一、理论题
1、Azkaban的web访问端口,SuperSet的web访问端口,yarn的web访问端口,hdfs的web访问端口,yarn的聚合日志访问端口?
Azkaban的web访问端口:8081SuperSet的web访问端口:8787yarn的web访问端口:8088hdfs的web访问端口:9870yarn的聚合日志访问端口:19888
2、Hive SQL中三种排名函数的区别?
rank() 排序时若两元素值相同 会重复编号,但总数不会变dense_rank() 排序时若两元素值相同 编号也会重复,但总数会减少row_nubver() 当元素值重复时 会根据数据的顺序来排编号 编号不会重复
3、Hive SQL中什么是行转列,什么是列转行,怎么做?
行转列:先利用collect_set()函数或collext_list()函数进行汇总,返回array类型字段concat_ws()函数以某个分隔符进行拼接分组列转行:将一个字符串按照指定字符分割为一个array集合;将一列复杂的array或者map拆分为多行;lateral view能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
二、Scala编程题
1、算术题
有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少?(30个月的数据)
斐波那契数列(Fibonacci sequence),又称黄金分割数列,指的是这样一个数列:0、1、1、2、3、5、8、13、21、34....f(n) = f(n-1) + f(n-2)如果要输出这样的数列,实际上很简单,每一个数等于前两个数之和
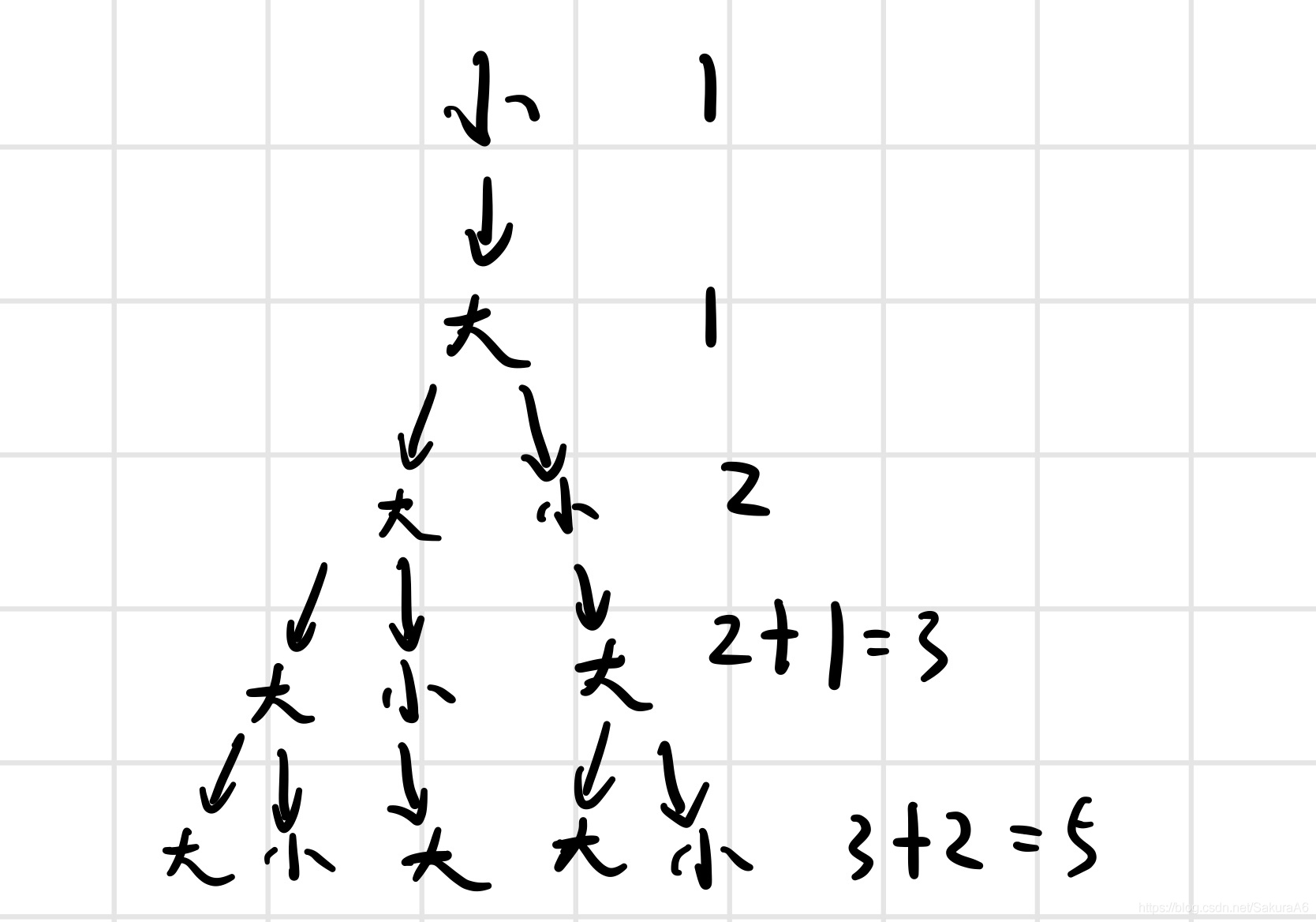
代码:
/**
* @Author laoyan
* @Description TODO
* @Date 2022/5/3 9:51
* @Version 1.0
*/
object _兔子问题 {
// 根据斐波那契数列的特点, f(n) = f(n-1) + f(n-2)
def fb(num:Int): Int ={
if(num == 0 || num == 1)
return 1
else
fb(num-1) + fb(num -2)
}
def main(args: Array[String]): Unit = {
var arr = new Array[Int](30); // 0,0,0,....
// to until 的区别
for(i <- 0 to arr.length-1){
// 每一个月的兔子的总对数,在这个数组中
arr(i) = fb(i)
}
var month = 1;
for(dui <- arr){
println(s"第${month}月的数量是"+(dui * 2) +"只")
month += 1;
}
}
}
2、编写一个简易的登录系统
进入系统后提示输入账户和密码,用户输入了账户和密码之后,从集合中查询账户和密码是否正确,如果正确提示登录成功,如果不正确提示登录失败。
import scala.io.StdIn
import scala.util.control.Breaks.{break, breakable}
/**
* @Author laoyan
* @Description TODO
* @Date 2022/5/3 10:02
* @Version 1.0
*/
object _登录代码 {
def main(args: Array[String]): Unit = {
val list = List("admin"->"admin","zhangsan"->"123456")
println("请输入账户:")
val username = StdIn.readLine();
println("请输入密码:")
val password = StdIn.readLine();
var result = false // 代表登录失败
// 优化: 不需要每次全部循环,只需要拿到值即终止循环,典型的break应用,scala中的break
breakable {
for(account <- list){
if(account._1 == username && account._2 == password){
result = true
break()
}
}
}
if(result){
println("登录成功")
}else{
println("登录失败")
}
}
}
三、Hive SQL题目
统计连续登陆的三天及以上的用户
试经常会问的SQL题目:统计连续登录的三天及以上的用户(或者类似的:连续3个月充值会员用户、连续N天购买商品的用户等),下面就来记录一下解题思路。
要求输出格式:
数据如下:user.txt
| user01,2018-02-28 user01,2018-03-01 user01,2018-03-02 user01,2018-03-04 user01,2018-03-05 user01,2018-03-06 user01,2018-03-07 user02,2018-03-01 user02,2018-03-02 user02,2018-03-03 user02,2018-03-06 |
|---|
创建表,编写SQL,统计结果:
哪个用户,连续登陆了多少天,起止日期是什么。
user01 3 2018-03-01 2018-03-04
create table user_login_info(
user_id string COMMENT '用户ID'
,login_date date COMMENT '登录日期'
)
row format delimited
fields terminated by ',';
load data local inpath "/root/zuoyedata/user.txt" into table user_login_info;
select user_id,login_date,row_number() over(partition by user_id order by login_date asc) as rank from user_login_info;
结果:
+----------+-------------+-------+
| user_id | login_date | rank |
+----------+-------------+-------+
| user01 | 2018-02-28 | 1 |
| user01 | 2018-03-01 | 2 |
| user01 | 2018-03-02 | 3 |
| user01 | 2018-03-04 | 4 |
| user01 | 2018-03-05 | 5 |
| user01 | 2018-03-06 | 6 |
| user01 | 2018-03-07 | 7 |
| user02 | 2018-03-01 | 1 |
| user02 | 2018-03-02 | 2 |
| user02 | 2018-03-03 | 3 |
| user02 | 2018-03-06 | 4 |
+----------+-------------+-------+
用 login_date - rank 得到的差值日期如果是一样的,则说明是连续登录的
select t1.user_id,t1.login_date,
date_sub(t1.login_date,t1.rank) as date_diff
from
(select user_id,login_date,row_number()
over(partition by user_id order by login_date asc)
as rank from user_login_info) t1;
结果:
+----------+-------------+-------------+
| user_id | login_date | date_diff |
+----------+-------------+-------------+
| user01 | 2018-02-28 | 2018-02-27 |
| user01 | 2018-03-01 | 2018-02-27 |
| user01 | 2018-03-02 | 2018-02-27 |
| user01 | 2018-03-04 | 2018-02-28 |
| user01 | 2018-03-05 | 2018-02-28 |
| user01 | 2018-03-06 | 2018-02-28 |
| user01 | 2018-03-07 | 2018-02-28 |
| user02 | 2018-03-01 | 2018-02-28 |
| user02 | 2018-03-02 | 2018-02-28 |
| user02 | 2018-03-03 | 2018-02-28 |
| user02 | 2018-03-06 | 2018-03-02 |
+----------+-------------+-------------+
根据 user_id 和 date_diff 分组,login_date 的最小时间即 start_date ,最大时间即 end_date,取分组后的count>=3的即为最终结果
select
t2.user_id,
count(1),
min(t2.login_date) start_date,
max(t2.login_date) end_date
from (
select t1.user_id,t1.login_date,
date_sub(t1.login_date,t1.rank) as date_diff
from
(select user_id,login_date,row_number()
over(partition by user_id order by login_date asc)
as rank from user_login_info) t1
) t2 group by t2.user_id,t2.date_diff having count(1)>=3;
结果:
+----------+--------+-------------+-------------+
| user_id | times | start_date | end_date |
+----------+--------+-------------+-------------+
| user01 | 3 | 2018-02-28 | 2018-03-02 |
| user01 | 4 | 2018-03-04 | 2018-03-07 |
| user02 | 3 | 2018-03-01 | 2018-03-03 |
+----------+--------+-------------+-------------+

其他思路参考:
(1)
select u_id,
u_date,
LEAD(u_date,1,'1900-01-01') over (partition by u_id order by u_date) as tim2
from usr;
==>
user01 2018-02-28 2018-03-01
user01 2018-03-01 2018-03-02
user01 2018-03-02 2018-03-04
user01 2018-03-04 2018-03-05
user01 2018-03-05 2018-03-06
user01 2018-03-06 2018-03-07
user01 2018-03-07 1900-01-01
user02 2018-03-01 2018-03-02
user02 2018-03-02 2018-03-03
user02 2018-03-03 2018-03-06
user02 2018-03-06 1900-01-01
(2)
select u_id,tim1,tim2 from
(
select u_id,
u_date tim1,
LEAD(u_date,1,'1900-01-01') over (partition by u_id order by u_date) as tim2
from usr
) t1 where datediff(tim1,tim2)=1;
(3)
select u_id,count(1) c,tim1,date_add(tim1,c) from
(
select u_id,
u_date tim1,
LEAD(u_date,1,'1900-01-01') over (partition by u_id order by u_date) as tim2
from usr
) t1 where datediff(tim1,tim2)=1 group by t1.u_id ;

若有收获,就点个赞吧
0 人点赞
