- 1-Mysql的安装
- 2-免密互信
- 3-高可用软件—MHA
- master_ip_failover_script=/usr/local/bin/master_ip_failover
#remote_workdir=/data/mysql/mha
#mha的用户
user=mha
#mha用户的密码
password=999999
#存活检查的间隔时间
ping_interval=2
#主从复制用户
repl_user=rep
#主从复制密码
repl_password=999999
#用于ssh远程的用户
ssh_user=root - 5-配置VIP漂移
- 6-配置binlog-server备份服务器
- —host是主库的IP —user —password是主库设置的mha的密码和用户
# 此处从mysql-bin.000001拉取所有二进制日志,生产中从master的最新二进制日志处拉取二进制日志
# —raw: 以 binlog 格式存储日志,方便后期使用 - 7-mysql中间件Atlas—读写分离
- 为登陆MySQL的授权账号信息,其中密码需要加密(通过/usr/local/mysql-proxy/bin/encrypt加密工具来加密)
pwds = root:pGQ5XOxcRtM=, mha:pGQ5XOxcRtM= - 管理接口的用户名
- 管理接口的密码
- Atlas监听的工作接口IP和端口
1-Mysql的安装
mysql的安装和gtid模式的主从复制参考上一章节
https://www.yuque.com/zhibizhuxieweilai/ycsu4z/mrqnf5
2-免密互信
所有机器都要进行免密互信,包括机器本身
ssh-keygen -t dsa -P “” -f ~/.ssh/id_dsa >/dev/null 2>&1
ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.0.111
ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.0.112
ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.0.113
3-高可用软件—MHA
1-软件简介
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换过程中,MHA能最大程度上保证数据库的一致性,以达到真正意义上的高可用。
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上。当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master,然后将所有其他的Slave重新指向新的Master。整个故障转移过程对应程序是完全透明的。
2-工作流程及原理
在 MHA 自动故障切换过程中,MHA 试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA 没法保存二进制日志,只进行故障转移而丢失了最新的数据。
从宕机崩溃的master保存二进制日志事件(binlog events);
识别含有最新更新的slave;
应用差异的中继日志(relay log)到其他的slave;
应用从master保存的二进制日志事件(binlog events);
提升一个slave为新的master;
使其他的slave连接新的master进行复制;
目前 MHA 主要支持一主多从的架构,要搭建 MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当 master,一台充当备用 master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。
3-MHA工具介绍
MHA软件由两部分组成,Manager工具包和Node工具包
#Manager工具包
masterha_check_ssh #检查MHA的SSH配置状况
masterha_check_repl #检查MySQL复制状况
masterha_check_status #检测当前MHA运行状态
masterha_master_monitor #检测master是否宕机
masterha_manger #启动MHA
masterha_master_switch #控制故障转移(自动或者手动)
masterha_conf_host #添加或删除配置的server信息
masterha_secondary_check #试图建立TCP连接从远程服务器
masterha_stop #停止MHA
#Node工具包
save_binary_logs #保存和复制master的二进制日志
apply_diff_relay_logs #识别差异的中继日志事件
filter_mysqlbinlog #去除不必要的ROLLBACK事件
purge_relay_logs #清除中继日志
4-MHA工具安装
工具使用:
https://bbs.huaweicloud.com/blogs/181665
1.安装依赖
所有节点
yum -y install perl-DBD-MySQL
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes perl-DBD-MySQL per1-Config-Tiny per1-Params-validate per1-CPAN per1-deve1
2.创建mha授权用户
创建用户
create user ‘mha’@’192.168.0.%’ identified by ‘999999’;
授权用户
mysql5的语句
grant all privileges on . to mha@’192.168.0.%’ identified by ‘999999’;
mysql8的语句
grant all privileges on . to mha@’192.168.0.%’ with grant option;
查看用户
select user,host from mysql.user where user=’mha’;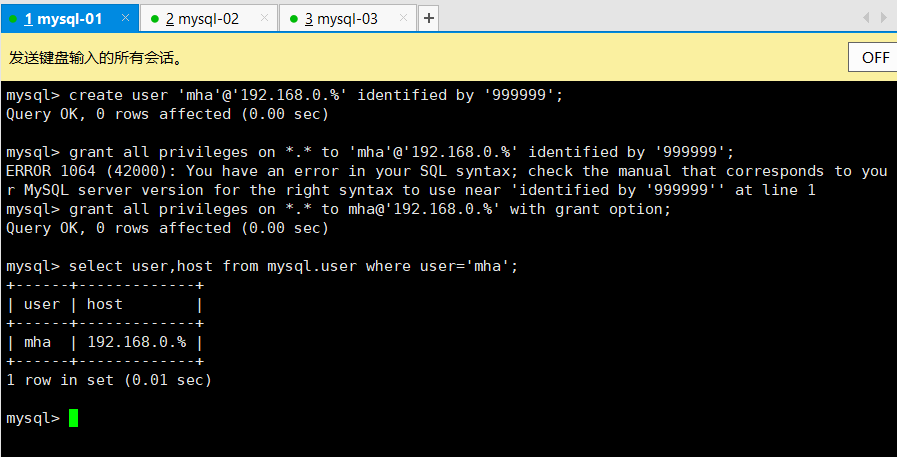
3.安装mha-node节点
mha4mysql-node-0.57-0.el7.noarch.zip
rpm -ivh mha4mysql-node-0.57-0.el7.noarch.rpm
4.安装mha-master节点
注意:MHA管理节点不要装到mysql主库和切换的从库上(备用的主库),否则会在后面的vip无法漂移
mha4mysql-manager-0.57-0.el7.noarch.zip
说明:在之前测试的基础之上,这里使用mysql-03作为master机器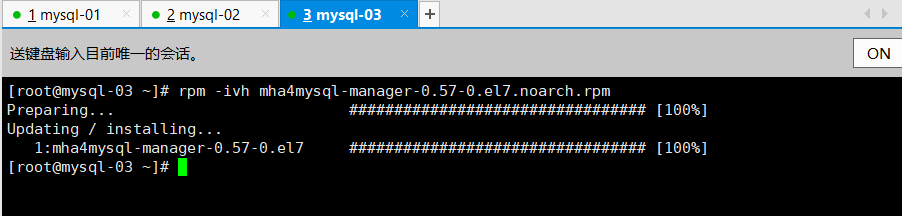
4.x附录:源码安装
源码安装master和node节点方法
node节点:
tar xf mha4mysq1-node-0. 58.tar .9z
cd mha4mysq1-node-0. 58
per1 Makefile.PL
make & make insta11
manager节点:
tar xf mha4mysq1 -manager-0.58. tar .gz
cd mha4mysq1-manager-0. 58
per1 Makefile.PL
make & make install
按装完成后会在/usr/local/bin目录下面生成以下脚本文件
5.创建mha目录
[root@mysql-03 ~]# mkdir /etc/mha #创建配置文件目录
[root@mysql-03 ~]# mkdir /var/log/mha #创建日志文件目录
编辑配置文件
mha.cnf
[server default]
#manage日志
manager_log=/var/log/mha/manager.log
#manage日志路径
manager_workdir=/var/log/mha
#binlog日志的存放路径
master_binlog_dir=/usr/local/mysql/data
master_ip_failover_script=/usr/local/bin/master_ip_failover
#remote_workdir=/data/mysql/mha
#mha的用户
user=mha
#mha用户的密码
password=999999
#存活检查的间隔时间
ping_interval=2
#主从复制用户
repl_user=rep
#主从复制密码
repl_password=999999
#用于ssh远程的用户
ssh_user=root
[server1]
hostname=192.168.0.111
port=3306
[server2]
hostname=192.168.0.112
port=3306
[server3]
hostname=192.168.0.113
port=3306
#候选master选项参数
#candidate_master=1
#check_repl_delay=0
特别说明:
参数:candidate_master=1
解释:设置为候选master,如果设置该参数以后,发生主从切换以后会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
参数:check_repl_delay=0
解释:默认情况下如果一个slave落后master 100M的relay logs 的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
6.mha-ssh-check
ssh通道检测
masterha_check_ssh —conf=/etc/mha/mha.cnf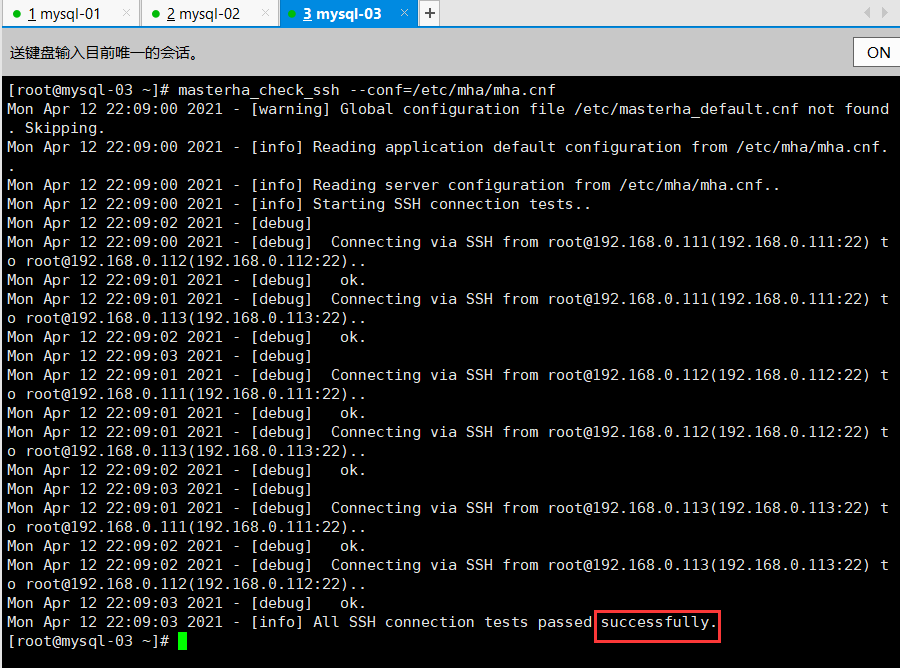
必须全都是ok,successfully才行
7.mha-rep-check
主从复制检测
看,这里报错了
[root@mysql-03 ~]# masterha_check_repl —conf=/etc/mha/mha.cnf
Tue Apr 13 07:54:12 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Apr 13 07:54:12 2021 - [info] Reading application default configuration from /etc/mha/mha.cnf..
Tue Apr 13 07:54:12 2021 - [info] Reading server configuration from /etc/mha/mha.cnf..
Tue Apr 13 07:54:12 2021 - [info] MHA::MasterMonitor version 0.57.
Tue Apr 13 07:54:13 2021 - [error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln188] There is no alive server. We can’t do failover
Tue Apr 13 07:54:13 2021 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. at /usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm line 329.
Tue Apr 13 07:54:13 2021 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers.
Tue Apr 13 07:54:13 2021 - [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK!
[root@mysql-03 ~]#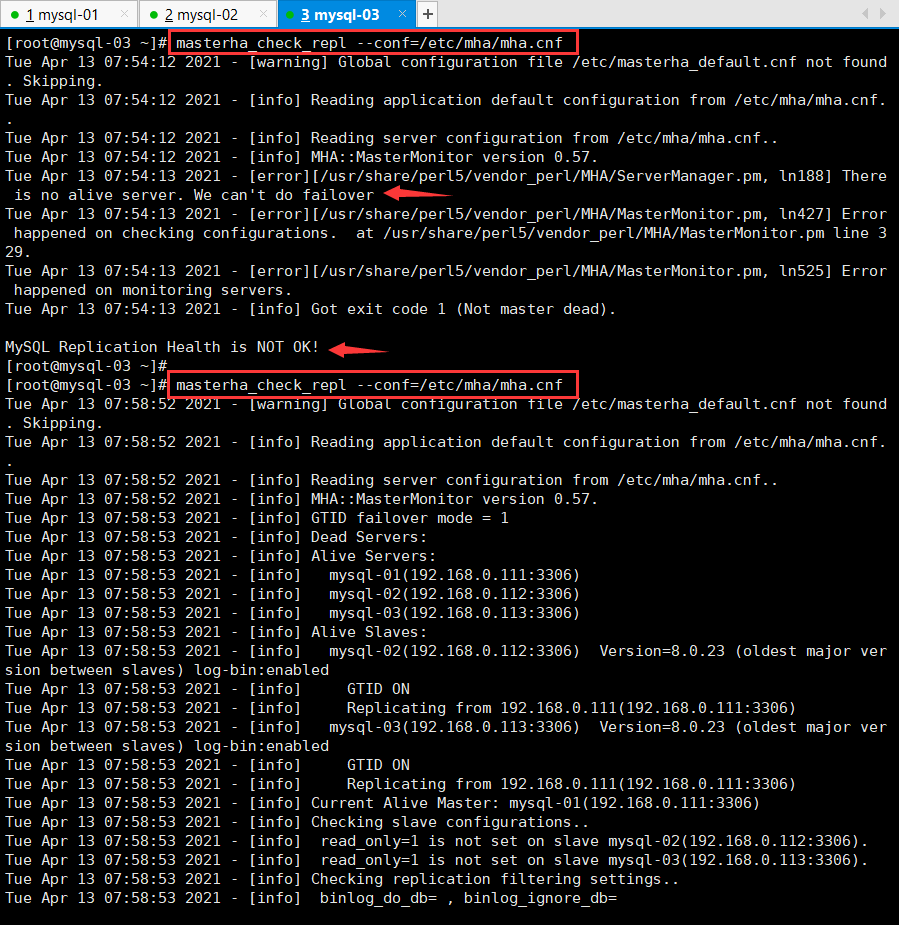
解决方法,参考地址:
https://blog.csdn.net/Linux_yzh/article/details/105232729?utm_medium=distribute.pc_relevant_bbs_down.none-task—2~all~first_rank_v2~rank_v29-18.nonecase&depth_1-utm_source=distribute.pc_relevant_bbs_down.none-task—2~all~first_rank_v2~rank_v29-18.nonecase
在主库上,更新两个授权用户的plugin
alter user mha@’192.168.0.%’ identified with mysql_native_password by ‘999999’;
alter user rep@’%’ identified with mysql_native_password by ‘999999’;
flush privileges;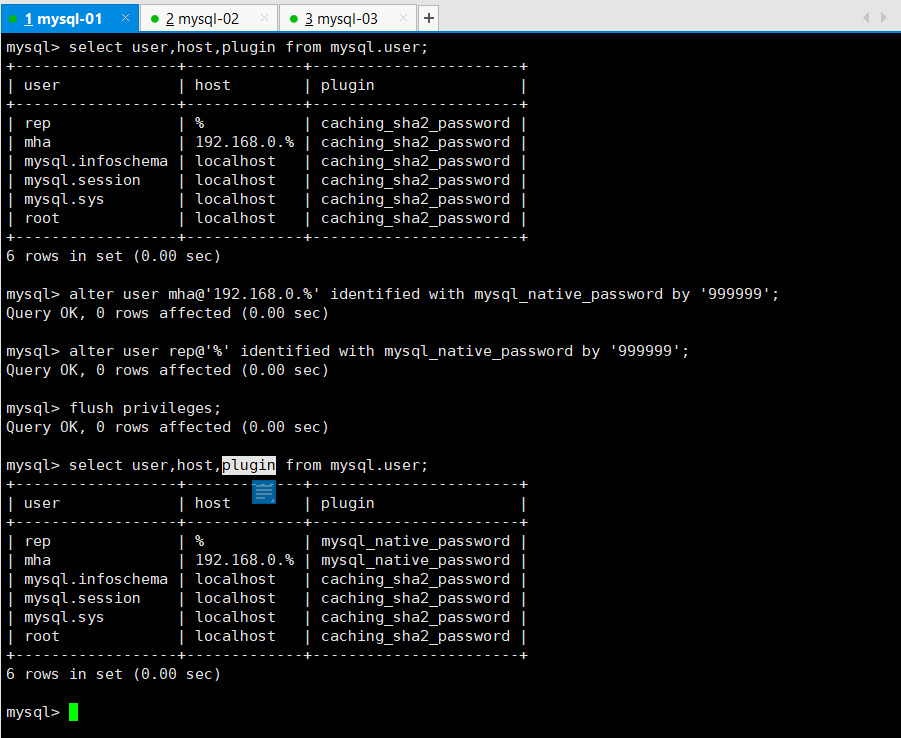
再次check-repl,通过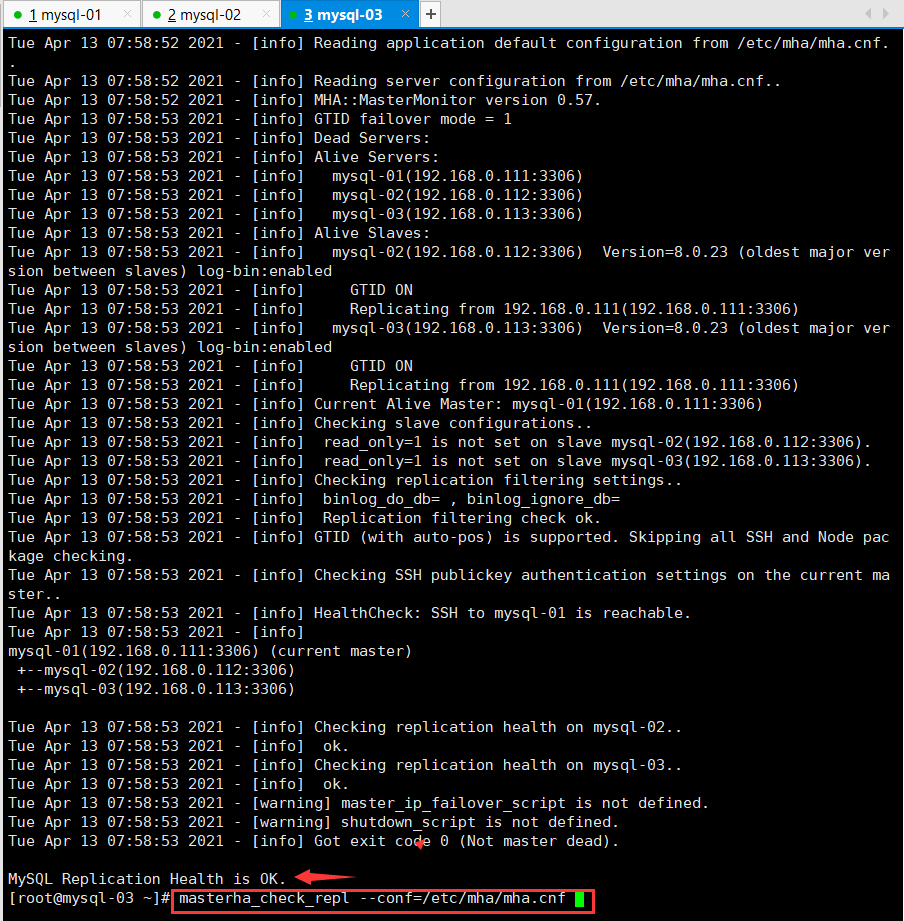
8.启动/监测mha-manage
启动manage
nohup masterha_manager —conf=/etc/mha/mha.cnf —remove_dead_master_conf —ignore_last_failover < /dev/null > /var/log/mha/manager.log 2>&1 &
命令参数:
—remove_dead_master_conf 该参数代表当发生主从切换后,老的主库的ip将会从配置文件中移除。
—manger_log 日志存放位置
—ignore_last_failover 在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件,默认情况下,MHA发生切换后会在日志目录,也就是上面设置的manager_workdir目录中产生app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便,这里设置为—ignore_last_failover。
监测manage
masterha_check_status —conf=/etc/mha/mha.cnf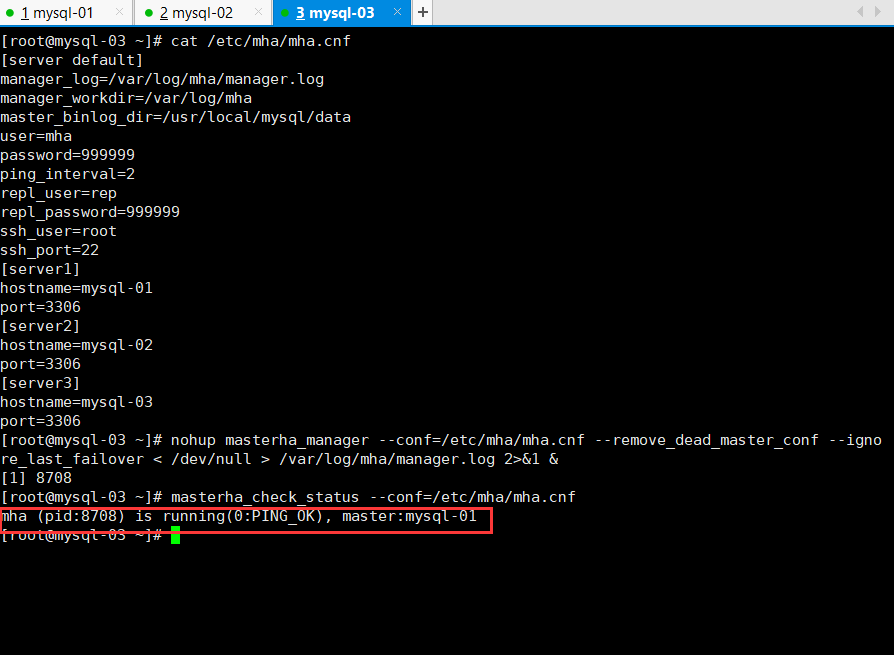
ps查看进程也是在的
9.故障演练
异常
停掉主的mysqld进程
检查主从复制状态,会发现maser的机器ip已经发生了漂移,也可以从mysql.slave_master_info表中查看当前master是谁,然后到从节点上查看主从同步的状态是否正常。
过程
发生故障时,MHA做了什么?
①当作为主库的mysql-01上的MySQL宕机以后,mha通过检测发现mysql-01的mysql宕机了,那么会将binlog日志最全的从库(mysql-02)立刻提升为主库,而其他的从库会指向新的主库进行再次同步。
②MHA会自己结束自己的进程,还会将/etc/mha/mha.cnf配置文件中,剔除坏掉的那台机器信息。
恢复
启动宕机机器的服务,change master to指定新的master进行主从复制,补全mha.cnf配置文件中缺失部分。
5-配置VIP漂移
IP漂移的两种方式
通过keepalived的方式,管理虚拟IP的漂移
通过MHA自带脚本方式,管理虚拟IP的漂移
mha常用脚本:
https://www.jianshu.com/p/e3a499cfd4b2
这里介绍脚本方法
1-获取管理脚本master_ip_failover
提示:yum安装的manager是没有这个脚本的。 我们需要从manager的源码包里复制一个。
mha4mysql058.zip
masterha_manage 命令使用方法
https://github.com/yoshinorim/mha4mysql-manager/wiki/masterha_manager
1.获取master_ip_failover脚本
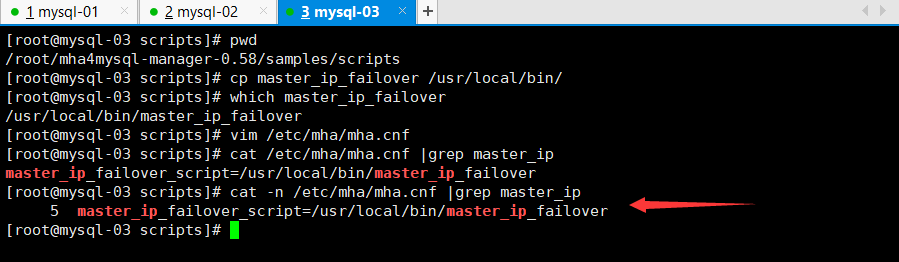
[root@mysql-03 scripts]# pwd
/root/mha4mysql-manager-0.58/samples/scripts
[root@mysql-03 scripts]# cp master_ip_failover /usr/local/bin/
[root@mysql-03 scripts]# which master_ip_failover
/usr/local/bin/master_ip_failover
[root@mysql-03 scripts]# 
2.修改配置文件
在配置文件中添加vip脚本
vim /etc/mha/mha.cnf
添加内容
master_ip_failover_script=/usr/local/bin/master_ip_failover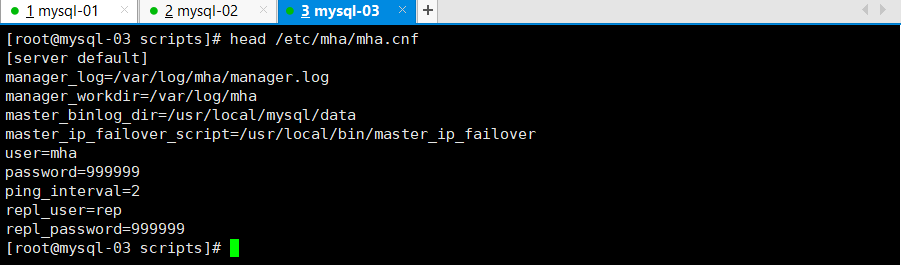
3.修改VIP漂移脚本
master_ip_failover.zip
修改vip漂移脚本,34行后添加如下内容
my $vip = ‘192.168.0.200/24’;
my $ssh_start_vip = “/usr/sbin/ip addr add $vip dev ens33”;
my $ssh_stop_vip = “/usr/sbin/ip addr del $vip dev ens33”;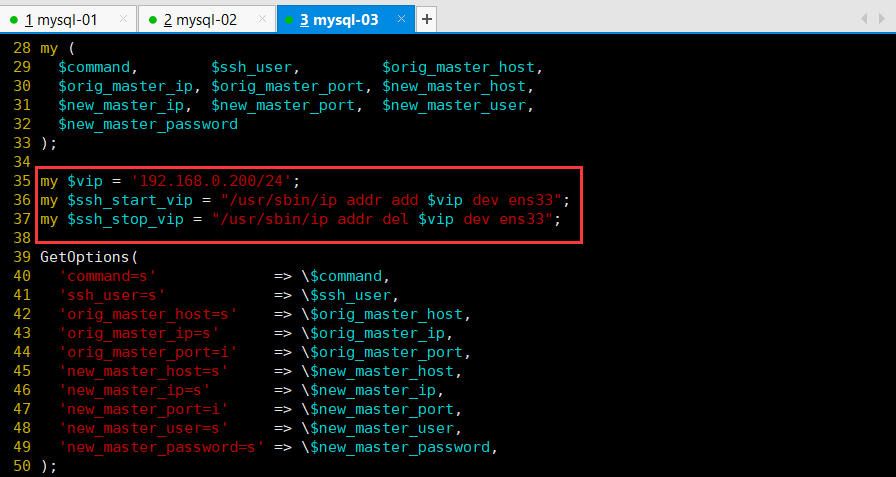
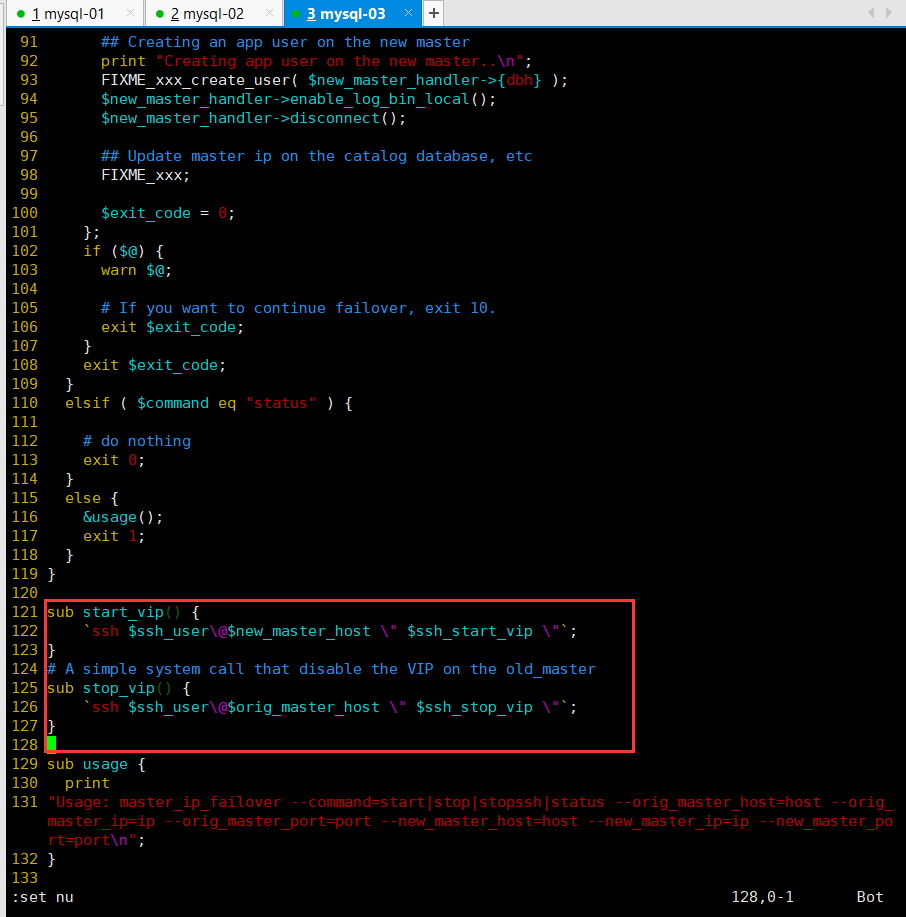
修改vip漂移脚本,120行后添加如下内容
sub start_vip() {
ssh $ssh_user\@$new_master_host \" $ssh_start_vip \";
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \";
}
完成以上修改后重启下master_manage服务,并检查服务状态
masterha_check_status —conf=/etc/mha/mha.cnf
nohup masterha_manager —conf=/etc/mha/mha.cnf —remove_dead_master_conf —ignore_last_failover < /dev/null > /var/log/mha/manager.log 2>&1 &
提示:
如果启动mha进程失败,需要进行mha的连接检测
masterha_check_ssh —conf=/etc/mha/mha.cnf #ssh连接检测
masterha_check_repl —conf=/etc/mha/mha.cnf #主从复制检测
masterha_check_status —conf=/etc/mha/mha.cnf #manage状态检测
绑定VIP
在master上绑定vip,(只需要在master绑定这一次,以后会自动切换,是mysql主从复制的主)
/usr/sbin/ip addr add 192.168.0.200/24 dev ens33 label ens33:1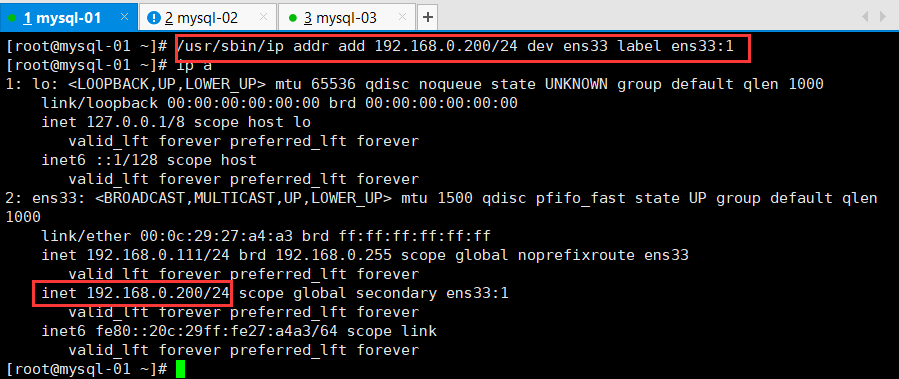
VIP漂移验证
停掉mysql服务,vip预期会进行漂移,查看mysql03上的与主的主从复制情况
故障恢复如之前一样
6-配置binlog-server备份服务器
主库宕机,也许会造成主库binlog复制不及时而导致数据丢失的情况出现,因此配置binlog-server进行时时同步备份,是必要的一种安全手段。
1.修改mha配置文件
cat /etc/mha/mha.cnf
[server default]
…
master_binlog_dir=/usr/local/mysql/data #全局的binlog存放位置
…
[binlog1] #添加binlog模块
no_master=1 #不允许切换为主
hostname=192.168.0.114 #存放IP
master_binlog_dir=/data/mysql/binlog/ #binlog存放位置优先级比全局的高
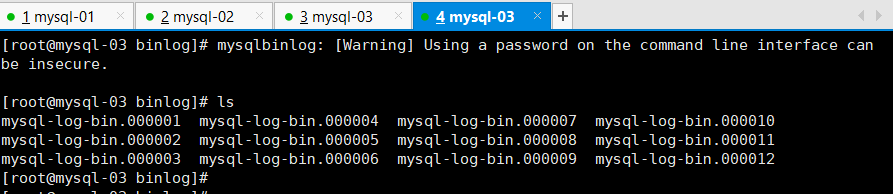
2.拉取主库上的binlog日志到mysql-04的存放目录里
mkdir -p /data/mysql/binlog #创建存放目录
cd /data/mysql/binlog/ #进入存放目录
[root@mysql-04 binlog]# ll
total 0
[root@mysql-04 binlog]# which mysqlbinlog
/usr/local/bin/mysqlbinlog
[root@mysql-04 binlog]# mysqlbinlog -R —host=192.168.0.111 —user=mha —password=999999 —raw —stop-never mysql-bin.000001 & #拉取主库binlog
[2] 15694
[root@mysql-04 binlog]# Warning: Using a password on the command line interface can be insecure.
[root@mysql-04 binlog]# ll
total 32
-rw-r—r—. 1 root root 143 Sep 5 20:53 mysql-bin.000001
-rw-r—r—. 1 root root 143 Sep 5 20:53 mysql-bin.000002
-rw-r—r—. 1 root root 331 Sep 5 20:53 mysql-bin.000003
-rw-r—r—. 1 root root 3114 Sep 5 20:53 mysql-bin.000004
-rw-r—r—. 1 root root 254 Sep 5 20:53 mysql-bin.000005
-rw-r—r—. 1 root root 800 Sep 5 20:53 mysql-bin.000006
-rw-r—r—. 1 root root 2714 Sep 5 20:53 mysql-bin.000007
-rw-r—r—. 1 root root 120 Sep 5 20:53 mysql-bin.000008
[root@mysql-04 binlog]# ps -ef | grep mysqlbinlog | grep -v grep
root 16061 12786 0 20:53 pts/2 00:00:00 mysqlbinlog -R —host=192.168.0.52 —user=mha —password=x xxxx —raw —stop-never mysql-bin.000001
—host是主库的IP —user —password是主库设置的mha的密码和用户
# 此处从mysql-bin.000001拉取所有二进制日志,生产中从master的最新二进制日志处拉取二进制日志
# —raw: 以 binlog 格式存储日志,方便后期使用
注意:
当备份过程报错如下
[root@mysql-03 ~]# mysqlbinlog: [Warning] Using a password on the command line interface can be insecure.
ERROR: Got error reading packet from server: Cannot replicate anonymous transaction when @@GLOBAL.GTID_MODE = ON, at file ./mysql-log-bin.000001, position 156.; the first event ‘mysql-log-bin.000001’ at 4, the last event read from ‘./mysql-log-bin.000001’ at 235, the last byte read from ‘./mysql-log-bin.000001’ at 235.
[1]+ Exit 1 mysqlbinlog -R —host=192.168.0.111 —user=mha —password=999999 —raw —stop-never mysql-log-bin.000001
设置主从库
SET @@GLOBAL.GTID_MODE = ON_PERMISSIVE;
https://stackoverflow.com/questions/36707108/anonymous-transactions-get-made-even-with-gtid-mode-on
再次备份即可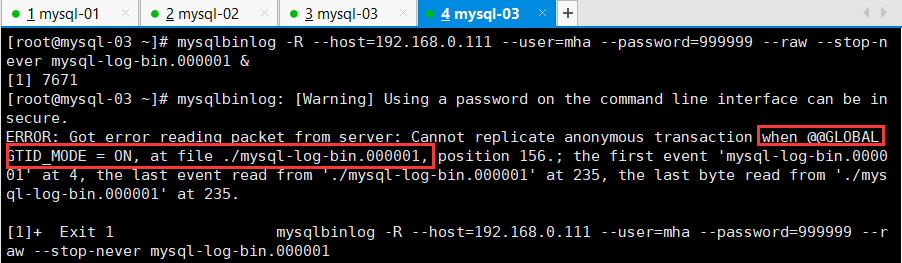
3.重启mha管理进程
[root@mysql-03 binlog]# nohup masterha_manager —conf=/etc/mha/mha1.cnf —remove_dead_master_conf —ignore_last_failover < /dev/null > /var/log/mha/mha1/manager.log 2>&1 &
[root@mysql-03 binlog]# ps -ef | grep perl | grep -v grep
root 15697 13211 0 20:42 pts/3 00:00:00 perl /usr/bin/masterha_manager —conf=/etc/mha/mha1.cnf —remove_dead_master_conf —ignore_last_failover
7-mysql中间件Atlas—读写分离
1.Atlas简介
Atlas是由Qihoo-360公司web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它在MySQL官方推出的MySQL-Proxy-0.8.2版本的基础上,修改了大量bug,添加了很多功能特性。它在MySQL官方推出的MySQL-Proxy0.8.2版本的基础上,修改了大量bug,添加了很多功能特性。
2.Atlas主要功能
读写分离
从库负载均衡
IP过滤
自动分表
DBA可平滑上下线DB
自动摘除宕机的DB
3.Atlas相对于官方MySQL-Proxy的优势
将主流程中所有Lua代码用C重写,Lua仅用于管理接口。
重写网络模型,线程模型
实现了真正意义上的连接池
优化了锁机制,性能提高数十倍
4.安装Atlas
安装Atlas超级简单,官方提供的Atlas有两种:
(普通):Atlas-2.2.1.el6.x86_64.rpm
(分表):Atlas-sharding_1.0.1-el6.x86_64.rpm
这里我们只需要下载普通的即可
Atlas-2.2.1.el6.x86_64.zip
[root@mysql-03 ~]# rpm -ivh Atlas-2.2.1.el6.x86_64.rpm

5.配置Atlas
修改后的配置文件为
[root@mysql-03 ~]# cat /usr/local/mysql-proxy/conf/test.cnf
[mysql-proxy]
#带#号的为非必需的配置项目
#管理接口的用户名
admin-username = user
#管理接口的密码
admin-password = pwd
#Atlas后端连接的MySQL主库的IP和端口,可设置多项,用逗号分隔;也就是VIP地址
proxy-backend-addresses = 192.168.0.200:3306
#Atlas后端连接的MySQL从库的IP和端口,只读的机器,@后面的数字代表权重,用来作负载均衡,若省略则默认为1,可设置多项,用逗号分隔
proxy-read-only-backend-addresses = 192.168.0.112:3306@1,192.168.0.113:3306@1
#用户名与其对应的加密过的MySQL密码,密码使用PREFIX/bin目录下的加密程序encrypt加密,下行的user1和user2为示例,将其替换为你的MySQL的用户名和加密密码!
为登陆MySQL的授权账号信息,其中密码需要加密(通过/usr/local/mysql-proxy/bin/encrypt加密工具来加密)
pwds = root:pGQ5XOxcRtM=, mha:pGQ5XOxcRtM=
#设置Atlas的运行方式,设为true时为守护进程方式,设为false时为前台方式,一般开发调试时设为false,线上运行时设为true,true后面不能有空格。
daemon = true
#设置Atlas的运行方式,设为true时Atlas会启动两个进程,一个为monitor,一个为worker,monitor在worker意外退出后会自动将其重启,设为false时只有worker,没有monitor,一般开发调试时设为false,线上运行时设为true,true后面不能有空格。
keepalive = true
#工作线程数,对Atlas的性能有很大影响,可根据情况适当设置
event-threads = 8
#日志级别,分为message、warning、critical、error、debug五个级别
log-level = error
#日志存放的路径
log-path = /var/log/atlas/
#SQL日志的开关,可设置为OFF、ON、REALTIME,OFF代表不记录SQL日志,ON代表记录SQL日志,REALTIME代表记录SQL日志且实时写入磁盘,默认为OFF
sql-log = ON
#慢日志输出设置。当设置了该参数时,则日志只输出执行时间超过sql-log-slow(单位:ms)的日志记录。不设置该参数则输出全部日志。
#sql-log-slow = 10
#实例名称,用于同一台机器上多个Atlas实例间的区分
#instance = test
#Atlas监听的工作接口IP和端口
proxy-address = 192.168.0.113:1234
#Atlas监听的管理接口IP和端口
admin-address = 192.168.0.113:2345
#分表设置,此例中person为库名,mt为表名,id为分表字段,3为子表数量,可设置多项,以逗号分隔,若不分表则不需要设置该项
#tables = person.mt.id.3
#默认字符集,设置该项后客户端不再需要执行SET NAMES语句
#charset = utf8
#允许连接Atlas的客户端的IP,可以是精确IP,也可以是IP段,以逗号分隔,若不设置该项则允许所有IP连接,否则只允许列表中的IP连接
#client-ips = 127.0.0.1, 192.168.1
#Atlas前面挂接的LVS的物理网卡的IP(注意不是虚IP),若有LVS且设置了client-ips则此项必须设置,否则可以不设置
#lvs-ips = 192.168.1.1
[root@mysql-03 ~]#
6.启动Atlas
/usr/local/mysql-proxy/bin/mysql-proxyd test start
#说明:
#为何启动服务需要加test,因为在Atlas配置文件里定义了一个实例名字为test
#Atlas实际是启动了某个实例(当然也可以多实例)
启动之前先检查mha运行是否正常
还要启动mysqlbinlog的备份进程
mysqlbinlog -R —host=192.168.0.52 —port=3307 —user=mha —password=123123 —raw —stop-never mysql-bin.000001 &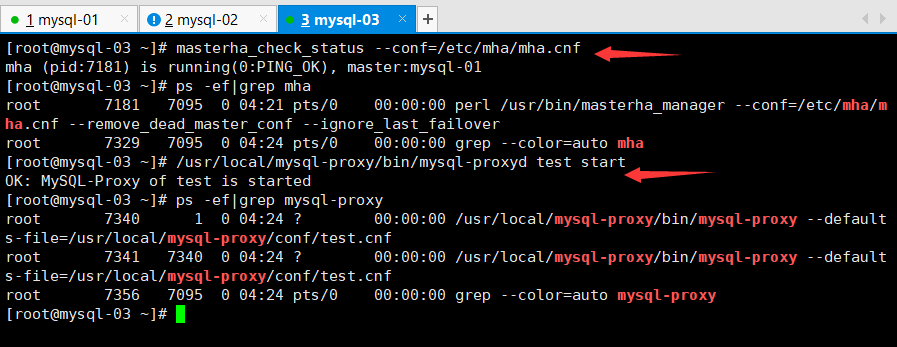
7.验证服务
1.登陆Atlas管理端口
管理接口的用户名
admin-username = user
管理接口的密码
admin-password = pwd
Atlas监听的工作接口IP和端口
proxy-address = 192.168.0.113:1234
#Atlas监听的管理接口IP和端口
admin-address = 192.168.0.113:2345
mysql> show databases; #看所有库,报错
ERROR 1105 (07000): use ‘SELECT FROM help’ to see the supported commands
mysql> select from help; #按提示输入命令
+——————————————+————————————————————————————-+
| command | description |
+——————————————+————————————————————————————-+
| SELECT FROM help | shows this help |
| SELECT FROM backends | lists the backends and their state |
| SET OFFLINE $backend_id | offline backend server, $backend_id is backend_ndxs id |
| SET ONLINE $backend_id | online backend server, … |
| ADD MASTER $backend | example: “add master 127.0.0.1:3306”, … |
| ADD SLAVE $backend | example: “add slave 127.0.0.1:3306”, … |
| REMOVE BACKEND $backend_id | example: “remove backend 1”, … |
| SELECT FROM clients | lists the clients |
| ADD CLIENT $client | example: “add client 192.168.1.2”, … |
| REMOVE CLIENT $client | example: “remove client 192.168.1.2”, … |
| SELECT FROM pwds | lists the pwds |
| ADD PWD $pwd | example: “add pwd user:raw_password”, … |
| ADD ENPWD $pwd | example: “add enpwd user:encrypted_password”, … |
| REMOVE PWD $pwd | example: “remove pwd user”, … |
| SAVE CONFIG | save the backends to config file |
| SELECT VERSION | display the version of Atlas |
+——————————————+————————————————————————————-+
16 rows in set (0.00 sec)
mysql> select * from backends; #输入上边列表里的命令,出现下表
+——————-+—————————-+———-+———+
| backend_ndx | address | state | type |
+——————-+—————————-+———-+———+
| 1 | 192.168.0.111:3307 | up | rw |
| 2 | 192.168.0.112:3307 | up | ro |
| 3 | 192.168.0.113:3307 | up | ro |
+——————-+—————————-+———-+———+
3 rows in set (0.00 sec)
#这里是平滑管理界面,可以在这里根据选项修改设置
2.进行读写分离及读负载均衡测试
(1)在mysql-02和mysql-03上的本地MySQL(3306端口)创建一个库
(2)登陆mysql-01(主库)进行查看
(3)主库192.168.0.111里并没有之前创建的任何一个库
(4)在mysql-db03的本地登陆Atlas代理的1234端口(用授权账户&&atlas的代理监听端口进行查看)
[root@mysql-03 ~]# mysql -uroot -p999999 -h 192.168.0.113 -P1234
每一次show databases; ,都可以list出库2或库3创建的库,负载均衡的展现出来
(5)我们在mysql-03的Atlas代理的MySQL服务端口里(也就是1234端口下)进行写入操作,测试读写分离
[root@mysql-db03 ~]# mysql -uroot -p999999 -h 192.168.0.113 -P1234
由此可见,mysql-02和mysql-03的库里都出现了新建的的库。
只有一个可能,数据是被写入了主库192.168.0.111里,然后同步到的从库。因此,读写分离测试完毕。

若有收获,就点个赞吧
0 人点赞
