为了完成大规模的、并发的任务,经过刀耕火种自己维护的年代后,决定抽象出来一个编程模型,称为 MapReduce.
MapReduce 编程模型
MapReduce 计算是由一组键值对的值,经过 map 函数转换为中间的另外的一组键值对的值,再这一组中间值通过 reduce 函数处理后,输出最终的值。<br /> 形象生动来写,就是下面这段:<br /> map (k1,v1) → list(k2,v2)<br /> reduce (k2,list(v2)) → list(v2)
MapReduce 实现步骤/执行过程
编程模型是不错。但是它在 Google 内部是有物理条件:<br /> 1. 很多台商业型(不是特高配)计算机资源。<br /> 2.受到网速限制。<br /> 3. 一个集群有很多台机器,当然机器错误也是正常的。<br /> 4. 内部有 Google File System(GFS)<br /> 5. 用户在调度系统里面提交任务/工作。<br />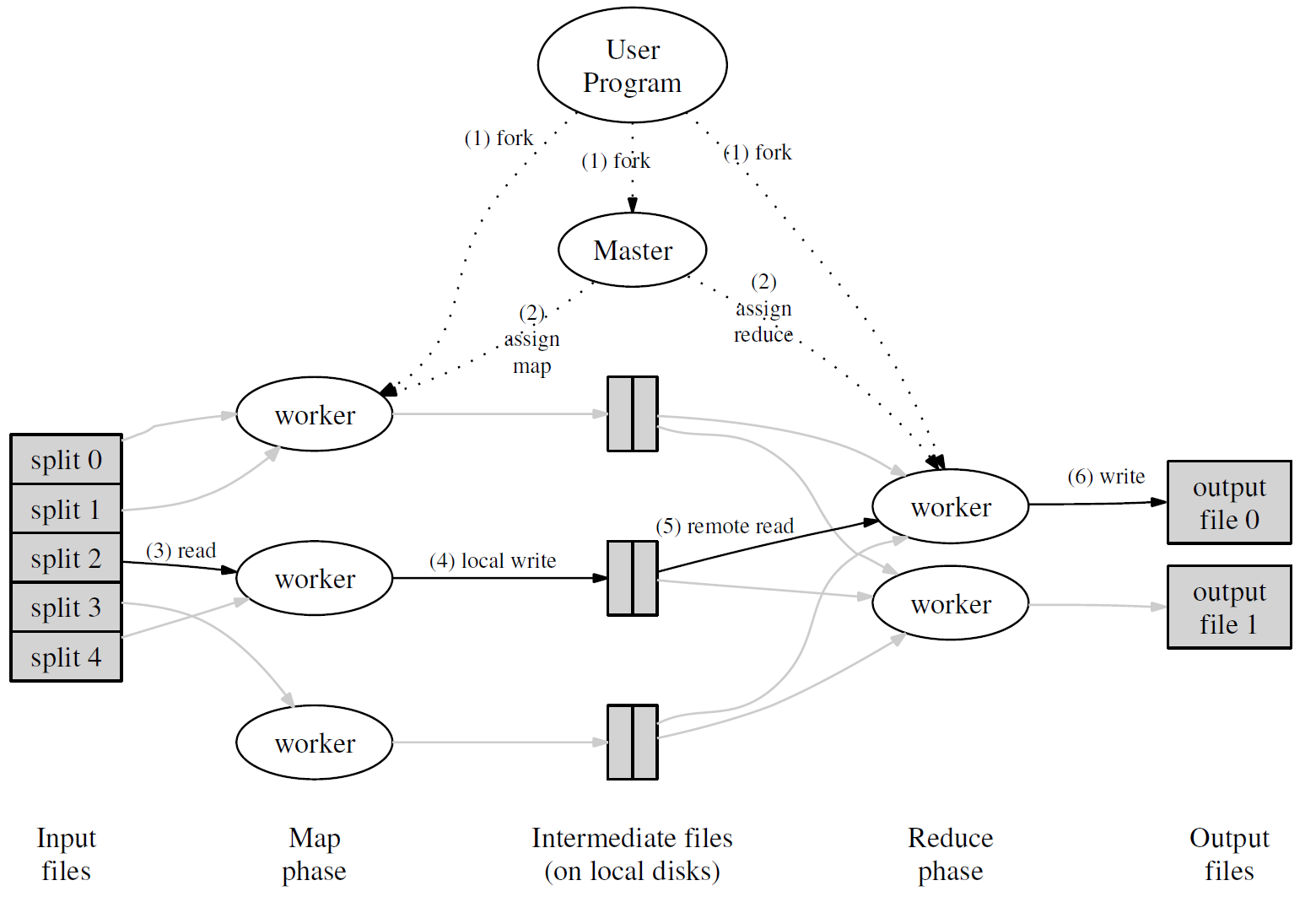<br /> 模型的具体思路:<br /> 1. 把初始化数据分成 M 份(一份大概 16 - 64MB 大小)给 map 方法使用。<br /> 2. 这个流程中有个 master 角色来控制流程的执行。<br /> 3. 分配到 map 任务的机器会读取初始化数据,经过用户自己写的函数,生成以 key/value 键值对的中间数据。<br /> 4. map 函数处理后的数据,周期性、分块存放在本地硬盘,并且系统机制通知 master 这些文件的位置。<br /> 5. reduce 函数在读取中间数据后,因为数量可能过多,会对 key 进行排序对中间数据进行处理。<br /> 6. reduce 分批逐步输出数据。<br /> 7. 完成 map 和 reduce 的处理后,master 通知用户完成。
MapReduce 的容错机制
MapReduce 对不熟悉分布式的用户很友好。我个人对于 fault tolerence 很好奇,不知道它们怎么做的。这块得益于看了呆呆同学的中文描述,自己才知道怎么写。以下很多会摘抄呆呆同学的写法加强自己的记忆。
Worker Failure
在一个 MapReduce 集群里面,Master 会周期地向每一个 Worker 发送 ping 信号。如果 Worker 在一段时间内没有响应,那么 Master 会认为这个 Worker 不可用。<br /> 如果该 Worker 分配到 map 任务(这个时候它不可用了)。无论是正在运行或者已经执行,都需要由 Master 分配到其他 Worker。因为该 Worker 不可用的话,那该 Worker 存储在本地存储的中间结果是不可用了,Master 也会通知到所有 Reducer 的机器,让没能从原来的 Mapper 获取中间结果的 Reducer 就从新的 Mapper 获取数据。<br /> 如果该 Worker 分配到 reduce 任务(这个时候它不可用了)。Master 会选取尚未完成的 Reduce 任务分配给其他 Worker。因为 MapReduce 的结果是存在 Google File System 里面的,已完成的 Reduce 任务的结果的可用性由 Google File System 提供,因此 MapReduce Master 只需要处理未完成的 Reduce 任务即可。
Master Failure
整个 MapReduce 集群中只有一个 Master 节点,所以 Master 失效的情况并不多见。<br /> Master 会在运行时周期性地将集群的当前状态作为保存点写入到磁盘中。Master 进程终止后,重新启动的 Master 进程即可利用存储在磁盘中的数据恢复到上一个保存点。
Backup Tasks
如果集群中有某个 Worker 花了特别长的时间来完成最后几个 Map 或 Reduce 任务,整个 MapReduce 计算任务的耗时就会延长。那么这样的 Worker 也就成了落后者(Straggler)<br /> MapReduce 在整个计算完成到一定程度时会将剩余的任务进行备份,即同时分配给这些任务给空闲的 Worker 来执行,并在其中一个 Worker 完成后将任务视为已完成。
目录
Abstract1 Introduction2 Programming Model2.1 Example2.2 Types2.3 More Examples3 Implementation3.1 Execution Overview3.2 Master Data Structures3.3 Fault Tolerance3.4 Locality3.5 Task Granularity3.6 Backup Tasks4 Refinements4.1 Partitioning Function4.2 Ordering Guarantees4.3 Combiner Function4.4 Input and Output Types4.5 Side-effects4.6 Skipping Bad Records4.7 Local Execution4.8 Status Information4.9 Counters5 Performance5.1 Cluster Configuration5.2 Grep5.3 Sort5.4 Effect of Backup Tasks5.5 Machine Failures6 Experience6.1 Large-Scale Indexing7 Related Work8 ConclusionsAcknowledgementsReferences
参考文档
本论文地址( 需要自行梯子): https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
个人觉得不错的中文核心部分: Google MapReduce 论文详解

若有收获,就点个赞吧
0 人点赞
