指针的作用
- 节省内存空间,提高程序执行效率
- 间接访问与修改变量的值
指针的运算和多级指针
修改变量的值
package mainimport "fmt"func main() {var intVariables int = 100fmt.Printf("intVariables的值=%d,地址=%v\n", intVariables, &intVariables)var pointerVariables *int = &intVariablesfmt.Printf("pointerVariables=%d,地址=%v\n", pointerVariables, &pointerVariables)// 修改变量的值*pointerVariables = 200fmt.Println(*pointerVariables)}
值类型
- 整型
- 浮点型
- bool
- 数组
- string
值类型在栈中进行分配
引用类型
- 指针
- slice
- map
- chan
- interface
引用类型在堆中进行分配
当我们定义一个指针的时候,并未分配任何变量,它的默认值是nil,如果通过*变量 = 10来赋值,会报错。
指针1
var c int = 2var pc *int = &c // 定义一个指针 指向 c变量的地址*pc = 3 // 将c的指向的内容更改为3fmt.Println(c) // 最后输出值为3
go的指针不能运算
go的参数传递
go语言仅仅是只有值传递这样的。但是我们可以通过指针的方式来进行引用传递。
下面通过一个C的一个代码来进行分析
void pass_by_val(int a) {a++;}void pass_by_ref(int& a) {a++;}int main() {int a = 3;pass_by_val(a);printf("After pass_by_val: %d\n", a); // 3pass_by_ref(a);printf("After pass_by_ref: %d\n", a); // 4}
pass_by_val是进行了值传递,将main函数内的a变量重新拷贝了一份传给函数。所以哪怕在函数中进行了改变,那也只是改变了拷贝的一个a的变量。
pass_by_ref是进行引用传递,将main函数内的a变量的地址赋给了函数 ,所以在函数中对a的操作都会影响到原来的a变量。
在Go语言中,它仅仅只有一种值传递的方式
但是呢,值传递意味着需要重新拷贝一份资源,是否会影响性能呢?所以就需要使用值传递和指针来进行配合。
参数传递
值传递
var a intfunc f(a int)
指针来实现引用传递的效果
var a intfunc f(pa *int)
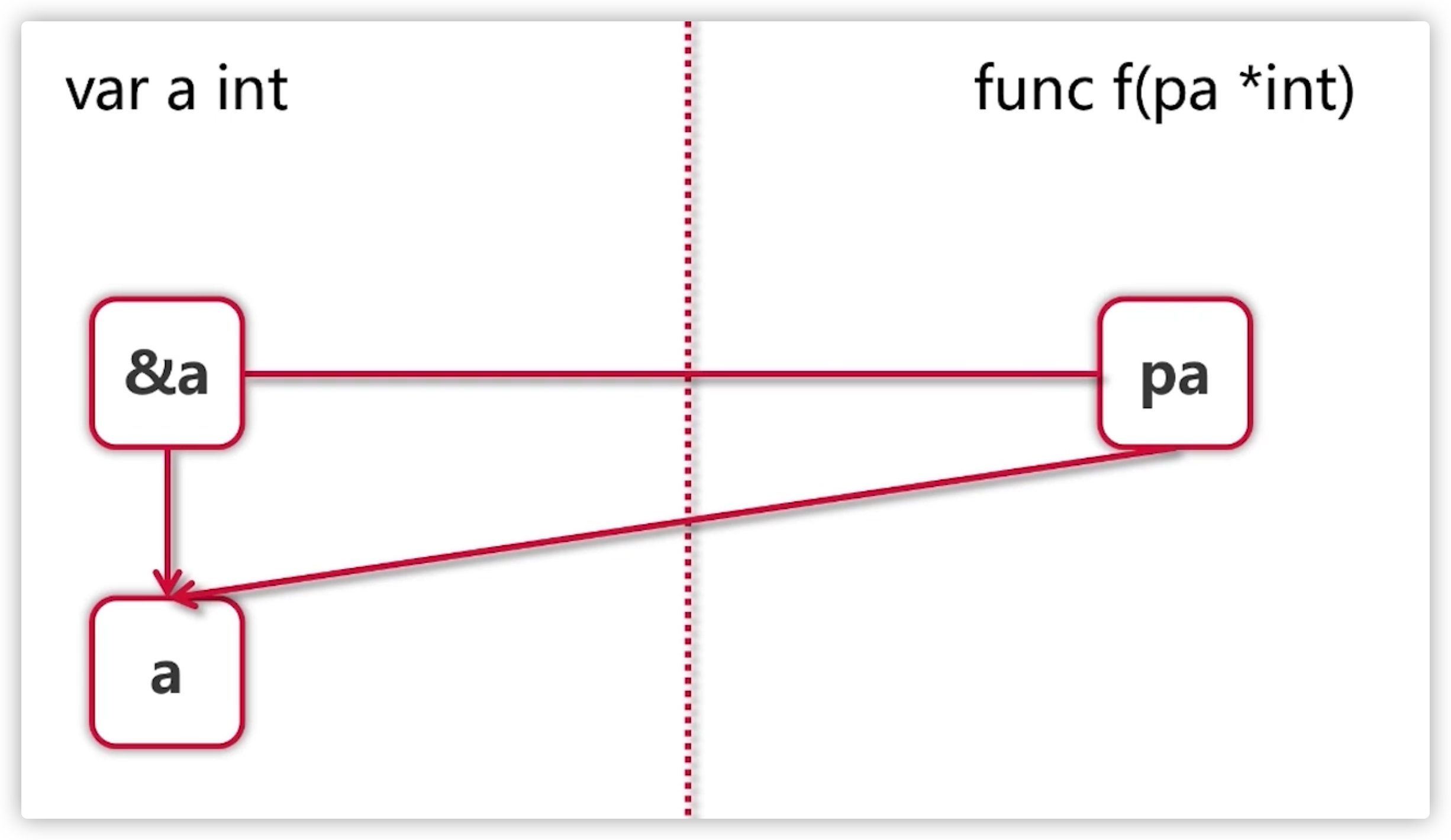
传递对象
var cache Cachefunc f(cache Cache)
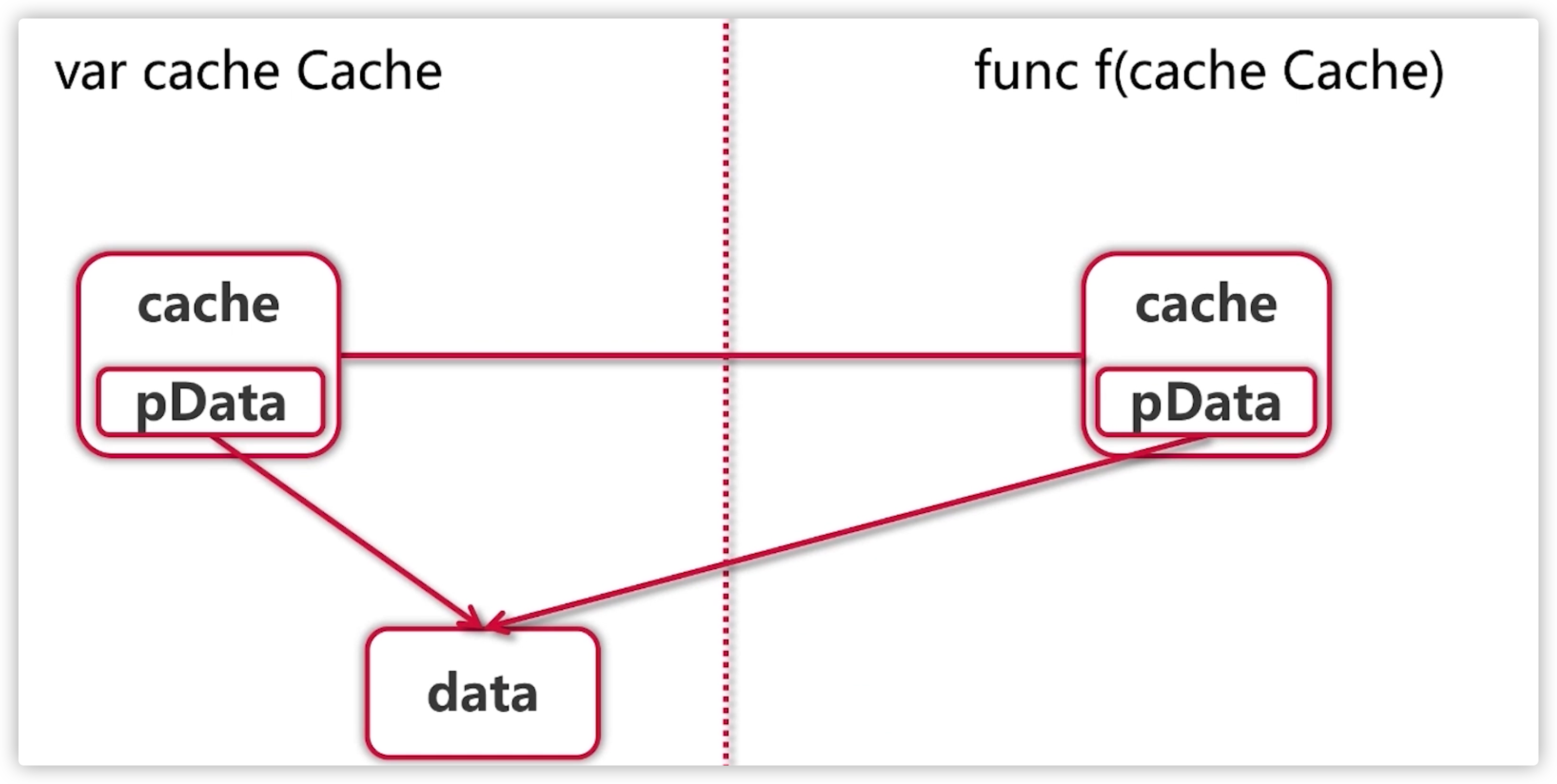
这样也是一种值传递的方式,只不过cache数据包含了一个指针,拷贝了一份指针的数据,指针都是指向一个数据包。
下面我们看一个,两个变量交换值的案例:
func swap(a, b int) {b, a = a, b}func main() {a, b := 3, 4swap(a, b)fmt.Println(a, b) // 3, 4}
很明显,这是值传递,就是将a和b拷贝了一份,并不会影响原来的值,所以最后还是3和4。
使用指针
func swap(a, b *int) {*b, *a = *a, *b}func main() {a, b := 3, 4swap(&a, &b)fmt.Println(a, b) // 4, 3}
这里将变量的地址传参,就可以进行替换。
但是对于此,我们何必要写成使用指针呢,我们直接使用函数将对应的两个值换个位置返回不就得了
func swap(a, b int) (int ,int) {return b, a}func main() {a, b := 3, 4a, b = swap(a, b)fmt.Println(a, b) // 4, 3}
这样定义才是更好的。

若有收获,就点个赞吧
0 人点赞
