}}}ht[lnode].parent=i;ht[rnode].parent=i; //两个最小节点的父节点是 iht[i].weight=ht[lnode].weight+ht[rnode].weight; //两个最小节点的父节点权值为两个最小节点权值之和ht[i].lchild=lnode;ht[i].rchild=rnode; //父节点的左节点和右节点}}
- 根据哈夫曼树求哈夫曼编码:
void CreateHCode(HTNode ht[],HCode hcd[],int n) {int i,p,c;HCode hc;for (i=0; i<n; i++) { //根据哈夫曼树求哈夫曼编码hc.start=n; //初始位置c=i; //从叶子结点 ht[i] 开始上溯p=ht[i].parent;while (p!=0) { // 循序直到树根结点结束循环hc.cd[hc.start--]=(ht[p].lchild)==c?'0':'1'; //左孩子记为 0,右孩子记为 1c=p;p=ht[p].parent; //与上句 c=i;p=ht[i].parent 同义,促进循环}hc.start++; //start 指向哈夫曼编码 hc.cd[] 中最开始字符hcd[i]=hc;}}
- 输出哈夫曼编码的列表:
void outputHCode(HTNode ht[],HCode hcd[],int n) { //输出哈夫曼编码的列表int i,k;printf("输出哈夫曼编码 :\n");for (i=0; i<n; i++) { //输出 data 中的所有数据,printf("%c:\t",ht[i].data);for (k=hcd[i].start; k<=n; k++) { //输出所有 data 中数据的编码printf("%c",hcd[i].cd[k]); //从初最开始的字符起输出}printf("\n");}}
- 编码函数,将编码结果存入文件hmfcode.txt中:
void editHCode(HTNode ht[],HCode hcd[],int n,char str[]) { //编码函数FILE* fp;fp = fopen("hmfcode.txt", "a+"); //打开文件,文件不存在则创建int i,j,k,l;printf("\n输出编码结果 :\n");for (i=0; i<MAX; i++)for (j=0; j<n; j++)if(str[i]==ht[j].data) { //循环查找与输入字符相同的编号,相同的就输出这个字符的编码for (k=hcd[j].start; k<=n; k++) {printf("%c",hcd[j].cd[k]);fputc(hcd[j].cd[k], fp);}break; //输出完成后跳出当前 for 循环}fputc('\n', fp);printf("\n");fclose(fp);}
- 译码函数(解压函数),将译码结果存入文件hmfcode.txt中:
void deHCode(HTNode ht[],HCode hcd[],int n,char str[]) { //译码函数FILE* fp;fp = fopen("hmfcode.txt", "a+"); //打开文件,文件不存在则创建printf("输出译码结果为 :\n");int i,j,k,x,m=0;char code[MAX];for (i=0; i<MAX; i++)for (j=0; j<n; j++)if(str[i]==ht[j].data) { //循环查找与输入字符相同的编号,相同的就输出这个字符的编码for (k=hcd[j].start; k<=n; k++) {code[m]=hcd[j].cd[k]; //将输出的编码赋值到数组中m++;}break; //输出完成后跳出当前 for 循环}code[m]='#';//把要进行译码的字符串存入 code 数组中while(code[0]!='#')for (i=0; i<n; i++) {m=0; //m 为想同编码个数的计数器for (k=hcd[i].start,j=0; k<=n; k++,j++) { //j 为记录所存储这个字符的编码个数if(code[j]==hcd[i].cd[k]) //当有相同编码时 m 值加 1m++;}if(m==j) { //当输入的字符串与所存储的编码字符串个数相等时则输出这个的 data 数据printf("%c",ht[i].data);fputc(ht[i].data, fp);for(x=0; code[x-j]!='#'; x++) { //把已经使用过的 code 数组里的字符串删除code[x]=code[x+j]; //删除 j 个数,往前移动 j 位}}}fputc('\n', fp);printf("\n");fclose(fp);}
- 主函数
#include <stdio.h>#include <string.h> //gets()函数需要#define N 256 //用 N 表示 50 叶节点数#define M 2*N-1 //用 M 表示节点总数 当叶节点数位 n 时总节点数为 2n-1#define MAX 32767int main() {FILE *fp = fopen("text.txt", "r");;int option;char st[MAX],sst[MAX];int cn[257];int n,i;printf("请选择:0:输入字符串\t1:打开文件text.txt:\n");scanf("%d",&option);if (!option) {getchar();printf("请输入字符串 (任意字符 ):\n");gets(st);} else {fgets(st, MAX, fp);printf("文件内容为:%s\n",st);}n=Statistics(st,cn,sst);for(i=0; i<99; i++)sst[i]=st[i];HTNode ht[M];HCode hcd[N];CreateHT(ht,n,st,cn);CreateHCode(ht,hcd,n);outputHCode(ht,hcd,n);editHCode(ht,hcd,n,sst);deHCode(ht,hcd,n,sst);printf("结果已成功保存在文件hmfcode.txt中!");fclose(fp);}
运行结果
- 输入字符串,实现编码,解码并将结果写入文件hmfcode.txt中:
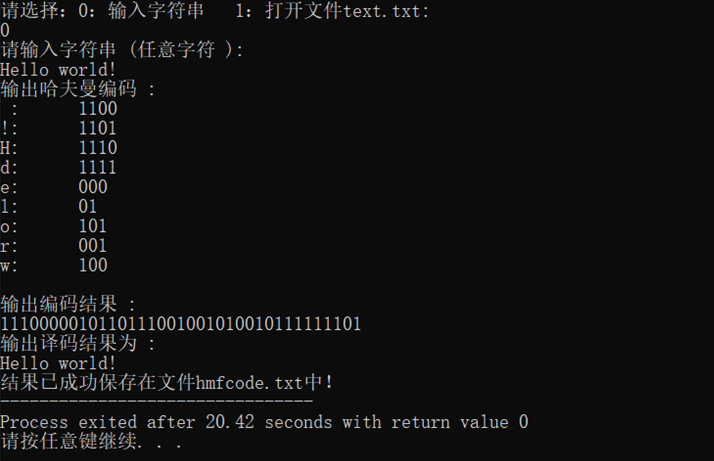
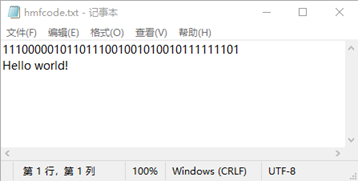
- 从文件text.txt读取内容,实现编码,解码并将结果写入文件hmfcode.txt中:
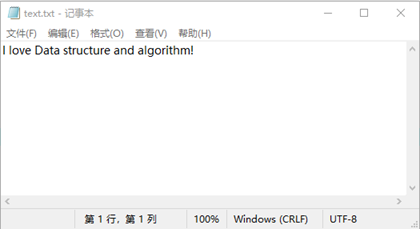
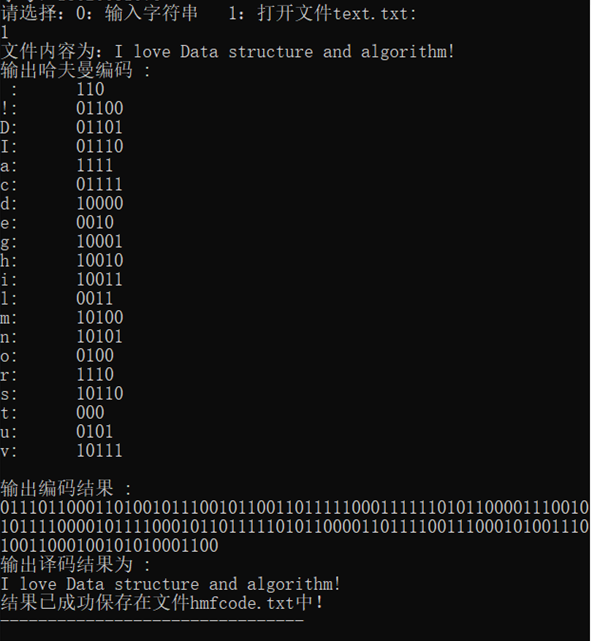

若有收获,就点个赞吧
0 人点赞
