结构化查询语言
SQL(Structured Query Language),中文为结构化查询语言,是一种所有关系型数据库的查询规范。
DDL 数据定义语言
DDL 操作库
db_name泛指数据库库名
建库
-- 创建数据库 (db_name)CREATE DATABASE db_name;-- 不存在创建数据库CREATE DATABASE IF NOT EXISTS db_name;-- 创建数据库并指定字符集CREATE DATABASE db_name CHARACTER SET 字符集;
查库
-- 查看所有的数据库show databases;-- 查看某个数据库的定义信息show create database db_name;
改库
-- 修改数据库默认的字符集ALTER DATABASE db_name DEFAULT CHARACTER SET 字符集;
删库
DROP DATABASE db_name;
用库
-- 查看正在使用的数据库SELECT DATABASE();-- 使用/切换数据库USE db_name;
DDL 操作表
tb_name 泛指表名 | colum_name 泛指字段名 | jdbc_type 泛指字段类型
建表
CREATE TABLE tb_name (colum_name1 jdbc_type1,colum_name2 jdbc_type2);
删表
-- 删除表DROP TABLE tb_name;-- 判断表是否存在,如果存在则删除表DROP TABLE IF EXISTS tb_name;
改表
-- 添加列ALTER TABLE tb_name ADD colum_name jdbc_type;-- 修改类型ALTER TABLE tb_name MODIFY colum_name jabc_type_new;-- 修改列名ALTER TABLE tb_name CHANGE colum_name colum_name_new jdbc_type;-- 删除列ALTER TABLE tb_name DROP colum_name;-- 修改表名RENAME TABLE tb_name TO tb_name_new;-- 修改字符集ALTER TABLE tb_name character set 字符集;
数据类型
| 分类 | 类型名称 | 类型说明 |
|---|---|---|
| 整数 | tinyInt | 微整型:很小的整数(占 8 位二进制) |
| smallint | 小整型:小的整数(占 16 位二进制) | |
| mediumint | 中整型:中等长度的整数(占 24 位二进制) | |
| int(integer) | 整型:整数类型(占 32 位二进制) | |
| 小数 | float | 单精度浮点数,占 4 个字节 |
| double | 双精度浮点数,占 8 个字节 | |
| 日期 | time | 表示时间类型 |
| date | 表示日期类型 | |
| datetime | 同时可以表示日期和时间类型 | |
| 字符串 | char(m) | 固定长度的字符串,无论使用几个字符都占满全部,M 为0~255 之间的整字符串数 |
| varchar(m) | 可变长度的字符串,使用几个字符就占用几个,M 为 0~65535 之间的整数 | |
| 大二进制 | tinyblob|Big Large|Object |
允许长度 0~255 字节 |
| blob | 允许长度 0~65535 字节 | |
| mediumblob | 允许长度 0~167772150 字节 | |
| longblob | 允许长度 0~4294967295 字节 | |
| 大文本 | tinytext | 允许长度 0~255 字节 |
| text | 允许长度 0~65535 字节 | |
| mediumtext | 允许长度 0~167772150 字节 | |
| longtext | 允许长度 0~4294967295 字节 |
-- 查看某个数据库中的所有表SHOW TABLES;-- 查看表结构DESC tb_name;describe tb_name;show columns from tb_name;explain tb_name;-- 查看创建表的 SQL 语句SHOW CREATE TABLE tb_name;-- 快速创建一个表结构相同的表CREATE TABLE tb_name_new LIKE tb_name;
DML 数据操纵语言
tb_name 泛指表名 | colum_name 泛指字段名 | colum_value 泛指字段值
插数据
插数据-- 插入记录INSERT [INTO] tb_name [colum_name ] VALUES (colum_value)-- 插入全部字段-- 所有的字段名都写出来INSERT INTO tb_name (colum_name 1, colum_name 2, colum_name 3…) VALUES (colum_value 1, colum_value 2, colum_value 3);-- 不写字段名INSERT INTO tb_name VALUES (colum_value 1, colum_value 2, colum_value 3…);-- 插入部分数据INSERT INTO tb_name (colum_name 1, colum_name 2, ...) VALUES (colum_value 1, colum_value 2, ...);# 注:没有添加数据的字段会使用 NULL
注意事项:
- 插入的数据应与字段的数据类型相同
- 数据的大小应在列的规定范围内,例如:不能将一个长度为 80 的字符串加入到长度为 40 的列中。
- 在 values 中列出的数据位置必须与被加入的列的排列位置相对应。在 mysql 中可以使用 value,但不建议使 用,功能与 values 相同。
- 字符和日期型数据应包含在单引号中。MySQL 中也可以使用双引号做为分隔符。
- 不指定列或使用 null,表示插入空值。
改数据
-- 不带条件修改数据UPDATE tb_name SET colum_name = colum_value-- 带条件修改数据UPDATE tb_name SET colum_name = colum_value WHERE colum_name = ?
删数据
-- 不带条件删除数据DELETE FROM tb_name;-- 带条件删除数据DELETE FROM tb_name WHERE colum_name = colum_value;-- 使用 truncate 删除表中所有记录TRUNCATE TABLE tb_name;
DQL 数据查询语言
tb_name 泛指表名 | colum_name 泛指字段名 | tb 泛指表别名 | cn 泛指列别名 | num 泛指固定值
-- 简单查询-- 使用*表示所有列SELECT * FROM tb_name;-- 查询指定列SELECT colum_name1, colum_name2, colum_name3, ... FROM tb_name;-- 指定列的别名进行查询-- 对列指定别名SELECT colum_name1 AS cn_1, colum_name2 AS cn_2, ... FROM tb_name;-- 对列和表同时指定别名SELECT tb_.colum_name1 AS cn_1, tb_.colum_name2 AS cn_1, ... FROM tb_name AS tb_;-- 清除重复值SELECT DISTINCT colum_name FROM tb_name;-- 查询结果参与运算-- 某列数据和固定值运算SELECT colum_name1 + num FROM tb_name;-- 某列数据和其他列数据参与运算SELECT colum_name1 + colum_name2 FROM tb_name;-- 条件查询SELECT * FROM tb_name WHERE colum_name1 = ?-- 运算符SELECT * FROM tb_name WHERE colum_name1 = | > | >= | < | <= | <> ?-- 逻辑运算符SELECT * FROM tb_name WHERE colum_name = ? AND | OR colum_name = ?-- IN 关键字SELECT * FROM tb_name where colum_name IN ('?', '?')-- 范围查询SELECT * FROM tb_name where colum_name between ? and ?-- LIKE 关键字-- 通配符 (% | _)SELECT * FROM tb_name where colum_name like '_?%'-- 排序-- 单列排序SELECT * FROM tb_name order by colum_name ASC | DESC-- 组合排序SELECT * FROM tb_name order by colum_name1 ASC | DESC ,colum_name2 ASC | desc-- 聚合函数SELECT count(*) | sum(colum_name) | max(colum_name) | min(colum_name) | avg(colum_name) FROM tb_name-- 分组SELECT * FROM tb_name group by colum_name-- limit 语句SELECT * FROM tb_name limit ? ?
DCL 数据控制语言
-- 创建用户create user 'username'@'hostname' identified by password;-- 用户授权grant authority1, authority2 ... on database_name.table_name to 'username'@'localname';-- 撤销权限revoke authority1, authority2 ... on database_name.table_name to 'username'@'localname';-- 查看权限show grant for 'username'@'localname'-- 删除用户drop user 'username'@'localname'-- 修改密码-- 管理员mysqladmin -uroot -p password new_password-- 普通用户set password for 'username'@'localname' = password('new_password');
数据库设计
范式
分类
- 第一范式(1NF)
- 第二范式(2NF)
- 第三范式(3NF)
- 巴斯-科德范式(BCNF)
- 第四范式(4NF)
- 第五范式(5NF,完美范式)
三大范式
1NF
数据库表的每一列都是不可分割的原子数据项2NF
在满足第一范式的前提下,表中的每一个字段都完全依赖于主键3NF
在满足第二范式的前提下,表中的每一列都直接依赖于主键,而不是通过其它的列来间接依赖于主键小结: 1NF 原子性:表中每列不可再拆分 2NF 不产生局部依赖,一张表只描述一件事情 3NF 不产生传递依赖,表中每一列都直接依赖于主键。而不是通过其它列间接依赖于主键
优点|缺点
优点
- 范式的更新操作通常比反范式要快
- 当数据较好的范式化时,就只有很少或没有重复的数据,所有修改的数据更少
- 范式的表通常更小,可以更好的放进内存里,所以执行操作会很快
- 很少有多余的数据意味着检索表时更少需要DISTINT 或 GROUP BY 字句
数据库事务
事务指的是一组原子操作,要么全部成功,要么全部失败,旨在保持数据的一致性。
操作类型
手动事务
start transaction; -- 开启事务commit; -- 提交事务rollback; -- 回滚事务
使用过程
执行成功: 开启事务 > 执行多条 SQL 语句 > 成功提交事务
执行失败: 开启事务 > 执行多条 SQL 语句 > 事务的回滚 
自动事务
查看
select @@autocommit;@@表示全局变量,1 表示开启,0 表示关闭
取消
事务原理
事务开启之后, 所有的操作都会临时保存到事务日志中, 事务日志只有在得到 commit 命令才会同步到数据表 中,其他任何情况都会清空事务日志(rollback,断开连接)
原理图
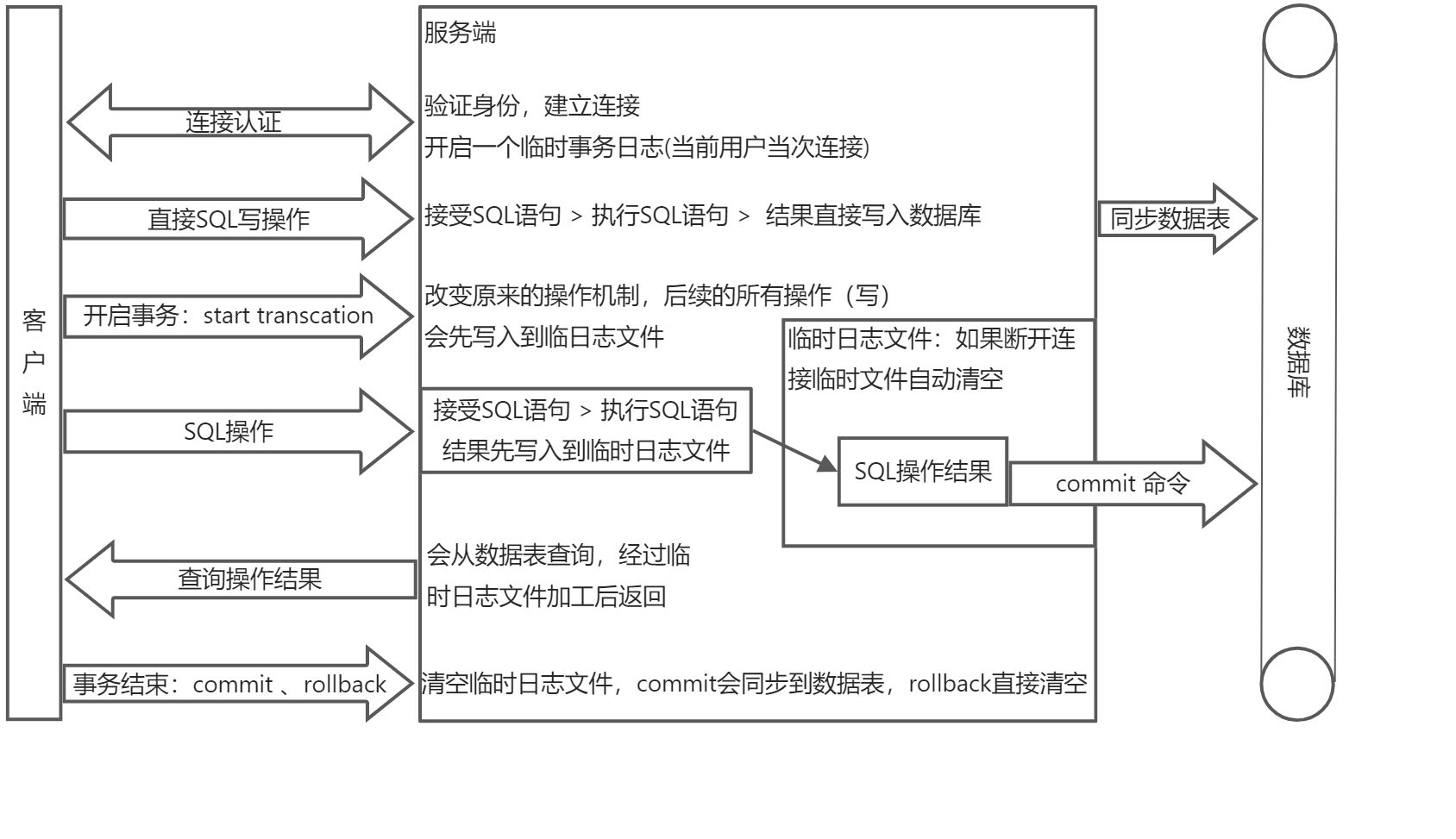
事务步骤
- 客户端连接数据库服务器,创建连接时创建此用户临时日志文件
- 开启事务以后,所有的操作都会先写入到临时日志文件中
- 所有的查询操作从表中查询,但会经过日志文件加工后才返回
- 如果事务提交则将日志文件中的数据写到表中,否则清空日志文件。
回滚点
概念
在某些成功的操作完成之后,在当前成功的位置设置一个回滚点,后续操作失败后返回这位置,而不是事务开始的位置,这个点称之为回滚点。操作命令
设置回滚点 savepoint 名字 回到回滚点 rollback to 名字
隔离级别
四大特性(ACID)
- 原子性(Atomicity) 每个事务都是一个整体,不可再拆分,事务中所有的 SQL 语句要么都执行成功, 要么都失败
- 一致性(Consistency) 事务在执行前数据库的状态与执行后数据库的状态保持一致
- 隔离性(Isolation) 事务与事务之间不应该相互影响,执行时保持隔离的状态
持久性(Durability) 一旦事务执行成功,对数据库的修改是持久的。就算关机,也是保存下来的
并发访问出现的问题
脏读 一个事务读取到了另一个事务中尚未提交的数据
- 不可重复读 一个事务中两次读取的数据内容不一致,要求的是一个事务中多次读取时数据是一致的,这是事务 update 时引发的问题
- 幻读 一个事务中两次读取的数据的数量不一致,要求在一个事务多次读取的数据的数量是一致 的,这是 insert 或 delete 时引发的问题
隔离级别
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复度 | 幻读 | | —- | —- | —- | —- | —- | —- | | 1 | 读未提交 | read uncommitted | Y | Y | Y | | 2 | 读已提交 | read committed | N | Y | Y | | 3 | 可重复读 | repeatable read | N | N | Y | | 4 | 串行化 | serializable | N | N | N |
注:隔离级别越高,性能越差,安全性越高
操作命令
select @@tx_isolation; -- 查询隔离级别set global transaction isolation level ?; -- 设置隔离级别 (? 指代的是隔离级别英文)

若有收获,就点个赞吧
0 人点赞
