4.1 窗口函数
4.1.1 简介
- 含义:窗口函数也称OLAP函数(Online Anallytical Processing,在线分析处理),可以用来对数据进行实时分析处理,这里的窗口表示范围。因为常规的SELECT语句是对整张表上的数据进行处理,而窗口函数则可以让我们对数据库中的某一部分数据进行汇总、计算和排序。
- 语法格式:
- 窗口函数 over([partition by 用于分组的列名][order by 用于排序的列名])
- PARTITON BY:可选参数,用于分组,即按哪个字段划分窗口,类似于GROUP BY的分组功能,但他只是决定函数的作用范围,不会改变表中记录的数量;
- ORDER BY:可选参数,用于决定窗口中的元素以哪种规则进行排序,默认是升序。
比如以下SQL语句:
SELECT product_name,product_type,sale_price,RANK() OVER (PARTITION BY product_typeORDER BY sale_price) AS rankingFROM product;
根据定义,该语句的意思就是根据product_type这一列进行分组,并对组内作用RANK()函数,并按照sale_price进行排序。具体的结果如下:

- 从结果中可以看出,这里RANK()函数的作用就是根据物品的价格生成窗口内的排名,具体的用法后面会详细介绍。
- 用法:
- 解决排名问题,如对学校中每个班级中的学生按成绩排名;
- 解决TOPN问题,如求出每个班级前两名的学生。
- 适用范围和注意事项:
- 窗口函数是对 where 后的 group by 子句处理后的结果进行操作,因此按照SQL语句的运行顺序,窗口函数一般放在select子句中;
- 窗口函数 OVER 中的 ORDER BY 子句并不会影响最终结果的排序。其只是用来决定窗口函数按何种规则进行排序。
【补充】:
对窗口函数的一些思考:
- 窗口函数中的两个参数均为可选参数,可以全都不加,但是没意义,比如sum窗口函数就会得到按某一列全表聚合的结果,而rank函数就会得到所有的行的排名都是1的情况,如下面的代码:
得到的结果如下:select product_id, product_type, sale_price, rank() over() as rk, sum(sale_price) over() as total from product;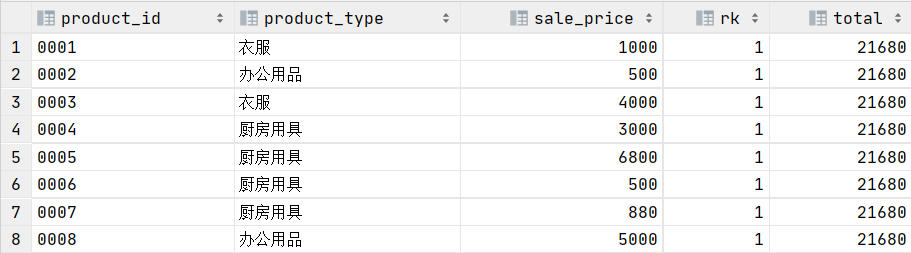
可以看到这里不做任何限制的开窗相当于对整个表使用了窗口函数,比如total字段就是全表的商品价格的聚合值;
- 窗口函数中的两个参数均为可选参数,可以全都不加,但是没意义,比如sum窗口函数就会得到按某一列全表聚合的结果,而rank函数就会得到所有的行的排名都是1的情况,如下面的代码:
但是,针对不同的窗口函数,省去某一个字段是有意义的,具体见下一节
4.1.2 窗口函数的分类
窗口函数分为两种,一种是像RANK()这样专用的窗口函数,还有一种就是将聚合函数应用在窗口函数中的函数。
4.1.2.1 专用窗口函数
RANK():
- 计算排序时考虑相同值,出现相同值则占用下一个排名的位置;
- 比如有 3 条记录排在第 1 位时,结果为:1 位、1 位、1 位、4 位;
- DENSE_RANK():
- 计算排序时考虑相同值,出现相同值不会占用下一个排名的位置;
- 比如有 3 条记录排在第 1 位时,结果为:1 位、1 位、1 位、2 位;
- row_number:
- 直接排名,不考虑重复值;
- 比如有 3 条记录排在第 1 位时,结果为:1 位、2 位、3 位、4 位;
下面通过这条语句来看下这三个函数的区别:
select
product_name,
product_type,
sale_price,
rank() over (partition by product_type order by sale_price) as ranking,
dense_rank() over (partition by product_type order by sale_price) as dense_ranking,
row_number() over (partition by product_type order by sale_price) as row_number_ranking
from
product;
结果如下:
这类窗口函数最常用来解决的问题就是TopN问题,比如我们要求每个商品类别的价格前二高的商品和其价格:
select
product_type,
product_name,
sale_price,
ranking
from (
select
product_type,
product_name,
sale_price,
rank() over (partition by product_type order by sale_price desc) as ranking
from
product
) sub_table
where
ranking <= 2;
结果如下: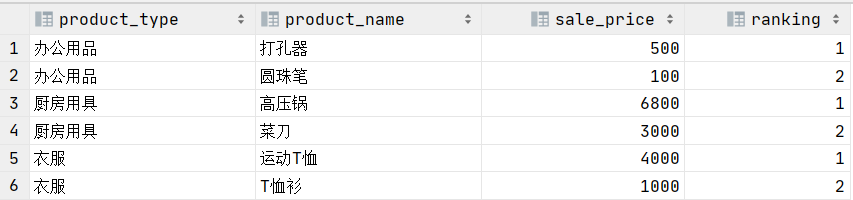
这里的关键点就是首先通过一个子查询求出每个窗口中的ranking,然后根据ranking过滤即可。
最后可以想一想,如果对于RANK函数,不增加 PARTITION BY 字段,会发生什么呢(不增加ORDER BY 很明显,就是所有列都是1,因为没指定排序列)?
这里就要回归开窗的定义,当我们不指定分区列时,整个表就相当于一个窗口,这里做的就是全表按特定列排序,比如下面的代码:
select
product_id,
product_type,
sale_price,
rank() over(order by sale_price desc) as rk
from
product;
得到的结果如下:
显然这是对表中所有的数据按价格生成了降序的排序。
4.1.2.2 聚合函数作为窗口函数
聚合函数(sum、avg、max和min等函数)在窗口函数中的使用方法和专用窗口函数基本一样,但是需要在函数的括号中指明聚合的列,他的结果是一个累计的聚合函数值。下面来看一个例子:
select
product_id,
product_name,
sale_price,
sum(sale_price) OVER (ORDER BY product_id) AS current_sum,
avg(sale_price) OVER (ORDER BY product_id) AS current_avg
from
product;
结果如下: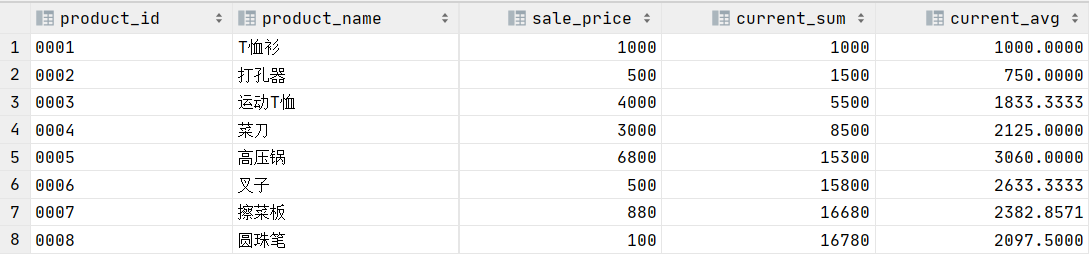
从结果中可以看到,该函数就是根据product_id进行排序,然后计算当前商品及之前所有的商品的总金额和平均金额,可以结合以下两张图片进一步理解:
4.1.2.3 窗口函数计算移动平均值
上一节中的聚合函数作为窗口函数使用时,计算的是累积到当前行的所有数据的聚合实际上,还可以指定更加详细的汇总范围。基本语法如下:
<窗口函数> OVER (ORDER BY <排序用列名> ROWS [BETWEEN] 一个时间点 [AND 另一个时间点]);
这里的时间点主要有以下几种:
- n PRECEDING:前 n 行;
- n FOLLOWING:后 n 行;
- CURRENT ROW:当前行;
- UNBOUNDED PRECEDING:窗口第一行;
- UNBOUNDED FOLLOWING:窗口的最后一行。
下面来看一个例子,执行以下语句:
select
product_id,
product_name,
sale_price,
sum(sale_price) OVER (ORDER BY product_id rows 2 preceding) AS current_sum,
avg(sale_price) OVER (ORDER BY product_id rows between 1 preceding and 1 following) AS current_avg
from
product;
结果如下: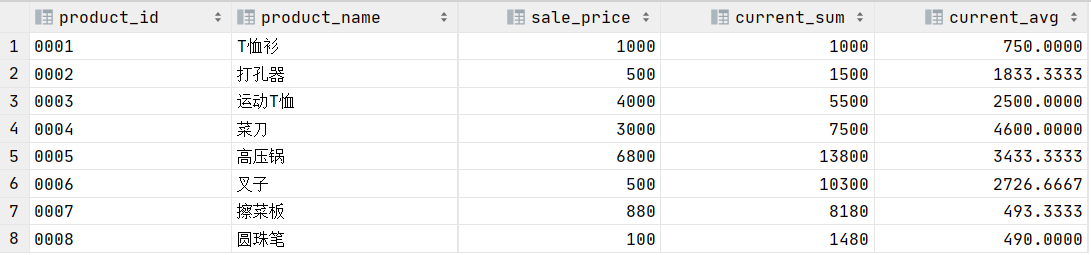
从结果可以看出该语句就是计算当前商品和前面两个商品的总价格,以及当前商品和前后两个商品的平均价格,具体可结合以下两图理解:
- 当前商品和前面两个商品的总价格:

- 当前商品和前后两个商品的平均价格:
-
4.2 GROUPING 运算符
之前学习的 GROUP BY 运算符是对不同的分组做一个汇总计算,但是当遇到合计或者小计等需求时,就不能使用了。此时虽然可以通过联合等方式求出想要的结果,但是代码太多了,并且往往需要执行多个 SELECT 语句,效率较差,因此引入了 GROUPING 运算符。目前 MySQL 仅支持GROUPING运算符,而 ClickHouse 支持三种运算符。
4.2.1 ROLL UP
常规的 GROUP BY 只能得到每个分类的小计,有时候还需要计算分类的合计,可以用 ROLLUP关键字来实现这一需求,下面来看一个案例:
select product_type, regist_date, sum(sale_price) as sum_price from product group by product_type, regist_date with rollup;结果如下:

可以看到,该语句计算了每一类物品的小计价格和合计价格。4.2.2 CUBE
CUBE关键字用于按照 GROUP BY 子句中聚合键的所有可能的组合结果做聚合。比如我们对A、B和C三个字段做聚合,最后得到的结果就是[[], [A], [B], [C], [A, B], [A, C], [B, C], [A, B, C]]。
4.2.3 GROUP SETS
GROUP SETS 关键字用于从 ROLLUP 和 CUBE 中的结果取出部分的记录,即将 CUBE 中所需聚合的列以参数的方式传入 GROUP SETS 中得到这些显示列的聚合结果。
4.3 存储过程和函数
存储过程程是一段可执行性代码的集合。其创建语句如下:
[delimiter //]($$,可以是其他特殊字符) CREATE [DEFINER = user] PROCEDURE sp_name ([proc_parameter [,...]]) [characteristic ...] [BEGIN] routine_body [END//]($$,可以是其他特殊字符)其中:
routine_body 由一个有效的SQL例程语句组成。它可以是一个简单的语句,如 SELECT 或 INSERT,或一个使用 BEGIN 和 END 编写的复合语句。复合语句可以包含声明、循环和其他控制结构语句。在实践中,存储函数倾向于使用复合语句,除非例程主体由一个 RETURN 语句组成;
- 存储过程和函数的参数有三类,分别是IN,OUT,INOUT,其中:
- IN 是入参。每个参数默认都是一个 IN 参数。如需设定一个参数为其他类型参数,请在参数名称前使用关键字 OUT 或 INOUT 。一个IN参数将一个值传递给一个过程。存储过程可能会修改这个值,但是当存储过程返回时,调用者不会看到这个修改。
- OUT 是出参。一个 OUT 参数将一个值从过程中传回给调用者。它的初始值在过程中是 NULL ,当过程返回时,调用者可以看到它的值。
- INOUT :一个 INOUT 参数由调用者初始化,可以被存储过程修改,当存储过程返回时,调用者可以看到存储过程的任何改变。

可以使用 CALL 语句调用一个存储过程。而要调用一个存储的函数时,则要在表达式中引用它。在表达式计算期间,该函数返回一个值。
对于每个 OUT 或 INOUT 参数,在调用过程的 CALL 语句中传递一个用户定义的变量,以便在过程返回时可以获得其值。如果你是在另一个存储过程或函数中调用存储过程,你也可以将一个常规参数或本地常规变量作为 OUT 或 INOUT 参数传递。如果从一个触发器中调用存储过程,也可以将 NEW.col_name 作为一个 OUT 或 INOUT 参数传递。
最后要注意的是一个存储例程与默认数据库相关联。要将该例程明确地与一个给定的数据库相关联,需要在创建该例程时将其名称指定为 db_name.sp_name。
4.4 预处理声明
MySQL 从4.1版本开始引入了 Prepare Statement 特性,使用 client/server binary protocol 代替 textual protocol,其将包含占位符()的查询传递给 MySQL 服务器,如以下示例所示:
SELECT *
FROM products
WHERE productCode = ?;
当MySQL使用不同的 productCode 值执行此查询时,它不必完全解析查询。因此,这有助于MySQL更快地执行查询,特别是当MySQL多次执行相同的查询时效果更明显。由于预准备语句使用占位符(),这有助于避免 SQL 注入的许多变体,从而使应用程序更安全。
基本语法如下:
PREPARE stmt_name FROM preparable_stmt
使用步骤如下:
- PREPARE – 准备需要执行的语句预处理声明。
- EXECUTE – 执行预处理声明。
- DEALLOCATE PREPARE – 释放预处理声明。
下图显示了预处理声明的使用过程:
下面来看一个例子,首先我们定义一个预处理声明:
prepare prep_stmt from
'select
product_id,
product_name
from
product
where
product_id = ?';
其次,声明变量pid代表商品编号,值为0005:
set @pid = ‘0005’;
然后,执行存储过程:
execute prep_stmt using @pid;
显示的结果如下:
最后释放预处理声明以释放其占用的资源:
deallocate prepare prep_stmt;
4.5 练习题
请输出以下语句得到的结果:
select product_id, product_name, sale_price, max(sale_price) over(order by product_id) as cur_max_price from product;该语句用于计算当前商品及其之前的商品的最大值,结果如下图所示:

计算出按照登记日期(regist_date)升序进行排列的各日期的销售单价(sale_price)的总额。排序是需要将登记日期为 NULL 的“运动 T 恤“记录排在第1位(也就是将其看作比其他日期都早)
语句如下:
select product_id, product_name, sale_price, regist_date, sum(sale_price) over(order by regist_date) as cur_sum_price from product;结果如下:

窗口函数不指定PARTITION BY的效果是什么?
- PARTITION BY 相当于把窗口函数的作用范围限制在根据PARTITION BY分割的多个窗口,不加该限制则类似于 GROUP BY 对全表进行操作。
为什么说窗口函数只能在SELECT子句中使用?
- 窗口函数是对 where 后的 group by 子句处理后的结果进行操作,因此按照SQL语句的运行顺序,窗口函数一般放在select子句中;
- SQL的执行顺序为 from -> where -> group by -> having -> select -> order by,因此在order by中使用则不会报错,而where则会报错(这也是为什么TopN查询需要使用子查询);
使用简洁的方法创建20个与 shop.product 表结构相同的表,如下图所示:
- 可以通过存储过程来实现这一操作,具体步骤如下:
- 创建一个存储过程: ``` create procedure create_test_table()
begin — 定义循环变量 declare num int; set num = 1;
-- 循环20遍
while num <= 20 do
set @table_name = concat('table', if(num < 10, concat('0', num), num));
-- 定义建表语句
set @sql_begin = 'create table if not exists ';
set @sql_end = ' like product;';
-- 拼接完整的sql语句
set @create_sql = concat(@sql_begin, @table_name, @sql_end);
-- 定义预处理过程
prepare create_table from @create_sql;
execute create_table;
deallocate prepare create_table;
set num = num + 1;
end while;
end;
call create_test_table();
- 执行:
```sql
call create_test_table
- 删除存储过程:
drop procedure create_test_table;
- 结果如下:

参考资料
- Wonderful-SQL:https://github.com/datawhalechina/wonderful-sql

若有收获,就点个赞吧
0 人点赞
