本文首发于泊浮目的专栏:https://segmentfault.com/blog/camile
| 版本 | 日期 | 备注 |
|---|---|---|
| 1.0 | 2017.12.10 | 文章首发 |
| 1.1 | 2020.9.6 | 根据缺陷提出一些可参考的解决方案 |
| 1.2 | 2021.7.13 | 增加示意图 |
| 1.3 | 2021.8.10 | 更新改进方案 |
前言
在ZStack中,最基本的执行单位不仅仅是一个函数,也可以是一个任务(Task。其本质实现了Java的Callable接口)。通过大小合理的线程池调度来并行的消费这些任务,使ZStack这个Iaas软件有条不紊运行在大型的数据中心里。
对线程池不太了解的同学可以先看我的一篇博客:Java多线程笔记(三):线程池
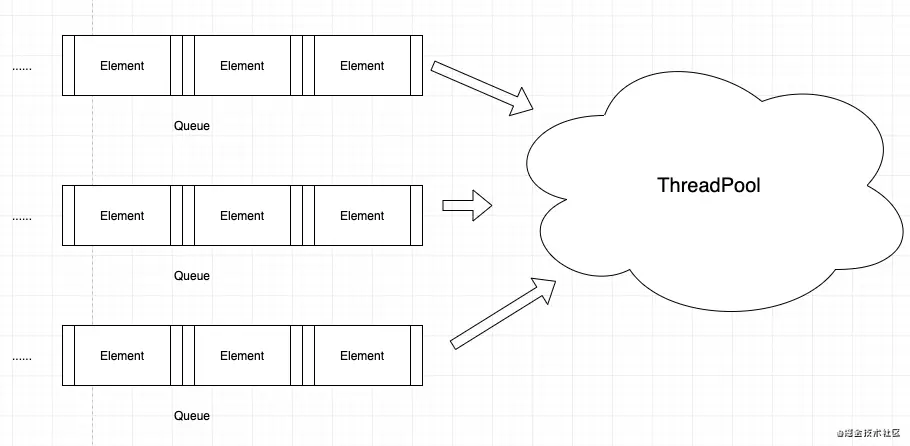
演示代码
在这里,将以ZStack中ThreadFacade最常用的方法为例进行演示。
syncSubmit
提交同步任务,线程将会等结果完成后才继续下一个任务。
这里先参考ZStack中ApiMediatorImpl ,其中有一段用于API消息调度的逻辑。
@Overridepublic void handleMessage(final Message msg) {thdf.syncSubmit(new SyncTask<Object>() {@Overridepublic String getSyncSignature() {return "api.worker";}@Overridepublic int getSyncLevel() {return apiWorkerNum;}@Overridepublic String getName() {return "api.worker";}@MessageSafepublic void handleMessage(Message msg) {if (msg instanceof APIIsReadyToGoMsg) {handle((APIIsReadyToGoMsg) msg);} else if (msg instanceof APIGetVersionMsg) {handle((APIGetVersionMsg) msg);} else if (msg instanceof APIGetCurrentTimeMsg) {handle((APIGetCurrentTimeMsg) msg);} else if (msg instanceof APIMessage) {dispatchMessage((APIMessage) msg);} else {logger.debug("Not an APIMessage.Message ID is " + msg.getId());}}@Overridepublic Object call() throws Exception {handleMessage(msg);return null;}});}
每个API消息都会被一个线程消费,同时最大并发量为5(apiWorkerNum=5)。每个线程都会等着API消息的回复,等到回复后便给用户。
chainSubmit
提交异步任务,这里的任务执行后将会执行队列中的下一个任务,不会等待结果。
参考VmInstanceBase关于虚拟机启动、重启、暂停相关的代码:
//暂停虚拟机protected void handle(final APIStopVmInstanceMsg msg) {thdf.chainSubmit(new ChainTask(msg) {@Overridepublic String getName() {return String.format("stop-vm-%s", self.getUuid());}@Overridepublic String getSyncSignature() {return syncThreadName;}@Overridepublic void run(SyncTaskChain chain) {stopVm(msg, chain);}});}//重启虚拟机protected void handle(final APIRebootVmInstanceMsg msg) {thdf.chainSubmit(new ChainTask(msg) {@Overridepublic String getName() {return String.format("reboot-vm-%s", self.getUuid());}@Overridepublic String getSyncSignature() {return syncThreadName;}@Overridepublic void run(SyncTaskChain chain) {rebootVm(msg, chain);}});}//启动虚拟机protected void handle(final APIStartVmInstanceMsg msg) {thdf.chainSubmit(new ChainTask(msg) {@Overridepublic String getName() {return String.format("start-vm-%s", self.getUuid());}@Overridepublic String getSyncSignature() {return syncThreadName;}@Overridepublic void run(SyncTaskChain chain) {startVm(msg, chain);}});}
通用特性
getSyncSignature则指定了其队列的key,这个任务队列本质一个Map。根据相同的k,将任务作为v按照顺序放入map执行。单从这里的业务逻辑来看,可以有效避免虚拟机的状态混乱。
chainTask的默认并发度为1,这意味着它是同步的。在稍后的源码解析中我们将会看到。
它的实现
先从接口ThreadFacade了解一下方法签名:
public interface ThreadFacade extends Component {<T> Future<T> submit(Task<T> task);//提交一个任务<T> Future<T> syncSubmit(SyncTask<T> task); //提交一个有返回值的任务Future<Void> chainSubmit(ChainTask task); //提交一个没有返回值的任务Future<Void> submitPeriodicTask(PeriodicTask task, long delay); //提交一个周期性任务,将在一定时间后执行Future<Void> submitPeriodicTask(PeriodicTask task); //提交一个周期性任务Future<Void> submitCancelablePeriodicTask(CancelablePeriodicTask task); //提交一个可以取消的周期性任务Future<Void> submitCancelablePeriodicTask(CancelablePeriodicTask task, long delay); //提交一个可以取消的周期性任务,将在一定时间后执行void registerHook(ThreadAroundHook hook); //注册钩子void unregisterHook(ThreadAroundHook hook); //取消钩子ThreadFacadeImpl.TimeoutTaskReceipt submitTimeoutTask(Runnable task, TimeUnit unit, long delay); //提交一个过了一定时间就算超时的任务void submitTimerTask(TimerTask task, TimeUnit unit, long delay); //提交一个timer任务}
以及几个方法逻辑实现类DispatchQueueImpl中的几个成员变量。
private static final CLogger logger = Utils.getLogger(DispatchQueueImpl.class);@AutowiredThreadFacade _threadFacade;private final HashMap<String, SyncTaskQueueWrapper> syncTasks = new HashMap<String, SyncTaskQueueWrapper>();private final HashMap<String, ChainTaskQueueWrapper> chainTasks = new HashMap<String, ChainTaskQueueWrapper>();private static final CLogger _logger = CLoggerImpl.getLogger(DispatchQueueImpl.class);public static final String DUMP_TASK_DEBUG_SINGAL = "DumpTaskQueue";
关键就是syncTasks(同步队列)和chainTasks(异步队列) ,用于存储两种类型的任务队列。
因此当我们提交chainTask时,要注意记得显示的调用next方法,避免后面的任务调度不到。
接着,我们从最常用的几个方法开始看它的代码。
chainSubmit方法
从ThreadFacadeImpl作为入口
@Overridepublic Future<Void> chainSubmit(ChainTask task) {return dpq.chainSubmit(task);}
DispatchQueue中的逻辑
//公有方法,即入口之一@Overridepublic Future<Void> chainSubmit(ChainTask task) {return doChainSyncSubmit(task);}
//内部逻辑private <T> Future<T> doChainSyncSubmit(final ChainTask task) {assert task.getSyncSignature() != null : "How can you submit a chain task without sync signature ???";DebugUtils.Assert(task.getSyncLevel() >= 1, String.format("getSyncLevel() must return 1 at least "));synchronized (chainTasks) {final String signature = task.getSyncSignature();ChainTaskQueueWrapper wrapper = chainTasks.get(signature);if (wrapper == null) {wrapper = new ChainTaskQueueWrapper();chainTasks.put(signature, wrapper);}ChainFuture cf = new ChainFuture(task);wrapper.addTask(cf);wrapper.startThreadIfNeeded();return cf;}}
这段逻辑大致为:
- 断言syncSignature不为空,并且必须并行度必须大于等于1。因为1会被做成队列,由一个线程完成这些任务。而1以上则指定了可以有几个线程来完成同一个
signature的任务。 - 加锁
HashMap<String, ChainTaskQueueWrapper> chainTasks,尝试取出相同signature的队列。如果没有则新建一个相关signature的队列,并初始化这个队列的线程数量和它的signature。无论如何,要将这个任务放置队列。 - 接下来就是
startThreadIfNeeded。所谓ifNeeded就是指给这个队列的线程数尚有空余。然后提交一个任务到线程池中,这个任务的内容是:从等待队列中取出一个Feture,如果等待队列为空,则删除这个等待队列的Map。
private class ChainTaskQueueWrapper {LinkedList pendingQueue = new LinkedList();final LinkedList runningQueue = new LinkedList();AtomicInteger counter = new AtomicInteger(0);int maxThreadNum = -1;String syncSignature;void addTask(ChainFuture task) {pendingQueue.offer(task);if (maxThreadNum == -1) {maxThreadNum = task.getSyncLevel();}if (syncSignature == null) {syncSignature = task.getSyncSignature();}}void startThreadIfNeeded() {//如果运行线程数量已经大于等于限制,不startif (counter.get() >= maxThreadNum) {return;}counter.incrementAndGet();_threadFacade.submit(new Task<Void>() {@Overridepublic String getName() {return "sync-chain-thread";}// start a new thread every time to avoid stack overflow@AsyncThreadprivate void runQueue() {ChainFuture cf;synchronized (chainTasks) {// remove from pending queue and add to running queue latercf = (ChainFuture) pendingQueue.poll();if (cf == null) {if (counter.decrementAndGet() == 0) {//并且线程只有一个(跑完就没了),则将相关的signature队列移除,避免占用内存chainTasks.remove(syncSignature);}//如果为空,则没有任务,返回return;}}synchronized (runningQueue) {// add to running queuerunningQueue.offer(cf);}//完成以后将任务挪出运行队列cf.run(new SyncTaskChain() {@Overridepublic void next() {synchronized (runningQueue) {runningQueue.remove(cf);}runQueue();}});}//这个方法将会被线程池调用,作为入口@Overridepublic Void call() throws Exception {runQueue();return null;}});}}
syncSubmit方法
syncSubmit的内部逻辑与我们之前分析的chainSubmit极为相似,只是放入了不同的队列中。
同样,也是从ThreadFacadeImpl作为入口
@Overridepublic <T> Future<T> syncSubmit(SyncTask<T> task) {return dpq.syncSubmit(task);}
然后是DispatchQueue中的实现
@Overridepublic <T> Future<T> syncSubmit(SyncTask<T> task) {if (task.getSyncLevel() <= 0) {return _threadFacade.submit(task);} else {return doSyncSubmit(task);}}
内部逻辑-私有方法
private <T> Future<T> doSyncSubmit(final SyncTask<T> syncTask) {assert syncTask.getSyncSignature() != null : "How can you submit a sync task without sync signature ???";SyncTaskFuture f;synchronized (syncTasks) {SyncTaskQueueWrapper wrapper = syncTasks.get(syncTask.getSyncSignature());if (wrapper == null) {wrapper = new SyncTaskQueueWrapper();//放入syncTasks队列。syncTasks.put(syncTask.getSyncSignature(), wrapper);}f = new SyncTaskFuture(syncTask);wrapper.addTask(f);wrapper.startThreadIfNeeded();}return f;}
submitPeriodicTask
提交一个定时任务本质上是通过了线程池的scheduleAtFixedRate来实现。这个方法用于对任务进行周期性调度,任务调度的频率是一定的,它以上一个任务开始执行时间为起点,之后的period时间后调度下一次任务。如果任务的执行时间大于调度时间,那么任务就会在上一个任务结束后,立即被调用。
调用这个方法时将会把任务放入定时任务队列。当任务出现异常时,将会取消这个Futrue,并且挪出队列。
public Future<Void> submitPeriodicTask(final PeriodicTask task, long delay) {assert task.getInterval() != 0;assert task.getTimeUnit() != null;ScheduledFuture<Void> ret = (ScheduledFuture<Void>) _pool.scheduleAtFixedRate(new Runnable() {public void run() {try {task.run();} catch (Throwable e) {_logger.warn("An unhandled exception happened during executing periodic task: " + task.getName() + ", cancel it", e);final Map<PeriodicTask, ScheduledFuture<?>> periodicTasks = getPeriodicTasks();final ScheduledFuture<?> ft = periodicTasks.get(task);if (ft != null) {ft.cancel(true);periodicTasks.remove(task);} else {_logger.warn("Not found feature for task " + task.getName()+ ", the exception happened too soon, will try to cancel the task next time the exception happens");}}}}, delay, task.getInterval(), task.getTimeUnit());_periodicTasks.put(task, ret);return ret;}
submitCancelablePeriodicTask
而submitCancelablePeriodicTask则是会在执行时检测ScheduledFuture是否被要求cancel,如果有要求则取消。
@Overridepublic Future<Void> submitCancelablePeriodicTask(final CancelablePeriodicTask task, long delay) {ScheduledFuture<Void> ret = (ScheduledFuture<Void>) _pool.scheduleAtFixedRate(new Runnable() {private void cancelTask() {ScheduledFuture<?> ft = cancelablePeriodicTasks.get(task);if (ft != null) {ft.cancel(true);cancelablePeriodicTasks.remove(task);} else {_logger.warn("cannot find feature for task " + task.getName()+ ", the exception happened too soon, will try to cancel the task next time the exception happens");}}public void run() {try {boolean cancel = task.run();if (cancel) {cancelTask();}} catch (Throwable e) {_logger.warn("An unhandled exception happened during executing periodic task: " + task.getName() + ", cancel it", e);cancelTask();}}}, delay, task.getInterval(), task.getTimeUnit());cancelablePeriodicTasks.put(task, ret);return ret;}
初始化操作
不同与通常的ZStack组件,它虽然实现了Component接口。但是其start中的逻辑并不全面,初始化逻辑是基于spring bean的生命周期来做的。见ThreadFacade。
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"xmlns:tx="http://www.springframework.org/schema/tx" xmlns:zstack="http://zstack.org/schema/zstack"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans-3.0.xsdhttp://www.springframework.org/schema/aophttp://www.springframework.org/schema/aop/spring-aop-3.0.xsdhttp://www.springframework.org/schema/txhttp://www.springframework.org/schema/tx/spring-tx-3.0.xsdhttp://zstack.org/schema/zstackhttp://zstack.org/schema/zstack/plugin.xsd"default-init-method="init" default-destroy-method="destroy"><bean id="ThreadFacade" class="org.zstack.core.thread.ThreadFacadeImpl"><property name="totalThreadNum" value="500" /><!-- don't declare Component extension, it's specially handled --></bean><bean id="ThreadAspectj" class="org.zstack.core.aspect.ThreadAspect" factory-method="aspectOf" /></beans>
再让回头看看ThreadFacadeImpl的init与destory操作。
//init 操作public void init() {//根据全局配置读入线程池最大线程数量totalThreadNum = ThreadGlobalProperty.MAX_THREAD_NUM;if (totalThreadNum < 10) {_logger.warn(String.format("ThreadFacade.maxThreadNum is configured to %s, which is too small for running zstack. Change it to 10", ThreadGlobalProperty.MAX_THREAD_NUM));totalThreadNum = 10;}// 构建一个支持延时任务的线程池_pool = new ScheduledThreadPoolExecutorExt(totalThreadNum, this, this);_logger.debug(String.format("create ThreadFacade with max thread number:%s", totalThreadNum));//构建一个DispatchQueuedpq = new DispatchQueueImpl();jmxf.registerBean("ThreadFacade", this);}
//destorypublic void destroy() {_pool.shutdownNow();}
看了这里可能大家会有疑问,这种关闭方式未免关于暴力(执行任务的线程会全部被中断)。在此之前,我们曾提到过,它实现了Component接口。这个接口分别有一个start和stop方法,使一个组件的生命周期能够方便的在ZStack中注册相应的钩子。
//stop 方法@Overridepublic boolean stop() {_pool.shutdown();timerPool.stop();return true;}
线程工厂
ThreadFacadeImpl同时也实现了ThreadFactory,可以让线程在创建时做一些操作。
@Overridepublic Thread newThread(Runnable arg0) {return new Thread(arg0, "zs-thread-" + String.valueOf(seqNum.getAndIncrement()));}
在这里可以看到ZStack为每一个新的线程赋予了一个名字。
线程池
ZStack对JDK中的线程池进行了一定的扩展,对一个任务执行前后都有相应的钩子函数,同时也开放注册钩子。
package org.zstack.core.thread;import org.apache.logging.log4j.ThreadContext;import org.zstack.utils.logging.CLogger;import org.zstack.utils.logging.CLoggerImpl;import java.util.ArrayList;import java.util.List;import java.util.concurrent.RejectedExecutionHandler;import java.util.concurrent.ScheduledThreadPoolExecutor;import java.util.concurrent.ThreadFactory;public class ScheduledThreadPoolExecutorExt extends ScheduledThreadPoolExecutor {private static final CLogger _logger =CLoggerImpl.getLogger(ScheduledThreadPoolExecutorExt.class);List<ThreadAroundHook> _hooks = new ArrayList<ThreadAroundHook>(8);public ScheduledThreadPoolExecutorExt(int corePoolSize, ThreadFactory threadFactory, RejectedExecutionHandler handler) {super(corePoolSize, threadFactory, handler);this.setMaximumPoolSize(corePoolSize);}public void registerHook(ThreadAroundHook hook) {synchronized (_hooks) {_hooks.add(hook);}}public void unregisterHook(ThreadAroundHook hook) {synchronized (_hooks) {_hooks.remove(hook);}}@Overrideprotected void beforeExecute(Thread t, Runnable r) {ThreadContext.clearMap();ThreadContext.clearStack();ThreadAroundHook debugHook = null;List<ThreadAroundHook> tmpHooks;synchronized (_hooks) {tmpHooks = new ArrayList<ThreadAroundHook>(_hooks);}for (ThreadAroundHook hook : tmpHooks) {debugHook = hook;try {hook.beforeExecute(t, r);} catch (Exception e) {_logger.warn("Unhandle exception happend during executing ThreadAroundHook: " + debugHook.getClass().getCanonicalName(), e);}}}@Overrideprotected void afterExecute(Runnable r, Throwable t) {ThreadContext.clearMap();ThreadContext.clearStack();ThreadAroundHook debugHook = null;List<ThreadAroundHook> tmpHooks;synchronized (_hooks) {tmpHooks = new ArrayList<ThreadAroundHook>(_hooks);}for (ThreadAroundHook hook : tmpHooks) {debugHook = hook;try {hook.afterExecute(r, t);} catch (Exception e) {_logger.warn("Unhandle exception happend during executing ThreadAroundHook: " + debugHook.getClass().getCanonicalName(), e);}}}}
另外,ScheduledThreadPoolExecutorExt是继承自ScheduledThreadPoolExecutor。本质上是一个任务调度线程池,用的工作队列也是一个延时工作队列。
小结
本文分析了ZStack的久经生产考验的核心组件——线程池。通过线程池,使并行编程变得不再那么复杂。
当然,其中也有一些可以改进的地方:
- 一些加锁的地方(synchronized),可以通过使用并发容器解决。这样可以有效提升吞吐量,节省因为竞争锁而导致的开销。
- 在提交大量任务的情况下,HashMap会因为扩容而导致性能耗损。可以考虑用固定大小的map并以hash key到固定entry的形式来保证数据结构不会持续扩容。
- 队列是无界的。在大量任务请求阻塞时,会对内存造成极大的负担。
- 任务队列无超时逻辑判断。ZStack中的调用绝大多数都是由MQ完成,每一个msg有着对应的超时时间。但是每一个任务却没有超时判定,这意味着一个任务执行时间过长时,后面的任务有可能进入了超时状态,而却没有挪出队列,配合之前提到的无界队列,就是一场潜在的灾难。针对这个问题,可以参考Zookeeper的
SessionBucket或Kafka的TimingWheel来解决这种问题。

若有收获,就点个赞吧
0 人点赞
