数据建模

- 概念
- 是对真实世界进行抽象描述的一种工具和方法
- 三个过程:概念模型=>逻辑模型=>数据模型(第三范式)
- 功能需求 + 性能需求
- 实体属性
- 实体之间关系
- 搜索相关配置
- 索引模板
- 分片数量
- 索引mapping
- 字段配置
- 关系处理
字段建模
- 子段类型
- 字段类型
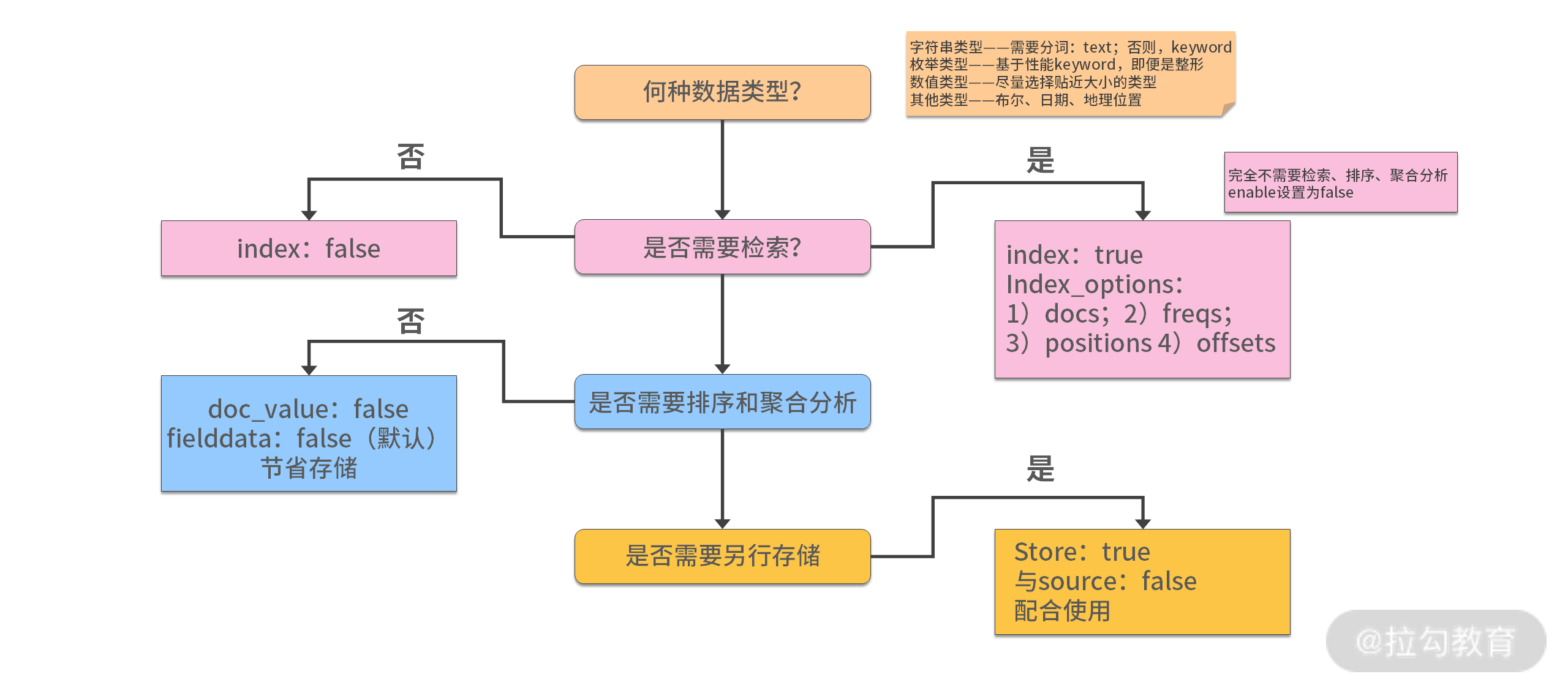
- text
- 会被analyzer分词
- 默认不支持聚合分析和排序。需要设置fielddata为true
- keyword
- 用于id、枚举及不需要分词的文本。例如电话号码、Email、性别等
- 适合Filter(精确匹配)、sorting和Aggregation
- 设置多字段类型
- 默认会为文本类型设置为text,并且设置一个keyword的子字段
- 在处理人类语言时,通过增加“英文”、”拼音“等分词器,提高搜索结构
- 数值类型
- 尽量选择贴近的类型。例如可以用byte,就不用long
- 枚举类型
- 设置keyword。即使数字,也设置keyword,获得更好的性能
- text
- 搜索
- 不需要被搜索的字段,字段index设置false
- 聚合及排序
- 如不需要检索、排序和聚合分析
- enabled设置false
- 如果不需要排序或者聚合分析
- doc_values/fielddata设置成false
- 当 doc_values 为 fasle 时,无法基于该字段排序、聚合、在脚本中访问字段值
- 当 doc_values 为 true 时,ES 会增加一个相应的正排索引,这增加的磁盘占用,也会导致索引数据速度慢一些
- 更新频繁,聚合查询频繁的keyword类型字段
- 推荐将eager_global_ordinals设置true,利用缓存你
- 如不需要检索、排序和聚合分析
- 字段类型
- 是否要搜索及分词
- 是否聚合及排序
- 是否要额外的存储
建模建议
- 子段类型
如何处理关联关系
- 优先考虑Object
- nested:当数据包含多数值对象(多个演员),同时有查询需求
- child/parent:关联文档更新非常频繁时
- 尤其应该避免多表关联。 Nested 嵌套可以使查询慢几倍,而 Join 父子关系可以使查询慢数百倍。
- 避免过多字段
- 一个文档中最好避免大量的字段
- 过多字段不容易维护
- Mapping信息保存在cluster state中,数据量过大,对集群性能会有影响(cluster state信息需要和多有的节点同步)
- 删除或修改需要reindex
- 默认最大字段数是1000,可以设置index.mapping.total_fields.limt限定最大字段数
- 一个文档中最好避免大量的字段
- 避免正则查询
- 正则、通配符查询、前缀查询属于term查询,但性能不好
- 特别是将通配符放在开头,会导致性能灾难
- 避免空值引起的聚合不准
- 设置字段的null_value
为索引的mapping加入meta信息
基于业务角度建模

若有收获,就点个赞吧
0 人点赞
