管理 Apache Geode
管理 Apache Geode 描述如何规划和实现与Apache Geode的管理,监视和故障排除相关的任务。
-
Apache Geode提供用于管理集群和监视集群成员运行状况的API和工具。
-
默认情况下,Apache Geode使用JVM堆。 Apache Geode还提供了一种从堆中存储数据的选项。 本节介绍如何管理堆和堆外内存以最好地支持您的应用程序。
-
使用Apache Geode磁盘存储,您可以将数据保存到磁盘,作为内存中副本的备份,并在内存使用过高时将数据溢出到磁盘。
-
快照允许您保存区域数据并在以后重新加载。 典型的用例是将数据从一个环境加载到另一个环境,例如从生产系统捕获数据并将其移动到较小的QA或开发系统中。
-
本节介绍区域压缩,其优点和用法。
-
Apache Geode体系结构和管理功能有助于检测和解决网络分区问题。
-
安全框架通过在连接时验证组件和成员来建立信任。 它有助于操作的授权。
-
一组工具和控件允许您监视和调整Apache Geode性能。
-
全面的日志消息可帮助您确认配置和代码中的系统配置和调试问题。
-
集群中的每个应用程序和服务器都可以访问有关Apache Geode操作的统计数据。 您可以使用
gfsh的alter runtime命令或gemfire.properties文件来配置统计信息的收集,以便于系统分析和故障排除。 -
本节提供了处理常见错误和故障情况的策略。
Apache Geode管理和监控
Apache Geode提供用于管理集群和监控成员运行状况的API和工具。
管理和监控功能
Apache Geode使用联合Open Open MBean策略来管理和监视集群的所有成员。 此策略为您提供集群的统一单代理视图。
Geode管理和监控工具概述
Geode提供了各种管理工具,可用于管理Geode集群。
架构和组件
Geode的管理和监视系统由一个JMX Manager节点(应该只有一个)和一个集群中的一个或多个受管节点组成。 集群中的所有成员都可通过MBean和Geode Management Service API进行管理。
JMX管理器操作
任何成员都可以托管嵌入式JMX Manager,它提供集群的所有MBean的联合视图。 通过在ManagementService上调用相应的API调用,可以将成员配置为在启动时或在其生命中的任何时间成为管理器。
联合MBean架构
Geode使用MBean来管理和监控Geode的不同部分。 Geode的联合MBean架构是可扩展的,允许您拥有Geode集群的单代理视图。
配置RMI注册表端口和RMI连接器
Geode以编程方式模拟Java提供的开箱即用的JMX,并在所有可管理成员上创建带有RMI Registry和RMI Connector端口的JMXServiceURL。
通过Management API执行gfsh命令
您还可以使用管理API以编程方式执行gfsh命令。
管理和监控功能
Apache Geode使用联合Open Open MBean策略来管理和监视集群的所有成员。 此策略为您提供集群的统一单代理视图。
应用程序和管理器开发更容易,因为您不必在MBean上找到正确的MBeanServer来发出请求。 相反,您与单个MBeanServer交互,该MBeanServer从所有其他本地和远程MBeanServers聚合MBean。
Geode管理架构的其他一些关键优势和特性:
- Geode监控紧密集成到Geode的流程中,而不是在单独安装和配置的监控代理中运行。 您可以使用相同的框架来实际管理Geode并执行管理操作,而不仅仅是监控它。
- 所有Geode MBean都是MXBeans。 它们代表有关集群状态及其所有成员的有用且相关的信息。 由于MXBeans将Open MBean模型与预定义的一组类型一起使用,因此客户端和远程管理程序不再需要访问表示MBean类型的特定于模型的类。 使用MXBeans可以为您选择的客户端增加灵活性,并使Geode管理和监控更容易使用。
- 集群中的每个成员都可以通过MXBeans进行管理,每个成员在Platform MBeanServer中托管自己的MXBean。
- 可以将任何Geode成员配置为为Geode集群中的所有成员提供所有MXBean的联合视图。
- Geode还将JMX的使用修改为行业标准,并且对通用JMX客户端友好。 您现在可以使用任何符合JMX的第三方工具轻松监控或管理集群。 例如,JConsole。
参考
有关MXBeans和Open MBean的更多信息,请参阅:
- http://docs.oracle.com/javase/8/docs/api/javax/management/MXBean.html
- http://docs.oracle.com/javase/8/docs/api/javax/management/openmbean/package-summary.html
Geode管理和监控工具概述
Geode提供了各种管理工具,可用于管理Geode集群。
Geode管理和监视工具允许您配置集群的所有成员和进程,监视系统中的操作以及启动和停止成员。 在内部,Geode使用Java MBean(特别是MXBeans)来公开管理控件和监视功能。 您可以通过编写使用这些MXBeans的Java程序来监视和控制Geode,也可以使用Geode提供的几种工具之一来监视和管理您的集群。 这些任务的主要工具是gfsh命令行工具,如本节所述。
Geode提供以下工具来管理Geode安装:
gfsh命令行工具
gfsh命令行工具提供了一组用于配置,管理和监视集群的命令。 gfsh是管理集群的推荐工具。
使用gfsh:
- 启动和停止Geode进程,例如定位器和缓存服务器
- 部署应用程序
- 创建和销毁区域
- 执行函数
- 管理磁盘存储
- 导入和导出数据
- 监控Geode流程
- 启动Geode监控工具
- 关闭集群
- 编写涉及Geode成员的各种操作
- 保存集群的所有成员的配置
gfsh在它自己的shell中运行,或者你可以直接从OS命令行执行gfsh命令。 gfsh可以与远程系统交互使用http协议。 您还可以编写在gfsh shell中运行的脚本以自动启动系统。
您可以使用gfsh为集群创建共享集群配置。 您可以定义适用于整个集群的配置,或仅适用于类似组的配置
架构和组件
Geode的管理和监视系统由一个JMX Manager节点(应该只有一个)和一个集群中的一个或多个受管节点组成。 集群中的所有成员都可通过MBean和Geode Management Service API进行管理。
架构
下图描绘了管理和监视系统组件的体系结构。
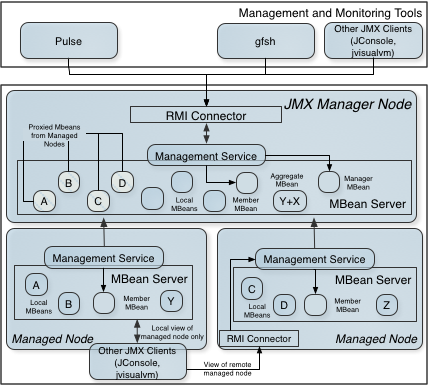
在这个架构中,每个Geode成员都是可管理的。 本地Geode进程的所有Geode MBean都自动注册在Platform MBeanServer(托管平台MXBeans的每个JVM的默认MBeanServer)中。
受管节点
群集的每个成员都是一个受管节点。 当前未同时充当JMX Manager节点的任何节点都简称为受管节点。 受管节点具有以下资源,因此它可以在本地和远程回答JMX查询:
- 代表节点上本地监视的组件的本地MXBean。 请参阅Geode JMX MBean列表,以获取受管节点现有的可能MXBean列表。
- 内置平台MBeans。
JMX Manager Node
JMX Manager节点是可以管理其他Geode成员(即其他受管节点)以及自身的成员。 JMX Manager节点可以管理集群中的所有其他成员。
要将受管节点转换为JMX Manager节点,请在gemfire.properties文件中配置Geode属性jmx-manager = true,并将该成员作为JMX Manager节点启动。
当您将-J=-Dgemfire.jmx-manager=true作为start server或start locator命令的参数提供时,可以将该成员作为JMX Manager节点启动。 有关详细信息,请参阅启动JMX Manager。
JMX Manager节点分配了以下额外资源,以便它可以回答JMX查询:
- RMI连接器,允许JMX客户端连接并访问集群中的所有MXBean。
- Local MXBean,表示此节点上本地监视的组件,与任何其他受管节点相同。
- Aggregate MXBeans:
- DistributedSystemMXBean
- DistributedRegionMXBean
- DistributedLockServiceMXBean
- 具有Scope=ALL的ManagerMXBean,它允许各种集群范围的操作。
- 受管节点上的MXBeans代理。
- 内置平台MXBeans。
JMX集成
管理和监视工具(如gfsh命令行界面和Pulse)使用JMX/RMI作为连接到Geode节点的通信层。 默认情况下,所有Geode进程都允许从localhost到Platform MBeanServer的JMX连接。 默认情况下,受管节点和JMX管理器节点都启用了RMI连接器以允许JMX客户端连接。
JConsole(以及支持Sun的Attach API的其他类似JMX客户端)可以通过使用Attach API连接到任何本地JVM,而无需RMI连接器。 这允许来自同一台机器的连接。
如果JVM配置为启动RMI连接器,则JConsole(和其他JMX客户端)可以连接到任何JVM。 这允许来自其他机器的远程连接。
JConsole可以连接到任何Geode成员,但如果它连接到非JMX-Manager成员,则JConsole仅检测节点的本地MBean,而不检测集群的MBean。
当Geode定位器或服务器成为集群的JMX Manager时,它将启用RMI连接器。 然后,JConsole只能连接到那个JVM,以查看整个集群的MBean。 它不需要连接到所有其他JVM。 Geode管理提供集群中所有MBean的联合视图所需的JVM间通信。
gfsh只能连接到JMX Manager或定位器。 如果连接到定位器,定位器将为现有JMX Manager提供必要的连接信息。 如果定位器检测到JMX Manager尚未在集群中运行,则定位器使自己成为JMX Manager。 gfsh无法连接到其他非Manager或非定位器成员。
有关如何配置RMI注册表和RMI连接器的信息,请参阅配置RMI注册表端口和RMI连接器。
管理API
Geode管理API代表JMX用户的Geode集群。 但是,它们不提供JMX中存在的功能。 它们仅为Geode监控和管理提供的各种服务提供网关。
Geode管理的入口点是通过ManagementService接口。 例如,要创建Management Service的实例:
ManagementService service = ManagementService.getManagementService(cache);
生成的ManagementService实例特定于提供的缓存及其集群。 getManagementService的实现现在是一个单例,但最终可能支持多个缓存实例。
您可以使用Geode管理API来完成以下任务:
- 监控客户端的健康状态。
- 获取单个磁盘备份的状态和结果。
- 查看与特定成员的磁盘使用情况和性能相关的指标。
- 浏览为特定成员设置的Geode属性。
- 查看JVM指标,例如内存,堆和线程使用情况。
- 查看网络指标,例如接收和发送的字节数。
- 查看分区区域属性,例如存储区总数,冗余副本和最大内存信息。
- 查看持久成员信息,例如磁盘存储区ID。
- 浏览区域属性。
请参阅org.apache.geode.managementJavaDocs获得更多细节。
您还可以使用ManagementService API执行gfsh命令。 请参阅通过Management API执行gfsh命令和org.apache.geode.management.cli的JavaDocs。
Geode管理和监控工具
本节列出了当前可用于管理和监控Geode的工具:
- gfsh. Apache Geode命令行界面,提供简单而强大的命令shell,支持Geode应用程序的管理,调试和部署。 它具有上下文相关帮助,脚本以及使用简单API从应用程序内调用任何命令的功能。 见gfsh。
- Geode Pulse. 易于使用的基于浏览器的仪表板,用于监控Geode部署。 Geode Pulse提供集群中所有Geode成员的集成视图。 请参阅Geode Pulse。
- Pulse Data Browser. 此Geode Pulse实用程序提供了一个图形界面,用于在Geode集群中执行OQL即席查询。 请参阅数据浏览器。
- Other Java Monitoring Tools such as JConsole and jvisualvm.JConsole是Java 2平台中提供的基于JMX的管理和监视工具,它提供有关Java应用程序的性能和资源消耗的信息。 请参阅http://docs.oracle.com/javase/6/docs/technotes/guides/management/jconsole.html。 Java VisualVM (jvisualvm) 是一个用于分析Java虚拟机的分析工具。 Java VisualVM对Java应用程序开发人员有用,可以对应用程序进行故障排除,并监视和改进应用程序的性能。 Java VisualVM可以允许开发人员生成和分析堆转储,跟踪内存泄漏,执行和监视垃圾收集,以及执行轻量级内存和CPU分析。 有关使用jvisualvm的更多详细信息,请参阅http://docs.oracle.com/javase/6/docs/technotes/tools/share/jvisualvm.html。
JMX管理器操作
任何成员都可以托管嵌入式JMX Manager,它提供集群的所有MBean的联合视图。 通过在ManagementService上调用相应的API调用,可以将成员配置为在启动时或在其生命中的任何时间成为管理器。
您需要在集群中启动JMX Manager才能使用Geode管理和监视工具,例如gfsh 和Geode Pulse。
注意: 充当JMX Manager的每个节点都有额外的内存要求,具体取决于它管理和监视的资源数量。 作为JMX Manager可以增加任何进程的内存占用,包括定位器进程。 有关计算Geode进程内存开销的更多信息,请参阅缓存数据的内存要求。
- 启动一个 JMX Manager
- 配置一个 JMX Manager
- 停止一个 JMX Manager
启动一个 JMX Manager
JMX Manager节点是管理其他Geode成员(以及他们自己)的成员。 JMX Manager节点可以管理集群中的所有其他成员。 通常,定位器将用作JMX Manager,但您也可以将任何其他成员(如服务器)转换为JMX Manager节点。
要允许服务器成为JMX Manager,请在服务器的gemfire.properties文件中配置Geode属性jmx-manager=true。 此属性将节点配置为被动地成为JMX Manager节点; 如果gfsh在连接到集群时找不到JMX Manager,则服务器节点将作为JMX Manager节点启动。
注意: 所有定位器的默认属性设置是gemfire.jmx-manager=true。 对于其他成员,默认属性设置为gemfire.jmx-manager=false。
要在服务器启动时强制服务器成为JMX Manager节点,请在服务器的gemfire.properties文件中设置Geode属性jmx-manager-start=true和jmx-manager=true。 请注意,对于节点,必须将这两个属性都设置为true。
要在命令行上将成员作为JMX Manager节点启动,请提供-J=-Dgemfire.jmx-manager-start =true和-J=-Dgemfire.jmx-manager=true作为参数。 start server或`start locator’命令。
例如,要在gfsh命令行上将服务器作为JMX Manager启动:
gfsh>start server --name=<server-name> --J=-Dgemfire.jmx-manager=true \--J=-Dgemfire.jmx-manager-start=true
默认情况下,任何定位器在启动时都可以成为JMX Manager。 启动定位器时,如果集群中未检测到其他JMX Manager,则定位器会自动启动定位器。 如果启动第二个定位器,它将检测当前的JMX Manager,并且不会启动另一个JMX Manager,除非第二个定位器的gemfire.jmx-manager-start属性设置为true。
对于大多数部署,每个集群只需要一个JMX Manager。 但是,如有必要,您可以运行多个JMX Manager。 如果要为Pulse监视工具提供高可用性和冗余,或者运行除gfsh之外的其他JMX客户端,则使用jmx-manager-start = true属性强制单个节点(定位器或服务器)成为JMX管理器在启动时。 由于作为JMX Manager存在一些性能开销,我们建议使用定位器作为JMX Manager。 如果您不希望定位器成为JMX管理器,则在启动定位器时必须使用jmx-manager = false属性。
节点成为JMX Manager后,将应用配置JMX Manager中列出的所有其他jmx-manager- *配置属性。
以下是启动新定位器也启动嵌入式JMX Manager的示例(在检测到另一个JMX Manager不存在之后)。 此外,gfsh还会自动将您连接到新的JMX Manager。 例如:
gfsh>start locator --name=locator1Starting a Geode Locator in /Users/username/apache-geode/locator1.......Locator in /Users/username/apache-geode/locator1 on 192.0.2.0[10334] as locator1is currently online.Process ID: 27144Uptime: 5 secondsGeode Version: 1.7Java Version: 1.8.0_121Log File: /Users/username/apache-geode/locator1/locator1.logJVM Arguments: -Dgemfire.enable-cluster-configuration=true-Dgemfire.load-cluster-configuration-from-dir=false-Dgemfire.launcher.registerSignalHandlers=true-Djava.awt.headless=true -Dsun.rmi.dgc.server.gcInterval=9223372036854775806Class-Path: /Users/username/apache-geode/lib/geode-core-1.2.0.jar:/Users/username/apache-geode/lib/geode-dependencies.jarSuccessfully connected to: JMX Manager [host=192.0.2.0, port=1099]Cluster configuration service is up and running.
定位器还跟踪可以成为JMX Manager的所有节点。
创建缓存后,JMX Manager节点立即开始从其他成员联合MBean。 JMX Manager节点准备就绪后,JMX Manager节点会向所有其他成员发送通知,通知他们它是新的JMX Manager。 然后其他成员将完整的MBean状态放入每个隐藏的管理区域。
在任何时候,您都可以使用MemberMXBean.isManager()方法确定节点是否为JMX Manager。
使用Java API,任何使用jmx-manager=true配置的受管节点也可以通过调用ManagementService.startManager()方法转换为JMX Manager节点。
注意: 如果以编程方式启动JMX Manager并希望启用命令处理,则还必须将gfsh-dependencies.jar的绝对路径(位于安装的lib目录中)添加到应用程序的CLASSPATH。 不要将此库复制到CLASSPATH,因为此库通过相对路径引用lib中的其他依赖项。
配置一个 JMX Manager
在gemfire.properties文件中,您可以按如下方式配置JMX管理器。
| 属性 | 描述 | 缺省值 |
|---|---|---|
| http-service-port | 如果非零,则Geode启动一个侦听此端口的嵌入式HTTP服务。 HTTP服务用于托管Geode Pulse Web应用程序。 如果您在自己的Web服务器上托管Pulse Web应用程序,则通过将此属性设置为零来禁用此嵌入式HTTP服务。 如果jmx-manager为false,则忽略。 |
7070 |
| http-service-bind-address | 如果设置,则Geode成员将嵌入式HTTP服务绑定到指定的地址。 如果未设置此属性但使用http-service-port启用HTTP服务,则Geode会将HTTP服务绑定到成员的本地地址。 |
not set |
| jmx-manager | 如果是true则该成员可以成为JMX Manager。 所有其他jmx-manager- *属性在成为JMX Manager时使用。 如果此属性为false,则忽略所有其他jmx-manager- *属性。定位器上的默认值为true。 |
false (with Locator exception) |
| jmx-manager-access-file | 默认情况下,JMX Manager允许任何客户端完全访问所有MBean。 如果将此属性设置为文件名,则可以将客户端限制为仅读取MBean; 他们无法修改MBean。 对于密码文件中定义的每个用户名,可以在此文件中以不同方式配置访问级别。 有关此文件格式的更多信息,请参阅Oracle的com.sun.management.jmxremote.access.file系统属性文档。 如果jmx-manager为false或者jmx-manager-port为零,则忽略。 |
not set |
| jmx-manager-bind-address | 默认情况下,配置了端口的JMX Manager会侦听所有本地主机的地址。 您可以使用此属性配置JMX Manager将侦听的特定IP地址或主机名。 如果jmx-manager为false或jmx-manager-port为零,则忽略此属性。 如果您托管Pulse Web应用程序,此地址也适用于Geode Pulse服务器。 |
not set |
| jmx-manager-hostname-for-clients | 给客户端的主机名,询问定位器JMX Manager的位置。 默认情况下,使用JMX Manager的IP地址。 但是,对于不同网络上的客户端,您可以配置要为客户端提供的其他主机名。 如果jmx-manager为false或者jmx-manager-port为零,则忽略。 |
not set |
| jmx-manager-password-file | 默认情况下,JMX Manager允许没有凭据的客户端进行连接。 如果将此属性设置为文件名,则只允许使用与此文件中的条目匹配的凭据连接的客户端。 大多数JVM要求文件只能由所有者读取。 有关此文件格式的更多信息,请参阅Oracle的com.sun.management.jmxremote.password.file系统属性文档。 如果jmx-manager为false或jmx-manager-port为零,则忽略。 |
not set |
| jmx-manager-port | 此JMX Manager侦听客户端连接的端口。 如果此属性设置为零,则Geode不允许远程客户端连接。 或者,使用JVM支持的标准系统属性来配置远程JMX客户端的访问。 如果jmx-manager为false,则忽略。 默认RMI端口为1099。 | 1099 |
| jmx-manager-ssl | 如果为true且jmx-manager-port不为零,则JMX Manager仅接受SSL连接。 ssl-enabled属性不适用于JMX Manager,但其他SSL属性适用。 这允许仅为JMX Manager配置SSL,而无需为其他Geode连接配置SSL。 如果jmx-manager为false,则忽略。 |
false |
| jmx-manager-start | 如果为true,则此成员在创建缓存时启动JMX Manager。 在大多数情况下,您不应将此属性设置为true,因为在将jmx-manager设置为true的成员上需要时会自动启动JMX Manager。 如果jmx-manager为false,则忽略。 |
false |
| jmx-manager-update-rate | 此成员将更新推送到任何JMX管理器的速率(以毫秒为单位)。 目前该值应大于或等于statistic-sample-rate。 将此值设置得太高会导致gfsh和Geode Pulse看到过时的值。 |
2000 |
停止一个 JMX管理器
要使用gfsh停止JMX Manager,只需关闭托管JMX Manager的定位器或服务器即可。
对于定位器:
gfsh>stop locator --dir=locator1Stopping Locator running in /home/user/test2/locator1 on ubuntu.local[10334] as locator1...Process ID: 2081Log File: /home/user/test2/locator1/locator1.log....No longer connected to ubuntu.local[1099].
对于服务器:
gfsh>stop server --dir=server1Stopping Cache Server running in /home/user/test2/server1 ubuntu.local[40404] as server1...Process ID: 1156Log File: /home/user/test2/server1/server1.log....No longer connected to ubuntu.local[1099].
请注意,gfsh已自动断开您与已停止的JMX Manager的连接。
要使用管理API停止JMX管理器,请使用ManagementService.stopManager()方法阻止成员成为JMX Manager。
当Manager停止时,它会从其Platform MBeanServer中删除其他成员的所有联合MBean。 它还会发出通知,通知其他成员它不再被视为JMX Manager。
联邦MBean架构
Geode使用MBean来管理和监控Geode的不同部分。 Geode的联合MBean架构是可扩展的,允许您拥有Geode集群的单代理视图。
Geode MBean和MBeanServers的联合
MBeanServers的联合意味着一个成员JMX Manager Node可以提供MBeanServer托管的所有MBean的代理视图。 联合还意味着操作和通知分布在集群中。
Geode federation负责以下功能:
- MBean代理创建
- MBean状态传播
- 通知传播
- 操作调用
MBean代理命名约定
每个Geode MBean都遵循特定的命名约定,以便于分组。 例如:
GemFire:type=Member,service=LockService,name=<dlsName>,memberName=<memberName>
在JMX Manager节点上,此MBean将作为域注册到GemFire /
以下是一些示例MBean名称:
MemberMBean:
GemFire:type=Member,member=<Node1>
使用MXBeans
在其管理API中,Geode提供MXBeans以确保任何客户端(包括远程客户端)都可以使用所创建的任何MBean,而无需客户端访问特定类以访问MBean的内容。
MBean代理创建
Geode代理本质上是本地MBean。 每个Geode JMX管理器成员都托管指向每个受管节点的本地MBean的代理。 当在该受管节点中发生事件时,代理MBean还将发出受管节点中本地MBean发出的任何通知。
注意: JMX Manager节点上的聚合MBean未被代理。
Geode JMX MBean列表
本主题提供了Geode中可用的各种管理和监视MBean的说明。
下图说明了为管理和监视Apache Geode而开发的不同JMX MBean之间的关系。

JMX Manager MBeans
本节介绍JMX Manager节点上可用的MBean。
Managed Node MBeans
本节介绍所有受管节点上可用的MBean。
JMX Manager MBeans
本节介绍JMX Manager节点上可用的MBean。
JMX Manager节点包括Managed Node MBeans下列出的所有本地bean以及仅可用的以下bean 在JMX Manager节点上:
ManagerMXBean
表示托管成员的Geode Management层。 控制管理范围。 此MBean提供start和stop方法,以将受管节点转换为JMX Manager节点或停止节点成为JMX Manager。 对于潜在的管理者(jmx-manager=true和jmx-manager-start=false),这个MBean是在Locator请求时创建的。
注意: 您必须配置节点以允许它成为JMX Manager。 有关配置信息,请参阅配置JMX Manager。
MBean 细节
| Scope | ALL |
| Proxied | No |
| Object Name | GemFire:type=Member, service=Manager,member= |
| Instances Per Node | 1 |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.ManagerMXBean JavaDocs。
DistributedSystemMXBean
系统范围的聚合MBean,提供整个集群的高级视图,包括所有成员(缓存服务器,对等方,定位器)及其缓存。 在任何给定的时间点,它都可以提供完整集群及其操作的快照。
DistributedSystemMXBean提供用于执行集群范围操作的API,例如备份所有成员,关闭所有成员或显示各种集群指标。
您可以将标准JMX NotificationListener附加到此MBean以侦听整个集群中的通知。 有关详细信息,请参阅Geode JMX MBean通知。
这个MBean还提供了一些MBean模型导航APIS。 应使用这些API来浏览Geode系统公开的所有MBean。
MBean 细节
| Scope | Aggregate |
| Proxied | No |
| Object Name | GemFire:type=Distributed,service=System |
| Instances Per Node | 1 |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.DistributedSystemMXBean JavaDocs。
DistributedRegionMXBean
系统范围的命名区域的聚合MBean。 它为托管和/或使用该区域的所有成员提供了一个区域的高级视图。 例如,您可以获取托管该区域的所有成员的列表。 某些方法仅适用于分区区域。
MBean Details
| Scope | Aggregate |
| Proxied | No |
| Object Name | GemFire:type=Distributed,service=Region,name= |
| Instances Per Node | 0..N |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.DistributedRegionMXBean JavaDocs。
DistributedLockServiceMXBean
表示DistributedLockService的命名实例。 可以在成员中创建任意数量的DistributedLockService。
DistributedLockService的命名实例定义了一个空间,用于锁定由指定分发管理器定义的集群中的任意名称。 可以使用不同的服务名称创建任意数量的DistributedLockService实例。 对于集群中已创建具有相同名称的DistributedLockService实例的所有进程,在任何时间点,只允许一个线程拥有该实例中给定名称的锁。 此外,线程可以锁定整个服务,从而防止系统中的任何其他线程锁定服务或服务中的任何名称。
MBean Details
| Scope | Aggregate |
| Proxied | No |
| Object Name | GemFire:type=Distributed,service=LockService,name= |
| Instances Per Node | 0..N |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.DistributedLockServiceMXBean JavaDocs。
受管节点MBean
本节介绍所有受管节点上可用的MBean。
所有受管节点上可用的MBean包括:
- MemberMXBean
- CacheServerMXBean
- RegionMXBean
- LockServiceMXBean
- DiskStoreMXBean
- AsyncEventQueueMXBean
- LocatorMXBean
- LuceneServiceMXBean
JMX Manager节点将自己拥有受管节点MBean,因为它们也是集群中的可管理实体。
MemberMXBean
成员对其连接和缓存的本地视图。 它是管理特定成员的主要网关。 它公开了成员级属性和统计信息。 像createCacheServer()和createManager()这样的操作将有助于创建一些Geode资源。 任何JMX客户端都可以连接到MBean服务器,并使用此MBean开始管理Geode成员。
See MemberMXBean Notifications for a list of notifications emitted by this MBean.
MBean 细节
| Scope | Local |
| Proxied | Yes |
| Object Name | GemFire:type=Member,member= |
| Instances Per Node | 1 |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.MemberMXBean JavaDocs。
CacheServerMXBean
表示Geode CacheServer。 提供有关服务器,订阅,持久队列和索引的数据和通知。
有关此MBean发出的通知的列表,请参阅CacheServerMXBean Notifications。
MBean 细节
| Scope | Local |
| Proxied | Yes |
| Object Name | GemFire:type=Member,service=CacheServer,member= |
| Instances Per Node | 1 |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.CacheServerMXBean JavaDocs。
RegionMXBean
成员局部区域的视角。
MBean Details
| Scope | Local |
| Proxied | Yes |
| Object Name | GemFire:type=Member,service=Region,name= |
| Instances Per Node | 0..N |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.RegionMXBean JavaDocs。
LockServiceMXBean
表示LockService的命名实例。 可以在成员中创建任意数量的LockServices。
MBean Details
| Scope | Local |
| Proxied | Yes |
| Object Name | GemFire:type=Member,service=LockService,name= |
| Instances Per Node | 0..N |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.LockServiceMXBean JavaDocs。
DiskStoreMXBean
表示为一个或多个区域提供磁盘存储的DiskStore对象
MBean 细节
| Scope | Local |
| Proxied | Yes |
| Object Name | GemFire:type=Member,service=DiskStore,name= |
| Instances Per Node | 0..N |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.DiskStoreMXBean JavaDocs。
AsyncEventQueueMXBean
AsyncEventQueueMXBean提供对AsyncEventQueue的访问,AsyncEventQueue表示将事件传递到AsyncEventListener的通道。
MBean 细节
| Scope | Local |
| Proxied | Yes |
| Object Name | GemFire:type=Member,service=AsyncEventQueue,queue= |
| Instances Per Node | 0..N |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.AsyncEventQueueMXBean JavaDocs。
LocatorMXBean
LocatorMXBean表示定位器。
MBean Details
| Scope | Local |
| Proxied | Yes |
| Object Name | GemFire:type=Member,service=Locator,port= |
| Instances Per Node | 0..1 |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.LocatorMXBean JavaDocs。
LuceneServiceMXBean
成员对现有Lucene索引的本地视图。
MBean 细节
| Scope | Local |
| Proxied | Yes |
| Object Name | GemFire:service=CacheService,name=LuceneService,type=Member,member= |
| Instances Per Node | 0..1 |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.cache.lucene.management.LuceneServiceMXBean JavaDocs。
GatewaySenderMXBean
GatewaySenderMXBean表示网关发件人。
MBean 细节
| Scope | Local |
| Proxied | Yes |
| Object Name | GemFire:type=Member,service=GatewaySender,gatewaySender= |
| Instances Per Node | 0..1 |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.GatewaySenderMXBean JavaDocs。
GatewayReceiverMXBean
GatewayReceiverMXBean表示网关接收器。
MBean 细节
| Scope | Local |
| Proxied | Yes |
| Object Name | GemFire:type=Member,service=GatewayReceiver,member= |
| Instances Per Node | 0..1 |
有关可用MBean方法和属性的信息,请参阅org.apache.geode.management.GatewayReceiverMXBean JavaDocs。
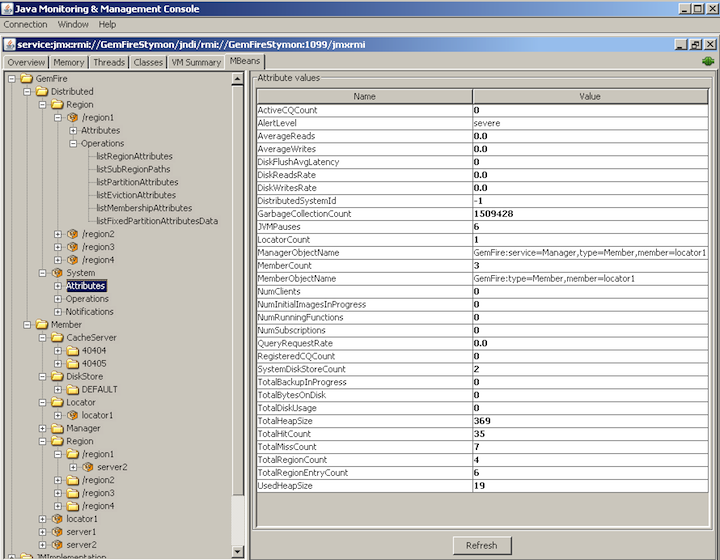
通过JConsole浏览Geode MBean
您可以使用JConsole浏览集群中的所有Geode MBean。
要通过JConsole查看Geode MBean,请执行以下步骤:
启动
gfsh提示符。通过使用嵌入式JMX Manager连接到定位器或直接连接到JMX Manager,连接到正在运行的集群。 例如:
gfsh>connect --locator=locator1[10334]
或者
gfsh>connect --jmx-manager=locator1[1099]
启动 JConsole:
gfsh>start jconsole
如果成功,将显示“正在运行JDK JConsole”消息。 JConsole应用程序使用RMI直接启动并连接到JMX Manager。
在JConsole屏幕上,单击MBeans选项卡。 展开GemFire。 然后展开每个MBean以浏览各个MBean属性,操作和通知。
以下是Geode集群中MBean层次结构的示例屏幕截图:
Geode JMX MBean通知
Apache Geode MBean在发生特定事件或Geode系统中引发警报时发出通知。 使用标准JMX API,用户可以添加通知处理程序来侦听这些事件。
通知联邦
从受管节点发出的所有通知都将联合到系统中的所有JMX Manager。
JMX MBean通知列表
本主题列出了Geode MBeans发出的所有可用JMX通知。
通知联邦
从受管节点发出的所有通知都将联合到系统中的所有JMX Manager。
这些通知是联合的,然后由DistributedSystemMXBean发出。 如果将javax.management.NotificationListener附加到DistributedSystemMXBean,NotificationListener可以侦听来自所有MemberMXBeans和所有CacheServerMXBeans的通知。
将监听器附加到MXBeans
将通知侦听器附加到DistributedSystemMXBean时,DistributedSystemMXBean将充当整个集群的通知中心。 您不必将侦听器附加到每个单独的成员或缓存服务器MBean,以便侦听集群中的所有通知。
以下是使用JMX MBeanServer API将NotificationListener附加到MBean的示例:
NotificationListener myListener = ...ObjectName mbeanName = ...MBeanServer.addNotificationListener(mbeanName, myListener, null, null);
JMX Manager将为所有集群成员发出通知,但有两个例外:
- 如果使用cache.xml定义区域和磁盘等资源,则这些资源的通知不会联合到JMX Manager。 在这些情况下,DistributedSystemMXBean无法发出这些通知。
- 如果在创建资源后启动JMX Manager,则JMX Manager无法为该资源发出通知。
系统警报通知
系统警报是包含在JMX通知中的Geode警报。 JMX Manager将自身注册为系统中每个成员的警报侦听器,默认情况下,它会接收集群中任何节点使用SEVERE警报级别记录的所有消息。 因此,DistributedSystemMXBean将代表DistributedSystem发出这些警报的通知。
默认情况下,JMX Manager会自行注册以仅为SEVERE级别警报发送通知。 要更改JMX Manager将发送通知的警报级别,请使用DistributedMXBean.changeAlertLevel方法。 可设置的警报级别为WARNING,ERROR,SEVERE和NONE。 更改级别后,JMX Manager将仅发出该级别的日志消息作为通知。
通知对象包括类型,源和消息属性。 系统警报还包括userData属性。 对于系统警报,通知对象属性对应于以下内容:
- type: system.alert
- source: Distributed System ID
- message: alert message
- userData: name or ID of the member that raised the alert
JMX MBean通知列表
本主题列出了Geode MBeans发出的所有可用JMX通知。
通知由以下MBean发出:
- MemberMXBean 通知
- MemberMXBean Gateway 通知
- CacheServerMXBean 通知
- DistributedSystemMXBean 通知
MemberMXBean 通知
| Notification Type | Notification Source | Message |
|---|---|---|
| gemfire.distributedsystem.cache.region.created | Member name or ID | Region Created with Name |
| gemfire.distributedsystem.cache.region.closed | Member name or ID | Region Destroyed/Closed with Name |
| gemfire.distributedsystem.cache.disk.created | Member name or ID | DiskStore Created with Name |
| gemfire.distributedsystem.cache.disk.closed | Member name or ID | DiskStore Destroyed/Closed with Name |
| gemfire.distributedsystem.cache.lockservice.created | Member name or ID | LockService Created with Name |
| gemfire.distributedsystem.cache.lockservice.closed | Member name or ID | Lockservice Closed with Name |
| gemfire.distributedsystem.async.event.queue.created | Member name or ID | Async Event Queue is Created in the VM |
| gemfire.distributedsystem.cache.server.started | Member name or ID | Cache Server is Started in the VM |
| gemfire.distributedsystem.cache.server.stopped | Member name or ID | Cache Server is stopped in the VM |
| gemfire.distributedsystem.locator.started | Member name or ID | Locator is Started in the VM |
MemberMXBean Gateway 通知
| Notification Type | Notification Source | Message |
|---|---|---|
| gemfire.distributedsystem.gateway.sender.created | Member name or ID | GatewaySender Created in the VM |
| gemfire.distributedsystem.gateway.sender.started | Member name or ID | GatewaySender Started in the VM |
| gemfire.distributedsystem.gateway.sender.stopped | Member name or ID | GatewaySender Stopped in the VM |
| gemfire.distributedsystem.gateway.sender.paused | Member name or ID | GatewaySender Paused in the VM |
| gemfire.distributedsystem.gateway.sender.resumed | Member name or ID | GatewaySender Resumed in the VM |
| gemfire.distributedsystem.gateway.receiver.created | Member name or ID | GatewayReceiver Created in the VM |
| gemfire.distributedsystem.gateway.receiver.started | Member name or ID | GatewayReceiver Started in the VM |
| gemfire.distributedsystem.gateway.receiver.stopped | Member name or ID | GatewayReceiver Stopped in the VM |
| gemfire.distributedsystem.cache.server.started | Member name or ID | Cache Server is Started in the VM |
CacheServerMXBean 通知
| Notification Type | Notification Source | Message |
|---|---|---|
| gemfire.distributedsystem.cacheserver.client.joined | CacheServer MBean Name | Client joined with Id |
| gemfire.distributedsystem.cacheserver.client.left | CacheServer MBean Name | Client crashed with Id |
| gemfire.distributedsystem.cacheserver.client.crashed | CacheServer MBean name | Client left with Id |
DistributedSystemMXBean 通知
| Notification Type | Notification Source | Message |
|---|---|---|
| gemfire.distributedsystem.cache.member.joined | Name or ID of member who joined | Member Joined |
| gemfire.distributedsystem.cache.member.departed | Name or ID of member who departed | Member Departed |
| gemfire.distributedsystem.cache.member.suspect | Name or ID of member who is suspected | Member Suspected |
| system.alert.* | DistributedSystem(“ |
Alert Message |
配置RMI注册表端口和RMI连接器
Geode以编程方式模拟Java提供的开箱即用的JMX,并在所有可管理成员上创建带有RMI Registry和RMI Connector端口的JMXServiceURL。
配置JMX Manager端口和绑定地址
您可以在启动将承载Geode JMX Manager的进程时配置特定的连接端口和地址。 为此,请指定jmx-manager-bind-address的值,它指定JMX管理器的IP地址和jmx-manager-port,它定义了RMI连接端口。
默认的Geode JMX Manager RMI端口为1099.如果保留1099用于其他用途,则可能需要修改此默认值。
使用开箱即用的RMI连接器
如果由于某种原因需要在部署中使用标准JMX RMI用于其他监视目的,请在要使用标准JMX RMI的任何成员上将Geode属性jmx-manager-port设置为0。
如果您使用开箱即用的JMX RMI而不是启动嵌入式Geode JMX Manager,则在为客户应用程序启动JVM时应考虑设置-Dsun.rmi.dgc.server.gcInterval = Long.MAX_VALUE-1 和客户进程。 每个Geode进程在创建和启动JMX RMI连接器之前在内部设置此设置,以防止暂停进程完全垃圾回收。
通过Management API执行gfsh命令
您还可以使用管理API以编程方式执行gfsh命令。
注意: 如果以编程方式启动JMX Manager并希望启用命令处理,则还必须将gfsh-dependencies.jar的绝对路径(位于Geode安装的$ GEMFIRE/lib中)添加到应用程序的CLASSPATH中。 不要将此库复制到CLASSPATH,因为此库通过相对路径引用$ GEMFIRE/lib中的其他依赖项。 以下代码示例演示了如何使用Java API处理和执行gfsh命令。
首先,检索CommandService实例。
注意: CommandService API目前仅在JMX Manager节点上可用。
// Get existing CommandService instance or create new if it doesn't existcommandService = CommandService.createLocalCommandService(cache);// OR simply get CommandService instance if it exists, don't create new oneCommandService commandService = CommandService.getUsableLocalCommandService();
接下来,处理命令及其输出:
// Process the user specified command StringResult regionListResult = commandService.processCommand("list regions");// Iterate through Command Result in String form line by linewhile (regionListResult.hasNextLine()) {System.out.println(regionListResult.nextLine());}
或者,您可以从命令字符串创建一个可以重复使用的CommandStatement对象,而不是处理该命令。
// Create a command statement that can be reused multiple timesCommandStatement showDeadLocksCmdStmt = commandService.createCommandStatement("show dead-locks --file=deadlock-info.txt");Result showDeadlocksResult = showDeadLocksCmdStmt.process();// If there is a file as a part of Command Result, it can be saved// to a specified directoryif (showDeadlocksResult.hasIncomingFiles()) {showDeadlocksResult.saveIncomingFiles(System.getProperty("user.dir") +"/commandresults");}
管理堆和堆外内存
默认情况下,Apache Geode使用JVM堆。 Apache Geode还提供了一种从堆中存储数据的选项。 本节介绍如何管理堆和堆外内存以最好地支持您的应用程序。
调整JVM垃圾收集参数
由于Apache Geode专门用于处理内存中保存的数据,因此您可以通过调整Apache Geode使用JVM堆的方式来优化应用程序的性能。
有关可用于改进垃圾回收(GC)响应的所有特定于JVM的设置,请参阅JVM文档。 至少,请执行以下操作:
- 将初始和最大堆开关
-Xms和-Xmx设置为相同的值。gfsh start server选项--initial-heap和--max-heap实现了相同的目的,增加了提供资源管理器默认值的值,例如逐出阈值和临界阈值。 - 配置JVM以进行并发标记清除(CMS)垃圾回收。
- 如果您的JVM允许,请将其配置为在堆使用率比资源管理器“eviction-heap-percentage”的设置低至少10%时启动CMS收集。 您希望收集器在Geode驱逐或驱逐不会产生更多空闲内存时工作。 例如,如果
eviction-heap-percentage设置为65,则将堆垃圾收集设置为在堆使用率不高于55%时启动。
| JVM | CMS switch flag | CMS initiation (begin at heap % N) |
|---|---|---|
| Sun HotSpot | ‑XX:+UseConcMarkSweepGC |
‑XX:CMSInitiatingOccupancyFraction=N |
| JRockit | -Xgc:gencon |
-XXgcTrigger:N |
| IBM | -Xgcpolicy:gencon |
N/A |
对于gfsh start server命令,使用--J开关传递这些设置,例如:‑‑J=‑XX:+UseConcMarkSweepGC。
以下是为应用程序设置JVM的示例:
$ java app.MyApplication -Xms=30m -Xmx=30m -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=60
注意: 启动服务器时,请勿使用-XX:+UseCompressedStrings和-XX:+UseStringCache JVM配置属性。 这些JVM选项可能会导致数据损坏和兼容性问题。
或者,使用gfsh:
$ gfsh start server --name=app.MyApplication --initial-heap=30m --max-heap=30m \--J=-XX:+UseConcMarkSweepGC --J=-XX:CMSInitiatingOccupancyFraction=60
使用Geode资源管理器
Geode资源管理器与您的JVM终身垃圾收集器一起使用,以控制堆使用并保护您的成员免受因内存过载而导致的挂起和崩溃。
Geode资源管理器通过驱逐旧数据来防止缓存占用过多内存。 如果垃圾收集器无法跟上,则资源管理器会拒绝添加到缓存,直到收集器释放了足够的内存。
资源管理器有两个阈值设置,每个设置表示为总终端堆的百分比。 两者都默认禁用。
Eviction Threshold(驱逐阈值). 在此之上,管理器命令所有区域的驱逐,其中
eviction-attributes设置为lru-heap-percentage。 这会提示专用的后台驱逐,独立于任何应用程序线程,它还告诉所有应用程序线程向区域添加数据以驱逐至少与添加的数据一样多的数据。 JVM垃圾收集器删除已逐出的数据,减少堆使用。 该驱逐继续下去,直到管理器确定堆的使用是再次跌破驱逐阈值。资源管理器仅对LRU驱逐策略基于堆百分比的区域强制执行驱逐阈值。 基于条目计数或存储器大小的驱逐策略的区域使用其他机制来管理驱逐。 有关驱逐政策的更多详细信息,请参阅驱逐。
Critical Threshold(临界阈值). 在此之上,所有可能将数据添加到缓存的活动都将被拒绝。 该阈值设置在驱逐阈值之上,旨在使驱逐和GC工作赶上。 此JVM,集群中的所有其他JVM以及系统的所有客户端都会收到“LowMemoryException”,以查看是否会增加此关键成员的堆消耗。 允许获取或减少数据的活动。 有关拒绝操作的列表,请参阅
ResourceManager方法setCriticalHeapPercentage的Javadoc。无论LRU驱逐策略如何,都会对所有区域强制执行临界阈值,但可以将其设置为零以禁用其效果。

当堆使用在任一方向上通过逐出阈值时,管理器记录信息级消息。
当堆使用超过临界阈值时,管理器会记录错误级别的消息。 避免超过临界阈值。 一旦被识别为关键,Geode成员将成为只读成员,拒绝其所有区域的缓存更新,包括传入的分布式更新。
有关更多信息,请参阅联机API文档中的org.apache.geode.cache.control.ResourceManager。
如何进行后台驱逐
当管理器开始驱逐时:
- 从为本地缓存中为堆LRU驱逐配置的所有区域,后台驱逐管理器创建随机列表,其包含每个分区区域桶(主要或次要)的一个条目和每个非分区区域的一个条目。 因此,每个分区区域桶的处理方式与单个非分区区域相同。
- 后台逐出管理器为本地计算机上的每个处理器启动四个逐出器线程。 管理器将每个线程传递给桶/区域列表的共享。 管理器通过计数尽可能均匀地划分桶/区域列表,而不是通过内存消耗。
- 每个线程在其桶/区域列表上循环遍历,逐个每个桶/区域驱逐一个LRU条目,直到资源管理器发送信号以停止驱逐。
另请参见缓存数据的内存要求。
使用资源管理器控制堆使用
资源管理器行为与垃圾收集(GC)活动的触发,JVM中并发垃圾收集器的使用以及用于并发的并行GC线程数密切相关。
此处提供的使用管理器的建议假设您对Java VM的堆管理和垃圾收集服务有充分的了解。
资源管理器可用于任何Apache Geode成员,但您可能不希望在任何地方激活它。 对于某些成员而言,在挂起或OME崩溃后偶尔重启可能比驱逐数据和/或拒绝分布式缓存活动更好。 此外,没有冒险超出其内存限制的成员将无法从资源管理器消耗的开销中受益。 缓存服务器通常配置为使用管理器,因为它们通常承载更多数据并且具有比其他成员更多的数据活动,从而需要更高的数据清理和收集响应能力。
对于要激活资源管理器的成员:
- 为堆LRU管理配置Geode。
- 设置JVM GC调整参数以与Geode管理器一起处理堆和垃圾收集。
- 监视和调整堆LRU配置和GC配置。
- 在投入生产之前,请使用与目标系统近似的应用程序行为和数据加载来运行系统测试,以便您可以根据生产需要进行调整。
- 在生产中,不断监控和调整以满足不断变化的需求。
配置堆用于LRU管理的Geode
这里使用的配置术语是cache.xml元素和属性,但您也可以通过gfsh和org.apache.geode.cache.control.ResourceManager和RegionAPIs进行配置。
启动服务器时,将
initial-heap和max-heap设置为相同的值。设置
resource-manager和client-heap-percentage阈值。 这应该尽可能接近100,同时仍然足够低,以便管理者的响应可以防止成员挂起或得到’OutOfMemoryError`。 默认情况下,阈值为零(无阈值)。注意: 设置此阈值时,它还启用查询监视功能,以在执行查询或创建索引时防止大多数内存不足异常。 请参阅监视内存不足的查询。
将
resource-manager和eviction-heap-percentage阈值设置为低于临界阈值的值。 这应该尽可能高,同时仍然足够低,以防止您的成员达到临界阈值。 默认情况下,阈值为零(无阈值)。确定哪些区域将参与堆驱逐并将其
eviction-attributes设置为“lru-heap-percentage”。 见Eviction。 您为驱逐配置的区域应具有足够的数据活动,以便驱逐有用,并且应包含应用程序可以删除或卸载到磁盘的数据。
gfsh的例子:
gfsh>start server --name=server1 --initial-heap=30m --max-heap=30m \--critical-heap-percentage=80 --eviction-heap-percentage=60
cache.xml 例子:
<cache><region refid="REPLICATE_HEAP_LRU" />...<resource-manager critical-heap-percentage="80" eviction-heap-percentage="60"/></cache>
注意: resource-manager规范必须出现在cache.xml文件中的区域声明之后。
设置JVM GC调整参数
如果您的JVM允许,请将其配置为在堆使用率比资源管理器eviction-heap-percentage的设置低至少10%时启动并发标记清除(CMS)垃圾回收。 您希望收集器在Geode驱逐或驱逐不会产生更多空闲内存时工作。 例如,如果eviction-heap-percentage设置为65,则将堆垃圾收集设置为在堆使用率不高于55%时启动。
监视和调整堆LRU配置
在调整资源管理器时,您的中心焦点应该是使成员保持在临界阈值以下。 提供关键阈值是为了避免成员挂起和崩溃,但由于其分布式更新的异常抛出行为,在关键时间中花费的时间会对整个集群产生负面影响。 为了保持低于临界值,调整以便在达到驱逐阈值时Geode驱逐和JVM的GC充分响应。
使用JVM提供的统计信息确保您的内存和GC设置足以满足您的需求。
GeodeResourceManagerStats提供有关内存使用以及管理器阈值和逐出活动的信息。
如果您的应用程序定期高于临界阈值,请尝试降低逐出阈值。 如果应用程序永远不会接近关键,您可以提高驱逐阈值以获得更多可用内存,而不会产生不必要的驱逐或GC周期的开销。
适用于您的系统的设置取决于许多因素,包括:
- 您存储在缓存中的数据对象的大小: 可以驱逐非常大的数据对象并相对快速地收集垃圾。 许多小对象使用相同数量的空间需要更多的处理工作来清除,并且可能需要较低的阈值以允许驱逐和GC活动跟上。
- 应用行为: 快速将大量数据放入缓存的应用程序可以更轻松地超越驱逐和GC功能。 驱逐速度较慢的应用程序可能更容易通过驱逐和GC工作来抵消,可能允许您将阈值设置为高于更易变的系统。
- 您选择的JVM: 每个JVM都有自己的GC行为,这会影响收集器的运行效率,它在需要时的速度以及其他因素。
资源管理器示例配置
这些示例将临界阈值设置为终身堆的85%,并将驱逐阈值设置为75%。 区域bigDataStore被配置为参与资源管理器的驱逐活动。
gfsh 例子:
gfsh>start server --name=server1 --initial-heap=30m --max-heap=30m \--critical-heap-percentage=85 --eviction-heap-percentage=75
gfsh>create region --name=bigDataStore --type=PARTITION_HEAP_LRU
XML:
<cache><region name="bigDataStore" refid="PARTITION_HEAP_LRU"/>...<resource-manager critical-heap-percentage="85" eviction-heap-percentage="75"/></cache>
注意:
resource-manager规范必须出现在cache.xml文件中的区域声明之后。Java:
Cache cache = CacheFactory.create();ResourceManager rm = cache.getResourceManager();rm.setCriticalHeapPercentage(85);rm.setEvictionHeapPercentage(75);RegionFactory rf =cache.createRegionFactory(RegionShortcut.PARTITION_HEAP_LRU);Region region = rf.create("bigDataStore");
用例示例代码
这是示例中使用的配置的一种可能方案:
- 在运行Linux的4 CPU系统上具有8 Gb堆空间的64位Java VM。
- 数据区bigDataStore有大约2-3百万个小值,平均条目大小为512字节。 因此,大约4-6 Gb的堆用于区域存储。
- 托管该区域的成员还运行可能需要最多1 Gb堆的应用程序。
- 应用程序必须永远不会耗尽堆空间并且已经精心设计,如果由于应用程序问题导致堆空间变得有限,则该区域中的数据丢失是可接受的,因此默认的“lru-heap-percentage”操作销毁是合适的。
- 应用程序的服务保证使其非常不能容忍
OutOfMemoryException错误。 测试表明,当使用-XX:CMSInitiatingOccupancyFraction=70配置CMS垃圾收集器时,在向区域添加数据时,将15%的头部空间留在临界阈值之上可以获得99.5%的正常运行时间而没有“OutOfMemoryException”错误。
管理 Off-Heap 内存
可以将Geode配置为在堆外内存中存储区域值,该内存是JVM中不受Java垃圾回收影响的内存。
JVM中的垃圾收集(GC)可能会成为性能障碍。 服务器无法控制JVM堆内存中的垃圾收集何时发生,并且服务器几乎无法控制调用的触发器。 堆外内存将值卸载到不受Java GC约束的存储区域。 通过利用堆外存储,应用程序可以减少受GC开销影响的堆存储量。
堆外内存与堆一起使用,它不会替换它。 密钥存储在堆内存空间中。 Geode自己的内存管理器处理堆外内存的性能优于Java垃圾收集器对某些区域数据集的性能。
资源管理器监视堆外内存的内容,并根据两个类似于监视JVM堆的阈值调用内存管理操作:eviction-off-heap-percentage和critical-off-heap-percentage。
On-heap 和 Off-heap 对象
以下对象始终存储在JVM堆中:
- 区域元数据
- 条目元数据
- Keys
- 索引
- 订阅队列元素
以下对象可以存储在堆外内存中:
- 值 - 最大值大小为2GB
- 引用计数
- 可用内存块列表
- WAN队列元素
注意: 不要将函数范围索引与堆外数据一起使用,因为它们不受支持。 尝试这样做会产生异常。
Off-heap 建议
Off-heap 存储最适合数据模式,其中:
- 存储的值在大小上相对均匀
- 存储的值大多小于128K
- 使用模式涉及许多创建的循环,然后是销毁或清除
- 这些值不需要经常反序列化
- 许多值都是长寿命的参考数据
请注意,Geode必须执行额外的工作来访问存储在堆外内存中的数据,因为它以序列化形式存储。 这项额外的工作可能会导致某些用例在堆外配置中运行速度较慢,即使它们使用较少的内存并避免垃圾收集开销。 但是,即使进行额外的反序列化,堆外存储也可以为您提供最佳性能。 可能增加开销的功能包括
- 经常更新
- 存储的大小各不相同的值
- 增量
- 查询
实现细节
堆外存储器管理器有效地处理大小相同或具有固定大小的区域数据值。 在堆外内存中分配固定和相同大小的数据值时,通常可以重用已释放的块,并且很少或根本不需要将周期用于碎片整理。
即使该区域配置为使用堆外内存,小于或等于8个字节的区域值也不会驻留在堆外内存中。 这些非常小的区域值驻留在JVM堆中,而不是对堆外位置的引用。 此性能增强可节省空间和加载时间。
使用资源管理器控制堆外使用
Geode资源管理器通过两个阈值控制堆外内存,与JVM堆内存的方式大致相同。 请参阅使用Geode资源管理器。 资源管理器通过驱逐旧数据来防止缓存占用过多的堆外内存。 如果堆外内存管理器无法跟上,则资源管理器会拒绝添加到缓存,直到堆外内存管理器释放足够的内存。
资源管理器有两个阈值设置,每个设置表示为总堆外内存的百分比。 两者都默认禁用。
Eviction Threshold(驱逐阈值). 驱逐应该开始的堆外记忆的百分比。 驱逐继续,直到资源管理器确定堆外内存使用再次低于驱逐阈值。 使用
eviction-off-heap-percentageregion属性设置逐出阈值。 资源管理器仅对具有HEAP_LRU特征的区域强制执行驱逐阈值。 如果临界阈值不为零,则默认逐出阈值比临界阈值低5%。 如果临界阈值为零,则默认逐出阈值为总堆外内存的80%。资源管理器仅对LRU驱逐策略基于堆百分比的区域强制执行驱逐阈值。 基于条目计数或存储器大小的驱逐策略的区域使用其他机制来管理驱逐。 有关驱逐政策的更多详细信息,请参阅驱逐。
Critical Threshold(临界阈值). 高速缓存存在无法操作风险的堆外内存百分比。 当缓存使用超过临界阈值时,将拒绝所有可能向缓存添加数据的活动。 任何会增加堆外内存消耗的操作都会抛出
LowMemoryException而不是完成其操作。 使用critical-off-heap-percentage区域属性设置临界阈值。无论LRU驱逐策略如何,都会对所有区域强制执行临界阈值,但可以将其设置为零以禁用其效果。
指定堆外内存
要使用堆外内存,请在设置服务器和区域时指定以下选项:
按调整JVM的垃圾收集参数中的说明启动JVM。 特别是,将初始和最大堆大小设置为相同的值。 当您计划使用堆外内存时,小于32GB的大小是最佳选择。
从gfsh,启动每个服务器,它将支持非堆内存,并具有非零的“off-heap-memory-size”值,以兆字节(m)或千兆字节(g)为单位。 如果您计划使用资源管理器,请指定临界阈值,逐出阈值或(在大多数情况下)两者。
例子:
gfsh> start server --name=server1 -–initial-heap=10G -–max-heap=10G -–off-heap-memory-size=200G \-–lock-memory=true -–critical-off-heap-percentage=90 -–eviction-off-heap-percentage=80
通过将
off-heapregion属性设置为true来标记其条目值应存储在堆外的区域。为托管同一区域的数据的所有成员统一配置其他区域属性。。例子:
gfsh>create region --name=region1 --type=PARTITION_HEAP_LRU --off-heap=true
gfsh Off-heap支持
gfsh支持服务器和区域创建操作以及报告功能中的堆外内存:
alter disk-store
--off-heap=(true | false) 重置指定区域的off-heap属性。 有关详细信息,请参阅alter disk-store。
create region
--off-heap=(true | false)设置指定区域的off-heap属性。 有关详细信息,请参阅create region。
describe member 显示堆外大小
describe offline-disk-store 显示离线区域是否处于堆外
describe region 显示区域的堆外属性的值
show metrics
包括堆外指标 maxMemory, freeMemory, usedMemory, objects, fragmentation 和 defragmentationTime
start server
支持堆外选项--lock-memory,--off-heap-memory-size,--critical-off-heap-percentage和--eviction-off-heap-percentage请参阅 启动服务器了解详情。
资源管理 API
org.apache.geode.cache.control.ResourceManager接口定义了支持堆外使用的方法:
public void setCriticalOffHeapPercentage(float Percentage)public float getCriticalOffHeapPercentage()public void setEvictionOffHeapPercentage(float Percentage)public float getEvictionOffHeapPercentage()
gemfire.properties文件支持一个堆外属性:
off-heap-memory-size
指定堆外内存的大小,以兆字节(m)或千兆字节(g)为单位。 例如:
off-heap-memory-size=4096moff-heap-memory-size=120g
有关详细信息,请参阅gemfire.properties和gfsecurity.properties(Geode Properties)。
cache.xml文件支持一个区域属性:
off-heap(=true | false)
Specifies that the region uses off-heap memory; defaults to false. For example:
<region-attributesoff-heap="true"></region-attributes>
cache.xml文件支持两个资源管理器属性:
critical-off-heap-percentage=value
指定堆外内存的百分比达到或超过其缓存中成为不可操作的危险,由于内存不足异常的考虑。 有关详细信息,请参阅。
eviction-off-heap-percentage=value
指定应该开始驱逐的堆外内存的百分比。 可以为任何区域设置,但仅在为HEAP_LRU驱逐配置的区域中主动运行。 有关详细信息,请参阅。
例如:
<cache>...<resource-managercritical-off-heap-percentage="99.9"eviction-off-heap=-percentage="85"/>...</cache>
调整堆外内存使用情况
Geode收集有关堆外内存使用情况的统计信息,您可以使用gfshshow metrics命令查看。 有关可用的堆外统计信息的说明,请参阅Off-Heap(OffHeapMemoryStats)。
默认情况下,堆外内存优化用于存储大小为128 KB的值。 此图称为“最大优化存储值大小”,我们将在此处用maxOptStoredValSize表示。 如果您的数据通常运行较大,则可以通过将OFF_HEAP_FREE_LIST_COUNT系统参数增加到大于maxOptStoredValSize/8的数字来增强性能,其中maxOptStoredValSize以KB(1024字节)表示。 因此,默认值对应于:
128 KB / 8 = (128 * 1024) / 8 = 131,072 / 8 = 16,384-Dgemfire.OFF_HEAP_FREE_LIST_COUNT=16384
要优化最大优化存储值大小(默认值的两倍或256 KB),空闲列表计数应加倍:
-Dgemfire.OFF_HEAP_FREE_LIST_COUNT=32768
在调优过程中,您可以打开和关闭off-heap区域属性,保留其他堆外设置和参数,以便比较应用程序的堆上和堆外性能。
锁定内存(仅限Linux系统)
在Linux系统上,您可以锁定内存以防止操作系统分页堆或堆外内存。
要使用此功能:
配置锁定内存的操作系统限制。 将操作系统的
ulimit -l值(可能在内存中锁定的最大大小)从默认值(通常为32 KB或64 KB)增加到至少Geode用于堆栈或关闭的内存总量 堆存储。 要查看当前设置,请在shell提示符下输入ulimit -a并找到max locked memory的值:# ulimit -a...max locked memory (kbytes, -l) 64...
使用
ulimit -l max-size-in-kbytes来提高限制。 例如,要将锁定的内存限制设置为64 GB:# ulimit -l 64000000
以这种方式使用锁定内存会增加启动Geode所需的时间。 启动Geode所需的额外时间取决于所使用的内存总量,可以在几秒到10分钟或更长的范围内。 为了缩短启动时间并减少成员超时的可能性,请通过发出以下命令,指示内核在启动Geode成员之前释放操作系统页面缓存:
$ echo 1 > /proc/sys/vm/drop_caches
使用gfsh
-lock-memory=true选项启动每个Geode数据存储。 如果每个主机部署多个服务器,请先顺序启动每个服务器。 如果不小心分配了可用的RAM,则按顺序启动服务器可以避免操作系统中的竞争状况,该竞争状况可能导致故障(甚至导致机器崩溃)。 确认系统配置稳定后,即可并发启动服务器。
磁盘存储
使用Apache Geode磁盘存储,您可以将数据保存到磁盘,作为内存中副本的备份,并在内存使用过高时将数据溢出到磁盘。
磁盘存储的工作原理
溢出和持久性单独或一起使用磁盘存储来存储数据。
磁盘存储文件名和扩展名
磁盘存储文件包括存储管理文件,访问控制文件和操作日志或oplog文件,包括一个用于删除的文件和另一个用于所有其他操作的文件。
磁盘存储操作日志
在创建时,每个操作日志都在磁盘存储的
max-oplog-size中初始化,其大小分为crf和drf文件。 当oplog关闭时,Apache Geode会将文件缩小到每个文件中使用的空间。配置磁盘存储
除了您指定的磁盘存储之外,Apache Geode还有一个默认磁盘存储,它在配置磁盘使用时未使用指定磁盘存储名称时使用。 您可以修改默认磁盘存储行为。
使用磁盘存储优化系统
遵循本节中的准则,优化可用性和性能。
启动并关闭磁盘存储
本节介绍启动和关闭期间发生的情况,并提供这些操作的过程。
磁盘存储管理
gfsh命令行工具有许多选项可用于检查和管理磁盘存储。gfsh工具,cache.xml文件和DiskStore API是在线和离线磁盘存储的管理工具。为系统恢复和运营管理创建备份
备份是磁盘存储中持久数据的副本。 备份用于将磁盘存储还原到备份时的状态。 根据集群是联机还是脱机,相应的备份和还原过程会有所不同。 在线系统目前正在运行成员。 离线系统没有任何正在运行的成员。
磁盘存储的工作原理
溢出和持久性单独或一起使用磁盘存储来存储数据。
磁盘存储可用于以下项目:
- Regions. 持久化和/或从区域溢出数据。
- Server’s client subscription queues. 溢出消息传递队列以控制内存使用。
- Gateway sender queues. 坚持这些以获得高可用性。 这些队列总是溢出。
- PDX serialization metadata. 使用Geode PDX序列化保留有关您序列化的对象的元数据。
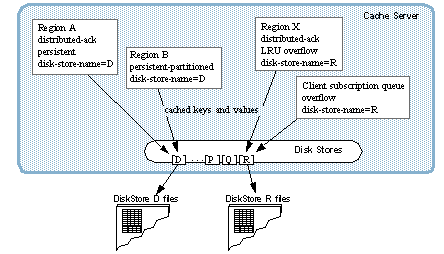
每个成员都有自己的一组磁盘存储,它们与任何其他成员的磁盘存储完全分开。 对于每个磁盘存储,定义数据存储到磁盘的位置和方式。 您可以将来自多个区域和队列的数据存储在单个磁盘存储中。
此图显示了已定义磁盘存储D到R的成员。 该成员有两个持久区域使用磁盘存储D和溢出区域以及使用磁盘存储R的溢出队列。
Geode写入磁盘存储的内容
Geode将以下内容写入磁盘存储:
- 创建和配置磁盘存储时指定的持久性和溢出数据
- 承载存储和信息及其状态的成员,例如哪些成员在线以及哪些成员处于脱机状态和时间戳
- 磁盘存储标识符
- 磁盘存储区中的哪些区域由区域名称指定并包括所选属性
- 磁盘存储区域所依赖的共同定位区域的名称
- 记录所有区域的运营情况
Geode不会将索引写入磁盘。
磁盘存储状态
磁盘存储的文件由Geode作为一个组。 将它们视为一个单一的实体。 如果您复制它们,请将它们全部复制在一起。 不要更改文件名。
磁盘存储访问和管理根据成员是在线还是离线而不同。 当成员正在运行时,其磁盘存储在线。 当成员退出并且未运行时,其磁盘存储处于脱机状态。
- Online, 磁盘存储由其成员进程拥有和管理。 要在联机磁盘存储上运行操作,请在成员进程中使用API调用,或使用
gfsh命令行界面。 - Offline, 磁盘存储只是主机文件系统中的文件集合。 可以根据文件系统权限访问这些文件。 您可以复制文件以进行备份或移动成员的磁盘存储位置。 您还可以使用
gfsh命令行界面运行一些维护操作,例如文件压缩和验证。 脱机时,磁盘存储的信息对集群不可用。 对于分区区域,区域数据在多个成员之间分配,因此成员的启动取决于所有成员,并且必须等待所有成员联机。 尝试访问脱机成员存储在磁盘上的条目会导致PartitionOfflineException。
磁盘存储文件名和扩展名
磁盘存储文件包括存储管理文件,访问控制文件和操作日志或oplog文件,包括一个用于删除的文件和另一个用于所有其他操作的文件。
下表描述了文件名和扩展名; 它们后面是示例磁盘存储文件。
文件名
文件名有三个部分:用途标识符,磁盘存储库名称和oplog序列号。
文件名的第一部分: Usage Identifier
| 值 | 用于 | 例子 |
|---|---|---|
| OVERFLOW | 仅来自溢出区域和队列的Oplog数据。 | OVERFLOWoverflowDS1_1.crf |
| BACKUP | 来自持久性和持久性+溢出区域和队列的Oplog数据。 | BACKUPoverflowDS1.if, BACKUPDEFAULT.if |
| DRLK_IF | 访问控制-锁定磁盘存储。 | DRLK_IFoverflowDS1.lk, DRLK_IFDEFAULT.lk |
文件名的第二部分: Disk Store Name
| 值 | 用于 | 例子 |
|---|---|---|
| 非默认磁盘存储。 | name=“overflowDS1” DRLK_IFoverflowDS1.lk, name=“persistDS1” BACKUPpersistDS1_1.crf | |
| DEFAULT | 默认磁盘存储名称,当在区域或队列上指定持久性或溢出但未命名磁盘存储时使用。 | DRLK_IFDEFAULT.lk, BACKUPDEFAULT_1.crf |
文件名的第三部分: oplog Sequence Number
| 值 | 用于 | 例子 |
|---|---|---|
| 序列号格式为 _n | 仅Oplog数据文件。 编号从1开始。 | OVERFLOWoverflowDS1_1.crf, BACKUPpersistDS1_2.crf, BACKUPpersistDS1_3.crf |
文件扩展名
| File extension | 用于 | 说明 |
|---|---|---|
| if | 磁盘存储元数据 | 存储在为存储列出的第一个磁盘目录中。 可忽略的大小-在大小控制中不考虑。 |
| lk | 磁盘存储访问控制 | 存储在为存储列出的第一个磁盘目录中。 可忽略的大小-在大小控制中不考虑。 |
| crf | Oplog:创建,更新和作废 | 在创建时预分配了最大max-oplog大小的90%。 |
| drf | Oplog: 删除操作 | 创建时预先分配的总最大操作日志大小的10%。 |
| krf | Oplog: 键和crf偏移量信息 | 在oplog达到max-oplog-size后创建。 用于提高启动时的性能。 |
磁盘存储的示例文件为persistDS1和overflowDS1:
bash-2.05$ ls -tlr persistData1/total 8-rw-rw-r-- 1 person users 188 Mar 4 06:17 BACKUPpersistDS1.if-rw-rw-r-- 1 person users 0 Mar 4 06:18 BACKUPpersistDS1_1.drf-rw-rw-r-- 1 person users 38 Mar 4 06:18 BACKUPpersistDS1_1.crfbash-2.05$ ls -tlr overflowData1/total 1028-rw-rw-r-- 1 person users 0 Mar 4 06:21 DRLK_IFoverflowDS1.lk-rw-rw-r-- 1 person users 0 Mar 4 06:21 BACKUPoverflowDS1.if-rw-rw-r-- 1 person users 1073741824 Mar 4 06:21 OVERFLOWoverflowDS1_1.crf
持久区域的默认磁盘存储文件示例:
bash-2.05$ ls -tlrtotal 106-rw-rw-r-- 1 person users 1010 Mar 8 15:01 defTest.xmldrwxrwxr-x 2 person users 512 Mar 8 15:01 backupDirectory-rw-rw-r-- 1 person users 0 Mar 8 15:01 DRLK_IFDEFAULT.lk-rw-rw-r-- 1 person users 107374183 Mar 8 15:01 BACKUPDEFAULT_1.drf-rw-rw-r-- 1 person users 966367641 Mar 8 15:01 BACKUPDEFAULT_1.crf-rw-rw-r-- 1 person users 172 Mar 8 15:01 BACKUPDEFAULT.if
磁盘存储操作日志
在创建时,每个操作日志都在磁盘存储的max-oplog-size中初始化,其大小分为crf和drf文件。 当oplog关闭时,Apache Geode会将文件缩小到每个文件中使用的空间。
关闭oplog之后,Geode还会尝试创建一个krf文件,其中包含键名以及crf文件中值的偏移量。 虽然启动时不需要此文件,但如果它可用,它将通过允许Geode在加载条目键后在后台加载条目值来提高启动性能。
当操作日志已满时,Geode会自动关闭它并创建一个包含下一个序列号的新日志。 这称为oplog rolling。 您还可以通过API调用DiskStore.forceRoll请求oplog滚动。 您可能希望在压缩磁盘存储之前立即执行此操作,因此最新的oplog可用于压缩。
注意: 日志压缩可以更改磁盘存储文件的名称。 通常会更改文件编号顺序,删除一些现有日志,或者使用编号较高的较新日志替换。 Geode始终以高于任何现有数字的数字开始新日志。
此示例清单显示系统中的日志,其中只有一个为存储指定的磁盘目录。 第一个日志(BACKUPCacheOverflow_1.crf和BACKUPCacheOverflow_1.drf)已关闭,系统正在写入第二个日志。
bash-2.05$ ls -tlratotal 55180drwxrwxr-x 7 person users 512 Mar 22 13:56 ..-rw-rw-r-- 1 person users 0 Mar 22 13:57 BACKUPCacheOverflow_2.drf-rw-rw-r-- 1 person users 426549 Mar 22 13:57 BACKUPCacheOverflow_2.crf-rw-rw-r-- 1 person users 0 Mar 22 13:57 BACKUPCacheOverflow_1.drf-rw-rw-r-- 1 person users 936558 Mar 22 13:57 BACKUPCacheOverflow_1.crf-rw-rw-r-- 1 person users 1924 Mar 22 13:57 BACKUPCacheOverflow.ifdrwxrwxr-x 2 person users 2560 Mar 22 13:57 .
系统将在所有可用磁盘目录中旋转以写入其日志。 下一个日志始终在未达到其已配置容量的目录中启动(如果存在)。
磁盘存储Oplog达到配置的磁盘容量时
如果不存在容量限制范围内的目录,Geode如何处理这取决于是否启用了自动压缩。
如果启用了自动压缩,Geode会在其中一个目录中创建一个新的oplog,超出限制,并记录一个警告,报告:
Even though the configured directory size limit has been exceeded anew oplog will be created. The current limit is of XXX. The currentspace used in the directory is YYY.
注意: 启用自动压缩后,
dir-size不会限制使用多少磁盘空间。 Geode将执行自动压缩,这应该释放空间,但系统可能会超过配置的磁盘限制。如果禁用自动压缩,Geode不会在附加到磁盘存储块的区域中创建新的oplog操作,并且Geode会记录此错误:
Disk is full and rolling is disabled. No space can be created
配置磁盘存储
除了您指定的磁盘存储之外,Apache Geode还有一个默认磁盘存储,它在配置磁盘使用时未使用指定磁盘存储名称时使用。 您可以修改默认磁盘存储行为。
设计和配置磁盘存储
您可以在缓存中定义磁盘存储,然后通过在区域和队列配置中设置
disk-store-name属性将它们分配给您的区域和队列。磁盘存储配置参数
您可以使用
gfsh create disk-store命令或cache.xml中缓存声明的<disk-store>子元素来定义磁盘存储。 所有磁盘存储都可供所有区域和队列使用。修改默认磁盘存储
您可以通过为名为“DEFAULT”的磁盘存储指定所需的属性来修改默认磁盘存储的行为。
设计和配置磁盘存储
您可以在缓存中定义磁盘存储,然后通过在区域和队列配置中设置disk-store-name属性将它们分配给您的区域和队列。
注意: 除了您指定的磁盘存储,Apache Geode还有一个默认磁盘存储,它在配置磁盘使用时没有指定磁盘存储名称。 默认情况下,此磁盘存储区保存到应用程序的工作目录中。 您可以更改其行为,如创建和配置磁盘存储和修改默认磁盘。
设计您的磁盘存储
在开始之前,您应该了解Geode 基本配置和编程。
与您的系统设计人员和开发人员一起规划测试和生产缓存系统中预期的磁盘存储要求。 考虑空间和功能要求。
为了提高效率,仅在单独的磁盘存储中溢出的数据与持久或持久且溢出的数据分开。 区域可以溢出,持久存在,或两者兼而有之。 服务器订阅队列仅溢出。
计算磁盘需求时,请参考数据修改模式和压缩策略。 Geode以max-oplog-size创建每个oplog文件,默认为1 GB。 只有在压缩过程中才会从oplog中删除过时的操作,因此您需要足够的空间来存储压缩之间完成的所有操作。 对于混合使用更新和删除的区域,如果使用自动压缩,则所需磁盘空间的上限为
(1 / (1 - (compaction_threshold/100)) ) * data size
其中数据大小是您存储在磁盘存储中的所有数据的总大小。 因此,对于默认的压缩阈值50,磁盘空间大约是数据大小的两倍。 请注意,压缩线程可能落后于其他操作,导致磁盘使用暂时超过阈值。 如果禁用自动压缩,则所需的磁盘数量取决于手动压缩之间累积的过时操作数量。
根据预期的磁盘存储要求和主机系统上的可用磁盘,与主机系统管理员一起确定磁盘存储目录的放置位置。
- 确保新存储不会干扰在系统上使用磁盘的其他进程。 如果可能,请将文件存储到其他进程未使用的磁盘,包括虚拟内存或交换空间。 如果您有多个可用磁盘,为了获得最佳性能,请在每个磁盘上放置一个目录。
- 为不同的成员使用不同的目录。 您可以将任意数量的目录用于单个磁盘存储。
创建和配置磁盘存储
在您选择的位置,创建要为磁盘存储指定的所有目录。 如果在创建磁盘存储时指定的目录不可用,Geode会抛出异常。 您不需要用任何东西填充这些目录。
打开
gfsh提示符并连接到集群。在
gfsh提示符下,创建并配置磁盘存储:指定磁盘存储的名称(
--name)。- 为您的操作系统选择合适的磁盘存储名称。 磁盘存储名称用于磁盘文件名:
- 使用满足操作系统文件命名要求的磁盘存储名称。 例如,如果将数据存储在Windows系统中的磁盘上,则磁盘存储名称不能包含任何这些保留字符,<>:“/ \ |?*。
- 不要使用很长的磁盘存储名称。 完整文件名必须符合您的操作系统限制。 例如,在Linux上,标准限制为255个字符。
gfsh>create disk-store --name=serverOverflow --dir=c:\overflow_data#20480
- 为您的操作系统选择合适的磁盘存储名称。 磁盘存储名称用于磁盘文件名:
配置目录位置(
--dir)和用于存储的最大空间(在磁盘目录名称后面指定#和最大数字,以兆字节为单位)。gfsh>create disk-store --name=serverOverflow --dir=c:\overflow_data#20480
(可选)您可以配置存储的文件压缩行为。 在这种情况,计划和方案对于任何手动压缩结合使用。 例:
gfsh>create disk-store --name=serverOverflow --dir=c:\overflow_data#20480 \--compaction-threshold=40 --auto-compact=false --allow-force-compaction=true
如果需要,请配置单个oplog的最大大小(以MB为单位)。 当前文件达到此大小时,系统将前滚到新文件。 使用相对较小的最大文件大小可以获得更好的性能 例:
gfsh>create disk-store --name=serverOverflow --dir=c:\overflow_data#20480 \--compaction-threshold=40 --auto-compact=false --allow-force-compaction=true \--max-oplog-size=512
如果需要,请修改队列管理参数以进行异步排队到磁盘存储。 您可以为同步或异步排队配置任何区域(区域属性
disk-synchronous)。 服务器队列和网关发送方队列始终同步运行。 当达到queue-size(队列容量)或time-interval(毫秒)时,排队的数据被刷新到磁盘。 您还可以通过DiskStoreflushToDisk方法同步将未写入的数据刷新到磁盘。 例:gfsh>create disk-store --name=serverOverflow --dir=c:\overflow_data#20480 \--compaction-threshold=40 --auto-compact=false --allow-force-compaction=true \--max-oplog-size=512 --queue-size=10000 --time-interval=15
如果需要,修改用于写入磁盘的缓冲区的大小(以字节为单位)。 例:
gfsh>create disk-store --name=serverOverflow --dir=c:\overflow_data#20480 \--compaction-threshold=40 --auto-compact=false --allow-force-compaction=true \--max-oplog-size=512 --queue-size=10000 --time-interval=15 --write-buffer-size=65536
如果需要,修改
disk-usage-warning-percentage和disk-usage-critical-percentagethresholds,确定将触发警告的磁盘使用百分比(默认值:90%)和百分比(默认值:99 %)磁盘使用率将产生错误并关闭成员缓存。 例:gfsh>create disk-store --name=serverOverflow --dir=c:\overflow_data#20480 \--compaction-threshold=40 --auto-compact=false --allow-force-compaction=true \--max-oplog-size=512 --queue-size=10000 --time-interval=15 --write-buffer-size=65536 \--disk-usage-warning-percentage=80 --disk-usage-critical-percentage=98
以下是完整的磁盘存储cache.xml配置示例:
<disk-store name="serverOverflow" compaction-threshold="40"auto-compact="false" allow-force-compaction="true"max-oplog-size="512" queue-size="10000"time-interval="15" write-buffer-size="65536"disk-usage-warning-percentage="80"disk-usage-critical-percentage="98"><disk-dirs><disk-dir>c:\overflow_data</disk-dir><disk-dir dir-size="20480">d:\overflow_data</disk-dir></disk-dirs></disk-store>
注意: 作为在集群中的每个服务器上定义cache.xml的替代方法 - 如果启用了集群配置服务,则在gfsh中创建磁盘存储时,可以与其余集群共享磁盘存储的配置。 请参见集群配置服务概述。
修改磁盘存储
您可以使用alter disk-store命令修改脱机磁盘存储。 如果要修改默认磁盘存储配置,请使用“DEFAULT”作为磁盘存储名称。
配置区域,队列和PDX序列化以使用磁盘存储
以下是为区域,队列和PDX序列化使用已创建和命名的磁盘存储的示例。
使用磁盘存储区域持久性和溢出的示例:
gfsh:
gfsh>create region --name=regionName --type=PARTITION_PERSISTENT_OVERFLOW \--disk-store=serverPersistOverflow
cache.xml
<region refid="PARTITION_PERSISTENT_OVERFLOW" disk-store-name="persistOverflow1"/>
将命名磁盘存储用于服务器订阅队列溢出(cache.xml)的示例:
<cache-server port="40404"><client-subscriptioneviction-policy="entry"capacity="10000"disk-store-name="queueOverflow2"/></cache-server>
将命名磁盘存储用于PDX序列化元数据(cache.xml)的示例:
<pdx read-serialized="true"persistent="true"disk-store-name="SerializationDiskStore"></pdx>
在网关发件人上配置磁盘存储
网关发件人队列始终溢出,可能会保留。 如果不持久,则将它们分配给溢出磁盘存储,如果这样做,则分配给持久性磁盘存储。
将命名磁盘存储用于网关发送方队列持久性的示例:
gfsh:
gfsh>create gateway-sender --id=persistedSender1 --remote-distributed-system-id=1 \--enable-persistence=true --disk-store-name=diskStoreA --maximum-queue-memory=100
cache.xml:
<cache><gateway-sender id="persistedsender1" parallel="true"remote-distributed-system-id="1"enable-persistence="true"disk-store-name="diskStoreA"maximum-queue-memory="100"/>...</cache>
使用默认磁盘存储区进行网关发送方队列持久性和溢出的示例:
gfsh:
gfsh>create gateway-sender --id=persistedSender1 --remote-distributed-system-id=1 \--enable-persistence=true --maximum-queue-memory=100
cache.xml:
<cache><gateway-sender id="persistedsender1" parallel="true"remote-distributed-system-id="1"enable-persistence="true"maximum-queue-memory="100"/>...</cache>
磁盘存储配置参数
您可以使用gfsh create disk-store命令或cache.xml中缓存声明的<disk-store>子元素来定义磁盘存储。 所有磁盘存储都可供所有区域和队列使用。
这些<disk-store>属性和子元素在org.apache.geode.cache.DiskStoreFactory和org.apachegeode.cache.DiskStoreAPI中具有相应的gfsh create disk-storecommand-line参数以及getter和setter方法。
磁盘存储配置属性和元素
| disk-store 属性 | 描述 | 缺省值 |
|---|---|---|
name |
用于标识此磁盘存储的字符串。 所有区域和队列都通过指定此名称来选择其磁盘存储。 | DEFAULT |
allow-force-compaction |
布尔值,指示是否允许通过API或命令行工具进行手动压缩。 | false |
auto-compact |
布尔值,指示文件到达时是否自动压缩 compaction-threshold. |
true |
compaction-threshold |
文件在符合压缩条件之前允许的垃圾百分比。 垃圾由入口销毁,条目更新和区域销毁和创建创建。 超过此百分比不会使压缩发生 - 它使文件在压缩完成时有资格被压缩。 | 50 |
disk-usage-critical-percentage |
磁盘使用率高于此阈值会生成错误消息并关闭成员的缓存。 例如,如果阈值设置为99%,则1 TB驱动器上的10 GB可用磁盘空间不足会生成错误并关闭缓存。设置为“0”(零)以禁用。 | 99 |
disk-usage-warning-percentage |
磁盘使用率高于此阈值会生成警告消息。 例如,如果阈值设置为90%,则在100 GB可用磁盘空间下的1 TB驱动器上会生成警告。设置为“0”(零)以禁用。 | 90 |
max-oplog-size |
允许操作日志在自动滚动到新文件之前的最大大小(以兆字节为单位)。 此大小是oplog文件的组合大小。 | 1024 |
queue-size |
用于异步排队。 在自动刷新队列之前允许进入写入队列的最大操作数。 在刷新队列之前将条目添加到队列块的操作。 值为零意味着没有大小限制。 达到此限制或时间间隔限制将导致队列刷新。 | 0 |
time-interval |
用于异步排队。 数据刷新到磁盘之前可以经过的毫秒数。 达到此限制或队列大小限制会导致队列刷新。 | 1000 |
write-buffer-size |
用于写入磁盘的缓冲区大小(以字节为单位)。 | 32768 |
disk-storesubelement |
描述 | 缺省值 |
|---|---|---|
<disk-dirs> |
定义写入磁盘存储的系统目录及其最大大小。 | . 没有大小限制 |
disk-dirs元素
<disk-dirs>元素定义用于磁盘存储的主机系统目录。 它包含一个或多个单个<disk-dir>元素,其中包含以下内容:
- 目录规范,作为
disk-dir元素的文本提供。 - 一个可选的
dir-size属性,指定用于目录中磁盘存储的最大空间量(以兆字节为单位)。 默认情况下,没有限制。 使用的空间计算为所有oplog文件的组合大小。
您可以为disk-dirs元素指定任意数量的disk-dir子元素。 数据均匀分布在目录中的活动磁盘文件中,并保持在您设置的任何限制范围内。
例子:
<disk-dirs><disk-dir>/host1/users/gf/memberA_DStore</disk-dir><disk-dir>/host2/users/gf/memberA_DStore</disk-dir><disk-dir dir-size="20480">/host3/users/gf/memberA_DStore</disk-dir></disk-dirs>
注意: 创建磁盘存储或系统抛出异常时,目录必须存在。 Geode不会创建目录。
对不同的磁盘存储使用不同的disk-dir规范。 您不能在两个不同的成员中为同一个命名磁盘存储使用相同的目录。
修改默认磁盘存储
您可以通过为名为“DEFAULT”的磁盘存储指定所需的属性来修改默认磁盘存储的行为。
无论何时使用磁盘存储而不指定要使用的磁盘存储,Geode都会使用名为“DEFAULT”的磁盘存储。
例如,这些区域和队列配置指定持久性和/或溢出,但不指定disk-store-name。 由于未指定磁盘存储,因此这些存储使用名为“DEFAULT”的磁盘存储。
使用默认磁盘存储区域持久性和溢出的示例:
gfsh:
gfsh>create region --name=regionName --type=PARTITION_PERSISTENT_OVERFLOW
cache.xml
<region refid="PARTITION_PERSISTENT_OVERFLOW"/>
使用默认磁盘存储区进行服务器订阅队列溢出(cache.xml)的示例:
<cache-server port="40404"><client-subscription eviction-policy="entry" capacity="10000"/></cache-server>
更改默认磁盘存储的行为
Geode使用默认磁盘存储配置设置初始化默认磁盘存储。 您可以通过为名为“DEFAULT”的磁盘存储指定所需的属性来修改默认磁盘存储的行为。 关于默认磁盘存储,您唯一无法更改的是名称。
以下示例更改默认磁盘存储以允许手动压缩并使用多个非默认目录:
cache.xml:
<disk-store name="DEFAULT" allow-force-compaction="true"><disk-dirs><disk-dir>/export/thor/customerData</disk-dir><disk-dir>/export/odin/customerData</disk-dir><disk-dir>/export/embla/customerData</disk-dir></disk-dirs></disk-store>
使用磁盘存储优化系统
遵循本节中的准则,优化可用性和性能。
- Apache Geode建议在Linux或Solaris平台上运行时使用
ext4文件系统。ext4文件系统支持预分配,这有利于磁盘启动性能。 如果您在具有高写入吞吐量的延迟敏感环境中使用ext3文件系统,则可以通过将maxOplogSize(请参阅DiskStoreFactory.setMaxOplogSize)设置为低于默认值1 GB的值来提高磁盘启动性能。 通过在Geode进程启动时指定系统属性gemfire.preAllocateDisk=false来禁用预分配。 - 启动系统时,大致同时启动具有持久区域的所有成员。 创建和使用启动脚本以确保一致性和完整性。
- 使用gfsh
shutdown命令关闭系统。 这是一个有序的关闭,可以定位磁盘存储以加快启动速度。 - 配置磁盘的关键使用阈值(
disk-usage-warning-percentage和disk-usage-critical-percentage)。 默认情况下,这些设置为80%用于警告,99%用于关闭缓存的错误。 - 确定文件压缩策略,并在需要时开发监视文件和执行常规压缩的过程。
- 确定磁盘存储的备份策略并遵循它。 您可以使用
backup disk-store命令备份正在运行的系统。 - 如果在磁盘存储脱机时删除任何永久区域或更改其配置,请考虑同步磁盘存储中的区域。
启动并关闭磁盘存储
本节介绍启动和关闭期间发生的情况,并提供这些操作的过程。
启动
当您使用持久区域启动成员时,将从磁盘存储中检索数据以重新创建成员的持久区域。 如果成员未保存该区域的所有最新数据,则其他成员将拥有数据和区域创建块,等待其他成员。 具有共置条目的分区区域也在启动时阻塞,等待共置区域的条目可用。 永久网关发件人的处理方式与共处理区域相同,因此它也可以阻止区域创建。
使用日志级别的信息或以下信息,系统会提供有关等待的消息。 这里,server2的磁盘存储区具有该区域的最新数据,server1正在等待server2。
Region /people has potentially stale data.It is waiting for another member to recover the latest data.My persistent id:DiskStore ID: 6893751ee74d4fbd-b4780d844e6d5ce7Name: server1Location: /192.0.2.0:/home/dsmith/server1/.Members with potentially new data:[DiskStore ID: 160d415538c44ab0-9f7d97bae0a2f8deName: server2Location: /192.0.2.0:/home/dsmith/server2/.]Use the "gfsh show missing-disk-stores" command to see all disk storesthat are being waited on by other members.
当最新数据可用时,系统会更新区域,记录消息并继续启动。
[info 2010/04/09 10:52:13.010 PDT CacheRunner <main> tid=0x1]Done waiting for the remote data to be available.
如果成员的磁盘存储区包含从未创建的区域的数据,则数据将保留在磁盘存储区中。
每个成员的持久区域尽可能快地加载并上线,而不是不必要地等待其他成员完成。 出于性能原因,这些操作是异步发生的:
- 一旦从磁盘恢复了每个存储桶的至少一个副本,该区域就可用。 辅助存储桶将异步加载。
- 在考虑条目值之前,从磁盘存储区中的密钥文件加载条目密钥。 加载所有密钥后,Geode将异步加载条目值。 如果在加载之前请求了值,则将立即从磁盘存储中获取该值。
启动程序
要启动具有磁盘存储的系统:
首先使用持久数据同时启动所有成员. 具体如何执行此操作取决于您的成员。 确保启动托管共处区域的成员以及持久网关发件人。
在他们初始化他们的区域时,成员确定哪些具有最新的区域数据,并使用最新的数据初始化他们的区域。
对于仅在某些区域的主机成员中定义持久性的复制区域,请在非持久性复制成员之前启动持久性复制成员,以确保从磁盘恢复数据。
这是一个用于并行启动成员的bash脚本示例。 脚本等待启动完成。 如果其中一个作业失败,它将以错误状态退出。
#!/bin/bashssh servera "cd /my/directory; gfsh start server --name=servera &ssh serverb "cd /my/directory; gfsh start server --name=serverb &STATUS=0;for job in `jobs -p`doecho $jobwait $job;JOB_STATUS=$?;test $STATUS -eq 0 && STATUS=$JOB_STATUS;doneexit $STATUS;
回应被阻止的成员. 当成员阻止等待来自另一个成员的更新数据时,该成员将无限期地等待而不是使用陈旧数据联机。 使用
gfsh show missing-disk-stores命令检查缺少的磁盘存储。 请参阅处理丢失的磁盘存储。
示例启动以说明订购
以下列出了在关闭后启动复制的持久区域的两种可能性。 假设成员A(MA)首先退出,将剩余数据留在磁盘上用于RegionP。 成员B(MB)继续在RegionP上运行操作,RegionP更新其磁盘存储并使MA的磁盘存储处于过时状态。 MB退出,将最新数据保留在RegionP的磁盘上。
- 重启订单1
- MB首先启动。 MB标识它具有RegionP的最新磁盘数据并从磁盘初始化该区域。 MB不会阻止。
- MA已启动,从磁盘恢复其数据,并根据需要从MB中的数据更新区域数据。
- 重启订单2
- MA首先启动。 MA确定它没有最新的磁盘数据和块,等待MB在MA中重新创建RegionP之前启动。
- MB已启动。 MB标识它具有RegionP的最新磁盘数据并从磁盘初始化该区域。
- MA从磁盘恢复其RegionP数据,并根据需要从MB中的数据更新区域数据。
关闭
如果多个成员承载持久区域或队列,则在重新启动系统时,各个成员关闭的顺序可能很重要。 退出系统或关闭的最后一个成员具有磁盘上最新的数据。 每个成员都知道退出或关闭时哪些其他系统成员在线。 这允许成员在随后的启动时获取最新数据。
对于具有持久性的复制区域,要退出的最后一个成员具有最新数据。
对于分区区域,每个成员都会持有自己的存储桶。 使用gfsh shutdown的关闭会在退出前同步磁盘存储,因此所有磁盘存储都会保存最新的数据。 如果没有有序关闭,某些磁盘存储可能具有比其他磁盘存储更新的存储区数据。
关闭系统的最佳方法是在所有成员运行时调用gfsh shutdown命令。 所有在线数据存储将在关闭之前同步,因此所有数据存储都保留最新的数据副本。 要关闭定位器以外的所有成员:
gfsh>shutdown
To shut down all members, including locators:
gfsh>shutdown --include-locators=true
磁盘存储管理
gfsh命令行工具有许多选项可用于检查和管理磁盘存储。 gfsh工具,cache.xml文件和DiskStore API是在线和离线磁盘存储的管理工具。
有关可用命令的列表,请参阅磁盘存储命令。
磁盘存储管理命令和操作
验证磁盘存储
在磁盘存储日志文件上运行压缩
保持磁盘存储与缓存同步
配置磁盘可用空间监视
处理丢失的磁盘存储
当缓冲区刷新到磁盘时更改
您可以将Geode配置为立即写入磁盘,您可以修改操作系统行为以更频繁地执行缓冲区刷新。
磁盘存储管理命令和操作
您可以使用gfsh命令行工具管理磁盘存储。 有关gfsh命令的更多信息,请参阅gfsh和磁盘存储命令。
注意: 这些命令中的每一个都在联机磁盘存储或脱机磁盘存储上运行,但不能同时运行。
| gfsh 命令 | Online or Offline 命令 | 参见 … |
|---|---|---|
alter disk-store |
Off | 保持磁盘存储与缓存同步 |
compact disk-store |
On | 在磁盘存储日志文件上运行压缩 |
backup disk-store |
On | 为系统恢复和运营管理创建备份 |
compact offline-disk-store |
Off | 在磁盘存储日志文件上运行压缩 |
export offline-disk-store |
Off | 为系统恢复和运营管理创建备份 |
revoke missing-disk-store |
On | 处理丢失的磁盘存储 |
show missing-disk-stores |
On | 处理丢失的磁盘存储 |
shutdown |
On | 启动并关闭磁盘存储 |
validate offline disk-store |
Off | 验证磁盘存储e |
要获得任何gfsh命令的完整命令语法,请在gfsh命令行中运行help <command>。
在线磁盘存储操作
对于在线操作,gfsh必须通过JMX管理器连接到集群,并将操作请求发送给具有磁盘存储的成员。 这些命令不会在脱机磁盘存储上运行。
脱机磁盘存储操作
对于脱机操作,gfsh对指定的磁盘存储及其指定的目录运行命令。 您必须指定磁盘存储的所有目录。 例如:
gfsh>compact offline-disk-store --name=mydiskstore --disk-dirs=MyDirs
脱机操作不会在联机磁盘存储上运行。 该工具在磁盘存储运行时锁定它,因此该成员无法在操作过程中启动。
如果您尝试为联机磁盘存储运行脱机命令,则会收到如下消息:
gfsh>compact offline-disk-store --name=DEFAULT --disk-dirs=s1This disk store is in use by another process. "compact disk-store" canbe used to compact a disk store that is currently in use.
验证磁盘存储
validate offline-disk-store命令验证脱机磁盘存储的运行状况,并为您提供有关其中区域的信息,总条目以及压缩存储时将删除的记录数。
在以下时间使用此命令:
- 在压缩脱机磁盘存储之前,以帮助确定它是否值得做。
- 在还原或修改磁盘存储之前。
- 任何时候你想确定磁盘存储器的状态良好。
例子:
gfsh>validate offline-disk-store --name=ds1 --disk-dirs=hostB/bupDirectory
在磁盘存储日志文件上运行压缩
将缓存操作添加到磁盘存储时,同一条目的任何预先存在的操作记录都将过时,Apache Geode会将其标记为垃圾。 例如,当你创建一个条目,创建操作被添加到存储中。 如果稍后更新该条目,则会添加更新操作,并且创建操作将变为垃圾。 Geode不会删除垃圾记录,但它会跟踪每个操作日志中的垃圾百分比,并提供删除垃圾以压缩日志文件的机制。
Geode通过将所有非垃圾记录复制到当前日志并丢弃旧文件来压缩旧操作日志。 与日志记录一样,在压缩期间根据需要滚动oplog以保持在最大oplog设置内。
您可以将系统配置为在垃圾内容达到特定百分比时自动压缩任何已关闭的操作日志。 您还可以手动请求在线和离线磁盘存储的压缩。 对于联机磁盘存储,无论压缩包含多少垃圾,当前操作日志都不可用于压缩。
联机磁盘存储的日志文件压缩
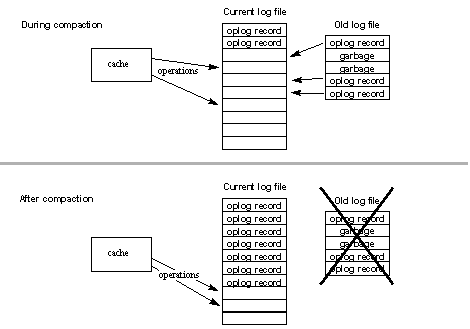
脱机压缩基本上以相同的方式运行,但没有传入的缓存操作。 此外,由于当前没有打开日志,因此压缩会创建一个新的开始日志。
运行在线压缩
当旧日志文件的垃圾内容超过总文件的配置百分比时,它们就有资格进行在线压缩。 当一个记录的操作被同一个对象的更新操作取代时,该记录就是垃圾。 在压缩期间,非垃圾记录将与新的缓存操作一起添加到当前日志中。 在线压缩不会阻止当前的系统操作。
自动压缩. 当
auto-compact为真时,Geode会在其垃圾内容超过compaction-threshold时自动压缩每个oplog。 这需要从其他操作开始循环,因此您可能希望禁用此操作并仅执行手动压缩,以控制时间。手动压缩. 要运行手动压缩:
将磁盘存储属性
allow-force-compaction设置为true。 这会导致Geode维护有关文件的额外数据,以便按需压缩。 默认情况下禁用此选项以节省空间。 您可以在系统运行时随时运行手动在线压缩。 有资格根据compaction-threshold进行压缩的Oplog被压缩到当前的oplog中。根据需要运行手动压缩。 Geode有两种类型的手动压缩:
使用
forceCompaction方法通过API压缩单个在线磁盘存储的日志。 此方法首先滚动oplog,然后压缩它们。 例:myCache.getDiskStore("myDiskStore").forceCompaction();
使用
gfsh,使用compact disk-store命令压缩磁盘存储。 例子:gfsh>compact disk-store --name=Disk1gfsh>compact disk-store --name=Disk1 --group=MemberGroup1,MemberGroup2
注意: 您需要连接到
gfsh中的JMX Manager才能运行此命令。
运行脱机压缩
离线压缩是一个手动过程。 无论他们持有多少垃圾,所有日志文件都会尽可能地压缩。 脱机压缩为压缩的日志记录创建新的日志文件。
使用gfsh,使用compact offline-disk-store压缩各个离线磁盘存储命令:
gfsh>compact offline-disk-store --name=Disk2 --disk-dirs=/Disks/Disk2gfsh>compact offline-disk-store --name=Disk2 --disk-dirs=/Disks/Disk2--max-oplog-size=512 -J=-Xmx1024m
注意: Do not perform offline compaction on the baseline directory of an incremental backup.
您必须提供磁盘存储中的所有目录。 如果未指定oplog max size,则Geode使用系统默认值。
离线压缩可能会占用大量内存。 如果在运行时出现“java.lang.OutOfMemory”错误,则可能需要使用-J=-Xmx参数增加堆大小。
手动压实的性能优势
如果禁用自动压缩并在较轻的系统负载期间或停机期间运行您自己的手动压缩,则可以在繁忙时间提高性能。 在应用程序执行大量数据操作后,您可以运行API调用。 当系统使用率很低时,你可以每晚运行compact disk-store命令。
要遵循这样的策略,您需要留出足够的磁盘空间来容纳所有未压缩的磁盘数据。 您可能需要增加系统监视以确保不会超出磁盘空间。 您可能只能运行离线压缩。 如果是这样,您可以将allow-force-compaction设置为false,并避免存储手动在线压缩所需的信息。
目录大小限制
压缩期间达到目录大小限制具有不同的结果,具体取决于您是运行自动压缩还是手动压缩:
- 对于自动压缩,系统会记录警告,但不会停止。
- 对于手动压缩,操作停止并向调用进程返回
DiskAccessException,报告系统磁盘空间不足。
示例压缩运行
在这个离线压缩运行列表的例子中,磁盘存储压缩在*_3.*文件中没有任何关系,所以它们是独立的。 *_4.*文件有垃圾记录,因此来自它们的oplog被压缩成新的*_5.*文件。
bash-2.05$ ls -ltra backupDirectorytotal 28-rw-rw-r-- 1 user users 3 Apr 7 14:56 BACKUPds1_3.drf-rw-rw-r-- 1 user users 25 Apr 7 14:56 BACKUPds1_3.crfdrwxrwxr-x 3 user users 1024 Apr 7 15:02 ..-rw-rw-r-- 1 user users 7085 Apr 7 15:06 BACKUPds1.if-rw-rw-r-- 1 user users 18 Apr 7 15:07 BACKUPds1_4.drf-rw-rw-r-- 1 user users 1070 Apr 7 15:07 BACKUPds1_4.crfdrwxrwxr-x 2 user users 512 Apr 7 15:07 .bash-2.05$ gfshgfsh>validate offline-disk-store --name=ds1 --disk-dirs=backupDirectory/root: entryCount=6/partitioned_region entryCount=1 bucketCount=10Disk store contains 12 compactable records.Total number of region entries in this disk store is: 7gfsh>compact offline-disk-store --name=ds1 --disk-dirs=backupDirectoryOffline compaction removed 12 records.Total number of region entries in this disk store is: 7gfsh>exitbash-2.05$ ls -ltra backupDirectorytotal 16-rw-rw-r-- 1 user users 3 Apr 7 14:56 BACKUPds1_3.drf-rw-rw-r-- 1 user users 25 Apr 7 14:56 BACKUPds1_3.crfdrwxrwxr-x 3 user users 1024 Apr 7 15:02 ..-rw-rw-r-- 1 user users 0 Apr 7 15:08 BACKUPds1_5.drf-rw-rw-r-- 1 user users 638 Apr 7 15:08 BACKUPds1_5.crf-rw-rw-r-- 1 user users 2788 Apr 7 15:08 BACKUPds1.ifdrwxrwxr-x 2 user users 512 Apr 7 15:09 .bash-2.05$
保持磁盘存储与缓存同步
当离线数据的配置与在线数据的配置匹配时,从脱机磁盘存储中恢复数据的速度最快。
每当您更改或删除持久区域时(通过修改cache.xml或配置区域的代码),您应该更改相应的脱机磁盘存储以匹配。 如果不这样做,则下次恢复此磁盘存储时,它将使用旧配置将该区域的所有数据恢复到临时区域。 旧配置仍将使用旧配置的资源(堆内存,堆外内存)。 如果这些资源不再可用(例如,该区域的旧配置是堆外的,但您决定不再在JVM上配置堆外内存),则磁盘存储恢复将失败。
通常的做法是拥有多个离线磁盘存储,因为集群的每个成员通常都有自己的副本。 确保将相同的alter disk-store命令应用于磁盘存储的每个脱机副本。
更改区域配置
磁盘存储脱机时,可以使用cache.xml和API设置使其区域的配置保持最新。 磁盘存储区保留区域配置属性的子集。 (有关保留属性的列表,请参阅alter disk-store)。 如果配置在启动时不匹配,cache.xml和API将覆盖任何磁盘存储设置,磁盘存储将自动更新以匹配。 因此,您无需修改磁盘存储以保持缓存配置和磁盘存储同步,但如果这样做,您将节省启动时间和内存。
例如,要更改磁盘存储中名为“partitioned_region”的区域的初始容量:
gfsh>alter disk-store --name=myDiskStoreName --region=partitioned_region--disk-dirs=/firstDiskStoreDir,/secondDiskStoreDir,/thirdDiskStoreDir--initialCapacity=20
要列出区域的所有可修改设置及其当前值,请运行不指定任何操作的命令:
gfsh>alter disk-store --name=myDiskStoreName --region=partitioned_region--disk-dirs=/firstDiskStoreDir,/secondDiskStoreDir,/thirdDiskStoreDir
从缓存配置和磁盘存储中取出一个区域
如果您决定重命名区域或将其数据拆分为两个完全不同的区域,则可以从应用程序中删除区域。 任何重要的数据重组都可能导致您退出某些数据区域。
这适用于磁盘存储脱机时删除区域。 您通过API调用或gfsh销毁的区域将自动从在线成员的磁盘存储中删除。
在应用程序开发中,当您停止使用持久区域时,也要从成员的磁盘存储区中删除该区域。
注意: 请谨慎执行以下操作。 您正在永久删除数据。
您可以通过以下两种方式之一从磁盘存储区中删除该区域:
删除整个磁盘存储文件集。 您的成员将在下次启动时使用一组空文件进行初始化。 从文件系统中删除文件时请务必小心,因为可以指定多个区域使用相同的磁盘存储目录。
使用以下命令从磁盘存储中选择性地删除已停止的区域:
gfsh>alter disk-store --name=myDiskStoreName --region=partitioned_region--disk-dirs=/firstDiskStoreDir,/secondDiskStoreDir,/thirdDiskStoreDir --remove
为防止意外数据丢失,Geode会在磁盘存储区域中维护该区域,直到您手动删除它为止。 磁盘存储中与应用程序中的任何区域无关的区域仍会加载到内存中的临时区域,并在成员的生命周期内保留。 系统无法检测您的API是否会在某个时刻创建缓存区域,因此它可以保持临时区域的加载和可用。
配置磁盘可用空间监视
要修改disk-usage-warning-percentage和disk-usage-critical-percentage阈值,请在执行gfsh create disk-store命令时指定参数。
gfsh>create disk-store --name=serverOverflow --dir=c:\overflow_data#20480 \--compaction-threshold=40 --auto-compact=false --allow-force-compaction=true \--max-oplog-size=512 --queue-size=10000 --time-interval=15 --write-buffer-size=65536 \--disk-usage-warning-percentage=80 --disk-usage-critical-percentage=98
默认情况下,磁盘使用率高于80%会触发警告消息。 磁盘使用率高于99%会生成错误并关闭访问该磁盘存储的成员缓存。 要禁用磁盘存储监视,请将参数设置为0。
要查看为现有磁盘存储设置的当前阈值,请使用gfsh describe disk-store命令:
gfsh>describe disk-store --member=server1 --name=DiskStore1
您还可以使用以下DiskStoreMXBean方法API以编程方式配置和获取这些阈值。
getDiskUsageCriticalPercentagegetDiskUsageWarningPercentagesetDiskUsageCriticalPercentagesetDiskUsageWarningPercentage
通过访问以下统计信息,可以获取磁盘空间使用情况和磁盘空间监视性能的统计信息:
diskSpacemaximumSpacevolumeSizevolumeFreeSpacevolumeFreeSpaceChecksvolumeFreeSpaceTime
请参阅磁盘空间使用情况(DiskDirStatistics).
处理丢失的磁盘存储
本节适用于为至少一个区域保存最新数据副本的磁盘存储。
显示缺少的磁盘存储
使用gfsh,show missing-disk-stores命令列出所有磁盘存储,其中包含其他成员正在等待的最新数据。
对于复制区域,此命令仅列出阻止其他成员启动的缺少成员。 对于分区区域,此命令还列出所有脱机数据存储,即使该区域的其他数据存储处于联机状态,因为它们的脱机状态可能导致缓存操作中的PartitionOfflineExceptions或阻止系统满足冗余。
例子:
gfsh>show missing-disk-storesDisk Store ID | Host | Directory------------------------------------ | --------- | -------------------------------------60399215-532b-406f-b81f-9b5bd8d1b55a | excalibur | /usr/local/gemfire/deploy/disk_store1
注意: 您需要在gfsh中连接到JMX Manager才能运行此命令。
注意: 为缺少的磁盘存储列出的磁盘存储目录可能不是您当前为该成员配置的目录。 该列表是从其他正在运行的成员中检索的 - 即报告缺失成员的成员。 它们具有上次丢失的磁盘存储在线时的信息。 如果移动文件并更改成员的配置,则这些目录位置将过时。
磁盘存储通常会丢失,因为它们的成员无法启动。 该成员可能由于多种原因而无法启动,包括:
- 磁盘存储文件损坏。 您可以通过验证磁盘存储来检查这一点。
- 成员的集群配置不正确
- 网络分区
- 驱动器故障
撤消丢失的磁盘存储
本节适用于满足以下两个条件的磁盘存储:
- 具有一个或多个区域或区域存储桶的最新数据副本的磁盘存储。
- 磁盘存储不可恢复,例如删除它们,或者文件已损坏或磁盘发生灾难性故障时。
如果无法在线提供最新的持久化副本,请使用revoke命令告知其他成员停止等待。 撤消存储后,系统会查找剩余的最新数据副本并使用该数据。
注意: 撤消后,磁盘存储无法重新引入系统。
使用gfsh show missing-disk-stores来正确识别需要撤销的磁盘存储。 revoke命令将磁盘存储区ID作为输入,由该命令列出。
例子:
gfsh>revoke missing-disk-store --id=60399215-532b-406f-b81f-9b5bd8d1b55aMissing disk store successfully revoked
当缓冲区刷新到磁盘时更改
您可以将Geode配置为立即写入磁盘,您可以修改操作系统行为以更频繁地执行缓冲区刷新。
通常,Geode将磁盘数据写入操作系统的磁盘缓冲区,操作系统会定期将缓冲区刷新到磁盘。 增加写入磁盘的频率会降低应用程序或计算机崩溃导致数据丢失的可能性,但会影响性能。 您可以使用Geode的内存中数据备份的另一个选择是提供更好的性能。 通过将数据存储在多个复制区域或配置有冗余副本的分区区域中来执行此操作。 参见地区类型.
修改操作系统的磁盘刷新
您可以更改定期刷新的操作系统设置。 您还可以从应用程序代码执行显式磁盘刷新。 有关这些选项的信息,请参阅操作系统的文档。 例如,在Linux中,您可以通过修改设置/proc/sys/vm/dirty_expire_centiseconds来更改磁盘刷新间隔。 默认为30秒。 要更改此设置,请参阅dirty_expire_centiseconds的Linux文档。
在磁盘写入上修改Geode以刷新缓冲区
您可以让Geode在每次磁盘写入时刷新磁盘缓冲区。 通过在启动Geode成员时在命令行中将系统属性gemfire.syncWrites设置为true来执行此操作。 您只能在启动成员时修改此设置。 设置此项后,Geode使用带有标记“rwd”的Java“RandomAccessFile”,这会使每个文件更新同步写入存储设备。 如果您的磁盘存储位于本地设备上,则仅保证您的数据。 请参阅Java文档中的java.IO.RandomAccessFile。
要修改Geode应用程序的设置,请在启动成员时将其添加到java命令行:
-Dgemfire.syncWrites=true
要修改缓存服务器的设置,请使用以下语法:
gfsh>start server --name=... --J=-Dgemfire.syncWrites=true
为系统恢复和运营管理创建备份
备份是磁盘存储中持久数据的副本。 备份用于将磁盘存储还原到备份时的状态。 根据集群是联机还是脱机,相应的备份和还原过程会有所不同。 在线系统目前正在运行成员。 离线系统没有任何正在运行的成员。
- 系统在线时进行备份
- What a Full Online Backup Saves
- What an Incremental Online Backup Saves
- Disk Store Backup Directory Structure and Contents
- Offline Members—Manual Catch-Up to an Online Backup
- Restore Using a Backup Made While the System Was Online
系统在线时进行备份
gfsh命令backup disk-store为集群中运行的所有成员创建磁盘存储的备份。 备份通过将命令传递给正在运行的系统成员来工作; 因此,成员需要在线才能使此操作成功。 具有持久数据的每个成员都会创建自己的配置和磁盘存储的备份。 备份不会阻止集群中的任何活动,但它确实使用资源。
注意: 请勿尝试使用操作系统的文件复制命令从正在运行的系统创建备份文件。 这将创建不完整且无法使用的副本。
准备备份
在进行备份之前,请考虑压缩磁盘存储。 如果关闭自动压缩,您可能需要进行手动压缩以节省备份通过网络复制的数据量。 有关配置手动压缩的更多信息,请参阅手动压缩.
在区域操作静止时进行备份,以避免区域数据与异步事件队列(AEQ)或WAN网关发送方(使用持久队列)之间出现不一致的可能性。 导致持久写入区域的区域操作涉及磁盘操作。 关联的队列操作也会导致磁盘操作。 这两个磁盘操作不是以原子方式进行的,因此如果在两个磁盘操作之间进行备份,则备份表示区域和队列中的数据不一致。
在系统中的低活动期间运行备份。 备份不会阻止系统活动,但它会在集群中的所有主机上使用文件系统资源,并且可能会影响性能。
通过修改成员的
cache.xml文件,为每个成员配置要备份的任何其他文件或目录。 应该包含在备份中的其他项目:- 应用程序jar文件
- 启动时应用程序需要的其他文件,例如设置类路径的文件
例如,要在备份中包含文件
myExtraBackupStuff,数据存储的cache.xml文件规范将包括:<backup>./myExtraBackupStuff</backup>
目录以递归方式复制,其中包含从此用户指定的备份中排除的任何磁盘存储。
备份到SAN(推荐)或所有成员都可以访问的目录。 确保该目录存在并具有所有成员写入目录和创建子目录的适当权限。
为备份指定的目录可以多次使用。 每次进行备份时,都会在指定目录中创建一个新子目录,该新子目录的名称代表日期和时间。
您可以使用以下两个位置之一进行备份:
单个物理位置,例如网络文件服务器,例如:
/export/fileServerDirectory/gemfireBackupLocation
系统中所有主机的本地目录,例如:
./gemfireBackupLocation
确保所有具有持久数据的成员都在系统中运行,因为脱机成员无法备份其磁盘存储。 备份命令的输出不会识别托管已脱机的复制区域的成员。
如何进行完整的在线备份
如果禁用自动压缩,则需要手动压缩:
gfsh>compact disk-store --name=Disk1
运行
gfsh backup disk-store命令,指定备份目录位置。 例如:gfsh>backup disk-store --dir=/export/fileServerDirectory/gemfireBackupLocation
输出将列出已成功备份磁盘存储的每个成员的信息。 表格信息将包含成员的名称,其UUID,备份的目录以及成员的主机名。
任何未能完成备份的在线成员都会在其最高级别的备份目录中留下名为
INCOMPLETE_BACKUP的文件。 此文件的存在标识备份文件仅包含部分备份,并且不能在还原操作中使用。验证备份以供以后恢复使用。 在命令行上,可以使用诸如以下命令检查每个备份
cd 2010-04-10-11-35/straw_14871_53406_34322/diskstores/ds1gfsh validate offline-disk-store --name=ds1 --disk-dirs=/home/dsmith/dir1
如何进行增量备份
增量备份包含自上次备份以来已更改的项目。
要执行增量备份,请使用--baseline-dir参数指定增量备份所基于的备份目录。 例如:
gfsh>backup disk-store --dir=/export/fileServerDirectory/gemfireBackupLocation--baseline-dir=/export/fileServerDirectory/gemfireBackupLocation/2012-10-01-12-30
输出将与完整在线备份的输出相同。
任何未能完成增量备份的在线成员都会在其最高级别的备份目录中留下名为“INCOMPLETE_BACKUP”的文件。 此文件的存在标识备份文件仅包含部分备份,并且不能在还原操作中使用。 下次进行备份时,将进行完整备份。
什么是完整的在线备份保存
对于具有持久数据的每个成员,完整备份包括以下内容:
包含持久区域数据的所有成员的磁盘存储文件。
cache.xml配置文件中指定的文件和目录为<backup>元素。 例如:<backup>./systemConfig/gf.jar</backup><backup>/users/user/gfSystemInfo/myCustomerConfig.doc</backup>
使用gfsh deploy命令部署的已部署JAR文件。
成员启动时的配置文件。
gemfire.properties, 包括成员启动的属性。cache.xml, 如果使用。
这些配置文件不会自动恢复,以避免干扰更新的配置。 特别是,如果从master
jar文件中提取这些文件,将单独的文件复制到工作区可以覆盖jar中的文件。 如果要备份和还原这些文件,请将它们添加为自定义<backup>元素。一个还原脚本,在Windows上称为“restore.bat”,在Linux上称为“restore.sh”。 此脚本稍后可用于执行还原。 该脚本将文件复制回原始位置。
增量在线备份保存的内容
增量备份可以保存上次备份与当前数据之间的差异。 增量备份仅复制每个成员的基准目录中尚不存在的操作日志。 对于增量备份,还原脚本包含对一个或多个先前链接的增量备份中的操作日志的显式引用。 从增量备份运行还原脚本时,它还会还原作为备份链一部分的先前增量备份的操作日志。
如果基线目录中缺少成员,因为它们处于脱机状态或在基准备份时不存在,则这些成员会将其所有文件的完整备份放入增量备份目录中。
磁盘存储备份目录结构和内容
$ cd thebackupdir$ ls -R./2012-10-18-13-44-53:dasmith_e6410_server1_8623_v1_33892 dasmith_e6410_server2_8940_v2_45565./2012-10-18-13-44-53/dasmith_e6410_server1_8623_v1_33892:config diskstores README.txt restore.sh user./2012-10-18-13-44-53/dasmith_e6410_server1_8623_v1_33892/config:cache.xml./2012-10-18-13-44-53/dasmith_e6410_server1_8623_v1_33892/diskstores:DEFAULT./2012-10-18-13-44-53/dasmith_e6410_server1_8623_v1_33892/diskstores/DEFAULT:dir0./2012-10-18-13-44-53/dasmith_e6410_server1_8623_v1_33892/diskstores/DEFAULT/dir0:BACKUPDEFAULT_1.crf BACKUPDEFAULT_1.drf BACKUPDEFAULT.if./2012-10-18-13-44-53/dasmith_e6410_server1_8623_v1_33892/user:
离线成员 - 手动追赶在线备份
如果在联机备份期间必须使成员脱机,则可以手动备份其磁盘存储。 手动将此成员的文件带入在线备份框架,并从另一个成员的脚本的副本开始手动创建还原脚本:
- 复制此成员的备份成员的目录结构。
- 根据需要重命名目录以反映此成员的特定备份,包括磁盘存储名称。
- 清除除还原脚本以外的所有文件。
- 复制此成员的文件。
- 修改还原脚本以适用于此成员。
使用系统在线时进行的备份还原
restore.sh或restore.bat脚本将文件复制回原始位置。
- 缓存成员脱机且系统关闭时,还原磁盘存储。
- 查看每个还原脚本以查看它们将文件放在何处并确保目标位置准备就绪。 还原脚本将拒绝复制具有相同名称的文件。
- 在发起备份的主机上运行每个还原脚本。
还原将这些文件复制回原始位置:
- 包含持久区域数据的所有商店的磁盘存储文件。
- 您已配置为在
cache.xml`` <backup>元素中备份的任何文件或目录。
缓存和区域快照
快照允许您保存区域数据并在以后重新加载。 典型的用例是将数据从一个环境加载到另一个环境,例如从生产系统捕获数据并将其移动到较小的QA或开发系统中。
实际上,您可以将数据从一个集群加载到另一个集群中。 管理员导出区域或整个缓存(多个区域)的快照,然后使用RegionSnapshotService或CacheSnapshotService接口以及Region.getSnapshotService或Cache.getSnapshotService方法将快照导入另一个区域或集群。
快照文件是一个二进制文件,包含来自特定区域的所有数据。 二进制格式包含序列化的键/值对,并支持PDX类型注册表以允许PDX数据的反序列化。 快照可以直接导入区域或逐个读取,以便进一步处理或转换为其他格式。
注意: 之前的Region.loadSnapshot和Region.saveSnapshot API已被弃用。 以此格式编写的数据与新API不兼容。
用法和性能说明
通过了解缓存和区域快照的执行方式来优化缓存和区域快照功能
导出缓存和区域快照
要将Geode缓存或区域数据保存到稍后可以加载到另一个集群或区域的快照,请使用
cache.getSnapshotService.saveAPI,region.getSnapshotService.saveAPI或gfsh命令行界面 (导出数据)。导入缓存和区域快照
要导入先前导出到另一个集群或区域的Geode缓存或区域数据快照,请使用
cache.getSnapshotService.loadAPI,region.getSnapshotService.loadAPI或gfsh命令行界面(import data)。导入或导出期间过滤条目
您可以通过在导入或导出区域或缓存期间过滤条目来自定义快照。
以编程方式读取快照
您可以逐个条目地读取快照,以便进一步处理或转换为其他格式。
用法和性能说明
通过了解缓存和区域快照的执行方式来优化缓存和区域快照功能
缓存一致性和并发操作
导入和导出区域数据是一种管理操作,某些同时运行时条件可能导致导入或导出操作失败,例如重新平衡分区区域存储桶或遇到网络分区事件时。 此行为是预期的,您应该重试该操作。 重做导出会覆盖不完整的快照文件,并重做导入会更新部分导入的数据。
快照功能不保证一致性。 快照导入或导出期间的并发缓存操作可能导致数据一致性问题。 如果快照一致性很重要,我们建议您在导出和导入之前使应用程序脱机,以提供安静的时间段以确保快照中的数据一致性。
例如,导出期间对区域条目的修改可能会导致快照包含一些但不是所有更新。 如果在导出期间条目{A,B}更新为{A’,B’},则快照可以包含{A,B’},具体取决于写入顺序。 此外,导入期间对区域条目的修改可能导致缓存中的更新丢失。 如果区域包含条目{A,B}且快照包含{A’,B’},则在导入完成后,并发更新{A ,B }可能导致包含{A *,B’}的区域。
默认行为是在调用快照操作的节点上执行所有I/O操作。 如果该区域是分区区域,这将涉及通过网络收集或分散数据。
性能注意事项
使用数据快照功能时,请注意以下性能注意事项:
- 导入和导出缓存或区域快照会导致额外的CPU和网络负载。 您可能需要根据应用程序和基础结构增加CPU容量或网络带宽。 此外,如果导出已配置为溢出到磁盘的区域,则可能需要其他磁盘I/O才能执行导出。
- 导出分区区域数据时,请分配额外的堆内存,以便执行导出的成员可以缓冲从其他缓存成员收集的数据。 除了支持应用程序或缓存所需的任何配置外,还要为每个成员分配至少10MB的堆内存。
导出缓存和区域快照
要将Geode缓存或区域数据保存到稍后可以加载到另一个集群或区域的快照,请使用cache.getSnapshotService.save API,region.getSnapshotService.save API或gfsh命令行界面 (export data)。
如果在导出期间发生错误,则导出将暂停并取消快照操作。 暂停导出的典型错误包括完整磁盘,文件权限问题和网络分区等方案。
导出缓存快照
导出整个缓存时,它会将缓存中的所有区域作为单独的快照文件导出到目录中。 如果未指定目录,则默认为当前目录。 为每个区域创建快照文件,导出操作使用以下约定自动命名每个快照文件名:
snapshot-<region>[-<subregion>]*
当导出操作写入快照文件名时,它会用短划线(’ - ‘)替换区域路径中的每个正斜杠(’/‘)。
使用 Java API:
File mySnapshotDir = ...Cache cache = ...cache.getSnapshotService().save(mySnapshotDir, SnapshotFormat.GEMFIRE);
可选,您可以在导出期间在快照条目上设置过滤器。 有关示例,请参阅导入或导出期间的过滤条目。
导出区域快照
您还可以使用以下API或gfsh命令导出特定区域:
Java API:
File mySnapshot = ...Region<String, MyObject> region = ...region.getSnapshotService().save(mySnapshot, SnapshotFormat.GEMFIRE);
gfsh:
打开gfsh提示符。 连接到Geode集群后,在提示符下键入:
gfsh>export data --region=Region --file=FileName.gfd --member=MemberName
其中Region对应于要导出的区域的名称,FileName(必须以.gfd结尾)对应于导出文件的名称,MemberName对应于承载该区域的成员。 例如:
gfsh>export data --region=region1 --file=region1_2012_10_10.gfd --member=server1
快照文件将写在远程成员上的--fileargument指定的位置。 例如,在上面的示例命令中,region1_2012_10_10.gfd文件将写在server1的工作目录中。 有关此命令的更多信息,请参阅导出数据.
使用选项导出示例
这些示例显示如何包含用于导出分区区域的parallel选项。 请注意,parallel选项采用目录而不是文件; 见export data for details.
Java API:
File mySnapshotDir = ...Region<String, MyObject> region = ...SnapshotOptions<Integer, MyObject> options =region.getSnapshotServive.createOptions().setParallelMode(true);region.getSnapshotService().save(mySnapshotDir, SnapshotFormat.GEMFIRE, options);
gfsh:
上面的Java API示例实现了与以下gfsh命令相同的目的:
gfsh>export data --parallel --region=region1 --dir=region1_2012_10_10 --member=server1
导入缓存和区域快照
要导入先前导出到另一个集群或区域的Geode缓存或区域数据快照,请使用cache.getSnapshotService.loadAPI,region.getSnapshotService.load API或gfsh命令行界面 (import data)。
导入要求
在导入区域快照之前:
- 确保正确配置了缓存。 配置所有已注册的PdxSerializers,DataSerializers和Instantiators; 创建区域; 并确保类路径包含任何必需的类。
- 导入包含PDX类型的快照时,必须等到导出的类型定义导入缓存之后才能插入导致类型冲突的数据。 建议您在插入数据之前等待导入完成。
导入限制
在导入期间,不会调用CacheWriter和CacheListener回调。
如果在导入期间发生错误,则导入将暂停,并且该区域将包含一些但不是所有快照数据。
导入后,缓存客户端的状态不确定。 客户端缓存中的数据可能与导入的数据不一致。 导入期间使客户端脱机,并在导入完成后重新启动它。
导入缓存快照
导入缓存快照时,快照文件将导入到快照导出期间使用的同一区域(由名称确定的匹配)。 导入缓存时,将位于目录中的所有快照文件导入缓存。 API尝试加载指定目录中的所有文件。
Java API:
File mySnapshotDir = ...Cache cache = ...cache.getSnapshotService().load(mySnapshotDir, SnapshotFormat.GEMFIRE);
导入区域快照
Java API:
File mySnapshot = ...Region<String, MyObject> region = ...region.getSnapshotService().load(mySnapshot, SnapshotFormat.GEMFIRE);
gfsh:
打开gfsh提示符。 连接到Geode集群后,在提示符下键入:
gfsh>import data --region=Region --file=FileName.gfd --member=MemberName
其中 Region 对应于要将数据导入的区域的名称; FileName (必须以.gfd结尾)对应于要导入的文件的名称; 和 MemberName 对应一个托管该区域的成员。 例如:
gfsh>import data --region=region1 --file=region1_2012_10_10.gfd --member=server2
在导入之前,快照文件必须已驻留在--file参数中指定的位置的指定成员上。
有关此命令的更多信息,请参阅导入数据. 有关如何使用其他选项调用此命令的示例,请参阅使用选项导出示例.
导入或导出期间过滤条目
您可以通过在导入或导出区域或缓存期间过滤条目来自定义快照。
例如,使用过滤器将数据导出限制到特定日期范围。 如果在导入或导出缓存时设置过滤器,则过滤器将应用于缓存中的每个区域。
以下示例按偶数键过滤快照数据。
File mySnapshot = ...Region<Integer, MyObject> region = ...SnapshotFilter<Integer, MyObject> even = new SnapshotFilter<Integer, MyObject>() {@Overridepublic boolean accept(Entry<Integer, MyObject> entry) {return entry.getKey() % 2 == 0;}};RegionSnapshotService<Integer, MyObject> snapsrv = region.getSnapshotService();SnapshotOptions<Integer, MyObject> options = snapsrv.createOptions().setFilter(even);// only save cache entries with an even keysnapsrv.save(mySnapshot, SnapshotFormat.GEMFIRE, options);
以编程方式读取快照
您可以逐个条目地读取快照,以便进一步处理或转换为其他格式。
以下是处理先前生成的快照文件中的条目的快照阅读器的示例。
File mySnapshot = ...SnapshotIterator<String, MyObject> iter = SnapshotReader.read(mySnapshot);try {while (iter.hasNext()) {Entry<String, MyObject> entry = iter.next();String key = entry.getKey();MyObject value = entry.getValue();System.out.println(key + " = " + value);}} finally {iter.close();}
区域压缩
本节介绍区域压缩,其优点和用法。
减少Geode内存消耗的一种方法是在您的区域中启用压缩。 Geode允许您使用可插拔压缩器(压缩编解码器)压缩内存中的区域值。 Geode包含Snappy压缩器作为内置压缩编解码器; 但是,您可以为每个压缩区域实现和指定不同的压缩器。
怎样得到压缩
在区域中启用压缩时,存储在该区域中的所有值都将在内存中进行压缩。 密钥和索引不会被压缩。 放入内存高速缓存时会压缩新值,并在从高速缓存读取时解压缩所有值。 持久化到磁盘时不会压缩值。 在通过线路发送给其他对等成员或客户端之前,将对值进行解压缩。
启用压缩后,将压缩区域中的每个值,并将每个区域条目压缩为单个单元。 无法压缩条目的各个字段。
您可以在同一缓存中混合使用压缩区域和非压缩区域。
使用压缩的指南
本主题描述在决定是否使用压缩时要考虑的因素。
如何在区域中启用压缩
本主题介绍如何在您所在的区域启用压缩。
使用压缩器
使用区域压缩时,您可以使用Geode附带的默认Snappy压缩器,也可以指定自己的压缩器。
压缩和非压缩区域的性能比较
压缩区域与非压缩区域的比较性能可以根据区域的使用方式以及区域是否托管在内存绑定的JVM中而变化。
使用压缩的指南
本主题描述在决定是否使用压缩时要考虑的因素。
在决定是否在您所在的地区启用压缩时,请查看以下准则:
当JVM内存使用率过高时使用压缩. 压缩允许您在内存中存储更多区域数据,并减少昂贵的垃圾收集周期数,以防止JVM在内存使用率较高时耗尽内存。
要确定JVM内存使用率是否很高,请检查以下统计信息:
- vmStats>freeMemory
- vmStats->maxMemory
- ConcurrentMarkSweep->collectionTime
如果可用内存量经常降至20%-25%以下或者垃圾收集周期的持续时间通常偏高,那么托管在该JVM上的区域是启用压缩的良好候选者。
考虑区域条目中字段的类型和长度. 由于压缩是分别对每个条目执行的(而不是整个区域),因此请考虑单个条目中重复数据的可能性。 重复的字节更容易压缩。 此外,由于区域条目在被压缩之前首先被序列化为字节区域,因此数据可能压缩的程度取决于整个条目中的重复字节的数量和长度,而不仅仅是单个字段。 最后,条目越大,压缩越有可能获得良好的结果,因为重复字节和一系列重复字节的可能性增加。
考虑您要压缩的数据类型. 存储的数据类型对数据压缩的程度有很大影响。 字符串数据通常比数字数据压缩得更好,因为字符串字节更有可能重复; 然而,情况可能并非总是如此。 例如,包含两个短的唯一字符串的区域条目在压缩时可能无法提供与另一个包含大量整数值的区域条目相同的内存节省。 简而言之,在评估压缩区域的潜在收益时,请考虑单个序列化区域条目具有重复字节的可能性,更重要的是一系列重复字节的长度。 此外,已经压缩的数据(例如JPEG格式文件)实际上可以使用更多内存。
如果要存储大文本值,请压缩. 如果要在Geode中存储大型文本值(如JSON或XML)或Blob,压缩将受益于压缩,这将是有益的。
考虑被查询的字段是否已编入索引. 您可以查询压缩区域; 但是,如果您要查询的字段尚未编入索引,则必须先解压缩字段,然后才能将其用于比较。 简而言之,在查询非索引字段时,可能会产生一些查询性能成本。
存储在压缩区域中的对象必须是可序列化的. 压缩仅对字节数组进行操作,因此存储在压缩区域中的对象必须是可序列化和可反序列化的。 对象可以实现Serializable接口,也可以使用其他Geode序列化机制(例如PdxSerializable)。 实施者应始终注意,当启用压缩时,放入区域的对象实例在取出时将不是同一个实例。 因此,当将包含对象放入区域并从区域中取出时,瞬态属性将失去其值。
压缩区域将默认启用克隆. 设置压缩器然后禁用克隆会导致异常。 这些选项是不兼容的,因为压缩/序列化然后解压缩/反序列化的过程将导致创建的对象的不同实例,并且可能被解释为克隆该对象。
如何在区域中启用压缩
本主题介绍如何在您所在的区域启用压缩。
要在您的区域上启用压缩,请在cache.xml中设置以下region属性:
<?xml version="1.0" encoding= "UTF-8"?><cache xmlns="http://geode.apache.org/schema/cache"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://geode.apache.org/schema/cache http://geode.apache.org/schema/cache/cache-1.0.xsd"version="1.0” lock-lease="120" lock-timeout= "60" search-timeout= "300" is-server= "true" copy-on-read= "false" ><region name="compressedRegion" ><region-attributes data-policy="replicate" ... /><compressor><class-name>org.apache.geode.compression.SnappyCompressor</class-name></compressor>...</region-attributes></region></cache>
在Compressor元素中,指定压缩器实现的类名。 此示例指定与Geode捆绑在一起的Snappy压缩器。 您还可以指定自定义压缩器。 有关示例,请参阅使用压缩器。
可以在使用gfsh创建区域期间或以编程方式启用压缩。
使用 gfsh:
gfsh>create-region --name=”CompressedRegion” --compressor=”org.apache.geode.compression.SnappyCompressor”;
API:
regionFactory.setCompressor(new SnappyCompressor());
或者
regionFactory.setCompressor(SnappyCompressor.getDefaultInstance());
如何检查压缩是否已启用
您还可以通过查询正在使用的编解码器来检查区域是否已启用压缩。 空编解码器表示没有为该区域启用压缩。
Region myRegion = cache.getRegion("myRegion");Compressor compressor = myRegion.getAttributes().getCompressor();
使用压缩器
使用区域压缩时,您可以使用Geode附带的默认Snappy压缩器,也可以指定自己的压缩器。
压缩API由压缩提供程序必须实现的单个接口组成。 默认压缩器(SnappyCompressor)是与产品捆绑在一起的单个压缩实现。 请注意,由于Compressor是无状态的,因此任何JVM中只需要一个实例; 但是,可以毫无问题地使用多个实例。 可以使用SnappyCompressor.getDefaultInstance()静态方法检索SnappyCompressor的单个默认实例。
注意: Geode附带的Snappy编解码器不能与Solaris部署一起使用。 Snappy仅支持Geode的Linux,Windows和macOS部署。
此示例提供自定义Compressor实现:
package com.mybiz.myproduct.compression;import org.apache.geode.compression.Compressor;public class LZWCompressor implements Compressor {private final LZWCodec lzwCodec = new LZWCodec();@Overridepublic byte[] compress(byte[] input) {return lzwCodec.compress(input);}@Overridepublic byte[] decompress(byte[] input) {return lzwCodec.decompress(input);}}
要在区域上使用新的自定义压缩器:
确保新压缩程序包在将承载该区域的所有JVM的类路径中可用。
使用以下任一机制为该区域配置自定义压缩器:
使用 gfsh:
gfsh>create-region --name=”CompressedRegion” \--compressor=”com.mybiz.myproduct.compression.LZWCompressor”
使用 API:
例如:
regionFactory.setCompressor(new LZWCompressor());
cache.xml:
<region-attributes><Compressor><class-name>com.mybiz.myproduct.compression.LZWCompressor</class-name></Compressor></region-attributes>
更改已压缩区域的压缩器
您通常在创建区域时在区域上启用压缩。 在区域联机时,您无法修改Compressor或禁用该区域的压缩。
但是,如果需要更改压缩器或禁用压缩,可以通过执行以下步骤来执行此操作:
- 关闭托管您要修改的区域的成员。
- 修改成员的cache.xml文件,指定新压缩器或从区域中删除压缩器属性。
- 重启成员。
压缩和非压缩区域的性能比较
压缩区域与非压缩区域的比较性能可以根据区域的使用方式以及区域是否托管在内存绑定的JVM中而变化。
在考虑启用压缩的成本时,您应该考虑读取和写入压缩数据的相对成本以及压缩成本占管理区域中条目的总时间的百分比。 作为一般规则,在区域上启用压缩将为区域创建和更新操作增加30% - 60%的开销,而不是区域获取操作。 因此,启用压缩会对写入较重的区域产生比读取较重的区域更多的开销。
但是,在尝试评估启用压缩的性能成本时,还应考虑压缩成本相对于管理区域中条目的总成本。 可以以这样的方式调整区域,使得其针对读取和/或写入性能进行高度优化。 例如,未保存到磁盘的复制区域将具有比保存到磁盘的分区区域更好的读写性能。 对已针对读取和写入性能进行了优化的区域启用压缩将比使用未以此方式优化的区域上的压缩提供更明显的结果。 更具体地,在读/写优化区域上性能可能降低几百%,而在非优化区域上它可能仅降低5%到10%。
有关性能的最终说明与在内存绑定JVM中对区域启用压缩时的成本有关。 启用压缩通常假定封闭的JVM受内存限制,因此花费大量时间进行垃圾回收。 在这种情况下,性能可以提高几百%,因为JVM将运行更少的垃圾收集周期并且在运行周期时花费更少的时间。
监控压缩性能
以下统计信息提供对缓存压缩的监视:
compressTimedecompressTimecompressionsdecompressionspreCompressedBytespostCompressedBytes
请参阅缓存性能(CachePerfStats) 用于统计描述。
网络分区
Apache Geode体系结构和管理功能有助于检测和解决网络分区问题。
网络分区管理的工作原理
Geode通过使用加权系统来确定剩余的可用成员是否具有足够的仲裁以继续作为集群来处理网络中断。
故障检测和成员资格视图
Geode使用故障检测从成员资格视图中删除无响应的成员。
成员协调员,主要成员和成员加权
网络分区检测使用指定的成员资格协调器和加权系统来计算潜在客户成员以确定是否发生了网络分区。
网络分区方案
本主题描述网络分区方案以及集群的分区端发生的情况。
配置Apache Geode处理网络分区
本节列出了网络分区检测的配置步骤。
防止网络分区
本节提供了可以阻止网络分区发生的简短列表。
网络分区管理的工作原理
Geode通过使用加权系统来确定剩余的可用成员是否具有足够的仲裁以继续作为集群来处理网络中断。
为每个成员分配权重,并通过将当前响应成员的总权重与响应成员的先前总权重进行比较来确定法定人数。
当成员无法相互查看时,您的集群可以拆分为单独的运行系统。 此问题的典型原因是网络故障。 检测到分区系统时,只有系统的一侧保持运行,另一侧自动关闭。
默认情况下,网络分区检测功能启用,其中enable-network-partition-detection属性为true。 有关详细信息,请参阅配置Apache Geode以处理网络分区。 无论此配置设置如何,始终执行和记录仲裁权重计算。
检测网络分区的整个过程如下:
集群启动。 启动集群时,首先启动定位器,然后启动缓存服务器,然后启动其他成员,例如访问集群数据的应用程序或进程。
成员启动后,最老的成员(通常是定位器)承担成员协调员的角色。 成员出现时会发生对等发现,成员会为集群生成成员资格发现列表。 当每个成员进程启动时,定位器分发成员资格发现列表。 此列表通常包含有关当前成员协调员的提示。
成员加入并在必要时离开集群:
成员进程向协调器发出加入集群的请求。 如果经过身份验证,协调员将创建新的成员资格视图,将新成员资格视图交给新成员,并通过向现有成员发送视图准备消息开始发送新成员资格视图(添加新成员)的过程 在视图中。
当成员加入系统时,成员可能也会通过正常的故障检测过程离开或被移除。 故障检测会删除无响应或缓慢的成员。 请参阅管理慢速接收器和故障检测和成员资格视图,用于描述故障检测过程。 如果发出包含一个或多个失败进程的新成员资格视图,协调器将记录新的权重计算。 在任何时候,如果由于无响应的进程而检测到仲裁丢失,协调器还将记录严重级别的消息以识别失败的进程:
Possible loss of quorum detected due to loss of {0} cache processes: {1}
其中{0}是失败的进程数,{1}列出进程。
每当协调器收到成员变更的警报(成员加入或离开集群)时,协调器就会生成新的成员资格视图。 成员资格视图由两阶段协议生成:
- 在第一阶段,成员协调员向所有成员发送视图准备消息,并等待12秒,以获得来自每个成员的视图准备确认消息。 如果协调器在12秒内未收到来自成员的ack消息,则协调器会尝试连接到该成员的故障检测套接字。 如果协调器无法连接到成员的故障检测套接字,则协调器会声明该成员已死,并从头开始再次启动成员资格视图协议。
- 在第二阶段,协调器将新的成员资格视图发送给承认视图准备消息或通过连接测试的所有成员。
每次成员协调员发送视图时,每个成员都会计算当前成员资格视图中成员的总权重,并将其与先前成员资格视图的总权重进行比较。 一些条件需要注意:
- 当第一个成员资格视图发出时,没有累积的损失。 第一个视图只有附加内容。
- 如果新协调员没有看到前一个(失败的)协调员发送的最后一个成员资格视图,则可能会有一个陈旧的成员资格视图。 如果在该失败期间添加了新成员,则在发送第一个新视图时可能会忽略新成员。
- 如果在故障转移期间将成员移除给新协调员,那么新协调员将必须在视图准备步骤中确定这些损失。
使用默认值
enable-network-partition-detection,在单个成员资格视图更改(丢失仲裁)中检测到总成员资格权重降至51%以下的任何成员都会声明网络分区事件。 协调器向所有成员(甚至是非响应成员)发送网络分区检测到的UDP消息,然后使用ForcedDisconnectException关闭集群。 如果成员在协调器关闭系统之前未能收到消息,则该成员负责自行检测事件。
假设在声明网络分区时,构成仲裁的成员将继续操作。 幸存的成员选出新的协调员,指定一名主要成员,等等。
故障检测和成员资格视图
Geode使用故障检测从成员资格视图中删除无响应的成员。
故障检测
网络分区具有故障检测协议,当NIC或计算机发生故障时,该协议不会挂起。 故障检测使每个成员在成员资格视图中观察来自对等体的消息(参见下面的“成员资格视图”视图布局)。 怀疑其对等方失败的成员向可疑成员发送数据报心跳请求。 在没有来自可疑成员的回复的情况下,可疑成员向所有其他成员广播SuspectMembersMessage数据报消息。 协调器尝试连接到可疑成员。 如果连接尝试失败,则会从成员资格视图中删除可疑成员。 将向可疑成员发送消息以断开与集群的连接并关闭缓存。 在收到SuspectMembersMessage的同时,如果协调者是可疑成员,则分布式算法会促使视图中最左边的成员充当协调者。
如果在收到对消息的响应之前经过gemfire.properties ack-wait-threshold,如果无法对该成员进行TCP/IP连接,则对成员也会启动故障检测处理 (P2P)消息传递,如果没有从该成员检测到其他流量。
注意: TCP连接ping不用于连接保持活动目的; 它仅用于检测失败的成员。 有关TCP保持活动配置,请参阅TCP/IP KeepAlive配置。
如果发送包含一个或多个失败成员的新成员资格视图,协调员将记录新的仲裁权重计算。 在任何时候,如果由于无响应进程而检测到仲裁丢失,协调器还将记录严重级别的消息以识别失败的成员:pre由于{0}缓存进程丢失而检测到的仲裁可能丢失:{1}
其中{0}是失败的进程数,{1}列出成员(缓存进程)。
成员视图
以下是示例成员资格视图:
[info 2012/01/06 11:44:08.164 PST bridgegemfire1 <UDP Incoming Message Handler> tid=0x1f]Membership: received new view [ent(5767)<v0>:8700|16] [ent(5767)<v0>:8700/44876,ent(5829)<v1>:48034/55334, ent(5875)<v2>:4738/54595, ent(5822)<v5>:49380/39564,ent(8788)<v7>:24136/53525]
成员资格视图的组件如下:
视图的第一部分 (
[ent(5767)<v0>:8700|16]
在上面的例子中) 对应于视图ID。 它确定:
- 上面例子中的成员协调员的地址和processId-
ent(5767)。 - 在上面的例子中,成员首次出现在 -
<v0>中的成员资格视图的视图号(<vXX>)。 - 上例中的成员协调员 -
8700的成员端口。 - 上面例子中的view-number-
16
视图的第二部分列出了当前视图中的所有成员进程。
[ent(5767)<v0>:8700/44876, ent(5829)<v1>:48034/55334, ent(5875)<v2>:4738/54595, ent(5822)<v5>:49380/39564, ent(8788)<v7>:24136/53525],在上面的例子中。每个列出的成员的总体格式为:
Address(processId)<vXX>:membership-port/distribution port。 成员协调员几乎总是视图中的第一个成员,其余的按年龄排序。membership -port是用于发送数据报的JGroups TCP UDP端口。 分发端口是用于缓存消息传递的TCP / IP端口。
每个成员都会观察其成员的右侧以进行故障检测。
成员协调员,主要成员和成员加权
网络分区检测使用指定的成员资格协调器和加权系统来计算潜在客户成员以确定是否发生了网络分区。
成员协调员和主要成员
成员协调员是管理集群中其他成员的进入和退出的成员。 启用网络分区检测后,协调器可以是任何Geode成员,但首选定位器。 在基于定位器的系统中,如果所有定位器都处于重新连接状态,则系统继续运行,但在成功重新连接定位器之前,新成员无法加入。 定位器重新连接后,重新连接的定位器将接管协调器的角色。
当协调器关闭时,它会发出一个视图,将其从列表中删除,其他成员必须确定新协调器是谁。
主要成员由协调员确定。 任何已启用网络分区检测的成员,不托管定位器,并且不是管理员界面,只有成员才有资格被协调员指定为主要成员。 协调员选择符合标准的最长寿命成员。
主要成员角色的目的是提供额外的重量。 它不执行任何特定功能。
成员加权系统
默认情况下,为各个成员分配以下权重:
- 除lead成员外,每个成员的权重为10。
- lead成员的权重为15。
- 定位器的重量为3。
您可以通过在启动时定义gemfire.member-weight系统属性来修改特定成员的默认权重。
将视图改变之前的成员的权重加在一起并与丢失的成员的权重进行比较。 丢失的成员被视为在最后一个视图和完成的视图准备消息发送之间被删除的成员。 如果在单个成员资格视图更改中成员资格减少了一定百分比,则会声明网络分区。
损失百分比阈值为51(表示51%)。 请注意,百分比计算使用标准舍入。 因此,值50.51舍入为51.如果舍入损失百分比等于或大于51%,则成员协调员启动关闭。
样本成员权重计算
本节提供了一些示例计算。
例子 1: 集群有12个成员。 2个定位器,10个缓存服务器(一个缓存服务器被指定为主要成员。)查看总权重等于111。
- 4个缓存服务器无法访问。 成员总权重减少40(36%)。 由于36%低于51%的损失阈值,因此集群保持不变。
- 1个定位器和4个缓存服务器(包括主要成员)变得无法访问。 成员减重等于48(43%)。 由于43%低于51%的损失阈值,因此集群保持不变。
- 5个缓存服务器(不包括主要成员),两个定位器都无法访问。 成员减重等于56(49%)。 由于49%低于51%的损失阈值,因此集群保持不变。
- 5个缓存服务器(包括主要成员)和1个定位器变得无法访问。 成员减重等于58(52%)。 由于52%大于51%阈值,协调器启动关闭。
- 6个缓存服务器(不包括主要成员),两个定位器都无法访问。 成员减重等于66(59%)。 由于59%大于51%阈值,因此新选出的协调器(缓存服务器,因为没有定位器保留)将启动关闭。
例子 2: 集群有4个成员。 2个缓存服务器(1个缓存服务器被指定为主要成员),2个定位器。 查看总权重是31。
- 指定为主要成员的缓存服务器变得无法访问。 成员减重等于15或48%。 集群保持工作状态。
- 指定为主要成员的缓存服务器和1个定位器变得无法访问。 成员减重等于18或58%。 成员协调员启动关闭。 如果无法访问的定位器是成员协调器,则另一个定位器被选为协调器,然后启动关闭。
即使未启用网络分区,如果由于无响应进程而检测到仲裁丢失,定位器也会记录严重级别的消息以识别失败的进程:pre由于{0}缓存进程丢失而检测到的仲裁可能丢失:{1}
其中{0}是失败的进程数,{1}列出进程。
启用网络分区检测只允许一个子组在拆分后继续存在。 系统的其余部分已断开连接,缓存已关闭。
发生关闭时,关闭的成员将记录以下警报消息:由于{0}缓存进程丢失导致可能的网络分区事件导致退出:{1}
其中{0}是丢失成员的计数,{1}是丢失的成员ID列表。
网络分区方案
本主题描述网络分区方案以及集群的分区端发生的情况。

失败的一面是什么
在网络分区方案中,“丢失方”构成了集群分区,其中成员协调器检测到成员的法定人数不足以继续。
成员协调员在发出其视图准备消息后计算成员权重变化。 如果在视图准备阶段之后没有剩余法定数量的成员,则“丢失方”上的协调器声明网络分区事件,并向成员发送检测到网络分区的UDP消息。 然后协调器使用ForcedDisconnectException关闭其集群。 如果成员在协调器关闭连接之前未能收到消息,则它负责自行检测事件。
当丢失方发现网络分区事件已经发生时,所有对等成员都会收到RegionDestroyedException并带有Operation:FORCED_DISCONNECT。
如果安装了CacheListener,则使用RegionDestroyedEvent调用afterRegionDestroy回调,如此示例所示,由丢失方的回调记录。 对等成员进程ID是14291(主要成员)和14296,定位器是14289。
[info 2008/05/01 11:14:51.853 PDT <CloserThread> tid=0x4a]Invoked splitBrain.SBListener: afterRegionDestroy in client1 whereIWasRegistered: 14291event.isReinitializing(): falseevent.getDistributedMember(): thor(14291):40440/34132event.getCallbackArgument(): nullevent.getRegion(): /TestRegionevent.isOriginRemote(): falseOperation: FORCED_DISCONNECTOperation.isDistributed(): falseOperation.isExpiration(): false
仍然在缓存上主动执行操作的成员可能会看到ShutdownExceptions或CacheClosedExceptions withCustsed by:ForcedDisconnectException。
孤立的成员做了什么
当成员与所有定位器隔离时,它无法接收成员资格视图更改。 它无法知道当前协调员是否存在,或者如果已经离开,是否有其他成员可以接管该角色。 在这种情况下,成员最终将检测到所有其他成员的丢失,并将使用损失阈值来确定是否应该自行关闭。 对于具有2个定位器和2个高速缓存服务器的集群,与非高速缓存服务器和两个定位器的通信丢失将导致这种情况,并且剩余的高速缓存服务器最终会自行关闭。
配置Apache Geode处理网络分区
本节列出了与网络分区检测相关的配置注意事项。
系统使用成员协调员和指定为主要成员的系统成员的组合来检测和解决网络分区问题。
网络分区检测适用于所有环境。 使用多个定位器可以减轻网络分区的影响。 请参阅配置点对点发现.
默认情况下启用网络分区检测。
gemfire.properties文件中的默认设置是enable-network-partition-detection=true
未启用网络分区检测的进程不能成为主要成员,因此它们的失败不会触发网络分区的声明。
所有系统成员都应具有相同的
enable-network-partition-detection设置。 如果他们不这样做,系统会在启动时抛出GemFireConfigException。如果使用分区或持久区域,则
enable-network-partition-detection属性必须为true。 如果您创建一个持久区域并且enable-network-partition-detection设置为false,您将收到以下警告消息:Creating persistent region {0}, but enable-network-partition-detection is set to false.Running with network partition detection disabled can lead to an unrecoverable system in theevent of a network split."
使用范围设置为
DISTRIBUTED_ACK或GLOBAL配置要防止网络分区的区域。 不要使用DISTRIBUTED_NO_ACK范围。 这可以防止在检测到网络分区之前在整个集群中执行操作。 注意:如果在启用网络分区检测时检测到DISTRIBUTED_NO_ACK区域,则Geode会发出警报:Region {0} is being created with scope {1} but enable-network-partition-detection is enabled in the distributed system.This can lead to cache inconsistencies if there is a network failure.
这些其他配置参数会影响网络分区检测或与之交互。 检查它们是否适合您的安装并根据需要进行修改。
- 如果启用了网络分区检测,则允许的成员资格权重丢失的阈值百分比值将自动配置为51.您无法修改此值。 注意:减重计算使用舍入到最近。 因此,值50.51舍入为51并将导致网络分区。
- 如果成员的
ack-wait-threshold(默认为15秒)和ack-severe-alert-threshold(15秒)属性在接收到对消息的响应之前已经过了,则启动故障检测。 如果修改ack-wait-threshold配置值,则应修改ack-severe-alert-threshold以匹配其他配置值。 - 如果系统有客户端连接到它,客户端的’cache.xml
池read-timeout应该设置为服务器的gemfire.properties文件中member-timeout`设置的至少三倍。 默认池“read-timeout”设置为10000毫秒。 - 您可以通过在启动时指定系统属性
gemfire.member-weight来调整成员的默认权重。 例如,如果您有一些托管所需服务的虚拟机,则可以在启动时为其分配更高的权重。
默认情况下,由网络分区事件强制退出集群的成员将自动重新启动并尝试重新连接。 数据成员将尝试重新初始化缓存。 请参阅使用自动重新连接处理强制高速缓存断开连接.
防止网络分区
本节提供了可以阻止网络分区发生的简短列表。
要避免网络分区:
- 使用NIC组合实现冗余连接。 有关详细信息,请参阅http://www.cisco.com/en/US/docs/solutions/Enterprise/Data_Center/vmware/VMware.html#wp696452。
- 最好是所有服务器共享一个公共网络交换机。 具有多个网络交换机增加了发生网络分区的可能性。 如果必须使用多个交换机,则应尽可能使用冗余路由路径。 在多交换机配置中共享交换机的成员的权重将确定如果存在交换机间故障则哪个分区存活。
- 在Geode配置方面,考虑成员的权重。 例如,您可以为重要流程分配更高的权重。
安全
安全框架允许对集群的所有通信组件进行连接组件的身份验证和操作授权。
安全实施简介和概述
加密,SSL安全通信,身份验证和授权有助于保护集群。
安全细节考虑因素
本节在一个方便的位置收集离散的详细信息,以便更好地帮助您评估和配置环境的安全性。
使用属性定义启用安全性
认证
使用身份验证的集群禁止恶意对等方或客户端,并阻止对其缓存的无意访问。
授权
可以根据分配给客户端提交的凭据的角色和权限来限制或完全阻止缓存服务器上的客户端操作。
区域数据的后处理
SSL
SSL可保护应用程序之间传输的数据。
安全实施简介和概述
安全功能
加密,SSL安全通信,身份验证和授权功能有助于保护集群。
安全功能包括:
- 所有组件的单一安全界面. 单一身份验证和授权机制简化了安全性实施。 它以一致的方式查看所有组件并与之交互。
- 全系统基于角色的访问控制. 角色团授权各个组件要求的操作。
- SSL通信. 允许配置连接是基于SSL的,而不是普通的套接字连接。 您可以分别为对等,客户端,JMX,网关发件人和接收者以及HTTP连接启用SSL。
- 区域数据的后处理. 可以格式化返回区域值的操作的返回值。
概览
身份验证和授权机制构成了集群内部安全的核心。 通过为传输中的数据启用SSL,可以进一步保护通信。
身份验证可验证通信组件的身份,从而控制参与。 参与者的种类包括对等成员,服务器,客户端,JMX操作的发起者,Pulse,代表系统WAN成员的网关发送者和接收者,以及代表系统用户或管理员从gfsh到达的命令。
连接请求会触发身份验证回调的调用。 这个特殊用途的回调是作为应用程序的一部分编写的,它试图通过它选择的任何算法来验证请求者。 结果是返回的主体表示请求者的身份验证身份,或者是指示请求者未经过身份验证的异常。 委托人成为经营授权程序的任何操作请求的一部分。
鉴于身份验证,可以通过实现授权机制来进一步保护对缓存数据和系统状态的隔离和访问,该授权机制也作为应用程序的一部分实现为专用回调。 例如,保护可能只允许某些系统管理员启动和停止服务器。 执行此操作的权限需要限于特定的已验证帐户,以防止未经授权的帐户。 授权回调的实现将要求认证身份伴随对系统的所有请求,并且系统维护允许哪些身份完成哪些动作或高速缓存命令的表示。
安全细节考虑因素
本节在一个方便的位置收集离散的详细信息,以便更好地帮助您评估和配置环境的安全性。
外部接口,端口和服务
Geode进程使用UDP或TCP/IP端口与其他进程或客户端进行通信。
必须受到保护的资源
某些Geode配置文件应该只能由运行服务器的专用用户读取和写入。
日志文件位置
默认情况下,日志文件位于启动相应进程时使用的工作目录中。
放置安全配置设置的位置
外部接口,端口和服务
Geode进程使用UDP或TCP/IP端口与其他进程或客户端进行通信。
例如:
- 成员可以使用多播与对等成员进行通信。 您可以在
gemfire.properties文件中指定多播地址和多播端口,或者在使用gfsh启动成员时在命令行中指定参数。 - 客户端连接到定位器以发现缓存服务器。
- JMX客户端(例如
gfsh和JConsole)可以在预定义的RMI端口1099上连接到JMX Manager和其他可管理成员。如有必要,可以配置不同的端口。 - 每个网关接收器通常都有一个端口范围,用于监听传入的通信。
有关Geode使用的端口的完整列表,其默认值以及如何使用,请参阅防火墙和端口,如果您不想使用默认值,请配置它们。
Geode没有任何需要启用或打开的外部接口或服务。
必须受到保护的资源
这些配置文件应该只能由运行服务器的专用用户读取和写入:
gemfire.propertiescache.xmlgfsecurity.propertiesdefaultConfigs目录中没有提供默认的gfsecurity.properties。 如果选择使用此属性文件,则必须手动创建它。 明文用户名和关联的明文密码可以在此文件中以进行身份验证。 依赖文件系统的访问权限来保护这些敏感信息。
gemfire.properties和cache.xml配置文件的默认位置是主安装目录的defaultConfigs子目录。
日志文件位置
默认情况下,日志文件位于启动相应进程时使用的工作目录中。
对于Geode成员(定位器和缓存服务器),还可以在启动每个进程时指定自定义工作目录位置。 有关详细信息,请参阅Logging。
日志文件如下:
locator-name.log: 包含定位器进程的日志记录信息。server-name.log: 包含缓存服务器进程的日志记录信息。gfsh-%u_%g.log: 包含单个gfsh环境和会话的日志记录信息。注意: 默认情况下,禁用
gfsh会话日志记录。 要启用gfsh日志记录,必须设置Java系统属性-Dgfsh. log-level=desired_log_level。 有关详细信息,请参阅配置gfsh环境。
这些日志文件应该只由运行服务器的专用用户读写。
放置安全配置设置的位置
通常在gemfire.properties中配置的任何与安全相关的(以security- *开头的属性)配置属性都可以移动到单独的gfsecurity.properties文件中。 将这些配置设置放在单独的文件中允许您限制对安全配置数据的访问。 这样,您仍然可以允许对gemfire.properties文件进行读或写访问。
启动时,Geode进程将按顺序在以下位置查找gfsecurity.properties文件:
- 当前的工作目录
- 用户的主目录
- 类路径
如果文件中列出了任何与密码相关的安全属性但具有空值,则该过程将提示用户在启动时输入密码。
使用属性定义启用安全性
安全管理器属性
使用security-manager属性指定实现SecurityManager接口的认证回调和授权回调。 定义此属性后,将启用身份验证和授权。 security-manager属性的定义是实现SecurityManager接口的类的完全限定名。 例如:
security-manager = com.example.security.MySecurityManager
要确保在集群中一致地应用security-manager属性,请遵循以下准则:
- 在属性文件中指定
security-manager属性,例如gemfire.properties,而不是在集群配置文件(例如cluster.properties)中。 - 启动集群的第一个定位器时指定属性文件。 定位器会将值传播到后面的所有成员(定位器和服务器)。
- 如果必须为服务器指定
security-manager属性(既不必要也不建议),请确保其值与为第一个定位器指定的值完全相同。
系统的所有组件都会调用相同的回调。 以下是组件及其与系统建立的连接的描述。
- 客户端与服务器连接并发出该服务器的操作请求。 调用的回调是由该服务器的
SecurityManager接口定义的回调。 - 服务器与定位器连接,调用为该定位器定义的
authenticate回调。 - 与定位器的JMX管理器通信的组件连接并发出定位器的操作请求。 调用的回调是由该定位器的
SecurityManager接口定义的回调。gfsh和Pulse都使用这种形式的通信。 - 通过REST API进行通信的应用程序使服务器在连接和操作请求时调用安全回调。
- 请求网关发件人制作定位器会调用为该定位器定义的安全回调。
security-post-processor Property(安全后处理器属性)
PostProcessor接口允许定义一组回调,这些回调在获取数据的操作之后但在返回数据之前调用。 这允许回调干预并格式化要返回的数据。 回调不会修改区域数据,只会修改要返回的数据。
通过定义“security-post-processor”属性以及接口定义的路径,启用数据的后处理。 例如,
security-post-processor = com.example.security.MySecurityPostProcessing
认证
身份验证可验证集群中组件的身份,例如对等方,客户端以及连接到JMX管理器的组件。
实施身份验证
集群的所有组件都通过自定义编写的方法以相同的方式进行身份验证。
验证示例
该示例演示了
SecurityManager.authenticate方法的实现的基础知识。
实施身份验证
身份验证通过在组件连接到系统时验证组件的身份,为集群提供一定程度的安全性。 所有组件都使用相同的身份验证机制
身份验证如何工作
当组件启动与集群的连接时,将调用SecurityManager.authenticate方法。 该组件以属性的形式提供其凭证作为authenticate方法的参数。 证书被认为是两个属性security-username和security-password。 期望authenticate方法返回表示委托人的对象或抛出AuthenticationFailedException。
精心设计的authenticate方法将具有一组已知的用户和密码对,可以与所提供的凭证进行比较,或者有一种获得这些对的方法。
服务器如何设置其凭据
为了与进行身份验证的定位器连接,服务器需要设置其凭据,由两个属性security-username和security-password组成。 有两种方法可以实现此目的:
在服务器的
gfsecurity.properties文件中设置security-username和security-password,该文件将在服务器启动时读取,如示例中所示security-username=adminsecurity-password=xyz1234
用户名和密码以明文形式存储,因此必须通过限制具有文件系统权限的访问来保护
gfsecurity.properties文件。为服务器实现
AuthInitialize接口的getCredentials方法。 此回调的位置在属性security-peer-auth-init中定义,如示例中所示security-peer-auth-init=com.example.security.MyAuthInitialize
然后,
getCredentials的实现可以以任何方式获取属性security-username和security-password的值。 它可能会在数据库或其他外部资源中查找值。
网关发件人和接收者作为其服务器成员的组件进行通信。 因此,服务器的凭证成为网关发送者或接收者的凭证。
缓存客户端如何设置其凭据
为了与定位器或进行身份验证的服务器连接,客户端需要设置其凭证,由两个属性security-username和security-password组成。 要做到这一点:
为客户端实现
AuthInitialize接口的getCredentials方法。 此回调的位置在属性security-client-auth-init中定义,如示例中所示security-client-auth-init=com.example.security.ClientAuthInitialize
然后,
getCredentials的实现可以以任何方式获取属性security-username和security-password的值。 它可能会在数据库或其他外部资源中查找值,也可能会提示输入值。
其他组件如何设置其凭据
gfsh在调用gfsh connect命令时提示输入用户名和密码。
Pulse在启动时提示输入用户名和密码。
由于REST API的无状态特性,通过REST API与服务器或定位器通信的Web应用程序或其他组件将对每个请求进行身份验证。 请求的标头需要包含定义security-username和security-password值的属性。
实现SecurityManager接口
完成这些项目以实现定位器或服务器完成的身份验证。
- 确定身份验证算法。 验证示例存储一组用户名和密码对,表示将连接到的组件的标识。 系统。 如果传递给
authenticate方法的用户名和密码与其中一个存储对匹配,则这种简单算法将用户名作为主体返回。 - 定义
security-manager属性。 有关此属性的详细信息,请参阅使用属性定义启用安全性。 - 实现
SecurityManager接口的authenticate方法。 - 定义实现的身份验证算法所需的任何额外资源,以便做出决策。
验证示例
此示例演示了SecurityManager.authenticate方法的实现的基础知识。 该示例的其余部分可以在geode-core/src/main/java/org/apache/geode/examples/security目录中的Apache Geode源代码中找到。
当然,每个安装的安全实现都是唯一的,因此这个示例不能在生产环境中使用。 在成功进行身份验证后,将用户名用作返回的主体是一种特别糟糕的设计选择,因为发现实现的任何攻击者都可能欺骗系统。
此示例假定在初始化时已将一组表示可成功通过身份验证的用户的用户名和密码对读入数据结构中。 为用户名提供正确密码的任何组件都会成功进行身份验证,并且其身份将作为该用户进行验证。 因此,authenticate方法的实现检查credentials参数中提供的用户名是否在其数据结构中。 如果存在用户名,则将credentials参数中提供的密码与该用户名的数据结构的已知密码进行比较。 匹配时,身份验证成功。
public Object authenticate(final Properties credentials)throws AuthenticationFailedException {String user = credentials.getProperty(ResourceConstants.USER_NAME);String password = credentials.getProperty(ResourceConstants.PASSWORD);User userObj = this.userNameToUser.get(user);if (userObj == null) {throw new AuthenticationFailedException("SampleSecurityManager: wrong username/password");}if (user != null&& !userObj.password.equals(password)&& !"".equals(user)) {throw new AuthenticationFailedException("SampleSecurityManager: wrong username/password");}return user;}
授权
可以根据为各种集群组件设置的已配置访问权限来限制,拦截和修改集群和缓存操作,或者完全阻止集群和缓存操作。
实施授权
要对客户端/服务器系统使用授权,必须由其服务器对客户端连接进行身份验证。
授权示例
本主题讨论使用
XmlAuthorization.java,XmlErrorHandler.java和authz6_0.dtd在templates/security下的产品中提供的授权示例。
实施授权
授权如何运作
当组件请求操作时,将调用SecurityManager.authorize方法。 它传递了操作请求者的主体和ResourcePermission,它描述了所请求的操作。
SecurityManager.authorize方法的实现决定了是否授予委托人执行操作的权限。 它返回一个布尔值,其中返回值true允许操作,返回值false阻止操作。
精心设计的authorize方法将具有或将有一种方法来获取它们被允许做的操作(以资源许可的形式)的主体映射。
资源许可
所有操作都由ResourcePermission类的实例描述。 权限包含Resource数据成员,该成员将操作分类为是否正在进行操作
- cache data; value is
DATA - the cluster; value is
CLUSTER
权限还包含Operation数据成员,该成员将操作分类为
- reading; value is
READ - changing information; value is
WRITE - making administrative changes; value is
MANAGE
这些操作不是分层的; MANAGE并不意味着WRITE,而WRITE并不意味着READ。
一些DATA操作进一步指定了权限中的区域名称。 这允许将该区域的操作限制为仅限那些授权的主体。 在某个区域内,某些操作可能会指定密钥。 这允许将该区域内该密钥的操作限制为仅限那些授权的主体。
一些CLUSTER操作进一步为操作指定了更细粒度的目标。 使用字符串值指定目标:
DISK定位写入磁盘存储的操作GATEWAY定位管理网关发件人和接收者的操作QUERY定位管理索引和连续查询的操作DEPLOY定位将代码部署到服务器的操作LUCENE以Lucene索引操作为目标
此表对为客户端 - 服务器交互通用的操作分配的权限进行分类。
| 客户操作 | 分配ResourcePermission |
|---|---|
| get function attribute | CLUSTER:READ |
| create region | DATA:MANAGE |
| destroy region | DATA:MANAGE |
| Region.Keyset | DATA:READ:RegionName |
| Region.query | DATA:READ:RegionName |
| Region.getAll | DATA:READ:RegionName |
| Region.getAll with a list of keys | DATA:READ:RegionName:Key |
| Region.getEntry | DATA:READ:RegionName |
| Region.containsKeyOnServer(key) | DATA:READ:RegionName:Key |
| Region.get(key) | DATA:READ:RegionName:Key |
| Region.registerInterest(key) | DATA:READ:RegionName:Key |
| Region.registerInterest(regex) | DATA:READ:RegionName |
| Region.unregisterInterest(key) | DATA:READ:RegionName:Key |
| Region.unregisterInterest(regex) | DATA:READ:RegionName |
| execute function | Defaults to DATA:WRITE. Override Function.getRequiredPermissions to change the permission. |
| clear region | DATA:WRITE:RegionName |
| Region.putAll | DATA:WRITE:RegionName |
| Region.clear | DATA:WRITE:RegionName |
| Region.removeAll | DATA:WRITE:RegionName |
| Region.destroy(key) | DATA:WRITE:RegionName:Key |
| Region.invalidate(key) | DATA:WRITE:RegionName:Key |
| Region.destroy(key) | DATA:WRITE:RegionName:Key |
| Region.put(key) | DATA:WRITE:RegionName:Key |
| Region.replace | DATA:WRITE:RegionName:Key |
| queryService.newCq | DATA:READ:RegionName |
| CqQuery.stop | DATA:READ |
此表对为gfsh操作分配的权限进行分类。
gfsh 命令 |
Assigned ResourcePermission |
|---|---|
| alter disk-store | CLUSTER:MANAGE:DISK |
| alter region | DATA:MANAGE:RegionName |
| alter runtime | CLUSTER:MANAGE |
| backup disk-store | DATA:READ and CLUSTER:WRITE:DISK |
| change loglevel | CLUSTER:WRITE |
| clear defined indexes | CLUSTER:MANAGE:QUERY |
| close durable-client | CLUSTER:MANAGE:QUERY |
| close durable-cq | CLUSTER:MANAGE:QUERY |
| compact disk-store | CLUSTER:MANAGE:DISK |
| configure pdx | CLUSTER:MANAGE |
| create async-event-queue | CLUSTER:MANAGE:DEPLOY, plus CLUSTER:WRITE:DISK if the associated region is persistent |
| create defined indexes | CLUSTER:MANAGE:QUERY |
| create disk-store | CLUSTER:MANAGE:DISK |
| create gateway-receiver | CLUSTER:MANAGE:GATEWAY |
| create gateway-sender | CLUSTER:MANAGE:GATEWAY |
| create index | CLUSTER:MANAGE:QUERY |
| create jndi-binding | CLUSTER:MANAGE |
| create lucene index | CLUSTER:MANAGE:LUCENE |
| create region | DATA:MANAGE, plus CLUSTER:WRITE:DISK if the associated region is persistent |
| define index | CLUSTER:MANAGE:QUERY |
| deploy | CLUSTER:MANAGE:DEPLOY |
| describe client | CLUSTER:READ |
| describe config | CLUSTER:READ |
| describe disk-store | CLUSTER:READ |
| describe jndi-binding | CLUSTER:READ |
| describe lucene index | CLUSTER:READ:LUCENE |
| describe member | CLUSTER:READ |
| describe offline-disk-store | CLUSTER:READ |
| describe region | CLUSTER:READ |
| destroy disk-store | CLUSTER:MANAGE:DISK |
| destroy function | CLUSTER:MANAGE:DEPLOY |
| destroy index | CLUSTER:MANAGE:QUERY |
| destroy jndi-binding | CLUSTER:MANAGE |
| destroy lucene index | CLUSTER:MANAGE:LUCENE |
| destroy region | DATA:MANAGE |
| execute function | Defaults to DATA:WRITE. Override Function.getRequiredPermissions to change the permission. |
| export cluster-configuration | CLUSTER:READ |
| export config | CLUSTER:READ |
| export data | CLUSTER:READ |
| export logs | CLUSTER:READ |
| export offline-disk-store | CLUSTER:READ |
| export stack-traces | CLUSTER:READ |
| gc | CLUSTER:MANAGE |
| get ‑key=key1 ‑region=region1 | DATA:READ:RegionName:Key |
| import data | DATA:WRITE:RegionName |
| import cluster-configuration | CLUSTER:MANAGE |
| list async-event-queues | CLUSTER:READ |
| list clients | CLUSTER:READ |
| list deployed | CLUSTER:READ |
| list disk-stores | CLUSTER:READ |
| list durable-cqs | CLUSTER:READ |
| list functions | CLUSTER:READ |
| list gateways | CLUSTER:READ |
| list indexes | CLUSTER:READ:QUERY |
| list jndi-binding | CLUSTER:READ |
| list lucene indexes | CLUSTER:READ:LUCENE |
| list members | CLUSTER:READ |
| list regions | CLUSTER:READ |
| load-balance gateway-sender | CLUSTER:MANAGE:GATEWAY |
| locate entry | DATA:READ:RegionName:Key |
| netstat | CLUSTER:READ |
| pause gateway-sender | CLUSTER:MANAGE:GATEWAY |
| put –key=key1 –region=region1 | DATA:WRITE:RegionName:Key |
| query | DATA:READ:RegionName |
| rebalance | DATA:MANAGE |
| remove | DATA:WRITE:RegionName or DATA:WRITE:RegionName:Key |
| resume gateway-sender | CLUSTER:MANAGE:GATEWAY |
| revoke mising-disk-store | CLUSTER:MANAGE:DISK |
| search lucene | DATA:READ:RegionName |
| show dead-locks | CLUSTER:READ |
| show log | CLUSTER:READ |
| show metrics | CLUSTER:READ |
| show missing-disk-stores | CLUSTER:READ |
| show subscription-queue-size | CLUSTER:READ |
| shutdown | CLUSTER:MANAGE |
| start gateway-receiver | CLUSTER:MANAGE:GATEWAY |
| start gateway-sender | CLUSTER:MANAGE:GATEWAY |
| start server | CLUSTER:MANAGE |
| status cluster-config-service | CLUSTER:READ |
| status gateway-receiver | CLUSTER:READ |
| status gateway-sender | CLUSTER:READ |
| status locator | CLUSTER:READ |
| status server | CLUSTER:READ |
| stop gateway-receiver | CLUSTER:MANAGE:GATEWAY |
| stop gateway-receiver | CLUSTER:MANAGE:GATEWAY |
| stop locator | CLUSTER:MANAGE |
| stop server | CLUSTER:MANAGE |
| undeploy | CLUSTER:MANAGE:DEPLOY |
gfsh connect没有权限,因为它是调用身份验证的操作。 这些gfsh命令没有定义权限,因为它们不与集群交互:
gfsh describe connection, which describes thegfshend of the connectiongfsh debug, which toggles the mode withingfshgfsh exitgfsh helpgfsh hintgfsh historygfsh run, although individual commands within the script will go through authorizationgfsh set variablegfsh shgfsh sleepvalidate offline-disk-storegfsh version
此表对为JMX操作分配的权限进行分类。
| JMX 操作 | Assigned ResourcePermission |
|---|---|
| DistributedSystemMXBean.shutdownAllMembers | CLUSTER:MANAGE |
| ManagerMXBean.start | CLUSTER:MANAGE |
| ManagerMXBean.stop | CLUSTER:MANAGE |
| ManagerMXBean.createManager | CLUSTER:MANAGE |
| ManagerMXBean.shutDownMember | CLUSTER:MANAGE |
| Mbeans get attributes | CLUSTER:READ |
| MemberMXBean.showLog | CLUSTER:READ |
| DistributedSystemMXBean.changerAlertLevel | CLUSTER:WRITE |
| ManagerMXBean.setPulseURL | CLUSTER:WRITE |
| ManagerMXBean.setStatusMessage | CLUSTER:WRITE |
| CacheServerMXBean.closeAllContinuousQuery | CLUSTER:MANAGE:QUERY |
| CacheServerMXBean.closeContinuousQuery | CLUSTER:MANAGE:QUERY |
| CacheServerMXBean.executeContinuousQuery | DATA:READ |
| CqQuery.execute | DATA:READ:RegionName and CLUSTER:MANAGE:QUERY |
| CqQuery.executeWithInitialResults | DATA:READ:RegionName and CLUSTER:MANAGE:QUERY |
| DiskStoreMXBean.flush | CLUSTER:MANAGE:DISK |
| DiskStoreMXBean.forceCompaction | CLUSTER:MANAGE:DISK |
| DiskStoreMXBean.forceRoll | CLUSTER:MANAGE:DISK |
| DiskStoreMXBean.setDiskUsageCriticalPercentage | CLUSTER:MANAGE:DISK |
| DiskStoreMXBean.setDiskUsageWarningPercentage | CLUSTER:MANAGE:DISK |
| DistributedSystemMXBean.revokeMissingDiskStores | CLUSTER:MANAGE:DISK |
| DistributedSystemMXBean.setQueryCollectionsDepth | CLUSTER:MANAGE:QUERY |
| DistributedSystemMXBean.setQueryResultSetLimit | CLUSTER:MANAGE:QUERY |
| DistributedSystemMXBean.backupAllMembers | DATA:READ and CLUSTER:WRITE:DISK |
| DistributedSystemMXBean.queryData | DATA:READ |
| DistributedSystemMXBean.queryDataForCompressedResult | DATA:READ |
| GatewayReceiverMXBean.pause | CLUSTER:MANAGE:GATEWAY |
| GatewayReceiverMXBean.rebalance | CLUSTER:MANAGE:GATEWAY |
| GatewayReceiverMXBean.resume | CLUSTER:MANAGE:GATEWAY |
| GatewayReceiverMXBean.start | CLUSTER:MANAGE:GATEWAY |
| GatewayReceiverMXBean.stop | CLUSTER:MANAGE:GATEWAY |
| GatewaySenderMXBean.pause | CLUSTER:MANAGE:GATEWAY |
| GatewaySenderMXBean.rebalance | CLUSTER:MANAGE:GATEWAY |
| GatewaySenderMXBean.resume | CLUSTER:MANAGE:GATEWAY |
| GatewaySenderMXBean.start | CLUSTER:MANAGE:GATEWAY |
| GatewaySenderMXBean.stop | CLUSTER:MANAGE:GATEWAY |
| LockServiceMXBean.becomeLockGrantor | CLUSTER:MANAGE |
| MemberMXBean.compactAllDiskStores | CLUSTER:MANAGE:DISK |
实施授权
完成这些项目以实现授权。
- 确定授权算法。 授权示例存储允许哪些主体(用户)执行哪些操作的映射。 该算法的决定基于查找授予尝试操作的主体的权限。
- 定义
security-manager属性。 有关此属性的详细信息,请参阅使用属性定义启用安全性。 - 实现
SecurityManager接口的authorize方法。 - 定义实现的授权算法所需的任何额外资源,以便做出决策。
功能执行的授权
默认情况下,在服务器上执行的函数要求调用该函数的实体对所涉及的区域具有DATA:WRITE权限。 由于默认权限可能不适合所有功能,因此可能会更改所需的权限。
要实现不同的权限集,请覆盖函数类中的Function.getRequiredPermissions()方法。 该方法应该返回调用函数执行的实体所需权限的集合。
从查询调用的方法的授权
启用SecurityManager会通过限制正在运行的查询可能调用的方法来影响查询。 有关详细信息,请参阅方法调用。
授权示例
此示例演示了SecurityManager.authorize方法的实现的基础知识。 该示例的其余部分可以在geode-core/src/main/java/org/apache/geode/examples/security目录中的Apache Geode源代码中找到。
当然,每个安装的安全实现都是唯一的,因此该示例不能在生产环境中使用,因为角色和权限将无法满足任何真实分布式系统的需求。
此示例假定在JSON格式文件中描述了一组用户,用户可能在系统中执行的一组角色以及用户到其角色的映射。 角色定义为这些角色中的用户授予的一组授权资源权限。 此处未显示的代码解析文件以使用有关角色和用户的信息组成数据结构。 authorize回调拒绝任何没有表示操作请求者身份的主体的操作的权限。 给定主体,该方法遍历数据结构,搜索主体的必要权限。 找到必要的权限后,通过返回值true来授予授权。 如果在数据结构中未找到权限,则该方法返回false,拒绝授权操作。
public boolean authorize(final Object principal, final ResourcePermission context) {if (principal == null) return false;User user = this.userNameToUser.get(principal.toString());if (user == null) return false; // this user is not authorized to do anything// check if the user has this permission defined in the contextfor (Role role : this.userNameToUser.get(user.name).roles) {for (Permission permitted : role.permissions) {if (permitted.implies(context)) {return true;}}}return false;}
区域数据的后处理
PostProcessor接口允许定义在任何和所有客户端和gfsh操作之后但在返回数据之前调用的回调。 它允许回调干预并格式化要返回的数据。 回调不会修改区域数据,只会修改要返回的数据。
processRegionValue方法被赋予操作请求者的主体。 该操作已经完成,这意味着委托人将被授权完成所要求的操作。 因此,后处理可以基于请求者(主体)的身份格式化返回的数据。
为这些API调用调用processRegionValue方法:
Region.getRegion.getAllQuery.executeCqQuery.executeCqQuery.executeWithInitialResultsCqListener.onEvent- 来自
CacheListener.afterUpdate的相关区域事件,其中有兴趣注册了Region.registerInterest
在设计实现后处理回调的系统时应该小心。 它会导致每次get操作的额外方法调用的性能损失。
实施后期处理
完成这些项目以实现后期处理。
- 定义
security-post-processor属性。 有关此属性的详细信息,请参阅使用属性定义启用安全性。 - 实现
PostProcessor接口的processRegionValue方法。
SSL
SSL通过确保只有您标识的应用程序可以共享集群数据来保护应用程序之间传输的数据。
为了安全起见,必须在存储,分发和处理期间保护Geode系统中缓存的数据。 任何时候,集群中的数据可能位于以下一个或多个位置:
- 在内存里
- 在磁盘上
- 进程之间的传输(例如,在internet或intranet中)
为了保护内存或磁盘上的数据,Geode依赖于您的标准系统安全功能,例如防火墙,操作系统设置和JDK安全设置。
SSL实施可确保只有您标识的应用程序才能共享传输中的集群数据。 在此图中,集群可见部分中的数据由防火墙以及操作系统和JDK中的安全设置保护。 例如,磁盘文件中的数据受防火墙和文件权限的保护。 使用SSL进行数据分发可在防火墙内外的Geode系统成员之间提供安全通信。
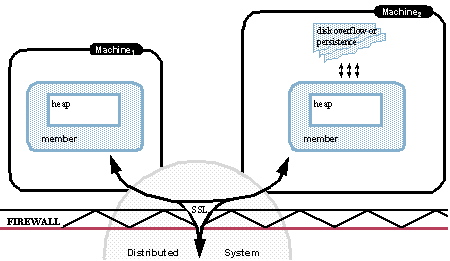
配置SSL
您可以为成员之间的相互身份验证配置SSL,并在分发期间保护数据。 您可以单独使用SSL,也可以与其他Geode安全选项一起使用。
SSL示例实施
一个简单的示例演示了使用SSL配置和启动Geode系统组件。
配置SSL
您可以配置SSL以在成员之间进行身份验证,并在分发期间保护您的数据。 您可以单独使用SSL,也可以与其他Geode安全选项一起使用。
Geode SSL连接使用Java安全套接字扩展(JSSE)包,因此此处描述的属性适用于Geode服务器和基于Java的客户端。 非Java客户端中的SSL配置可能不同 - 有关详细信息,请参阅客户端的文档。
SSL可配置组件
您可以指定在系统范围内使用SSL,也可以为特定系统组件单独配置SSL。 以下列表显示了可以单独配置为使用SSL进行通信的系统组件,以及每个组件名称所涉及的通信类型:
集群
集群成员之间的点对点通信
网关
WAN网关从一个站点到另一个站点的通信
web
所有基于Web的服务都托管在配置的服务器上,其中包括Developer REST API服务,Management REST API服务(用于远程集群管理)和Pulse监控工具的基于Web的用户界面。
jmx
Java管理扩展通信,包括与gfshutility的通信。 Pulse监视工具使用JMX与定位器进行服务器端通信,但仅当Pulse位于与定位器不同的应用程序服务器上时,SSL才适用于此连接。 当Pulse和定位器共同定位时,两者之间的JMX通信不涉及TCP连接,因此SSL不适用。
locator
与定位器之间的通信
server
客户端和服务器之间的通信
all
以上所有(使用SSL系统范围)
指定为SSL启用组件适用于组件的服务器套接字端及其客户端套接字端。 例如,如果为定位器启用SSL,则与定位器通信的任何进程也必须启用SSL。
SSL配置属性
您可以使用Geode配置属性来启用或禁用SSL,识别SSL密码和协议,以及提供密钥和信任存储的位置和凭据。
ssl-enabled-components
要启用SSL的组件列表。 组件列表可以是“全部”或以逗号分隔的组件列表。
ssl-endpoint-identification-enabled
一个布尔值,当设置为true时,会导致客户端使用服务器的证书验证服务器的主机名。 默认值为false。 在信任非自签名证书时,启用端点标识可防止DNS中间人攻击。
ssl-require-authentication
需要双向身份验证,适用于除Web以外的所有组件。 Boolean - 如果为true(默认值),则需要双向身份验证。
ssl-web-require-authentication
需要对Web组件进行双向身份验证。 Boolean - 如果为true,则需要双向身份验证。 默认值为false(仅限单向身份验证)。
ssl-default-alias
服务器使用一个密钥库来保存其SSL证书。 该服务器上的所有组件都可以共享由ssl-default-alias属性指定的单个证书。 如果未指定ssl-default-alias,则密钥存储区中的第一个证书将充当默认证书。
ssl-component-alias=string
您可以为任何组件配置单独的证书。 所有证书都驻留在同一个密钥库中,但可以使用此语法由包含组件名称的单独别名指定,其中component是组件的名称。 如果指定了特定于组件的别名,它将覆盖指定的component的ssl-default-alias。
例如,ssl-locator-alias将在系统密钥库中指定定位器组件的证书的名称。
ssl-ciphers
用于启用SSL的组件连接的有效SSL密码的逗号分隔列表。 any设置使用在配置的JSSE提供程序中默认启用的任何密码。
ssl-protocols
以逗号分隔的有效启用SSL的组件连接列表。 any设置使用配置的JSSE提供程序中默认启用的任何协议。
ssl-keystore, ssl-keystore-password
密钥库的路径和密钥库密码,指定为字符串
ssl-truststore, ssl-truststore-password
信任存储的路径和信任库密码,指定为字符串
ssl-keystore-type, ssl-truststore-type
密钥库和信任库的类型,指定为字符串。 两者的默认值为“JKS”,表示Java密钥库或信任库。
示例:始终保护通信
要在整个集群中实现安全的SSL通信,每个进程都应为所有组件启用SSL。
ssl-enabled-components=allssl-endpoint-identification-enabled=truessl-keystore=secure/keystore.datssl-keystore-password=changeitssl-truststore=secure/truststore.datssl-truststore-password=changeit
如果密钥库具有多个证书,您可能希望指定要为每个进程使用的别名。 例如,ssl-default-alias=Hiroki。
示例:非安全集群通信,安全客户端/服务器
在此示例中,SSL用于保护客户端和服务器之间的通信:
服务器属性
集群SSL未启用。
ssl-enabled-components=server,locatorssl-server-alias=serverssl-keystore=secure/keystore.datssl-keystore-password=changeitssl-truststore=secure/truststore.datssl-truststore-password=changeitssl-default-alias=Server-Cert
定位器属性
集群SSL未启用。
ssl-enabled-components=locatorssl-locator-alias=locatorssl-keystore=secure/keystore.datssl-keystore-password=changeitssl-truststore=secure/truststore.datssl-truststore-password=changeitssl-default-alias=Locator-Cert
客户端属性
在Java客户端上,已启用组件的列表反映了服务器的配置,因此客户端知道如何与(例如)服务器和定位器进行通信。 密钥库和信任库的路径是客户端的本地路径。
在此示例中,客户端的信任存储必须信任定位器和服务器证书。 由于客户端未指定证书别名,因此SSL将在其密钥库中使用默认证书。
ssl-enabled-components=server,locatorssl-endpoint-identification-enabled=truessl-keystore=secret/keystore.datssl-keystore-password=changeitssl-truststore=secret/truststore.datssl-truststore-password=changeit
SSL属性参考表
下表列出了可以配置为使用SSL的组件。
Table 1. SSL可配置组件
| 部件 | 通信类型 |
|---|---|
| cluster | 集群成员之间的点对点通信 |
| gateway | WAN网关从一个站点到另一个站点的通信 |
| web | 基于Web的通信,包括REST接口 |
| jmx | Java管理扩展通信,包括gfsh |
| locator | 与定位器之间的通信 |
| server | 客户端和服务器之间的通信 |
| all | 上述所有的 |
下表列出了可用于在Geode系统上配置SSL的属性。
Table 2. SSL配置属性
| 属性 | 描述 | 值 |
|---|---|---|
| ssl‑enabled‑components | 要启用SSL的组件列表 | “all”或以逗号分隔的组件列表:cluster,gateway,web,jmx,locator,server |
| ssl‑endpoint‑identification‑enabled | 使客户端使用服务器证书验证服务器主机名 | boolean - if true, does validation; defaults to false |
| ssl-require-authentication | 需要双向身份验证,适用于除Web以外的所有组件 | boolean - if true (the default), two-way authentication is required |
| ssl‑web‑require‑authentication | 需要对Web组件进行双向身份验证 | boolean - if true, two-way authentication is required. Default is false (one-way authentication only) |
| ssl-default-alias | 默认证书名称 | string - if empty, use first certificate in key store |
| ssl-component-alias | 组件特定的证书名称 | string - applies to specified component |
| ssl-ciphers | SSL密码列表 | comma-separated list (default “any”) |
| ssl-protocols | SSL协议列表 | comma-separated list (default “any”) |
| ssl-keystore | 密钥库的路径 | string |
| ssl-keystore-password | 密钥库密码 | string |
| ssl-truststore | 信任商店的路径 | string |
| ssl-truststore-password | 信任商店密码 | string |
程序
确保您的Java安装包含JSSE API并熟悉其使用。 有关信息,请参阅Oracle JSSE网站.
根据需要为每种连接类型配置SSL:
使用定位器在集群中进行成员发现以及用于客户端发现服务器。 请参阅配置点对点发现 和 配置客户端/服务器系统.
使用上述属性,根据需要为不同的组件类型配置SSL属性。 例如,要为客户端和服务器之间的通信启用SSL,您可以在
gemfire.properties文件中配置属性,类似于:ssl-enabled-components=serverssl-protocols=anyssl-ciphers=SSL_RSA_WITH_NULL_MD5, SSL_RSA_WITH_NULL_SHAssl-keystore=/path/to/trusted.keystoressl-keystore-password=passwordssl-truststore=/path/to/trusted.keystoressl-truststore-password=password
SSL示例实施
一个简单的示例演示了使用SSL配置和启动Geode系统组件。
特定于提供者的配置文件
此示例使用Javakeytool应用程序创建的密钥库为提供程序提供正确的凭据。 要创建密钥库,请运行keytool实用程序:
keytool -genkey \-alias self \-dname "CN=trusted" \-validity 3650 \-keypass password \-keystore ./trusted.keystore \-storepass password \-storetype JKS
这将创建一个稍后将使用的./ trusted.keystore文件。
gemfire.properties 文件
您可以在gemfire.properties文件中启用SSL。 在此示例中,为所有组件启用了SSL。
ssl-enabled-components=allmcast-port=0locators=<hostaddress>[<port>]
gfsecurity.properties 文件
您可以在gfsecurity.properties文件中指定特定于提供程序的设置,然后可以通过限制对此文件的访问来保护该文件。 以下示例配置JDK附带的默认JSSE提供程序设置。
ssl-keystore=/path/to/trusted.keystoressl-keystore-password=passwordssl-truststore=/path/to/trusted.keystoressl-truststore-password=passwordsecurity-username=xxxxsecurity-userPassword=yyyy
定位器启动
在启动其他系统成员之前,我们使用SSL和特定于提供程序的配置设置启动了定位器。 在正确配置gemfire.properties和gfsecurity.properties之后,启动定位器并提供属性文件的位置。 如果任何密码字段留空,系统将提示您输入密码。
gfsh>start locator --name=my_locator --port=12345 \--properties-file=/path/to/your/gemfire.properties \--security-properties-file=/path/to/your/gfsecurity.properties
其他成员启动
应用程序和缓存服务器可以与定位器启动类似地启动,并在当前工作目录中放置相应的gemfire.properties文件和gfsecurity.properties文件。 您还可以在命令行上将两个文件的位置作为系统属性传递。 例如:
gfsh>start server --name=my_server \--properties-file=/path/to/your/gemfire.properties \--security-properties-file=/path/to/your/gfsecurity.properties
连接到正在运行的集群
您可以使用gfsh通过指定use-ssl命令行选项并提供安全配置文件的路径来连接已启用的已启用SSL的集群:
gfsh>connect --locator=localhost[10334] --use-ssl \--security-properties-file=/path/to/your/gfsecurity.properties
连接后,您可以发出gfsh命令来执行各种操作,包括列出成员和显示区域特征。
性能调整和配置
一组工具和控件允许您监视和调整Apache Geode性能。
禁用TCP SYN Cookie
这是Linux系统必须做的事情。
提高vSphere的性能
本主题提供有关调整承载Apache Geode部署的vSphere虚拟化环境的指南。
性能控制
本主题提供了开发人员特别感兴趣的调优建议,主要是编程技术和缓存配置。
系统成员性能
您可以修改某些配置参数以提高系统成员的性能。
带有TCP/IP的慢速接收器
您可以使用多种方法来防止可能导致数据分发接收速度缓慢的情况。 慢接收器选项仅控制使用TCP/IP的对等通信。 此讨论不适用于客户端/服务器或多站点通信,也不适用于使用UDP单播或多播协议的通信。
慢分布式确认消息
在具有分布式ack区域的系统中,突然大量的分布式非ack操作可能导致分布式ack操作需要很长时间才能完成。
套接字通信
Geode进程使用TCP/IP和UDP单播和多播协议进行通信。 在所有情况下,通信都使用可以调整的套接字来优化性能。
UDP通信
您可以进行配置调整,以提高对等通信的多播和单播UDP性能。
组播通信
您可以进行配置调整,以提高Geode系统中对等通信的UDP组播性能。
维护缓存一致性
维护分布式Geode系统中缓存之间的数据一致性对于确保其功能完整性和防止数据丢失至关重要。
禁用TCP SYN Cookies
大多数默认Linux安装使用SYN cookie来保护系统免受泛滥TCP SYN数据包的恶意攻击(例如DDOS)。
此功能与稳定和繁忙的Geode集群不兼容。 SYN Cookie保护会被正常的Geode流量错误地激活,严重限制带宽和新的连接速率,并破坏SLA。 安全实现应该通过将Geode服务器集群置于高级防火墙保护之下来寻求防止DDOS类型的攻击。
要永久禁用SYN cookie:
编辑
/etc/sysctl.conf文件以包含以下行:net.ipv4.tcp_syncookies = 0
将此值设置为零将禁用SYN Cookie。
重新加载
sysctl.conf:sysctl -p
提高vSphere的性能
操作系统指南
使用最新支持的客户操作系统版本,并使用Java大型分页。
使用客户机操作系统的最新受支持版本. 该指南可能是最重要的。 将客户操作系统升级到Geode支持的最新版本。 例如,对于RHEL,至少使用7.0版或SLES使用至少11.0。 对于Windows,请使用Windows Server 2012.对于RedHat Linux用户,使用RHEL 7特别有用,因为RHEL 7版本中有特定的增强功能可以改进虚拟化延迟敏感工作负载。
在客户操作系统中使用Java大型分页. 在客户操作系统上配置Java以使用大页面。 启动Java时添加以下命令行选项:
-XX:+UseLargePages
NUMA, CPU, 和 BIOS 设置
本节为您的硬件和虚拟机提供VMware推荐的NUMA,CPU和BIOS设置。
- 始终启用超线程,不要过度使用CPU。
- 对于大多数生产Apache Geode服务器,始终使用具有至少两个vCPU的虚拟机。
- 通过调整虚拟机大小以适应NUMA节点来应用非统一内存访问(NUMA)位置。
- VMware建议使用以下BIOS设置:
- BIOS Power Management Mode: 最高性能。
- CPU Power and Performance Management Mode: 最高性能。
- Processor Settings:启用Turbo模式。
- Processor Settings:C状态禁用.
注意: 根据您的硬件品牌和型号,设置可能略有不同。 根据需要使用上面的设置或等效设置。
物理和虚拟NIC设置
这些指南可帮助您减少延迟。
物理 NIC: VMware建议您使用以下命令禁用ESXi主机的物理网卡上的中断合并:
ethtool -C vmnicX rx-usecs 0 rx-frames 1 rx-usecs-irq 0 rx-frames-irq 0
其中
vmnicX是ESXi命令报告的物理网卡:esxcli network nic list
您可以通过发出命令来验证您的设置是否已生效:
ethtool -C vmnicX
如果重新启动ESXi主机,则必须重新应用上述配置。
注意: 禁用中断合并可以减少虚拟机的延迟; 但是,它会影响性能并导致更高的CPU利用率。 它还会破坏大型接收卸载(LRO)的优势,因为某些物理网卡(例如Intel 10GbE NIC)会在禁用中断合并时自动禁用LRO。 有关详细信息,请参阅http://kb.vmware.com/kb/1027511。
Virtual NIC: 配置虚拟NIC时,请遵循以下准则:
- 将VMXNET3虚拟NIC用于对延迟敏感或其他性能关键型虚拟机。 有关为虚拟机选择适当类型的虚拟NIC的详细信息,请参阅http://kb.vmware.com/kb/1001805。
- VMXNET3支持自适应中断合并,可以帮助驱动具有多个具有并行工作负载(多线程)的vCPU的虚拟机的高吞吐量,同时最大限度地减少虚拟中断交付的延迟。 但是,如果您的工作负载对延迟非常敏感,VMware建议您禁用虚拟NIC的虚拟中断合并。 您可以通过API或编辑虚拟机的.vmx配置文件以编程方式执行此操作。 有关具体说明,请参阅vSphere API参考或VMware ESXi文档。
VMware vSphere vMotion和DRS集群使用情况
本主题讨论vSphere vMotion的使用限制,包括将其与DRS一起使用。
- 首次调试数据管理系统时,请将VMware vSphere Distributed Resource Scheduler™(DRS)置于手动模式,以防止可能影响响应时间的自动VMwarevSpherevMotion®操作。
- 减少或消除使用vMotion在Geode虚拟机负载过重时迁移它们。
- 不允许使用Apache Geode定位器进程进行vMotion迁移,因为此进程引入的延迟可能导致Apache Geode服务器的其他成员错误地怀疑其他成员已死亡。
- 使用专用的Apache Geode vSphere DRS集群。 当您考虑专门调整物理NIC和虚拟NIC以在集群中的ESXi主机的每个NIC上禁用中断合并时,这一点尤为重要。 这种类型的调优有利于Geode工作负载,但它可能会损害与内存吞吐量相关的其他非Apache Geode工作负载,而不像Apache Geode工作负载那样对延迟敏感。
- 如果无法使用专用vSphere DRS集群,并且Apache Geode必须在共享DRS集群中运行,请确保已设置DRS规则,以便不在Geode虚拟机上执行vMotion迁移。
- 如果必须使用vMotion进行迁移,VMware建议在低活动和计划维护时段期间,Apache Geode成员的所有vMotion迁移活动都将超过10GbE。
虚拟机的放置和组织
本节提供有关JVM实例和缓存数据冗余副本放置的指南。
- 每个虚拟机都有一个JVM实例。
- 增加堆空间以满足对更多数据的需求比在单个虚拟机上安装第二个JVM实例要好。 如果不能增加JVM堆大小,请考虑将第二个JVM放在单独的新创建的虚拟机上,从而提高更有效的水平可伸缩性。 随着您增加Apache Geode服务器的数量,还要增加虚拟机的数量,以便在Apache Geode服务器,JVM和虚拟机之间保持1:1:1的比例。
- 在一个JVM实例中运行一个Apache Geode服务器的至少四个vCPU虚拟机的大小。 这允许垃圾收集器有足够的CPU周期,其余用于用户事务。
- 由于Apache Geode可以在任何虚拟机上放置缓存数据的冗余副本,因此可能会在同一ESX/ESXi主机上无意中放置两个冗余数据副本。 如果主机发生故障,这不是最佳选择。 要创建更强大的配置,请使用VM1到VM2反关联性规则,以向vSphere指示VM1和VM2永远不能放在同一主机上,因为它们包含冗余数据副本。
虚拟机内存预留
本节提供了调整大小和设置内存的指南。
- 在虚拟机级别设置内存预留,以便ESXi在虚拟机启动时提供并锁定所需的物理内存。 分配后,ESXi不允许删除内存。
- 不要过度使用Geode主机的内存。
- 在为一个虚拟机上的一个JVM内的Geode服务器调整内存大小时,虚拟机的总预留内存不应超过一个NUMA节点中可用的内存以获得最佳性能。
vSphere的高可用性和Apache的Geode
在Apache Geode虚拟机上,禁用vSphere High Availability(HA)。
如果您使用的是专用的Apache Geode DRS集群,则可以在集群中禁用HA。 但是,如果您使用的是共享集群,请从vSphere HA中排除Geode虚拟机。
此外,为了支持高可用性,您还可以在Apache Geode虚拟机之间设置反关联性规则,以防止两个Apache Geode服务器在同一DRS集群内的同一ESXi主机上运行。
存储指南
本节提供持久性文件,二进制文件,日志等的存储准则。
- 将PVSCSI驱动程序用于I / O密集型Apache Geode工作负载。
- 在VMFS和客户机操作系统级别对齐磁盘分区。
- 将VMDK文件设置为eagerzeroedthick以避免Apache Geode成员的延迟清零。
- 对Apache Geode持久性文件,二进制文件和日志使用单独的VMDK。
- 将专用LUN映射到每个VMDK。
- 对于Linux虚拟机,使用NOOP调度作为I/O调度程序而不是完全公平队列(CFQ)。 从Linux内核2.6开始,CFQ是许多Linux发行版中的默认I/O调度程序。 有关详细信息,请参阅http://kb.vmware.com/kb/2011861。
其他资源
这些较旧的VMware出版物提供了有关vSphere优化的其他资源。
- “VMware vSphere 5.0的性能最佳实践” - http://www.vmware.com/pdf/Perf_Best_Practices_vSphere5.0.pdf
- “在vSphere虚拟机中对延迟敏感工作负载进行性能调优的最佳实践” - http://www.vmware.com/files/pdf/techpaper/VMW-Tuning-Latency-Sensitive-Workloads.pdf
- “VMware上的企业Java应用程序 - 最佳实践指南” - http://www.vmware.com/resources/techresources/1087
性能控制
本主题提供了开发人员特别感兴趣的调优建议,主要是编程技术和缓存配置。
在开始之前,您应该了解Apache Geode 基本配置和编程.
数据序列化
除标准Java序列化外,Geode还提供序列化选项,为数据存储,传输和语言类型提供更高的性能和更大的灵活性。
设置缓存超时
缓存超时属性可以通过gfsh
alter runtime命令修改(或在cache.xml文件中声明),也可以通过接口方法org.apache.geode.cache.Cache进行设置。控制套接字使用
对于对等通信,您可以在系统成员级别和线程级别管理套接字使用。
慢速接收器的管理
您有几个选项来处理接收数据分发的慢成员。 慢接收器选项仅控制使用TCP/IP的分布式区域之间的对等通信。 本主题不适用于客户端/服务器或多站点通信,也不适用于使用UDP单播或IP多播协议的通信。
增加缓存命中率
越频繁的获取没有找到第一缓存有效值和有尝试第二高速缓存越多,整体性能受到影响。
数据序列化
除标准Java序列化外,Geode还提供序列化选项,为数据存储,传输和语言类型提供更高的性能和更大的灵活性。
在使用Apache Geode开发中,请参阅数据序列化.
设置缓存超时
缓存超时属性可以通过gfshalter runtime命令修改(或在cache.xml文件中声明),也可以通过接口方法org.apache.geode.cache.Cache进行设置。
要修改缓存超时属性,可以发出以下gfsh alter runtime命令。 例如:
gfsh>alter runtime --search-timeout=150
--search-timeout参数指定netSearch操作在超时之前可以等待数据的时间。 默认值为5分钟。 您可能希望根据您对网络负载或其他因素的了解来更改此设置。
接下来的两个配置描述了在具有全局范围的区域中锁定的超时设置。 锁定操作可以在两个地方超时:等待获取锁定(锁定超时); 并持有一个锁(锁定租约时间)。 修改全局区域中对象的操作使用自动锁定。 此外,您可以通过org.apache.geode.cache.Region手动锁定全局区域及其条目。 API提供的显式锁定方法允许您指定锁定超时参数。 隐式操作的锁定超时和隐式和显式操作的锁定租用时间由这些缓存范围的设置控制:
gfsh>alter runtime --lock-timeout=30 --lock-lease=60
--lock-timeout. 对象锁定请求超时,以秒为单位指定。 该设置仅影响自动锁定,不适用于手动锁定。 默认值为1分钟。 如果锁定请求未在指定的超时期限之前返回,则会取消锁定请求并返回失败。--lock-lease. 对象锁定租约的超时,以秒为单位指定。 该设置会影响自动锁定和手动锁定。 默认值为2分钟。 一旦获得锁定,它就可以在锁定租用时间段内保持有效,然后由系统自动清除。
控制套接字使用
对于对等通信,您可以在系统成员级别和线程级别管理套接字使用。
conserve-socket设置指示应用程序线程是否与其他线程共享套接字或使用自己的套接字进行成员通信。 此设置对服务器与其客户端之间的通信没有影响,但它确实控制服务器与其对等方的通信或网关发送方与网关接收方的通信。 特别是在客户端/服务器设置中,每个服务器可能有大量客户端,控制对等套接字使用是调整服务器性能的重要部分。
您可以在gemfire.properties中为该成员配置conserve-socket。 此外,您可以通过API更改单个线程的套接字保护策略。
当conserve-sockets设置为false时,每个应用程序线程都使用专用线程发送到每个对等体,并使用专用线程从每个对等体接收。 禁用套接字保护需要更多系统资源,但可以通过消除线程之间的套接字争用和优化分布式ACK操作来潜在地提高性能。 对于分布式区域,put操作以及区域和条目的销毁和无效都可以通过将conserve-socket设置为false来优化。 对于分区区域,将conserve-socket设置为false可以提高一般吞吐量。
注意: 当您在EMPTY,NORMAL或PARTITION区域上运行事务时,请确保将conserve-sockets设置为false以避免分布式死锁。
您可以覆盖各个线程的conserve-socket设置。 这些方法位于org.apache.geode.distributed.DistributedSystem中:
setThreadsSocketPolicy. 设置调用线程的单个套接字策略,覆盖整个应用程序的策略集。 如果设置为true,则调用线程与其他线程共享套接字连接。 如果为false,则调用线程有自己的套接字。releaseThreadsSockets. 释放调用线程持有的任何套接字。 仅当conserve-socket为false时,线程才会拥有自己的套接字。 持有自己的套接字的线程可以调用此方法以避免在套接字租用时间到期之前保持套接字。
典型的实现可能会在应用程序级别将conserve-sockets设置为true,然后覆盖执行大量分布式操作的特定应用程序线程的设置。 下面的示例显示了执行基准测试的线程中两个API调用的实现。 该示例假定该类实现了Runnable。 请注意,只有在应用程序级别将conserve-sockets设置为true时,调用setThreadsSocketPolicy(false)才有意义。
public void run() {DistributedSystem.setThreadsSocketPolicy(false);try {// do your benchmark work} finally {DistributedSystem.releaseThreadsSockets();}}
慢速接收器的管理
您有几个选项来处理接收数据分发的慢成员。 慢接收器选项仅控制使用TCP / IP的分布式区域之间的对等通信。 本主题不适用于客户端/服务器或多站点通信,也不适用于使用UDP单播或IP多播协议的通信。
处理慢速成员的大多数选项都与系统集成和调优期间的现场配置有关。 有关此信息,请参阅使用TCP/IP的慢速接收器.
当应用程序运行多个线程,发送大消息(由于大的条目值)或混合区域配置时,更可能发生减速。
注意: 如果您遇到性能下降并且正在发送大型对象(多兆字节),则在实现这些慢速接收器选项之前,请确保您的套接字缓冲区大小足以容纳您分发的对象。 套接字缓冲区大小使用gemfire.socket-buffer-size设置。
默认情况下,系统成员之间的分配是同步执行的。 使用同步通信,当一个成员接收缓慢时,它也可能导致其生产者成员减速。 这可能导致集群中的一般性能问题。
处理缓慢接收的规范主要影响您的成员如何管理具有distributed-no-ack范围的区域的分发,但它也会影响其他分布式范围。 如果没有地区具有distributed-no-ack范围,则这种机制根本不可能发挥作用。 但是,当慢速收据处理启动时,它会影响生产者和消费者之间的所有分配,无论范围如何。 分区区域忽略范围属性,但出于本讨论的目的,您应该将它们视为具有隐式分布式确认范围。
配置选项
慢接收器选项在生成器成员的region属性,enable-async-conflation和consumer成员的async *gemfire.properties设置中设置。
投递重试
如果接收方未能收到消息,则只要接收成员仍在集群中,发送方就会继续尝试传递消息。 在重试周期中,抛出包含此字符串的警告:
will reattempt
当交付最终成功时,警告后面会显示一条信息消息。
慢速接收器的异步排队
可以配置您的使用者成员,以便在消费者对缓存消息分发响应缓慢时,他们的生产者切换到异步消息传递。
当生产者切换时,它会创建一个队列来保存和管理该消费者的缓存消息。 当队列清空时,生产者切换回消费者的同步消息。 导致生产者切换的设置在gemfire.properties文件设置中在使用者端指定。
如果将消费者配置为慢速收据排队,并且您的区域范围是distributed-no-ack,则还可以配置生产者以将其中的条目更新消息混合在其队列中。 此配置选项设置为区域属性enable-async-conflation。 默认情况下,不会混合使用distributed-no-ack条目更新消息。
根据应用程序的不同,混合可以大大减少生产者需要发送给消费者的消息数量。 通过合并,当向队列添加条目更新时,如果排队等待该密钥的最后一个操作也是更新操作,则删除先前排队的更新,仅将最新更新发送给使用者。 仅汇总源自具有distributed-no-ack范围的区域的条目更新消息。 除了更新之外的区域操作和输入操作不会混淆。

可能不会发生某种混淆,因为条目更新在被混合之前会发送给消费者。 对于此示例,假设在添加密钥A的更新时不发送任何消息。
注意: 这种混合方法与服务器到客户端的混合行为相同。
您可以逐个区域启用队列压缩。 您应始终启用它,除非它与您的应用程序需求不兼容。 通过配置可减少排队和分发的数据量。
这些是为什么混淆可能对您的应用程序不起作用的原因:
- 通过混合,较早的条目更新将从队列中删除,并替换为稍后在队列中发送的更新。 对于依赖于条目修改的特定顺序的应用程序而言,这是有问题的。 例如,如果您的接收器具有需要了解每个状态更改的CacheListener,则应禁用混合。
- 如果您的队列在相当长的一段时间内仍在使用,并且您有频繁更新的条目,则可能会有一系列更新消息替换,从而导致某些条目的任何更新到达时出现显着延迟。 想象一下,更新1在发送之前被删除,以支持稍后的更新2.然后,在发送更新2之前,将其删除以支持更新3,依此类推。 这可能导致接收器上的数据无法接受。
增加缓存命中率
越频繁的获取没有找到第一缓存有效值和有尝试第二高速缓存越多,整体性能受到影响。
未命中的常见原因是条目的到期或驱逐。 如果您启用了区域的条目到期或驱逐,请监视区域和条目统计信息。
如果您看到条目上的未命中率与命中率高,请考虑增加到期时间或驱逐的最大值(如果可能)。 有关更多信息,请参阅Eviction
系统成员性能
您可以修改某些配置参数以提高系统成员的性能。
在此之前,您应该了解基本配置和编程.
成员属性
多个与性能相关的属性适用于连接到集群的缓存服务器或应用程序。
JVM内存设置和系统性能
您可以通过向java调用添加参数来为Java应用程序配置JVM内存设置。 对于缓存服务器,将它们添加到gfsh
start server命令的命令行参数中。垃圾收集和系统性能
如果您的应用程序表现出不可接受的高延迟,则可以通过修改JVM的垃圾收集行为来提高性能。
连接线程设置和性能
当并发启动许多对等进程时,可以通过将p2p.HANDSHAKE_POOL_SIZE系统属性值设置为预期的成员数来改善集群连接时间。
成员属性
多个与性能相关的属性适用于连接到集群的缓存服务器或应用程序。
- statistic-sampling-enabled.关闭统计信息采样可以节省资源,但它也会为正在进行的系统调整和意外系统问题带走可能有价值的信息。 如果配置了LRU驱逐,则必须打开统计采样。
- statistic-sample-rate. 提高统计信息的采样率可以减少系统资源的使用,同时仍然提供一些系统调整和故障分析的统计信息
- log-level. 与统计采样率一样,降低此设置可降低系统资源消耗。 见日志.
JVM内存设置和系统性能
您可以通过向java调用添加参数来为Java应用程序配置JVM内存设置。 对于缓存服务器,将它们添加到gfshstart server命令的命令行参数中。
JVM堆大小 - 您的JVM可能需要比默认分配的内存更多的内存。 例如,您可能需要增加存储大量数据的应用程序的堆大小。 您可以设置最大大小和初始大小,因此如果您知道在成员的生命周期中将使用最大值(或接近它),则可以通过将初始大小设置为最大值来加快内存分配时间。 这会将Java应用程序的最大和初始内存大小设置为1024 MB:
-Xmx1024m -Xms1024m
可以在
gfsh命令行上将属性传递给缓存服务器:gfsh>start server --name=server-name --J=-Xmx1024m --J=-Xms1024m
MaxDirectMemorySize—JVM有一种称为直接内存的内存,它与普通的JVM堆内存不同,可以用完。 您可以通过增加最大堆大小(请参阅先前的JVM堆大小)来增加直接缓冲区内存,这会增加最大堆和最大直接内存,或者只使用-XX:MaxDirectMemorySize来增加最大直接内存。 添加到Java应用程序启动的以下参数将最大直接内存大小增加到256兆字节:
-XX:MaxDirectMemorySize=256M
缓存服务器的效果相同:
gfsh>start server --name=server-name --J=-XX:MaxDirectMemorySize=256M
JVM堆栈大小 - Java应用程序中的每个线程都有自己的堆栈。 堆栈用于保存返回地址,函数和方法调用的参数等。 由于Geode是一个高度多线程的系统,因此在任何给定的时间点都有多个线程池和线程正在使用中。 Java中线程的默认堆栈大小设置为1MB。 堆栈大小必须在连续的块中分配,如果主机正在使用并且系统中有许多线程运行(任务管理器显示活动线程数),您可能会遇到
OutOfMemory错误:无法创建新的本机 thread,即使你的进程有足够的可用堆。 如果发生这种情况,请考虑减少缓存服务器上线程的堆栈大小要求。 添加到Java应用程序启动的以下参数限制了堆栈的最大大小。-Xss384k
特别是,我们建议在这种情况下启动堆栈大小为384k或512k的缓存服务器。 例如:
gfsh>start server --name=server-name --J=-Xss384kgfsh>start server --name=server-name --J=-Xss512k
Off-heap memory size—对于使用堆外内存的应用程序,指定要分配的堆外内存量。 设置
off-heap-memory-size是启用各个区域的堆外功能的先决条件。 例如:gfsh>start server --name=server-name --off-heap-memory-size=200G
有关此参数的其他注意事项,请参阅使用堆外内存。
锁定内存 - 在Linux系统上,您可以通过将
lock-memory参数设置为true来防止堆和堆外存储器被分页。 例如:gfsh>start server --name=server-name --off-heap-memory-size=200G --lock-memory=true
有关此参数的其他注意事项,请参阅锁定内存。
垃圾收集和系统性能
如果您的应用程序表现出不可接受的高延迟,则可以通过修改JVM的垃圾收集行为来提高性能。
必要时,垃圾收集会通过消耗应用程序可用的资源,从而将延迟引入系统。 您可以通过两种方式减少垃圾收集的影响:
- 优化JVM堆中的垃圾收集。
- 通过在堆外内存中存储值来减少暴露于垃圾回收的数据量。
注意: 垃圾收集调整选项取决于您使用的JVM。 此处给出的建议适用于Sun HotSpot JVM。 如果您使用其他JVM,请与您的供应商联系,看看您是否可以使用这些或类似的选项。
注意: 对垃圾收集的修改有时会产生意外结果。 始终在进行更改之前和之后测试您的系统,以验证系统的性能是否已得到改进。
优化垃圾收集
这里建议的两个选项可能通过引入并行性并关注最有可能为清理做好准备的数据来加速垃圾收集活动。 第一个参数导致垃圾收集器与应用程序进程并发运行。 第二个参数使它为“年轻代”垃圾收集运行多个并行线程(即,在内存中的最新对象上执行垃圾收集 - 期望获得最大好处):
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC
对于应用程序,如果使用远程方法调用(RMI)Java API,则还可以通过禁用对垃圾回收器的显式调用来减少延迟。 RMI内部每60秒自动调用一次垃圾回收,以确保清理RMI活动引入的对象。 您的JVM可能能够处理这些额外的垃圾收集需求。 如果是这样,您的应用程序可能会在禁用显式垃圾收集的情 您可以尝试将以下命令行参数添加到应用程序调用中并进行测试,以查看您的垃圾收集器是否能够满足需求:
-XX:+DisableExplicitGC
使用堆外内存
您可以通过将数据值存储在堆外内存中来提高某些应用程序的性能。 某些对象(如键)必须保留在JVM堆中。 有关详细信息,请参阅管理堆外内存。
连接线程设置和性能
当并发启动许多对等进程时,可以通过将p2p.HANDSHAKE_POOL_SIZE系统属性值设置为预期的成员数来改善集群连接时间。
此属性控制可用于在对等高速缓存之间建立新TCP/IP连接的线程数。 如果线程空闲60秒,则丢弃线程。
p2p.HANDSHAKE_POOL_SIZE的默认值为10.此命令行规范将线程数设置为100:
-Dp2p.HANDSHAKE_POOL_SIZE=100
带有TCP/IP的慢速接收器
您可以使用多种方法来防止可能导致数据分发接收速度缓慢的情况。 慢接收器选项仅控制使用TCP/IP的对等通信。 此讨论不适用于客户端/服务器或多站点通信,也不适用于使用UDP单播或多播协议的通信。
在开始之前,您应该了解Geode 基本配置和编程.
防止慢速接收器
在系统集成期间,您可以识别并消除对等通信中慢接收器的潜在原因。
管理慢速接收器
如果接收方未能收到消息,则只要接收成员仍在集群中,发送方就会继续尝试传递消息。
防止慢速接收器
在系统集成期间,您可以识别并消除对等通信中慢接收器的潜在原因。
与网络管理员合作,消除您发现的任何问题。
当应用程序运行多个线程,发送大消息(由于大的条目值)或混合区域配置时,更可能发生减速。 问题也可能是由间歇性连接问题导致的消息传递重试引起的。
主机资源
确保运行Geode成员的计算机具有足够的CPU可用空间。 不要在同一台机器上运行任何其他重量级进程。
承载Geode应用程序和缓存服务器进程的计算机应具有可比较的计算能力和内存容量。 否则,功能较弱的机器上的成员往往难以跟上该组的其他人。
网络容量
通过重新平衡流量负载来消除网络上的拥塞区域。 与网络管理员合作,识别并消除流量瓶颈,无论是由分布式Geode系统的体系结构引起的,还是由Geode流量与网络上的其他流量之间的争用引起的。 考虑是否需要更多子网来将Geode管理流量与Geode数据传输分开,并将所有Geode流量与其余网络负载分开。
主机之间的网络连接需要具有相同的带宽。 如果没有,您最终可能会得到如下图中的多播示例之类的配置,这会在成员之间产生冲突。 例如,如果app1以7Mbps发送数据,app3和app4就可以了,但app2会遗漏一些数据。 在这种情况下,app2会联系TCP通道上的app1并发送一条日志消息,告知它正在丢弃数据。

增长计划
将基础架构升级到可接受性能所需的级别。 与网络容量相比,分析预期的Geode流量。 增加额外的增长容量和高流量峰值。 同样,评估托管Geode应用程序和缓存服务器进程的计算机是否可以处理预期的负载。
管理慢速接收器
如果接收方未能收到消息,则只要接收成员仍在集群中,发送方就会继续尝试传递消息。
在重试周期中,Geode会抛出包含此字符串的警告:
will reattempt
当交付最终成功时,警告后面会显示一条信息性消息。
对于分布式区域,区域的范围确定是否需要分发确认和分布式同步。 分区区域忽略范围属性,但出于本讨论的目的,您应该将它们视为具有隐式分布式确认范围。
默认情况下,系统成员之间的分配是同步执行的。 使用同步通信,当一个成员接收缓慢时,它也可能导致其生产者减速。 当然,这可能会导致集群中的一般性能问题。
如果您遇到性能下降并且正在发送大型对象(多兆字节),则在实现这些慢速接收器选项之前,请确保您的套接字缓冲区大小适合您分发的对象的大小。 套接字缓冲区大小是使用gemfire.properties文件中的socket-buffer-size设置的。
管理慢速分布式无ACK接收器
您可以配置您的消费者成员,以便他们的消息在响应缓慢时单独排队。 当生产者检测到缓慢的收据并允许生产者继续以正常速率向其他消费者发送时,排队发生在生产者成员中。 可以按照本节中的说明配置接收数据分发的任何成员。
处理慢速接收的规范主要影响成员如何管理具有distributed-no-ack作用域的区域的分布,其中分布是异步的,但规范也会影响其他分布式作用域。 如果没有地区具有distributed-no-ack范围,则该机制根本不可能启动。 但是,当慢速收据处理启动时,它会影响生产者和该消费者之间的所有分配,而不管范围如何。
注意: 在使用SSL的系统中禁用这些慢速接收器选项。 见SSL.
每个消费者成员确定其生产者如何处理其自身的缓慢行为。 这些设置被指定为分布式系统连接属性。 本节介绍设置并列出关联的属性。
- async-distribution-timeout—分发超时指定生成器在切换到与该使用者的异步消息传递之前等待使用者响应同步消息传递的时间。 当生产者切换到异步消息传递时,它会为该消费者的消息创建一个队列,并为处理通信创建一个单独的线程。 当队列清空时,生产者自动切换回与消费者的同步通信。 这些设置会影响生产者的缓存操作可能会阻塞的时间。 所有使用者的超时总和是生产者阻止缓存操作的最长时间。
- async-queue-timeout—队列超时设置了异步消息传递队列可以存在的时间长度的限制,而没有成功分发到慢速接收器。 当达到超时时,生产者要求消费者离开集群。
- async-max-queue-size—最大队列大小限制了异步消息传递队列可以使用的内存量。 当达到最大值时,生产者要求消费者离开集群。
配置异步队列配置
当作用域是distributed-no-ack作用域时,您可以将生产者配置为在其队列中混合条目更新消息,这可以进一步加快通信速度。 默认情况下,不会混合distributed-no-ack条目更新消息。 配置在区域级别的生产者中设置。
强制慢速接收器断开连接
如果达到队列超时或最大队列大小限制中的任何一个,则生产者向消费者发送高优先级消息(在与用于高速缓存消息传递的连接不同的TCP连接上),告知它与集群断开连接。 这可以防止在慢速接收器等待接收器赶上时对其进行排队更改的其他进程增加内存消耗。 它还允许慢速成员重新开始,可能会清除导致其缓慢运行的问题。
当生产者放弃慢速接收器时,它会记录以下类型的警告之一:
- 阻塞时间ms,该时间长于异步队列超时ms的最大值,因此要求慢速接收器slow_receiver_ID断开连接。
- 排队的字节超过asyncMaxQueueSize的最大值,因此要求慢速接收器slow_receiver_ID断开连接。
当一个进程在收到生产者的请求后断开连接时,它会记录一个这种类型的警告消息:
- 生产者强制断开因为我们太慢了。
如果启用了日志记录并且日志级别设置为包含警告的级别(默认情况下),则这些消息仅显示在日志中。 见日志.
如果您的消费者无法接收甚至高优先级的消息,则只有生产者的警告才会出现在日志中。 如果只看到生产者警告,则可以重新启动使用者进程。 否则,Geode故障检测代码最终将导致成员自己离开集群。
用例
这些是慢速接收器规范的主要用例:
- Message bursts—使用消息突发,套接字缓冲区可能会溢出并导致生成器阻塞。 要防止阻塞,首先要确保您的套接字缓冲区足够大以处理正常数量的消息(使用socket-buffer-size属性),然后将异步分发超时设置为1.使用此非常低的分发超时,当您的 套接字缓冲区确实填满,生产者快速切换到异步排队。 使用分发统计信息asyncQueueTimeoutExceeded和asyncQueueSizeExceeded来确保您的队列设置足够高,以避免在消息突发期间强制断开连接。
- Unhealthy or dead members—当成员死亡或非常不健康时,他们可能无法与其他成员沟通。 缓慢的接收器规范允许您强制残缺的成员断开连接,释放资源并可能允许成员重新启动。 要为此配置,请将分发超时设置为高(一分钟),并将队列超时设置为低。 这是避免排队暂时缓慢的最佳方法,同时仍然很快告诉非常不健康的成员离开集群。
- Combination message bursts and unhealthy members—要配置上述两种情况,请将分发超时设置为低,并将队列超时设置为高,与消息突发方案一样。
管理慢速分布式ack接收器
使用distributed-no-ack以外的分发范围时,会为慢速接收器发出警报。 未响应消息的成员可能生病,缓慢或缺失。 在消息传输和回复等待处理代码中检测到病态或慢速成员,首先触发警告警报。 如果成员仍未响应,则会发出严重警告警报,指示该成员可能与集群断开连接。 通过将ack-wait-threshold和ack-severe-alert-threshold设置为某个秒数来启用此警报序列。
设置ack-severe-alert-threshold时,区域配置为使用ether distributed-ack或全局作用域,或使用分区数据策略。 对于对缓存操作的响应,Geode将等待总共ack-wait-threshold秒,然后它会记录警告警报(“Membership: requesting removal of entry(#). Disconnected as a slow-receiver”)。 在达到第一个阈值后等待额外的ack-severe-alert-threshold秒后,系统还会通知故障检测机制接收器可疑并可能断开连接,如下图所示。
 事件按此顺序发生:
事件按此顺序发生:
- CACHE_OPERATION - 启动缓存操作的传输。
- SUSPECT - 通过ack-wait-threshold识别为嫌疑人,这是在启动故障检测之前等待确认的最长时间。
- I AM ALIVE - 如果进程仍然存在,则通知系统以响应故障检测查询。 如果可疑进程未能通过I AM ALIVE回答,则会向所有成员发送新的成员资格视图。
- SEVERE ALERT- ack-severe-wait-threshold结果没有收到回复。
当成员未通过可疑处理时,将关闭其缓存并使用afterRegionDestroyed通知通知其CacheListener。 通过此通知传递的RegionEvent具有CACHE_CLOSED操作和FORCED_DISCONNECT操作,如FORCED_DISCONNECT示例所示。
public static final Operation FORCED_DISCONNECT= new Operation("FORCED_DISCONNECT",true, // isLocaltrue, // isRegionOP_TYPE_DESTROY,OP_DETAILS_NONE);
缓存由于被其他成员从集群中驱逐而关闭。 通常,当成员变得无响应并且在成员超时期限内没有响应心跳请求,或者ack-severe-alert-threshold在没有成员响应的情况下过期时,就会发生这种情况。
注意: 这被标记为区域操作。
其他成员查看离职成员的正常成员资格通知。 例如,RegionMembershipListeners接收afterRemoteRegionCrashed通知,SystemMembershipListeners接收memberCrashed通知。
慢分布式确认消息
在具有分布式ack区域的系统中,突然大量的分布式非ack操作可能导致分布式ack操作需要很长时间才能完成。
distributed-no-ack操作可以来自任何地方。 它们可能是对distributed-no-ack区域的更新,或者它们可能是在缓存中的任何区域(包括distributed-ack区域)上执行的其他distributed-no-ack操作,如销毁。
大量的distributed-no-ack消息可能会延迟distributed-ack操作的主要原因是:
- 对于任何单个套接字连接,所有操作都是串行执行的。 如果在发送
distributed-ack时有任何其他操作被缓冲用于传输,则distributed-ack操作必须等待才能在传输之前到达行的前面。 当然,操作的调用过程也在等待。 distributed-no-ack消息在传输之前由其线程缓冲。 如果许多消息被缓冲然后立即发送到套接字,则传输线可能很长。
您可以采取以下步骤来减少此问题的影响:
- 如果您使用的是TCP,请检查是否为您的成员启用了套接字保护。 通过将Geode属性
conserve-sockets设置为true来配置它。 如果启用,除非您在线程级别覆盖设置,否则每个应用程序的线程将共享套接字。 与应用程序编程人员一起工作,看看是否可以完全禁用共享,或者至少是执行distributed-ack操作的线程。 这些包括对distributed-ack区域的操作以及对任何分布式范围的区域执行的netSearches。 (注意:netSearch仅在数据策略为空,正常和预加载的区域上执行。)如果给每个执行distributed-ack操作的线程自己的套接字,你实际上让它在前面 在其他线程正在执行的distributed-no-ack操作之前的行。 线程级别覆盖是通过调用DistributedSystem.setThreadsSocketPolicy(false)方法完成的。 - 减小缓冲区大小以减慢distributed-no-ack操作。 这些更改会减慢执行distributed-no-ack操作的线程,并允许以更及时的方式发送执行distributed-ack操作的线程。
- 如果您正在使用UDP(您在gemfire.properties中具有多播启用区域或已将
disable-tcp设置为true),请考虑将mcast-flow-control的byteAllowance减小到小于默认值3.5 MB的值。 - 如果您正在使用TCP / IP,请减少gemfire.properties中的
socket-buffer-size。
- 如果您正在使用UDP(您在gemfire.properties中具有多播启用区域或已将
套接字通信
Geode进程使用TCP / IP和UDP单播和多播协议进行通信。 在所有情况下,通信都使用可以调整的套接字来优化性能。
您为调整Geode通信所做的调整可能会遇到操作系统限制。 如果发生这种情况,请咨询系统管理员,了解如何调整操作系统设置。
这里讨论的所有设置都列为gemfire.properties和cache.xml设置。 它们也可以通过API配置,有些可以在命令行配置。 在开始之前,您应该了解Geode 基本配置和编程.
设置套接字缓冲区大小
确定缓冲区大小设置时,尝试在通信需求和其他处理之间取得平衡。
短暂的TCP端口限制
默认情况下,Windows的临时端口在1024-4999范围内,包括在内。您可以增加范围。
确保你有足够的Sockets
应用程序可用的套接字数量受操作系统限制的约束。
TCP/IP KeepAlive 配置
Geode支持TCP KeepAlive以防止套接字连接超时。
TCP/IP Peer-to-Peer 握手超时
您可以通过使用系统属性p2p.handshake Timeout Ms.增加连接握手超时间隔来缓解TCP / IP连接的连接握手超时。
设置套接字缓冲区大小
确定缓冲区大小设置时,必须在通信需求和其他处理之间取得平衡。
较大的套接字缓冲区允许您的成员更快地分发数据和事件,但它们也会使内存远离其他内容。 如果在缓存中存储非常大的数据对象,则为缓冲区找到正确的大小调整,同时为缓存的数据留下足够的内存,这对系统性能至关重要。
理想情况下,您应该有足够大的缓冲区来分发任何单个数据对象,这样就不会出现消息碎片,从而降低性能。 您的缓冲区应该至少与最大的存储对象及其密钥一样大,加上消息头的一些开销。 开销取决于发送和接收的人员,但100个字节就足够了。 您还可以查看进程之间通信的统计信息,以查看正在发送和接收的字节数。
如果您发现性能问题并记录指示阻塞编写器的消息,则增加缓冲区大小可能会有所帮助。
此表列出了各种成员关系和协议的设置,并说明了设置它们的位置。
| Protocol / Area Affected | 配置位置 | 属性名称 |
|---|---|---|
| TCP / IP | — | — |
| Peer-to-peer send/receive | gemfire.properties | socket-buffer-size |
| Client send/receive | cache.xml |
socket-buffer-size |
| Server send/receive | gfsh start server orcache.xml |
socket-buffer-size |
| UDP Multicast | — | — |
| Peer-to-peer send | gemfire.properties | mcast-send-buffer-size |
| Peer-to-peer receive | gemfire.properties | mcast-recv-buffer-size |
| UDP Unicast | — | — |
| Peer-to-peer send | gemfire.properties | udp-send-buffer-size |
| Peer-to-peer receive | gemfire.properties | udp-recv-buffer-size |
TCP/IP 缓冲区大小
如果可能,您的TCP / IP缓冲区大小设置应与Geode安装相匹配。 至少应遵循此处列出的准则。
Peer-to-peer.
gemfire.properties中的socket-buffer-size设置在整个集群中应该是相同的。Client/server. 客户端的池套接字缓冲区大小应该与池使用的服务器的设置相匹配,如这些示例中的
cache.xml片段:Client Socket Buffer Size cache.xml Configuration:<pool>name="PoolA" server-group="dataSetA" socket-buffer-size="42000"...Server Socket Buffer Size cache.xml Configuration:<cache-server port="40404" socket-buffer-size="42000"><group>dataSetA</group></cache-server>
UDP多播和单播缓冲区大小
通过UDP通信,一个接收器可以让许多发送器立即发送给它。 为了适应所有传输,接收缓冲区应该大于发送缓冲区的总和。 如果您的系统最多有五个成员在任何时间运行,其中所有成员都更新其数据区域,则应将接收缓冲区设置为发送缓冲区大小的至少五倍。 如果您的系统具有生产者和使用者成员,其中只有两个生产者成员一次运行,则接收缓冲区大小应设置为发送缓冲区大小的两倍以上,如下例所示:
mcast-send-buffer-size=42000mcast-recv-buffer-size=90000udp-send-buffer-size=42000udp-recv-buffer-size=90000
操作系统限制
您的操作系统对其允许的缓冲区大小设置限制。 如果您请求的大小超过允许的大小,则可能会在启动期间收到有关该设置的警告或例外情况。 这些是您可能会看到的消息类型的两个示例:
[warning 2008/06/24 16:32:20.286 PDT CacheRunner <main> tid=0x1]requested multicast send buffer size of 9999999 but got 262144: seesystem administration guide for how to adjust your OSException in thread "main" java.lang.IllegalArgumentException: Could notset "socket-buffer-size" to "99262144" because its value can not begreater than "20000000".
如果您认为要为缓冲区大小请求的空间大于系统允许的空间,请与系统管理员联系以了解有关调整操作系统限制的信息。
短暂的TCP端口限制
默认情况下,Windows的临时端口在1024-4999范围内。 你可以增加范围。
如果您反复收到以下异常:
java.net.BindException: Address already in use: connect
如果您的系统正在经历高度的网络活动,例如众多短期客户端连接,这可能与短暂TCP端口数量的限制有关。 虽然其他操作系统可能会出现此问题,但通常情况下,由于默认限制较低,因此只能在Windows中看到此问题。
执行此过程以增加限制:
打开Windows注册表编辑器。
导航到以下键:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameter
从“编辑”菜单中,单击“新建”,然后添加以下注册表项:
Value Name: MaxUserPortValue Type: DWORDValue data: 36863
退出注册表编辑器,然后重新启动计算机。
这会影响Windows操作系统的所有版本。
关于Unix系统上的UDP的注意事项
Unix系统有一个默认的最大套接字缓冲区大小,用于接收UDP多播和单播传输,这些传输低于mcast-recv-buffer-size和udp-recv-buffer-size的默认设置。 要实现大容量多播消息传递,您应该将最大Unix缓冲区大小增加到至少一兆字节。
确保你有足够的Sockets
应用程序可用的套接字数量受操作系统限制的约束。
套接字使用文件描述符,操作系统的应用程序套接字使用视图以文件描述符表示。 有两个限制,一个是关于单个应用程序可用的最大描述符,另一个是关于系统中可用的描述符总数。 如果您收到错误消息,告诉您打开了太多文件,则可能会因使用套接字而达到操作系统限制。 您的系统管理员可能能够增加系统限制,以便您可以获得更多可用信息。 您还可以调整成员,以便为其传出连接使用更少的套接字。 本节讨论Geode中的套接字使用以及限制Geode成员中套接字消耗的方法。
套接字共享
您可以为peer-to-peer 和 client-to-server连接配置套接字共享:
Peer-to-peer. 您可以配置您的成员是在应用程序级别还是在线程级别共享套接字。 要在应用程序级别启用共享,请将
gemfire.properties属性conserve-sockets设置为true。 但是,为了实现最大吞吐量,我们建议您将conserve-sockets设置为false。在线程级别,开发人员可以使用DistributedSystem API方法
setThreadsSocketPolicy覆盖此设置。 您可能希望在应用程序级别启用套接字共享,然后让执行大量缓存工作的线程单独拥有其套接字。 确保使用releaseThreadsSockets方法编程这些线程以尽快释放其套接字,而不是等待超时或线程死亡。Client. 您可以配置客户端是否与池设置为
thread-local-connections的服务器共享其套接字连接。 此设置没有线程覆盖。 所有线程都有自己的套接字或者它们都共享。
套接字租约时间
您可以强制释放空闲套接字连接以进行对等和客户端到服务器连接:
- Peer-to-peer. 对于不共享套接字的对等线程,可以使用
socket-lease-time来确保没有套接字空闲太长时间。 当属于单个线程的套接字在此时间段内保持未使用状态时,系统会自动将其返回到池中。 下一次线程需要套接字时,它会创建一个新套接字。 - Client. 对于客户端连接,可以通过设置池
idle-timeout来影响相同的租用时间行为。
计算连接要求
每种类型的成员都有自己的连接要求。 客户端需要连接到他们的服务器,对等端需要连接到对等端,等等。 许多成员都有复合角色。 使用这些指南来计算每个成员的套接字需求,并计算在单个主机系统上运行的成员的组合需求。
成员的套接字使用受许多因素控制,包括:
- 它连接了多少个对等成员
- 它有多少个线程来更新缓存以及线程是否共享套接字
- 无论是服务器还是客户端,
- 其他进程有多少连接
这里描述的套接字要求是最坏的情况。 通常,为您的应用程序计算确切的套接字使用是不切实际的。 套接字的使用取决于许多因素,包括运行的成员数量,线程正在做什么以及线程是否共享套接字。
要计算任何成员的套接字要求,请为适用于该成员的每个类别添加要求。 例如,在与客户端连接的集群中运行的缓存服务器具有对等和服务器套接字要求。
每位成员的Peer-to-Peer 套接字要求
集群的每个成员都维护到每个对等方的两个传出连接和两个传入连接。 如果线程共享套接字,则这些固定套接字是它们共享的套接字。
对于不共享套接字的每个线程,为每个对等体添加额外的套接字,一个输入和一个输出。 这不仅会影响成员的套接字计数,还会影响成员线程连接到的每个成员的套接字计数。
在此表中:
- M是集群中的成员总数。
- T是拥有自己的套接字且不共享的成员中的线程数。
| 对等成员套接字描述 | 使用的数量 |
|---|---|
| 成员故障检测 | 2 |
| 传入对等连接的侦听器(服务器P2P) | 1 |
| 共享套接字(2输入和2输出)共享套接字的线程使用这些。 | 4 * (M-1) |
| 此成员的线程拥有的套接字(每个线程为每个对等成员1个和1个)。 | (T 2) (M-1) |
| 连接到此成员的其他成员的线程拥有的套接字(每个成员1个和1个)。 请注意,如果任何其他成员是服务器,则可能包括服务器线程(请参阅服务器)。 | Summation over (M-1) other members of (T*2) |
注意: 服务客户端请求的线程会为连接到其对等方的成员以及连接到此成员的对等方添加线程拥有的套接字的总数。
每服务器的服务器套接字要求
服务器为每个传入客户端连接使用一个连接。 默认情况下,每个连接都由服务器线程提供服务。 这些服务客户端请求的线程与其余服务器通信以满足请求和分布式更新操作。 这些线程中的每一个都使用自己的线程拥有的套接字进行对等通信。 所以这会增加服务器的线程拥有的套接字组。
服务器中的线程和连接计数可能受服务器配置设置的限制。 这些是cache.xml的max-connections和max-threads设置。 这些设置限制服务器接受的连接数以及可以为客户端请求提供服务的最大线程数。 这两个都限制了服务器的整体连接要求:
- 达到连接限制时,服务器拒绝其他连接。 这限制了服务器用于客户端的连接数。
- 达到线程限制时,线程开始为多个连接提供服务。 这不会限制客户端连接的数量,但会限制为客户端请求提供服务所需的对等连接数。 用于客户端的每个服务器线程都使用自己的套接字,因此它需要2个连接到每个服务器的对等端。
max-threads设置会限制服务器所需的此类对等连接的数量。
服务器为每个传入的客户端池连接使用一个套接字。 如果使用客户端订阅,则服务器会为每个启用订阅的客户端创建其他连接。
在此表中,M是集群中的成员总数。
| 服务器套接字描述 | 使用的数量 |
|---|---|
| 侦听传入的客户端连接 | 1 |
| 客户端池与服务器的连接 | 此服务器的池连接数 |
为客户端请求提供服务的线程(客户端池连接数和服务器的max-threads设置中的较小者)。 这些连接是服务器的对等方。 |
(2 服务客户端池连接的服务器中的线程数)(M-1)这些线程不共享套接字。 |
| 订阅连接 | 2 *此服务器的客户端订阅连接数 |
在客户端/服务器安装中,与任何单个服务器的客户端连接数量未确定,但Geode的服务器负载平衡和调节使连接在服务器之间保持相当均匀的分布。
服务器是它们自己的集群中的对等体,并具有额外的套接字要求,如上面的点对点部分所述。
每个客户的客户端套接字要求
客户端连接要求因其使用的池数而变得复杂。 使用情况因运行时客户端连接需求而异,但通常具有最大和最小设置。 在cache.xml中查找配置属性的
| 客户端套接字描述 | 使用的数量 |
|---|---|
| 池连接 | 对max-connections的客户端池进行求和 |
| 订阅连接 | 对已启用订阅的客户端池进行2 *总结 |
如果您的客户端充当其自己的集群中的对等方,则它具有附加的套接字要求,如本主题的“对等”部分所述。
TCP/IP KeepAlive配置
Geode支持TCP KeepAlive以防止套接字连接超时。
gemfire.enableTcpKeepAlive系统属性可防止出现空闲的连接超时(例如,通过防火墙)。当配置为true时,Geode为各个套接字启用SO_KEEPALIVE选项。 此操作系统级设置允许套接字向远程系统发送验证检查(ACK请求),以确定是否保持套接字连接处于活动状态。
注意: 在操作系统级别配置发送第一个ACK KeepAlive请求的时间间隔,后续ACK请求以及关闭套接字之前发送的请求数。
默认情况下,此系统属性设置为true。
TCP/IP Peer-to-Peer握手超时
您可以通过使用系统属性p2p.handshake Timeout Ms增加连接握手超时间隔来缓解TCP/IP连接的连接握手超时。
默认设置为59000毫秒。
这会将Java应用程序的握手超时设置为75000毫秒:
-Dp2p.handshakeTimeoutMs=75000
这些属性在gfsh命令行上传递给缓存服务器:
gfsh>start server --name=server_name --J=-Dp2p.handshakeTimeoutMs=75000
在多站点(WAN)部署中配置套接字
确定缓冲区大小设置时,尝试在通信需求和其他处理之间取得平衡。
此表列出了网关关系和协议的设置,并说明了设置它们的位置。
| 受影响的协议/区域 | 配置位置 | 属性名称 |
|---|---|---|
| TCP / IP | — | — |
| Gateway sender | gfsh create gateway-senderorcache.xml |
socket-buffer-size |
| Gateway receiver | gfsh create gateway-receiveror cache.xml |
socket-buffer-size |
TCP/IP缓冲区大小
如果可能,您的TCP/IP缓冲区大小设置应与您的安装相匹配。 至少应遵循此处列出的准则。
Multisite (WAN). 在使用网关的多站点安装中,如果未针对最佳吞吐量调整站点之间的链接,则可能导致消息在缓存队列中备份。 如果接收队列由于缓冲区大小不足而溢出,则它将与发送方不同步,接收方将不知道该情况。
网关发送方的socket-buffer-size属性应与发送方连接的所有网关接收方的网关接收方的socket-buffer-size属性相匹配,如下所示
cache.xml片段:Gateway Sender Socket Buffer Size cache.xml Configuration:<gateway-sender id="sender2" parallel="true"remote-distributed-system-id="2"socket-buffer-size="42000"maximum-queue-memory="150"/>Gateway Receiver Socket Buffer Size cache.xml Configuration:<gateway-receiver start-port="1530" end-port="1551"socket-buffer-size="42000"/>
注意: WAN部署增加了Geode系统的消息传递需求。 为避免与WAN消息传递相关的挂起,请始终为参与WAN部署的GemFire成员设置conserve-sockets=false。
Multi-site (WAN) 套接字要求
每个网关发送方和网关接收方使用套接字来分发事件或侦听来自远程站点的传入连接。
| Multi-site 套接字说明 | 使用的数量 |
|---|---|
| 侦听传入连接 | 为成员定义的网关接收器数量的总和 |
| 传入连接 | 配置为连接到网关接收器的远程网关发送器总数的总和 |
| 传出连接 | 为成员定义的网关发件人数量的总和 |
服务器是它们自己的集群中的对等体,并具有额外的套接字要求,如上面的点对点部分所述。
成员生成SocketTimeoutException
当客户端,服务器,网关发送器或网关接收器停止等待来自连接另一端的响应并关闭套接字时,会产生SocketTimeoutException。 此异常通常发生在握手或建立回调连接时。
响应:
增加成员的默认套接字超时设置。 对于客户端池以及网关发送方和网关接收方,可以在cache.xml文件中或通过API单独设置此超时。 对于客户端/服务器配置,请按[]http://geode.apache.org/docs/guide/17/reference/topics/client-cache.html#cc-pool )中所述调整“读取超时”值(或使用org.apache.geode.cache.client.PoolFactory.setReadTimeout方法。 有关网关发送方或网关接收方,请参阅WAN配置。
UDP 通信
您可以进行配置调整,以提高对等通信的多播和单播UDP性能。
您可以调整Geode UDP消息传递以最大化吞吐量。 有两个主要的调整目标:使用最大的合理数据报数据包大小并降低重传率。 这些操作可以减少网络上的消息传递开销和总体流量,同时仍然可以将数据放在需要的位置。 Geode还提供统计信息,以帮助您决定何时更改UDP消息传递设置。
在开始之前,您应该了解Geode 基本配置和编程。 另请参阅套接字通信和多播通信中涵盖的一般通信调优和多播特定调整。
UDP数据报大小
您可以使用Geode属性udp-fragment-size更改UDP数据报大小。 这是通过UDP单播或多播套接字传输的最大数据包大小。 如果可能,将较小的消息组合成最多为此设置大小的批次。
大多数操作系统为UDP数据报设置的最大传输大小为64k,因此该设置应保持在60k以下以允许通信头。 如果您的网络容易丢包,则将片段大小设置得过高会导致额外的网络流量,因为每次重新传输都必须重新发送更多数据。 如果在DistributionStats中出现许多UDP重新传输,您可以通过降低片段大小来获得更好的吞吐量。
UDP流量控制
UDP协议通常具有内置的流控制协议,以防止进程的no-ack消息超出进程。 Geode UDP流量控制协议是一种基于信用的系统,其中发送方具有在其接收方补充或重新充值其字节信用计数之前可以发送的最大字节数。 虽然其字节信用太低,但发件人等待。 接收器尽最大努力预测发送者的充电要求,并在需要之前提供充电。 如果发送方的信用额度过低,则明确要求其接收方进行充值。
此流控制协议用于所有多播和单播no-ack消息传递,使用三部分Geode属性mcast-flow-control进行配置。 此属性包括:
byteAllowance—确定在从接收进程接收补给之前可以发送多少字节(也称为信用)。rechargeThreshold—设置发送方剩余信用与其byteAllowance之比的下限。 当比率低于此限制时,接收器自动发送充电。 这减少了来自发件人的充值请求消息,并有助于防止发送者在等待充值时阻塞。rechargeBlockMs—告诉发件人在明确请求之前需要等待多长时间。
在一个调整良好的系统中,缓存事件的消费者与生产者保持同步,可以将byteAllowance设置为高,以限制控制流消息和暂停。 JVM膨胀或频繁的消息重传表明生产者的缓存事件超出了消费者。
UDP重传统计
Geode存储其发送者和接收者的重传统计数据。 您可以使用这些统计信息来帮助确定流控制和片段大小设置是否适合您的系统。
重传率存储在分布式状态ucastRetransmits和mcastRetransmits中。 对于多播,还有一个接收方统计信息mcastRetransmitRequests,可用于查看哪些进程没有跟上并请求重新传输。 没有类似的方法可以判断哪些接收器在接收单播UDP消息时遇到问题。
组播通信
您可以进行配置调整,以提高Geode系统中对等通信的UDP组播性能。
在开始之前,您应该了解Geode 基本配置和编程。 另请参阅套接字通信和[UDP通信](http://geode.apache.org/docs/guide/17/managing/monitor_tune/udp_communication.html#udp_comm)中介绍的一般通信调优和UDP调整。
为多播提供带宽
多播安装比TCP安装需要更多的规划和配置。 使用IP多播,您可以获得可扩展性,但却失去了TCP的管理便利性。
测试多播速度限制
TCP会自动将其速度调整为使用它的进程的能力,并强制执行带宽共享,以便每个进程都能获得转换。 使用多播,您必须确定并明确设置这些限制。
配置多播速度限制
确定最大传输速率后,配置并调整生产系统。
多播的运行时注意事项
使用多播进行消息传递和数据分发时,需要了解运行状况监视设置的工作原理以及如何控制内存使用。
排除多播调整过程
在多播的初始测试和调整过程中可能会出现几个问题。
为多播提供带宽
多播安装比TCP安装需要更多的规划和配置。 使用IP多播,您可以获得可扩展性,但却失去了TCP的管理便利性。
当您安装通过TCP运行的应用程序时,几乎总是为TCP设置网络,而其他应用程序已经在使用它。 当您安装要通过IP多播运行的应用程序时,它可能是网络上的第一个多播应用程序。
多播非常依赖于它运行的环境。 它的操作受到网络硬件,网络软件,Geode进程在哪些机器上运行的机器以及是否存在任何竞争应用程序的影响。 您可能会发现您的站点在TCP中具有连接但在多播中没有,因为某些交换机和网卡不支持多播。 您的网络可能存在潜在的问题,否则您将永远看不到。 要使用多播成功实现分布式Geode系统,需要系统和网络管理员的配合。
多播的有界操作
Geode系统需要组速率控制来维持缓存一致性。 如果您的应用程序向一组成员提供相同的数据,那么您的系统调优工作需要关注慢速接收器。
如果您的某些成员无法跟上传入的数据,则该组中的其他成员可能会受到影响。 充其量,慢速接收器会导致生产者使用缓冲,为慢速接收器增加延迟,并可能为所有这些接收器增加延迟。 在最坏的情况下,组的吞吐量可以完全停止,而生产者的CPU,内存和网络带宽专用于为慢速接收器提供服务。
要解决此问题,您可以实现有界操作策略,该策略为生产者的操作设置边界。 通过调整和测试确定适当的速率限制,以便尽可能快地进行操作,同时最大限度地减少消费者群体中的数据丢失和延迟。 此政策适用于需要高吞吐量,可靠交付和网络稳定性的金融市场数据等应用。 边界设置正确后,生产者的流量不会导致网络中断。
多播协议通常具有内置于其中的流控制协议,以防止进程被溢出。 Geode流控制协议使用mcast-flow-control属性为多播流操作设置生产者和消费者边界。 该属性提供以下三种配置设置:
byteAllowance |
无需充电即可发送的字节数 |
|---|---|
rechargeThreshold |
告诉消费者,在发送充值之前,生产者的初始剩余免税额应该是多少。 |
rechargeBlockMs |
告诉生产者在请求之前等待充电需要多长时间。 |
测试多播速度限制
TCP会自动将其速度调整为使用它的进程的能力,并强制执行带宽共享,以便每个进程都能获得转换。 使用多播,您必须确定并明确设置这些限制。
如果没有正确的配置,多播会尽可能快地提供流量,超出消费者处理数据和锁定等待带宽的其他进程的能力。 您可以使用gemfire.properties中的mcast-flow-control来调整多播和单播行为。j
使用Iperf
Iperf是一种开源TCP/UDP性能工具,可用于查找站点通过多播进行数据分发的最大速率。 Iperf可以从诸如国家应用网络研究实验室(NLANR)的网站下载。
Iperf测量最大带宽,允许您调整参数和UDP特性。 Iperf报告有关带宽,延迟抖动和数据报丢失的统计信息。 在Linux上,您可以将此输出重定向到文件; 在Windows上,使用-o filename参数。
运行每个测试十分钟,以确保任何潜在的问题都有机会发展。 使用以下命令行启动发送方和接收方。
发送方:
iperf -c 192.0.2.0 -u -T 1 -t 100 -i 1 -b 1000000000
此处:
| -c address | 在客户端模式下运行并连接到多播地址 |
|---|---|
| -u | 使用UDP |
| -T # | 组播生存时间:组播数据包在路由器丢弃数据包之前可以通过的子网数量 |
注意: 在未咨询网络管理员的情况下,请勿将-T参数设置为1以上。 如果此数字太高,则iperf流量可能会干扰生产应用程序或继续上网。
| -t | 传输时间,以秒为单位 |
|---|---|
| -i | 定期带宽报告之间的时间,以秒为单位 |
| -b | 发送带宽,以每秒位数为单位 |
接收者:
iperf -s -u -B 192.0.2.0 -i 1
此处:
| -s | 在服务器模式下运行 |
|---|---|
| -u | 使用 UDP |
| -B address | 绑定到多播地址 |
| -i # | 定期带宽报告之间的时间,以秒为单位 |
注意: 如果您的Geode集群跨多个子网运行,请在每个子网上启动接收器。
在接收器的输出中,查看Lost/ Total Datagrams列中的丢失数据包的数量和百分比。
Iperf测试的输出:
[ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams[ 3] 0.0- 1.0 sec 129 KBytes 1.0 Mbits/sec 0.778 ms 61/ 151 (40%)[ 3] 1.0- 2.0 sec 128 KBytes 1.0 Mbits/sec 0.236 ms 0/ 89 (0%)[ 3] 2.0- 3.0 sec 128 KBytes 1.0 Mbits/sec 0.264 ms 0/ 89 (0%)[ 3] 3.0- 4.0 sec 128 KBytes 1.0 Mbits/sec 0.248 ms 0/ 89 (0%)[ 3] 0.0- 4.3 sec 554 KBytes 1.0 Mbits/sec 0.298 ms 61/ 447 (14%)
在不同的带宽上重新运行测试,直到找到最大有用的多播速率。 从高处开始,然后逐渐降低发送速率,直到测试运行一致且没有丢包。 例如,您可能需要连续运行五个测试,每次更改-b(每秒位数)参数,直到没有丢失:
- -b 1000000000 (loss)
- -b 900000000 (no loss)
- -b 950000000 (no loss)
- -b 980000000 (a bit of loss)
- -b 960000000 (no loss)
输入iperf -h以查看所有命令行选项。 有关更多信息,请参阅Iperf用户手册。
配置多播速度限制
确定最大传输速率后,配置并调整生产系统。
为了获得最佳性能,生产者和消费者应该在不同的机器上运行,每个进程应该至少有一个专用的CPU。 以下是可以提高多播性能的配置更改列表。 请咨询系统管理员,了解如何更改此处讨论的任何限制。
将运行Microsoft Windows的系统的默认数据报大小从1024字节增加到与网络的最大传输单元(MTU)匹配的值,通常为1500字节。 较高的设置应该可以提高系统的网络性能。
默认情况下,禁用堆栈时间探测的分布统计信息以提高组播性能。 要降低多播速度,可以通过将gemfire .
enable-time-statistics属性设置为true来启用时间统计。这将启用Java应用程序的时间统计信息:
-Dgemfire.enable-time-statistics=true
时间统计信息属性在
gfsh命令行上传递给缓存服务器:gfsh>start server --name=server_name --enable-time-statistics=true
监控接收数据的成员是否有数据丢失迹象。 在区域创建期间可能会发生一些数据丢失消息。 还可以监视多播重传请求和单播重传以检测数据丢失。 即使您看到数据丢失,问题的原因也可能与网络无关。 但是,如果它经常发生,那么你应该再次尝试测试流量控制率
如有必要,重新配置所有
gemfire.properties文件,并使用较低的流量控制最大信用重复,直到找到安装的最大有效速率。通过减少多播消息在网络中的传输速度,可能有助于降低系统性能。
通过禁用批处理来减少多播延迟。 默认情况下,Geode在区域范围为distributed-no-ack时使用批处理操作。 在应用程序上或通过
gfsh命令行启动缓存服务器进程时,将disableBatching属性设置为true:gfsh>start server --name=server_name --J=-Dp2p.disableBatching=true
多播的运行时注意事项
使用多播进行消息传递和数据分发时,需要了解运行状况监视设置的工作原理以及如何控制内存使用。
多播健康监视器
Geode管理和监控系统由集群成员的maxRetransmissionRatio健康监控设置补充。 该比率是接收的重传请求数除以写入的多播数据报数。 如果比率为1.0,则成员重新发送与最初发送的数据包一样多的数据包。 重传是点对点的,许多进程可能会请求重传,因此如果出现问题,这个数字可能会很高。 maxRetransmissionRatio的默认值是0.2。
例如,考虑使用多播来传输缓存更新的具有一个生产者和两个缓存事件使用者的集群。 添加了新成员,该成员在未启用多播的计算机上运行。 结果,每次缓存更新都有重发请求,并且maxRetransmissionRatio变为1.0。
控制具有多播的Geode主机上的内存使用
内存不足会影响成员的性能并最终导致严重错误。
当数据通过多播分发时,Geode会产生为传输缓冲区保留的固定内存开销。 为每个分布式区域保留指定数量的内存。 这些生产者端缓冲区仅在接收器没有足够的CPU从生成器发送时快速读取其自己的接收缓冲区时使用。 在这种情况下,接收方抱怨数据丢失。 然后,生产者检索数据,如果它仍然存在于其缓冲区中,则重新发送给接收者。
调整传输缓冲区需要仔细平衡。 较大的缓冲区意味着更多数据可用于重传,在出现问题时提供更多保护。 另一方面,更大量的保留内存意味着可用于缓存的内存更少。
您可以通过重置gemfire.properties文件中的mcast-send-buffer-size参数来调整传输缓冲区大小:
mcast-send-buffer-size=45000
注意: 最大缓冲区大小仅受系统限制的约束。 如果您没有看到可能与内存不足相关的问题,请不要更改默认值,因为它可以在出现网络问题时提供更好的保护。
排除多播调整过程
在多播的初始测试和调整过程中可能会出现几个问题。
部分或全部成员无法沟通
如果您的应用程序和缓存服务器无法相互通信,即使它们配置正确,您的网络上也可能没有多播连接。 通常具有单播连接,但不具有多播连接。 见网络管理员。
组播速度比预期慢
寻找以太网流量控制限制。 如果您的混合速度网络导致多播泛洪问题,则以太网硬件可能会尝试减慢快速流量。
确保您的网络硬件可以处理多播流量并有效地路由它。 一些用于处理多播的网络硬件性能不足以支持全面的生产系统。
组播意外失败
例如,如果您通过测试发现多播失败超过了一个整数,它可以达到100 Mbps并且无论如何都会失败,因为它超过网络速率而怀疑它是失败的。 此问题通常出现在其中一个辅助LAN比主网络慢的站点
维护缓存一致性
维护分布式Geode系统中缓存之间的数据一致性对于确保其功能完整性和防止数据丢失至关重要。
一般准则
在使用磁盘存储重新启动区域之前,请考虑整个区域的状态
注意: 如果撤消成员的磁盘存储,请不要在以后使用其磁盘存储 - 隔离 - 重新启动该成员。
Geode存储有关持久数据的信息,并阻止您在正在运行的系统中启动具有已撤销磁盘存储的成员。 但Geode无法阻止您单独启动已撤销的成员,并使用其已撤销的数据运行。 这是不太可能的情况,但可以这样做:
- 成员A和B正在运行,都将区域数据存储到磁盘。
- 成员A关闭了。
- 成员B关闭了。
- 此时,成员B具有最新的磁盘数据。
- 成员B不可用。 也许它的主机暂时停机或中断。
- 要启动并运行系统,请启动成员A,然后使用命令行工具将成员B的状态撤消为具有最新数据的成员。 系统加载成员A的数据,然后你继续前进。
- 成员A被停止。
- 此时,成员A和成员B都在其磁盘文件中包含信息,表明它们是黄金副本成员。
- 如果启动成员B,它将从磁盘加载其数据。
- 当您启动成员A时,系统将识别不兼容状态并报告异常,但此时,您在两个文件中都有良好的数据,无法将它们组合在一起。
了解缓存事务
了解Geode事务的操作可以帮助您最小化缓存可能不同步的情况。
事务在具有全局范围的分布式区域中不起作用。
事务在一个缓存中提供一致性,但结果到其他成员的分布不一致。
由于读取已提交隔离,缓存中的多个事务可能会产生不一致。 由于多个线程无法参与事务,因此大多数应用程序将运行多个事务。
直接更改键值而不执行put的就地更改可能导致缓存不一致。 对于事务,它会产生额外的困难,因为它会破坏read committed isolation。 如果可能的话,请使用copy-on-read。
在distributed-no-ack范围内,不同成员中的两个冲突事务可以同时提交,在分发更改时互相覆盖。
如果在事务期间存在缓存写入器,则每个事务写入操作都会触发缓存写入器的相关调用。 无论区域的范围如何,事务提交只能在本地缓存中调用缓存编写器,而不能在远程缓存中调用。
具有事务的高速缓存中的区域可能不与没有事务的另一高速缓存中的同名区域保持同步。
在其事务中运行相同操作序列的两个应用程序可能会得到不同的结果。 这可能是因为在其中一个成员的事务外发生的操作可能会覆盖事务,即使在提交过程中也是如此。 如果大事务的结果超出机器的内存或Geode的容量,也可能发生这种情况。 这些限制因机器而异,因此两个成员可能不同步。
多站点部署指南
优化套接字缓冲区大小
在使用网关的多站点安装中,如果未针对最佳吞吐量调整站点之间的链接,则可能导致消息在缓存队列中备份。 如果队列因缓冲区大小不足而溢出,则它将与发送方不同步,接收方将不知道该情况。 您可以通过更改cache.xml文件中的gateway-sender和gateway-receiver元素的socket-buffer-size属性来配置用于数据传输的TCP/IP连接的发送 - 接收缓冲区大小。 通过确定链路带宽来设置缓冲区大小,然后使用ping来测量往返时间。
优化套接字缓冲区大小时,请为网关发送方和网关接收方使用相同的值。
防止主要和次要网关发件人脱机
在多站点安装中,如果主网关服务器脱机,则辅助网关发件人必须接管主要职责作为故障转移系统。 现有的辅助网关发件人检测到主网关发件人已脱机,而辅助网关发件人成为新的主要发件人。 由于队列是分布式的,因此其内容可供所有网关发件人使用。 因此,当辅助网关发送方成为主要网关时,它能够开始处理前一个主网关闭的队列,而不会丢失数据。
如果主网关发件人及其所有辅助发件人都脱机并且邮件在其队列中,则可能会发生数据丢失,因为没有故障转移系统。
验证isOriginRemote是否设置为False
默认情况下,服务器或多站点网关的isOriginRemote标志设置为false,以确保将更新分发给其他成员。 在服务器或接收网关成员中将其值设置为true仅将更新应用于该成员,因此更新不会分发给对等成员。
日志
全面的日志消息可帮助您确认配置和代码中的系统配置和调试问题。
Geode日志如何工作
Apache Geode使用Apache Log4j 2作为其日志记录系统的基础。
了解日志消息及其类别
系统日志消息通常与启动有关; 日志管理; 连接和系统成员; 分配; 或缓存,区域和条目管理。
命名,搜索和创建日志文件
管理和理解日志的最佳方法是让每个成员登录到自己的文件。
设置日志记录
您可以在成员的
gemfire.properties中或在启动时使用gfsh配置日志记录。高级用户 - 为Geode配置Log4j 2
基本Geode日志记录配置是通过gemfire.properties文件配置的。 本主题适用于由于与第三方库集成而需要加强对日志记录的控制的高级用户。
Geode日志如何工作
Apache Geode使用Apache Log4j 2作为其日志记录系统的基础。
Geode使用Apache Log4j 2API和核心库作为其日志记录系统的基础。 Log4j 2 API是一种流行且功能强大的前端日志API,所有Geode类都使用它来生成日志语句。 Log4j 2 Core是一个用于记录的后端实现; 您可以路由任何前端日志记录API库以记录到此后端。 Geode使用Core后端运行两个自定义Log4j 2 Appender:AlertAppender和LogWriterAppender。
Geode已经使用Log4j 2.11进行了测试。 Geode要求log4j-api-2.11.0.jar和log4j-core-2.11.0.jar JAR文件在类路径中。 这两个JAR都分布在<path-to-product>/lib目录中,并包含在相应的*-dependencies.jar便利库中。
AlertAppender 是生成Geode警报的组件,然后由JMX管理和监视系统管理。 有关详细信息,请参阅通知联合。
LogWriterAppender 是由所有log-*Geode属性配置的组件,例如log-file,log-file-size-limit和log-disk-space-limit。
这两个appender都是以编程方式创建和控制的。 您可以使用log-*Geode属性以及在JMX管理和监视系统中配置的警报级别来配置其行为。 这些appender目前不支持log4j2.xml配置文件中的配置。
高级用户可能希望定义自己的log4j2.xml。 有关详细信息,请参阅高级用户 - 为Geode配置Log4j 2。
了解日志消息及其类别
系统日志消息通常与启动有关; 日志管理; 连接和系统成员; 分配; 或缓存,区域和条目管理。
- 启动信息. 描述Java版本,Geode本机版本,主机系统,当前工作目录和环境设置。 这些消息包含有关系统和运行进程的配置的所有信息。
- 日志管理. 与维护日志文件本身有关。 此信息始终位于主日志文件中(请参阅日志文件名中的讨论)。
- 连接和系统成员资格. 报告集群成员(包括当前成员)的到达和离开以及与连接活动或故障相关的任何信息。 这包括有关分层缓存中层之间通信的信息。
- 分布式. 报告系统成员之间的数据分布。 这些消息包括有关区域配置,条目创建和修改以及区域和条目失效和销毁的信息。
- 缓存,区域和条目管理. 缓存初始化,侦听器活动,锁定和解锁,区域初始化和条目更新。
日志消息的结构
每条日志消息包含:
- 方括号内的消息头:
- 消息级别
- 记录消息的时间
- 记录消息的连接和线程的ID,可能是主程序或系统管理进程
- 消息本身,可以是带有异常堆栈跟踪的字符串和/或异常
[config 2005/11/08 15:46:08.710 PST PushConsumer main nid=0x1]Cache initialized using "file:/Samples/quickstart/xml/PushConsumer.xml".
日志文件名
在gemfire属性log-file设置中指定Geode系统成员的主日志。
Geode将此名称用于最新的日志文件,如果成员正在运行,则会主动使用,或用于上次运行。 Geode在应用程序启动时创建主日志文件。
默认情况下,主日志包含成员会话的整个日志。 如果指定log-file-size-limit,Geode会将日志记录拆分为以下文件:
- 主要的当前日志. 保持当前记录条目。 以您在
log-file中指定的字符串命名。 - 子日志. 持有较旧的日志条目。 这些是通过在达到大小限制时重命名主要的当前日志来创建的。
- 元数据日志文件,带有元名称前缀. 用于跟踪启动,关闭,子日志管理和其他日志记录管理操作
当达到指定的大小限制时,将当前日志重命名或滚动到下一个可用子日志。
当您的应用程序连接启用日志记录时,它会创建主日志文件,如果需要,还会创建meta -日志文件。 如果成员启动时存在主日志文件,则会将其重命名为下一个可用子日志,以便为新日志记录腾出空间。
您当前的主日志文件始终具有您在log-file中指定的名称。 旧日志文件和子日志文件具有从主日志文件名派生的名称。 这些是重命名的日志或子日志文件名的片段,其中filename.extension是log-file规范
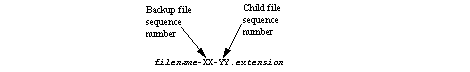
如果未使用子日志,则子文件序列号为常量00(两个零)。
对于定位器,日志文件名是固定的。 对于在gfsh中启动的独立定位器,它始终命名为<locator_name> .log,其中locator_name对应于定位器启动时指定的名称。 对于在另一个成员内部运行的定位器,日志文件是成员的日志文件。
对于应用程序和服务器,您的日志文件规范可以是相对的或绝对的。 如果未指定文件,则默认值为应用程序的标准输出,对于以gfsh启动的服务器的<server_name> .log和使用旧缓存服务器脚本启动的服务器的cacheserver.log。
要找出成员最近的活动,请查看meta-日志文件,如果不存在元文件,则查看主日志文件。
系统如何重命名日志
您指定的日志文件是用于所有日志记录和日志记录存档的基本名称。 如果启动时已存在具有指定名称的日志文件,则集群会在创建当前日志文件之前自动重命名该日志文件。 这是使用log-file=system.log进行几次运行后的典型目录列表:
bash-2.05$ ls -tlra system*-rw-rw-r-- 1 jpearson users 11106 Nov 3 11:07 system-01-00.log-rw-rw-r-- 1 jpearson users 11308 Nov 3 11:08 system-02-00.log-rw-rw-r-- 1 jpearson users 11308 Nov 3 11:09 system.logbash-2.05$
第一次运行创建了system.log,时间戳为11月3日11:07。 第二次运行将该文件重命名为system-01-00.log并创建了一个新的system.log,其时间戳为11月3日11:08。 第三次运行将该文件重命名为system-02-00.log,并在此清单中创建了名为system.log的文件。
当集群重命名日志文件时,它会将下一个可用数字分配给新文件,如filename-XX-YY.extension的XX。 下一个可用的数字取决于现有的旧日志文件以及任何旧的统计信息存档。 系统分配的下一个数字高于用于统计或记录的任何数字。 这样可以保持当前日志文件和统计信息存档的配对,而不管目录中旧文件的状态如何。 因此,如果应用程序正在归档统计信息并记录到system.log和statArchive.gfs,并且它在带有这些文件的Unix目录中运行:
bash-2.05$ ls -tlr stat* system*-rw-rw-r-- 1 jpearson users 56143 Nov 3 11:07 statArchive-01-00.gfs-rw-rw-r-- 1 jpearson users 56556 Nov 3 11:08 statArchive-02-00.gfs-rw-rw-r-- 1 jpearson users 56965 Nov 3 11:09 statArchive-03-00.gfs-rw-rw-r-- 1 jpearson users 11308 Nov 3 11:27 system-01-00.log-rw-rw-r-- 1 jpearson users 59650 Nov 3 11:34 statArchive.gfs-rw-rw-r-- 1 jpearson users 18178 Nov 3 11:34 system.log
运行后的目录内容如下所示(粗体中更改的文件):
bash-2.05$ ls -ltr stat* system*-rw-rw-r-- 1 jpearson users 56143 Nov 3 11:07 statArchive-01-00.gfs-rw-rw-r-- 1 jpearson users 56556 Nov 3 11:08 statArchive-02-00.gfs-rw-rw-r-- 1 jpearson users 56965 Nov 3 11:09 statArchive-03-00.gfs-rw-rw-r-- 1 jpearson users 11308 Nov 3 11:27 system-01-00.log-rw-rw-r-- 1 jpearson users 59650 Nov 3 11:34 statArchive-04-00.gfs-rw-rw-r-- 1 jpearson users 18178 Nov 3 11:34 system-04-00.log-rw-rw-r-- 1 jpearson users 55774 Nov 4 10:08 statArchive.gfs-rw-rw-r-- 1 jpearson users 17681 Nov 4 10:08 system.log
统计信息和日志文件使用两者都可用的下一个整数重命名,因此在这种情况下,日志文件序列会跳过间隙。
日志级别
日志级别越高,消息越重要和越紧急。 如果您的系统出现问题,则第一级方法是降低日志级别(从而将更多详细消息发送到日志文件)并重新创建问题。 其他日志消息通常有助于发现源。
这些是按降序排列的级别,带有示例输出:
severe (highest level). 此级别表示严重故障。 通常,严重消息描述了相当重要的事件,这些事件将阻止正常的程序执行。 您可能需要关闭或重新启动至少部分系统才能纠正这种情况。
通过将系统成员配置为连接到不存在的定位器来产生此严重错误:
[severe 2005/10/24 11:21:02.908 PDT nameFromGemfirePropertiesDownHandler (FD_SOCK) nid=0xf] GossipClient.getInfo():exception connecting to host localhost:30303:java.net.ConnectException: Connection refused
error. 此级别表示系统出现问题。 您应该能够继续运行,但错误消息中记录的操作失败。
这个错误是通过从
CacheListener抛出Throwable而产生的。 在将事件分派给客户实现的缓存侦听器时,Geode会捕获侦听器抛出的任何Throwable并将其记录为错误。 这里显示的文本后面是Throwable本身的输出。[error 2007/09/05 11:45:30.542 PDT gemfire1_newton_18222<vm_2_thr_5_client1_newton_18222-0x472e> nid=0x6d443bb0]Exception occurred in CacheListener
warning. 此级别表示潜在问题。 通常,警告消息描述最终用户或系统管理员感兴趣的事件,或指示程序或系统中潜在问题的事件。
此消息是通过在没有服务器运行来创建客户端队列时启动配置了启用排队的池的客户端获得的:
[warning 2008/06/09 13:09:28.163 PDT <queueTimer-client> tid=0xe]QueueManager - Could not create a queue. No queue servers available
此消息是通过尝试获取客户端区域中的条目而没有服务器运行来响应客户端请求而获得的:
[warning 2008/06/09 13:12:31.833 PDT <main> tid=0x1] Unable to create aconnection in the allowed timeorg.apache.geode.cache.client.NoAvailableServersExceptionat org.apache.geode.cache.client.internal.pooling.ConnectionManagerImpl.borrowConnection(ConnectionManagerImpl.java:166). . .org.apache.geode.internal.cache.LocalRegion.get(LocalRegion.java:1122)
info. 这适用于信息性消息,通常面向最终用户和系统管理员。
这是在系统成员启动时创建的典型信息消息。 这表明集群中没有其他`DistributionManager’正在运行,这意味着没有其他系统成员正在运行:
[info 2005/10/24 11:51:35.963 PDT CacheRunner main nid=0x1]DistributionManager straw(7368):41714 started on 192.0.2.0[10333]with id straw(7368):41714 (along with 0 other DMs)
当另一个系统成员加入集群时,这些信息消息由已在运行的成员输出:
[info 2005/10/24 11:52:03.934 PDT CacheRunner P2P message reader forstraw(7369):41718 nid=0x21] Member straw(7369):41718 has joined thedistributed cache.
当另一个成员因中断或正常程序终止而离开时:
[info 2005/10/24 11:52:05.128 PDT CacheRunner P2P message reader forstraw(7369):41718 nid=0x21] Member straw(7369):41718 has left thedistributed cache.
当另一名成员被杀时:
[info 2005/10/24 13:08:41.389 PDT CacheRunner DM-Puller nid=0x1b] Memberstraw(7685):41993 has unexpectedly left the distributed cache.
config. 这是日志记录的默认设置。 此级别提供静态配置消息,这些消息通常用于调试与特定配置相关的问题。
您可以使用此配置消息来验证启动配置:
[config 2008/08/08 14:28:19.862 PDT CacheRunner <main> tid=0x1] Startup Configuration:ack-severe-alert-threshold="0"ack-wait-threshold="15"archive-disk-space-limit="0"archive-file-size-limit="0"async-distribution-timeout="0"async-max-queue-size="8"async-queue-timeout="60000"bind-address=""cache-xml-file="cache.xml"conflate-events="server"conserve-sockets="true"...socket-buffer-size="32768"socket-lease-time="60000"ssl-ciphers="any"ssl-enabled="false"ssl-protocols="any"ssl-require-authentication="true"start-locator=""statistic-archive-file=""statistic-sample-rate="1000"statistic-sampling-enabled="false"tcp-port="0"udp-fragment-size="60000"udp-recv-buffer-size="1048576"udp-send-buffer-size="65535"
fine. 此级别提供开发人员通常感兴趣的跟踪信息。 它用于最低卷,最重要的跟踪消息。
注意: 通常,您应该仅在技术支持的指示下使用此级别。 在此日志记录级别,您将看到许多可能不会表明应用程序出现问题的噪音。 此级别创建非常详细的日志,可能需要比更高级别更多的磁盘空间。
[fine 2011/06/21 11:27:24.689 PDT <locatoragent_ds_w1-gst-dev04_2104> tid=0xe] SSL Configuration:ssl-enabled = false
finer, finest, and all. 这些级别仅供内部使用。 它们会产生大量数据,因此会占用大量磁盘空间和系统资源。 注意:除非技术支持人员要求,否则请勿使用这些设置。
注意: Geode不再支持为VERBOSE日志记录设置系统属性。 要启用VERBOSE日志记录,请参阅高级用户 - 为Geode配置Log4j 2
命名,搜索和创建日志文件
管理和理解日志的最佳方法是让每个成员登录到自己的文件。
日志文件命名建议
对于在同一台机器上运行的成员,您可以让它们通过在不同的工作目录中启动它们并使用相同的相对log-file规范来登录到它们自己的文件。 例如,您可以在<commonDirectoryPath>/gemfire.properties中设置它:
log-file=./log/member.log
然后使用此命令启动每个成员在不同的目录中,该命令指向公共属性文件:
java -DgemfirePropertyFile=<commonDirectoryPath>/gemfire.properties
这样,每个成员在其自己的工作目录下都有自己的日志文件。
搜索日志文件
要获得最清晰的描述,请使用gfsh export logs命令合并日志文件:
gfsh> export logs --dir=myDir --dir=myDir --merge-log=true
搜索以这些字符串开头的行:
- [warning
- [error
- [severe
创建自己的日志消息
除系统日志外,您还可以从Java代码中添加自己的应用程序日志。 有关向应用程序添加自定义日志记录的信息,请参阅org.apache.geode.LogWriter接口的联机Java文档。 根据您的日志记录配置设置输出和存储系统和应用程序日志记录。
设置日志记录
您可以在成员的gemfire.properties中或在启动时使用gfsh配置日志记录。
在开始之前,请确保您了解基本配置和编程.
在所有Geode主机上运行NTP等时间同步服务。 这是生成对故障排除有用的日志的唯一方法。 同步时间戳确保可以合并来自不同主机的日志消息,以准确地再现分布式运行的时间顺序历史。
使用嗅探器监视日志查找新的或意外的警告,错误或严重消息。 系统输出的日志具有各自的特征,表明您的系统配置和应用程序的特定行为,因此您必须熟悉应用程序的日志才能有效地使用它们。
根据需要在每个成员的
gemfire.properties中配置成员日志记录:# Default gemfire.properties log file settingslog-level=configlog-file=log-file-size-limit=0log-disk-space-limit=0
注意: 使用
gfsh命令行实用程序启动成员(定位器或服务器)时,也可以指定日志记录参数。 此外,您可以在成员已经运行时使用[alter runtime]修改日志文件属性和日志级别设置(http://geode.apache.org/docs/guide/17/tools_modules/gfsh/command-pages/alter.html#topic_7E6B7E1B972D4F418CB45354D1089C2B) 命令。设置
log-level。 选项是severe(最高级别),error,warning,info,config和fine。 较低级别包括更高级别的设置,因此warning的设置将记录warning,error和severe消息。 对于一般故障排除,我们建议将日志级别设置为config或更高。fine设置可以很快填满磁盘并影响系统性能。 仅在必要时使用fine。在
log-file中指定日志文件名。 这可以是相对的或绝对的。 如果未指定此属性,则默认值为:应用程序的标准输出
对于服务器,默认日志文件位置为:
working-directory/server-name.log
默认情况下,当通过
gfsh启动服务器时,working -directory对应于缓存服务器在启动时创建的目录(以其自身命名)。 或者,您可以在启动缓存服务器时指定其他工作目录路径。 server-name对应于启动时提供的缓存服务器的名称。对于独立定位器,默认日志文件位置为:
working-directory/locator-name.log
默认情况下,当通过
gfsh启动定位器时,working-directory对应于定位器启动时创建的目录(以其自身命名)。 或者,您可以在启动定位器时指定其他工作目录路径。 locator-name对应于启动时提供的定位器的名称。 如果使用共置定位器或嵌入式定位器,定位器日志将成为成员日志文件的一部分。
对于最简单的日志检查和故障排除,请将日志发送到文件而不是标准输出。 注意:确保每个成员都记录到自己的文件。 这使日志更容易破译。
在
log-file-size-limit中设置单个日志文件的最大大小。 如果未设置,则使用单个主日志文件。 如果设置,则使用元数据文件,主日志和滚动子日志。在
log-disk-space-limit中设置所有日志文件的最大大小。 如果非零,则限制所有非活动日志文件的组合大小,首先删除最旧的文件以保持在限制之下。 零设置表示没有限制。
如果使用
gfsh命令行界面,gfsh可以在运行gfsh或gfsh.bat脚本的目录中创建自己的日志文件。 默认情况下,gfsh不会为自己生成日志文件。 要启用gfsh日志,请在启动gfsh之前将以下系统属性设置为所需的日志级别:export JAVA_ARGS=-Dgfsh.log-level=[severe|warning|info|config|fine|finer|finest]
gfsh日志文件名为
gfsh-0_0.log。
高级用户 - 为Geode配置Log4j 2
基本Geode日志记录配置是通过gemfire.properties文件配置的。 本主题适用于由于与第三方库集成而需要加强对日志记录的控制的高级用户。
Geode使用的默认log4j2.xml作为log4j2-default.xml存储在geode.jar中。 可以在以下位置的产品分发中查看配置的内容:$GEMFIRE/defaultConfigs/log4j2.xml。
要指定您自己的log4j2.xml配置文件(或Log4j 2支持的任何其他内容,如.json或.yaml),请在启动JVM或Geode成员时使用以下标志:
-Dlog4j.configurationFile=<location-of-your-file>
如果指定了Java系统属性log4j.configurationFile,则Geode将不使用geode.jar中包含的log4j2-default.xml。 但是,如果配置了alert-level和log-fileGeode属性,Geode仍将创建并注册AlertAppender和LogWriterAppender。 然后,您可以使用Geode LogWriter记录Geode的日志,或者从客户的应用程序和所有第三方库生成警报和接收日志语句。 或者,您可以使用配置为记录到Log4j 2的任何前端日志记录API。
使用不同的前端日志API登录到Log4j2
您还可以配置Log4j 2以使用各种常用和常用的日志记录API。 要获取并配置最常用的前端日志记录API以登录到Log4j 2,请参阅Apache Log4j 2网站上的说明,网址为http://logging.apache.org/log4j/2.x/。
例如,如果您使用:
- Commons Logging, 下载 “Commons Logging Bridge” (
log4j-jcl-2.7.jar) - SLF4J, 下载 “SLFJ4 Binding” (
log4j-slf4j-impl-2.7.jar) - java.util.logging, 下载 “JUL adapter” (
log4j-jul-2.7.jar)
有关更多示例,请参阅http://logging.apache.org/log4j/2.x/faq.html。
以上所有三个JAR文件都在Log4J 2.1的完整发行版中,可以在http://logging.apache.org/log4j/2.x/download.html下载。 下载相应的桥接器,适配器或绑定JAR,以确保Geode日志记录与各种第三方库或您自己的应用程序中使用的每个日志记录API集成在一起。
注意: Apache Geode已经使用Log4j 2.1进行了测试。 随着Log4j 2的新版本问世,您可以在该页面上的Previous Releases下找到2.1。
自定义您自己的log4j2.xml文件
高级用户可能希望完全放弃设置log-*gemfire属性,而是使用-Dlog4j.configurationFile指定自己的log4j2.xml。
Geode中的自定义Log4j 2配置附带一些注意事项和注意事项:
不要在log4j2.xml文件中使用
“monitorInterval=”,因为这样做会对性能产生重大影响。 此设置指示Log4j 2在运行时监视log4j2.xml配置文件,并在文件更改时自动重新加载和重新配置。Geode的默认
log4j2.xml指定status=“FATAL”,因为当Geode停止其AlertAppender或LogWriterAppender时,Log4j 2的StatusLogger会在ERROR级别生成标准输出警告。 Geode使用大量并发线程来执行带有日志语句的代码; 这些线程可能在Geode appender停止时进行日志记录。Geode的默认log4j2.xml指定
shutdownHook=“disable”因为Geode有一个关闭钩子,它断开DistributedSystem并关闭Cache,它正在执行执行日志记录的代码。 如果Log4J2关闭挂钩在Geode完成关闭之前停止记录,则Log4j 2将尝试开始备份。 此重新启动反过来尝试注册另一个Log4j 2关闭挂钩,该挂钩失败导致Log4j 2记录了FATAL(致命)级别消息。GEODE_VERBOSE标记(Log4J2标记在http://logging.apache.org/log4j/2.x/manual/markers.html上讨论)可用于在TRACE级别启用其他详细日志语句。 只需启用DEBUG或TRACE即可启用许多日志语句。 但是,通过使用MarkerFilter接受GEODE_VERBOSE,可以进一步启用更多日志语句。 默认的Geode
log4j2.xml使用以下行禁用GEODE_VERBOSE:<MarkerFilter marker="GEODE_VERBOSE" onMatch="DENY" onMismatch="NEUTRAL"/>
您可以通过将
onMatch=“DENY”更改为onMatch=“ACCEPT”来启用GEODE_VERBOSE日志语句。 通常,在某些类或包而不是整个Geode产品上简单地启用DEBUG或TRACE更有用。 但是,如果所有其他调试方法都失败,则此设置可用于内部调试目的。
统计
集群中的每个应用程序和服务器都可以访问有关Apache Geode操作的统计数据。 您可以使用gfsh的alter runtime命令或gemfire.properties文件来配置统计信息的收集,以便于系统分析和故障排除。
统计如何运作
加入集群的每个应用程序或缓存服务器都可以收集和存档统计数据以分析系统性能。
瞬态区域和条目统计
对于复制区域,分布区域和本地区域,Geode为区域及其条目提供标准的统计信息集。
应用程序定义和自定义统计
Geode包括用于定义和维护您自己的统计信息的接口。
配置和使用统计信息
您可以通过多种不同方式配置统计信息和统计信息。
查看存档统计信息
统计如何运作
加入集群的每个应用程序或缓存服务器都可以收集和存档统计数据以分析系统性能。
可以为集群,应用程序,服务器或区域启用Geode统计信息。 为集群,应用程序或缓存服务器收集的统计信息将保存到文件中并可以存档,而区域统计信息是暂时的,只能通过API访问。
在gfsh或gemfire.properties配置文件中设置控制集群,应用程序或缓存统计信息收集的配置属性。 您还可以收集自己的应用程序定义统计信息。
当Java应用程序和服务器加入集群时,可以通过集群配置服务对其进行配置,以启用统计信息采样以及是否存档收集的统计信息。
注意: Geode统计信息使用JavaSystem.nanoTimer进行纳秒时序。 该方法提供纳秒精度,但不一定是纳秒精度。 有关更多信息,请参阅用于Geode的JRE的System.nanoTimer的联机Java文档。
统计抽样为正在进行的系统调整和故障排除提 采用默认采样率的采样统计信息(不包括基于时间的统计信息)不会影响整体集群性能。 我们建议在生产环境中启用统计抽样。 我们不建议在生产环境中启用基于时间的统计信息(使用enable-time-statistics属性配置)。
瞬态区域和条目统计
对于复制区域,分布区域和本地区域,Geode为区域及其条目提供标准的统计信息集。
当gfsh的create region命令的--enable-statistics参数设置为true或者在cache.xml中,区域属性statistics-enabled设置为true时,Geode会收集这些统计信息。
注意: 与其他Geode统计信息不同,这些区域和条目统计信息不会存档,也无法绘制。
注意: 启用这些统计信息需要每个条目额外的内存。 请参阅缓存数据的内存要求。
这些是为除分区区域以外的所有区域收集的瞬态统计信息:
- 命中和错过计数. 对于条目,命中计数是通过
Region.get方法访问缓存条目的次数,而未命中计数是这些命中未找到有效值的次数。 对于该地区,这些计数是该地区所有条目的总数。 API为命中和未命中计数提供了`get方法,提供了返回命中率的简便方法,以及将计数归零的方法。 - 上次访问时间. 对于条目,这是从本地缓存条目检索有效值的最后一次。 对于该地区,这是该地区所有条目的最近“最后访问时间”。 此统计信息用于空闲超时到期活动。
- 上次修改时间. 对于条目,这是由于加载,创建或放置操作而最后一次更新条目值(直接或通过分发)。 对于该地区,这是该地区所有条目的最近“最后修改时间”。 此统计信息用于生存时间和空闲超时到期活动。
这些统计信息中收集的命中和未命中计数可用于微调系统的缓存。 例如,如果您启用了区域的条目到期,并且看到条目的未命中率与命中率的比例很高,则可以选择增加到期时间。
通过Region和Region.Entry对象的getStatistics方法检索区域和条目统计信息。
应用程序定义和自定义统计
Geode包括用于定义和维护您自己的统计信息的接口。
Geode包org.apache.geode包括以下用于定义和维护自己的统计信息的接口:
- StatisticDescriptor. 描述个人统计。 每个统计信息都有一个名称和关于它所持有的统计信息的信息,例如它的类类型(long,int等),以及它是一个总是递增的计数器,还是一个可以以任何方式变化的指标。
- StatisticsType. 保存
StatisticDescriptors列表并提供访问方法的逻辑类型。StatisticsType包含的StatisticDescriptors每个都在列表中分配一个唯一的ID。StatisticsType用于创建Statistics实例。 - Statistics. 使用设置,递增,获取单个
StatisticDescriptor值以及设置回调的实例来实例化现有的StatisticsType对象,该回调将在配置的采样间隔重新计算统计值。 - StatisticsFactory. 创建
Statistics的实例。 您还可以使用它来创建StatisticDescriptor和StatisticsType的实例,因为它实现了StatisticsTypeFactory。DistributedSystem是StatisticsFactory的一个实例。 - StatisticsTypeFactory. 创建
StatisticDescriptor和StatisticsType的实例。
统计信息接口使用包中包含的统计工厂方法进行实例化。 有关编码示例,请参阅StatisticsFactory和`StatisticsTypeFactory的在线Java API文档。
例如,应用程序服务器可能会收集每个客户端会话的统计信息,以便衡量是否以令人满意的方式处理客户端请求。长请求队列或长服务器响应时间可能会提示某些容量管理操作,例如启动其他应用程序服务器。为了进行设置,在StatisticDescriptor实例中标识并定义每个会话状态数据点。一个实例可能是一个RequestsInQueue规范,一个递增和递减的非负整数。另一个可能是RequestCount计数器,一个总是递增的整数。这些描述符的列表用于实例化SessionStateStats StatisticsType。当客户端连接时,应用程序服务器使用StatisticsType对象来创建特定于会话的Statistics对象。然后,服务器使用Statistics方法来修改和检索客户端的统计信息。下图说明了统计接口之间的关系,并显示了此用例的实现。

统计接口
每个StatisticDescriptor都包含一条统计信息。 StatisticalDesriptor对象被收集到StatisticsType中。 实例化StatisticsType以创建Statistics对象。

统计实现
此处显示的StatisticDescriptor对象包含有关客户端会话状态的三条统计信息。 这些被收集到SessionStateStats StatisticsType中。 使用此类型,服务器为每个连接的客户端创建一个Statistics对象。
配置和使用统计信息
您可以通过多种方式配置统计信息和统计信息归档。
配置集群或服务器统计信息
在此过程中,假设您了解基本配置和编程.
执行以下命令以修改集群的配置并启用集群或服务器统计信息。
gfsh>start locator --name=l1 --enable-cluster-configuration=truegfsh>alter runtime --enable-statistics=true -–statistic-archive-file=myStatisticsArchiveFile.gfs
请注意,statistics-archive-file的空值仍会计算统计信息,但它们不会存档到文件中。
您还可以配置采样率和统计存档文件的文件名。 有关更多命令选项,请参阅alter runtime。
或者,如果您不使用集群配置服务,请配置gemfire.properties以进行所需的统计信息监视和归档:
为集群启用统计信息收集。 所有其他统计活动都需要这样做:
statistic-sampling-enabled=truestatistic-archive-file=myStatisticsArchiveFile.gfs
注意: 以默认采样率(1000毫秒)进行的统计采样不会影响系统性能,建议在生产环境中进行故障排除。
根据需要更改统计采样率。 例如:
statistic-sampling-enabled=truestatistic-archive-file=myStatisticsArchiveFile.gfsstatistic-sample-rate=2000
要将统计信息归档到磁盘,请启用该设置并设置所需的任何文件或磁盘空间限制。 例如:
statistic-sampling-enabled=truestatistic-archive-file=myStatisticsArchiveFile.gfsarchive-file-size-limit=100archive-disk-space-limit=1000
如果您需要基于时间的统计信息,请启用它。 基于时间的统计数据需要统计抽样和归档。 例如:
statistic-sampling-enabled=truestatistic-archive-file=myStatisticsArchiveFile.gfsenable-time-statistics=true
注意: 基于时间的统计信息可能会影响系统性能,因此不建议用于生产环境。
如果启用了这些统计信息,则可以通过gfsh show metrics命令访问存档的统计信息。
配置瞬态区域和条目统计信息
在您需要的区域上启用瞬态区域和条目统计信息收集。 此配置与启用集群或服务器统计信息不同。
gfsh example:
gfsh>create region --name=myRegion --type=REPLICATE --enable-statistics=true
cache.xml 例子:
<region name="myRegion" refid="REPLICATE"><region-attributes statistics-enabled="true"></region-attributes></region>
API 例子:
注意: 区域和条目统计信息不归档,只能通过API访问。 根据需要,通过Region和Region.Entry对象的getStatistics方法检索区域和条目统计信息。 例:
out.println("Current Region:\n\t" + this.currRegion.getName());RegionAttributes attrs = this.currRegion.getAttributes();if (attrs.getStatisticsEnabled()) {CacheStatistics stats = this.currRegion.getStatistics();out.println("Stats:\n\tHitCount is " + stats.getHitCount() +"\n\tMissCount is " + stats.getMissCount() +"\n\tLastAccessedTime is " + stats.getLastAccessedTime() +"\n\tLastModifiedTime is " + stats.getLastModifiedTime());}
配置定制统计
通过cache.xml和API创建和管理所需的任何自定义统计信息。
cache/cluster.xml 例子:
// Create custom statistics<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE statistics PUBLIC"-//Example Systems, Inc.//Example Statistics Type//EN""http://www.example.com/dtd/statisticsType.dtd"><statistics><type name="StatSampler"><description>Stats on the statistic sampler.</description><stat name="sampleCount" storage="int" counter="true"><description>Total number of samples taken by this sampler.</description><unit>samples</unit></stat><stat name="sampleTime" storage="long" counter="true"><description>Total amount of time spent taking samples.</description><unit>milliseconds</unit></stat></type></statistics>
API 例子:
// Update custom stats through the APIthis.samplerStats.incInt(this.sampleCountId, 1);this.samplerStats.incLong(this.sampleTimeId, nanosSpentWorking / 1000000);
控制存档文件的大小
您可以使用gfshalter runtime命令为统计信息指定存档文件的限制。 这些是控制领域:
存档文件增长率
--statistic-sample-rate参数控制采样的频率,这会影响存档文件增长的速度。--statistic-archive-file参数控制是否压缩统计文件。 如果为文件名提供一个.gz后缀,则会对其进行压缩,从而占用较少的磁盘空间。
单个存档文件的最大大小. 如果
--archive-file-size-limit的值大于零,则在当前存档的大小超过限制时启动新存档。 一次只能激活一个存档。 注意: 如果在集群运行时修改--archive-file-size-limit的值,则在当前归档变为非活动状态(即启动新归档时)之前,新值不会生效。所有存档文件的最大大小.
--archive-disk-space-limit参数控制所有非活动归档文件的最大大小。 默认情况下,限制设置为0,表示存档空间不受限制。 每当存档变为非活动状态或重命名存档文件时,都会计算非活动文件的组合大小。 如果大小超过--archive-disk-space-limit,则删除具有最早修改时间的非活动归档。 这一直持续到组合尺寸小于极限。 如果--archive-disk-space-limit小于或等于--archive-file-size-limit,当活动归档因其大小而变为非活动状态时,会立即删除它。
注意: 如果在集群运行时修改--archive-disk-space-limit的值,则在当前归档变为非活动状态之前,新值不会生效。
查看存档统计信息
启用采样和存档后,您可以检查存档的历史数据以帮助诊断性能问题。 使用gfshshow metrics命令研究归档文件中的统计信息。 您可能还希望使用单独的统计信息显示实用程序。
故障排除和系统恢复
本节提供了处理常见错误和故障情况的策略。
生成用于故障排除的工件
有几种类型的文件对于故障排除至关重要。
诊断系统问题
本节提供系统问题的可能原因和建议的响应。
系统故障和恢复
本节介绍对各种系统故障的警报和适当的响应。 它还可以帮助您规划数据恢复策略。
使用自动重新连接处理强制缓存断开连接
如果成员在一段时间内没有响应,或者如果网络分区将一个或多个成员分成太小而不能充当集群的组,则可以强制断开Geode成员与集群的连接。
从应用程序和缓存服务器崩溃中恢复
当应用程序或缓存服务器崩溃时,其本地缓存将丢失,并且它所拥有的任何资源(例如,分布式锁定)都将被释放。 成员必须在恢复时重新创建其本地缓存。
从机器崩溃中恢复
当计算机因关闭,断电,硬件故障或操作系统故障而崩溃时,其所有应用程序和缓存服务器及其本地缓存都将丢失。
从冲突的持久数据异常中恢复
启动持久成员时出现
ConflictingPersistentDataException表示您有一些持久数据的多个副本,并且Geode无法确定要使用哪个副本。防止和恢复磁盘完全错误
监视Geode成员的磁盘使用情况非常重要。 如果成员缺少足够的磁盘空间用于磁盘存储,则该成员会尝试关闭磁盘存储及其关联的缓存,并记录错误消息。 由于成员磁盘空间不足而导致的关闭可能导致数据丢失,数据文件损坏,日志文件损坏以及可能对您的应用程序产生负面影响的其他错误情况。
理解和恢复网络中断
对网络中断的最安全响应是重新启动所有进程并调出新数据集。
生成用于故障排除的工件
有几种类型的文件对于故障排除至关重要。
Geode日志和统计信息是故障排除中使用的两个最重要的工件。 此外,它们是Geode系统健康验证和性能分析所必需的。 出于这些原因,应始终启用日志记录和统计信息,尤其是在生产中。 保存以下文件以进行故障排除:
- 日志文件. 即使在默认日志记录级别,日志也包含可能很重要的数据。 保存整个日志,而不仅仅是堆栈。 为了进行比较,请在问题发生之前,期间和之后保存日志文件。
- 统计存档文件。
- 核心文件或堆栈跟踪。
- 对于Linux,您可以使用gdb从核心文件中提取堆栈。
- 崩溃转储。
- 对于Windows,请保存用户模式转储文件。 有些位置要检查这些文件:
- C:\ProgramData\Microsoft\Windows\WER\ReportArchive
- C:\ProgramData\Microsoft\Windows\WER\ReportQueue
- C:\Users*UserProfileName*\AppData\Local\Microsoft\Windows\WER\ReportArchive
- C:\Users*UserProfileName*\AppData\Local\Microsoft\Windows\WER\ReportQueue
当出现涉及多个进程的问题时,最可能的原因是网络问题。 诊断问题时,请为所涉及的所有集群的每个成员创建一个日志文件。 如果您正在运行客户端/服务器体系结构,请为客户端创建日志文件。
注意: 您必须在所有主机上运行时间同步服务以进行故障排除。 同步时间戳确保可以合并不同主机上的日志消息,以准确地再现分布式运行的时间顺序历史。
对于每个流程,请完成以下步骤:
确保主机的时钟与其他主机同步。 使用时间同步工具,如网络时间协议(NTP)。
通过编辑
gemfire.properties来包含以下行,启用日志记录而不是标准输出:log-file=filename
将日志级别保持在
config以避免在包含配置信息时填满磁盘。 将此行添加到gemfire.properties:log-level=config
注意: 使用
fine的日志级别运行可能会影响系统性能并填满磁盘。通过修改
gemfire.properties为集群启用统计信息收集:statistic-sampling-enabled=truestatistic-archive-file=StatisticsArchiveFile.gfs
或者使用
gfsh alter rutime命令:alter runtime --group=myMemberGroup --enable-statistics=true --statistic-archive-file=StatisticsArchiveFile.gfs
注意: 以1000毫秒的默认采样率频率收集统计信息不会产生性能开销。
再次运行该应用程序。
检查日志文件。 要获得最清晰的描述,请合并文件。 要查找日志文件中的所有错误,请搜索以这些字符串开头的行:
[error[severe
有关合并日志文件的详细信息,请参阅[export logs]的
--merge-log参数(http://geode.apache.org/docs/guide/17/tools_modules/gfsh/command-pages/export.html#topic_B80978CC659244AE91E2B8CE56EBDFE3)命令。导出并分析运行应用程序的成员或成员组上的堆栈跟踪。 使用
gfsh export stack-traces命令。 例如:gfsh> export stack-traces --file=ApplicationStackTrace.txt --member=member1
诊断系统问题
本节提供系统问题的可能原因和建议的响应。
- 定位器无法启动
- 应用程序或缓存服务器进程无法启动
- 应用程序或缓存服务器不加入集群
- 成员流程似乎挂了
- 成员进程不读取gemfire.properties文件中的设置
- 缓存创建失败 - 必须与模式定义根匹配
- 缓存配置不正确
- keySetOnServer和containsKeyOnServer的意外结果
- 数据操作返回PartitionOfflineException
- 条目未按预期被逐出或过期
- 找不到日志文件
- 内存溢出错误
- 分区区域分布异常
- 分区区域存储异常
- 应用程序崩溃而不会产生异常
- 超时警报
- 成员生成SocketTimeoutException
- 成员日志强制关闭ForcedDisconnectException,Cache和DistributedSystem
- 成员们看不到对方
- 集群的一部分无法看到另一部分
- 虽然成员进程正在运行,但数据分发已停止
- Distributed-ack操作需要很长时间才能完成
- 系统性能低下
- 无法获取Windows性能数据
- 64位平台上的Java应用程序挂起或使用100%CPU
定位器无法启动
使用gfsh调用定位器失败,出现如下错误:
Starting a GemFire Locator in C:\devel\gfcache\locator\locatorThe Locator process terminated unexpectedly with exit status 1. Please refer to the logfile in C:\devel\gfcache\locator\locator for full details.Exception in thread "main" java.lang.RuntimeException: An IO error occurred whilestarting a Locator in C:\devel\gfcache\locator\locator on 192.0.2.0[10999]: Network isunreachable; port (10999) is not available on 192.0.2.0.atorg.apache.geode.distributed.LocatorLauncher.start(LocatorLauncher.java:622)atorg.apache.geode.distributed.LocatorLauncher.run(LocatorLauncher.java:513)atorg.apache.geode.distributed.LocatorLauncher.main(LocatorLauncher.java:188)Caused by: java.net.BindException: Network is unreachable; port (10999) is not available on192.0.2.0.atorg.apache.geode.distributed.AbstractLauncher.assertPortAvailable(AbstractLauncher.java:136)atorg.apache.geode.distributed.LocatorLauncher.start(LocatorLauncher.java:596)...
这表示地址中某处不匹配,用于定位器启动和配置的端口对。 用于定位器启动的地址必须与您在gemfire.properties定位器规范中为定位器列出的地址匹配。 该集群的每个成员(包括定位器本身)都必须在gemfire.properties中具有完整的定位器规范。
解答:
- 检查您的定位器规范是否包含用于启动定位器的地址。
- 如果使用绑定地址,则必须使用数字地址作为定位器规范。 绑定地址不会解析为计算机的默认地址。
- 如果您使用的是64位Linux系统,请检查您的系统是否遇到了闰秒错误。 有关详细信息,请参阅64位平台上的Java应用程序挂起或使用100%CPU。
应用程序或缓存服务器进程无法启动
如果进程尝试启动然后静默消失,则在Windows上这表示存在内存问题。
解答:
在Windows主机上,减小最大JVM堆大小。 此属性在
gfsh命令行中指定:gfsh>start server --name=server_name --max-heap=1024m
有关详细信息,请参阅JVM内存设置和系统性能。
如果这不起作用,请尝试重新启动。
应用程序或缓存服务器不加入集群
解答: 检查这些可能的原因。
- 网络问题 - 最常见的原因。 首先,尝试ping其他主机。
- 防火墙问题。 如果分布式Geode系统的成员位于LAN外部,请检查防火墙是否阻止通信。 Geode是一个以网络为中心的分布式系统,因此如果您的计算机上运行了防火墙,则可能会导致连接问题。 例如,如果防火墙对基于Java的套接字的入站或出站权限设置了限制,则连接可能会失败。 您可能需要修改防火墙配置以允许流量到您计算机上运行的Java应用程序。 具体配置取决于您使用的防火墙。
- 使用多播进行成员身份时,组播端口错误。 检查此应用程序或缓存服务器的
gemfire.properties文件,以查看是否正确配置了mcast-port。 如果您在站点上运行多个集群,则每个集群都必须使用唯一的多播端口。 - 无法连接到定位器(使用TCP进行发现时)。
- 检查此进程的
gemfire.properties中的locators属性是否具有正确的定位器IP地址。 - 检查定位器进程是否正在运行。 如果没有,请参阅相关问题的说明,数据分发已停止,但成员进程正在运行。
- 在多宿主主机上绑定地址设置不正确。 指定绑定地址时,请使用IP地址而不是主机名。 有时,多个网络适配器配置有相同的主机名。 有关使用绑定地址的详细信息,请参阅拓扑和通信一般概念。
- 检查此进程的
- 错误的Geode版本。 版本不匹配可能导致进程挂起或崩溃。 使用gemfire version命令检查软件版本。
成员流程似乎挂了
解答:
- 初始化期间—对于持久性区域,成员可能正在等待具有更新近数据的另一个成员从其磁盘存储启动和加载。 请参阅磁盘存储。 等待初始化完成或超时。 这个过程可能很忙 - 有些缓存有数百万个条目,并且它们可能需要很长时间才能加载。 特别是对于缓存服务器,请查找它,因为它们的区域通常是副本,因此存储区域中的所有条目。 另一方面,应用程序通常仅存储条目的子集。 对于分区区域,如果初始化最终超时并产生异常,则系统架构师需要重新分区数据。
- 对于正在运行的进程—调查另一个成员是否正在初始化。 在某些可选的集群配置下,可能需要一个进程在其进行之前等待来自其他进程的响应。
成员进程不读取gemfire.properties文件中的设置
进程无法找到配置文件,或者如果是应用程序,则可能正在进行编程配置。
解答:
- 检查
gemfire.properties文件是否在正确的目录中。 - 确保该进程没有从搜索路径中较早的另一个
gemfire.properties文件中获取设置。 Geode按顺序在当前工作目录,主目录和CLASSPATH中查找gemfire.properties文件。 - 对于应用程序,请检查文档以查看它是否进行了编程配置。 如果是这样,则无法在
gemfire.properties文件中重置以编程方式设置的属性。 有关配置更改,请参阅应用程序的客户支持组。
缓存创建失败 - 必须与模式定义根匹配
系统成员启动失败,出现如下错误:
Exception in thread "main" org.apache.geode.cache.CacheXmlException:While reading Cache XML file:/C:/gemfire/client_cache.xml.Error while parsing XML, caused by org.xml.sax.SAXParseException:Document root element "client-cache", must match DOCTYPE root "cache".Exception in thread "main" org.apache.geode.cache.CacheXmlException:While reading Cache XML file:/C:/gemfire/cache.xml.Error while parsing XML, caused by org.xml.sax.SAXParseException:Document root element "cache", must match DOCTYPE root "client-cache".
Geode声明式缓存创建使用两个根元素对之一:cache或client-cache。 两个地方的名称必须相同。
解答:
- 修改
cache.xml文件,使其具有正确的XML命名空间和模式定义。
对于成员和服务器:
<?xml version="1.0" encoding="UTF-8"?><cachexmlns="http://geode.apache.org/schema/cache"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://geode.apache.org/schema/cache http://geode.apache.org/schema/cache/cache-1.0.xsd"version="1.0”>...</cache>
对于客户端:
<?xml version="1.0" encoding="UTF-8"?><client-cachexmlns="http://geode.apache.org/schema/cache"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://geode.apache.org/schema/cache http://geode.apache.org/schema/cache/cache-1.0.xsd"version="1.0">...</client-cache>
缓存配置不正确
空缓存可以是正常情况。 某些应用程序以空缓存开始并以编程方式填充,但其他应用程序则设计为在初始化期间批量加载数据。
解答:
如果您的应用程序应该以完整缓存开始但是空白,请检查以下可能的原因:
- 无区域—如果缓存没有区域,则进程不会读取缓存配置文件。 检查缓存配置文件的名称和位置是否与
gemfire.properties中cache-xml-file属性中配置的名称和位置相匹配。 如果它们匹配,则该过程可能不会读取gemfire.properties。 请参阅成员进程不读取gemfire.properties文件中的设置. - 区域没有数据—如果缓存以区域开头但没有数据,则此进程可能没有加入正确的集群。 检查日志文件以查找指示其他成员的消息。 如果您没有看到任何内容,则该进程可能在其自己的集群中单独运行。 在明显属于正确集群的过程中,没有数据的区域可能表示实现设计错误。
keySetOnServer和containsKeyOnServer的意外结果
如果您的服务器区域未配置为分区或复制区域,则客户机对keySetOnServer和containsKeyOnServer的调用可能会返回不完整或不一致的结果。
未分区的非复制服务器区域可能无法保存分布式区域的所有数据,因此这些方法将在数据集的部分视图上运行。
此外,客户端方法对每个方法调用使用负载最小的服务器,因此可以使用不同的服务器进行两次调用。 如果服务器的本地数据集中没有一致的视图,则对客户端请求的响应会有所不同。
只有通过使用分区或复制数据策略设置配置服务器区域,才能保证一致的视图。 服务器系统的非服务器成员可以使用任何允许的配置,因为它们不可用于接收客户端请求。
以下服务器区域配置会产生不一致的结果。 这些配置允许不同服务器上的不同数据。 服务器上没有其他消息传递,因此没有跨服务器的key联合或检查其他服务器的key。
- 正常
- 混合(复制,正常,空)单个分布区域。 结果不一致取决于客户端向哪个服务器发送请求
这些配置提供一致的结果:
- 分区服务器区域
- 复制的服务器区域
- 空服务器区域:keySetOnServer返回空集,containsKeyOnServer返回false
解答: 对服务器区域使用分区或复制数据策略。 这是为服务器数据集的客户端提供一致视图的唯一方法。 请参阅区域数据存储和分配选项.
数据操作返回PartitionOfflineException
在持久保存到磁盘的分区区域中,如果有任何成员脱机,则分区区域仍然可用,但可能只有一些存储区仅在脱机磁盘存储区中表示。 在这种情况下,访问存储区条目的方法返回PartitionOfflineException,类似于:
org.apache.geode.cache.persistence.PartitionOfflineException:Region /__PR/_B__root_partitioned__region_7 has persistent data that is nolonger online stored at these locations:[/192.0.2.1:/export/straw3/users/jpearson/bugfix_Apr10/testCL/hostB/backupDirectorycreated at timestamp 1270834766733 version 0]
解答: 如果可能的话,将失踪的成员重新联机。 这会将存储桶还原到内存中,您可以再次使用它们。 如果丢失的成员无法重新联机,或者该成员的磁盘存储已损坏,则可能需要撤消该成员,这将允许系统在新成员中创建存储桶并使用这些条目恢复操作。 请参阅处理丢失的磁盘存储.
条目未按预期被逐出或过期
检查这些可能的原因。
- 事务—如果它们涉及事务,则到期的条目可以保留在缓存中。 此外,事务永远不会超时,因此如果事务挂起,事务中涉及的条目将仍然停留在缓存中。 如果您有一个挂起事务的进程,则可能需要结束该进程以删除该事务。 在您的应用程序编程中,不要让事务处于开放状态。 将所有事务编程为以提交或回滚结束。
- 分区区域—出于性能原因,逐出区域中的逐出和过期行为会有所不同,并且可能导致条目在您预期之前被删除。 参见逐出 和过期。
找不到日志文件
没有日志文件的操作可能是正常情况,因此该过程不会记录警告。
解答:
- 检查
gemfire.properties中是否配置了log-file属性。 如果没有,则日志记录默认为标准输出,而在Windows上可能根本不可见。 - 如果正确配置了log-file,则该进程可能不会读取
gemfire.properties。 请参阅成员进程不读取gemfire.properties文件中的设置。
内存溢出错误
如果应用程序需要的内存超过进程能够提供的内存,则会获得OutOfMemoryError。 消息包括java.lang.OutOfMemoryError。
解答:
该过程可能正在达到其虚拟地址空间限制。 虚拟地址空间必须足够大,以容纳堆,代码,数据和动态链接库(DLLs)。
如果您的应用程序经常内存不足,您可能需要对其进行分析以确定原因。
如果您怀疑堆大小设置得太低,可以使用-Xmx重置最大堆大小来增加直接内存。 有关详细信息,请参阅JVM内存设置和系统性能.
您可能需要降低线程堆栈大小。 默认的线程堆栈大小非常大:Sparc上的512kb和Intel上的256kb(1.3和1.4 32位JVM),以及64位Sparc 1.4 JVM的1mb; 和1.2k用于1.2 JVM。 如果你有数千个线程,那么你可能会浪费大量的堆栈空间。 如果这是您的问题,则错误可能是这样的:
OutOfMemoryError: unable to create new native thread
1.3和1.4中的最小设置为64kb,1.2中的最小设置为32kb。 您可以使用-Xss标志更改堆栈大小,如下所示:-Xss64k
您还可以通过设置区域的输入限制来控制内存使用。
分区区域分布异常
多次尝试完成分布式操作后Geode失败时,会出现org.apache.geode.cache.PartitionedRegionDistributionException。 此异常表示无法找到数据存储成员执行销毁,无效或获取操作。
解答:
- 检查网络是否存在交通拥堵或与成员断开的连接。
- 查看问题的整体安装,例如应用程序级别的操作设置为比Geode进程更高的优先级。
- 如果您一直看到PartitionedRegionDistributionException,则应评估是否需要启动更多成员。
分区区域存储异常
当Geode无法创建新条目时,将显示org.apache.geode.cache.PartitionedRegionStorageException。 此异常源于put和create操作缺少存储空间或者使用加载器进行get操作。 PartitionedRegionStorageException通常表示数据丢失或即将发生的数据丢失。
文本字符串指示异常的原因,如下例所示:
Unable to allocate sufficient stores for a bucket in the partitioned region....Ran out of retries attempting to allocate a bucket in the partitioned region....
解答:
- 检查网络是否存在交通拥堵或与成员断开的连接。
- 看是否存在问题,如设置成比的Geode处理更高优先级的应用程序级的操作整体安装。
- 如果您继续看到PartitionedRegionStorageException,则应评估是否需要启动更多成员。
应用程序崩溃而不会产生异常
如果应用程序崩溃没有任何异常,这可能是由对象内存问题引起的。 该过程可能会达到其虚拟地址空间限制。 有关详细信息,请参阅OutOfMemoryError.
解答: 通过设置区域的输入限制来控制内存使用。
超时警报
如果分布式消息在指定时间内没有得到响应,它会发送一个警报,表示系统成员可能没有响应的问题。 警报将作为警告记录在发件人日志中。
超时警报可被视为正常。
解答:
- 如果您看到很多超时并且之前没有看过它们,请检查您的网络是否比较拥挤。
- 如果在正常操作期间不断看到这些警报,请考虑将ack-wait-threshold提高到默认值15秒以上。
成员生成SocketTimeoutException
当客户端和服务器停止等待来自连接另一端的响应并关闭套接字时,它会产生SocketTimeoutException。 此异常通常发生在握手或建立回调连接时。
解答:
增加成员的默认套接字超时设置。 此超时是为客户端池单独设置的。 对于客户端/服务器配置,请按 中所述调整“读取超时”值或使用org.apache.geode.cache.client.PoolFactory.setReadTimeout方法。
成员日志强制关闭ForcedDisconnectException,Cache和DistributedSystem
如果集群成员的Cache和DistributedSystem生病或者太慢而无法响应心跳请求,则会强制关闭集群成员的Cache和DistributedSystem。 发生这种情况时,侦听器会收到带有FORCED_DISCONNECT操作码的RegionDestroyed通知。 该成员的Geode日志文件显示带有该消息的ForcedDisconnectException
This member has been forced out of the cluster because it did not respondwithin member-timeout milliseconds
解答:
为了最大限度地减少发生这种情况的可能性,可以增加DistributedSystem属性member-timeout。 但请注意,此设置还会控制注意网络故障所需的时间长度。 它不应该设置得太高。
成员们看不到对方
怀疑网络问题或在运输用于存储器和发现的结构的问题。
解答:
- 检查网络监视工具以查看网络是否已关闭或已泛滥。
- 如果您使用的是多宿主主机,请确保为所有系统成员设置绑定地址并保持一致。 有关使用绑定地址的详细信息,请参阅拓扑和通信一般概念.
- 检查所有应用程序和缓存服务器是否使用相同的定位器地址。
集群的一部分无法看到另一部分
这种情况可能会使您的缓存处于不一致状态。 在网络圈中,这种网络中断被称为“裂脑问题”。
解答:
- 重新启动所有进程以确保数据一致性。
- 展望未来,设置网络监控工具以快速检测这些类型的中断。
- 启用网络分区检测。
另请参阅了解和恢复网络中断.
虽然成员进程正在运行,但数据分发已停止
怀疑网络,定位器或多播配置存在问题,具体取决于您的集群使用的传输。
解答:
检查系统成员的运行状况。 在日志中搜索此字符串:
Uncaught exception
未捕获的异常意味着严重错误,通常是OutOfMemoryError。参见见OutOfMemoryError.
检查网络监视工具以查看网络是否已关闭或已泛滥。
如果使用多播,请检查现有配置是否不适合当前网络流量。
检查定位器是否已停止。 有关正在使用的定位器的列表,请检查其中一个应用程序
gemfire.properties文件中的locators属性。- 如果可能,重新启动相同主机上的定位器进程。 集群开始正常运行,数据分发自动重启。
- 如果必须将定位器移动到其他主机或其他IP地址,请完成以下步骤:
- 按通常顺序关闭集群的所有成员。
- 在新位置重新启动定位器进程。
- 编辑所有gemfire.properties文件以在locators属性中更改此定位器的IP地址。
- 按常规顺序重新启动应用程序和缓存服务器。
在每个定位器主机上创建一个watchdog守护程序或服务,以在停止时重新启动定位器进程
Distributed-ack操作需要很长时间才能完成
在具有大量distributed-no-ack操作的系统中可能会发生此问题。 也就是说,许多非ack操作的存在可能导致ack操作需要很长时间才能完成。
解答:
有关缓解此问题的信息,请参阅Slow distributed-ack Messages.
系统性能低下
系统性能较慢有时是由于缓冲区大小太小而不能分配对象。
解答:
如果您遇到性能下降并且正在发送大对象(多兆字节),请尝试增加系统中的套接字缓冲区大小设置。 有关更多信息,请参阅套接字通信.
无法获取Windows性能数据
尝试在Windows上运行Geode的性能测量可能会产生以下错误消息:
Can't get Windows performance data. RegQueryValueEx returned 5
发生此错误的原因是,当Win32应用程序使用HKEY_PERFORMANCE_DATA调用ANSI版本的RegQueryValueEx Win32 API时,会返回不正确的信息。 Microsoft知识库文章ID 226371中http://support.microsoft.com/kb/226371/en-us中描述了此错误。
解答:
若要成功获取Windows性能数据,您需要验证您是否具有系统注册表中正确的注册表项访问权限。 特别是,确保以下注册表路径中的Perflib可由Geode进程读取(KEY_READ访问):
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Perflib
性能数据的合理安全性的一个示例是授予管理员KEY_ALL_ACCESS访问权限和交互式用户KEY_READ访问权限。 此特定配置将阻止非管理员远程用户查询性能数据。
有关如何确保Geode进程可以访问与性能相关的注册表项的说明,请参阅http://support.microsoft.com/kb/310426和http://support.microsoft.com/kb/146906。。
64位平台上的Java应用程序挂起或使用100%CPU
如果您的Java应用程序突然开始使用100%CPU,您可能会遇到闰秒错误。 这个错误可以在Linux内核中找到,并且会严重影响Java程序。 特别是,您可能会注意到使用Thread.sleep(n)进行方法调用,其中n是一个小数字,实际上会比该方法定义的时间长得多。 要验证您是否遇到此错误,请检查主机的dmesg输出以获取以下消息:
[10703552.860274] Clock: inserting leap second 23:59:60 UTC
要解决此问题,请在受影响的Linux计算机上发出以下命令:
prompt> /etc/init.d/ntp stopprompt> date -s "$(date)"
有关更多信息,请访问以下网站:http://blog.wpkg.org/2012/07/01/java-leap-second-bug-30-june-1-july-2012-fix/
系统故障和恢复
本节介绍对各种系统故障的警报和适当的响应。 它还可以帮助您规划数据恢复策略。
如果系统成员由于成员,主机或网络出现故障而不自觉地从集群中退出,则其他成员会自动适应丢失并继续运行。 集群不会遇到任何干扰,例如超时。
规划数据恢复
在规划数据恢复策略时,请考虑以下因素:
- 区域是否仅配置为数据冗余分区区域。
- 区域的角色丢失策略配置,它控制区域在崩溃或系统故障之后的行为 - 仅针对分布式区域。
- 区域是否配置为持久性到磁盘。
- 失败的程度,涉及多个成员或网络中断。
- 您的应用程序的特定需求,例如更换数据的难度以及运行应用程序数据不一致的风险。
- 当由于网络分区或响应缓慢而生成警报时,表示某些进程可能或将要失败。
本节的其余部分提供了各种系统故障的恢复说明。
网络分区,慢响应和成员删除警报
当发生网络分区检测或响应缓慢时,会生成以下警报:
- 检测到网络分区
- 成员花了太长时间做出响应
- 找不到定位器
- 删除前的警告通知
- 成员被迫出局
有关配置系统成员以帮助避免出现网络故障时的网络分区配置条件或成员无法相互通信的信息,请参阅了解和恢复网络中断.
检测到网络分区
警报:
Membership coordinator id has declared that a network partition has occurred.
描述:
发生网络分区时会发出此警报,然后在单个成员上发出此警报:
警报:
Exiting due to possible network partition event due to loss of {0} cache processes: {1}
解答:
检查列出的缓存进程的网络连接和运行状况。
成员太长时间没有回应
警报:
15 sec have elapsed while waiting for replies: <ReplyProcessor21 6 waiting for 1 repliesfrom [ent(27130):60333/36743]> on ent(27134):60330/45855 whose current membershiplist is: [[ent(27134):60330/45855, ent(27130):60333/36743]]
描述:
成员(27130):60333/36743由于可疑验证失败而面临被迫退出集群的危险。 在达到ack-wait-threshold之后,将在警告级别发出此警报。
解答:
操作员应检查过程以确定其是否健康。 在名为ent的机器上,慢响应器的进程ID是27130。 慢响应者的端口是60333/36743。 查找字符串,Starting distribution manager ent:60333/36743,并检查拥有包含此字符串的日志文件的进程。
警报:
30 sec have elapsed while waiting for replies: <ReplyProcessor21 6 waiting for 1 repliesfrom [ent(27130):60333/36743]> on ent(27134):60330/45855 whose current membershiplist is: [[ent(27134):60330/45855, ent(27130):60333/36743]]
描述:
由于可疑验证失败,成员(27134)有被迫离开集群的危险。 在达到ack-wait-threshold之后且经过ack-severe-alert-threshold秒后,将在严重级别发出此警报。
解答:
操作员应检查过程以确定其是否健康。 慢响应者的进程ID在名为ent的机器上是27134。 慢响应者的端口是60333/36743。 查找字符串,Starting distribution manager ent:60333/36743,并检查拥有包含此字符串的日志文件的进程。
警报:
15 sec have elapsed while waiting for replies: <DLockRequestProcessor 33636 waitingfor 1 replies from [ent(4592):33593/35174]> on ent(4592):33593/35174 whose currentmembership list is: [[ent(4598):33610/37013, ent(4611):33599/60008,ent(4592):33593/35174, ent(4600):33612/33183, ent(4593):33601/53393, ent(4605):33605/41831]]
描述:
当锁定授予者未在ack-wait-threshold和ack-severe-alert-threshold内响应锁定请求时,此警报由具有全局范围的分区区域和区域发出。
解答:
无.
警报:
30 sec have elapsed while waiting for replies: <DLockRequestProcessor 23604 waitingfor 1 replies from [ent(4592):33593/35174]> on ent(4598):33610/37013 whose currentmembership list is: [[ent(4598):33610/37013, ent(4611):33599/60008,ent(4592):33593/35174, ent(4600):33612/33183, ent(4593):33601/53393, ent(4605):33605/41831]]
描述:
当锁定授予者未在ack-wait-threshold和ack-severe-alert-threshold内响应锁定请求时,此警报由全局范围处于严重级别的分区区域和区域发出。
解答:
无.
警报:
30 sec have elapsed waiting for global region entry lock held by ent(4600):33612/33183
描述:
当锁定持有者为ack-wait-threshold + ack-severe-alert-threshold秒保持所需锁定并且可能没有响应时,此警报由全局范围处于严重级别的区域发出。
解答:
无.
警报:
30 sec have elapsed waiting for partitioned region lock held by ent(4600):33612/33183
描述:
当锁定持有者为ack-wait-threshold + ack-severe-alert-threshold秒保持所需的锁定并且可能没有响应时,此警报由严重级别的分区区域发出。
解答:
无.
找不到定位器
注意: 使用定位器的所有进程可能会使用相同的消息退出。
警报:
Membership service failure: Channel closed: org.apache.geode.ForcedDisconnectException:There are no processes eligible to be group membership coordinator(last coordinator left view)
描述:
启用网络分区检测,并且存在定位器问题。
解答:
操作员应检查定位器进程和日志,然后重新启动定位器。
警报:
Membership service failure: Channel closed: org.apache.geode.ForcedDisconnectException:There are no processes eligible to be group membership coordinator(all eligible coordinators are suspect)
描述:
启用网络分区检测,并且存在定位器问题。
解答:
操作员应检查定位器进程和日志,然后重新启动定位器。
警报:
Membership service failure: Channel closed: org.apache.geode.ForcedDisconnectException:Unable to contact any locators and network partition detection is enabled
描述:
启用网络分区检测,并且存在定位器问题。
解答:
操作员应检查定位器进程和日志,然后重新启动定位器。
警报:
Membership service failure: Channel closed: org.apache.geode.ForcedDisconnectException:Disconnected as a slow-receiver
描述:
该成员无法足够快地处理消息,并被另一个进程强制断开连接。
解答:
操作员应检查并重新启动断开连接的过程。
删除前的警告通知
警报:
Membership: requesting removal of ent(10344):21344/24922 Disconnected as a slow-receiver
描述:
仅在使用慢速接收器功能时才会生成此警报。
解答:
操作员应检查定位器进程和日志。
警报:
Network partition detection is enabled and both membership coordinator and lead memberare on the same machine
描述:
如果成员协调员和主要成员都在同一台计算机上,则会发出此警报。
解答:
操作员可以通过将系统属性gemfire.disable-same-machine-warnings设置为true来关闭它。 但是,最好在与缓存进程不同的计算机上运行定位器进程,这些进程在启用网络分区检测时充当成员协调器。
成员被迫离开
警报:
Membership service failure: Channel closed: org.apache.geode.ForcedDisconnectException:This member has been forced out of the Distributed System. Please consult GemFire logs tofind the reason.
描述:
该过程发现它不在集群中,无法确定删除的原因。 成员协调员在无法响应内部“你还活着”的消息后删除了该成员。
解答:
操作员应检查定位器进程和日志。
由于内存不足错误导致重新启动失败
本节介绍停止的系统是使用持久性区域配置的系统时可能发生的重新启动失败。 特别:
- 恢复系统的某些区域在运行时被配置为PERSISTENT区域,这意味着它们将数据保存到磁盘。
- 至少一个持久区域被配置为通过将值溢出到磁盘来驱逐最近最少使用(LRU)的数据。
如何从持久区域恢复数据
重启后,数据恢复始终会恢复keys。 您可以配置系统是否以及如何恢复与这些keys关联的值以填充系统缓存。
Value 恢复
- 在启动期间立即恢复所有值会减慢启动时间,但在“热”缓存启动后会产生一致的读取性能。
- 恢复没有值意味着更快启动但是“冷”缓存,因此每个值的第一次检索将从磁盘读取。
- 在后台线程中异步检索值允许在“热”缓存上进行相对快速的启动,最终将恢复每个值。
检索或忽略LRU值
当具有持久LRU区域的系统关闭时,系统不记录最近使用的值。 在后续启动时,如果将值恢复到LRU区域,则它们可能是最近最少使用的而不是最近使用的。 此外,如果在堆或堆外LRU区域上恢复LRU值,则可能会超出LRU内存限制,从而在恢复期间导致OutOfMemoryException。 由于这些原因,LRU值恢复可以与非LRU值不同地处理。
持久区域的默认恢复行为
默认行为是系统恢复所有key,然后异步恢复所有数据值,使LRU值无法恢复。 此默认策略最适合大多数应用程序,因为它在恢复速度和缓存完整性之间取得了平衡。
配置持久区域的恢复
三个Java系统参数允许开发人员控制持久区域的恢复行为:
gemfire.disk.recoverValues
缺省 = true, 恢复值. 如果 false, 仅仅恢复 keys, 不恢复值.
如何使用: 当’true时,值的恢复会“加热”缓存,因此数据检索将在缓存中找到它们的值,而不会导致耗时的磁盘访问。 当'false时,缩短恢复时间,以便系统可以更快地使用,但是每个key的第一次检索将需要磁盘读取。
gemfire.disk.recoverLruValues
缺省 = false, 不恢复 LRU 值. 如果 true, 恢复 LRU 值. 如果gemfire.disk.recoverValues 是 false, 则忽略 gemfire.disk.recoverLruValues ,因为没有恢复值.
如何使用: 当’false时,忽略LRU值会缩短恢复时间。 当true`时,将更多数据值恢复到缓存。 恢复LRU值会增加堆内存使用量,并可能导致内存不足错误,从而阻止系统重新启动。
gemfire.disk.recoverValuesSync
缺省=false,通过异步后台进程恢复值。 如果为true,则同步恢复值,并且在检索到所有值之前恢复不完整。 如果gemfire.disk.recoverValues为’false,则忽略gemfire.disk.recoverValuesSync`,因为没有恢复值。
如何使用: 当false时,允许系统更快地变为可用,但是在将所有值从磁盘读入高速缓冲存储器之前必须经过一段时间。 某些key检索需要磁盘访问,有些则不需要。 当’true`时,延长重启时间,但确保在可用时,缓存完全填充,数据检索时间最佳。
使用自动重新连接处理强制缓存断开连接
如果成员在一段时间内没有响应,或者如果网络分区将一个或多个成员分成太小而不能充当集群的组,则Geode成员可能被强制与Geode集群断开连接。
自动连接过程如何工作
从集群断开连接后,Geode成员将关闭,默认情况下会自动重新启动到“重新连接”状态,同时通过联系已知定位器列表定期尝试重新加入集群。 如果成员成功重新连接到已知定位器,该成员将从现有成员重建其集群视图,并接收新的分布式成员标识。
如果该成员无法连接到已知定位器,则该成员将检查它本身是否是定位器(或托管嵌入式定位器进程)。 如果该成员是定位器,则该成员执行基于仲裁的重新连接; 它将尝试在断开连接之前联系成员视图中的法定成员。 如果可以联系法定数量的成员,则允许开始启动集群。 由于重新连接成员不知道哪些成员在网络分区事件中幸存,因此处于重新连接状态的所有成员将保持其UDP单播端口打开并响应ping请求。
使用网络分区检测中使用的相同成员权重系统来确定成员仲裁。 见成员协调员,牵头成员和成员加权.
请注意,当定位器处于重新连接状态时,它不会为集群提供任何发现服务。
重新连接后重新配置缓存的默认设置假定集群配置服务具有有效(XML)配置。 如果使用API调用配置集群,则情况不会如此。 要处理这种情况,请通过将属性设置为禁用自动重新连接
disable-auto-reconnect = true
或者,通过将属性设置为禁用集群配置服务
enable-cluster-configuration = false
缓存重新连接后,应用程序必须获取对新缓存,区域,DistributedSystem和其他工件的引用。 旧引用将继续抛出取消异常,例如CacheClosedException(cause=ForcedDisconnectException)。
有关更多信息,请参阅GeodeDistributedSystem和Cache Java API文档。
管理自动连接过程
默认情况下,Geode成员将尝试重新连接,直到通过使用DistributedSystem.stopReconnecting()或Cache.stopReconnecting()方法告知它停止。 您可以通过将disable-auto-reconnect Geode属性设置为“true”来完全禁用自动重新连接。
您可以使用DistributedSystem和Cache回调方法在重新连接过程中执行操作,或者在必要时取消重新连接过程。
DistributedSystem和CacheAPI提供了几种方法,您可以在成员重新连接到集群时使用这些方法执行操作:
DistributedSystem.isReconnecting()如果成员在其他成员从系统中删除后重新连接并重新创建缓存,则返回true。DistributedSystem.waitUntilReconnected(long, TimeUnit)等待一段时间,然后返回一个布尔值,以指示该成员是否已重新连接到DistributedSystem。 使用-1秒的值无限期等待,直到重新连接完成或成员关闭。 使用0秒的值作为快速探测以确定成员是否已重新连接。DistributedSystem.getReconnectedSystem()返回重新连接的DistributedSystem。DistributedSystem.stopReconnecting()停止重新连接过程并确保DistributedSystem保持断开连接状态。Cache.isReconnecting()如果缓存尝试重新连接到集群,则返回true。Cache.waitForReconnect(long, TimeUnit)等待一段时间,然后返回一个布尔值,以指示DistributedSystem是否已重新连接。 使用-1秒的值无限期等待,直到重新连接完成或缓存关闭。 使用0秒的值作为快速探测以确定成员是否已重新连接。Cache.getReconnectedCache()返回重新连接的Cache。Cache.stopReconnecting()停止重新连接过程并确保DistributedSystem保持断开连接状态。
操作员干预
如果在网络连接被修复之前进程或硬件崩溃或以其他方式关闭,您可能需要干预自动连接过程。 在这种情况下,处于“重新连接”状态的成员将无法通过UDP探测器找到丢失的进程,并且在他们能够联系定位器之前不会重新加入系统。
从应用程序和缓存服务器崩溃中恢复
当应用程序或缓存服务器崩溃时,其本地缓存将丢失,并且它所拥有的任何资源(例如,分布式锁定)都将被释放。 成员必须在恢复时重新创建其本地缓存。
使用点对点配置从崩溃中恢复
当成员崩溃时,其余成员继续操作,就好像丢失的应用程序或缓存服务器从未存在过一样。 恢复过程因区域类型和范围以及数据冗余配置而异。
使用客户端/服务器配置从崩溃中恢复
在客户端/服务器配置中,首先使服务器再次作为集群的成员可用,然后尽快重新启动客户端。 客户端通过正常操作从其服务器恢复其数据。
使用点对点配置从崩溃中恢复
当成员崩溃时,其余成员继续操作,就好像丢失的应用程序或缓存服务器从未存在过一样。 恢复过程因区域类型和范围以及数据冗余配置而异。
其他系统成员被告知它已意外离开。 如果任何剩余的系统成员正在等待响应(ACK),则ACK仍然成功并返回,因为仍处于活动状态的每个成员都已响应。 如果丢失的成员拥有GLOBAL条目的所有权,则下一次获得该所有权的尝试就像没有所有者一样。
恢复取决于成员如何配置其缓存。 本节包括以下内容:
- 分区区域的恢复
- 分布式区域的恢复
- 局部范围区域的恢复
- 从磁盘恢复数据
要判断区域是分区的,分布式的还是本地的,请检查cache.xml文件。 如果文件包含本地范围设置,则该区域与任何其他成员都没有连接:
<region-attributes scope="local">
如果文件包含任何其他范围设置,则它正在配置分布式区域。 例如:
<region-attributes scope="distributed-no-ack">
如果文件包含以下任一行,则表示正在配置分区区域。
<partition-attributes...<region-attributes data-policy="partition"/><region-attributes data-policy="persistent-partition"/>
重新分配的客户端继续顺利运行,如故障转移情况。 成功的重新平衡操作不会造成任何数据丢失。
如果重新平衡失败,则客户端将故障转移到具有正常故障转移行为的活动服务器。
使用客户端/服务器配置从崩溃中恢复
在客户端/服务器配置中,首先使服务器再次作为集群的成员可用,然后尽快重新启动客户端。 客户端通过正常操作从其服务器恢复其数据。
客户端/服务器配置从应用程序或缓存服务器崩溃中恢复的程度取决于服务器可用性和客户端配置。通常,通过在足够的机器上运行足够的服务器来使服务器高度可用,以确保在网络,机器或服务器崩溃的情况下最小的覆盖范围。客户端通常配置为连接到主服务器和一些辅助服务器或冗余服务器。辅助服务器充当主服务器的热备份。对于客户端崩溃情况下的高可用性消息传递,客户端可能与其服务器具有持久连接。如果是这种情况,则部分或全部数据和数据事件将保留在服务器内存中并自动恢复,前提是您在配置的超时内重新启动客户端。有关持久消息传递的信息,请参阅配置客户端/服务器事件消息传递。
从服务器故障中恢复
从服务器故障中恢复有两部分:服务器恢复为集群成员,然后其客户端恢复其服务。
当服务器发生故障时,将按照使用对等配置从崩溃中恢复中所述对集群的任何成员执行自己的恢复。
从客户端的角度来看,如果系统配置为高可用性,则服务器故障不会被检测到,除非有足够的服务器发生故障,服务器到客户端的比率低于可行的水平。 无论如何,您的第一个行动方案是尽快恢复服务器。
要从服务器故障中恢复:
- 按照使用对等配置从崩溃中恢复中的描述恢复服务器及其数据。
- 一旦服务器再次可用,定位器(或客户端池,如果您使用的是静态服务器列表)会自动检测其存在并将其添加到可行服务器列表中。 客户端可能需要一段时间才能开始使用已恢复的服务器。 时间部分取决于客户端的配置方式和编程方式。 请参阅客户端/服务器配置。
如果需要在新的主机/端口位置启动服务器
本节仅适用于客户端的服务器池配置使用静态服务器列表的系统。 这很不寻常,但您的系统可能就是这种情况。 如果服务器池配置为没有静态服务器列表,意味着客户端使用定位器来查找其服务器,则在新地址启动服务器不需要特殊操作,因为定位器会自动检测到新服务器。 您可以通过查看客户端cache.xml文件来确定客户端是使用定位器列表还是服务器列表。 使用静态服务器列表配置的系统在
如果池配置了静态服务器列表,则客户端仅连接到列表中提供的特定地址的服务器。 要在新位置移动服务器或添加服务器,必须修改客户端的cache.xml文件中的
从客户端故障中恢复
当客户端崩溃时,以通常的方式尽快重新启动它。 客户端通过正常操作从其服务器恢复其数据。 一些数据可能会立即恢复,有些数据可能会在客户端请求时懒得恢复。 另外,服务器可以被配置为重放某些数据和某些客户端查询的事件。 这些是影响客户端恢复的不同配置:
- 条目立即发送给客户—如果这些条目存在于服务器缓存中,则会立即将条目发送到客户端以查找客户端注册的条目。
- 条目懒惰地发送给客户—条目被懒惰地发送到客户端,用于客户端注册的对于服务器高速缓存中最初不可用的条目。
- 事件立即发送给客户端—如果服务器一直在为客户端保存事件,则在客户端重新连接时会立即重播这些事件。 保存客户端已注册持久兴趣的条目的缓存修改事件。
如果您将持久客户端配置为连接到多个服务器,请记住,在客户端断开连接时,Geode不会维护服务器冗余。 如果丢失了所有主服务器和辅助服务器,则会丢失客户端的排队消息。 即使服务器一次失败一个,以便运行的客户端有时间进行故障转移并选择新的辅助服务器,离线持久客户端也无法做到这一点,从而丢失其排队的消息。
从机器崩溃中恢复
当计算机因关闭,断电,硬件故障或操作系统故障而崩溃时,其所有应用程序和缓存服务器及其本地缓存都将丢失。
其他计算机上的系统成员会收到通知,说明此计算机的成员已意外离开集群。
恢复程序
要从机器崩溃中恢复:
- 确定在此计算机上运行的进程。
- 重新启动机器。
- 如果Geode定位器在此处运行,请先启动它。 注意: 在启动任何应用程序或缓存服务器之前,必须至少运行一个定位器。
- 按常规顺序启动应用程序和缓存服务器。
如果必须将定位器进程移动到其他计算机,则在更新gemfire.properties文件中的定位器列表并重新启动集群中的所有应用程序和缓存服务器之前,定位器无用。 但是,如果其他定位器正在运行,则不必立即重新启动系统。 有关正在使用的定位器的列表,请检查其中一个应用程序gemfire.properties文件中的locators属性。
分区区域的数据恢复
无论数据存储重新加入的顺序如何,分区区域都会正确初始化。 应用程序和缓存服务器在返回活动工作时会自动重新创建数据。
如果分区区域配置为数据冗余,则Geode可以自动处理机器崩溃而不会丢失数据,具体取决于有多少冗余副本以及必须重新启动的成员数。 另请参见分区区域恢复.
如果分区区域没有冗余副本,则系统成员通过正常操作重新创建数据。 如果崩溃的成员是应用程序,请检查它是否设计为将其数据写入外部数据源。 如果是,请确定是否可以进行数据恢复,并且最好是从通过Geode集群生成的新数据开始。
分布式区域的数据恢复
应用程序和缓存服务器会自动重新创建数据。 通过副本,磁盘存储文件或新生成的数据进行恢复,如分布式区域恢复中所述。
如果恢复来自磁盘存储,则可能无法获取所有最新数据。 持久性取决于操作系统将数据写入磁盘,因此当计算机或操作系统意外失败时,最后的更改可能会丢失。
为了获得最大程度的数据保护,您可以在网络上设置重复的复制区域,每个复制区域都配置为将其数据备份到磁盘。 假设正确的重启顺序,这种架构显着增加了恢复每次更新的机会。
客户端/服务器配置中的数据恢复
如果崩溃的机器托管了服务器,则服务器如何恢复其数据取决于区域是分区还是分布。 请参阅分区区域的数据恢复和分布式区域的数据恢复视情况而定。
服务器崩溃对其客户端的影响取决于是否为高可用性服务器配置了安装。 有关信息,请参阅使用客户端/服务器配置从崩溃中恢复。
如果崩溃的计算机托管了客户端,请尽快重新启动客户端,并让它从服务器自动恢复其数据。 有关详细信息,请参阅从客户端故障中恢复。
从ConfictingPersistentDataExceptions中恢复
启动持久成员时出现ConflictingPersistentDataException表示您有一些持久数据的多个副本,并且Geode无法确定要使用哪个副本。
通常,Geode使用元数据自动确定要使用的持久数据副本。 除了区域数据外,每个成员还会保留托管该区域的其他成员列表以及他们的数据是否是最新的。 当两个成员比较它们的元数据并发现它不一致时,会发生ConflictingPersistentDataException。 成员要么彼此不了解,要么他们都认为其他成员有陈旧数据。
以下部分描述了可能导致Geode中出现ConflictingPersistentDataException以及如何解决冲突的场景。
独立创建的副本
尝试将两个独立创建的集群合并到一个集群中将导致ConflictingPersistentDataException。
有几种方法可以结束独立创建的系统。
- 通过让成员连接到彼此不了解的不同定位器来创建两个不同的集群。
- 关闭所有持久成员,然后启动一组不同的全新持久成员。
Geode不会自动合并同一区域的独立创建数据。 相反,您需要从其中一个系统导出数据并将其导入另一个系统。 有关如何从一个系统导出数据并将其导入的信息,请参阅缓存和区域快照 。
首先开始新成员
在使用持久数据启动旧成员之前启动没有持久数据的全新成员可能会导致ConflictingPersistentDataException。
这可能发生的一种偶然方式是关闭系统,向启动脚本添加新成员,并并行启动所有成员。 偶然的机会,新成员可能会先开始。 问题是新成员将在旧成员启动之前创建一个空的,独立的数据副本。 Geode会像独立创建的副本一样处理这种情况。
在这种情况下,修复只是移动或删除新成员的持久文件,关闭新成员,然后重新启动旧成员。 当旧成员完全恢复时,重新启动新成员。
发生网络故障并禁用网络分区检测
当enable-network-partition-detection设置为默认值true时,Geode将检测网络分区并关闭无法访问的成员,以防止发生网络分区(“裂脑”)。 系统愈合时不会发生冲突。
但是,如果enable-network-partition-detection为false,Geode将不会检测到网络分区。 相反,网络分区的每一端最终都会记录分区的另一侧有陈旧数据。 当分区被修复并且持久成员重新启动时,成员将报告冲突,因为分区的两侧都认为其他成员是陈旧的。
在某些情况下,可以在网络分区的各边之间进行选择,只需从分区的一侧保留数据即可。 否则,您可能需要抢救数据并将其导入新系统。
抢救数据
如果收到ConflictingPersistentDataException,您将无法启动所有成员并让它们加入同一个集群。 您有一些成员有冲突的数据。
首先,查看是否有部分系统可以恢复。 例如,如果您刚刚向系统添加了一些新成员,请尝试启动而不包括这些成员。
对于其余成员,您可以从这些成员上的持久性文件中提取数据并导入数据。
要从持久性文件中提取数据,请使用gfsh export offline-disk-store命令。
gfsh> export offline-disk-store --name=MyDiskStore --disk-dirs=./mydir --dir=./outputdir
这将生成一组快照文件。 可以使用以下命令将这些快照文件导入到正在运行的系统中:
gfsh> import data --region=/myregion --file=./outputdir/snapshot-snapshotTest-test0.gfd --member=server1
防止和恢复磁盘完全错误
监视Geode成员的磁盘使用情况非常重要。 如果成员缺少足够的磁盘空间用于磁盘存储,则该成员会尝试关闭磁盘存储及其关联的缓存,并记录错误消息。 由于成员磁盘空间不足而导致的关闭可能导致数据丢失,数据文件损坏,日志文件损坏以及可能对您的应用程序产生负面影响的其他错误情况。
为成员提供足够的磁盘空间后,可以重新启动该成员。
您可以使用以下技术防止磁盘文件错误:
- 如果您使用的是ext4文件系统,我们建议您预先分配磁盘存储文件和磁盘存储元数据文件。 预分配为这些文件保留磁盘空间,并在磁盘存储区和区域关闭时使成员处于正常状态,允许您在足够的磁盘空间可用后重新启动成员。 默认情况下启用预分配。
- 配置磁盘的关键使用阈值(磁盘使用警告百分比和磁盘使用关键百分比)。 默认情况下,这些设置为90%用于警告,99%用于关闭缓存的错误。
- 按照使用磁盘存储优化系统 中的建议,了解常规磁盘管理最佳做法。
当磁盘写入因磁盘已满而导致失败时,该成员将关闭并从集群中删除。
从磁盘完全错误中恢复
如果集群成员由于磁盘已满磁盘故障而失败,请添加或使其他磁盘容量可用,并尝试正常重新启动该成员。 如果该成员未重新启动并且其他成员上的磁盘存储中存在其区域的冗余副本,则可以使用以下步骤还原该成员:
- 从失败的成员中删除或移动磁盘存储文件。
- 使用gfsh
show missing-disk-stores命令识别任何丢失的数据。 您可能需要手动还原此数据。 - 使用revoke missing-disk-storegfsh命令撤消丢失的磁盘存储。
- 重启成员。
有关详细信息,请参阅处理丢失的磁盘存储 。
理解和恢复网络中断
对网络中断的最安全响应是重新启动所有进程并调出新数据集。
但是,如果您很好地了解系统的体系结构,并且确定不会恢复旧数据,则可以选择性地重新启动。 至少,您必须重新启动网络故障一侧的所有成员,因为网络中断会导致无法自动重新加入的单独集群。
网络中断期间会发生什么
当连接集群成员的网络出现故障时,系统成员会将此视为机器崩溃。 网络故障每一方的成员通过从成员列表中删除另一方的成员来做出响应。 如果启用了网络分区检测(默认设置),则包含足够仲裁(基于成员权重的大于51%)的分区将继续运行,而具有足够仲裁的其他分区将关闭。 有关此检测系统如何运行的详细说明,请参阅网络分区。
此外,通过网络分区或由于无响应而断开连接的成员将自动尝试重新连接到集群,除非另有配置。 请参阅使用自动重新连接处理强制缓存断开连接。
恢复程序
对于禁用网络分区检测和/或自动重新连接的部署,要从网络中断中恢复:
- 根据集群的体系结构确定要重新启动的应用程序和缓存服务器。 假设除数据源之外的任何进程都很糟糕,需要重新启动。 例如,如果外部数据馈送进入一个成员,然后将其重新分发给所有其他成员,则可以使该进程保持运行并重新启动其他成员。
- 关闭所有需要重新启动的进程。
- 按通常顺序重新启动它们。
成员在返回活动工作时重新创建数据。 有关详细信息,请参阅从应用程序和缓存服务器崩溃中恢复。
网络故障对分区域的影响
集群的两端继续运行,就好像另一侧的成员没有运行一样。 如果参与分区区域的成员位于网络故障的两侧,则分区区域的两侧也继续运行,就好像另一侧的数据存储不存在一样。 实际上,您现在有两个分区区域。
当网络恢复时,成员可能能够再次看到对方,但是他们无法一起合并到一个集群中并将他们的桶组合回一个分区区域。 您可以确定数据处于不一致状态。 无论您是否配置了数据冗余,您都不知道丢失了哪些数据,哪些数据没有丢失。 即使您有冗余副本并且它们幸存下来,条目的不同副本可能具有反映中断的工作流程和不可访问数据的不同值。
网络故障对分布式区域的影响
默认情况下,集群的两端继续运行,就好像另一侧的成员未运行一样。 但是,对于分布式区域,区域的可靠性策略配置可以更改此默认行为。
当网络恢复时,成员可能能够再次看到对方,但是他们无法一起合并到单个集群中。
网络故障对持久性区域的影响
使用持久性区域时网络故障可能会导致持久数据发生冲突。 恢复系统时,成员启动时可能会遇到ConflictingPersistentDataException。
因此,如果使用持久性区域,则必须将enable-network-partition-detection设置为true。
有关如何从ConflictingPersistentDataException错误中恢复的信息,请参阅从ConfictingPersistentDataExceptions中恢复。
网络故障对客户端/服务器安装的影响
如果客户端失去与其所有服务器的联系,则效果与崩溃时的效果相同。 您需要重新启动客户端。 请参阅从客户端故障中恢复。 如果客户端与某些服务器(但不是所有服务器)失去联系,则对客户端的影响与无法访问的服务器崩溃时的影响相同。 请参阅从服务器故障中恢复。
服务器(如应用程序)是集群的成员,因此网络故障对服务器的影响与应用程序相同。 究竟发生了什么取决于您的网站的配置。

若有收获,就点个赞吧
0 人点赞
