一、概念初识
什么是爬虫?
网络爬虫:自动采集网络数据的脚本或者程序,其目的在于获取有价值的信息。
爬虫原理:模拟浏览器发送请求,像浏览器一样思考。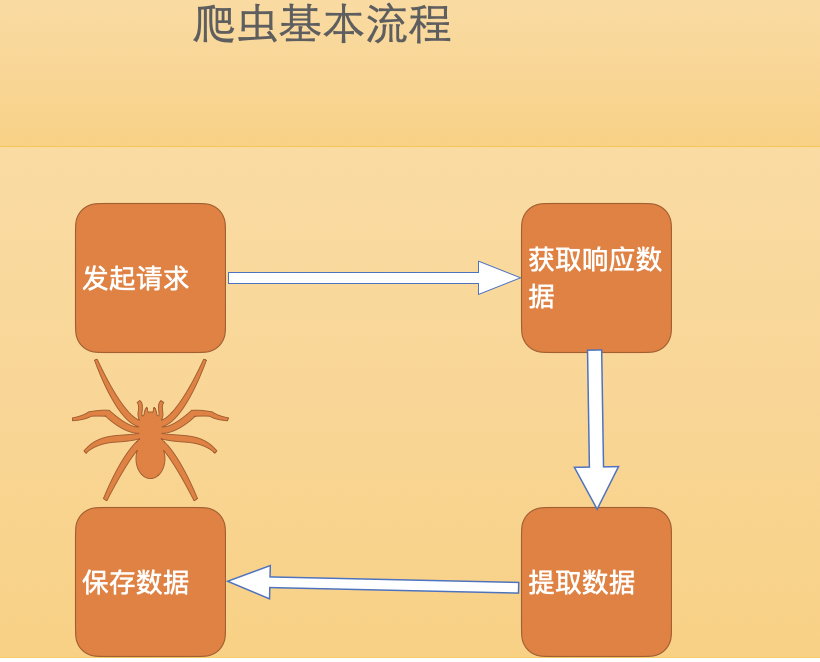
二、探索之路
1、数据采集探索一「urllib库」
- 功能:urllib库中的方法能够直接爬取百度页面源代码
```python from urllib import parse from urllib import requestfrom urllib import requesturl='http://www.baidu.com'response=request.urlopen(url,timeout=1)#html源代码,右击查看源代码功能print(response.read().decode('utf-8'))
data = bytes(parse.urlencode({‘word’:’hello’}),encoding=’utf8’)
print(data)
response = request.urlopen(‘http://httpbin.org/post‘, data=data) print(response.read().decode(‘utf-8’))
- 缺点:请求处理繁琐,data表单数据需要单独解析放弃<a name="sgKti"></a>#### 2、数据采集探索二**「requests」**- 功能:安装requests库实现get、post请求,可以返回text,也可以返回json格式:- 支持两种常见请求方式:1.1 get 参数在地址栏,参数有限<br />1.2 post 参数在表单,安全性较高- 支持模拟header请求头- 模拟请求头是因为服务器会验证请求是否为一个标准的浏览器发送过来的```python# get请求import requestsurl = 'http://httpbin.org/get'data = {'key': 'value', 'abc': 'xyz'}# .get是使用get方式请求url,字典类型的data不用进行额外处理response = requests.get(url, data)print(response.text)# post请求import requestsurl = 'http://httpbin.org/post'data = {'key': 'value', 'abc': 'xyz'}# .post表示为post方法response = requests.post(url, data)# 返回类型为json格式print(response.json())
-
3、数据采集探索三「requests+正则」
功能:获取到网页数据后,通过正则匹配出相关的数据 ```python import requests import re content = requests.get(‘http://www.cnu.cc/discoveryPage/hot-人像').text
print(content)
< div class =”grid-item work-thumbnail” >
< a href=”(.?)”.?title”>(.*?)
pattern = re.compile(r’<a href=”(.?)”.?title”>(.*?)‘, re.S) results = re.findall(pattern, content) print(results) for result in results: url,name=result print(url,re.sub(‘\s’,’’,name))
- 缺点:匹配出较多无效数据需要额外处理放弃- Tips:正则知识补充<br />1.1 非贪婪模式匹配 . * ?<br />1.2 生成一个正则匹配模式 re.compile(pattern[, flags])<br />匹配:re.findall()<br />1.3 sub:字符处理```pythonimport rephone = "2004-959-559 # 这是一个国外电话号码"# 删除字符串中的 Python注释num = re.sub(r'#.*$', "", phone)print "电话号码是: ", num# 删除非数字(-)的字符串num = re.sub(r'\D', "", phone)print "电话号码是 : ", num
4、数据采集探索四「requests+beautiful soup」
- 功能:更精准的方式爬取,条理清晰的层级关系便于查找和定位元素
- 知识弥补:
- html基础:了解网页基本结构- beautiful soup :如何通过标签和属性获取数据- 官方文档快速学习- - 
三、豆瓣电影实战
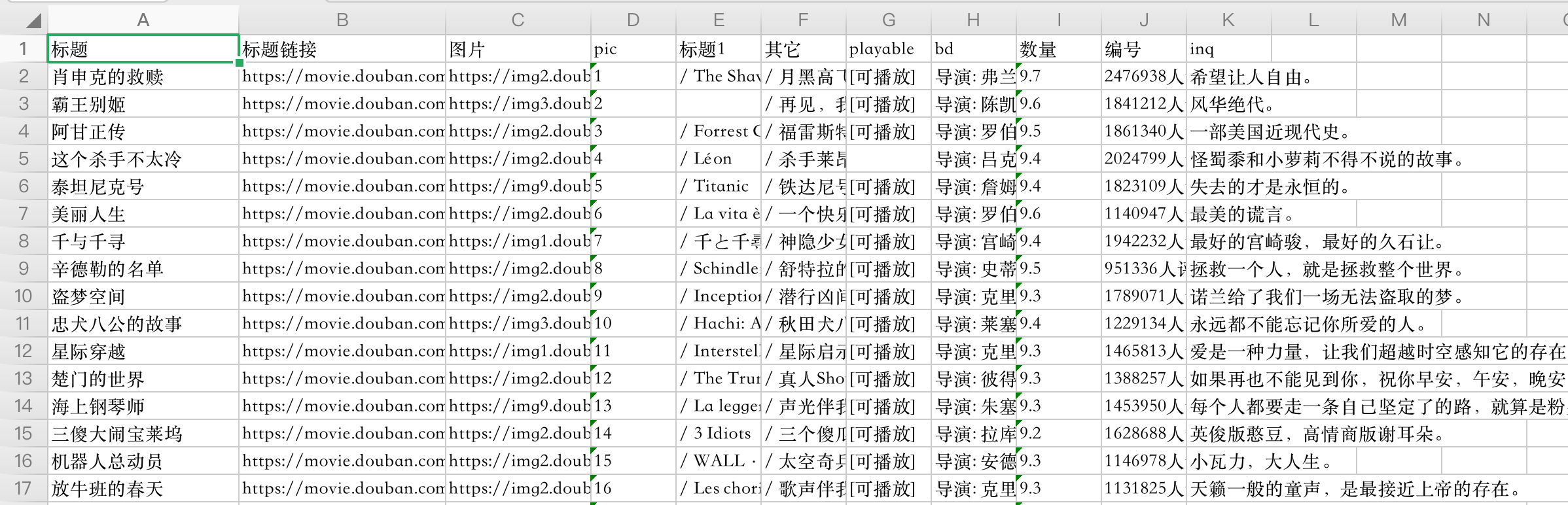
1、目标:爬取豆瓣高分电影的名称、链接、推荐语、评分
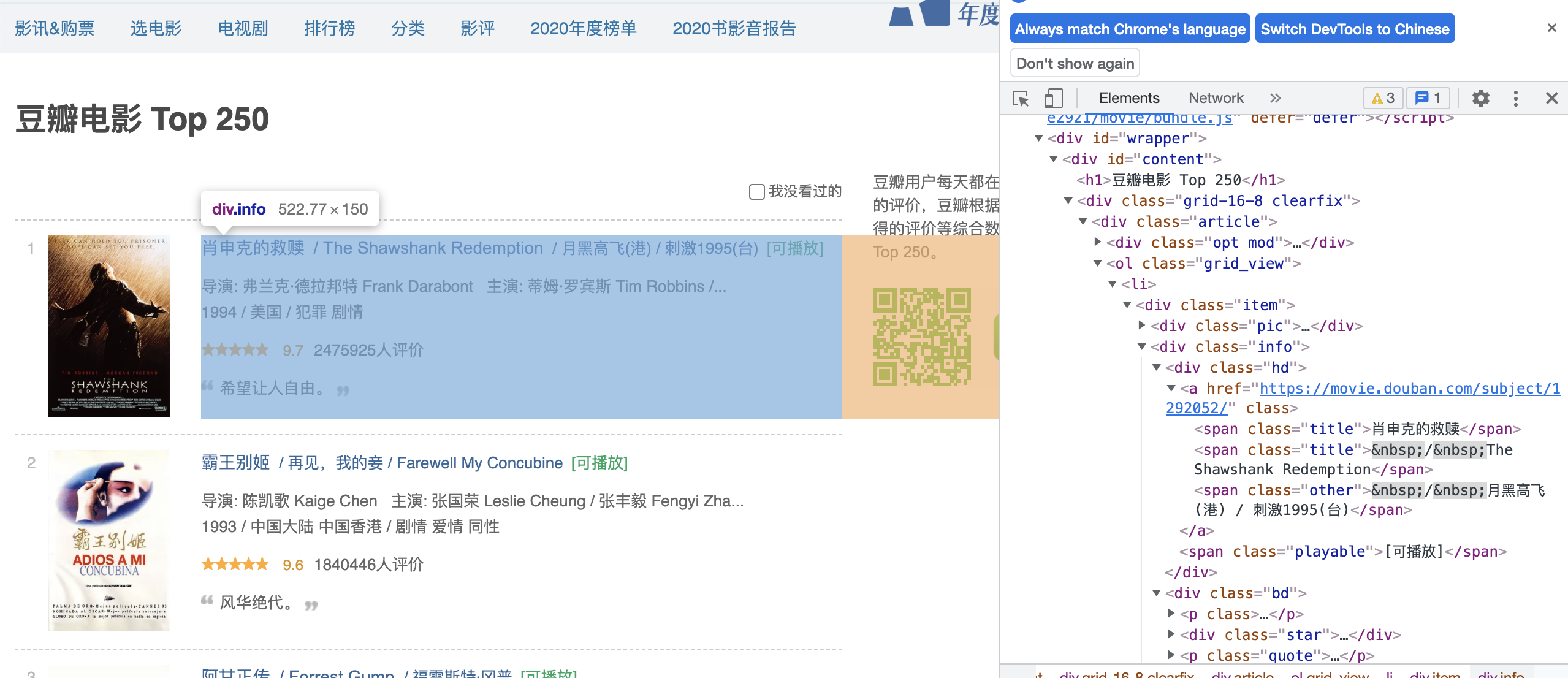
2、方法:requests请求数据+BeautifulSoup提取数据 ```python import requests from bs4 import BeautifulSoup
url=”https://movie.douban.com/top250“ header= { “Accept”: “text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8”, “Accept-Encoding”: “gzip, deflate, sdch”, “Accept-Language”: “zh-CN,zh;q=0.8”, “Connection”: “close”, “Referer”: “http://httpbin.org/“, “Upgrade-Insecure-Requests”: “1”, “User-Agent”: “Mozilla/5.0 (Macintosh; Intel Mac OS X 1015_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36” } res=requests.get(url,headers=header).text douban_soup=BeautifulSoup(res,’html.parser’) douban_item=douban_soup.find_all(‘div’,class=’item’) for item in doubanitem: link=item.find(‘a’) name=item.find(‘span’,class=”title”) quote=item.find(‘p’,class_=’quote’) print(name.text,link[‘href’],quote.text)
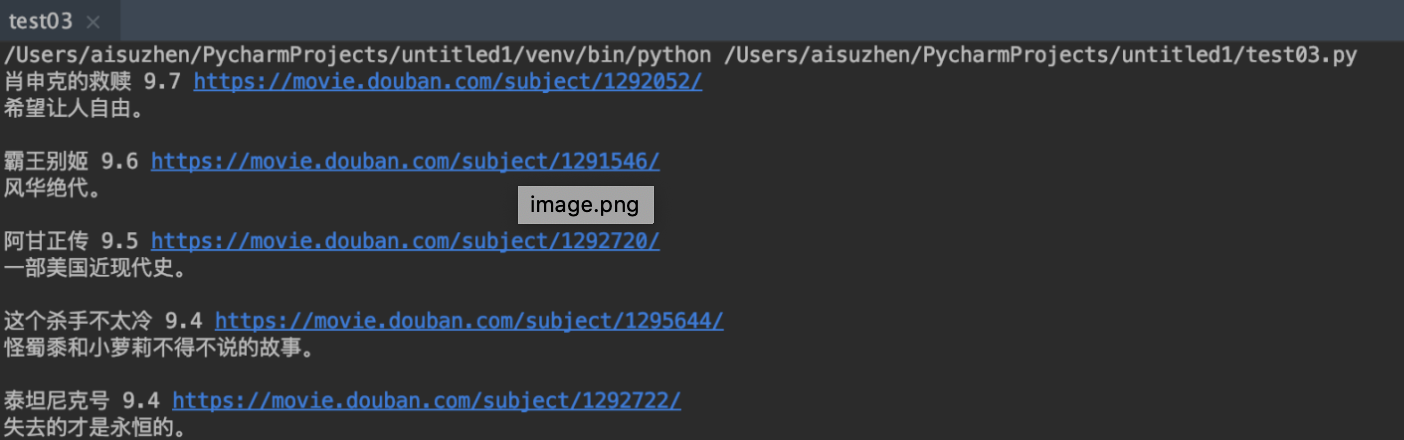3、爬虫数据存储```pythonimport requestsfrom bs4 import BeautifulSoupimport csvurl="https://movie.douban.com/top250"header= {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding": "gzip, deflate, sdch","Accept-Language": "zh-CN,zh;q=0.8","Connection": "close","Referer": "http://httpbin.org/","Upgrade-Insecure-Requests": "1","User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"}#存储电影数据file=open('/Users/aisuzhen/Downloads/douban_movie.csv','w',encoding='utf-8')writer=csv.writer(file)#设置文件表头writer.writerow(["名称","评分","链接","推荐语"])#采集数据res=requests.get(url,headers=header).textdouban_soup=BeautifulSoup(res,'html.parser')douban_item=douban_soup.find_all('div',class_='item')for item in douban_item:link=item.find('a')name=item.find('span',class_="title")quote=item.find('p',class_='quote')star=item.find('span',class_="rating_num")print(name.text,star.text,link['href'],quote.text)writer.writerow([name.text,star.text,link['href'],quote.text])
下面展示下效果👇
拓展:
那如果要爬取前三页呢?以如下找规律的方式:
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
https://movie.douban.com/top250?start=75&filter=
https://movie.douban.com/top250?start=i*25&filter=
url="https://movie.douban.com/top250?"real_url=url+"start="+str(i*25)+"&filter="
import requestsfrom bs4 import BeautifulSoupimport csvurl="https://movie.douban.com/top250?"header= {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding": "gzip, deflate, sdch","Accept-Language": "zh-CN,zh;q=0.8","Connection": "close","Referer": "http://httpbin.org/","Upgrade-Insecure-Requests": "1","User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"}#存储电影数据file=open('/Users/aisuzhen/Downloads/douban_movie.csv','w',encoding='utf-8')writer=csv.writer(file)#设置文件表头writer.writerow(["名称","评分","链接","推荐语"])#采集数据for i in range(0,3):real_url=url+"start="+str(i*25)+"&filter="print(real_url)res=requests.get(real_url,headers=header).textdouban_soup=BeautifulSoup(res,'html.parser')douban_item=douban_soup.find_all('div',class_='item')for item in douban_item:link=item.find('a')name=item.find('span',class_="title")quote=item.find('p',class_='quote')star=item.find('span',class_="rating_num")print(name.text,star.text,link['href'],quote.text)writer.writerow([name.text,star.text,link['href'],quote.text])
爬虫豆瓣250完成~ 也由此验证了这条正确高效的爬虫之路👏
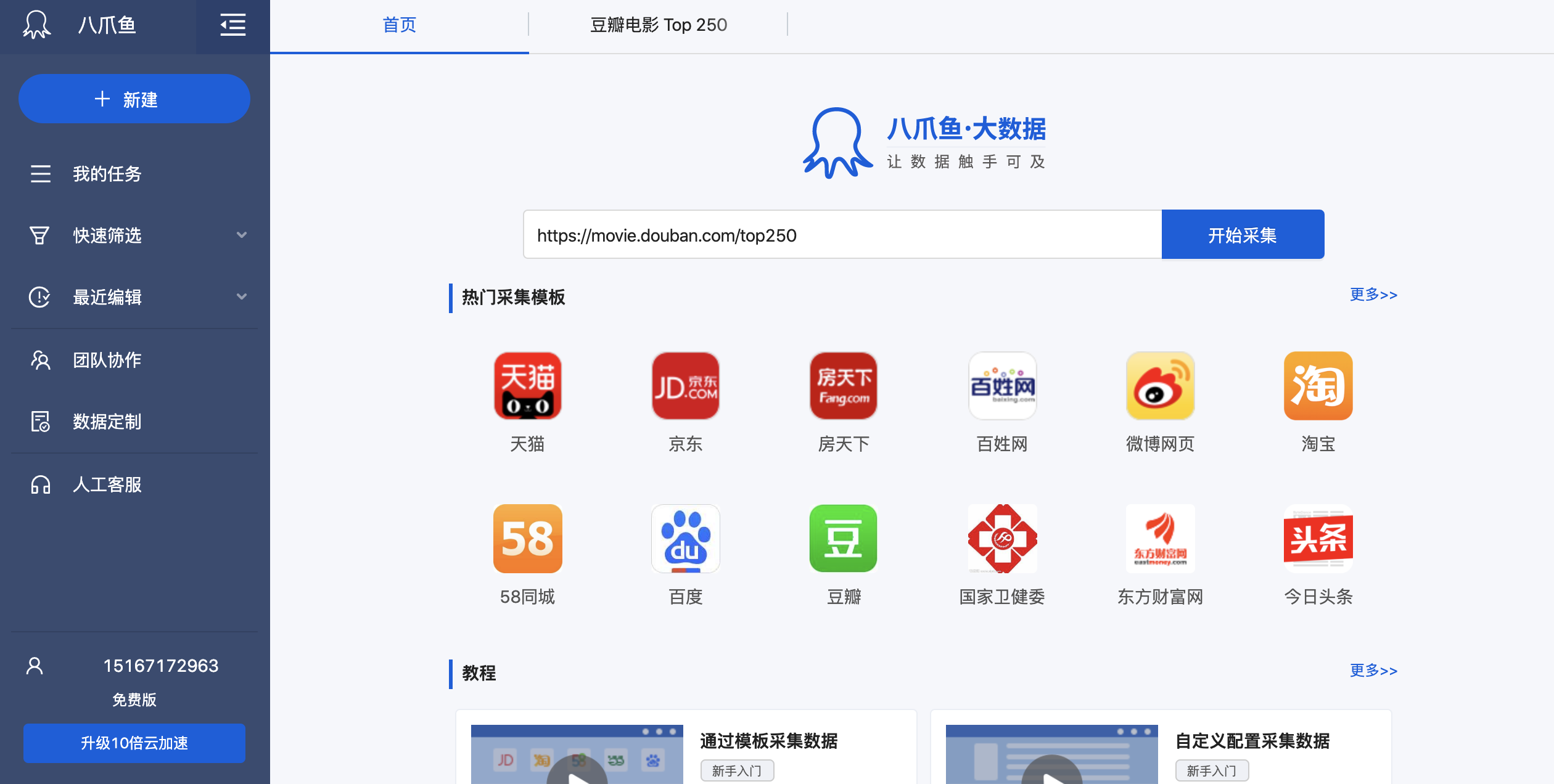
四、八爪鱼专业采集
- 一款专业采集数据的产品
- 涉及电商、房产、新闻、社交等各领域智能化采集,用于商业决策
- url复制八爪鱼采集器
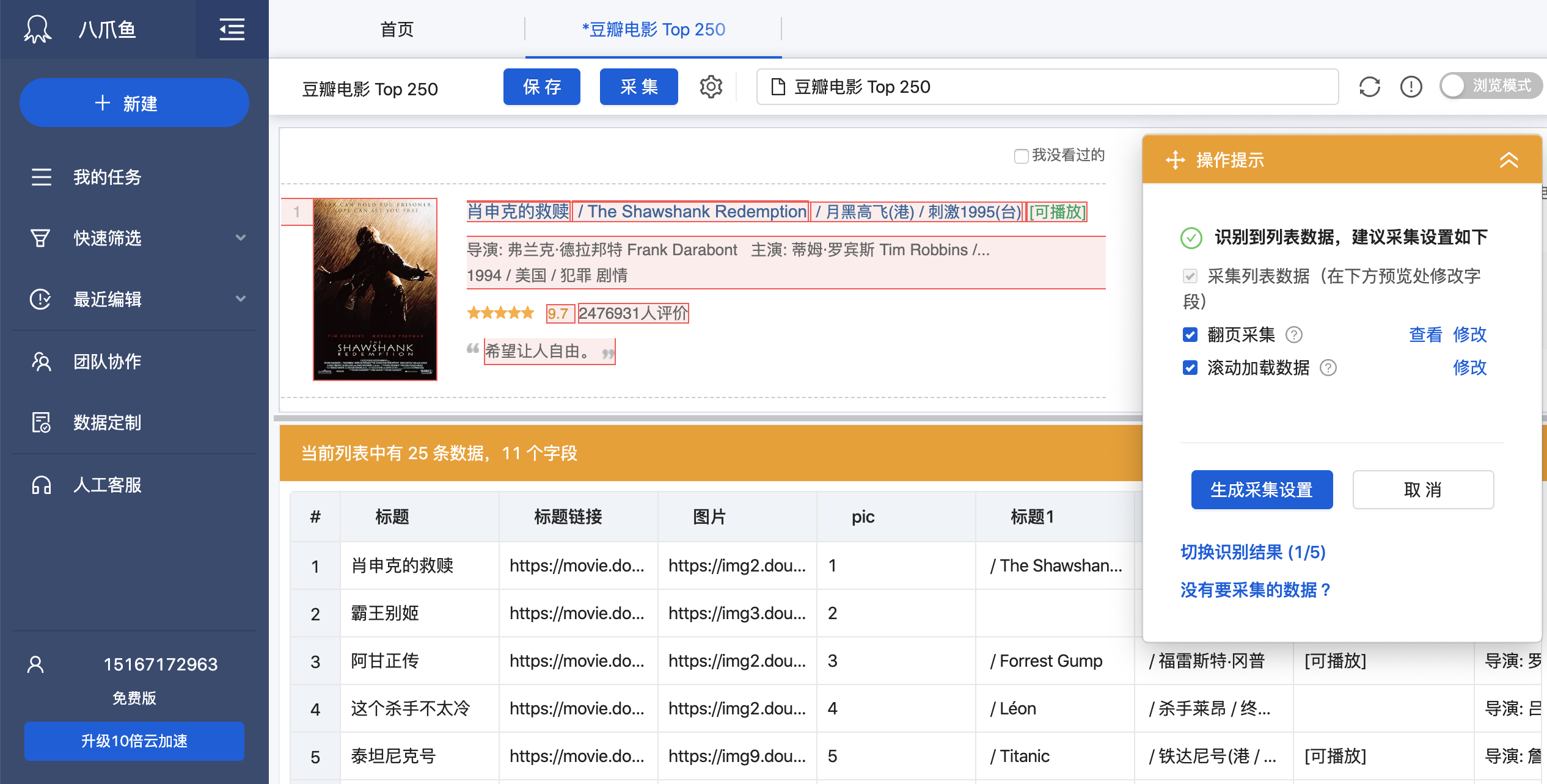
- 生成采集设置
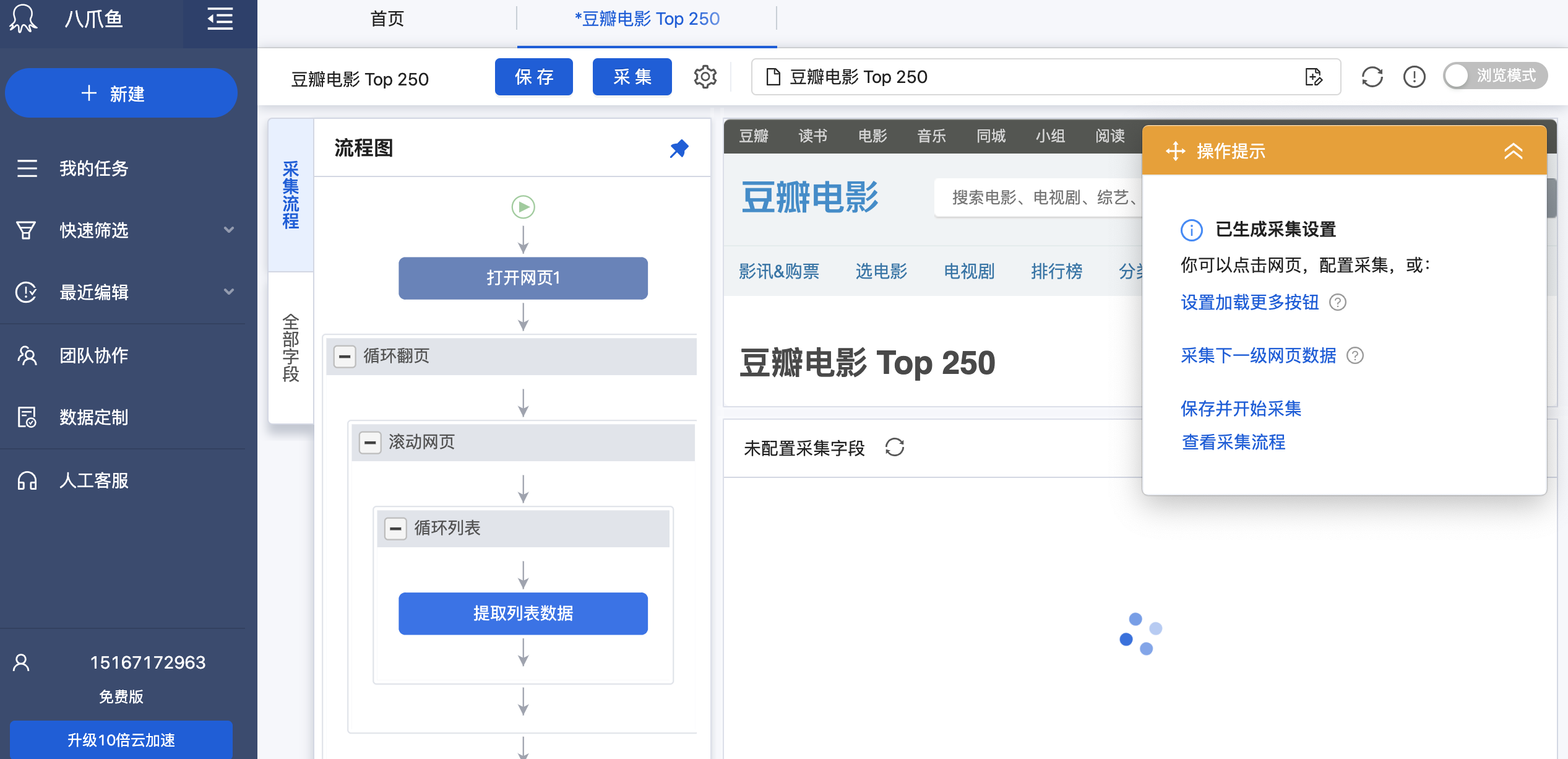
- 保存并开始采集
- 导出数据
五、工作运用
学习不仅仅是口号,目标需要产出,输出文档也好,解决实际工作问题也行,真正做到「学以致用」。
痛点:测试过程中需要在40几种工单中筛选一种业务工单
解决:模拟浏览器请求,自动打开工单
针对最常用的13种工单进行自动打开页面
以上就是本次爬虫实战的内容了,你是不是已经跃跃欲试了呢~  完结撒花~
完结撒花~

若有收获,就点个赞吧
0 人点赞
