ChatGPT 是一种通用自然语言生成模型,使用大量预料数据训练,以实现生成文本、回答问题、对话生成等功 能。
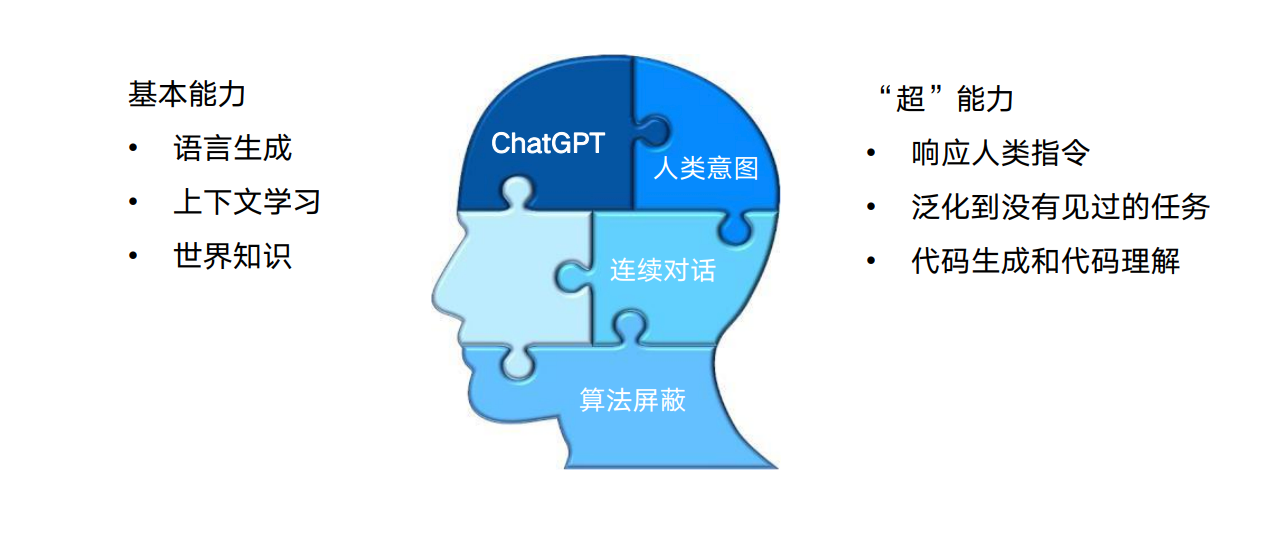
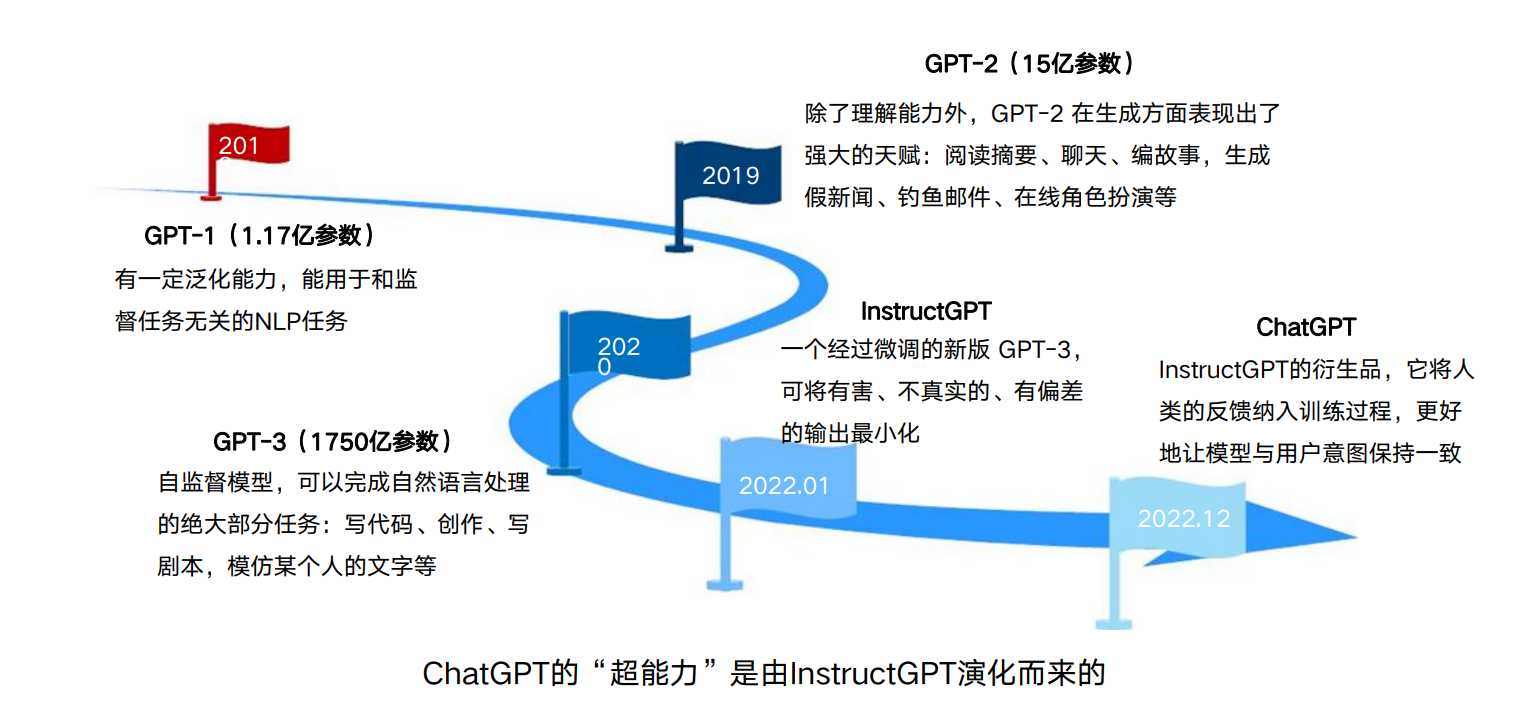
ChatGPT 的前世今生
ChatGPT 的训练流程
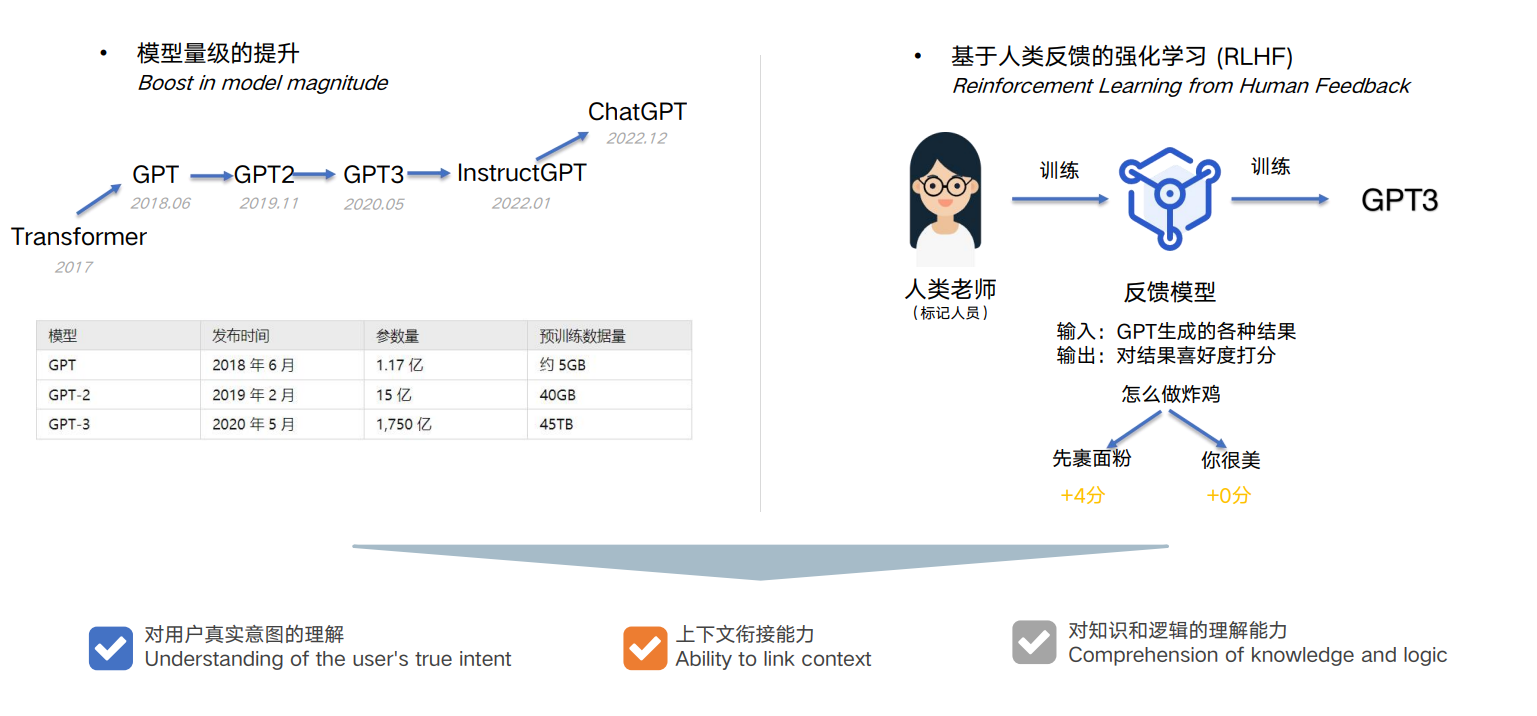
由于 ChatGPT 并没有放出论文,我们没法直接了解 ChatGPT 的设计细节。但它的博客中提到,ChatGPT 用的是和 InstructGPT一样的方法,只是在数据收集上和 InstructGPT 不一样 — ChatGPT 用的是多轮对话作为数据集。还有 InstructGPT 是在 GPT-3 上做微调,而 ChatGPT 是在 GPT3.5 上做微调。因此我们可以参考 InstructGPT的论文去理解 ChatGPT。
InstructGPT 的技术原理图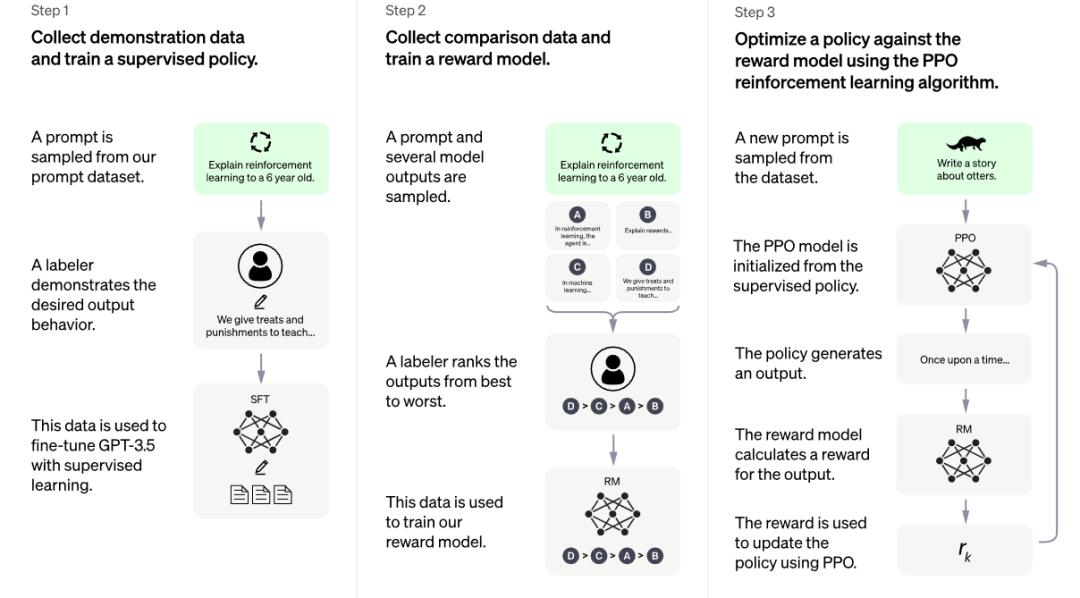
ChatGPT 博客中的技术原理图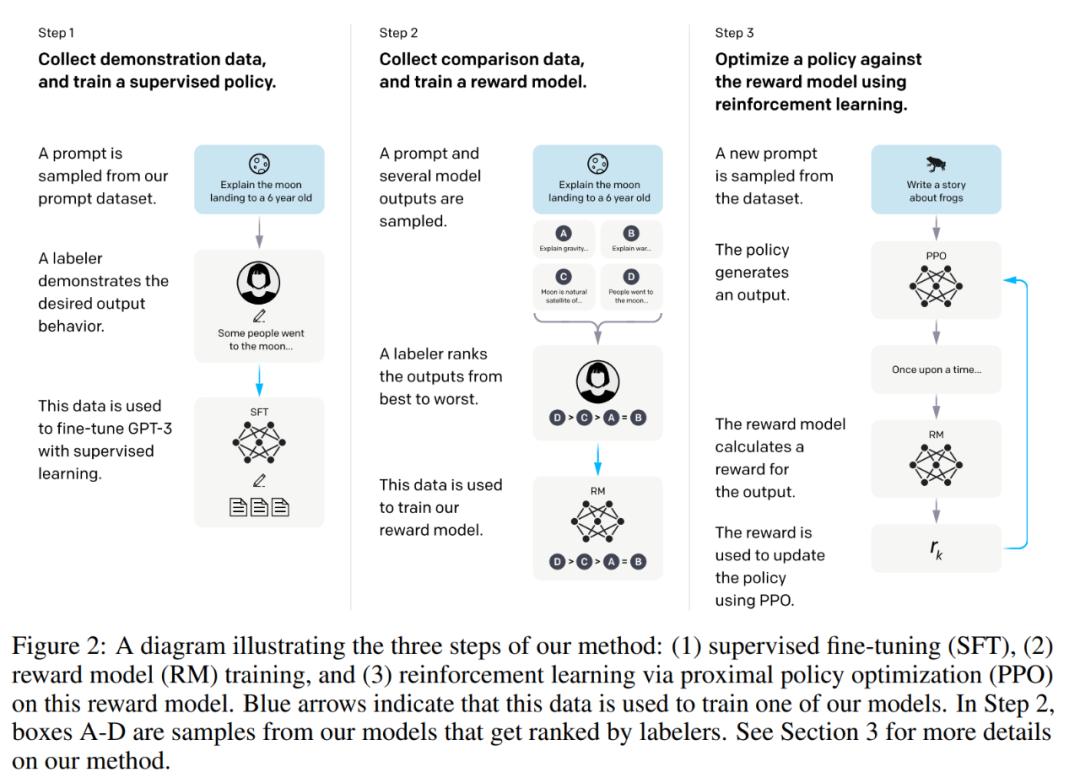
总体来说, ChatGPT 的训练流程包含三个步骤
监督学习。收集人工编写的期望模型,如何输出的数据集,并使用其来训练一 个生成模型(GPT3.5- based); :::info 简单说,就是根据人编写的答案,训练出一个简单模型,回答会有很大的局限性。 :::
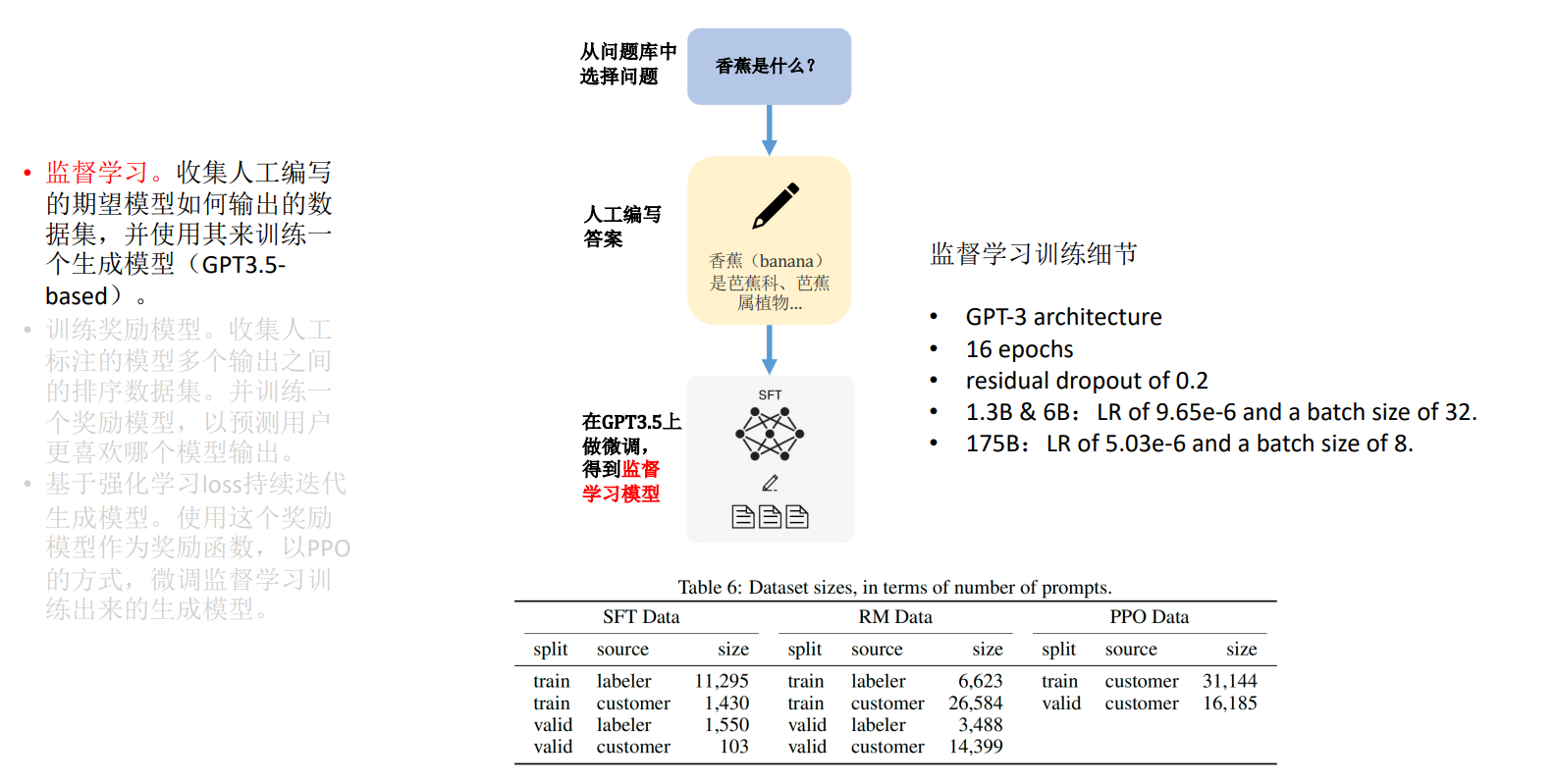
训练奖励模型。收集人工标注的模型多个输出之间的排序数据集。并训练一 个奖励模型,以预测用户更喜欢哪个模型输出。 :::info 说明:由于第一步训练出来的模型的回答会有很大的局限性,有正向回答,又有负向回答, ChatGPT 不知道给出那个答案更合适,于是通过人工对答案进行排序,再利用排序结果训练出奖励模型(打分) :::
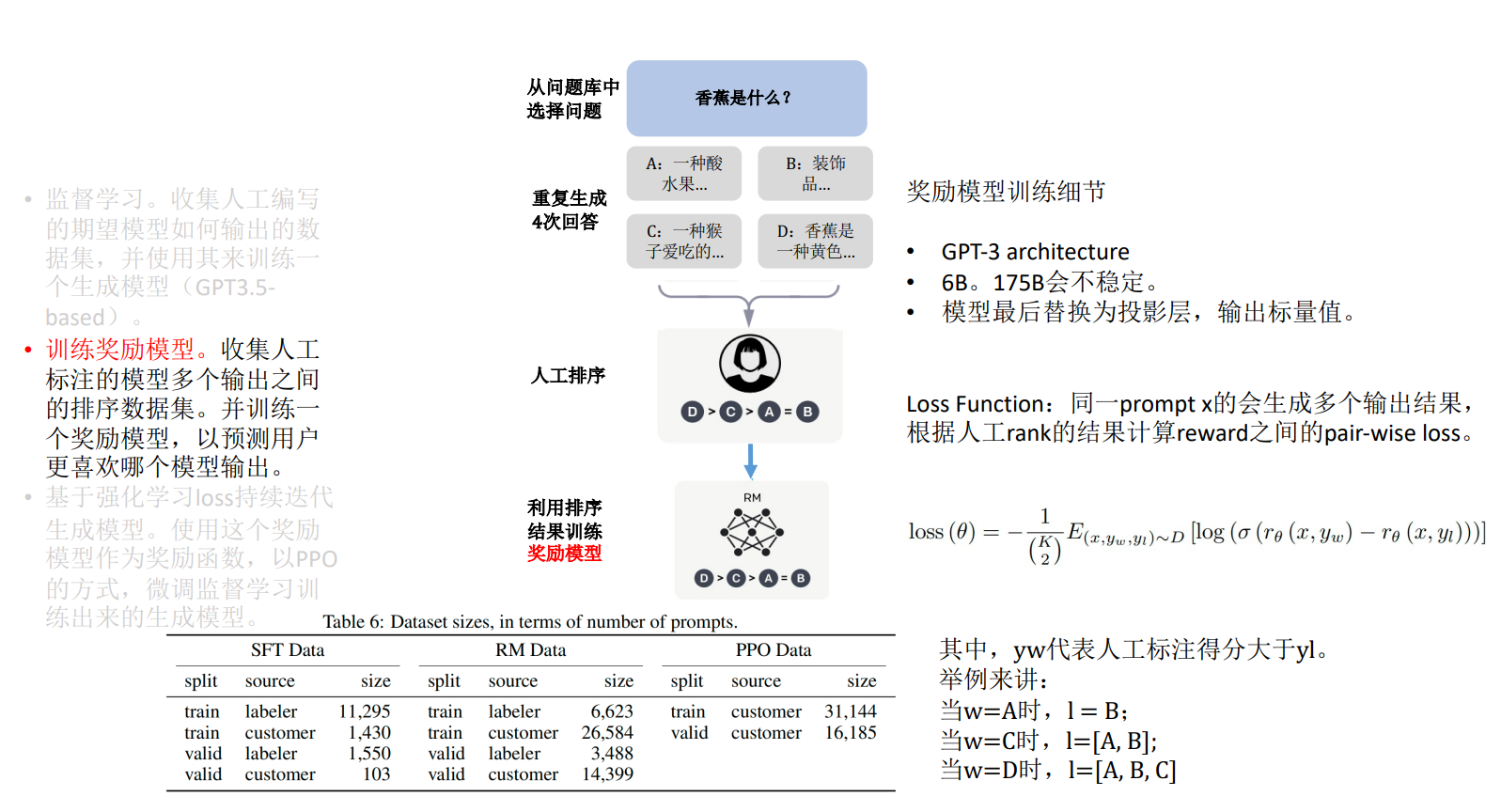
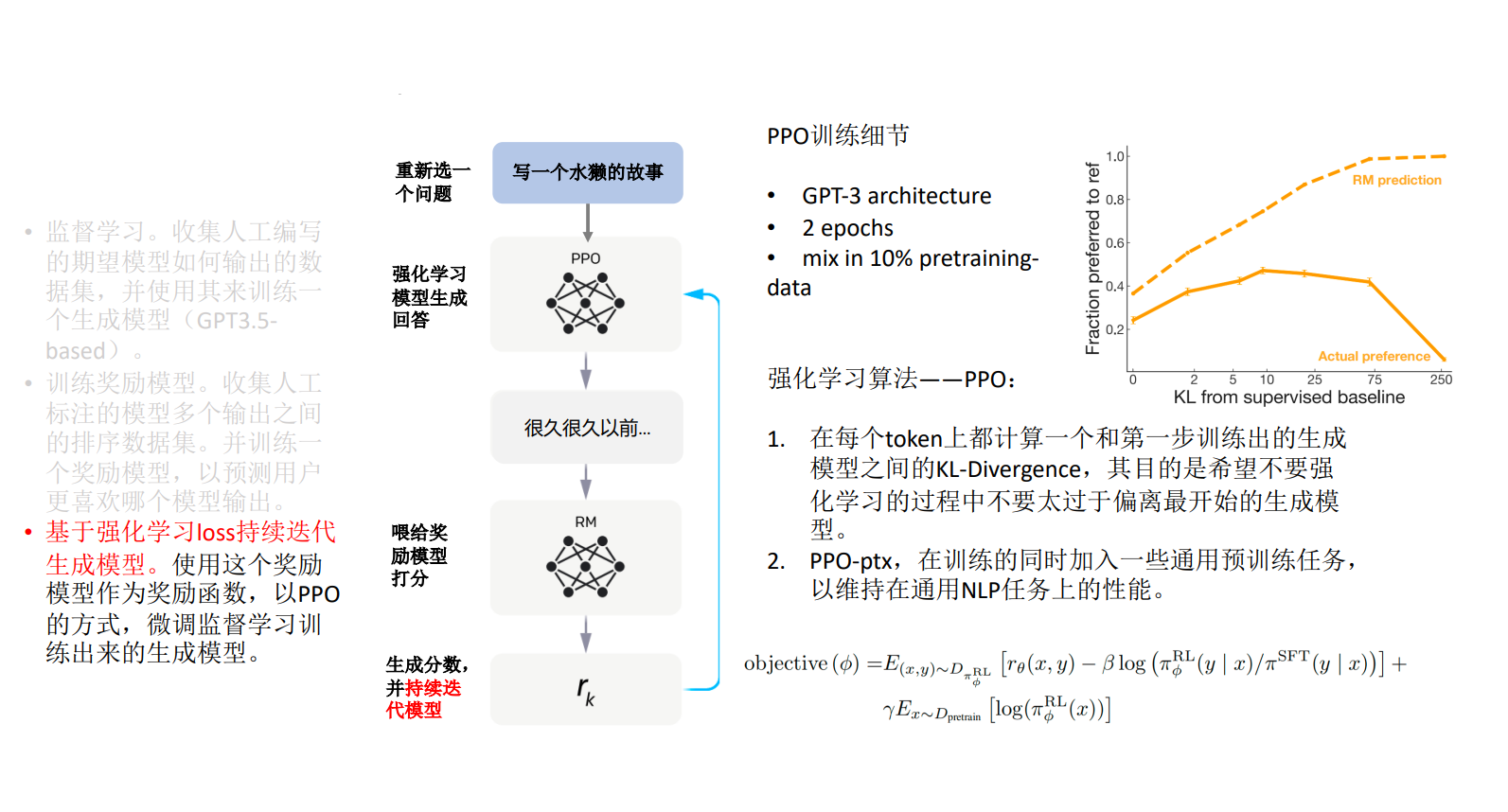
基于强化学习 loss 持续迭代生成模型。使用这个奖励模型作为奖励函数,以 PPO 的方式,微调监督学习训 练出来的生成模型 :::info 说明:将新的问题交给强化学习模型(以 PPO 的方式,微调监督学习训练出来的生成模型),然后将给出的答案喂给第二步训练出来的奖励模型生成答案和分数,再交给强化学习模型, 并持续迭代强化学习模型, 从而使 ChatGPT 生成更好的答案 :::
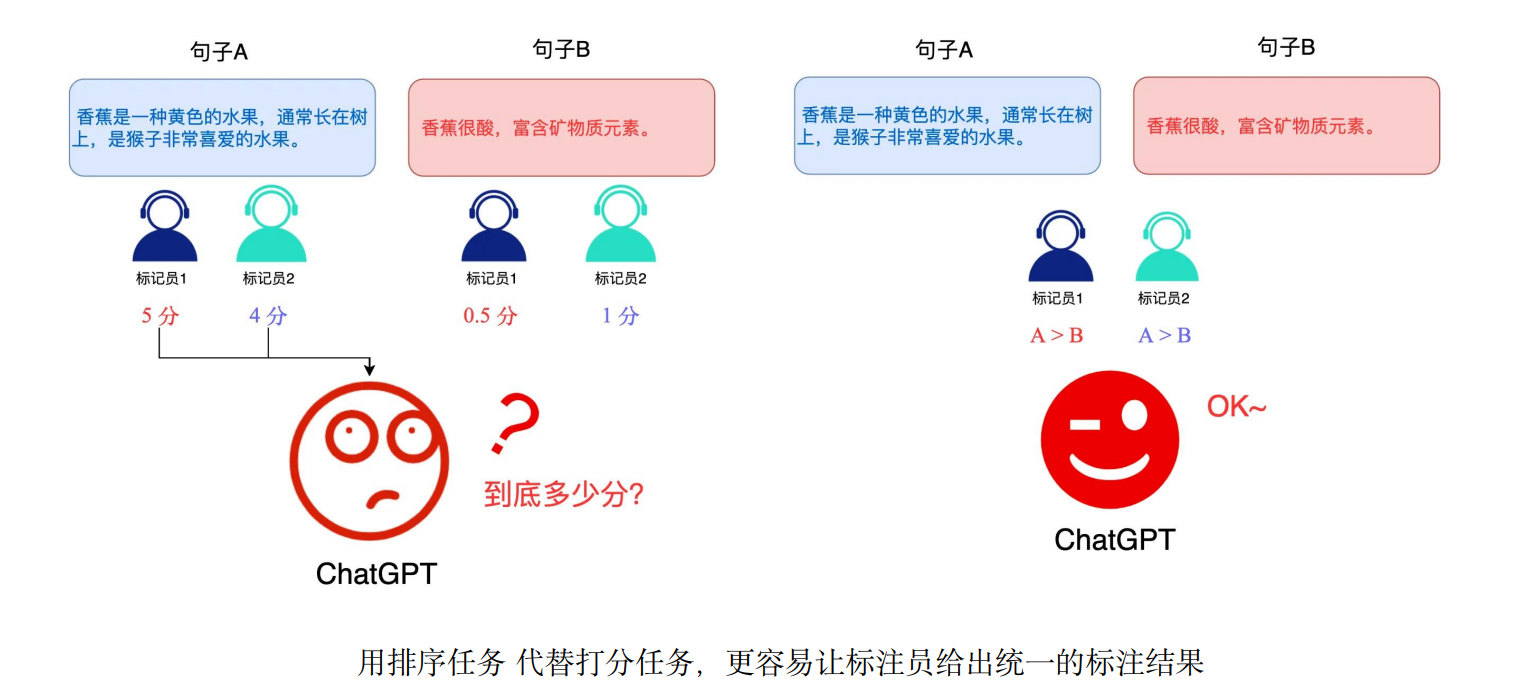
注解:排序任务
训练 Reward Model 模型的项目源码: https://github.com/HarderThenHarder/transformers_tasks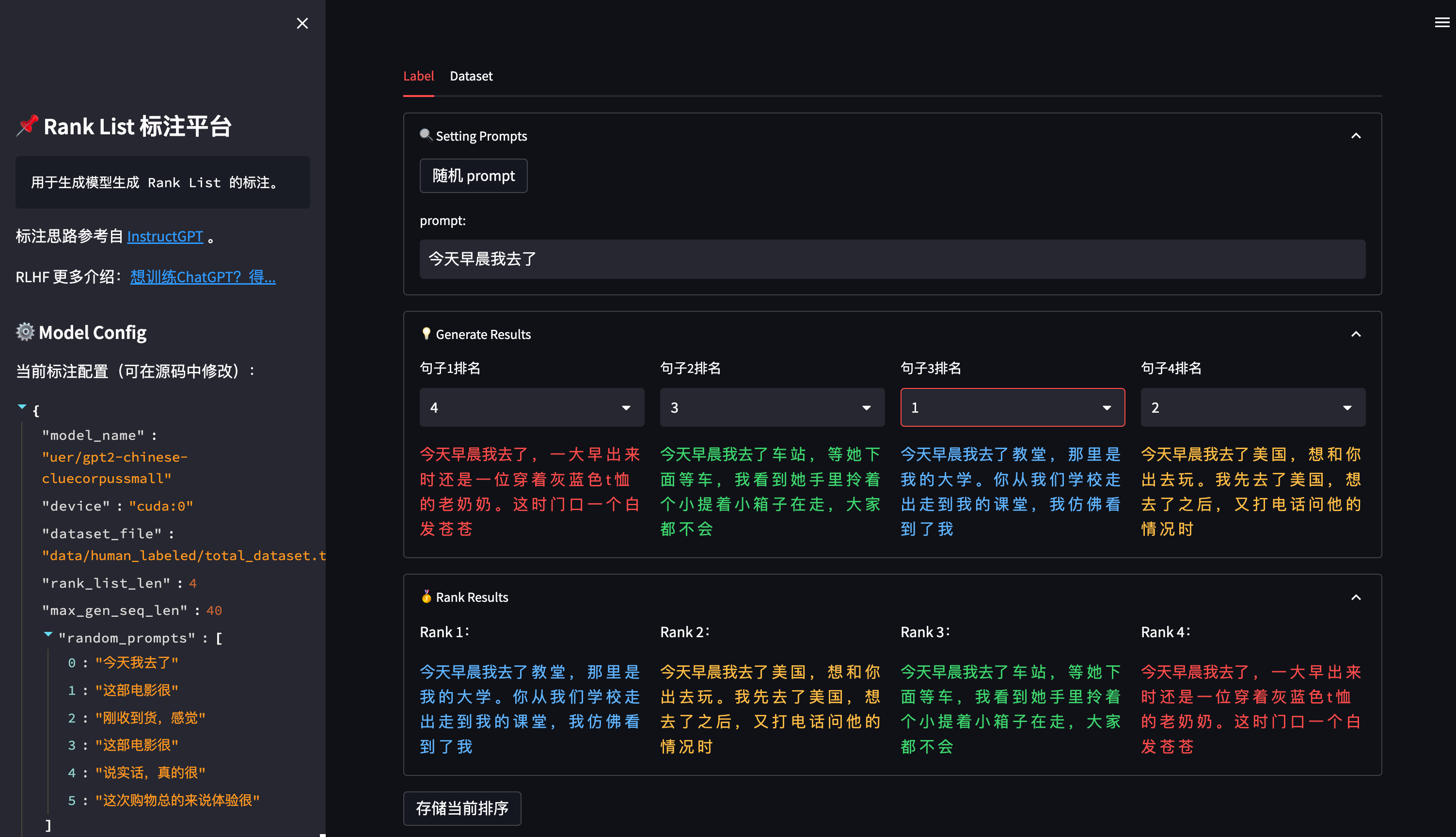
使用强化学习(而非监督学习)的方式更新语言模型,最大的优势是在于能够使得「模型更加自由的探索更新方向,从而突破监督学习的性能天花板」。
ChatGPT 的优势
ChatGPT 应用场景
应用场景:AI客服
假如你是一名银行客服人员,我是访问你们网站的顾客,你的目的是获取 我的电话号码。但是为了获取电话号码,你要帮我解决一些我提出的问题, 你觉得解决了问题之后,你想他要电话号码,这样成功率会比较高。现在 让我们开始吧

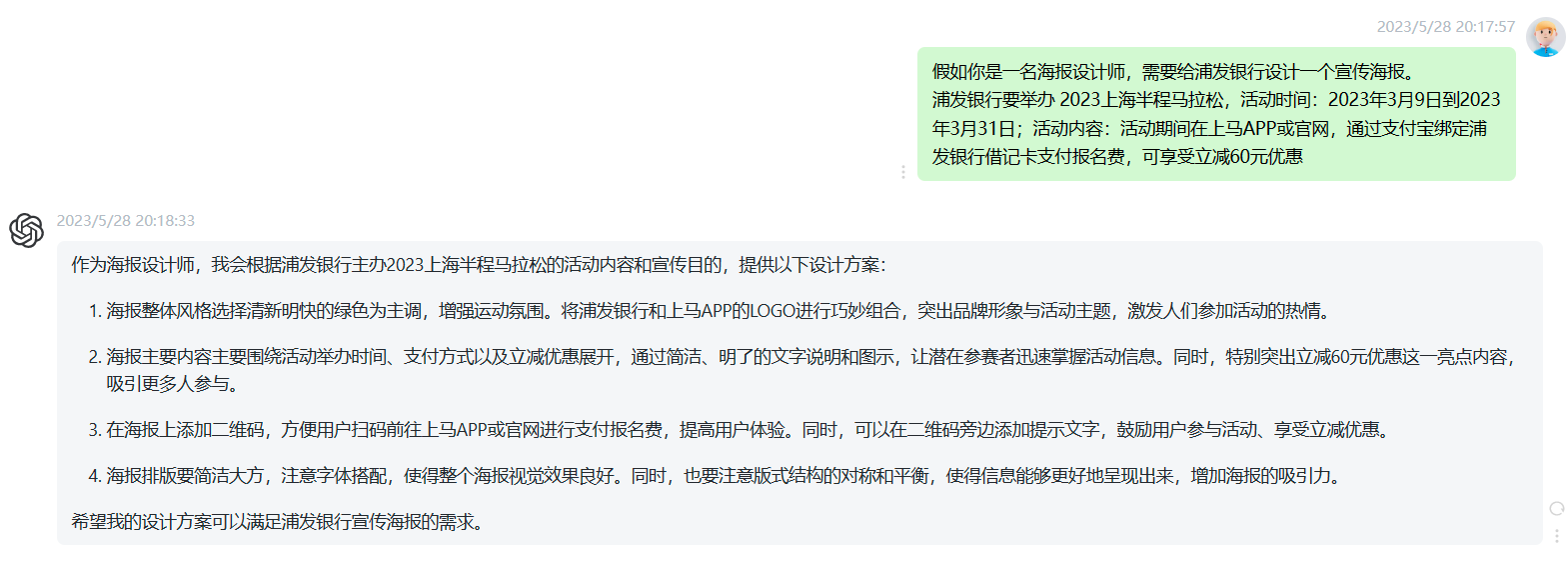
应用场景:AI文案
假如你是一名海报设计师,需要给浦发银行设计一个宣传海报。 浦发银行要举办 2023上海半程马拉松,活动时间:2023年3月9日到2023 年3月31日;活动内容:活动期间在上马APP或官网,通过支付宝绑定浦 发银行借记卡支付报名费,可享受立减60元优惠

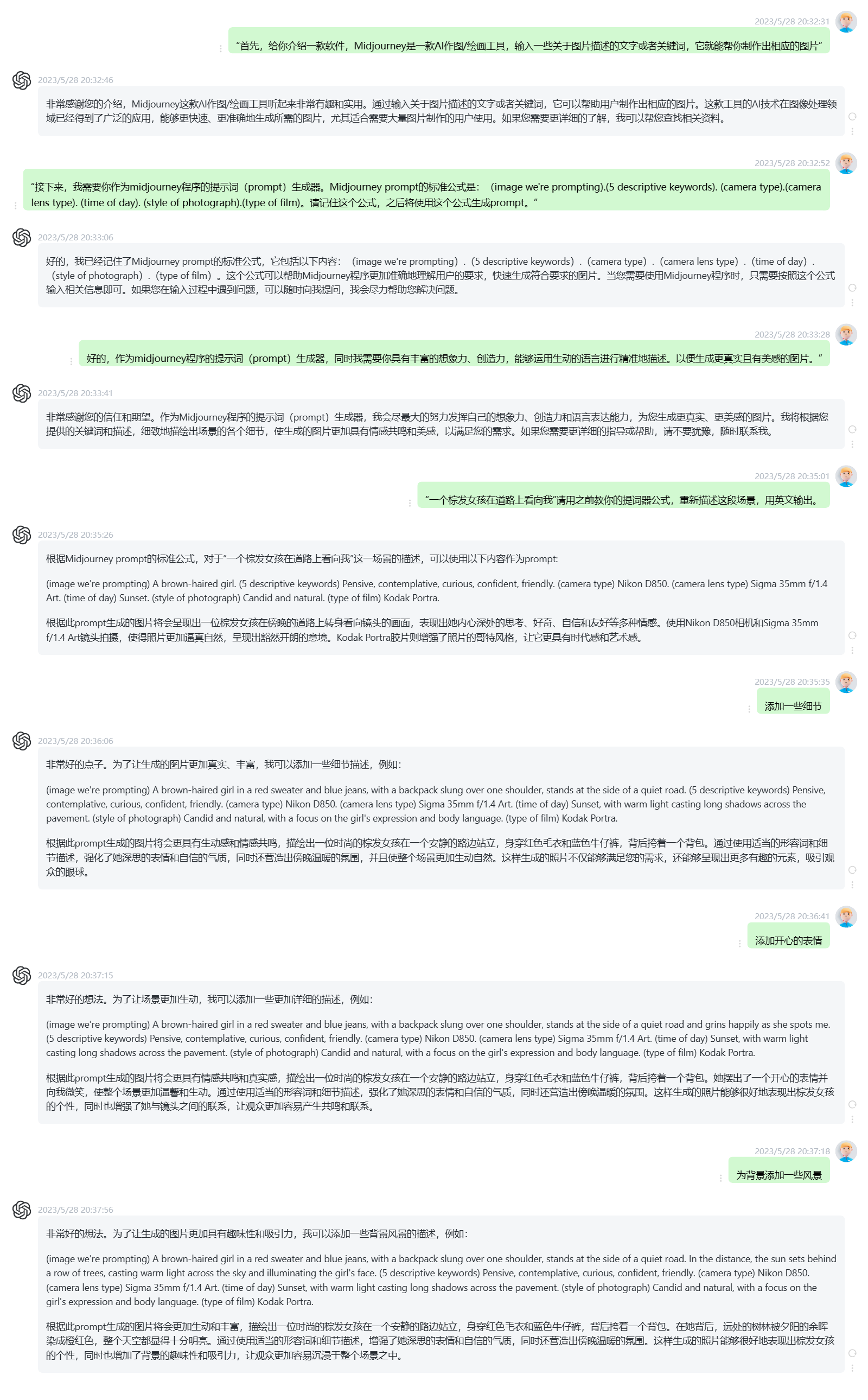
应用场景:AI作图
应用场景:AI写代码

若有收获,就点个赞吧
0 人点赞
