++++++++ ++++How to Choose the MySQL innodb_log_file_size
Peter Zaitsev | October 18, 2017 | Posted In: InnoDB, Insight for DBAs, MySQL
在这篇博客里,我将介绍怎么设置MySQL innodb_log_file_size大小。
In this blog post, I’ll provide some guidance on how to choose the MySQL innodb_log_file_size.
当使用默认的innodb存储引擎时,MySQL也像很多数据库管理系统那样使用日志持久性归档数据。这将确保一个事务提交后,数据不会在崩溃或者断电事件中丢失。
Like many database management systems, MySQL uses logs to achieve data durability (when using the default InnoDB storage engine). This ensures that when a transaction is committed, data is not lost in the event of crash or power loss.
MySQL的Innodb存储引擎使用一个固定的循环使用的redo log空间。 它的大小由innodb_log_file_size 和 innodb_log_files_in_group (默认为2)这两个参数控制。你可以统计两个参数的值相乘得到redo log实际可以用的空间大小。从技术上,你通过改变innodb_log_file_size或者innodb_log_files_in_group 参数来控制redo空间大小是没用的。大部分人只使用innodb_log_file_size,只留下innodb_log_files_in_group。(尽管从技术上讲,你可以通过改变innodb log file_size或innodb_log_file_in_group参数来控制redo空间的大小,但大多数人只是使用innodb_log_file_size参数,而不使用innodb_log_file_in_group。)
MySQL’s InnoDB storage engine uses a fixed size (circular) Redo log space. The size is controlled by innodb_log_file_size and innodb_log_files_in_group (default 2). You multiply those values and get the Redo log space that available to use. ++While technically it shouldn’t matter whether you change either the innodb_log_file_size or innodb_log_files_in_group variable to control the Redo space size, most people just work with the innodb_log_file_size and leave innodb_log_files_in_group alone.++
对于主要以写为主的工作环境Innodb存储引擎的redo空间是一项很重要的配置选项。然而,它是有代价的。你配置的越大,写IO优化越好,但是增加redo空间也意味着当系统断电或其它原因崩溃时恢复的时间也会更长。
Configuring InnoDB’s Redo space size is one of the most important configuration options for write-intensive workloads. However, it comes with trade-offs. The more Redo space you have configured, the better InnoDB can optimize write IO. However, increasing the Redo space also means longer recovery times when the system loses power or crashes for other reasons.
给定 innodb_log_file_size值去估计一次系统故障恢复任务花费的时间是不容易也不明确的。它取决于硬件,MySQL版本及工作负载。它变化范围比较大。(10倍或更大变化,取决于具体情况)。然而,五分钟左右生成一个 1G的 innodb_log_feile_size 是一个比较合适的值。如果这个参数对你的环境真的非常重要,我建议模拟在全负载(在数据库已经完全预热)下系统崩溃来测试它。
It is not easy or straightforward to predict how much time a system crash recovery takes for a specific innodb_log_file_size value – it depends on the hardware, MySQL version and workload. It can vary widely (10 times difference or more, depending on the circumstances). However, around five minutes per 1GB of innodb_log_file_size is a decent ballpark number. If this is really important for your environment, I would recommend testing it by a simulating system crash under full load (after the database has completely warmed up).
使用恢复时间作为参考来限定Innodb 重做日志的值的同时,也可以通过一些其它方法看到这个数字。尤其是你已经安装了PMM.
While recovery time can be a guideline for the limit of the InnoDB Log File size, there are a couple of other ways you can look at this number – especially if you have Percona Monitoring and Management installed.
查看PMM中的””MySQL Innodb 指标”仪表盘,如果你看到如下图:
Check Percona Monitoring and Management’s “MySQL InnoDB Metrics” Dashboard. If you see a graph like this:
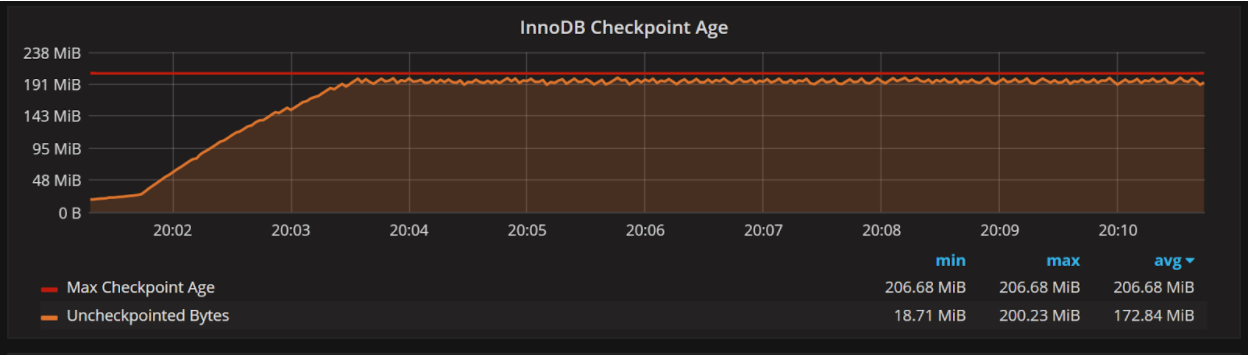
可以看到Uncheckpointed Bytes值已经非常接近Max Checkpoint Age,你可以肯定当前的innodb_log_file_size值已经限制了系统的性能。增大它可以带来实质的性能提升。
where Uncheckpointed Bytes is pushing very close to the Max Checkpoint Age, you can almost be sure your current innodb_log_file_size is limiting your system’s performance. Increasing it can provide substantial performance improvements.
如果你看到的是这样的: If you see something like this instead:
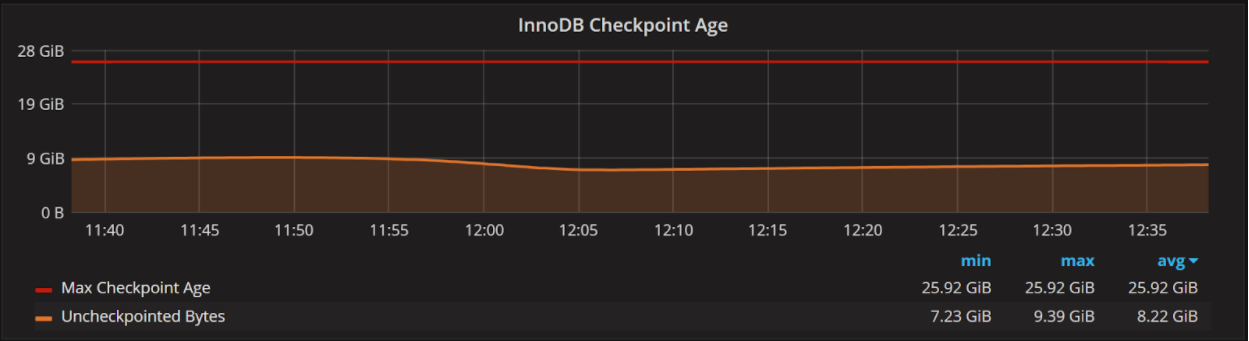
当Uncheckpointed Bytes值远低于Max Checkpoint Age值,增家日志文件的大小不会带来明显的性能提升。
where the number of Uncheckpointed Bytes is well below the Max Checkpoint Age, then increasing the log file size won’t give you a significant improvement.
注意:很多MySQL配置参数是关联的。一个特定的日志文件大小对于小的innodb_buffer_pool_size来说是足够的,大的innodb_buffer_pool值可能需要更大的日志文件来提升性能。
Note: many MySQL settings are interconnected. While a specific log file size might be good enough for smaller innodb_buffer_pool_size, larger InnoDB Buffer Pool values might warrant larger log files for optimal performance.
另外需要注意的是:我们早期提到的恢复时间是依赖Uncheckpointed Bytes而不是总的日志文件大小。如果你没有看到恢复时间随着更大的innodb_log_file_size值而增加,请查看innodb checkpoint age 图:可能是你在你的工作负载和配置下没有达到充分的利用大的日志文件大小。
Another thing to keep in mind: the recovery time we spoke about early really depends on the Uncheckpointed Bytes rather than total log file size. If you do not see recovery time increasing with a larger innodb_log_file_size, check out InnoDB Checkpoint Age graph – it might be you just can’t fully utilize large log files with your workload and configuration.
查看日志文件大小的另外一种方法是查看日志空间使用情况
Another way to look at the log file size is in context of log space usage:
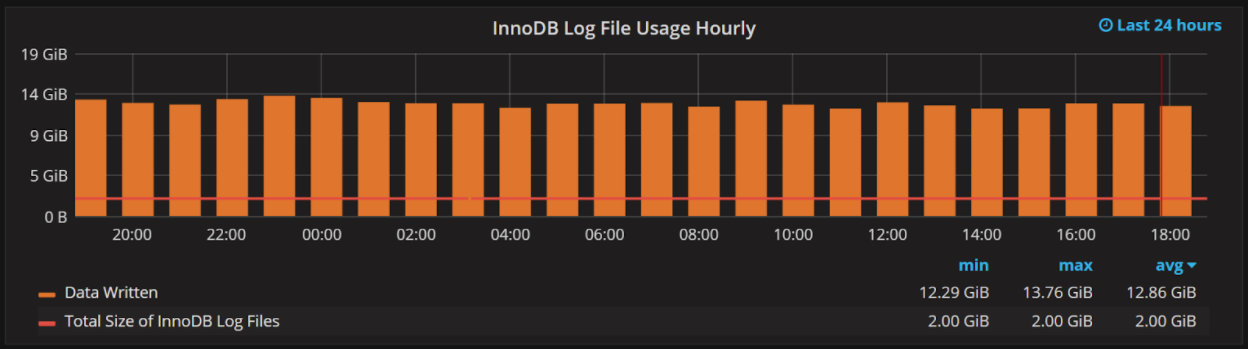
这种图展示了每小时写入innodb日志文件的数据量,以及总的innodb日志文件大小。在上图中,我们可以看到日志空间大小为2G,每小时写入日志文件的数据量为12G。这意味着我们每10分钟循环使用一次。
This graph shows the amount of Data Written to the InnoDB log files per hour, as well as the total size of the InnoDB log files. In the graph above, we have 2GB of log space and some 12GB written to the Log files per hour. This means we cycle through logs every ten minutes.
Innodb在每次循环周期中中至少要刷新一次在缓冲池中的每个脏页。
InnoDB has to flush every dirty page in the buffer pool at least once per log file cycle time.
Innodb在不那么频繁刷新的情况下得到更好的性能,并且在ssd设备上损耗更小。我觉得这个值在15分钟以上或1个小时更好了。
InnoDB gets better performance when it does that less frequently, and there is less wear and tear on SSD devices. I like to see this number at no less than 15 minutes. One hour is even better.
总结
Summary
得到innodb_log_file_file的大小对于获得合理的快速恢复时间和好的系统性能之间的平衡是很重要的。记住,你的恢复时间并不是你想象的不重要。我希望在这篇博客中描述的技术可以帮助你找到适合你的情况的最佳值。
Getting the innodb_log_file_file size is important to achieve the balance between reasonably fast crash recovery time and good system performance. Remember, your recovery time objective it is not as trivial as you might imagine. I hope the techniques described in this post help you to find the optimal value for your situation!

若有收获,就点个赞吧
0 人点赞
