主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果,减少方法使用
表达式与命令行:
聚合表达式:
| 字段路径表达式 | |
|---|---|
| $ |
指定字段 |
| $ |
指定字段和内嵌字段,如果不存在将为null |
| 系统变量表达式 | |
| $$ |
指定系统变量 |
| $$CURRENT | 指示管道中当前操作的系统文档 |
| 常量表达式 | |
| $literal: |
指示常量value |
| $literal:”$Hello” | 指示常量字符串:$Hello |
聚合管道运算符:
绿色代表 4.2 + 版才有的新特性
| 方法 | 描述 |
|---|---|
| $addFields | 添加新字段 |
| $collStats | 返回有关集合或视图的统计信息 |
| $count | 返回聚合管道阶段的文档数 |
| $facet | 在同一组输入文档的单个阶段内处理多个聚合管道 |
| $group | 根据输入符对文档进行分组 |
| $indexStats | 返回有关集合中每个索引的使用情况的统计信息 |
| $limit | 将未修改的前n 个文档传递到管道 |
| $match | 过滤文档流(where条件) |
| $merge | 将聚合管道结果写入集合,必须是管道中最后一步 |
| $out | 低于4.2版本的结果写入集合操作,必须是最后一步 |
| $sort | 排序 |
| $set | 添加新字段 |
| $unset | 删除字段 |
| $skip | 跳过指定数量的文档数据 |
| $unwind | 展开输入文档中的数组字段,返回新文档 |
| $project | 对输入文档进行再次投影 |
| $lookup | 相当于SQL中的多表 in 查询 |
管道操作命令:
db.collection.aggregate(pipeline, options) 指定操作符进行聚合操作
基础:
事先数据准备:
db.accounts.insertMany([{name:{ firstName:"alice",lastName:"wong" },balance:50,currency:["CNY","USD"]},{name:{ firstName:"bob",lastName:"yang" },balance:20,currency:"GBP"},{name:{ firstName:"charlie",lastName:"gordon" },balance:100},{name:{ firstName:"david",lastName:"wu" },balance:200,currency: []},{name:{ firstName:"eddie",lastName:"kim" },balance: 20,currency: null}])
$project案例:
#隐藏ID和balance字段:db.accounts.aggregate([ {$project:{ _id:0,balance:0 }}] )
$project + 字段路径案例:
#隐藏ID和balance字段,将name的字段添加到一个新数组中进行展示:db.accounts.aggregate([{$project:{_id: 0,balance: 1,nameArray:[ "$name.firstName","$name.middleName","$name.lastName"]}}])
$match 案例:
#筛选出name的firstName为alice的数据:db.accounts.aggregate([{$match:{"name.firstName":"alice"}}])#筛选出name的firstName为alice或balance为20的数据:db.accounts.aggregate([{$match:{$or:[{"name.firstName":"alice"},{"balance":20}]}}])
$skip和$limit案例:
#跳过一个文档:db.accounts.aggregate([{$skip:1}])#截取一个文档:db.accounts.aggregate([{$limit:1}])
$unwind案例:
与原文档的区别是结果中的文档 currency 字段只取其中一个元素,如果有文档中该展开字段不为数组类型,将直接返回原结果,如果该字段不存在或没有数据,默认将不返回
原文档数组中有N个数据,就会返回N个除对应展开数组字段以外其余字段数据全部一致的新文档数据
#展开currency数组:db.accounts.aggregate([{$unwind:{path:"$currency"}}])

如果需要返回没有数据可以展开的数组字段,需要添加额外参数:
#指定preserveNullAndEmptyArrays为True即可显示不可展开的数据db.accounts.aggregate([{$unwind: {path:"$currency",preserveNullAndEmptyArrays: true}}])

返回所有数据
$sort案例:
和 sort() 方法一致,用于排序
#将balance正向排序,name倒序db.accounts.aggregate([{$sort:{balance:1,name:-1}}])
$sout案例:
将管道操作后的数据写入到目标集合中,如果目标集合存在,进行清空数据操作(保留索引)再保存;如果不存在,则创建一个新集合
如果语句有误,将不会进行任何操作
#对accounts中s文档进行skip(3),将结果保存到 newCos 的集合中db.accounts.aggregate([{$skip:3},{$out:"newCos"}])
组合使用案例:
#筛选出name的firstName为alice或balance为20,且隐藏id显示的数据:db.accounts.aggregate([{$match:{$or:[{"name.firstName":"alice"},{"balance":20}]}},{$project:{_id: 0}}])
高级:
多表关联查询$lookup:
用于同一数据库中不同集合之间的嵌套查询,并符合的结果将结果写入集合中,不符合的结果写入空数组
语法一:
将两个集合做关联,将符合关联的问文档数据写入集合中,不符合的结果写入空数组
db.集合名.aggregate{$lookup:{from: <collection to join>,localField: <field from the input documents>,foreignField: <field from the documents of the "from" collection>,as: <output array field>}}
语法解释说明:
| 语法值 | 解释说明 |
|---|---|
| from | 同一个数据库下等待被Join的集合。 |
| localField | 源集合中的match值,如果输入的集合中,某文档没有 localField在处理的过程中,会默认为此文档含有 localField:null 的键值对。 |
| foreignField | 待Join的集合的match值,如果待Join的集合中,文档没有foreignField值,在处理的过程中,会默认为此文档含有 foreignField:null的键值对。 |
| as | 为输出文档的新增值命名。如果输入的集合中已存在该值,则会覆盖掉 |
| pipeline | 对查询集合文档进行pipeline操作 |
转换为SQL语句为:
SELECT *, <localField>FROM 集合名WHERE <output array field> IN (SELECT *FROM <collection to join>WHERE <foreignField> = <集合名.localField>)
语法二:
对目标集合进行管道操作,将返回结果写入集合的 as 字段名进行返回,该无关联方式语法仅支持 3.6 + 版本
db.集合名.aggregate{$lookup:{from: <collection to join>,let: {<var 1>:<expression>,....<var n >:<expression>},pipeline:[<pipeline to execute on the collection to join>],as: <output array field>}}
数据添加:
accounts集合数据为基础操作阶段添加
db.forex.insertMany([{ccy: "USD",rate: 6.91,date: new Date( "2018-12-21")},{ccy: "GBP",rate: 8.72,date: new Date("2018-08-21")},{ccy :"CNY",rate: 1.0,date: new Date( "2018-12-21" )}])
案例一:
将 forex集合中的 ccy 和 accounts集合中的 ccy 做对等关联,筛选出所有符合条件的文档后添加到 forexData字段中,并将 forexData字段写入到 accounts 所有能关联上的文档
db.accounts.aggregate([{$lookup: {from:"forex",localField:"currency",foreignField:"ccy",as:"forexData"}}])
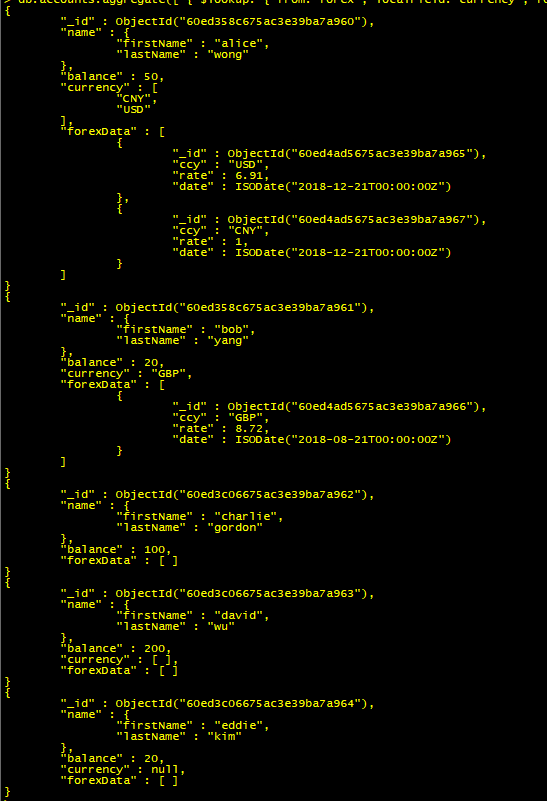<br /> **符合结果的文档会写入新字段数据,不符合的为空数组**
案例二:
将日期为 2018-12-13 的 forex 文档数据写入搭配 accounts 的 forexData 字段中
db.accounts.aggregate([{$lookup:{from: "forex",pipeline:[{$match:{date: new Date("2018-12-21")}}],as:"forexData"}}])
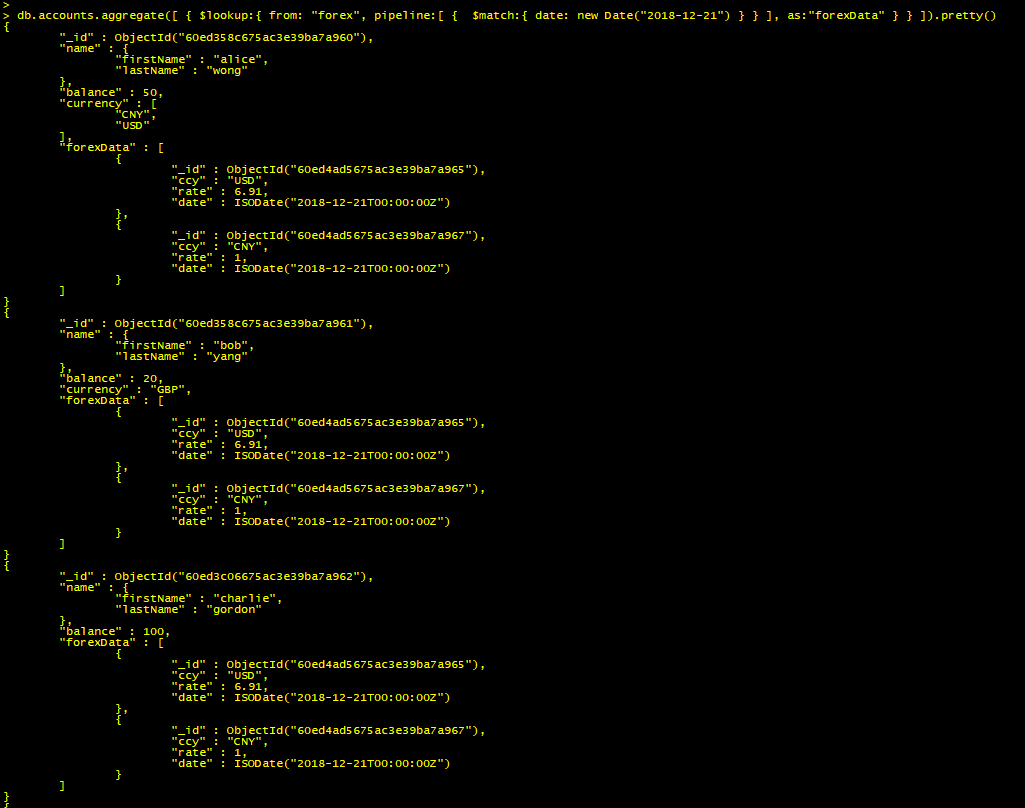
部分返回结果截图
案例三:
筛选 accounts集合中 balance 大于100 且 forex集合中时间为 2018-12-21 的数据添加到 accounts 集合中:
使用 let 声明的字段(转为系统变量)来取得目标集合字段的值,以此达到查询条件
当 let 声明新的系统变量来提取原管道集合的字段做查询条件时,要使用 $expr 才能操作
db.accounts.aggregate([{$lookup: {from:"forex",let: { bal:"$balance" },pipeline: [{ $match:{ $expr:{ $and:[{ $eq: [ "$date",new Date("2018-12-21") ] },{ $gt: [ "$$bal",100 ] }]}}}],as:"forexData"}}])
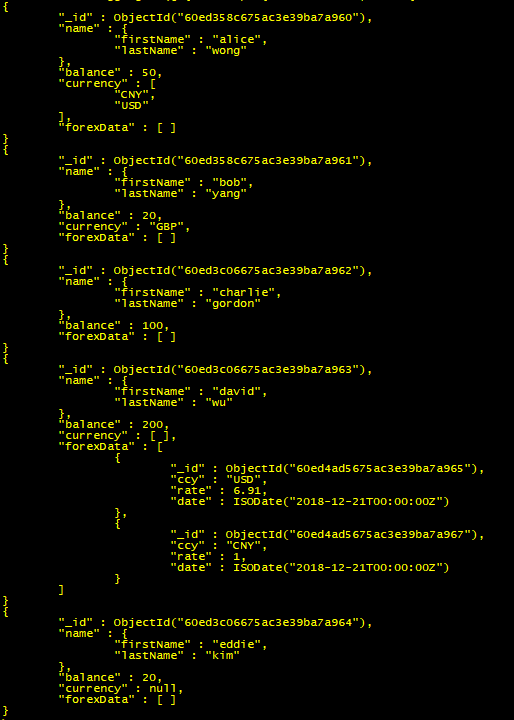
返回结果
分组操作$group:
类似SQL语句中的 Group By 语法, _id为需要分组的字段名称。如果 _id 的值为 null,将不进行分组操作,直接使用聚合操作符进行计算
{ $group:{ _id: <expression>, <field1>:{ <accumulator1> : <expression1> }, ... } }
数据添加:
db.transactions.insertMany( [{symbol: "600519",qty: 100,price: 567.4,currency: "CNY"},{symbol: "AMZN",qty: 1,price: 1377.5,currency: "USD"},{symbol:"AAPL",qty: 2,price: 150.7,currency: "USD"}])
案例一:
按照currency进行分组并计算 price 的值
db.transactions.aggregate( [{$group:{_id:"$currency",count:{$sum:"$price"}}}])

返回结果
案例二:
根据 currency 进行分组,求分组后的 qty 的和、( $multiply )对 price 和 qty 进行相乘再返回、求 price 的平均值,求分组后的每组总数、求相乘的最大值和最小值
db.transactions.aggregate([{$group: {_id: "$currency",totalQty: { $sum: "$qty" },totalNotional: { $sum: { $multiply: [ "$price", "$qty" ] } },avgPrice: { $avg: "$price" },count: { $sum: 1 },maxNotional: { $max: { $multiply: [ "$price", "$qty" ] } },minNotional: { $min: { $multiply: [ "$price", "$qty" ] } }}}])

数据返回结果
案例三:
对 currency 进行分组,将分组后的数据筛选出 symbol 添加到数组进行返回
db.transactions.aggregate( [{$group:{_id:"$currency",code:{$push:"$symbol"}}}])
容量问题:
每个聚合管道阶段最大数据量为100MB,当数据量大于100MB时,为防止聚合管道阶段超出内存上限导致抛出异常,需要指定 allowDiskUse 为 true
原理:将操作数据写入临时文件中(取配置文件中的 dbPath下的 _tem 文件夹,默认值为 /data/db )
使用案例:
db.transactions.aggregate( [{$group:{_id:"$currency",code:{$push:"$symbol"}}}],{ allowDiskUse:true })
优化:
在管道命令执行前,MongoDB将会对命令进行优化排序后再进行执行;实际和MySQL语句方案优化差不多
https://docs.mongodb.com/v4.4/core/aggregation-pipeline-optimization/ 官方文档
- 当 $match 和 $project 同时出现时,尽可能将 $match 移动到 $project 之前进行执行,先过滤再进行投影以减少筛选过程

原版命令
实际执行
- 当 $sort 和 $match 同时出现时,将会把 $match 移动到 $sort 前进行操作
- 当 $skip 和 $project / $unset 同时出现时,将会把 $skip 移动到 $project / $unset 之后进行操作
- 多个相同的命令紧跟在一起时将会进行合并
- 当 $sort 和 $ limit 紧跟在一起时,如果中间没有修改文档的数量,优化器将会自动合并
- 在 $lookup 后紧跟 $unwind,优化器将合并 $unwind 到 $lookup 中
#原版语句:db.accounts.aggregate([{$lookup: {from:"forex",localField:"currency",foreignField:"ccy",as:"forexData"}},{$unwind:{path:"$forexData"}}])

若有收获,就点个赞吧
0 人点赞
