任务:
40 数组中最小的K的数 . 这道题核心还是训练partition 的过程。
53 在排序数组中查找数字 考察 二分
57 和为s的数字 查找
61 扑克牌中的顺子。 杂题
62 圆圈中的最后剩下的数字。。约瑟夫环,比较经典的笔试题。
56 数组中数字出现的次数。。。用到了位运算知识,你先自己看看。
29 顺时针打印矩阵 二维数组遍历,找规律
40. 数组中最小的K的数

1. 思路
- 库函数排序
- 直接对arr排序,然后输出前k个
- 大顶堆
- 由于每次从堆顶弹出的数都是堆中最大的,最小的 k 个元素一定会留在堆里。
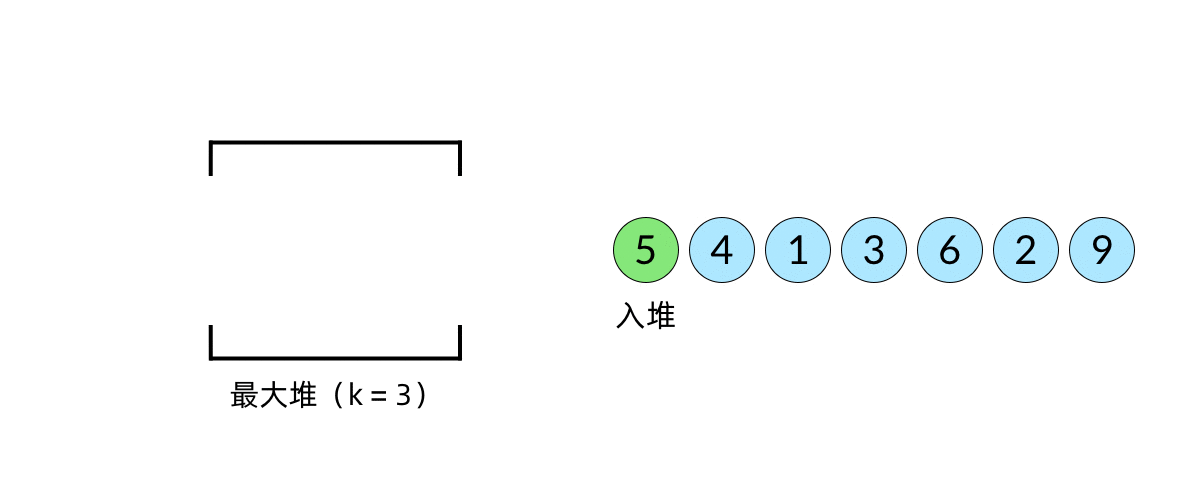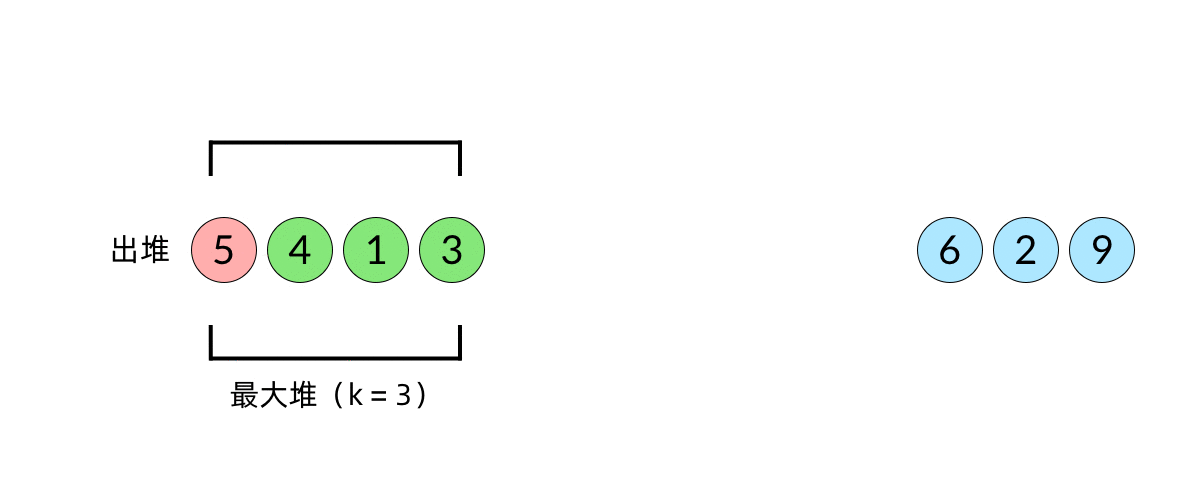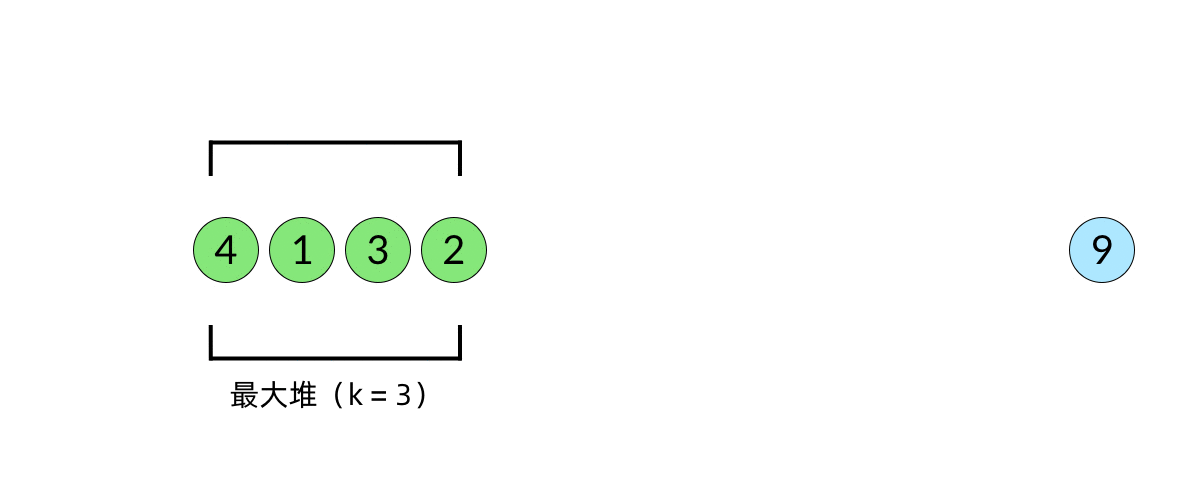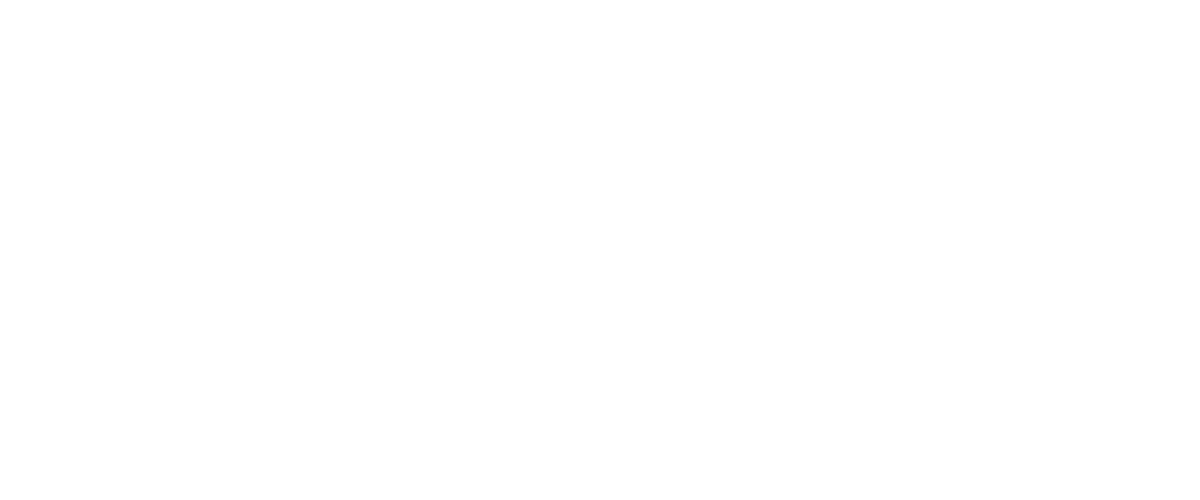
快速排序
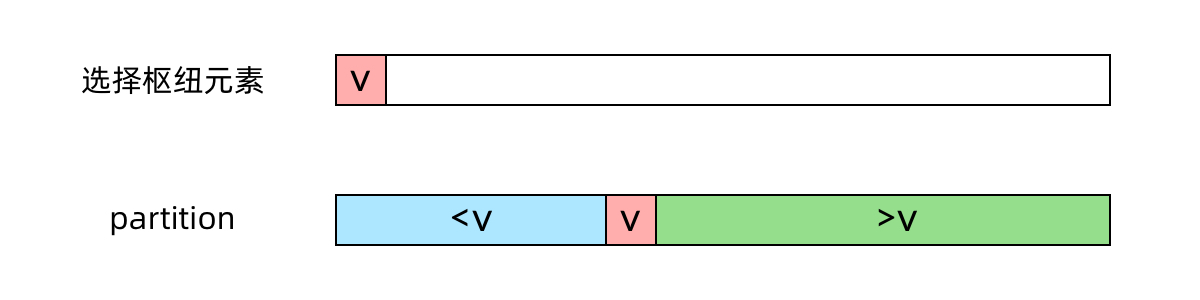
- 随机选一个纽扣元素v
- 把大于v的放右,把<v的放左
- 左侧为m
- 若 k = m,我们就找到了最小的 k 个数,就是左侧的数组;
- 若 k<m ,则最小的 k 个数一定都在左侧数组中,我们只需要对左侧数组递归地 parition 即可;
若 k>m,则左侧数组中的 m个数都属于最小的 kk 个数,我们还需要在右侧数组中寻找最小的 k-mk个数,对右侧数组递归地 partition 即可。
2. 库函数排序
class Solution:def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:arr.sort()return arr[:k]
3. 大顶堆
class Solution:def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:if k == 0:return list()hp = [-x for x in arr[:k]]heapq.heapify(hp)for i in range(k, len(arr)):if -hp[0] > arr[i]:heapq.heappop(hp)heapq.heappush(hp, -arr[i])ans = [-x for x in hp]return ans
4. 快速选择
class Solution:def partition(self, nums, l, r):pivot = nums[r]i = l - 1for j in range(l, r):if nums[j] <= pivot:i += 1nums[i], nums[j] = nums[j], nums[i]nums[i + 1], nums[r] = nums[r], nums[i + 1]return i + 1def randomized_partition(self, nums, l, r):i = random.randint(l, r)nums[r], nums[i] = nums[i], nums[r]return self.partition(nums, l, r)def randomized_selected(self, arr, l, r, k):pos = self.randomized_partition(arr, l, r)num = pos - l + 1if k < num:self.randomized_selected(arr, l, pos - 1, k)elif k > num:self.randomized_selected(arr, pos + 1, r, k - num)def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:if k == 0:return list()self.randomized_selected(arr, 0, len(arr) - 1, k)return arr[:k]
5. 总结
在面试中,另一个常常问的问题就是这两种方法有何优劣。看起来分治法的快速选择算法的时间、空间复杂度都优于使用堆的方法,但是要注意到快速选择算法的几点局限性:
第一,算法需要修改原数组,如果原数组不能修改的话,还需要拷贝一份数组,空间复杂度就上去了。
第二,算法需要保存所有的数据。如果把数据看成输入流的话,使用堆的方法是来一个处理一个,不需要保存数据,只需要保存 k 个元素的最大堆。而快速选择的方法需要先保存下来所有的数据,再运行算法。当数据量非常大的时候,甚至内存都放不下的时候,就麻烦了。所以当数据量大的时候还是用基于堆的方法比较好。
53. 在排序数组中查找数字
1. 思路
- 字典
- 用一个字典或者值遍历数组
- 找到加1
二分

2. 字典
class Solution:def search(self, nums: List[int], target: int) -> int:if len(nums) is None:return numsnu = {}nu[target] = 0for i in nums:if i not in nu:nu[i] = 1else:nu[i] += 1return nu[target]
class Solution:def search(self, nums: List[int], target: int) -> int:if len(nums) is None:return numsnu = 0for i in nums:if i == target:nu += 1elif i > target:breakreturn nu
3. 二分
class Solution:def search(self, nums: List[int], target: int) -> int:i, j = 0, len(nums) - 1while i <= j:m = (i + j) //2if nums[m] <= target:i = m + 1else:j = m - 1right = iif j >= 0 and nums[j] != target:return 0i = 0while i <= j:m = (i + j) //2if nums[m] < target:i = m + 1else:j = m - 1left = jreturn right - left -1
4. 总结
遍历这种方法需要O(n)的时间复杂度,二分查找需要O(logn)的时间复杂度,二分是这道题的最优解
- 二分法要注意右边的判断条件是 num[m] <= target, 左边的是 nums[m] < target
57. 和为s的两个数字
1. 思路
- 字典
- 把target-num作为key保存到字典中,遍历看是否有满足的
双指针

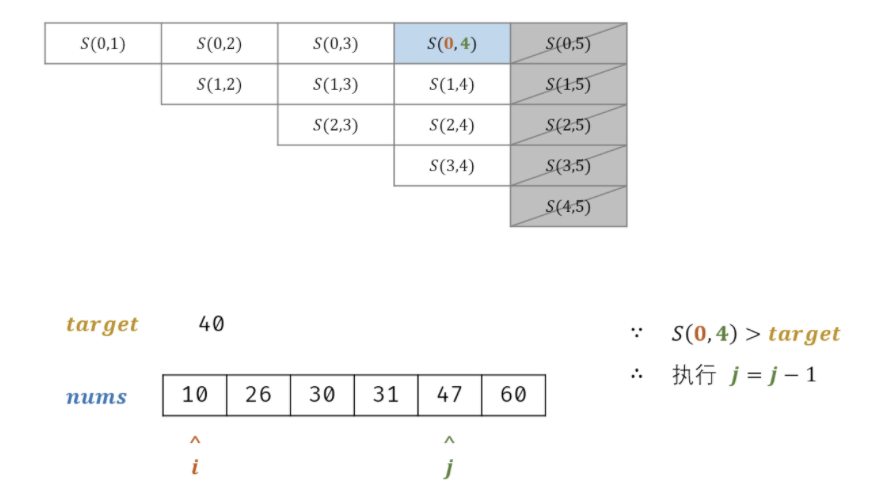
2. 字典
class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:partner = {}for i in nums:if i in partner:return [i, partner[i]]else:partner[target - i] = ireturn []
3. 双指针
class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:i, j = 0, len(nums) - 1while i < j:s = nums[i] + nums[j]if s > target: j -= 1elif s < target: i += 1else: return nums[i], nums[j]return []
4. 总结
这两种方法的时间复杂度都是O(n),字典的空间复杂度为O(n),双指针的空间复杂度为O(1)

若有收获,就点个赞吧
0 人点赞
