0 Recap on Probability and Statistics
参考: probability_1.pdf
Chapter 1 Probability Theory.pdf
0.1 概率空间
我们用
表示一个概率空间, 下面我们介绍几个概念
样本点和样本空间
: 样本点
: 所有可能发生的结果的集合,也叫所有样本点的集合,也称样本空间

sigma 代数
0.2 单变量概率分布
参考: probability_1.pdf
Chapter 1 Probability Theory.pdf
随机变量
离散型变量概率分布
PMF

连续性变量概率分布
CDF


0.3 多变量概率分布
离散型变量
PMF

条件概率

连续变型量
CDF



条件概率

0.4 期望与方差
离散型

连续型

混合型

多变量条件期望

全概率公式

1 Self-Information
定义
Self-Information代表了一个离散的概率事件所含的信息, 单位是bits假设我们有一个样本空间,里面是
4位二进制数的排列同时我们有
, 包含所有可能发生的事件的集合 假定现在我们有一个事件
, 我们想求它的
Self-Information我们可以定义一个函数, 输入一个事件,输出这个事件所含的
Self-Information,为了方便起见,我们选取底数是
2的对数比如我们的事件
是: 序列号形如
, 则这个事件发生的概率是
则这个事件
对应的
Self-Information就是完成这个计算的
python代码如下:

PyTorch实现
import torchdef selfInformation(p):"""Input a probability:return: The value of self-information"""return torch.log2(torch.tensor(p)).item()if __name__ == "__main__":print(selfInformation(1/16)) # -4.0
2 Entropy
Self-Information只能描述一个离散的事件所含的信息,但我们想要推广到任何随机变量(离散和连续)
定义
对于一个随机变量
, 它的
PMF或者,我们定义它的熵是
如果
是一个离散型随机变量(假设可能的取值为
):
如果
是一个连续性随即变量:

PyTorch实现
def entropy(p):"""Compute the Entropy For a discrete random variable:param p: Probability Vector, summing up to 1.0:return: Shannan Entropy"""entropy = - p * torch.log2(p)# Operator `nansum` will sum up the non-nan numberout = nansum(entropy)return outentropy(torch.tensor([0.1, 0.5, 0.1, 0.3])) # tensor(1.6855)
由来⭐
问1 : 为什么是
**log(p(x))**? 答: 假设, 那么采用
就能使得
,每个
彼此独立,共同为
贡献信息量, 这其实也很符合直觉,因为
,所以
,也就是说
,概率越小,此事件的信息量就越大
问2: 为什么我们需要对
**log(p(x))**取负? 答: 由第一问中的分析,因为entropy也是信息的一种,我们的目标是让这个信息熵对于一个小概率事件的值更大且为正。因为函数在
上是单调递增且恒为负的,所以取一个负号可以完成这个目标
问3: 为什么求
的时候出现了
**Expectation**? 答: 当我们看到一个随机变量的实现时,比如,, 我们把
当做一个离散的事件来看,我们要去求
这个事件的
Self-Information。但是我们不满足于这一次随机变量的观测,因为
还可能取其他的值构成其他的事件。所以,我们想要多次观测取平均,于是期望的概念就被运用在这里了。假设
是一个离散的随机变量, 可能的取值是
, 各自的概率是
,我们对这个随机变量
在各个取值下的
**Self-Information**的和, 得到的就是离散条件下的**Entropy**:

性质
一下性质假设
是一个随机变量,且
, 概率密度函数是
(离散) 或者
(连续), 但我们统一概率密度函数为
的正负性
- 对于所有的离散型随机变量
,
- 对于连续性随机变量
,
可能为负
的最小值
- 假设我们有两个概率测度(
Probability Measure)和
, 对应的概率密度函数是
和
- 换句话说,
给出了一个描述随机变量的最小的信息位(
information bits)的概率测度,对于一个随机变量
, 其他任何的概率测度
得到的信息量都会比用
本就服从的概率分布的测度
要大
的最大值
- 如果
, 且不同的事件发生的概率相近或者相等,我们的
的值就越大
- 对于离散型变量
,样本空间是
且定义事件
,
- 对于连续性变量
,如果它服从均匀分布,他的
相较于其他分布来说更大





3 Mutual Information
定义
前文我们探究了在单变量下的随机变量的信息量, 下文将展开对多变量条件下的随机变量的信息量的分析 我们着重于探究:
- 一组变量
的熵是多大?
- 一组变量
的熵相比于
和
各自的熵的总和的关系?
3.1 Joint Entropy
定义
我们假设有两个随机变量
属于同一个概率测度空间
- 对两个连续型变量,
- 对两个离散型变量,
类似的,我们定义

就相当于是
中包含的信息,有点类似于取并集的感觉



离散型变量
:::success
我们定义 :::
:::
连续性变量
:::success
我们定义 :::
:::
性质
:::info
我们可以将 理解为随机变量对
理解为随机变量对 中含有的所有信息量, 于是我们有一下关系:
中含有的所有信息量, 于是我们有一下关系:
- 如果
 ,那么
,那么
- 如果
 独立, 那么
独立, 那么
- 对于任意的
 ,我们有
,我们有 :::
:::
PyTorch实现
def joint_entropy(p_xy):"""Compute the joint entropy for the discrete joint random variables:param p_xy: A multidimensional array representing the pmf of the (X,Y):return: The joint entropy of the (X,Y) , namely, H(X,Y)"""entropy_array = -p_xy * torch.log2(p_xy)out = nansum(entropy_array)return outprint(joint_entropy(torch.tensor([[0.1,0.2,0.3],[0.1,0.1,0.2]]))) # tensor(2.4464)
3.2 Conditional Entropy
由来
:::info
条件熵的来源也非常的直观:
假设我们有一个样本集,其中的每一条数据都是(Image, Class Label)的形式
我们从这个样本中抽取一条数据,假设抽取的是 的二元随机变量组, 则这个随机变量对
的二元随机变量组, 则这个随机变量对 就描述了整个样本集,
就描述了整个样本集,  就是可能出现的
就是可能出现的手写数字图片数据, 就是可能出现的
就是可能出现的Class Label 就是给定了手写数字图片信息之后
就是给定了手写数字图片信息之后class label含有的信息熵
由于在知道了图片长什么样之后,样本空间缩减,class label变得更加确定,事件的概率更大,信息熵就越小
:::
定义
时刻记住我们想要探究的目标是什么,是: 对于一个
二元随机变量组,在
**X=x的前提下,Y=y**的这个事件带给我们的信息量 因为对于某个事件,它的
Self-Information是而我们想要探究所有满足
形如
的事件的平均
**Self-Information**, 于是我们定义:

多变量离散

多变量连续

性质
直观来讲:
给出了
联合信息量在
给定之后剩下的部分

PyTorch实现
假设
服从下列联合分布
| X=1 | X=2 | X=3 |  |
|
|---|---|---|---|---|
| Y=1 | 0.1 | 0.1 | 0.1 | 0.3 |
| Y=2 | 0.2 | 0.2 | 0.3 | 0.7 |
 |
0.3 | 0.3 | 0.4 | 1 |
def conditional_entropy(p_xy,p_x):"""Compute the conditional entropy given joint PMF and marginal PMF for multi-discrete random variables:param p_xy: joint pmf:param p_x: marginal pmf:return: conditional entropy"""p_y_given_x = p_xy/p_xcond_entropy = -p_xy*torch.log2(p_y_given_x)out = nansum(cond_entropy)return out# tensor(0.8755)print(conditional_entropy(torch.tensor([[0.1,0.1,0.1],[0.2,0.2,0.3]]),torch.tensor([[0.3,0.3,0.4]])))
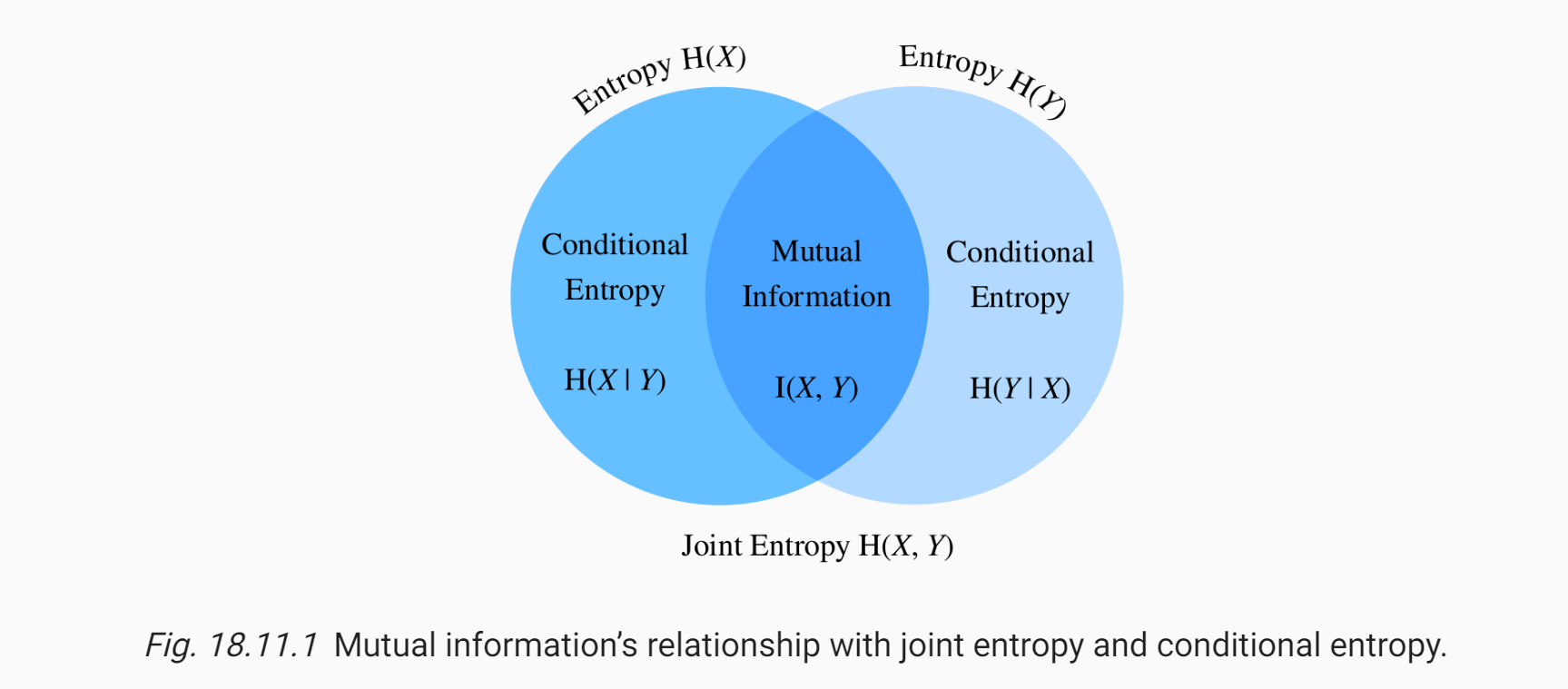
3.3 Mutual Information
假设我们有两个随机变量
,我们想要探究
共享的信息, 注意不是信息的总和 结合下面的图有助于我们理解
Joint Entropy和Mutual Information的概念
定义
我们定义两个变量的互信息
Mutual Information为用数学符号表达就是
具体的推导过程如下:

性质
互信息和自信息以及条件信息熵的关系:
互信息的性质:
- 对称性:
- 非负性:
- 独立条件:
当且仅当
和
是独立的,如果
和
是独立的 ,我知道了
不会提供任何线索(信息)给
- 如果
之间存在着一种
one-to-one correspondance的关系,也就是说: 如果存在一个bijective的,则
共享所有信息,相当于知道了其中任何一个就等于知道了另外一个,所以此时







PyTorch实现
假设
服从下列联合分布
| X=1 | X=2 |  |
|
|---|---|---|---|
| Y=1 | 0.1 | 0.3 | 0.4 |
| Y=2 | 0.4 | 0.2 | 0.6 |
 |
0.5 | 0.5 | 1 |
def mutual_information(p_xy,p_x,p_y):"""Compute the mutual Information for discrete joint random variables:param p_xy: Joint probability distribution of (X,Y):param p_x: Maringal probability distribution for X:param p_y: Marginal probability distribution for Y:return: The mutual information of (X,Y)"""p_on_condition = p_xy/(p_x*p_y)entropy = p_xy*torch.log2(p_on_condition)out = nansum(entropy)return out# tensor(0.1830)print(mutual_information(torch.tensor([[0.1,0.3],[0.4,0.2]]),torch.tensor([[0.5,0.5]]),torch.tensor([[0.4,0.6]])))
3.4 Pointwise Mutual Information
定义
前文介绍了求互信息的方法,本质是求了一个期望,但现在我们想知道一个特定事件的互信息 由于是互信息,一定就会牵扯到两个随机变量
的关系 参考
Self-Information的定义,我们有:这个指标使我们能够将互信息理解为: 如果
变量不独立,观测到
的信息和如果
独立,观测到
的信息相比是大了还是小了
3.5 Applications of Mutual Information
在自然语言处理中,最困难的问题是
**Ambiguity Resolution**,就是比如我们有一句话Amazon is on fire, 我们不知道这里的Amazon是亚马逊公司还是亚马逊雨林。 这时候我们可以应用互信息的概念, 假设,
之类的词,然后计算
,看看是
取
雨林,热带,雨的时候大还是取
公司,科技的时候大,依次来判断文章中的Amazon是什么意思
4 Kullback-Leibler Divergence
由来
:::info
K-L Divergence力图刻画两个不同的概率测度 和
和 之间的相近程度
:::
之间的相近程度
:::
定义
假设随机变量
, 且它的
pmf/pdf是,这时有另外一个概率测度
,且
在这个概率测度下的
pdf/pmf是q(x),我们定义KL-Divergence:此时我们发现,如果
,
为正且值很大,也就是说,随机变量
在
的概率测度下更可能出现,
事件的概率普遍比事件
在概率测度
下的概率大,且
Self-Information更小 总而言之: 我们借助随机变量和
得到了两个概率测度
之间的相近程度
性质

PyTorch实现
| X=1 | X=2 | X=3 | X=4 | |
|---|---|---|---|---|
 |
0.1 | 0.1 | 0.2 | 0.6 |
 |
0.4 | 0.3 | 0.1 | 0.2 |
def kl_divergence(p, q):"""Compute the KL Divergence for a random variable under distribution P and Q:param p: pmf for X under probabilistic measure P:param q: pmf for X under probabilistic measure Q:return: The absolute value of KL Divergence"""kl = p * torch.log2(p / q)out = nansum(kl)return out.abs().item()# 0.7924812436103821print(kl_divergence(torch.tensor([0.1,0.1,0.2,0.6]),torch.tensor([0.4,0.3,0.1,0.2])))
这里随机变量
在概率测度
下更容易出现
验证非对称性
假设有三个正太分布
,我们要验证
KL-Divergence的非对成性
def driver():"""Run the program:return:"""p_p,p_q1,p_q2 = generate_random_variable(10000)return calculate_similarity(p_p, p_q1, p_q2)def generate_random_variable(vector_length=10000):"""Generate random variable from different normal distributions:param vector_length: Length of the vector:return: The generated probability vector of normal distributions"""torch.manual_seed(1)p = torch.normal(0,1,(vector_length,))q1 = torch.normal(-1, 1, (vector_length,))q2 = torch.normal(1, 1, (vector_length,))return p,q1,q2def calculate_similarity(p, q1,q2):"""Calculate the similarity between two distributions:param refer: referenced distribution:param target1: 1st compared distribution:param target2: 2nd compared distribution:return: The similaritybetween distribution target1 and target2"""kl_pq1 = kl_divergence(p, q1)kl_pq2 = kl_divergence(p, q2)kl_q2p = kl_divergence(q2, p)similar_percentage = abs(kl_pq1-kl_pq2) / ((kl_pq1 + kl_pq2) / 2)*100differ_percentage = abs(kl_q2p - kl_pq2) / ((kl_q2p + kl_pq2) / 2) * 100return kl_pq1,kl_pq2,kl_q2p,similar_percentage,differ_percentageif __name__ == "__main__":print(driver()) #(676.23779296875, 575.7619018554688, 8803.0966796875, 16.050465751493352, 175.4442655532291)

5 Cross Entropy
定义
假设有两个概率测度
,
**Cross Entropy**也可以用于衡量两个概率测度之间的**Divergence**和**KL-Divergence**类似, 我们可以定义交叉熵为:同时根据
**Entropy**和**KL-Divergence**的定义,我们可以把交叉熵改写成:

PyTorch 实现
:::success
我们的输入标签相当于One-hot Encoding
:::
| |  |
|  |
|  | Cross Entropy |
| —- | —- | —- | —- | —- |
|
| Cross Entropy |
| —- | —- | —- | —- | —- |
|  |
|  |
|  |
|  |
|  |
|
|
|  |
|  |
|  |
|  |
|  |
|
def cross_entropy(y_hat, y):
ce = -torch.log(y_hat[range(len(y_hat)), y])
return ce.mean()
labels = torch.tensor([0, 2])
preds = torch.tensor([[0.3, 0.6, 0.1], [0.2, 0.3, 0.5]])
cross_entropy(preds, labels) # tensor(0.9486)
性质

多分类任务⭐
假设我们现在有数据集
,构成为
假设数据集对应的标签为
, 表示我们的分类任务有
个维度, 也就是有
类 标签
为独热编码 假设模型参数是

:::success
现在我们对每个样本的预测情况进行分析并对其求交叉熵, 这里假设 都是随机变量:
都是随机变量: 
现在我们着眼于某个样本标签对 :
:
首先我们求  ,它代表的含义是在给定
,它代表的含义是在给定 和模型参数
和模型参数 的情况下,输出正确标签
的情况下,输出正确标签 的概率,也就是输出正确分类的概率,我们自然是希望我们的模型使得这个概率越大越好, 这也是我们优化
的概率,也就是输出正确分类的概率,我们自然是希望我们的模型使得这个概率越大越好, 这也是我们优化 的目标, 下面开始计算, 由极大似然估计得:
的目标, 下面开始计算, 由极大似然估计得: ,这个公式难理解的点在于这个指数的存在,假设对于当前数据集,分类数量是
,这个公式难理解的点在于这个指数的存在,假设对于当前数据集,分类数量是 , 且第一条数据
, 且第一条数据 因为我们要预测的实际上是在
因为我们要预测的实际上是在 的条件下
的条件下 的概率, 也就是使得
的概率, 也就是使得 的那个维度
的那个维度 处的概率(
处的概率( ), 也就是
), 也就是 的概率,但
的概率,但 是一个
是一个Random Vector, 所以每一个维度 都需要求一下概率。而我们要求的只是那个维度的概率, 所以需要加上指数标记一下我们需要的那个维度的概率信息,其他维度都不需要,这其实也就和
都需要求一下概率。而我们要求的只是那个维度的概率, 所以需要加上指数标记一下我们需要的那个维度的概率信息,其他维度都不需要,这其实也就和One-hot encoding对应起来了
取负对数转化成交叉熵: 
所有样本的CE值相加, 就成了我们的Loss Function:  :::
:::

PyTorch 实现
# Implementation of cross-entropy loss in PyTorch combines `nn.LogSoftmax()`
# and `nn.NLLLoss()`
nll_loss = NLLLoss()
loss = nll_loss(torch.log(preds), labels)
loss

若有收获,就点个赞吧
0 人点赞
