4. Flink Table&SQL
4.1 简介
Flink 的 Table 模块包括 Table API 和 SQL:
- Table API 是一种类SQL的API,通过Table API,用户可以像操作表一样操作数据,非常直观和方便;
- SQL作为一种声明式语言,有着标准的语法和规范,用户可以不用关心底层实现即可进行数据的处理,非常易于上手;
- 这两者有80%的代码是共用的。作为一个流批统一的计算引擎,Flink 的 Runtime 层是统一的。
Table API & SQL的特点:
- 声明式:属于设定式语言,用户只要表达清楚需求即可,不需要了解底层执行;
- 高性能:可优化,内置多种查询优化器,这些查询优化器可为 SQL 翻译出最优执行计划;
- 简单易学:易于理解,不同行业和领域的人都懂,学习成本较低;
- 标准稳定:语义遵循SQL标准,非常稳定,在数据库 30 多年的历史中,SQL 本身变化较少;
- 流批统一:可以做到API层面上流与批的统一,相同的SQL逻辑,既可流模式运行,也可批模式运行,Flink底层Runtime本身就是一个流与批统一的引擎。
4.2 核心概念
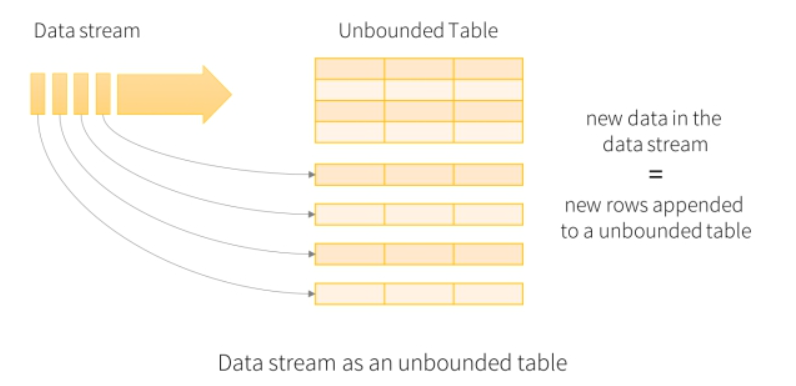
- 动态表(Dynamic Table):
- 无界流的表,即表是不断变化的;
- 可以把它理解为建立一个逻辑结构,这个逻辑结构需要映射到数据上去,随着数据不断流入,就好像往表中不断增加数据一样;
- image-20220430152447760
- 连续查询(Continuous Queries)—— 需要借助State:
- 对于有源源不断的数据流入动态表,我们基于这个数据流建立了一张表,再编写SQL语句查询数据,进行处理。这个SQL语句一定是不断地执行的,而不是只执行一次。于是这种查询操作称为连续查询;
- 由于动态表是实时变化的,因此连续查询每一次查询出来的数据也是不断变化的。

4.3 API
- 相关依赖:
org.apache.flink
flink-table-api-scala-bridge_2.12
1.12.0
org.apache.flink
flink-table-api-java-bridge_2.12
1.12.0 - 程序结构:

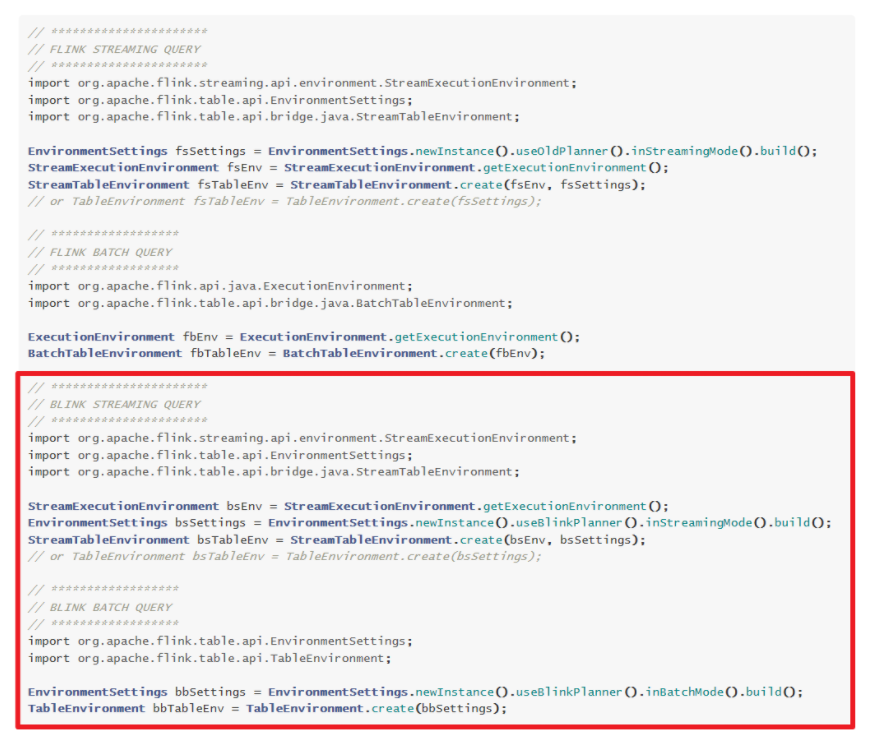
- 创建环境
- image-20220430162905677
- 创建表

- image-20220430162922782
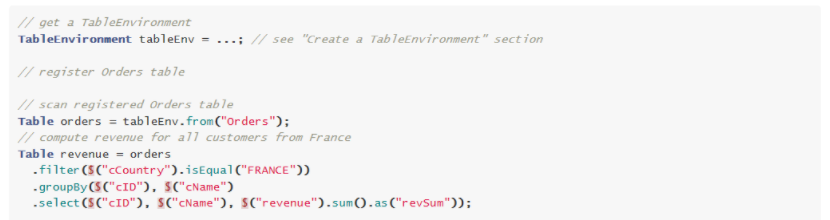
- 查询
- Table API
- image-20220430163005201
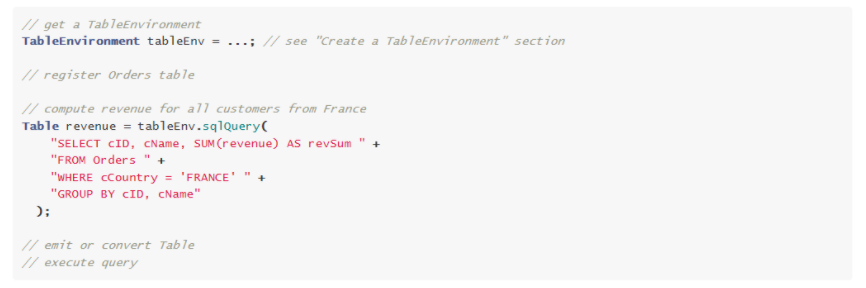
- SQL
- image-20220430163023333
4.4 案例1 —— 将DataStream转换为Table和View并进行SQL统计
package org.example.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Arrays;
import static org.apache.flink.table.api.Expressions.$;
public class TableAndSQL {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
// table环境
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
// source<br /> DataStreamSource<Order> orderA = env.fromCollection(<br /> Arrays.asList(<br /> new Order(1L, "beer", 3),<br /> new Order(1L, "diaper", 3),<br /> new Order(3L, "rubber", 3)<br /> ));DataStreamSource<Order> orderB = env.fromCollection(<br /> Arrays.asList(<br /> new Order(2L, "pen", 3),<br /> new Order(2L, "rubber", 3),<br /> new Order(4L, "beer", 1)<br /> ));// transformation<br /> // 将DataStream数据转Table和View,然后查询<br /> Table tableA = tenv.fromDataStream(orderA, $("user"), $("product"), $("amount"));<br /> tableA.printSchema();<br /> System.out.println(tableA);tenv.createTemporaryView("tableB", orderB, $("user"), $("product"), $("amount"));// 查询 tableA 中 amount>2 的和 tableB 中 amount>1 的数据并合并<br /> // 注意表名和where间一定要有空格<br /> String sql = "select * from " + tableA + " where amount > 2 \n" +<br /> "union \n" +<br /> "select * from tableB where amount > 1";Table resultTable = tenv.sqlQuery(sql);<br /> resultTable.printSchema();<br /> System.out.println(resultTable);// 将Table转成DataStream<br /> // union all 则用 toAppendStream<br /> // toAppendStream → 将计算后的数据append到结果DataStream中去<br /> // toRetractStream → 将计算后的新的数据在DataStream原数据的基础上更新true或是删除false<br /> // 类似StructuredStreaming中的append/update/complete<br /> DataStream<Tuple2<Boolean, Order>> resultDS = tenv.toRetractStream(resultTable, Order.class);// sink<br /> resultDS.print();// 启动并等待结束<br /> env.execute();<br /> }@Data<br /> @NoArgsConstructor<br /> @AllArgsConstructor<br /> public static class Order {<br /> private Long user;<br /> private String product;<br /> private int amount;<br /> }<br />}<br />
4.5 案例2 —— 使用Table/DSL风格和SQL风格完成WordCount
package org.example.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.util.Collector;
import static org.apache.flink.table.api.Expressions.$;
public class WordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
DataStreamSource<String> lines = env.fromElements("hadoop spark flink", "kafka flume", "flink spark java");<br /> SingleOutputStreamOperator<WordAndOne> wordAndOne = lines.flatMap(<br /> new FlatMapFunction<String, WordAndOne>() {<br /> @Override<br /> public void flatMap(String s, Collector<WordAndOne> collector) throws Exception {<br /> String[] arr = s.split(" ");<br /> for (String word : arr) {<br /> collector.collect(new WordAndOne(word, 1));<br /> }<br /> }<br /> });tenv.createTemporaryView("t_words", wordAndOne, $("word"), $("frequency"));String sql = "select word, sum(frequency) as frequency from t_words group by word";Table resultTable = tenv.sqlQuery(sql);// 转为DataStream<br /> DataStream<Tuple2<Boolean, WordAndOne>> resultDS = tenv.toRetractStream(resultTable, WordAndOne.class);// Sink<br /> resultDS.print();env.execute();}@Data<br /> @AllArgsConstructor<br /> @NoArgsConstructor<br /> public static class WordAndOne {<br /> private String word;<br /> private Integer frequency;<br /> }<br />}<br />DSL风格的代码如下:<br />package org.example.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.util.Collector;
import static org.apache.flink.table.api.Expressions.$;
public class WordCountWithDSL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
DataStreamSource<String> lines = env.fromElements("hadoop spark flink", "kafka flume", "flink spark java");<br /> SingleOutputStreamOperator<WordAndOne> wordAndOne = lines.flatMap(<br /> new FlatMapFunction<String, WordAndOne>() {<br /> @Override<br /> public void flatMap(String s, Collector<WordAndOne> collector) throws Exception {<br /> String[] arr = s.split(" ");<br /> for (String word : arr) {<br /> collector.collect(new WordAndOne(word, 1));<br /> }<br /> }<br /> });Table table = tenv.fromDataStream(wordAndOne);// DSL风格: 过滤出数量为2的单词<br /> Table resultTable = table<br /> .groupBy($("word"))<br /> .select($("word"), $("frequency").sum().as("frequency"))<br /> .filter($("frequency").isEqual(2));<br /> resultTable.printSchema();// 转为DataStream<br /> DataStream<Tuple2<Boolean, WordAndOne>> resultDS = tenv.toRetractStream(resultTable, WordAndOne.class);// Sink<br /> resultDS.print();env.execute();}@Data<br /> @AllArgsConstructor<br /> @NoArgsConstructor<br /> public static class WordAndOne {<br /> private String word;<br /> private Integer frequency;<br /> }<br />}<br />
4.6 案例3 —— 结合窗口和Watermarker
需求:使用Flink SQL统计5秒内每个用户的订单总数、订单的最大金额和订单的最小金额
提示:每隔5秒统计5秒内的相关信息,可以使用基于时间的滚动窗口实现
package org.example.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import java.time.Duration;
import java.util.Random;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
import static org.apache.flink.table.api.Expressions.$;
public class Statistics {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
// Source<br /> DataStreamSource<Order> orderDS = env.addSource(<br /> new RichSourceFunction<Order>() {<br /> private boolean flag = true;@Override<br /> public void run(SourceContext<Order> sourceContext) throws Exception {<br /> Random random = new Random();<br /> while (flag) {<br /> Order order = new Order(<br /> UUID.randomUUID().toString(),<br /> random.nextInt(3),<br /> random.nextInt(101),<br /> System.currentTimeMillis()<br /> );<br /> TimeUnit.SECONDS.sleep(1);<br /> sourceContext.collect(order);<br /> }<br /> }@Override<br /> public void cancel() {<br /> flag = false;<br /> }<br /> });// transformation<br /> SingleOutputStreamOperator<Order> orderDSWithWatermark = orderDS.assignTimestampsAndWatermarks(<br /> WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(5))<br /> .withTimestampAssigner((order, recordTimestamp) -> order.getCreateTime()));tenv.createTemporaryView("t_order", orderDSWithWatermark, $("orderId"), $("userId"), $("money"), $("createTime").rowtime());String sql = "select userId, count(orderId) as orderCount, max(money) as maxMoney, min(money) as minMoney \n" +<br /> "from t_order\n" +<br /> "group by userId, \n" +<br /> // 时间窗口<br /> "tumble(createTime, INTERVAL '5' SECOND)";Table resultTable = tenv.sqlQuery(sql);<br /> resultTable.printSchema();DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(resultTable, Row.class);resultDS.print();env.execute();<br /> }@Data<br /> @NoArgsConstructor<br /> @AllArgsConstructor<br /> public static class Order {<br /> private String orderId;<br /> private Integer userId;<br /> private Integer money;<br /> private Long createTime;<br /> }<br />}<br />DSL的写法如下:<br />package org.example.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import java.time.Duration;
import java.util.Random;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.lit;
public class StatisticsWithDSL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
// Source<br /> DataStreamSource<Order> orderDS = env.addSource(<br /> new RichSourceFunction<Order>() {<br /> private boolean flag = true;@Override<br /> public void run(SourceContext<Order> sourceContext) throws Exception {<br /> Random random = new Random();<br /> while (flag) {<br /> Order order = new Order(<br /> UUID.randomUUID().toString(),<br /> random.nextInt(3),<br /> random.nextInt(101),<br /> System.currentTimeMillis()<br /> );<br /> TimeUnit.SECONDS.sleep(1);<br /> sourceContext.collect(order);<br /> }<br /> }@Override<br /> public void cancel() {<br /> flag = false;<br /> }<br /> });// transformation<br /> SingleOutputStreamOperator<Order> orderDSWithWatermark = orderDS.assignTimestampsAndWatermarks(<br /> WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(5))<br /> .withTimestampAssigner((order, recordTimestamp) -> order.getCreateTime()));tenv.createTemporaryView("t_order", orderDSWithWatermark, $("orderId"), $("userId"), $("money"), $("createTime").rowtime());Table resultTable = tenv.from("t_order")<br /> // 采用方法的方式设置窗口<br /> .window(Tumble.over(lit(5).second())<br /> .on($("createTime"))<br /> .as("tumbleWindow"))<br /> // 按用户id和窗口进行聚合<br /> .groupBy($("tumbleWindow"), $("userId"))<br /> .select(<br /> $("userId"),<br /> $("orderId").count().as("orderCount"),<br /> $("money").max().as("maxMoney"),<br /> $("money").min().as("minMoney")<br /> );resultTable.printSchema();DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(resultTable, Row.class);resultDS.print();env.execute();<br /> }@Data<br /> @NoArgsConstructor<br /> @AllArgsConstructor<br /> public static class Order {<br /> private String orderId;<br /> private Integer userId;<br /> private Integer money;<br /> private Long createTime;<br /> }<br />}<br />
4.7 案例4 —— 整合Kafka
需求:从Kafka中消费数据,并过滤出状态为Success的数据并写入Kafka
示例数据如下:
{“user_id”: “1”, “page_id”:”1”, “status”: “success”}
{“user_id”: “1”, “page_id”:”1”, “status”: “success”}
{“user_id”: “1”, “page_id”:”1”, “status”: “success”}
{“user_id”: “1”, “page_id”:”1”, “status”: “success”}
{“user_id”: “1”, “page_id”:”1”, “status”: “fail”}
package org.example.sql;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class KafkaDemo {
public static void main(String[] args) throws Exception {
// Environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
// Source<br /> TableResult inputTable = tenv.executeSql(<br /> "CREATE TABLE input_kafka (\n" +<br /> " `user_id` BIGINT,\n" +<br /> " `page_id` BIGINT,\n" +<br /> " `status` STRING\n" +<br /> ") WITH (\n" +<br /> " 'connector' = 'kafka',\n" +<br /> " 'topic' = 'input_kafka',\n" +<br /> " 'properties.bootstrap.servers' = 'node01:9092',\n" +<br /> " 'properties.group.id' = 'testGroup',\n" +<br /> " 'scan.startup.mode' = 'latest-offset',\n" +<br /> " 'format' = 'json'\n" +<br /> ")"<br /> );// Transformation<br /> // 过滤出状态为 Success的数据<br /> String sql = "select * from input_kafka where status = 'success' ";<br /> Table etlTable = tenv.sqlQuery(sql);// Sink<br /> DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(etlTable, Row.class);<br /> resultDS.print();TableResult outputTable = tenv.executeSql(<br /> "CREATE TABLE output_kafka (\n" +<br /> " `user_id` BIGINT,\n" +<br /> " `page_id` BIGINT,\n" +<br /> " `status` STRING\n" +<br /> ") WITH (\n" +<br /> " 'connector' = 'kafka',\n" +<br /> " 'topic' = 'output_kafka',\n" +<br /> " 'properties.bootstrap.servers' = 'node01:9092',\n" +<br /> " 'format' = 'json',\n" +<br /> " 'sink.partitioner' = 'round-robin'\n" +<br /> ")"<br /> );tenv.executeSql("insert into output_kafka select * from " + etlTable);// 启动并等待结束<br /> env.execute();<br /> }<br />}<br />执行步骤如下:
- 启动zk和kafka
- 准备Kafka主题
- /export/servers/kafka-2.11/bin/kafka-topics.sh —create —zookeeper node01:2181 —replication-factor 2 —partitions 3 —topic input_kafka
- /export/servers/kafka-2.11/bin/kafka-topics.sh —create —zookeeper node01:2181 —replication-factor 2 —partitions 3 —topic output_kafka
- 启动生产者和消费者
- /export/servers/kafka-2.11/bin/kafka-console-producer.sh —broker-list node01:9092 —topic input_kafka
- /export/servers/kafka-2.11/bin/kafka-console-consumer.sh —bootstrap-server node01:9092 —topic output_kafka —from-beginning
- 启动程序并向生产者输入以下数据
- {“user_id”: “1”, “page_id”:”1”, “status”: “success”}
{“user_id”: “1”, “page_id”:”1”, “status”: “success”}
{“user_id”: “1”, “page_id”:”1”, “status”: “success”}
{“user_id”: “1”, “page_id”:”1”, “status”: “success”}
{“user_id”: “1”, “page_id”:”1”, “status”: “fail”}
4.8 整合Hive
4.8.1 Flink集成Hive的基本方式
主要体现在两个方面:
- 持久化元数据:
- Flink 利用 Hive 的 MetaStore 作为持久化的 Catalog ;
- 可以通过 HiveCatalog 将不同会话中的 Flink 元数据存储到 Hive MetaStore中;
- 比如可以使用 HiveCatalog 将其 Kafka 的数据源表存储在 Hive Metastore 中,这样该表的元数据信息会被持久化到 Hive 的 MetaStore 对应的元数据库中,在后续的 SQL 查询中,我们可以重复使用它们。
- 利用Flink读写Hive的表:
- Flink 打通了与 Hive 的集成,如同使用 SparkSQL 操作 Hive 中的数据一样,可以使用 Flink 直接读写 Hive 中的表;
- HiveCatalog 的设计提供了与 Hive 良好的兼容性,用户可以”开箱即用”的访问其已有的 Hive 表。不需要修改现有的 Hive Metastore,也不需要更改表的数据位置或分区。
4.8.2 配置
(待补充)

若有收获,就点个赞吧
0 人点赞
