前置基础
阅读下文需掌握前置知识点:
执行计划(explain): https://www.yuque.com/yufeng-asaiy/bciqei/dr14aw
性能监控:https://www.yuque.com/yufeng-asaiy/bciqei/vmq8rc#lzEh1
优化细则
1.索引列不要参与表达式计算**
案例:下图中 actor_id 是索引
同样的select语句,只有红框部分不同。但是从执行计划上看,结果已经天差地别了。
首先type的档位差太多,其次rows的预估值差太多
总结:当使用索引列进行查询时,尽量不要使用表达式。应该把计算放到业务层而不是数据库层
2.索引长度越小越好
原因:innoDB每次往硬盘查询的量是16kb(操作系统规定每次查询最小4kb,或者是4kb的整数倍)
如果索引本身过长,就会导致每次查询的索引个数过少,增加了整体查询的IO访问量。
memo: 如果一定要用varchar,char,text等类型的字段做索引,可以用 字段名(n) 这样的形式,只取该字段的前几个字节做索引。如 city(7),就是取city字段的前7个字节做索引,即前缀索引
3.排序尽量通过索引来
前置信息:order by 排序一般需要加载进内存,然后进行排序的算法,数据量较大的情况下,非常消耗性能。
原因:如果order by后面跟着的是索引的话,因为当初索引是按照B+树这个数据结构存储的,B+树天然就是一种排序,所以无论是asc,还是desc,都是已经排好序了,直接拿来用就可以了。
需要注意的是,如果A,B,C形成组合索引。
| where A=xxx order by B desc ,C desc; | 这种也是可以的 |
|---|---|
| where A=xxx order by B asc ,C desc; | 这种就不行了,一下升一下降 |
| where A=xxx order by B ,C ,D; | 这种也不行,多了一个普通字段 |
memo:可以通过explain的Extra字段来查看排序情况,如果值是 Using filesort,这个就是最low,最原始的排序。
4.union all,in,or 推荐 in
案例:
从执行计划上可以看出 union all 明显效率太低(要执行2个步骤),当然如果是union all 和 union比较的话,不推荐union,因为union 存在去重的步骤
从具体执行时间来看in比or快(当然这里数据量过小,差别不是很明显)
5.触发自动类型转换会使索引失效
案例<br />phone的类型是varchar,但是输入的时候没有带引号,mysql也能识别,可以看到执行计划上已经变成全表扫描了<br />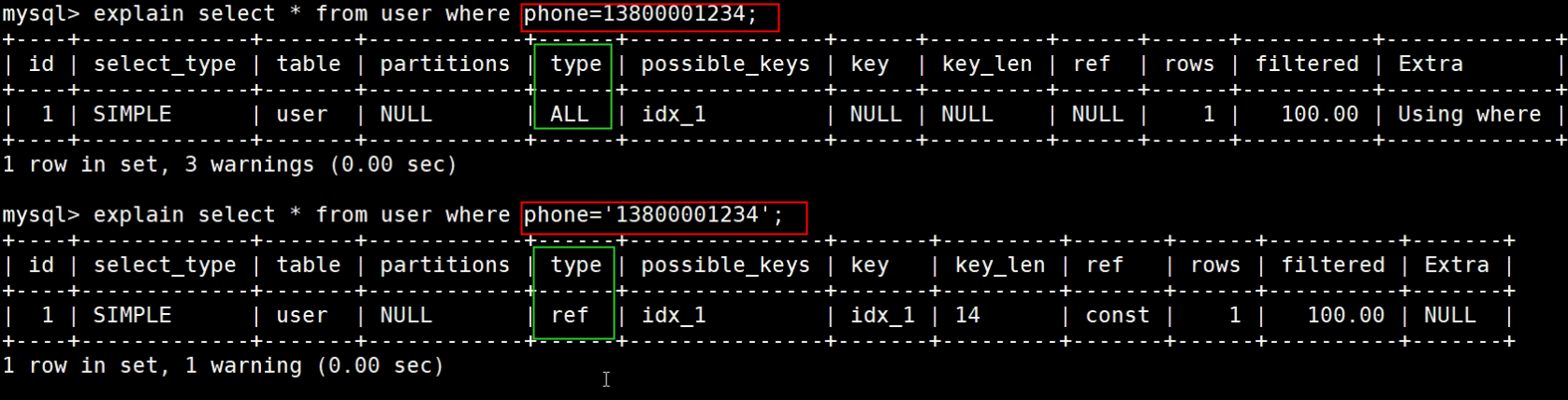
6. 明确只有一个结果时,用limit 1
首先回归 limit的本质,即限制输出,而非分页
当使用limit 1的时候,innoDB找到第一个结果之后就会直接中断后面操作。
如果没有加limit 1,innoDB找到第一个结果后,还会继续搜索操作

若有收获,就点个赞吧
0 人点赞
