基本数据类型
- 字符串 str
- 数字 int, float
- 布尔类型 True False
- 空 None
- 列表 []
- 元组 ()
- 集合 {1,2,3}
- 字典 {“a”: 1}
字符串 str
基本定义
定义一个字符串 使用 单引号''或者 双引号""引起来的内容为 字符串。
查看数据类型,使用 type() .# 定义变量a = "helloworld"b = "10"c = '中国'# 打印出来对应的变量的类型print(a,b,c, type(a),type(b),type(c))
单双引号的使用规则
如果一个字符串中有双引号,比如小明说:"你是个好人!"放在字符串中。 定义的时候使用 单引号来定义.a = '小明说:"你是个好人!"'print(a)
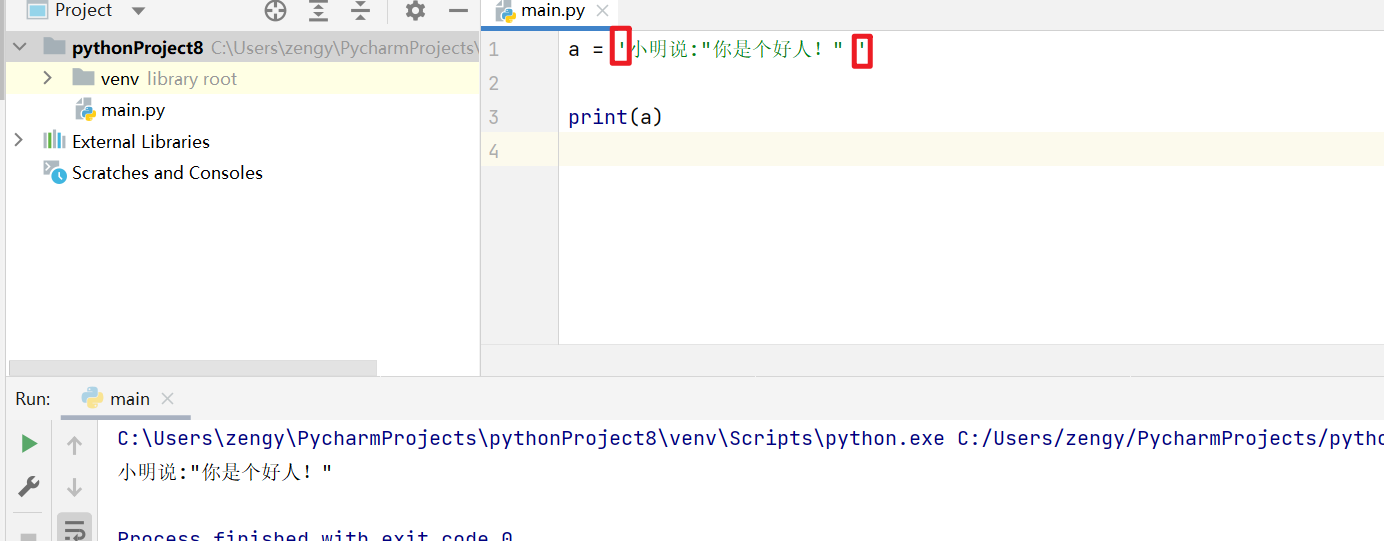
最外层不能直接使用 双引号。 需要大家注意,下面截图中的定义是错误的。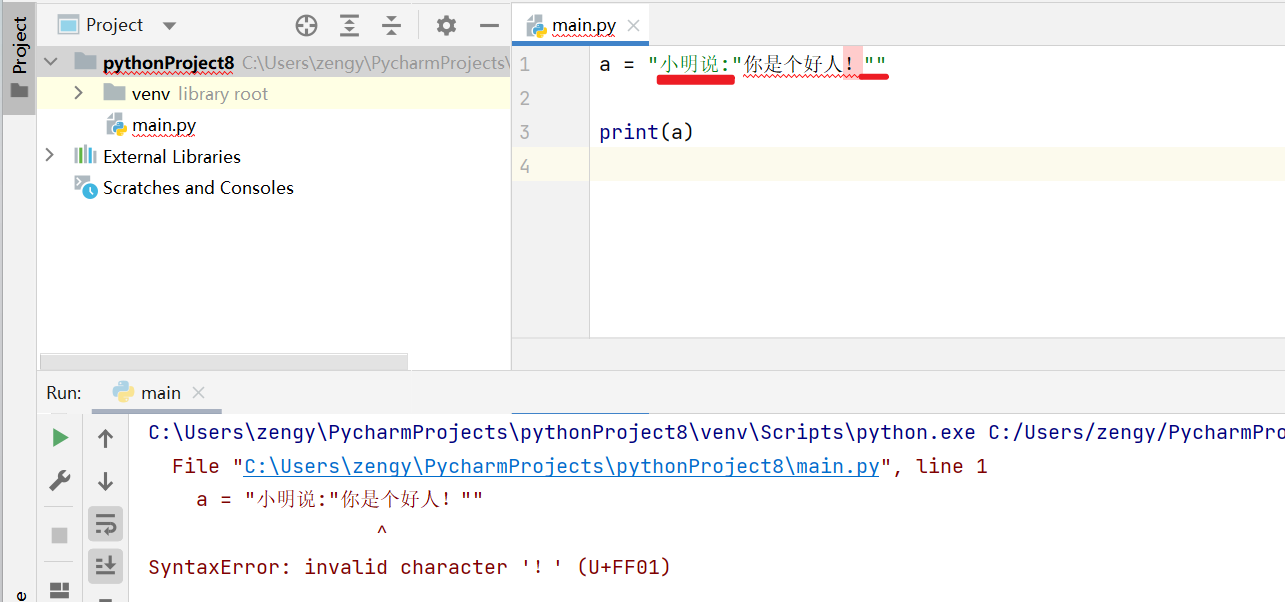
如果一个字符串中有单引号xiaiming:'you are my hero', 定义的时候,外层使用双引号
那么会报错:a = '小明说:"你好! i'm a good boy "'

如果外层使用双引号,一样也会出现问题:
可以使用 \ 转义来处理。当最外层使用 单引号'的时候的,字符串中含有单引号的部分前添加\进行转义(不要让字符串中的单引号作为定义字符串的功能)
同样的,如果外层使用的是双引号,字符串中有 双引号的地方添加a = '小明说:"你好! i\'m a good boy "'print(a)
\进行转义:b = "小明说:\"你好! i'm a good boy \""print(b)
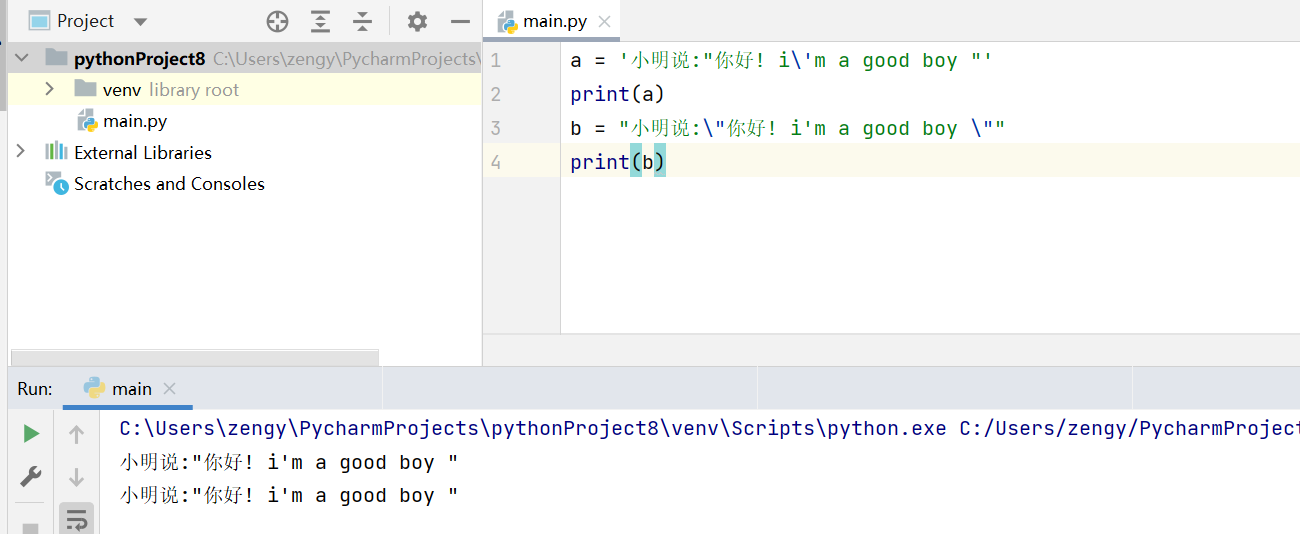 转义字符串会在 处理做接口测试 处理json数据字符串的时候会使用到。
转义字符串会在 处理做接口测试 处理json数据字符串的时候会使用到。
\其他特殊含义
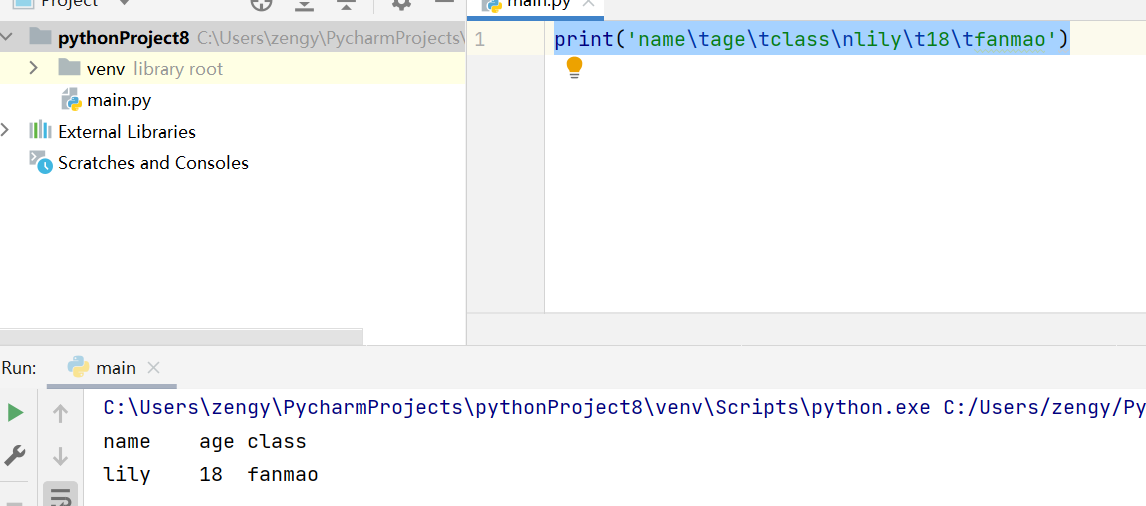
| 表达式 | 含义 | | —- | —- | | \t | tab键缩进 | | \n | 回车 |
print('name\tage\tclass\nlily\t18\tfanmao')
Windows路径问题
Windows目录中文件的绝对路径中也包含 \ 比如下面路径
file = "C:\Users\zengy\tycharmProjects\nebDemo"
python中 \t \n 有特殊的函数,上面的路径 在使用的时候。如果不加处理的话会直接报错。
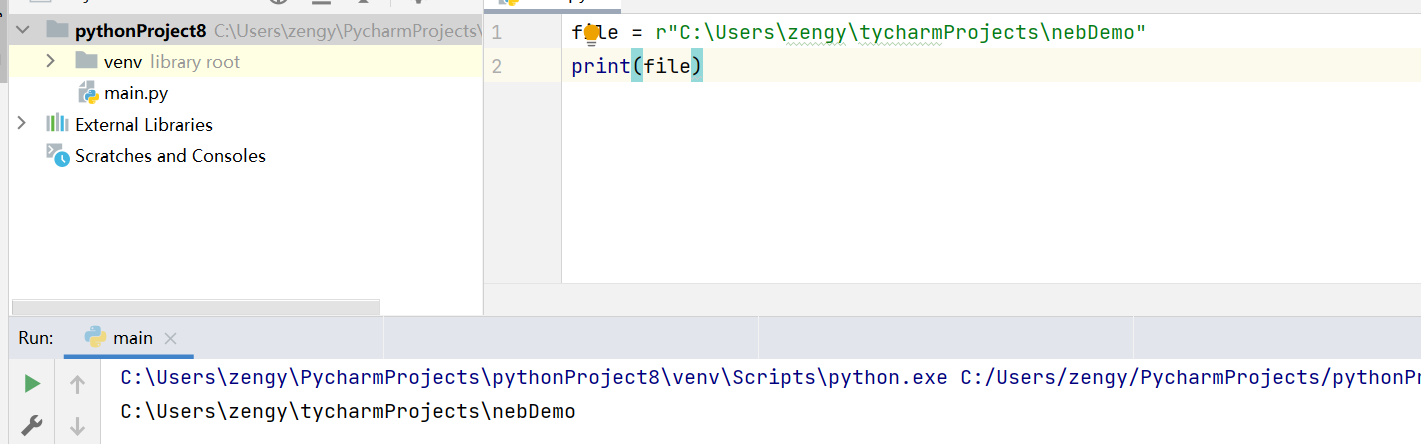
1、路径前添加 r
字符串前添加 r 表示原始字符,去掉 \ 的特殊含义。
file = r"C:\Users\zengy\tycharmProjects\nebDemo"print(file)
2、路径中添加 \
file = "C:\\Users\\zengy\\tycharmProjects\\nebDemo"print(file)

字符串中f引用变量
字符串中使用变量。可以用 f'{}' 格式来引用。
name = "小明"age = 25salary = 28000print(f'我的名字是{name},今年{age}岁,我有着一份月薪为{salary}的工作。')
数字
整数 int 浮点型 float
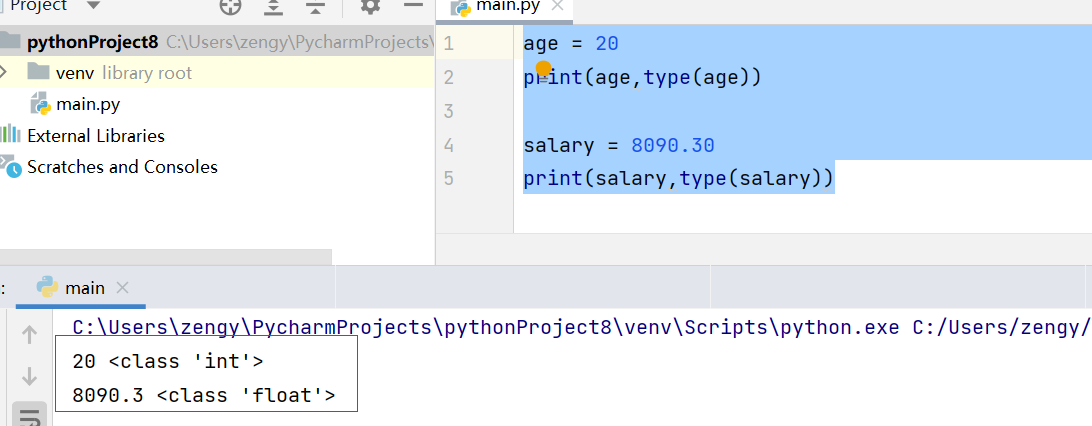
没有小数点就是整数
带有小数点就是浮点型
age = 20print(age,type(age))salary = 8090.30print(salary,type(salary))
数字支持数学运算
| 运算符 | 含义 | |
|---|---|---|
| + | 加法 | |
| - | 减法 | |
| * | 乘法 | |
| ** | 阶乘 | 2**3 2的3次方 |
| / | 除运行 | |
| // | 取商 | 10//3 = 3 |
| % | 取模 (取余数) | 10%3 = 1 |
a = 10b = 3print(a+b)print(a-b)print(a*b)print(a**b) # 10的3次方print(a/b) # 除print(a//b) # 取 商 3print(a%b) # 取余数 1
1373010003.333333333333333531
None 空
在python中,表示数据为空,使用None,类似于数据库中的 Null。
a = Noneprint(a, type(a))

在后面进行上下游传参时候,代码执行之前可以先声明一个空值 None
布尔类型 bool
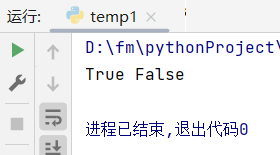
在python中 表示条件为真, 使用 True
表示条件为假 使用 False
a = Trueb = Falseprint(a,b)
| 运算符 | 含义 | |
|---|---|---|
| == | 判断两个值是否相等 | |
| >= | 大于等于 | |
| > | 大于 | |
| < | 小于 | |
| <= | 小于等于 | |
| != | 不等于 |
a = 10b = 20print(a!=b) # 不等于 Trueprint(a==b) # 判断两个值是否相等 False
and 运算
在判断条件的时候,如果多个条件 都是并且 的关系, 使用 and
a = 10b = 20c = 15print(a>b and b>c) # Falseprint(a<b and b>c) # True
or 运算
or 运算的时候, 如果其中有一个条件成立,结果为 True。
所有条件都不成立 结果为False
a = 10b = 20c = 15print(a>b or b>c) # Trueprint(a>b or b<c) # False 两个条件都不成立
列表 list
基本定义
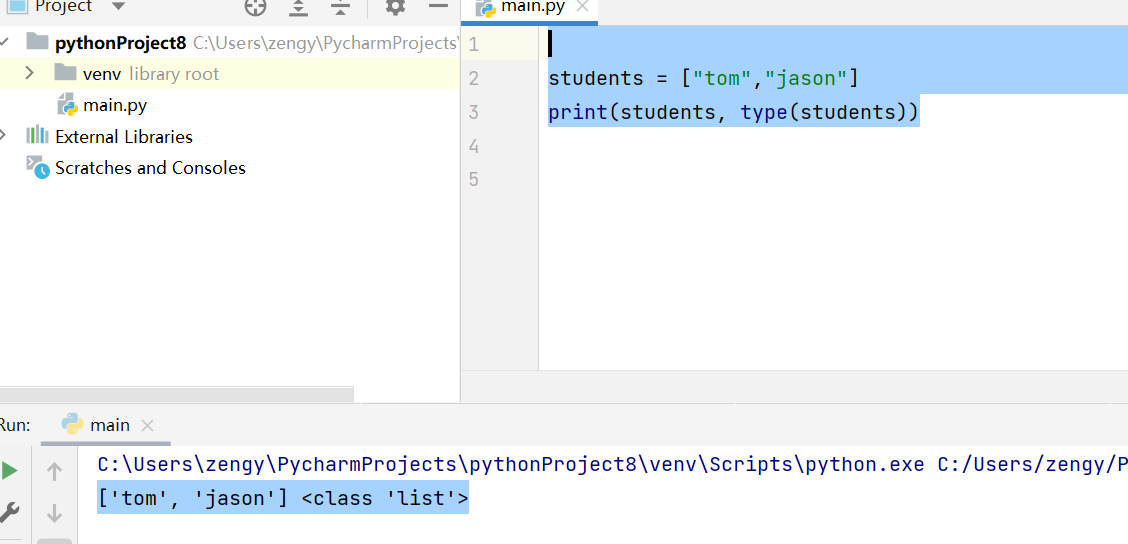
使用 []定义列表。
students = ["tom","jason"]print(students, type(students))
常用方法
append 追加
默认将元素放在列表的最后。
# 定义列表students = ["tom","jason"]print(students, type(students))# 追加一个新的元素students.append("lily")print(students) # ['tom', 'jason', 'lily']
insert 指定位置插入
append 追加的元素默认都是放在列表的最后。 insert可以指定位置插入元素。
# 定义列表students = ["tom","jason"]print(students, type(students))# 追加一个新的元素students.append("lily")print(students) # ['tom', 'jason', 'lily']students.insert(0,"小明") # 0 表示插入位置 第一个,print(students) # ['小明', 'tom', 'jason', 'lily']
插入的时候,需要指定索引位置。表示在索引位置之前插入。
- 0 表示在索引位置为0的之前插入,也就是使用索引值从0 表示在第一个元素之间插入,插入成功之后就是放在第一个位置,1表示在第二个元素之前插入,插入成功之后就放在第2个位置。
- 需要注意 如果往最后一位位置插入,使用append方法
- -1表示在[-1]最后一个元素之前插入,所以插入成功之后放在倒数第二个的位置 ,同样 -2表示插入成功之后会放在倒数第三个位置。
-
extend 添加多个元素
要将多个元素添加进来。 必须将多个值放在 list【】中。
students.extend([‘小红’,’小王’])
**['小红','小王']**自动添加在最后,不支持指定位置。# 定义列表students = ["tom","jason"]print(students, type(students))# 追加一个新的元素students.append("lily")print(students) # ['tom', 'jason', 'lily']students.insert(0,"小明") # 0 表示插入位置 第一个,print(students) # ['小明', 'tom', 'jason', 'lily']students.extend(['小红','小王']) # 添加两个元素。要将添加的值放在列表中print(students) # ['小明', 'tom', 'jason', 'lily', '小红', '小王']
pop 删除元素
pop 默认会将 列表中的最后一个元素删除掉。
pop中传入 指定的位置,可以指定位置删除。 ```python students.pop() # 删除最后一个元素 print(students) # [‘小明’, ‘tom’, ‘jason’, ‘lily’, ‘小红’]
students.pop(0) # 指定索引位置删除。 0 表示第一个, 删除第一个元素。 print(students) # [‘tom’, ‘jason’, ‘lily’, ‘小红’]
<a name="UWlrv"></a>### clear 清空所有元素可以清空所有的元素。```python# 定义列表students = ["tom","jason"]print(students, type(students))# 追加一个新的元素students.append("lily")print(students) # ['tom', 'jason', 'lily']students.insert(0,"小明") # 0 表示插入位置 第一个,print(students) # ['小明', 'tom', 'jason', 'lily']students.extend(['小红','小王']) # 添加两个元素。要将添加的值放在列表中print(students) # ['小明', 'tom', 'jason', 'lily', '小红', '小王']students.pop() # 删除最后一个元素print(students) # ['小明', 'tom', 'jason', 'lily', '小红']students.pop(0) # 指定索引位置删除。 0 表示第一个, 删除第一个元素。print(students) # ['tom', 'jason', 'lily', '小红']students.clear() # 清空所有print(students) # []
sort 列表排序
默认按照升序排序。
如果要进行降序排序, 使用 reverse=True
nums = [0,10,9,8,4]nums.sort() # 默认从小到大进行排序print(nums) # [0, 4, 8, 9, 10]nums.sort(reverse=True) # 进行降序排序print(nums) # [10, 9, 8, 4, 0]
元组 tuple
基本定义
使用小括号 ()来定义。
stus = ('tom','lily')print(stus, type(stus))
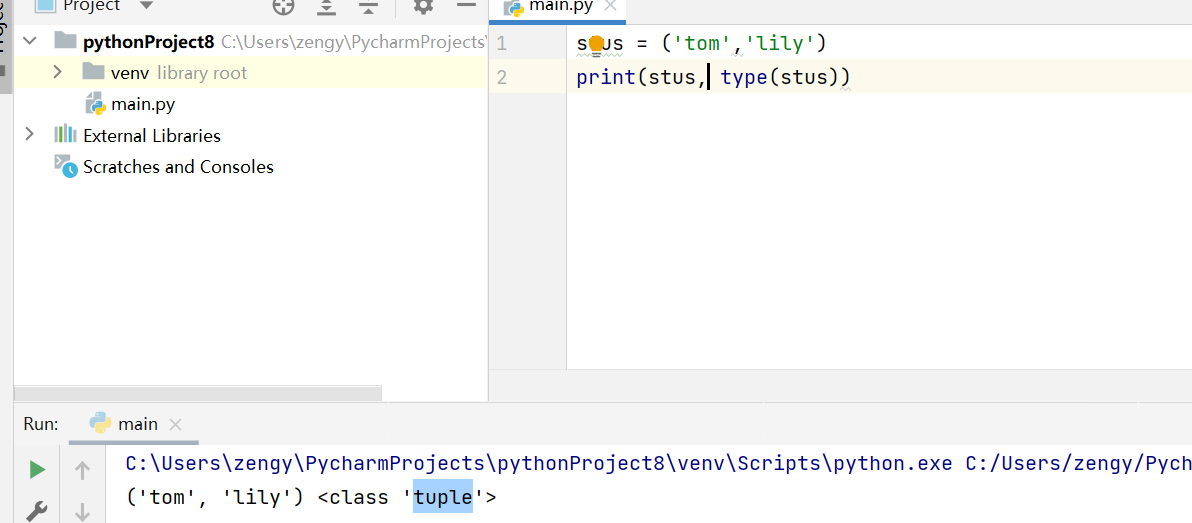
特征
元组中定义好数据不能进行修改。
如果要修改对应的值, 就会报错。
stus = ('tom','lily')print(stus, type(stus))# 定义列表nums = ['tom','lily']nums[0] = "tomson" # 修改列表中的第一个元素值print(nums)# 元组中的值不能进行修改stus[0] = 'tmo' # 这一句会报错
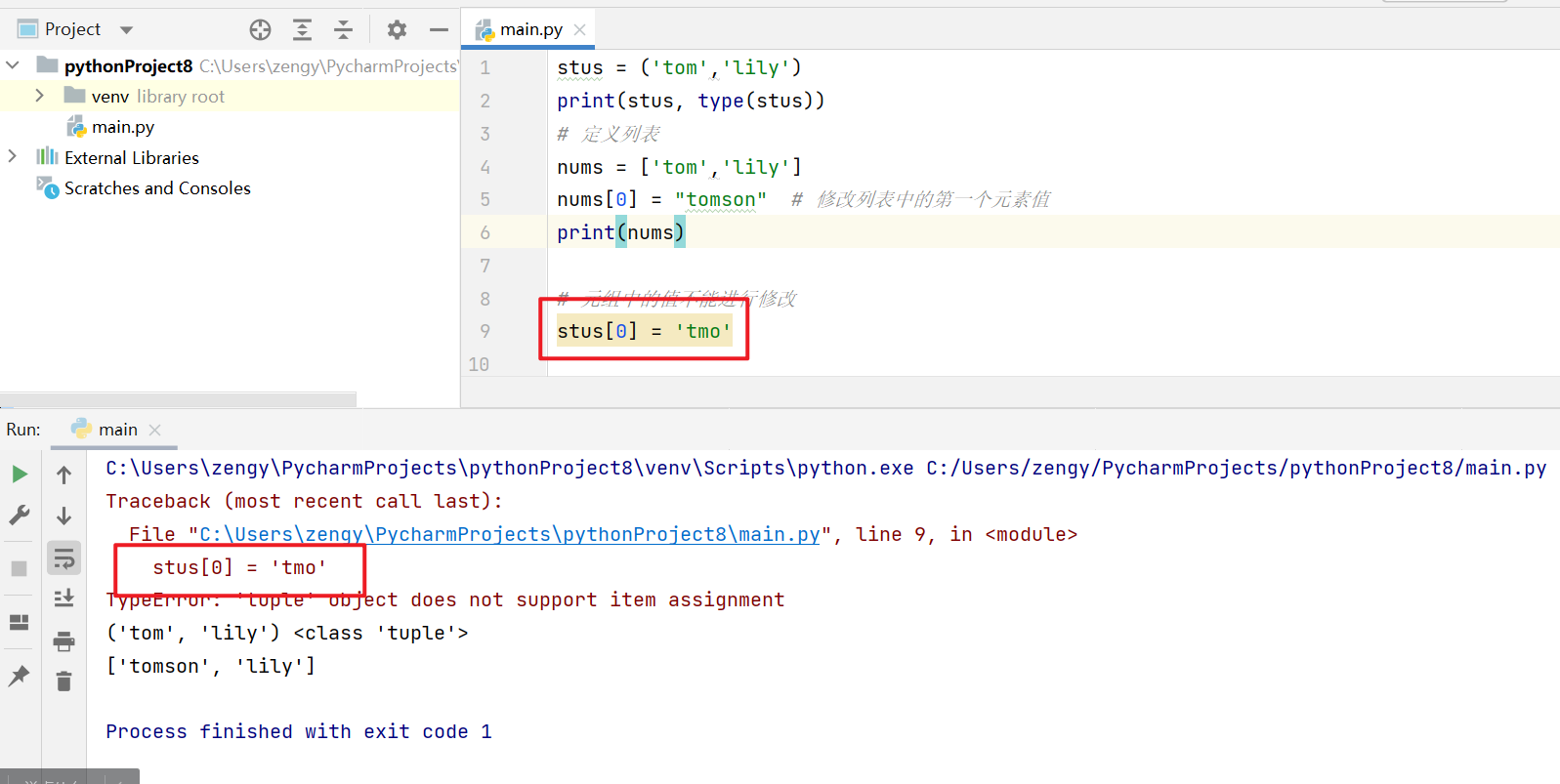
因为元组中定义的值不能进行修改,所以在使用的时候可以一些配置文件(不经常改动数据)定义在元组中。
集合 set
集合中最重要的一个特征是: 数据是无序, 没有重复值。
集合中可以将有重复的数据自动去重。
nums = {'a','c',10,1,2,'a',5,2,3,0,1}print(nums) # {0, 1, 2, 3, 5, 'a', 10, 'c'}
正是因为 set 集合这种类型可以自动将数据去重 这样的功能,所以在使用的时候主要依据这样的特征进行数据处理。
数据没有顺序,所以在集合中不能通过索引位置来访问里面的值。下面的代码会报错。
# 定义一个集合# 集合特征 自动去重 数据没有顺序nums = {'a',0,'a',1,'b',0,100,'c','c'}print(nums) # {0, 1, 'c', 100, 'a', 'b'} 会自动把重复数据去掉# 没有顺序,就不能使用 [0] 索引来访问里面的元素print(nums[0]) # 会报错
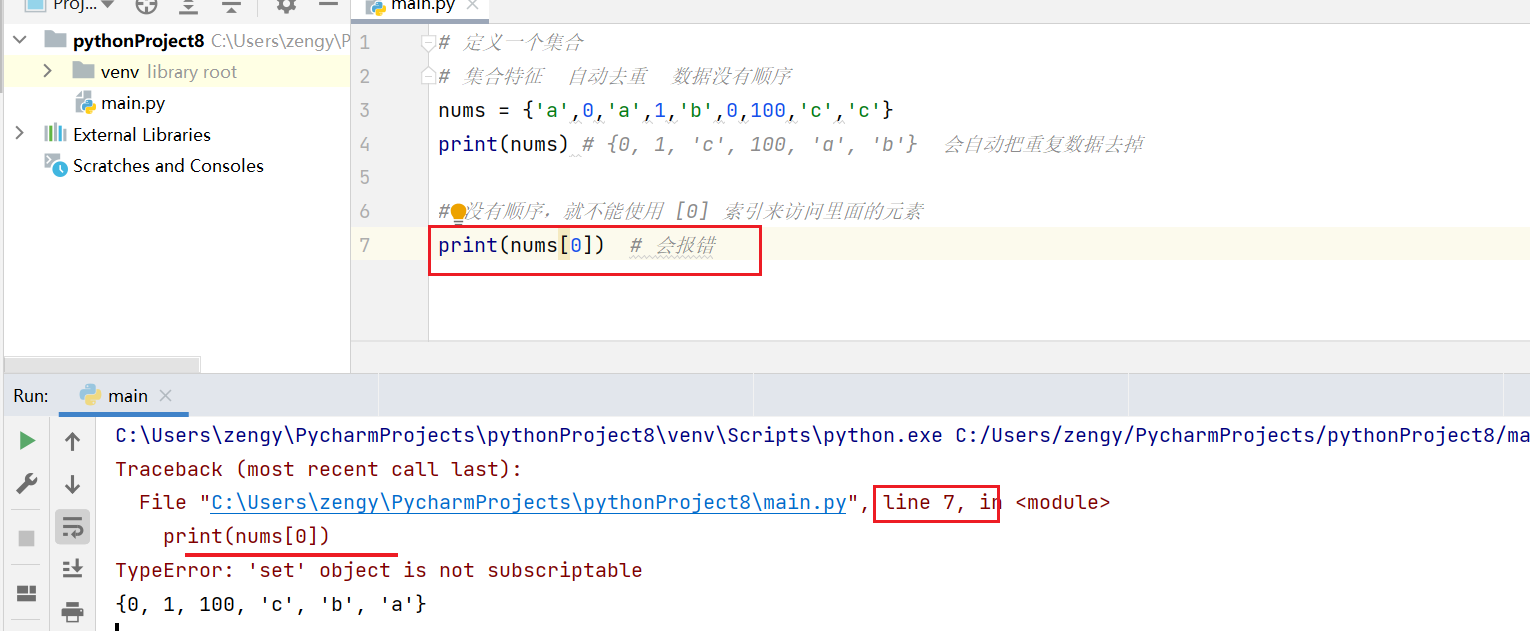
set() 将数据转换为 集合类型
可以使用set()将列表转换为 集合类型进行去重。
下面一个比较经典的问题 可以用到这样的特性。问题是这样的
nums = [100,90,98,0,100,5,10,5] # 定义了一个列表# 将 nums 转换为 set 集合 进行去重a = set(nums)print(a,type(a)) # {0, 98, 100, 5, 10, 90} <class 'set'># 将集合a再转换为列表 赋值给 变量bb = list(a)print(b, type(b)) # [0, 98, 100, 5, 10, 90] <class 'list'># 将列表进行排序b.sort()print(b) # [0, 5, 10, 90, 98, 100]
这个主要就是使用不同数据类型有不同的特性的方式 进行数据类型的转化。
字典 dict
定义字典
使用{k:v} 键值对的方式定义字典类型的数据。
user = {"name":"xiaoming","age":20}print(user, type(user))
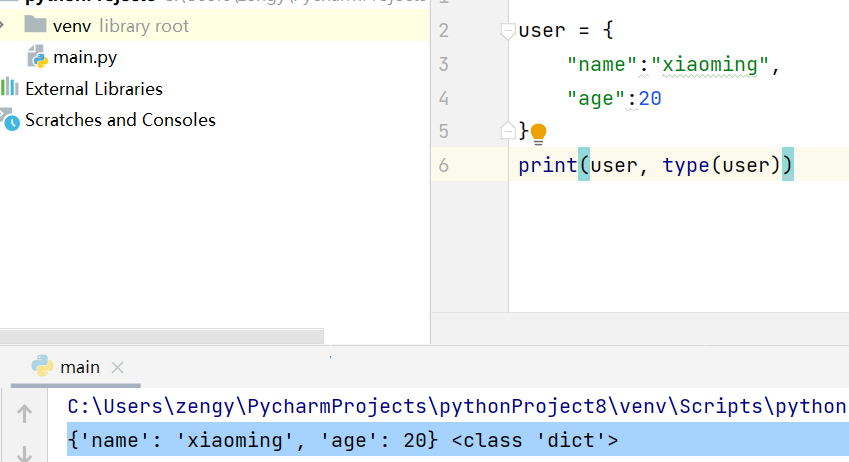
常用方法
修改字段值或添加字段
使用[属性] 直接赋值。
user = {
"name":"xiaoming",
"age":20
}
print(user, type(user))
# 更改 name 对应的值
user['name']="tom"
print(user) # {'name': 'tom', 'age': 20}
# 添加一个新的字段
user["sex"] = "man"
print(user) # {'name': 'tom', 'age': 20, 'sex': 'man'}
keys 获取key
获取到字段中所有的key值
user = {
"name":"xiaoming",
"age":20
}
print(user, type(user))
# 更改 name 对应的值
user['name']="tom"
print(user) # {'name': 'tom', 'age': 20}
# 添加一个新的字段
user["sex"] = "man"
print(user) # {'name': 'tom', 'age': 20, 'sex': 'man'}
k = user.keys()
print(k) # dict_keys(['name', 'age', 'sex'])
values 获取value值
字典中所有的值获取到
user = {
"name":"xiaoming",
"age":20
}
print(user, type(user))
# 更改 name 对应的值
user['name']="tom"
print(user) # {'name': 'tom', 'age': 20}
# 添加一个新的字段
user["sex"] = "man"
print(user) # {'name': 'tom', 'age': 20, 'sex': 'man'}
k = user.keys()
print(k) # dict_keys(['name', 'age', 'sex'])
v = user.values()
print(v) # dict_values(['tom', 20, 'man'])
items 获取对应key,value
kv = user.items()
print(kv) # dict_items([('name', 'tom'), ('age', 20), ('sex', 'man')])
popitem 删除最后一个元素
user = {
"name":"xiaoming",
"age":20
}
print(user, type(user))
# 更改 name 对应的值
user['name']="tom"
print(user) # {'name': 'tom', 'age': 20}
# 添加一个新的字段
user["sex"] = "man"
print(user) # {'name': 'tom', 'age': 20, 'sex': 'man'}
k = user.keys()
print(k) # dict_keys(['name', 'age', 'sex'])
v = user.values()
print(v) # dict_values(['tom', 20, 'man'])
kv = user.items()
print(kv) # dict_items([('name', 'tom'), ('age', 20), ('sex', 'man')])
# 删除最后一个元素
user.popitem()
print(user) # {'name': 'tom', 'age': 20}
pop 删除指定元素
使用这个方法的时候,需要传入指定的key进行删除。 使用的时候必须要传入一个key值。
user = {
"name":"xiaoming",
"age":20
}
print(user, type(user))
# 更改 name 对应的值
user['name']="tom"
print(user) # {'name': 'tom', 'age': 20}
# 添加一个新的字段
user["sex"] = "man"
print(user) # {'name': 'tom', 'age': 20, 'sex': 'man'}
k = user.keys()
print(k) # dict_keys(['name', 'age', 'sex'])
v = user.values()
print(v) # dict_values(['tom', 20, 'man'])
kv = user.items()
print(kv) # dict_items([('name', 'tom'), ('age', 20), ('sex', 'man')])
# 删除最后一个元素
user.popitem()
print(user) # {'name': 'tom', 'age': 20}
# 删除name
user.pop('name')
print(user) # {'age': 20}
clear 清空字典
使用 clear 方法可以将字典中的所有内容清空。
user = {
"name":"xiaoming",
"age":20
}
print(user, type(user))
# 更改 name 对应的值
user['name']="tom"
print(user) # {'name': 'tom', 'age': 20}
# 添加一个新的字段
user["sex"] = "man"
print(user) # {'name': 'tom', 'age': 20, 'sex': 'man'}
k = user.keys()
print(k) # dict_keys(['name', 'age', 'sex'])
v = user.values()
print(v) # dict_values(['tom', 20, 'man'])
kv = user.items()
print(kv) # dict_items([('name', 'tom'), ('age', 20), ('sex', 'man')])
# 删除最后一个元素
user.popitem()
print(user) # {'name': 'tom', 'age': 20}
# 删除name
user.pop('name')
print(user) # {'age': 20}
user.clear()
print(user) # {}

若有收获,就点个赞吧
0 人点赞
