Pandas的应用-4
DataFrame的应用
数据分析
经过前面的学习,我们已经将数据准备就绪而且变成了我们想要的样子,接下来就是最为重要的数据分析阶段了。当我们拿到一大堆数据的时候,如何从数据中迅速的解读出有价值的信息,这就是数据分析要解决的问题。首先,我们可以获取数据的描述性统计信息,通过描述性统计信息,我们可以了解数据的集中趋势和离散趋势。
例如,我们有如下所示的学生成绩表。
import numpy as npimport pandas as pdscores = np.random.randint(50, 101, (5, 3))names = ('关羽', '张飞', '赵云', '马超', '黄忠')courses = ('语文', '数学', '英语')df = pd.DataFrame(data=scores, columns=courses, index=names)df
输出:
语文 数学 英语关羽 96 72 73张飞 72 70 97赵云 74 51 79马超 100 54 54黄忠 89 100 88
我们可以通过DataFrame对象的方法mean、max、min、std、var等方法分别获取每个学生或每门课程的平均分、最高分、最低分、标准差、方差等信息,也可以直接通过describe方法直接获取描述性统计信息,代码如下所示。
计算每门课程成绩的平均分。
df.mean()
输出:
语文 86.2数学 69.4英语 78.2dtype: float64
计算每个学生成绩的平均分。
df.mean(axis=1)
输出:
关羽 80.333333张飞 79.666667赵云 68.000000马超 69.333333黄忠 92.333333dtype: float64
计算每门课程成绩的方差。
df.var()
输出:
语文 161.2数学 379.8英语 265.7dtype: float64
说明:通过方差可以看出,数学成绩波动最大,最不稳定。
获取每门课程的描述性统计信息。
df.describe()
输出:
语文 数学 英语count 5.000000 5.000000 5.000000mean 86.200000 69.400000 78.200000std 12.696456 19.488458 16.300307min 72.000000 51.000000 54.00000025% 74.000000 54.000000 73.00000050% 89.000000 70.000000 79.00000075% 96.000000 72.000000 88.000000max 100.000000 100.000000 97.000000
排序和Top-N
如果需要对数据进行排序,可以使用DataFrame对象的sort_values方法,该方法的by参数可以指定根据哪个列或哪些列进行排序,而ascending参数可以指定升序或是降序。例如,下面的代码展示了如何将学生表按语文成绩排降序。
df.sort_values(by='语文', ascending=False)
输出:
语文 数学 英语马超 100 54 54关羽 96 72 73黄忠 89 100 88赵云 74 51 79张飞 72 70 97
如果DataFrame数据量很大,排序将是一个非常耗费时间的操作。有的时候我们只需要获得排前N名或后N名的数据,这个时候其实没有必要对整个数据进行排序,而是直接利用堆结构找出Top-N的数据。DataFrame的nlargest和nsmallest方法就提供对Top-N操作的支持,代码如下所示。
找出语文成绩前3名的学生信息。
df.nlargest(3, '语文')
输出:
语文 数学 英语马超 100 54 54关羽 96 72 73黄忠 89 100 88
找出数学成绩最低的3名学生的信息。
df.nsmallest(3, '数学')
输出:
语文 数学 英语赵云 74 51 79马超 100 54 54张飞 72 70 97
分组聚合操作
我们先从 Excel 文件中读取一组销售数据,然后再为大家演示如何进行分组聚合操作。
df = pd.read_excel('2020年销售数据.xlsx')df.head()
说明:如果需要上面例子中的 Excel 文件,可以通过下面的阿里云盘地址进行获取,该文件在“我的分享”下面的“数据集”目录中。地址:https://www.aliyundrive.com/s/oPi7DRAVKRm。
输出:
销售日期 销售区域 销售渠道 销售订单 品牌 售价 销售数量0 2020-01-01 上海 拼多多 182894-455 八匹马 99 831 2020-01-01 上海 抖音 205635-402 八匹马 219 292 2020-01-01 上海 天猫 205654-021 八匹马 169 853 2020-01-01 上海 天猫 205654-519 八匹马 169 144 2020-01-01 上海 天猫 377781-010 皮皮虾 249 61
如果我们要统计每个销售区域的销售总额,可以先通过“售价”和“销售数量”计算出销售额,为DataFrame添加一个列,代码如下所示。
df['销售额'] = df['售价'] * df['销售数量']df.head()
输出:
销售日期 销售区域 销售渠道 销售订单 品牌 售价 销售数量 销售额0 2020-01-01 上海 拼多多 182894-455 八匹马 99 83 82171 2020-01-01 上海 抖音 205635-402 八匹马 219 29 63512 2020-01-01 上海 天猫 205654-021 八匹马 169 85 143653 2020-01-01 上海 天猫 205654-519 八匹马 169 14 23664 2020-01-01 上海 天猫 377781-010 皮皮虾 249 61 15189
然后再根据“销售区域”列对数据进行分组,这里我们使用的是DataFrame对象的groupby方法。分组之后,我们取“销售额”这个列在分组内进行求和处理,代码和结果如下所示。
df.groupby('销售区域').销售额.sum()
输出:
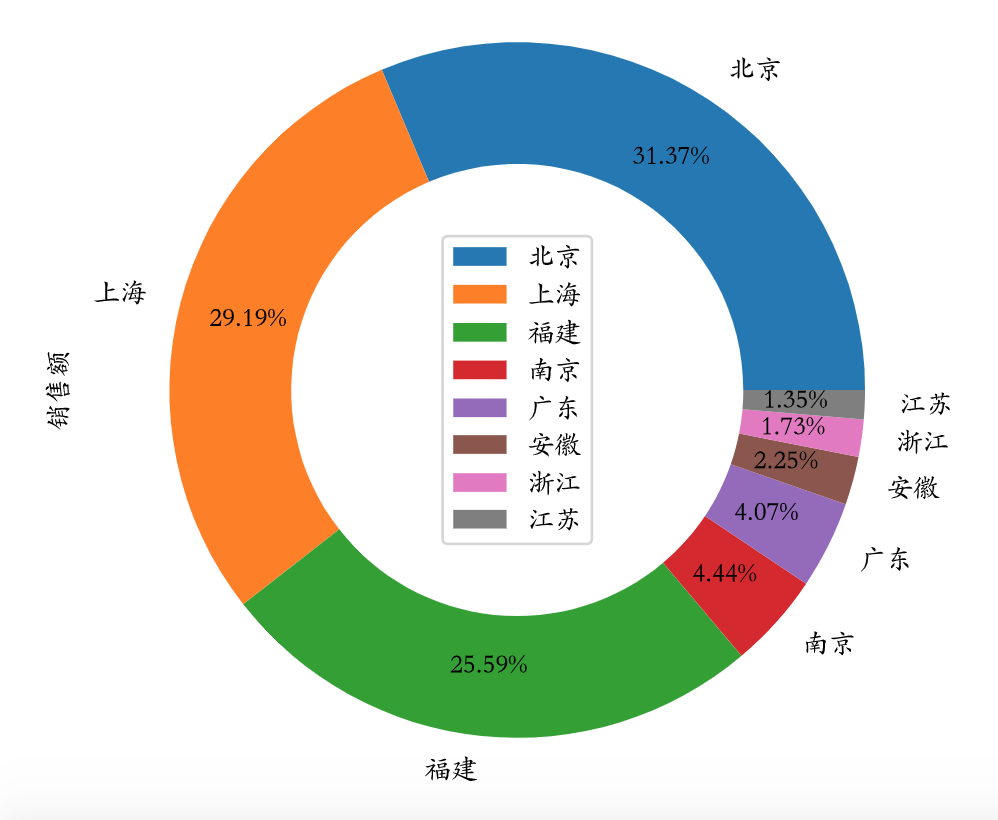
销售区域上海 11610489北京 12477717南京 1767301安徽 895463广东 1617949江苏 537079浙江 687862福建 10178227Name: 销售额, dtype: int64
如果我们要统计每个月的销售总额,我们可以将“销售日期”作为groupby`方法的参数,当然这里需要先将“销售日期”处理成月,代码和结果如下所示。
df.groupby(df['销售日期'].dt.month).销售额.sum()
输出:
销售日期1 54098552 46084553 41649724 39967705 32390056 28179367 35013048 29481899 263296010 237538511 238528312 1691973Name: 销售额, dtype: int64
接下来我们将难度升级,统计每个销售区域每个月的销售总额,这又该如何处理呢?事实上,groupby方法的第一个参数可以是一个列表,列表中可以指定多个分组的依据,大家看看下面的代码和输出结果就明白了。
df.groupby(['销售区域', df['销售日期'].dt.month]).销售额.sum()
输出:
销售区域 销售日期上海 1 16791252 16895273 10611934 10821875 8411996 7854047 8639068 7349379 110769310 41210811 82516912 528041北京 1 18782342 18077873 13606664 12059895 8073006 12164327 12190838 6457279 39007710 67160811 67866812 596146南京 7 84103210 71096212 215307安徽 4 3413085 554155广东 3 3881808 4693909 36519111 395188江苏 4 537079浙江 3 2483548 439508福建 1 18524962 11111413 11065794 8302075 10363516 8161007 5772838 6586279 76999910 58070711 48625812 352479Name: 销售额, dtype: int64
如果希望统计出每个区域的销售总额以及每个区域单笔金额的最高和最低,我们可以在DataFrame或Series对象上使用agg方法并指定多个聚合函数,代码和结果如下所示。
df.groupby('销售区域').销售额.agg(['sum', 'max', 'min'])
输出:
sum max min销售区域上海 11610489 116303 948北京 12477717 133411 690南京 1767301 87527 1089安徽 895463 68502 1683广东 1617949 120807 990江苏 537079 114312 3383浙江 687862 90909 3927福建 10178227 87527 897
如果希望自定义聚合后的列的名字,可以使用如下所示的方法。
df.groupby('销售区域').销售额.agg(销售总额='sum', 单笔最高='max', 单笔最低='min')
输出:
销售总额 单笔最高 单笔最低销售区域上海 11610489 116303 948北京 12477717 133411 690南京 1767301 87527 1089安徽 895463 68502 1683广东 1617949 120807 990江苏 537079 114312 3383浙江 687862 90909 3927福建 10178227 87527 897
如果需要对多个列使用不同的聚合函数,例如“统计每个销售区域销售额的平均值以及销售数量的最低值和最高值”,我们可以按照下面的方式来操作。
df.groupby('销售区域')[['销售额', '销售数量']].agg({'销售额': 'mean', '销售数量': ['max', 'min']})
输出:
销售额 销售数量mean max min销售区域上海 20622.538188 100 10北京 20125.350000 100 10南京 22370.898734 100 11安徽 26337.147059 98 16广东 32358.980000 98 10江苏 29837.722222 98 15浙江 27514.480000 95 20福建 18306.163669 100 10
透视表和交叉表
上面的例子中,“统计每个销售区域每个月的销售总额”会产生一个看起来很长的结果,在实际工作中我们通常把那些行很多列很少的表成为“窄表”,如果我们不想得到这样的一个“窄表”,可以使用DataFrame的pivot_table方法或者是pivot_table函数来生成透视表。透视表的本质就是对数据进行分组聚合操作,根据 A 列对 B 列进行统计,如果大家有使用 Excel 的经验,相信对透视表这个概念一定不会陌生。例如,我们要“统计每个销售区域的销售总额”,那么“销售区域”就是我们的 A 列,而“销售额”就是我们的 B 列,在pivot_table函数中分别对应index和values参数,这两个参数都可以是单个列或者多个列。
pd.pivot_table(df, index='销售区域', values='销售额', aggfunc='sum')
输出:
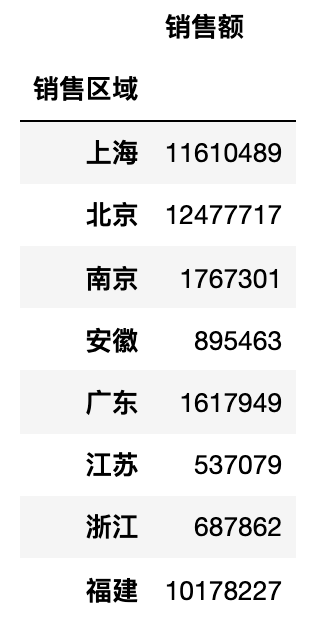
注意:上面的结果操作跟之前用
groupby的方式得到的结果有一些区别,groupby操作后,如果对单个列进行聚合,得到的结果是一个Series对象,而上面的结果是一个DataFrame对象。
如果要统计每个销售区域每个月的销售总额,也可以使用pivot_table函数,代码如下所示。
pd.pivot_table(df, index=['销售区域', df['销售日期'].dt.month], values='销售额', aggfunc='sum')
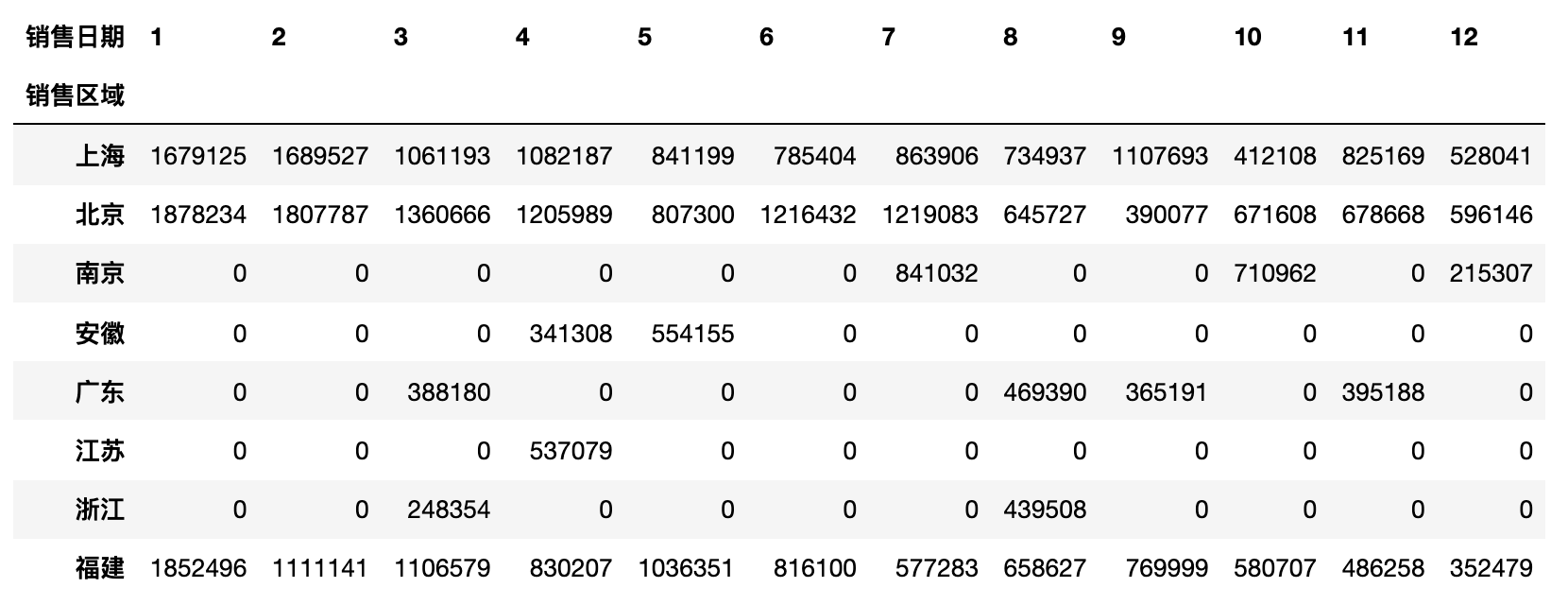
上面的操作结果是一个DataFrame,但也是一个长长的“窄表”,如果希望做成一个行比较少列比较多的“宽表”,可以将index参数中的列放到columns参数中,代码如下所示。
pd.pivot_table(df, index='销售区域', columns=df['销售日期'].dt.month,values='销售额', aggfunc='sum', fill_value=0)
说明:
pivot_table函数的fill_value=0会将空值处理为0。
输出:
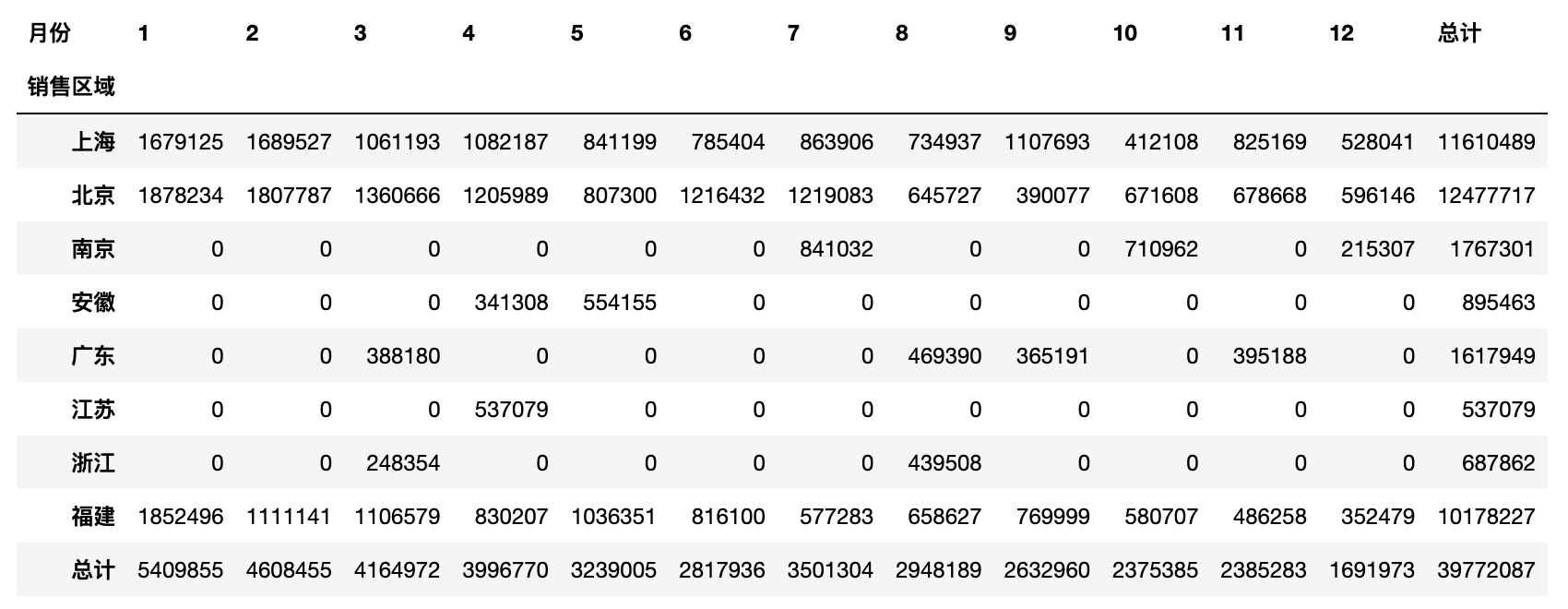
使用pivot_table函数时,还可以通过添加margins和margins_name参数对分组聚合的结果做一个汇总,具体的操作和效果如下所示。
df['月份'] = df['销售日期'].dt.monthpd.pivot_table(df, index='销售区域', columns='月份',values='销售额', aggfunc='sum', fill_value=0,margins=True, margins_name='总计')
输出:
交叉表就是一种特殊的透视表,它不需要先构造一个DataFrame对象,而是直接通过数组或Series对象指定两个或多个因素进行运算得到统计结果。例如,我们要统计每个销售区域的销售总额,也可以按照如下所示的方式来完成,我们先准备三组数据。
sales_area, sales_month, sales_amount = df['销售区域'], df['月份'], df['销售额']
使用crosstab函数生成交叉表。
pd.crosstab(index=sales_area, columns=sales_month, values=sales_amount, aggfunc='sum').fillna(0).applymap(int)
说明:上面的代码使用了
DataFrame对象的fillna方法将空值处理为0,再使用applymap方法将数据类型处理成整数。
数据可视化
一图胜千言,我们对数据进行透视的结果,最终要通过图表的方式呈现出来,因为图表具有极强的表现力,能够让我们迅速的解读数据中隐藏的价值。和Series一样,DataFrame对象提供了plot方法来支持绘图,底层仍然是通过matplotlib库实现图表的渲染。关于matplotlib的内容,我们在下一个章节进行详细的探讨,这里我们只简单的讲解plot方法的用法。
例如,我们想通过一张柱状图来比较“每个销售区域的销售总额”,可以直接在透视表上使用plot方法生成柱状图。我们先导入matplotlib.pyplot模块,通过修改绘图的参数使其支持中文显示。
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = 'FZJKai-Z03S'
说明:上面的
FZJKai-Z03S是我电脑上已经安装的一种支持中文的字体的名称,字体的名称可以通过查看用户主目录下.matplotlib文件夹下名为fontlist-v330.json的文件来获得,而这个文件在执行上面的命令后就会生成。
使用魔法指令配置生成矢量图。
%config InlineBackend.figure_format = 'svg'
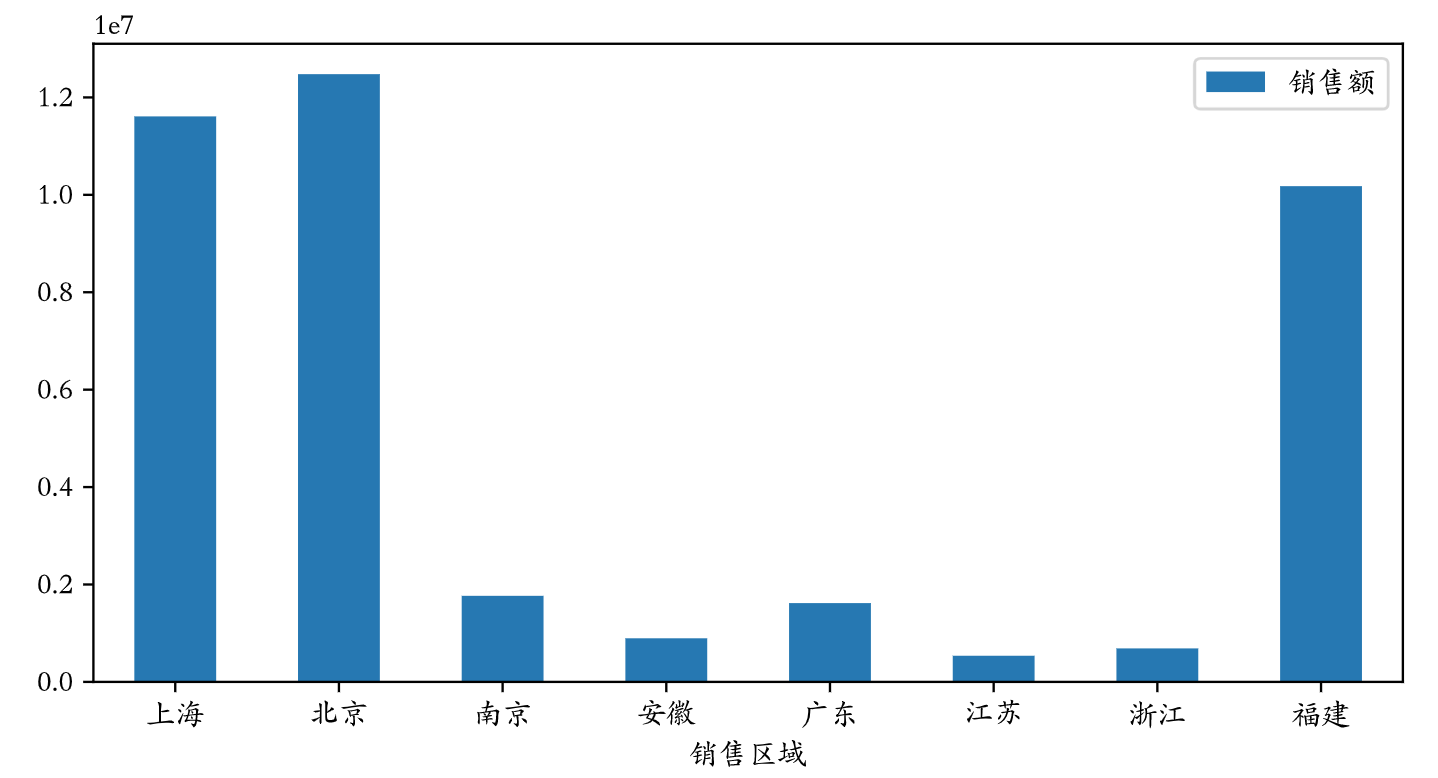
绘制“每个销售区域销售总额”的柱状图。
temp = pd.pivot_table(df, index='销售区域', values='销售额', aggfunc='sum')temp.plot(figsize=(8, 4), kind='bar')plt.xticks(rotation=0)plt.show()
说明:上面的第3行代码会将横轴刻度上的文字旋转到0度,第4行代码会显示图像。
输出:
如果要绘制饼图,可以修改plot方法的kind参数为pie,然后使用定制饼图的参数对图表加以定制,代码如下所示。
temp.sort_values(by='销售额', ascending=False).plot(figsize=(6, 6), kind='pie', y='销售额',autopct='%.2f%%', pctdistance=0.8,wedgeprops=dict(linewidth=1, width=0.35))plt.legend(loc='center')plt.show()
输出:

若有收获,就点个赞吧
0 人点赞
