Producer
数据生产流程分析
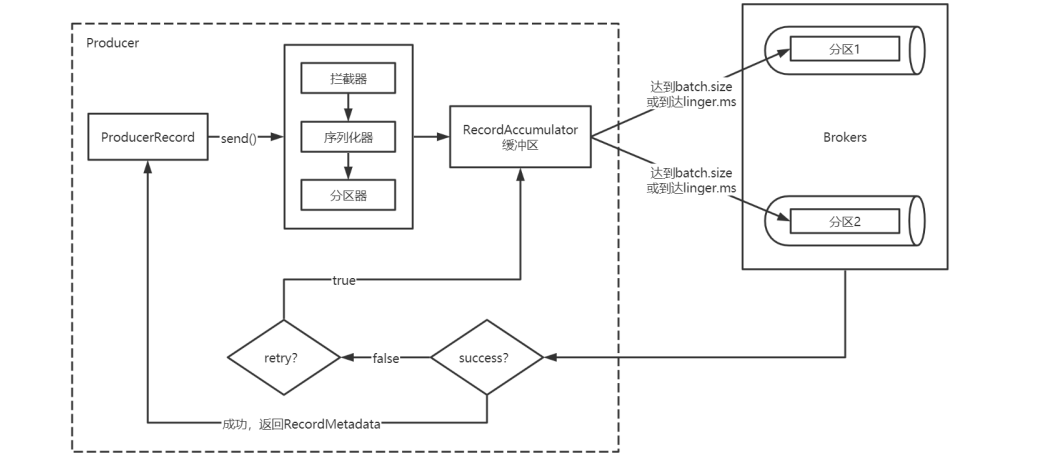
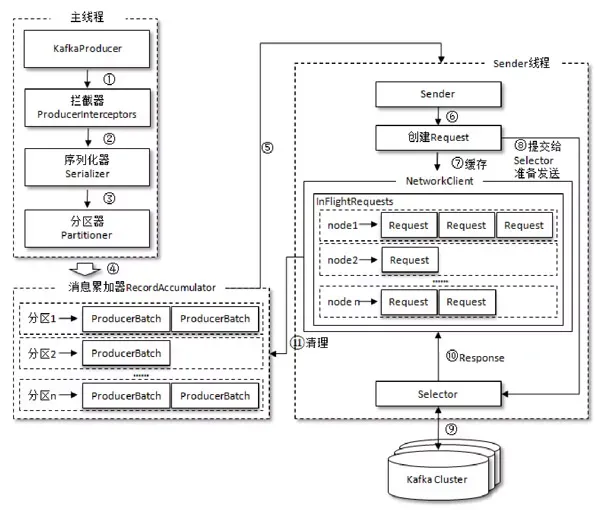
- Producer创建时,会创建一个Sender线程并设置为守护线程。
- 生产消息时,内部其实是异步流程;生产的消息先经过拦截器->序列化器->分区器,然后将消
息缓存在缓冲区(该缓冲区也是在Producer创建时创建)。 - 批次发送的条件为:缓冲区数据大小达到batch.size或者linger.ms达到上限,哪个先达到就算
哪个。 - 批次发送后,发往指定分区,然后落盘到broker;如果生产者配置了retrires参数大于0并且失
败原因允许重试,那么客户端内部会对该消息进行重试。 - 落盘到broker成功,返回生产元数据给生产者。
- 元数据返回有两种方式:一种是通过阻塞直接返回,另一种是通过回调返回。
必要参数解析
Map<String,Object> configs = new HashMap<String, Object>();// 设置连接Kafka的初始连接用到的服务器地址// 如果是集群,可以通过此初始连接发现集群中的其他broke,// 但最好配置单数以上,防止连接的Broke在启动是方剂configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.196.8.204:9092");// 设置key序列化器configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,IntegerSerializer.class);// 设置value序列化器configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);// acks确认机制configs.put(ProducerConfig.ACKS_CONFIG,"-1");// 重试次数configs.put(ProducerConfig.RETRIES_CONFIG,"1");KafkaProducer<Integer,String> kafkaProducer = new KafkaProducer<Integer, String>(configs);
| 参数 | 解析 |
|---|---|
| bootstrap.servers | 生产者客户端与broker集群建立初始连接需要的broker地址列表,由 该初始连接发现Kafka集群中其他的所有broker。该地址列表不需要 写全部的Kafka集群中broker的地址,但也不要写一个,以防该节点 宕机的时候不可用。形式为:host1:port1,host2:port2,… . |
| key.serializer | 实现了接口org.apache.kafka.common.serialization.Serializer的key序 列化类。 |
| value.serializer | 实现了接口org.apache.kafka.common.serialization.Serializer的value 序列化类。 |
| acks |
该选项控制着已发送消息的持久性。 acks=0:生产者不等待broker的任何消息确认。只要将消息放到了 socket的缓冲区,就认为消息已发送。不能保证服务器是否收到该消 息,retries设置也不起作用,因为客户端不关心消息是否发送失 败。客户端收到的消息偏移量永远是-1。 acks=1:leader将记录写到它本地日志,就响应客户端确认消息, 而不等待follower副本的确认。如果leader确认了消息就宕机,则可 能会丢失消息,因为follower副本可能还没来得及同步该消息。 acks=all:leader等待所有同步的副本(ISR)确认该消息。保证了只要有 一个同步副本存在,消息就不会丢失。这是最强的可用性保证。等价 于acks=-1。默认值为1,字符串。可选值:[all, -1, 0, 1] |
| compression.type |
生产者生成数据的压缩格式。默认是none(没有压缩)。允许的 值:none,gzip,snappy和lz4。压缩是对整个消息批次来讲 的。消息批的效率也影响压缩的比例。消息批越大,压缩效率越好。 字符串类型的值。默认是none |
| retries |
设置该属性为一个大于1的值,将在消息发送失败的时候重新发送消 息。该重试与客户端收到异常重新发送并无二至。允许重试但是不设 置max.in.flight.requests.per.connection为1,存在消息乱序 的可能,因为如果两个批次发送到同一个分区,第一个失败了重试, 第二个成功了,则第一个消息批在第二个消息批后。int类型的值,默 认:0,可选值:[0,…,2147483647] |
序列化器
为什么需要序列化 ?
在 TCP 的连接上,它传输数据的基本形式就是二进制流,也就是一段一段的 1 和 0。在一般编程语言或者网络框架提供的 API 中,传输数据的基本形式是字节,也就是 Byte。<极客时间>
对于在应用中,我们需要传输的结构化数据(一个类(Class) 或 一个结构体(Struct))。
所以要想使用网络框架的 API 来传输结构化的数据,必须得先实现结构化的数据与字节流之间的双向转换。这种将结构化数据转换成字节流的过程,我们称为序列化,反过来转换,就是反序列化。
简单一句话来说 : 序列化与反序列化。就是将结构化转化为可在网络中传输的二进制流.
序列化的用途除了用于在网络上传输数据以外,另外的一个重要用途是,将结构化数据保存在文件中,因为在文件内保存数据的形式也是二进制序列,和网络传输过程中的数据是一样的,所以序列化同样适用于将结构化数据保存在文件中。(优点 :长期保存不丢失,减少占用的内存空间)
Kafak的序列化
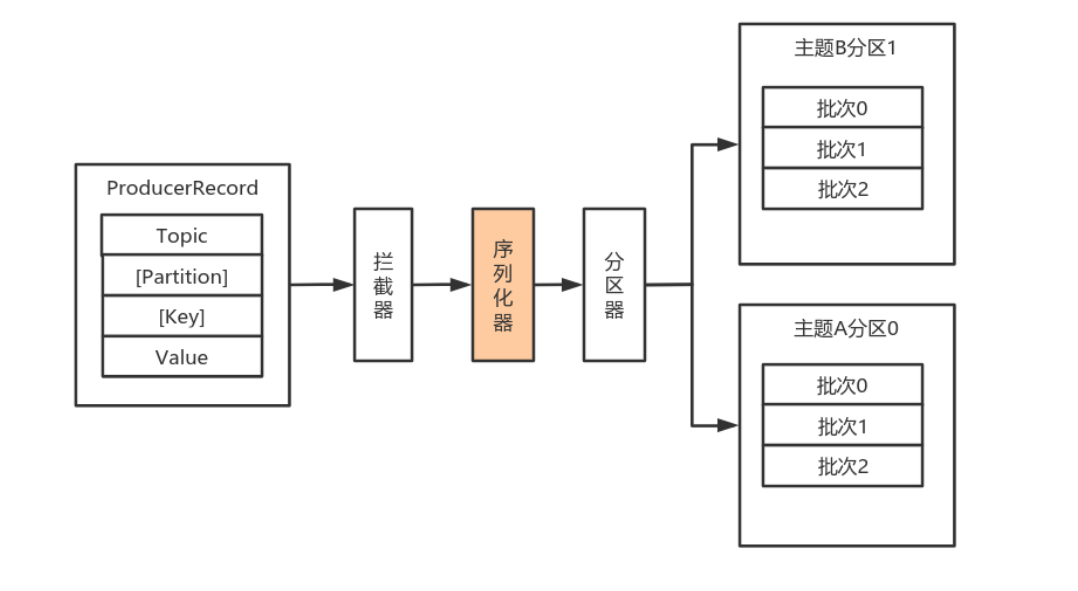
由于Kafka中的数据都是字节数组,在将消息发送到Kafka之前需要先将数据序列化为字节数组。
序列化器的作用就是用于序列化要发送的消息的。
如何进行序列化?
Kafka使用 org.apache.kafka.common.serialization.Serializer 接口用于定义序列化器,将
泛型指定类型的数据转换为字节数组 。
//// Source code recreated from a .class file by IntelliJ IDEA// (powered by Fernflower decompiler)//package org.apache.kafka.common.serialization;import java.io.Closeable;import java.util.Map;import org.apache.kafka.common.header.Headers;/*** 将对象转换为byte数组的接口* 该接口的实现类需要提供无参构造器* @param <T> 从哪个类型转换*/public interface Serializer<T> extends Closeable {/*** 类的配置信息* @param configs key/value pairs* @param isKey key的序列化还是value的序列化*/default void configure(Map<String, ?> configs, boolean isKey) {}byte[] serialize(String var1, T var2);/*** 将对象转换为字节数组* @param topic 主题名称* @param data 需要转换的对象* @return 序列化的字节数组*/default byte[] serialize(String topic, Headers headers, T data) {return this.serialize(topic, data);}/*** 关闭序列化器* 该方法需要提供幂等性,因为可能调用多次。*/default void close() {}}

若有收获,就点个赞吧
0 人点赞
