数据类型
数据处理大致可以分成两大类
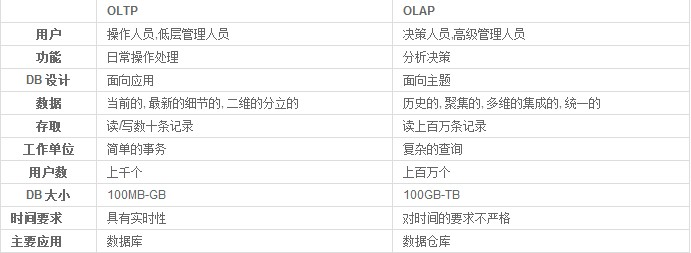
联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
OLTP与OLAP之间的比较:
Mysql事务,隔离级别
事务及级别
- 事务的基本要素 ACID
- 原子性: 事务开始后的所有操作,要么昨晚,要么全不做,执行过程中出错回滚到开始状态
- 一致性: 事务开始前和结束后,数据库的完整性约束没有被破坏。比如A向B转账,不能A扣钱但是B没收到
- 隔离性:同一时间,只允许一个事务请求同一数据,不同事务之间批次之间没有任何干扰。比如A从一张银行卡取钱,在A取钱的过程中,B不能像这种卡转账
- 持久性:事务完成后,事务对数据的所有更新将被保存到数据库,不能回滚
- 事务并发问题
- 脏读: 事务A读取了事务B更新的数据,然后B执行回滚操作,A读取到的数据是脏数据
- 不可重复读:事务A多次读取同一数据,事务B在事务A的多次读取过程中,对数据做了更新提交,导致事务A多次读取的数据不一致
- 幻读:管理员在修改数据库中的学生成绩 ABC,这时候管理员B 插入了一个学生记录D,A修改结束后发现,还有一个记录没有修改,就像发生了幻觉
不可重复读侧重于修改数据,幻读侧重于新增或删除。 解决不可重复读问题需要锁住满足条件的行,解决幻读需要锁表。
- 事务隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交read-uncommitted | 是 | 是 | 是 |
| 不可重复读read-commited | 否 | 是 | 是 |
| 可重复读 repeatable-read | 否 | 是 | 是 |
| 串行化 serializable | 否 | 否 | 否 |
读未提交;
所有事务都能看到其他未提交事务的执行结果。读取未提交数据也被称为脏读
读已提交:
大多数数据库的默认级别,但不是MySQL的默认级别。一个事务只能看见已经提交的事务所做的改变。支持不可重复读,因为同一事务的其他实例在该实例处理期间可能会有新的commit,所以同一select 也可能返回不同的结果。
可重复读:
MySQL默认的隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据。 但是理论上会导致幻读。 InnoDB 和 Falcon 存储引擎通过多版本并发控制(《MVCC Multiversion Concurrency Control) 机制解决了问题。
可串行化:
最高级别,通过强制事务排序,使之不可能相互冲突,解决了幻读问题。但是由于在每个读的数据行上加共享锁,可能会导致大量的超时现象和锁竞争。
Mysql的锁
数据库锁
共享锁 (读锁) 排它锁(写锁)
InnoDB引擎锁机制:支持事务,支持行锁和表锁
5.1 之前版本默认引擎MyISAM,不支持事务,只支持表锁
Mysql引擎
innodb和myisam的区别知道吗,说说底层的实现?
事务处理不同:
**
聚簇索引和非聚簇索引
- Mysql 索引
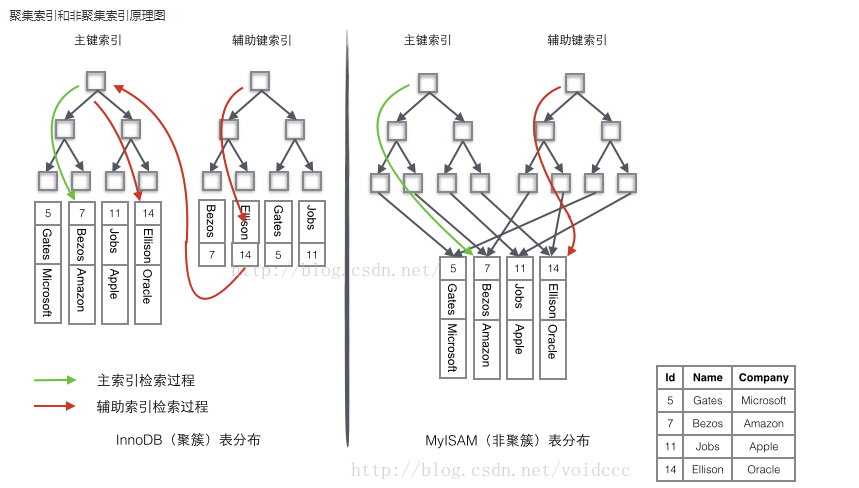
MyISAM的是非聚簇索引,B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。主索引和辅助索引没啥区别,只是主索引中的key一定得是唯一的。这里的索引都是非聚簇索引。非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,
这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。InnoDB的数据文件本身就是索引文件,B+Tree的叶子节点上的data就是数据本身,key为主键,这是聚簇索引。聚簇索引,叶子节点上的data是主键(所以聚簇索引的key,不能过长)。
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用”where id = 14”这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
②聚簇索引
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。聚簇索引要比非聚簇索引查询效率高很多。
聚集索引这种主+辅索引的好处是,当发生数据行移动或者页分裂时,辅助索引树不需要更新,因为辅助索引树存储的是主索引的主键关键字,而不是数据具体的物理地址。
③非聚簇索引
非聚集索引,类似于图书的附录,那个专业术语出现在哪个章节,这些专业术语是有顺序的,但是出现的位置是没有顺序的。每个表只能有一个聚簇索引,因为一个表中的记录只能以一种物理顺序存放。但是,一个表可以有不止一个非聚簇索引。
B+树知道吗?为什么使用B+树?
分库分表
了解死锁
Sql优化
实用SQL 语句
插入或替换
replace into table (column) values(value)
插入或更新 on duplicate key update
insert into table (column) values (value) on duplicate key update column=”value”, column2=”value2”
规则是这样的:如果你插入的记录导致一个UNIQUE索引或者primary key(主键)出现重复,那么就会认为该条记录存在,则执行update语句而不是insert语句,反之,则执行insert语句而不是更新语句。
这里特别需要注意的是:如果行作为新记录被插入,则受影响行的值为1;如果原有的记录被更新,则受影响行的值为2,如果更新的数据和已有的数据一模一样,则受影响的行数是0,这意味着不会去更新,也就是说即使你有的时间戳是自动记录最后一次的更新时间,这个时间戳也不会变动。
插入或忽略
insert ignore into table(column) values(value)
强制指定索引
select * from table force index(index_name) where ……
delete drop truncate 区别
相同点
- truncate 和不带where子句 delete 以及 drop 都会删除表内的数据
- drop truncate 都是DDL (数据定义语言), 执行后会自动提交
不同点
- truncate 和 delete 只删除数据,不删除表结构(定义)
- drop 语句
视图
操作语句
创建视图 CREATE VIEW <视图名> AS
修改视图 ALTER VIEW <视图名> AS
删除视图 DROP VIEW <视图名1> [ , <视图名2> …]
数据库视图是虚拟表或逻辑表,被定义为具有连接的SQL Select 查询语句。
与数据表的去呗
视图并不同于数据表,它们的区别在于以下几点:
- 视图不是数据库中真实的表,而是一张虚拟表,其结构和数据是建立在对数据中真实表的查询基础上的。
- 存储在数据库中的查询操作 SQL 语句定义了视图的内容,列数据和行数据来自于视图查询所引用的实际表,引用视图时动态生成这些数据。
- 视图没有实际的物理记录,不是以数据集的形式存储在数据库中的,它所对应的数据实际上是存储在视图所引用的真实表中的。
- 视图是数据的窗口,而表是内容。表是实际数据的存放单位,而视图只是以不同的显示方式展示数据,其数据来源还是实际表。
- 视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些 SQL 语句的集合。从安全的角度来看,视图的数据安全性更高,使用视图的用户不接触数据表,不知道表结构。
- 视图的建立和删除只影响视图本身,不影响对应的基本表。
使用视图的时候,还应该注意以下几点:
- 创建视图需要足够的访问权限。
- 创建视图的数目没有限制。
- 视图可以嵌套,即从其他视图中检索数据的查询来创建视图。
- 视图不能索引,也不能有关联的触发器、默认值或规则。
- 视图可以和表一起使用。
- 视图不包含数据,所以每次使用视图时,都必须执行查询中所需的任何一个检索操作。如果用多个连接和过滤条件创建了复杂的视图或嵌套了视图,可能会发现系统运行性能下降得十分严重。因此,在部署大量视图应用时,应该进行系统测试。
数据库视图的优缺点
数据库视图的优点
以下是使用数据库视图的优点 -
- 数据库视图允许简化复杂查询:数据库视图由与许多基础表相关联的SQL语句定义。 您可以使用数据库视图来隐藏最终用户和外部应用程序的基础表的复杂性。 通过数据库视图,您只需使用简单的SQL语句,而不是使用具有多个连接的复杂的SQL语句。
- 数据库视图有助于限制对特定用户的数据访问。 您可能不希望所有用户都可以查询敏感数据的子集。可以使用数据库视图将非敏感数据仅显示给特定用户组。
- 数据库视图提供额外的安全层。 安全是任何关系数据库管理系统的重要组成部分。 数据库视图为数据库管理系统提供了额外的安全性。 数据库视图允许您创建只读视图,以将只读数据公开给特定用户。 用户只能以只读视图检索数据,但无法更新。
- 数据库视图启用计算列。 数据库表不应该具有计算列,但数据库视图可以这样。 假设在
orderDetails表中有quantityOrder(产品的数量)和priceEach(产品的价格)列。 但是,orderDetails表没有一个列用来存储订单的每个订单项的总销售额。如果有,数据库模式不是一个好的设计。 在这种情况下,您可以创建一个名为total的计算列,该列是quantityOrder和priceEach的乘积,以表示计算结果。当您从数据库视图中查询数据时,计算列的数据将随机计算产生。 - 数据库视图实现向后兼容。 假设你有一个中央数据库,许多应用程序正在使用它。 有一天,您决定重新设计数据库以适应新的业务需求。删除一些表并创建新的表,并且不希望更改影响其他应用程序。在这种情况下,可以创建与将要删除的旧表相同的模式的数据库视图。
数据库视图的缺点
除了上面的优点,使用数据库视图有几个缺点:
- 性能:从数据库视图查询数据可能会很慢,特别是如果视图是基于其他视图创建的。
- 表依赖关系:将根据数据库的基础表创建一个视图。每当更改与其相关联的表的结构时,都必须更改视图。
//原文出自【易百教程】,商业转载请联系作者获得授权,非商业转载请保留原文链接:https://www.yiibai.com/mysql/introduction-sql-views.html
触发器
根据定义,触发器或数据库触发器是自动执行以响应特定事件的存储程序,例如在表中发生的插入,更新或删除。
**

若有收获,就点个赞吧
0 人点赞
