一条SQL语句在mysql中是如何执行的 ?
首先来看下mysql的组成部分

大体上,mysql可以分为server层和存储引擎层两部分。
server层:
不管是使用存储引擎,server层都是公用的,作为重点介绍。
引擎层:
InnoDB:平常在企业级应用使用InnoDB较为广泛,绝大多数使用InnoDB
MyISAM: 一些老版本的java-web应用,比如PHP开发的CMS系统,有可能使用到MyISAM作为存储引擎
内存型存储引擎:基于内存的存储引擎。
SERVER层:
1.连接器
在mysql中会专门有一个连接器去负责建立与客户端的连接,其底层是基于tcp套接字,它负责管理连接的建立与权限校验,包括校验用户的权限是否允许被登陆,用户的密码是否正确等等
连接的方式有多种,比如JDBC, Navicat…..
首先启动mysql,尝试创建连接
创建连接的过程
1.首先连接器会获取到输入的host(如果没有host则默认是本地连接)还有user,以及输入的pwd,去系统库的user表
做校验,首先根据用户名去查出来pwd及host
2.校验用户输入的username和pwd是不是相匹配,以及能不能在所在的地址进行登录,如果校验通过,允许登录
3.在建立连接之后,连接器还会干一件事情,每个连接器连到服务端之后,都会开辟一块专属于这个连接会话的存 储空间,叫session,这个连接所执行的很多操作所使用的的内存空间,都在这里
4.会把用户的权限,全都放进刚刚开辟的这个内存空间中来,包括当前登录的用户信息也会存放进来,如下图所示
会把这一行先load到内存中来.
1. 如果用户名或密码不对,你就会收到一个”Access denied for user”的错误,然后客户端程序结束执行。
2. 如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权 限。 这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权 限。
修改完成后,只有再新建的连接才会使用新的权限设置。用户的权限表在系统表空间的mysql的user表中。
2.查询缓存
查询缓存这个功能很鸡肋,在5.6+和5.7+的版本中保留,到了8+以后的版本这个功能就被取消了,为啥呢?
因为查询缓存往往弊大于利。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。 因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率 会非常低。 一般建议大家在静态表里使用查询缓存,什么叫静态表呢?就是一般我们极少更新的表。比如,一个系统配置表、字典 表,权限结构表,那这张表上的查询才适合使用查询缓存。好在 MySQL 也提供了这种“按需使用”的方式。可以将my.cnf参数 query_cache_type 设置成 DEMAND。
打开my.cnf
#query_cache_type = 2
#query_cache_type有3个值 0代表关闭查询缓存OFF,1代表开启ON,2(DEMAND)代表当sql语句中有 SQL_CACHE关键词时才缓存
这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定,像下面这个语句一样:
mysql> select SQL_CACHE * from test where ID=5;
查看当前mysql实例是否开启缓存机制
mysql> show global variables like “%query_cache_type%”;
监控查询缓存的命中率:
mysql> show status like’%Qcache%’; //查看
缓存返回字段的相关含义
Qcache_free_blocks:表示查询缓存中目前还有多少剩余的blocks,如果该值显示较大,则说明查询缓存中的内存碎片 过多了,可能在一定的时间进行整理。
Qcache_free_memory:查询缓存的内存大小,通过这个参数可以很清晰的知道当前系统的查询内存是否够用,是多 了,还是不够用,DBA可以根据实际情况做出调整。
Qcache_hits:表示有多少次命中缓存。我们主要可以通过该值来验证我们的查询缓存的效果。数字越大,缓存效果越 理想。
Qcache_inserts: 表示多少次未命中然后插入,意思是新来的SQL请求在缓存中未找到,不得不执行查询处理,执行 查询处理后把结果insert到查询缓存中。这样的情况的次数,次数越多,表示查询缓存应用到的比较少,效果也就不理 想。当然系统刚启动后,查询缓存是空的,这很正常。
Qcache_lowmem_prunes:该参数记录有多少条查询因为内存不足而被移除出查询缓存。通过这个值,用户可以适当的 调整缓存大小。
Qcache_not_cached: 表示因为query_cache_type的设置而没有被缓存的查询数量。
Qcache_queries_in_cache:当前缓存中缓存的查询数量。
Qcache_total_blocks:当前缓存的block数量。
3.分析器
词法分析器
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。 分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是 什么,代表什么。 MySQL 从你输入的”select”这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符 串“ID”识别成“列 ID”。 做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句 是否满足 MySQL 语法。 如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,比如下面这个语句 from 写成了 “rom”。如下图所示
词法分析器大概分为6步完成对一条sql语句的分析
1.词法分析
2.语法分析
3.语义分析
4.构造执行树
5.生成执行计划
6.执行
词法分析器类似于毕业论文的查重机制,先将论文中的词组一个个的拆分出来,形成一个个的词源,然后带入词库进行一一比对,以此来达到查重的目的,现在我们来看下词法分析器大体的执行过程
最后分析完毕,到达优化器。
4.优化器
经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。比如你执行下面这样的语句,这个语句是执行两个表的 join:
1 mysql>
SELECT * FROM
customer c JOIN repayment_plan r
USING(customer_id)
WHERE
c.customer_id=’6d36f2d5-01ac-11e8-8f73-00163e035a4f’
AND
r.customer_id=’6d36f2d5-01ac-11e8-8f73-00163e035a4f’;
既可以先从表 customer里面取出 customer_id=’’的记录值,再根据 cutsomer_id 值关联到表 repayment_plan,再判断 repayment_plan里面 name的值是否等于 #{customerId}。
也可以先从表 repayment_plan里面取出 customer_id=’’ 的记录值,再根据customer_id 值关联到 customer表,再判断 custsomer表 里面customer_id的值是否等于 #{customerId}。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。如果你还有一些疑问,比如优化器是怎么选择索引的,有没有可能选择错等等。可以使用EXPLAIN看看最终的执行效率。
以上就是一条SQL在mysql中执行的大概过程
bin-log归档
删库是不需要跑路的,因为我们的SQL执行时,会将sql语句的执行逻辑记录在我们的bin-log当中。
binlog是Server层实现的二进制日志,他会记录我们的cud操作。Binlog有以下几个特点:
1、Binlog在MySQL的Server层实现(引擎共用)
2、Binlog为逻辑日志,记录的是一条语句的原始逻辑
3、Binlog不限大小,追加写入,不会覆盖以前的日志
如果,我们误删了数据库,可以使用binlog进行归档!要使用binlog归档,首先我们得记录binlog,因此需要先开启MySQL的binlog功能。
配置my.cnf
1 配置开启binlog
2 log‐bin=/usr/local/mysql/data/binlog/mysql‐bin
3 注意5.7以及更高版本需要配置本项:server‐id=123454(自定义,保证唯一性);
4 #binlog格式,有3种statement,row,mixed
5 binlog‐format=ROW
6 #表示每1次执行写入就与硬盘同步,会影响性能,为0时表示,事务提交时mysql不做刷盘操作,由系统决定
7 sync‐binlog=1
binlog命令
mysql> show variables like ‘%log_bin%’; 查看bin‐log是否开启
mysql> flush logs; 会多一个最新的bin‐log日志
mysql> show master status; 查看最后一个bin‐log日志的相关信息
mysql> reset master; 清空所有的bin‐log日志
查看binlog内容
mysql> /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.
000001 查看binlog内容
用bin-log进行删库恢复
现在我们来执行truncate customer; 这条命令,将一个有2.7万条记录的cutsomer表删除
来看下删完之后的效果,显示表中已经没有数据了
从bin‐log恢复数据
恢复全部数据 : /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.000001 |mysql ‐uroot ‐p repay(数据库名)
恢复指定位置数据: /usr/local/mysql/bin/mysqlbinlog ‐‐start‐position=”19474059” ‐‐stop‐position=”37559051” /usr/local/mysql/var/mysql‐bin.000002 |mysql ‐uroot ‐p repay(数据库)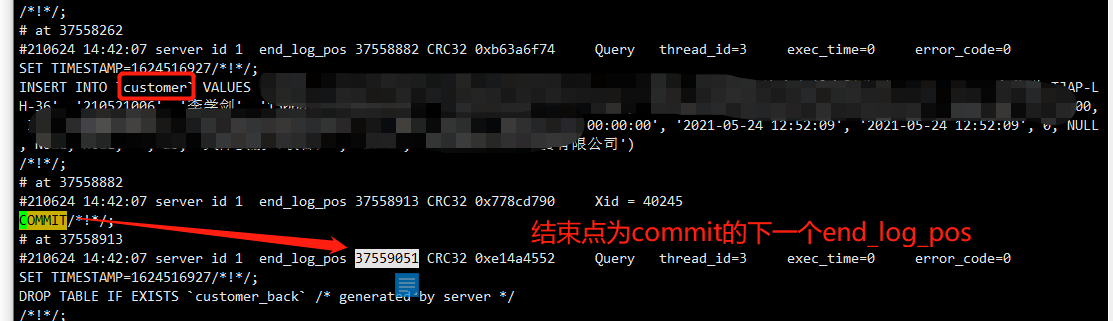
[root@localhost ~]# /usr/local/mysql/bin/mysqlbinlog —start-position=19474059 —stop-position=37559051 —database=repay /usr/local/mysql/var/mysql-bin.000002 | /usr/local/mysql/bin/mysql -uroot -p123456 
恢复完成后查看

若有收获,就点个赞吧
0 人点赞
