可靠消息最终一致性方案(用的比较多的)
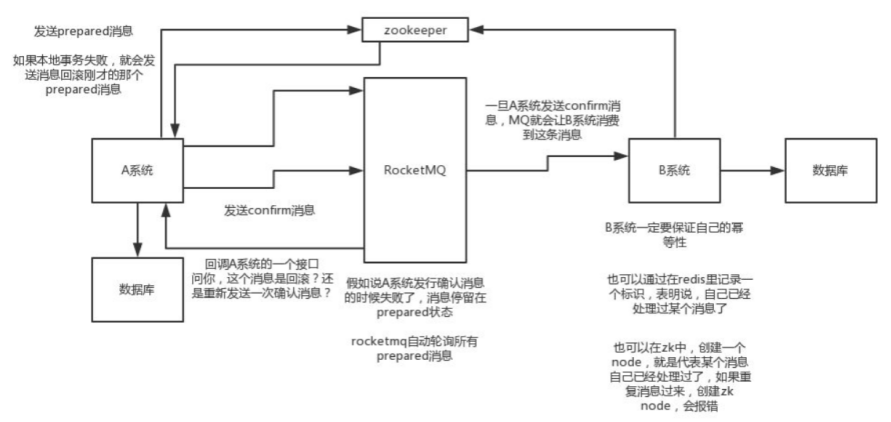
直接基于MQ来实现事务。比如阿里的RocketMQ就支持消息事务。
大概的意思就是:
1)A系统先发送一个prepared消息到mq,如果这个prepared消息发送失败那么就直接取消操作别执行了,如果发送成功说明MQ是活着的,MQ能正常工作.
2)如果这个消息发送成功过了,那么接着执行本地事务,如果成功就告诉mq发送确认消息,如果失败就告诉mq回滚消息
3)如果发送了确认消息,那么此时B系统会接收到确认消息,然后执行本地的事务
4)mq会自动定时轮询所有prepared消息回调你的接口,问你,这个消息是不是本地事务处理失败了,所有没发送确认消息?那是继续重试还是回滚?一般来说这里你就可以查下数据库看之前本地事务是否执行,如果回滚了,那么这里也回滚吧。这个就是避免可能本地事务执行成功了,别确认消息发送失败了。
5)这个方案里,要是系统B的事务失败了咋办?重试咯,自动不断重试直到成功,如果实在是不行,要么就是针对重要的资金类业务进行回滚,比如B系统本地回滚后,想办法通知系统A也回滚;或者是发送报警由人工来手工回滚和补偿
也可以B系统事务失败了,通过Zookeeper来通知A系统,让A系统再重新给消息再发送一遍,让B系统再处理一遍.
这个还是比较合适的,目前国内互联网公司大都是这么玩儿的,要不你举用RocketMQ支持的,要不你就自己基于类似ActiveMQ?RabbitMQ?自己封装一套类似的逻辑出来,总之思路就是这样子的
最大努力通知方案(用的比较少)
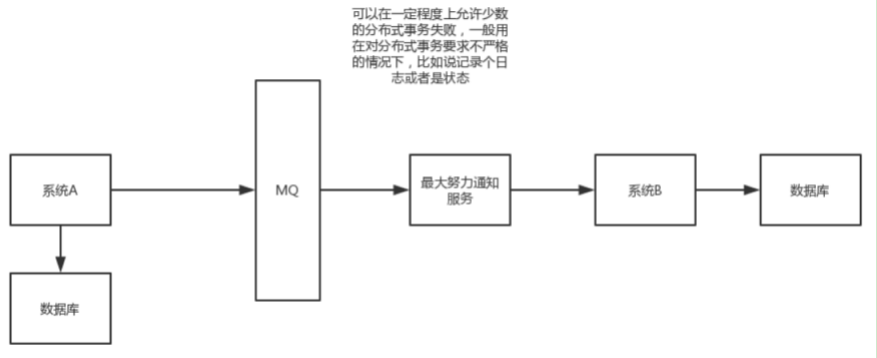
这个方案的大致意思就是:
1)系统A本地事务执行完之后,发送个消息到MQ
2)这里会有个专门消费MQ的最大努力通知服务,这个服务会消费MQ然后写入数据库中记录下来,或者是放入个内存队列也可以,接着调用系统B的接口
3)要是系统B执行成功就ok了;要是系统B执行失败了,那么最大努力通知服务就定时尝试重新调用系统B,反复N次(比如说设置10次),最后还是不行就放弃.
收款通知,注册通知,微信支付宝付款等等,就是最大努力通知方案.(貌似是)
比如支付系统,订单页面客户支付成功之后先到微信那里,微信收到订单的钱,此时我支付系统还没这个钱,此时微信发起回调请求,调用我们支付回调的http接口,告诉我们钱到账了,然后支付系统给订单状态改过来,微信在调用回调接口的时候就会非常努力的回调,来回调用5次,这就是最大努力通知型
XA两阶段提交方案(XA方案,很少用)
所谓的 XA 方案,即:两阶段提交,有一个事务管理器的概念,负责协调多个数据库(资源管理器)的事务,事务管理器先问问各个数据库你准备好了吗?如果每个数据库都回复 ok,那么就正式提交事务,在各个数据库上执行操作;如果任何其中一个数据库回答不 ok,那么就回滚事务。
这种分布式事务方案,比较适合单块应用里,跨多个库的分布式事务,而且因为严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发的场景。如果要玩儿,那么基于 Spring + JTA 就可以搞定,自己随便搜个 demo 看看就知道了。
这个方案,我们很少用, 如果是一个系统操作多个数据库的时候,这个方案比较常见.不过这种方案在实际的生产环境是很少见的,因为这种操作是不合规的
现在的微服务都是一个大的系统分成几百个微服务,或者几十个微服务,我们的规范是要求每个微服务只能操作自己对应的一个数据库..如果你要操作别的服务对应的库,不允许直连别的服务的库.违反微服务架构的规范的,如果是几百个微服务交叉访问的话,那么就乱套了.这样的一套服务是没法治理的.到时候经常出现数据被别人改错,自己的库被别人用挂掉了.简直是一塌糊涂.
如果你要操作别的服务对应的库,不允许直连别的服务的库,违反微服务架构的规范,你随便交叉胡乱访问,几百个服务的话,全体乱套,这样的一套服务是没法管理的,没法治理的,可能会出现数据被别人改错,自己的库被别人写挂等情况。
如果你要操作别人的服务的库,你必须是通过调用别的服务的接口来实现,绝对不允许交叉访问别人的数据库。
XA方案在Java代码实现是 Spring+JTA就能实现.不过这种分布式事务严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发场景.
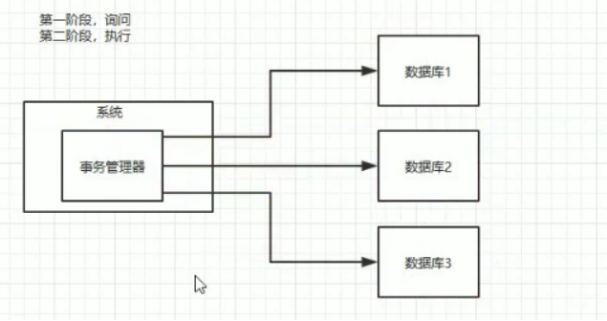
首先来看下2PC,翻译过来叫两阶段提交算法,它本身是一致强一致性算法,所以很适合用作数据库的分布式事务。其实数据库的经常用到的TCC本身就是一种2PC.
两阶段提交经常会用到分布式事务里面
回想下数据库的事务,数据库不管是MySQL还是MSSql,本身都提供的很完善的事务支持。
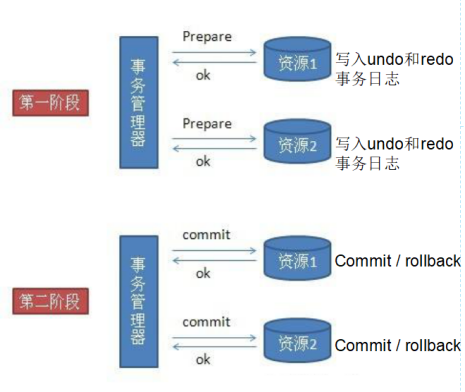
2PC就是两阶段提交,它会把整个事务分成两个阶段,第一个阶段叫做准备阶段,事务在请求都会发一个事务管理器,由事务管理器来管理各种各样的分布式事务,你提交 资源1 的时候,会先告诉事务管理器我已经准备好了,当你提交 资源2 的时候,也会告诉事务管理器我已经准备好了.
这个是第一阶段,事务会接收到一个个资源的请求,这个资源可以是数据库,如果是分布式事务的话,这个资源1也好,资源2也好,它都是一个个的事务,资源1或者资源2 会写undo和redo事务日志(undo和redo就是回退和回滚的日志),但是资源1和资源2都不会提交.
我们数据库里面怎么判断我们的资源是应该提交还是回滚?接收到commit就会提交,否则就是回滚.
第二阶段是当事务管理器接收到所有资源(资源1和资源2)的反馈的时候,此时两个资源都没报错啥的(说明执行成功了),此时事务管理器会发送commit命令分别给资源1和资源2,让这两个资源给我一个一个的提交,这个就是第二个阶段.
如果事务管理器发现commit失败了(至少一个资源失败了),它会发送rollback命令给两个资源, 让它们全部都回滚.这就是2PC的一个逻辑.
MySQL后面学分表分库的时候会讲到在innodb存储引擎,对数据库的修改都会写到undo和redo中,不只是数据库,很多需要事务支持的都会用到这个思路。
对一条数据的修改操作首先写undo日志,记录的数据原来的样子,接下来执行事务修改操作,把数据写到redo日志里面,万一捅娄子,事务失败了,可从undo里面回复数据。
不只是数据库,在很多企业里面,比如华为等提交数据库修改都回要求这样,你要新增一个字段,首先要把修改数据库的字段SQL提交给DBA(redo),这不够,还需要把删除你提交字段,把数据还原成你修改之前的语句也一并提交者叫(undo)
数据库通过undo与redo能保证数据的强一致性,要解决分布式事务的前提就是当个节点是支持事务的。
这在个前提下,2pc借鉴这失效,首先把整个分布式事务分两节点,首先第一阶段叫准备节点,事务的请求都发送给一个个的资源,这里的资源可以是数据库,也可以是其他支持事务的框架,他们会分别执行自己的事务,写日志到undo与redo,但是不提交事务。
当事务管理器收到了所以资源的反馈,事务都执行没报错后,事务管理器再发送commit指令让资源把事务提交,一旦发现任何一个资源在准备阶段没有执行成功,事务管理器会发送rollback,让所有的资源都回滚。这就是2pc,非常非常简单。
说他是强一致性的是他需要保证任何一个资源都成功,整个分布式事务才成功。
参考:
https://www.yuque.com/docs/share/cf1fefd3-815d-47e8-a25b-47e29d1b4d6a#
优点
缺点
同步阻塞,单点问题,数据不一致,容错性不好 ,性能太差
同步阻塞
在二阶段提交的过程中,所有的节点都在等待其他节点的响应(就是等待第一阶段事情都做完了才能接着执行第二阶段,否则都得等着.),无法进行其他操作。这种同步阻塞极大的限制了分布式系统的性能。
单点问题
协调者在整个二阶段提交过程中很重要,如果协调者(事务管理器)在提交阶段出现问题(比如事务管理器死机了),那么整个流程将无法运转。更重要的是,其他参与者将会处于一直锁定事务资源的状态中,而无法继续完成事务操作。
数据不一致
假设当协调者向所有的参与者发送commit请求之后,发生了局部网络异常,或者是协调者在尚未发送完所有 commit请求之前自身发生了崩溃,导致最终只有部分参与者收到了commit请求。这将导致严重的数据不一致问题。
什么是局部网络异常呢?
假如说资源A发送commit命令,资源B发送commit命令,资源C正在准备发送commit命令,忽然断电了,这个就是局部网络异常.
容错性不好
二阶段提交协议没有设计较为完善的容错机制,任意一个节点(事务管理器,多个资源都可能会失败)是失败都会导致整个事务的失败。
性能太差
XA两阶段提交方案性能不好,操作数据库的时候,多张被操作的表同时被锁定,当发送commit命令之后需要协调多个表提交事务处理,表被锁定的时间太长了,吞吐量比较差.,降低数据库性能百分之10左右.
三阶段提交
由于二阶段提交存在着诸如同步阻塞、单点问题,所以,研究者们在二阶段提交的基础上做了改进,提出了三阶段提交。
优缺点
改善了同步阻塞的时间(第一阶段确定了所有资源都是活着的,才去插入redo和undo日志)
改善了单点故障
缺点
同步阻塞,单点故障,数据不一致,容错机制不完善
TCC方案
TCC方案在电商、金融领域落地较多。TCC方案其实是两阶段提交的一种改进。其将整个业务逻辑的每个分支显式的分成了Try、Confirm、Cancel三个操作。Try部分完成业务的准备工作,confirm部分完成业务的提交,cancel部分完成事务的回滚。基本原理如下图所示。
TCC方案建议用阿里的seata来做.
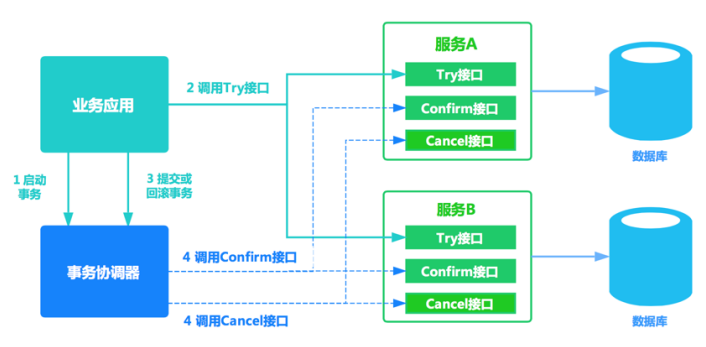
Try阶段:冻结银行资金
用户
Confirm阶段
1.在自己的库里材入数据
2,调用银行B的接口,扣款
3,调用银行C的接口,转账
数冠库
系统A
CanceI阶段:回浪
将银行B的扣的款给他加回去
银行B
银行C
数据库
数据库
TCC的全程是:Try、Confirm、Cancel。
这个其实是用到了补偿的概念,分为了三个阶段:
1)Try阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行锁定或者预留
2)Confirm阶段:这个阶段说的是在各个服务中执行实际的操作
3)Cancel阶段:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,就是执行已经执行成功的业务逻辑的回滚操作
给大家举个例子吧,比如说跨银行转账的时候,要涉及到两个银行的分布式事务,如果用TCC方案来实现,思路是这样的:
1)Try阶段:先把两个银行账户中的资金给它冻结住就不让操作了
2)Confirm阶段:执行实际的转账操作,A银行账户的资金扣减,B银行账户的资金增加
3)Cancel阶段:如果任何一个银行的操作执行失败,那么就需要回滚进行补偿,就是比如A银行账户如果已经扣减了,但是B银行账户资金增加失败了,那么就得把A银行账户资金给加回去(通过业务相关代码.)
这种方案说实话几乎很少用人使用,我们用的也比较少,但是也有使用的场景。因为这个事务回滚实际上是严重依赖于你自己写代码来回滚和补偿了(不同的回滚逻辑是不一样的),会造成补偿代码巨大,非常之恶心。
比如说我们,一般来说跟钱相关的,跟钱打交道的,支付、交易相关的场景,我们会用TCC,严格严格保证分布式事务要么全部成功,要么全部自动回滚,严格保证资金的正确性,在资金上出现问题.
比较适合的场景:这个就是除非你是真的一致性要求太高,是你系统中核心之核心的场景,比如常见的就是资金类的场景,那你可以用TCC方案了,自己编写大量的业务逻辑,自己判断一个事务中的各个环节是否ok,不ok就执行补偿/回滚代码。
而且最好是你的各个业务执行的时间都比较短。
但是说实话,一般尽量别这么搞,自己手写回滚逻辑,或者是补偿逻辑,实在太恶心了,那个业务代码很难维护。
![02.分布式事务几种方案[备用整理] - 图6](/uploads/projects/zjj1994@distributed/e78c641394e4005e21da6126a9fe3f9f.jpeg)
本地消息表(很少用)
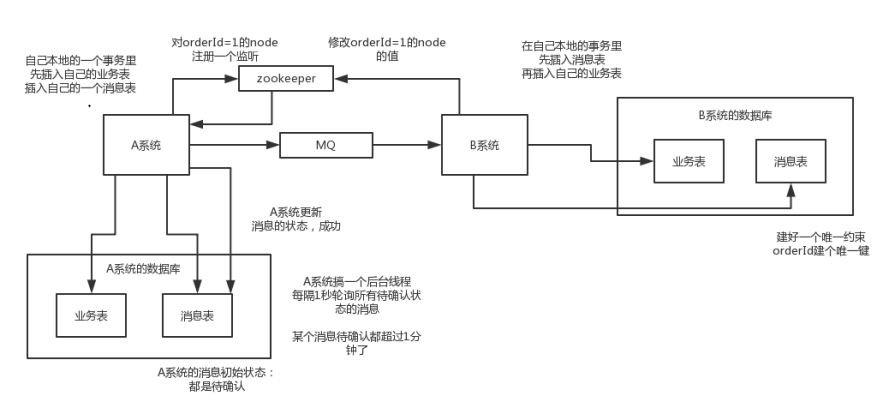
国外的ebay搞出来的这么一套思想
这个大概意思是这样的
1)A系统在自己本地一个事务里操作同时,插入一条数据到消息表(如果都插入成功代表我这里事务执行成功了)
2)接着A系统将这个消息发送到MQ中去
3)B系统接收到消息之后,在一个事务里,往自己本地消息表里先插入一条数据,同时执行其他的业务操作,如果这个消息已经被处理过了(MQ重复发送导致的),那么此时这个事务会回滚,这样保证不会重复处理消息.
4)B系统执行成功之后,就会更新自己本地消息表的状态以及A系统消息表的状态
5)如果B系统处理失败了,那么就不会更新消息表状态,那么此时A系统会定时扫描自己的消息表,如果有没处理的消息,会再次发送到MQ中去,让B再次处理
6)这个方案保证了最终一致性,哪怕B事务失败了,但是A会不断重发消息,直到B那边成功为止.
这个方案说实话最大的问题就在于严重依赖于数据库的消息表来管理事务啥的???这个会导致如果是高并发场景咋办呢?咋扩展呢?所以一般确实很少用.
LCN
LCN 名称是由早期版本的 LCN 框架命名,在设计框架之初的 1.0 ~ 2.0 的版本时框架设计的步骤是如下,各取其首字母得来的 LCN 命名。
锁定事务单元(lock)
确认事务模块状态(confirm)
通知事务(notify)
LCN默认是3pc事务,也可以替换成TCC事务,
框架定位
LCN 并不生产事务,LCN 只是本地事务的协调工
TX-LCN 定位于一款事务协调性框架,框架其本身并不操作事务,而是基于对事务的协调从而达到事务一致性的效果。
事务控制原理
TX-LCN 由两大模块组成, TxClient、TxManager,
TxClient 作为模块的依赖框架,提供 TX-LCN 的标准支持,TxManager 作为分布式事务的控制方。事务发起方或者参与反都由
TxClient 端来控制。
原理图:
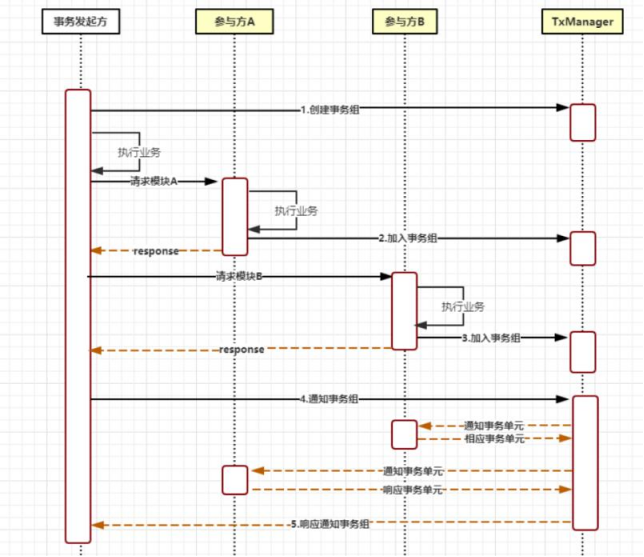
· 1.创建事务组
是指在事务发起方开始执行业务代码之前先调用 TxManager 创建事务组对象,然后拿到事务标示 GroupId 的过程。
· 2.加入事务组
添加事务组是指参与方在执行完业务方法以后,将该模块的事务信息通知给 TxManager 的操作。
· 3.通知事务组
是指在发起方执行完业务代码以后,将发起方执行结果状态通知给 TxManager,TxManager 将根据事务最终状态和事务组的信息
来通知相应的参与模块提交或回滚事务,并返回结果给事务发起方。

若有收获,就点个赞吧
0 人点赞
