Buffer Pool基本结构
Buffer Pool会不会产生内存碎片
因为Buffer Pool大小是你自己定的,很可能Buffer Pool划分完全部的缓存页和描述数据块之后,还剩一点点的内存,这一点点的内存放不下任何一个缓存页了,所以这点内存就只能放着不能用,这就是内存碎片。
怎么减少内存碎片?
数据库在Buffer Pool中划分缓存页的时候,会让所有的缓存页和描述数据块都紧密的挨在一起,这样尽可能减少内存浪费,就可以尽可能的减少内存碎片的产生了。
如果你的Buffer Poo里的缓存页是东一块西一块,那么必然导致缓存页的内存之间有很多内存空隙,这就会有大量的内存碎片。
从磁盘读取数据页到Buffer Pool的时候,free链表有什么用
数据库启动时,是如何初始化Buffer Pool的?
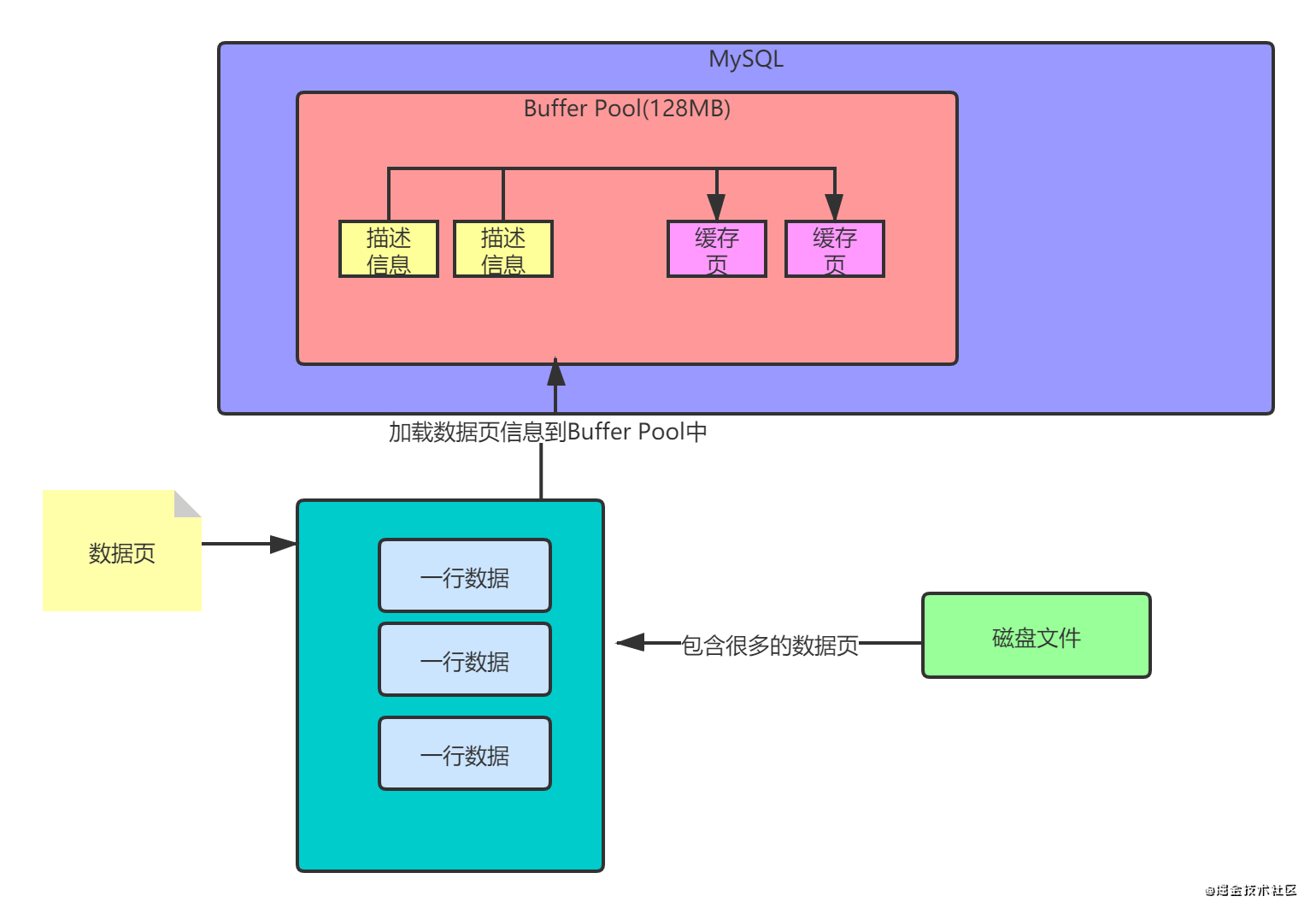
Buffer Pool中包含多个缓存页,每个缓存页都有对应的缓存页描述信息。
- 数据库只要一启动,就会按照指定的Buffer Pool大小,稍微再加大一点,去找操作系统申请一块内存区域,作为Buffer Pool的内存空间。
- 当内存区域申请完毕,数据库就会按照默认的缓存页的16KB大小以及对应的800字节左右的描述数据的大小,在Buffer Pool中划分出一个个的缓存页和他们对应的描述数据
此时缓存页都是空的,要等数据库运行起来以后,执行数据库的增删改查操作,才会把数据对应的页从磁盘中读取出来,放到Buffer Pool的缓存页。
如何知道哪些缓存页是空闲的
数据库执行增删改查操作,会不停地从磁盘文件中获取数据页,并将其放到Buffer Pool的缓存页中,从而将数据缓存起来,以后的增删改查操作就在缓存页中完成了。
因此,从磁盘中读取数据页放入缓存页,必然涉及到一个问题,哪些缓存页是空闲的。
因为默认情况下,数据页和缓存页的大小是一一对应的,都是16KB,一个数据页对应一个缓存页。
数据库会为Buffer Pool设计一个free链表,是一个双向链表结构,在free链表中,每个节点就是一个空闲的缓存页的描述数据块的地址。
- 只要缓存页是空闲的,那么他们对应的描述数据块就会加入到这个free链表中,每个节点都会双向链接自己的前后节点,组成一个双向链表。
- 除此之外,这个free链表有一个基础节点,他会引用链表的头节点和尾节点,里面还存储了链表中有多少个描述数据块的节点,也就是有多少个空闲的缓存页。
free链表占用多少空间
free链表,本身就是由Buffer Pool里的描述数据块组成的,可以认为是每个描述数据块里都有两个指针,一个是free pre,一个是free next,分别指向自己的上一个free链表的节点,以及下一个free链表的节点。
通过Buffer Pool中的描述数据块的free_pre和freenext两个指针,就可以把所有的描述数据块串成一个free链表。
对于free链表而言,只有一个基础节点是不属于Buffer Pool的,他是40字节大小的一个节点,里面就存放了free链表的头节点的地址,尾节点的地址,还有free链表里当前有多少个节点。如何将磁盘中的数据页读取到Buffer Pool中的缓存页中
- 首先从free链表中读取一个描述数据块(看到房东发的房源信息),然后获取到这个描述数据块对应的空闲缓存页(发现了房子的地址)
- 将磁盘的数据页读取到对应的缓存页中(把东西搬进去入住),同时将一些描述数据写入缓存页的描述数据块中(表示我住进来了,这是我的锅碗瓢盆)
- 将描述数据块从 free链表中移除(房东 下线了 房源信息,房子已经租出去了)
如何知道数据页 有没有被缓存
我们在执行增删改查的时候,肯定是先看这个数据页有没有被缓存,如果没被缓存就从free链表中找到一个空闲的缓存页,从磁盘上读取数据页写入缓存页,写入描述数据,从free链表中移除这个描述数据块。
但是如果数据页已经被缓存了,那么就会直接使用了。哈希表
数据库还会有一个哈希表数据结构,他会用表空间号+数据页号,作为一个key,然后缓存页的地址作为value。当你要使用一个数据页的时候,通过“表空间号+数据页号”作为key去这个哈希表里查一下,如果没有就读取数据页,如果已经有了,就说明数据页已经被缓存了。
每次读取一个数据页到缓存之后,都会在这个哈希表中写入一个key-value对,key就是表空间号+数据页号,value就是缓存页的地址,那么下次如果你再使用这个数据页,就可以从哈希表里直接读取出来,数据页已经被放入一个缓存页了。表空间、数据页
我们在SQL语句里都是用到的是表和行的概念,但是之前我们提到的表空间、数据页,他们之间的关系是什么呢?其实简单来讲,一个是逻辑概念,一个是物理概念。
表、列和行,都是逻辑概念,我们只知道数据库里有一个表,表里有几个字段,有多少行,但是这些表里的数据,在数据库的磁盘上如何存储的,你知道吗?我们是不关注的,所以他们都是逻辑上的概念。
表空间、数据页,这些东西,都是物理上的概念,实际上在物理层面,你的表里的数据都放在一个表空间中,表空间是由一堆磁盘上的数据文件组成的,这些数据文件里都存放了你表里的数据,这些数据是由一个一个的数据页组织起来的,这些都是物理层面的概念,这就是他们之间的区别。flush链表
在内存里更新的脏页的数据,都是要被刷新回磁盘文件的。
但是不可能所有的缓存页都刷回磁盘的,因为有的缓存页可能是因为查询的时候被读取到Buffer Pool里去的,可能根本没修改过!
所以数据库在引入了另外一个跟free链表类似的flush链表,这个flush链表本质也是通过缓存页的描述数据块中的两个指针,让被修改过的缓存页的描述数据块,组成一个双向链表。
凡是被修改过的缓存页,都会把他的描述数据块加入到flush链表中去,flush的意思就是这些都是脏页,后续都是要flush刷新到磁盘上去的(需要异步刷盘)
当Buffer Pool中的缓存页不够的时候,如何基于LRU算法淘汰部分缓存?
随着你不停的把磁盘上的数据页加载到空闲的缓存页里去,free链表中的空闲缓存页是不是会越来越少?
因为只要你把一个数据页加载到一个空闲缓存页里去,free链表中就会减少一个空闲缓存页。
所以,当你不停地把磁盘上的数据页加载到空闲缓存页里去,free链表中不停的移除空闲缓存页,迟早有那么一瞬间,你会发现free链表中已经没有空闲缓存页了。
这个时候,当你还要加载数据页到一个空闲缓存页的时候,怎么办呢?
如果所有的缓存页都被塞了数据了,此时就无法从磁盘上加载新的数据页到缓存页里去了,那么此时你只有一个办法,就是淘汰掉一些缓存页。
淘汰缓存页:将某个缓存页里被修改的数据,刷回磁盘中的数据页,然后再清空当前缓存页,成为一个空闲的缓存页。
然后再将磁盘上新的需要加载的数据页 加载到 这个空闲的缓存页中。
缓存命中率
假设现在有两个缓存页,一个缓存页的数据,经常会被修改和查询,比如在100次请求中,有30次都是在查询和修改这个缓存页里的数据。那么此时我们可以说这种情况下,缓存命中率很高为什么呢?因为100次请求中,30次都可以操作缓存,不需要从磁盘加载数据,这个缓存命中率就比较高了。
另外一个缓存页里的数据,就是刚从磁盘加载到缓存页之后,被修改和查询过1次,之后100次请求中没有一次是修改和查询这个缓存页的数据的,那么此时我们就说缓存命中率有点低,因为大部分请求可能还需要走磁盘查询数据,他们要操作的数据不在缓存中。
所以针对上述两个缓存页,假设此时让你做一个抉择,要把其中缓存页的数据刷入到磁盘去,腾出来一个空闲的缓存页,此时你会选择谁?
当然是选择第二个缓存页刷入磁盘
LRU
使用LRU链表来判断哪些缓存页是不常用的 ,Least Recently Used(最近最少使用)
- 假设我们从磁盘加载一个数据页到缓存页的时候,就把这个缓存页的描述数据块放到LRU链表头部去,那么只要有数据的缓存页,他都会在LRU里了,而且最近被加载数据的缓存页,都会放到LRU链表的头部。
- 然后假设某个缓存页的描述数据块本来在LRU链表的尾部,后续你只要查询或者修改了这个缓存页的数据,也要把这个缓存页挪动到LRU链表的头部去,也就是说最近被访问过的缓存页,一定在LRU链表的头部
这样的话,当你的缓存页没有一个空闲的时候,你是不是要找出来那个最近最少被访问的缓存页去刷入磁盘? 此时你就直接在LRU链表的尾部找到一个缓存页,他一定是最近最少被访问的那个缓存页!然后你就把LRU链表尾部的那个缓存页刷入磁盘中,然后把你需要的磁盘数据页加载到腾出来的空闲缓存页中就可以。
简单的LRU链表在Buffer Pool实际运行中,可能导致哪些问题?
预读机制带来的问题
首先会带来隐患的就是MySQL的预读机制,所谓预读机制,说的就是当你从磁盘上加载一个数据页的时候,他可能会连带着把这个数据页相邻的其他数据页,也加载到缓存里去。
假设现在有两个空闲缓存页,然后在加载一个数据页的时候,连带着把他的一个相邻的数据页也加载到缓存里去了,正好每个数据页放入一个空闲缓存页! 但是接下来呢,实际上只有一个缓存页是被访问了,另外一个通过预读机制加载的缓存页,其实并没有人访问,此时这两个缓存页可都在LRU链表的前面。
哪些情况会触发MySQL的预读机制
- 有一个参数是
innodb_read ahead_threshold,默认值是56,意思是如果顺序访问了一个区里的多个数据页,访问的数据页的数量超过了这个阈值,此时就会触发预读机制,把下一个相邻区中的所有数据页都加载到缓存里去 - 如果Buffer Pool里缓存了一个区里的13个连续的数据页,而且这些数据页都是比较频繁会被访问的,此时就会直接触发预读机制,把这个区里的其他的数据页都加载到缓存里去
这个机制是通过参数innodb random read ahead来控制的,他默认是OFF,也就是这个规则是关闭的。
所以默认情况下,主要是第一个规则可能会触发预读机制,一下子把很多相邻区里的数据页加载到缓存里去,这些缓存页如果一下子都放在LRU链表的前面,而且他们其实并没什么人会访问的话,就会导致本来就在缓存里的一些频繁被访问的缓存页在LRU链表的尾部。
一旦要把一些缓存页淘汰掉,刷入磁盘,腾出来空闲缓存页,就会如上所述,把LRU链表尾部一些频繁被访问的缓存页给刷入磁盘和清空掉了!这是完全不合理的!
全表扫描引发的问题
全表扫描,意思就是类似如下的SQL语句:SELECT*FROM USERS
此时他没加任何一个where条件,会导致他直接一下子把这个表里所有的数据页,都从磁盘加载到Buffer Pool里去。
此时可能会一下子就把这个表的所有数据页都依次装入各个缓存页里去!
此时可能LRU链表中排在前面的一大串缓存页,都是全表扫描加载进来的缓存页!
那么如果这次全表扫描过后,后续几乎没用到这个表里的数据呢?
此时LRU链表的尾部,可能全部都是之前一直被频繁访问的那些缓存页!
然后当你要淘汰掉一些缓存页腾出空间的时候,就会把LRU链表尾部一直被频繁访问的缓存页给淘汰掉了,而留下了之前全表扫描加载进来的大量的不经常访问的缓存页!
概括
如果使用简单的LRU链表的机制,其实是漏洞百出的,因为很可能预读机制,或者全表扫描的机制,都会一下子把大量未来可能不怎么访问的数据页加载到缓存页里去,然后LRU链表的前面全部是这些未来可能不怎么会被访问的缓存页!
而真正之前一直频繁被访问的缓存页可能此时都在LRU链表的尾部了!
如果此时此刻,需要把一些缓存页刷入磁盘,腾出空间来加载新的数据页,那么此时就只能把LRU链表尾部那些一直频繁被访问的缓存页给刷入磁盘了!
为什么MySQL要设计预读机制
加载一个数据页到缓存里去的时候,为什么要把一些相邻的数据页也加载到缓存里去呢?这么做的意义在哪里?是为了应对什么样的一个场景?
为了提升性能。
假设你读取了数据页01到缓存页里去,那么好,接下来有可能会接着顺序读取数据页01相邻的数据页 02到缓存页里去,这个时候,是不是可能在读取数据页02的时候要再次发起一次磁盘IO?
所以为了优化性能,MySQL才设计了预读机制,也就是说如果在一个区内,你顺序读取了好多数据页了,比如数据页01~数据页56都被你依次顺序读取了,MySQL会判断,你可能接着会继续顺序读取后面的数据页。
那么此时他就干脆提前把后续的一大堆数据页(比如数据页57~数据页72)都读取到Buffer Pool里去,那么后续你再读取数据页60的时候,是不是就可以直接从Buffer Pool里拿到数据了?
当然理想是上述那样,很丰满,但是现实可能很骨感。你预读的一大堆数据页要是占据了LRU链表的前面部分,可能这些预读的数据页压根儿后续没人会使用,那你这个预读机制就是在捣乱了。
基于冷热数据分离的方案,优化LRU算法
为了解决简单的LRU链表的问题,真正MySQL在设计LRU链表的时候,采取的实际上是冷热数据分离的思想。
之前一系列的问题,说白了,都是因为所有缓存页都混在一个LRU链表里才导致的。
所以真正的LRU链表,会被拆分为两个部分,一部分是热数据,一部分是冷数据,这个冷热数据的比例是由innodb old blocks pct参数控制的,他默认是37,也就是说冷数据占比37%。
当数据页第一次被加载到缓存页时,缓存页会被放在LRU链表的冷数据区域的链表头部;
MySQL设定了一个规则,设计了一个innodb old blocks time参数,默认值1000(单位是毫秒)
必须是一个数据页被加载到缓存页之后,在1s之后,你访问这个缓存页,他才会被挪动到热数据区域的链表头部去。
因为假设加载了一个数据页到缓存页,然后过了1s之后你还访问了这个缓存页,说明你后续很可能会经常要访问它,这个时间限制就是1s,因此只有1s后你访问了这个缓存页,他才会给你把缓存页放到热数据区域的链表头部去。(对热数据的判断)
冷热分离的LRU,是如何解决问题的?
- 对于预读机制和全表扫描加载进来的缓存页,会放在LRU链表的冷数据区域的前面
会一直放在冷数据区域吗?
如果仅仅是一个全表扫描的查询,此时你肯定是在1s内就把一大堆缓存页加载进来,然后就访问了这些缓存页一下,通常这些操作1s内就结束了。 基于目前的机制,可以确定,那些缓存页不会从冷数据区域转移到热数据区域的! 除非你在冷数据区域里的缓存页,在1s之后还被人访问了,那么此时他们就会判定为未来可能会被频繁访问的缓存页,然后移动到热数据区域的链表头部去!
如果缓存页不够了(不存在空闲缓存页),那怎么办呢?
直接找到LRU链表中的冷数据区域的尾部的缓存页,它们肯定是之前被加载进来的,而且加载进来1s过后都没人访问过(确定你就是冷数据);此时就直接淘汰冷数据区域的尾部的缓存页,刷入磁盘
总结一下:
在这样的一套缓存页分冷热数据的加载方案以及冷数据转化为热数据的时间限制方案,还有就是淘汰缓存页的时候优先淘汰冷数据区域的方案,基于这套方案,大家会发现,之前发现的问题,完美的被解决了。
因为那种预读机制以及全表扫描机制加载进来的数据页,大部分都会在1秒之内访问一下,之后可能再也不被访问了,所以这种缓存页基本上都会留在冷数据区域里。然后频繁访问的缓存页还是会留在热数据区域里。
当你要淘汰缓存的时候,优先就是会选择冷数据区域的尾部的缓存页,这就是非常合理的!它不会让刚加载进来的缓存页占据LRU链表的头部,频繁访问的缓存页在LRU链表的尾部,淘汰的时候淘汰尾部的频繁访问的缓存页了!
冷热数据隔离,尽可能让冷数据和热数据分来,避免冷数据影响热数据的访问。
缓存设计中对冷热隔离思想的运用
对于这种缓存中同时包含冷热数据的场景,如果你是在Redis中放了你业务系统的很多缓存数据,其中也是冷热数据都有的,此时可能会有什么问题?
那么针对这样的一个问题,你是否可以考虑在你自己的缓存设计中,运用冷热隔离的思想来优化重构呢?
常见的一个场景就是电商系统里的商品缓存数据,假设你有1亿个商品,然后只要查询商品的时候发现商品不在缓存里,就给他放到缓存里去,你要这么搞的话,必然导致大量的不怎么经常访问的商品会被放在Redis缓存里! 经常被访问的商品其实就是热数据,不经常被访问的商品其实就是冷数据,我们应该尽量让Redis里放的都是经常访问的热数据,而不是大量的冷数据。因为你放一大堆不怎么经常访问的商品在Redis里,那么他占用了很多内存,而且后续还不怎么会访问到他们!(冷数据占用内存,是不合理的,因为内存是有限的资源,应该尽可能地分配给热数据)
所以我们在设计缓存机制的时候,经常会考虑热数据的缓存预加载也就是说,每天统计出来哪些商品被访问的次数最多,然后晚上的时候,系统启动一个定时作业,把这些热门商品的数据(一定是非实时更新的数据项),预加载到Redis里;那么第二天对热门商品的访问就自然会优先走Redis缓存。(缓存预热)
个人理解:其实Redis LRU的内存淘汰策略,本事就是一种冷热数据处理方式,最近最少访问的数据,将其淘汰掉。
MySQL是如何将LRU链表的使用性能优化到极致的?
LRU链表的热数据区域是如何优化的?
在热数据区域,如果你访问了一个缓存页,是不是要将它立即移动到LRU的热数据区域的链表头部?
但是热数据区域里的缓存页可能是经常被访问的,所以这么频繁地进行移动是不是性能也并不是太好?也没这个必要呢?
所以LRU链表的热数据区域的访问规则被优化了,当有在热数据区域的后3/4部分的缓存页被访问了,才会给你移动到链表头部去。 如果是热数据区域的前面1/4的缓存页被访问,是不会移动到链表头部去的。
怎么理解呢?
假设热数据区域的链表里有100个缓存页,那么排在前面的25个缓存页,他即使被访问,也不会移动到链表头部去的。但是对于排在后面的75个缓存页,他只要被访问,就会移动到链表头部去。
这样的话,就可以尽可能的减少链表中的节点移动了。
对于LRU链表中尾部的缓存页,是如何淘汰他们刷入磁盘的?
缓存页和几个链表的复习
Buffer Pool在运行中被使用的时候,实际上会频繁的从磁盘上加载数据页到缓存页里去,然后free链表、flush链表、Iru链表都会在使用的时候同时被使用:
- 比如数据加载到一个缓存页,free链表里会移除这个缓存页,然后Iru链表的冷数据区域的头部会放入这个缓存页。
- 然后如果你要是修改了一个缓存页,那么flush链表中会记录这个脏页(需要刷盘实现Buffer Pool和磁盘数据一致),Iru链表中还可能会把你从冷数据区域移动到热数据区域的头部去。
- 如果你是查询了一个缓存页,那么此时就会把这个缓存页在Iru链表中(从冷数据区域)移动到热数据区域去,或者在热数据区域中也有可能会移动到头部去。
总之,MySQL在执行增删改查时,首先就是大量的操作缓存页以及对应的几个链表。然后在缓存页都满的时候,必须要把一些缓存页刷入磁盘中,然后清空这几个缓存页,接着把需要加载的数据页加载到缓存页中去。
定时将LRU尾部的部分缓存页刷入磁盘
并不是在缓存页满的时候,才会挑选LRU冷数据区域尾部的几个缓存页刷入磁盘
而是有一个后台线程,他会运行一个定时任务,这个定时任务每隔一段时间就会把LRU链表的冷数据区域的尾部的一些缓存页,刷入磁盘里去,清空这几个缓存页,把这些缓存页加入回free链表去。(同时从flush链表中移除,并从lru链表中移除)
把flush链表中的一些缓存页定时刷入磁盘
如果仅仅是把LRU链表中的冷数据区域的缓存页刷入磁盘,其实也不够。
因为在Iru链表的热数据区域里的很多缓存页可能也会被频繁的修改,难道他们永远都不刷入磁盘中了吗?
后台线程同时也会在MySQL不怎么繁忙的时候,找个时间把flush链表中的缓存页都刷入磁盘中,这样被你修改过的数据,迟早都会刷入磁盘的!
只要flush链表中的一波缓存页被刷入了磁盘,那么这些缓存页也会从flush链表和Iru链表中移除,然后加入到free链表中去!
可以这样理解:
- 一边不停的加载数据到缓存页里去,不停的查询和修改缓存数据,然后free链表中的缓存页不停的在减少,flush链表中的缓存页不停的在增加,Iru链表中的缓存页不停的在增加和移动。
- 另外一边,后台线程会不停地在把Iru链表的冷数据区域的缓存页以及flush链表的缓存页,刷入磁盘中来清空缓存页,然后flush链表和Iru链表中的缓存页在减少,free链表中的缓存页在增加。
实在没有空闲页怎么办
可能所有的free链表都被使用了,然后flush链表中有一大堆被修改过的缓存页,Iru链表中有一大堆的缓存页。
- 这个时候如果要从磁盘加载数据页到一个空闲缓存页中,就会从LRU链表的冷数据区域的尾部找到一个缓存页,一定是最不经常使用的缓存页!
- 然后把他刷入磁盘和清空,然后把数据页加载到这个腾出来的空闲缓存页里去!
生产经验
通过多个Buffer Pool来优化数据库的并发性能
- 多线程并发访问一个Buffer Pool,必然是要加锁的,然后让一个线程先完成一系列的操作,比如说加载数据页到缓存页,更新free链表,更新Iru链表,然后释放锁,接着下一个线程再执行一系列的操作
- 加锁操作,对数据库的性能是有影响的
- 可以给MySQL设置多个Buffer Pool来优化他的并发能力。
- 一般来说,MySQL默认的规则是,如果你给Buffer Pool分配的内存小于1GB,那么最多就只会给你一个Buffer Pool。但是如果机器内存很大,那么必然会给Buffer Pool分配较大的内存,比如给他个8G内存,那么此时同时可以设置多个Buffer Pool的,比如说下面的MySQL服务器端的配置。 【server】 innodb buffer pool size=8589934592 innodb buffer pool instances=4我们给buffer pool设置了8GB的总内存,然后设置了他应该有4个Buffer Pool,每个buffer pool的大小就是2GB
- 这样的话,每一个Buffer Pool负责管理一部分的缓存页和描述数据块,并有自己独立的lru、flush、free链表
- 多线程访问Buffer Pool,就减少了压力
通过chunk来支持数据库运行期间的Buffer Pool动态调整
什么是chunk
MySQL设计了一个chunk机制:
buffer pool是由很多chunk组成的,他的大小是innodb buffer_pool_chunk_size参数控制的,默认值就是128MB。
所以实际上我们可以做一个假设,比如现在我们给buffer pool设置一个总大小是8GB,然后有4个buffer pool,那么每个buffer pool就是2GB,此时每个buffer pool是由一系列的128MB的chunk组成的,也就是说每个buffer pool会有16个chunk。
然后每个buffer pool里的每个chunk里就是一系列的描述数据块和缓存页,每个buffer pool里的多个chunk共享一套free、flush、Iru这些链表。
buffer pool总大小是8GB,要动态加到16GB,那么此时只要申请一系列的128MB大小的chunk就可以了,只要每个chunk是连续的128MB内存就行了。然后把这些申请到的chunk内存分配给buffer pool就行了。 有个这个chunk机制,此时并不需要额外申请16GB的连续内存空间,然后还要把已有的数据进行拷贝。

若有收获,就点个赞吧
0 人点赞
