| 课程章节 | 算法训练营 开营直播课 |
|---|---|
| 课程作者 | 李煜东 |
| 学习状态 | 学完 |
| 内容简介 | 本节课主要讲了本课程设计思路,学习方法,以及算法时空复杂度分析相关知识。 |
| 相关资源 | 哔哩哔哩 |
课程设计思想
数据驱动算法
- 先学线性数据结构,然后学习其上各种灵活的算法
- 了解树、图等结构,然后学习递归、搜索等算法
- 形成集合、维度、状态空间等概念,然后学习动态规划等高级算法
- 抛开数据的支持,算法是假大空的
-
三天主线 + 两个副本
线性结构线
数组、链表、栈、队列 -> 前缀和、差分、双指针、滑动窗 -> 哈希、集合、映射 -> 字符串
- 树形结构线
递归、分治 -> 树、图 -> 搜索 -> 堆、二叉搜索树 -> 字典树、并查集 -> 图论算法
- 状态空间线

- 顺序优化副本:排序,二分
-
为什么 VS 怎么想到
课程注重思维体系的构建
- 希望帮你解决“怎么想到”,而不只是“为什么对”
情景引入一问题“模型化”一知识点一实战题目(讲思路的形成过程,现场写代码)
落地实战,用代码说话
主要解决:有了思路,写不出来或者写得慢,总出错还调不出来的问题?
- 养成能力:教给你如何写得又快又对,如何让代码结构简洁易懂,如何模块化处理细节,如何预判避免错误
找准定位
一分耕耘一分收获,付出的时间决定到达的目标,大致如下:
| 目标 | 要求 | 所需时间 |
|---|---|---|
| 降维打击算法面试 实现跳槽自由 |
理解课上教的内容 完成所有例题和习题 |
每节课 2h 教学 + 1h 回顾 + 7h 刷题 学完后 100h 强化,全程共 300h |
| 在大部分算法面试中得心应手 | 理解大部分内容 背通较难的模板 完成所有例题 |
每节课 2h教学+1h 回顾+5h刷题 学完后 40h 强化,全程共 200h |
| 做对中等题 难题有一定的思考方向 |
记住课上教的内容 技要求完成作业(5选2) |
每节课 2h 教学 + 0.5h 回顾 课后 3.5h 刷题,全程共 120h |
| 对算法题有基本认知 不会一脸懵逼 |
认真听讲 完成重点例题 |
每节课 2h 教学 课后 3.5h 刷题,全程共 80 h |
听课的方法
- 课前预习:
- 浏览 PPT,标注自己完全不懂的地方
- 每个知识点选 1 道例题,看看题意,大致想一想
- 课上听讲:
- 紧跟老师的大思考方向,不要太拘泥于细节的证明,可以之后再回放
- 承认算法和数据结构的复杂性,课上只听懂60%-70% 是正常的
- 课后回顾:
- 误区1:对待题解的“两个极端”
- 看题解刷题—看似速度快,做的题多,实际上抛开题解大脑一团空白
- 坚决不看题解,自己死抠——陷入自己原有的思路里,学不到高票题解、高票代码的优秀思路
- 误区 2:LeetCode 每题只做一遍或者 LeetCode 随机刷综合题
- 正确做法:坚持“分类三刷”
- 误区3:面对一道题,拿学过的算法挨个试解
- 正确做法:坚持“五步刷题”,剖析题目关键点一回想学过的模型 一根据特征找到算法
- 题目特征驱动算法,而不是猜测算法试解题目
- 误区4:使劲做题,记忆每道题的代码,打到熟练
- 背诵100 道题目,会的还是这100 道
- 记忆 50 个模型,能做出 500道题目
解题是靠模型驱动的,大部分题目都是一个模型的拓展,或多个模型拼起来。
坚持“三刷五步〞训练法
初学建议分类刷 -> 后期建议综合刷
- 一刷:每个“小类别”的代表性题目、各刷几道;此时如果需要看题解,很正常
- 二刷:复习代表性题目,”小类别〞合成“大类别〞,刷该分类更多的题目,举一反三,在尽量少的提示下完成。
- 三刷:综合性题目,尽量独立实现+测试
- 第一步:理解题面
- 想一想更多的例子和测试数据,看看有没有遗漏的地方
- 提炼题目中的关键信息、变化信息
- 面试的时候,跟面试官确认自己的理解
- 第二步:部分实现
- 无论什么题目,先尝试实现一个朴素解法(比如搜索)或者是部分场景下的解法
- 尽量让自己的解法更优,覆盖更多的场景
- 第三步:有提示解答
- 看提示之看题解
- 可以看题解的一部分,试试能否找到突破口
- 例如题目类别,题解标题,时间复杂度,一个小结论
- 面试是一个交互性的过程,你可以与面试官交流获取适当的提示
- 要能明白面试官在引导你什么,这就要从平时练起
- 第四步:独立解答
- 独立完成求解,同时注意测试
- 初期训练时通常可以从第二步的搜索出发
- 搜索时关注了哪些信息?
- 它们有没有冗余?能不能更好地维护?
- 有没有同类的子问题?
- 第五步 写题解
- 尝试给别人讲(面试的时候也是要讲的),尝试分析对比各种不同解法的优劣
- 题解也可以写成日记的形式,记录自己遇到的难点
-
复杂度分析方法
常见的复杂度代码逻辑
忽略常数,只看最高复杂度的运算,常见的复杂度如下:
O(1):Constant Complexity 常数复杂度O(log(n)):Logarithmic Complexity 对数复杂度O(n):Linear Complexity 线性时间复杂度O(n^2):N square Complexity 平方O(n^3):N cubic Complexity 立方O(2^n):Exponential Growth 指数O(n!):Factorial 阶乘
O(log(n))为什么没有底数?
复杂度对象的伪代码逻辑:
n := 100println(n)
for i := 1; i < n; i = i*2 {
println(i)
}
func calc(l, r int) {
if l >= r {
return
}
for i = l; i <= r; i++ {
// TODO
println(i)
}
mid := (l + r) / 2
calc(l, mid)
calc(mid + 1, r)
}
calc(1, n)
func fib(n int) int {
if n < 2 {
return n
}
return fib(n - 1) + fib(n - 2)
}
func dfs(depth int) {
if depth == n {
return
}
for i = 0; i < n; i++ {
if used[i] {
continue
}
used[i] = true
per.add(i)
dfs(depth + 1)
per.remove(per.size() - 1)
used[i] = false
}
mid := (l + r) / 2
calc(l, mid)
calc(mid + 1, r)
}
dfs(0)
时间复杂度曲线
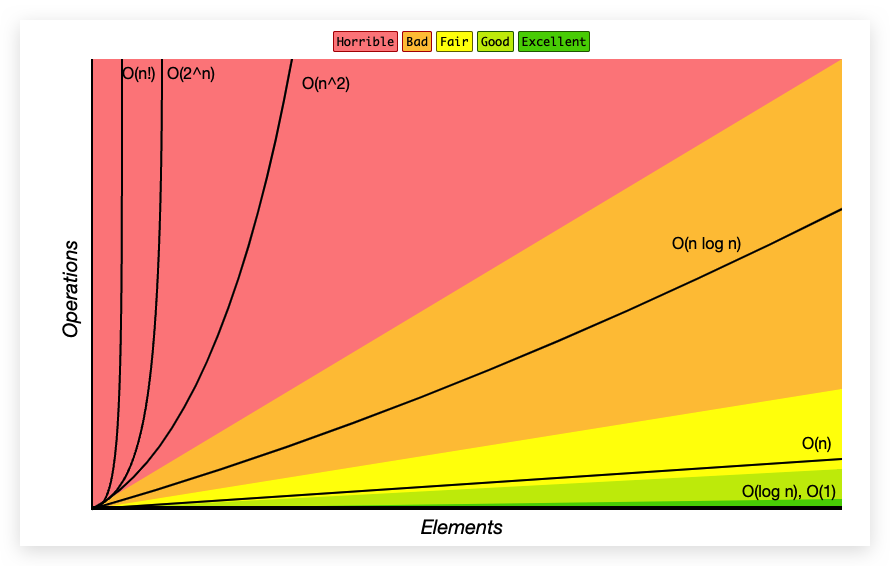
图片来源: Big-O Cheat Sheet
- 中文版
- 中文版 GitHub 地址
一些常见的式子
1 + 2 + 3 + ... + n = n(n + 1) / 2
n + n / 2 + n / 4 + ... + 1
< 2n
1 + 1 / 2 + 1 / 3 + ... + 1 / n
< 2
最坏 VS 均摊
对于整个代码,最坏 O(n),对于每个 i,内层最坏 O(n),均摊 O(1)。
for i, j, sum := 1, 1, 0; i <= n; i++ {
for j <= n && sum + a[j] <= T {
sum += a[j++]
}
sum -= a[i]
}
对于整个代码,最坏 O(n^2)。
for i := 1; i <= n; i++ {
for j, sum := i, 0; j <= n && sum + a[j] <= T {
sum += a[j++]
}
}
空间复杂度
主要有一下因素决定:




若有收获,就点个赞吧
0 人点赞
