 ">
">
前面也说过,度量Scale是数据空间到图形空间的转换桥梁,负责原始数据到[0,1]区间数值的相互转换工作,也叫归一化。不清楚为什么要做归一化操作的同学可以看options属性这篇文章。那scale又是如何实现这个归一化操作的呢?这个得从原始数据类型开始讲起。
原始数据类型
在G2中,我们按照数据是否连续将数据划分为以下几类:
- 分类(定性)数据,又分为有序的分类和无序的分类;
- 连续(定量)数据,连续不间断的数值,时间也是一种连续的数据类型。
例子说明:
[{ month: '一月', temperature: 7, city: 'tokyo' },{ month: '二月', temperature: 6.9, city: 'newYork' },{ month: '三月', temperature: 9.5, city: 'tokyo' },{ month: '四月', temperature: 14.5, city: 'tokyo' },{ month: '五月', temperature: 18.2, city: 'berlin' }]
其中:month 代表月份,temperature 代表温度,city 代表城市。
- 上面数据中
month和city都是离散的分类,但是又有所差异。month是有序的分类类型,而city是无序的分类类型。 temperature是连续的数字。
因为原始数据具有许多不同类型,因此scale也需要对应的类型去处理原始数据,下面就介绍一下scale的类型及其用法。
度量scale类型
G2中scale类型如下表:
连续 |
linear(连续数据基类) | 连续的数字 [1, 2, 3, 4, 5] |
|---|---|---|
| time | 连续的时间类型 | |
| log | 连续非线性的 Log 数据 将 [1, 10, 100, 1000] 转换成 [0, 1, 2, 3] | |
| pow | 连续非线性的 pow 数据 将 [2, 4, 8, 16, 32] 转换成 [1, 2, 3, 4, 5] | |
| 固定 | identity | 常量类型的数值,也就是说数据的某个字段是不变的常量 |
| 分类(非连续) | timeCat | 非连续的时间,比如股票的时间不包括周末或者未开盘的日期 |
| cat(分类数据基类) | 分类, [‘男’, ‘女’] |
注意点
连续数据度量类型和timeCat在显示时会默认对数据进行排序。
知道了scale的类型,那究竟不同类型的scale是怎么将不同的数据进行归一化的呢?
归一化操作(重要)
首先说一下归一化操作主要做的三件事:
- 将数据转换到 0-1 范围内,方便将数据映射到位置、颜色、大小等图形属性;
- 将转换过的数据从 0-1 的范围内反转到原始值。例如
分类a转换成 0.2,那此时 0.2 反转回来的值就是分类a; - 将数据划分,用于在坐标轴上、图例上显示数值的范围、分类等信息;
转换过程:
例子:
当原始数据类型为连续数据时,scale类型选择连续类型里的一种,
const data=[{name:1,value:5},{name:2,value:10},{name:2,value:15}];
scale配置:
默认配置机制
- 查看用户有没有配置了对应字段的scale
- 如果有,则按照配置的scale进行操作
- 如果没有,判断字段的第一条数据的字段类型
- 如果数据中不存在对应的字段,则为 ‘identity’
- 如果是数字则为 ‘linear’;
- 如果是字符串,判定是否是时间格式,如果是时间格式则为时间类型 ‘time’,
- 否则是分类类型 ‘cat’
- 如果数据中不存在对应的字段,则为 ‘identity’
例子:
const data=[{name:1,value:5},{name:2,value:10},{name:2,value:15}//{name:"1",value:5},// {name:"2",value:10},// {name:"3",value:15}];const chart=new G2.Chart({container:"root",width:400,height:400,});chart.source(data);chart.interval().position("name*value");chart.render();
data中name字段为数字 data中name字段为字符串
总结
从上图可以看出:当name为数字时,度量类型默认采用linear;当name为字符串时,因为不是时间格式,所以默认为cat
共同属性
不同类型的配置参数可能会有所差别,但是也有以下共同属性:
{type: {string}, // 度量的类型range: {array}, // 数值范围区间,即度量转换的范围,默认为 [0, 1]alias: {string}, // 为数据属性定义别名,用于图例、坐标轴、tooltip 的个性化显示ticks: {array}, // 存储坐标轴上的刻度点文本信息tickCount: {number}, // 坐标轴上刻度点的个数,不同的度量类型对应不同的默认值formatter: {function}, // 回调函数,用于格式化坐标轴刻度点的文本显示,会影响数据在坐标轴、图例、tooltip 上的显示}
下面针对每种类型scale的用法进行说明:
linear
连续数据类型的基类,除了以上共有属性,还包括以下特殊属性:
| 属性名 | 说明 |
|---|---|
| min | 定义域的最小值,默认取数据中的最小值(即坐标起点) |
| max | 定义域的最大值,默认取数据中的最大值(即坐标终点) |
| tickCount | 连续类型的度量,默认生成坐标点的个数是5 |
| tickInterval | 用于指定坐标轴各个标度点的间距,是原始数据之间的间距差值,tickCount 和 tickInterval 同时声明时以 tickCount 为准 |
| nice | 是否根据人对数字识别的友好度,来调整min和max。例如 min:3,max: 97,如果nice: true,那么会自动调整为:min: 0,max: 100 |
linear和cat的区别
举例:
代码:
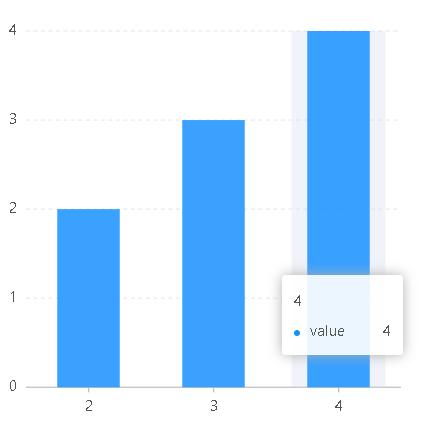
const data=[{name:"3",value:5},{name:"4",value:10},{name:"5",value:15}];const chart=new G2.Chart({container:"root",width:400,height:400,options:{scales:{name:{type:"linear"//type:"cat"}}}});chart.source(data);chart.interval().position("name*value");chart.render();
总结
当type为linear时,因为min和max及tickCount都没有设置,所以min默认取数据中的最小值3,max默认取数据中的最大值5,又因为tickCount默认分成5个坐标点,所以tickInterval被设置成了0.5,但是这样的图表显然不是我们想要的,所以我们可以通过设置min和max让图表的位置更加合理。
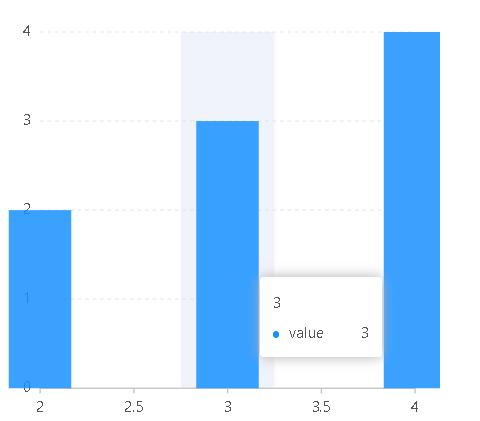
当type为cat时,为什么图表的位置就正常了呢?
因为当type为cat时,scale的转换方式就变了,它会将3,4,5分成3类,每一类的所占比例都是均分的,这是和linear时的scale转换最大的不同,linear是按照数值大小来取比例的,并不是均分的,所以最后的图表才会出现这种差异化。
cat
分类类型度量的独有属性:
| 属性名 | 说明 |
|---|---|
| values | 当前字段的分类值(其实就是个排序操作,按数组中的分类值进行排序) |
values属性说明
将linear实例代码中的scales改为:
name:{type:"cat",//values:["5","4","1"]}
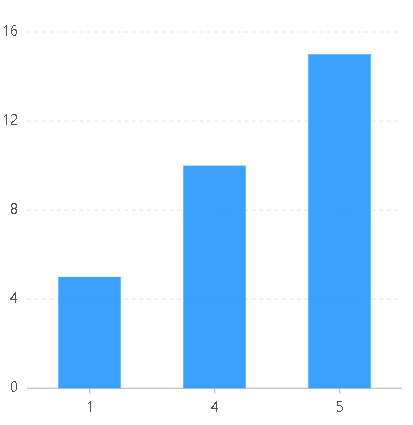
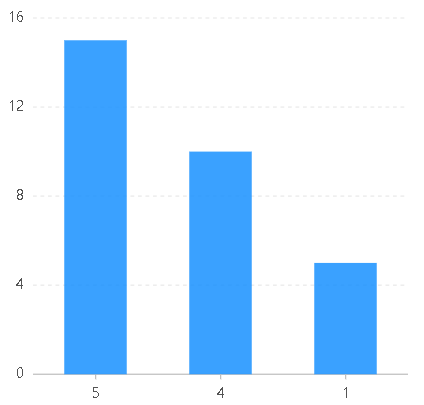
values设置之前 values设置之后
可以发现,当values设置之后,最后图表分类字段的显示顺序变成了数组中的分类字段排列顺序了。
注意:values中的值必须和数据中的字段一一对应,即不能采用数据中不存在的字段。
time
time类型的值是一种特殊的连续类型,是linear的子类,其特殊的属性:
| 属性名 | 说明 |
|---|---|
| mask | 数据的格式化格式 默认:’YYYY-MM-DD’ |
目前支持两种time类型:
- 时间戳的数字形式, 1436237115500 // new Date().getTime()
- 时间字符串: ‘2015-03-01’, ‘2015-03-01 12:01:40’, ‘2015/01/05’,’2015-03-01T16:00:00.000Z’
time与linear的区别
因为用linear无法直接表示数据类型为时间的数据,所以增加了time度量类型来专门处理数据类型为时间的数据。
log
log类型度量可以将数据[2,4,8,16,32]转换成[1,2,3,4,5]再进行归一化处理,所以能将非常大范围的数据映射到一个均匀的范围内,这种度量是linear的子类,支持所有通用的属性和linear度量的属性,特有的属性:
| 属性名 | 说明 |
|---|---|
| base | Log 的基数,默认是2 |
以下情形下建议使用log度量
- 散点图时数据的分布非常广,同时数据分散在几个区间内。例如 分布在 0-100, 10000 - 100000, 1千万 - 1亿内,这时候适合使用log 度量
- 使用热力图时,数据分布不均匀时也会出现只有非常高的数据点附近才有颜色,此时需要使用log度量,对数据进行log处理。
linear和log的区别:
例子:
代码:
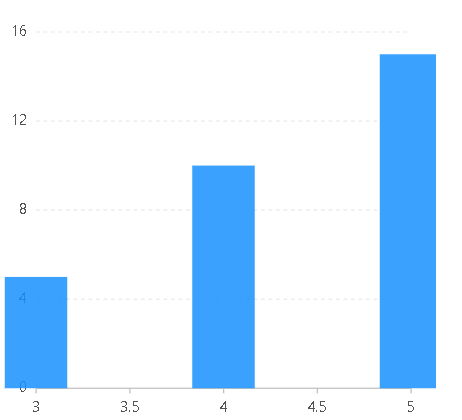
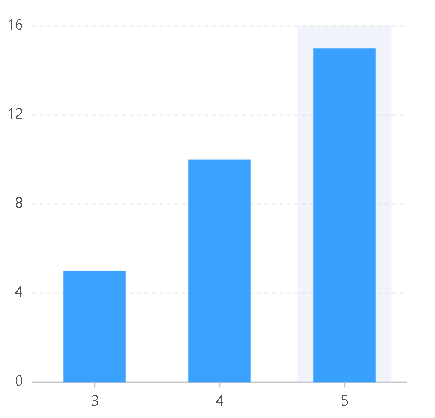
const data=[{name:1,value:1},{name:2,value:2},{name:3,value:3},{name:4,value:4},{name:5,value:5},{name:6,value:6},{name:1024,value:15}];const chart=new G2.Chart({container:"root",width:400,height:400,options:{scales:{name:{type:"log"//type:"linear"}}}});chart.source(data);chart.point().position("name*value");chart.render();
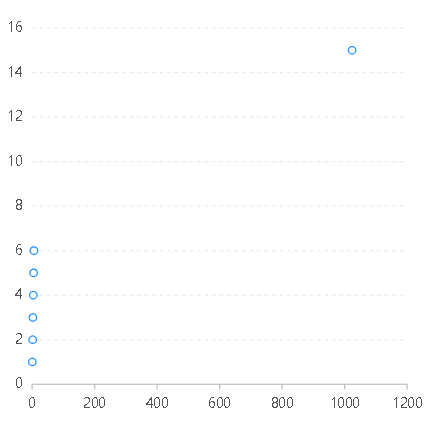
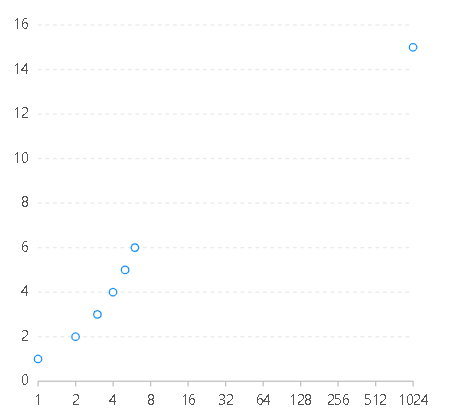
type为linear type为log
由以上两图可以看出,当数据分布不均匀时,此处低值数值比较密集,如果用linea类型r,则低数值范围基本排为一列,看不出差异;但是如果用log类型,则低数值范围也能很好的展示。
pow
pow类型的度量能将数据[1,2,3,4,5]转换成[2,4,8,16,32]然后进行归一化处理,它也是linear类型的一个子类,除了支持所有通用的属性和linear度量的属性外也有自己的属性:
| 属性名 | 说明 |
|---|---|
| exponent | 指数,默认是2 |
使用场景:
timeCat类型的数据,是一种日期数据,但是不是连续的日期。例如代表存在股票交易的日期,此时如果使用time类型,那么节假日没有数据,折线图、k线图会断裂,所以此时使用timeCat的度量表示分类的日期,默认会对数据做排序。
| 属性名 | 说明 |
|---|---|
| tickCount | 此时需要设置坐标点的个数 |
| mask | 数据的格式化格式 |
timeCat、time、cat的区别
举例:
代码:
const data=[{name:2,value:2,time:"1996-05-01"},{name:3,value:3,time:"1996-05-02"},{name:4,value:4,time:"1996-05-03"},{name:5,value:5,time:"1996-08-01"},{name:6,value:16,time:"1996-09-03"},{name:1024,value:15,time:"1996-08-02"}];const chart=new G2.Chart({container:"root",width:400,height:400,options:{scales:{time:{type:"timeCat"//type:"time"//type:"cat"}}}});chart.source(data);chart.interval().position("time*value");chart.render();
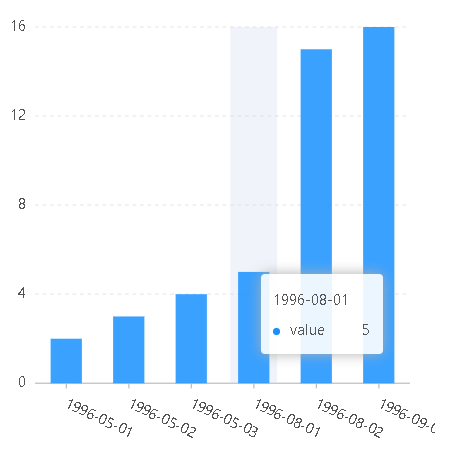
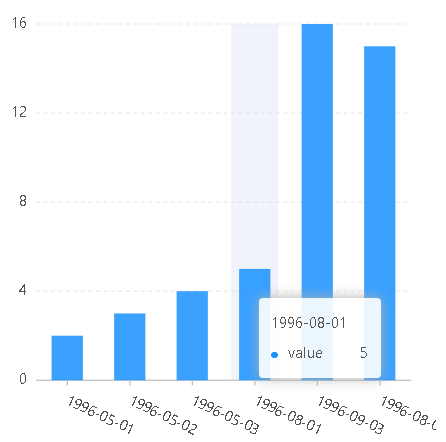
type为timeCat type为cat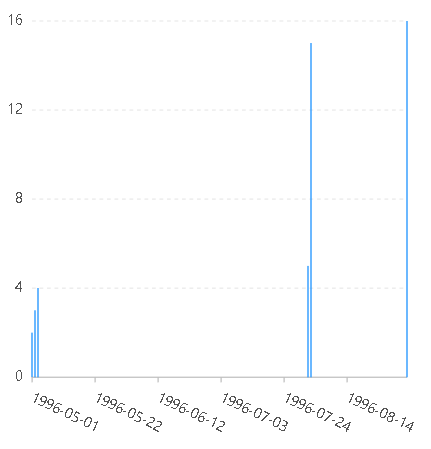
type为time
从以上三幅图的对比中我们可以看出:
timeCat与cat的区别:timeCat会对分类的时间进行排序,而cat只是简单的分类,并不会对分类进行排序,
可以把timeCat理解成time和cat的子类,所以既有time对日期排序的特性,也有cat分类的特性。
timeCat与time的区别:timeCat是分类度量,对时间进行分类,然后再进行归一化出处理,而time是连续度量,会对时间直接进行归一化处理。

若有收获,就点个赞吧
0 人点赞
