- MDP背景介绍
- MDP动态特性
- MDP价值函数
- MDP贝尔曼期望方程
- 价值函数分类
- 两种价值函数之间的关系
- #card=math&code=v%5Cpi%28s%29&id=u1ivw) 和 #card=math&code=q_%5Cpi%28s%2Ca%29&id=ew1J8) 之间的关系">
#card=math&code=v%5Cpi%28s%29&id=u1ivw) 和 #card=math&code=q_%5Cpi%28s%2Ca%29&id=ew1J8) 之间的关系
- #card=math&code=q%5Cpi%28s%2Ca%29&id=NLYHI) 和 #card=math&code=v_%5Cpi%28s%27%29&id=LDmyE) 之间的关系">
#card=math&code=q%5Cpi%28s%2Ca%29&id=NLYHI) 和 #card=math&code=v_%5Cpi%28s%27%29&id=LDmyE) 之间的关系
- #card=math&code=v%5Cpi%28s%29&id=u1ivw) 和 #card=math&code=q_%5Cpi%28s%2Ca%29&id=ew1J8) 之间的关系">
- 贝尔曼期望等式(方程)
- Summary
- MDP贝尔曼最优方程
- PDF版本
- 参考文献
作者:YJLAugus 博客: https://www.cnblogs.com/yjlaugus 项目地址:https://github.com/YJLAugus/Reinforcement-Learning-Notes,如果感觉对您有所帮助,烦请点个⭐Star。
MDP背景介绍
Random Variable
随机变量(Random Variable),通常用大写字母来表示一个随机事件。比如看下面的例子:
: 河水是咸的
: 井水是甜的
很显然,,
两个随机事件是没有关系的。也就是说
和
之间是相互独立的。记作:
Stochastic Process
对于一类随机变量来说,它们之间存在着某种关系。比如:
:表示在
时刻某支股票的价格,那么
和
之间一定是有关系的,至于具体什么样的关系,这里原先不做深究,但有一点可以确定,两者之间一定存在的一种关系。随着时间
的变化,可以写出下面的形式:
这样就生成了一组随机变量,它们之间存在着一种相当复杂的关系,也就是说,各个随机变量之间存在着关系,即不相互独立。由此,我们会把按照某个时间或者次序上的一组不相互独立的随机变量的这样一个整体作为研究对象。这样的话,也就引出了另外的一个概念:随机过程(Stochastic Process)。也就是说随机过程的研究对象不在是单个的随机变量,而是一组随机变量,并且这一组随机变量之间存在着一种非常紧密的关系(不相互独立)。记作:
Markov Chain/Process
马尔科夫链(Markov Chain)即马尔可夫过程,是一种特殊的随机过程——具备马尔可夫性的随机过程。
- 马尔可夫性:(Markov Property): 还是上面股票的例子,如果满足
%20%3D%20P(S%7Bt%2B1%7D%5Cmid%20S_t)#card=math&code=P%28S%7Bt%2B1%7D%20%5Cmid%20St%2CS%7Bt-1%7D…S1%29%20%3D%20P%28S%7Bt%2B1%7D%5Cmid%20St%29&id=zWx37),即具备了马尔可夫性。简单来说, 和
之间存在关系,和以前的时刻的没有关系,即只和“最近的状态” 有关系。
- 现实例子:下一个时刻仅依赖于当前时刻,跟过去无关。比如:一个老师讲课,明天的讲课状态一定和今天的状态最有关系,和过去十年的状态基本就没关系了。
- 最主要考量:为了简化计算。
马尔可夫链/过程 即满足马尔可夫性质的随机过程,记作:
%20%5Cmid%20St%2CS%7Bt-1%7D…S1)%20%3D%20P(S%7Bt%2B1%7D%5Cmid%20St)%0A#card=math&code=%5Clarge%20P%28S%7Bt%2B1%7D%29%20%5Cmid%20St%2CS%7Bt-1%7D…S1%29%20%3D%20P%28S%7Bt%2B1%7D%5Cmid%20S_t%29%0A&id=FIGhP)
State Space Model
状态空间模型(State Space Model),常应用于 HMM,Kalman Filterm Particle Filter,关于这几种这里不做讨论。在这里就是指马尔可夫链 + 观测变量,即Markov Chain + Obervation

如上图所示,s1-s2-s3为马尔可夫链,a1, a2, a3为观测变量,以a2为例,a2只和s2有关和s1, s3无关。状态空间模型可以说是由马尔可夫链演化而来的模型。记作:
Markov Reward Process
马尔可夫奖励过程(Markov Reward Process),即马尔可夫链+奖励,即:Markov Chain + Reward。如下图:

举个例子,比如说你买了一支股票,然后你每天就会有“收益”,当然了这里的收益是泛化的概念,收益有可能是正的,也有可能是负的,有可能多,有可能少,总之从今天的状态 到明天的状态
,会有一个
reward。记作:
Markov Decision Process
马尔可夫决策过程(Markov Decision Process),即马尔可夫奖励过程的基础上加上action,即:Markov Chain + Reward + action。如果还用刚才的股票为例子的话,我们只能每天看到股票价格的上涨或者下降,然后看到自己的收益,但是无法操作股票的价格的,只有看到份,只是一个“小散户”。这里的马尔可夫决策过程相当于政策的制定者,相当于一个操盘手,可以根据不同的状态而指定一些政策,也就相当于 action。
在马尔可夫决策过程中,所有的状态是我们看成离散的,有限的集合。所有的行为也是离散有限的集合。记作:
%7D%20%5Cquad%5Cquad%20At%5C%5C%0A%5Cit%20R%3A%20%5Cquad%20reward%20%5Cquad%20set%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%20R_t%2C%20R%7B(t%2B1)%7D%20%5C%5C%0A%7D%0A#card=math&code=%5Clarge%0A%5Cenclose%7Bbox%7D%7B%0A%5Cit%20S%3A%20%5Cquad%20state%20%5Cquad%20set%20%5Cquad%20%5Cquad%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%20St%20%5C%5C%20%0A%5Cit%20A%3A%20%5Cquad%20action%20%5Cquad%20set%20%2C%5Cquad%20%5Cquad%20%5Cforall%20s%20%5Cin%20S%2CA%7B%28s%29%7D%20%5Cquad%5Cquad%20At%5C%5C%0A%5Cit%20R%3A%20%5Cquad%20reward%20%5Cquad%20set%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%20R_t%2C%20R%7B%28t%2B1%29%7D%20%5C%5C%0A%7D%0A&id=wckEZ)
对于上述公式简单说明, 用来表示某一个时刻的状态。
%7D#card=math&code=A%7B%28s%29%7D&id=XlPSR) 表示在某一个状态时候的行为 ,这个行为一定是基于某个状态而言的,假设在
时刻的状态为
此时的
action记作 。%7D#card=math&code=Rt%20%E5%92%8C%20R%7B%28t%2B1%29%7D&id=kKXRI) 只是记法不同,比如下面的例子:从
状态经过
到
状态,获得的奖励一般记作
%7D#card=math&code=R%7B%28t%2B1%29%7D&id=nyr82)。 也就是说
,
,%7D#card=math&code=R_%7B%28t%2B1%29%7D&id=Dh2D8) 是配对使用的。

Summary

MDP动态特性
Markov Chain
马尔可夫链只有一个量——状态。比如 #card=math&code=S%5Cin%28s1%2Cs_2%2Cs_3%2Cs_4%2Cs_5%2Cs_6%2Cs_7%2Cs_8%2Cs_9%2Cs%7B10%7D%29&id=Z3eur) ,在状态集合中一共有十个状态,每个状态之间可以互相转化,即可以从一个状态转移到另外一个状态,当然,“另外的状态” 也有可能是当前状态本身。如下图所示,s1状态到可以转移到s2状态,s1状态也可以转移到自己当前的状态,当然s1也有可能转移到s3,s4,s5,状态,下图中没有给出。

根据上面的例子,我们可以把所有的状态写成矩阵的形式,就成了状态转移矩阵。用状态转移矩阵来描述马尔可夫链的动态特性。以上面的状态集合#card=math&code=S%5Cin%28s1%2Cs_2%2Cs_3%2Cs_4%2Cs_5%2Cs_6%2Cs_7%2Cs_8%2Cs_9%2Cs%7B10%7D%29&id=uyPnf) 为例,可得一个
的矩阵。如下图所示:
由上面的例子可知,在状态转移的过程中,对于下一个状态转移是有概率的,比如说s1转移到到s1状态的概率可能是0.5,s1有0.3的概率转移到s2状态。⻢尔科夫过程是⼀个⼆元组(S, P) , 且满⾜: S是有限状态集合, P是状态转移概率。 可得:
一个简单的例子:如图2.2所⽰为⼀个学⽣的7种状态{娱乐, 课程1, 课程2, 课程3, 考过, 睡觉, 论⽂}, 每种状态之间的转换概率如图所⽰。 则该⽣从课程 1 开始⼀天可能的状态序列为:
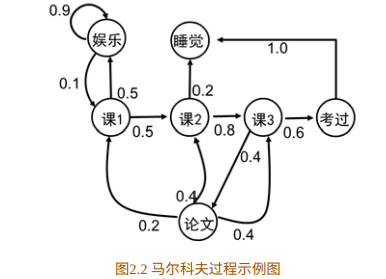
MRP
在 MPR 中,打个比喻,更像是随波逐流的小船,没有人为的干预,小船可以在大海中随波逐流。
MDP
在MDP中,打个比喻,更像是有人划的小船,这里相比较MRP中的小船来说,多了“人划船桨”的概念,可以认为控制船的走向。这里我们看下面的图:

s1状态到s2状态的过程,agent从s1发出action A1,使得s1状态转移到s2状态,并从s2状态得到一个R2的奖励。其实就是下图所示的一个过程。这是一个动态的过程,由此,引出动态函数。
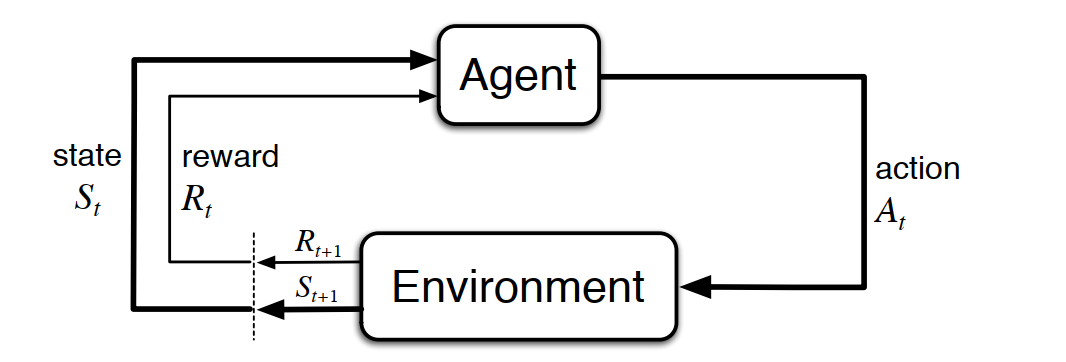
- 动态函数: The function
defines the dynamics of the MDP. 这是书上的原话,也就说,这个动态函数定义了MDP的
动态特性,动态函数如下:%20%5Cdot%7B%3D%7D%20Pr%5Clbrace%20S%7Bt%2B1%7D%3Ds’%2CR%7Bt%2B1%7D%20%3D%20r%20%5Cmid%20S%7Bt%7D%20%3Ds%2CA%7Bt%7D%3Da%20%5Crbrace%0A#card=math&code=%5Clarge%0Ap%28s%27%2Cr%5Cmid%20s%2Ca%29%20%5Cdot%7B%3D%7D%20Pr%5Clbrace%20S%7Bt%2B1%7D%3Ds%27%2CR%7Bt%2B1%7D%20%3D%20r%20%5Cmid%20S%7Bt%7D%20%3Ds%2CA%7Bt%7D%3Da%20%5Crbrace%0A&id=CqMeS)
- 状态转移函数: 我们去掉
,也就是
reward,动态函数也就成了状态转移函数。
%20%5Cdot%7B%3D%7D%20Pr%5Clbrace%20S%7Bt%2B1%7D%3Ds’%2C%5Cmid%20S%7Bt%7D%20%3Ds%2CA%7Bt%7D%3Da%20%5Crbrace%20%5C%5C%0A%20%20p(s’%5Cmid%20s%2Ca)%20%3D%20%5Csum%7Br%5Cin%20R%7D%20p(s’%5Cmid%20s%2Ca)%0A%20%20%7D%0A#card=math&code=%5Clarge%7B%0Ap%28s%27%5Cmid%20s%2Ca%29%20%5Cdot%7B%3D%7D%20Pr%5Clbrace%20S%7Bt%2B1%7D%3Ds%27%2C%5Cmid%20S%7Bt%7D%20%3Ds%2CA%7Bt%7D%3Da%20%5Crbrace%20%5C%5C%0A%20%20p%28s%27%5Cmid%20s%2Ca%29%20%3D%20%5Csum%7Br%5Cin%20R%7D%20p%28s%27%5Cmid%20s%2Ca%29%0A%20%20%7D%0A&id=hWU8W)
**reward**的动态性: 在 s 和 a 选定后,r 也有可能是不同的,即 r 也是随机变量。但是,大多数情况在 s 和 a 选定后 r 是相同的,这里只做简单的介绍。
Summary
MDP价值函数
策略的定义
在MDP中,即马尔可夫决策过程,最重要的当然是策略(Policy),用 来表示。在策略中其主要作用的就是
action,也即 ,需要指出的一定是,action 一定是基于某一状态 S 时。看下面的例子:

即,当 状态时,无论
取何值,只要遇到
状态就 选定
这个 action ,这就是一种策略,并且是确定性策略。
策略的分类
- 确定性策略:也就是说和时间
已经没有关系了,只和这个状态有关,只要遇到这个状态,就做出这样的选择。
- 随机性策略:与确定性策略相对,当遇到
状态时,可能选择
,可能选择
,也可能选择
。只是选择action的概率不同。如下图,就是两种不同的策略:

从上面两天图中,因为一个策略是基于一个状态而言的,在状态,可能选择
,可能选择
,也可能选择
,故三个
action之间是或的关系,所以说以上是两个策略,而不要误以为是6个策略。
故策略可分为确定性策略和随机性策略两种。
%24%7D%20%5C%5C%20%E9%9A%8F%E6%9C%BA%E6%80%A7%E7%AD%96%E7%95%A5%2C%20%26%20%5Ctext%20%7B%20%24%5Cpi(a%5Cmid%20s)%20%5Cdot%7B%3D%7D%20P%20%5Clbrace%20A_t%3Da%20%5Cmid%20S_t%20%3D%20s%20%5Crbrace%24%7D%20%5Cend%7Bcases%7D%0A#card=math&code=%5Clarge%0APolicy%3D%20%5Cbegin%7Bcases%7D%20%E7%A1%AE%E5%AE%9A%E6%80%A7%E7%AD%96%E7%95%A5%2C%20%26%20%5Ctext%20%7Ba%20%24%5Cdot%7B%3D%7D%5Cpi%28s%29%24%7D%20%5C%5C%20%E9%9A%8F%E6%9C%BA%E6%80%A7%E7%AD%96%E7%95%A5%2C%20%26%20%5Ctext%20%7B%20%24%5Cpi%28a%5Cmid%20s%29%20%5Cdot%7B%3D%7D%20P%20%5Clbrace%20A_t%3Da%20%5Cmid%20S_t%20%3D%20s%20%5Crbrace%24%7D%20%5Cend%7Bcases%7D%0A&id=kvpmE)
对于随机性策略而言,给定一个 ,选择一个
,也就是条件概率了。
确定性策略可以看作是一种特殊的随机性策略,以上表-Policy1为例,选择a1的概率为1,选择a2,a3的概率都为0。
最优策略
在所有的策略中一定存在至少一个最优策略,而且在强化学习中,reward的获得有延迟性(delay),举雅达利游戏中,很多游戏只有到结束的时候才会知道是否赢了或者输了,才会得到反馈,也就是reward,所以这就是奖励获得延迟。当选定一个状态 时,选定action
,因为奖励延迟的原因可能对后续的
等状态都会产生影响。这样,就不能用当前的reward来衡量策略的好坏、优劣。这里引入了回报和价值函数的概念。
回报( )
)
而是后续多个reward的加和,也就是回报,用 表示
时刻的回报。

如上图所示,此时的“回报”可以表示为:
值得注意的是, 可能是有限的,也有可能是无限的。
举例:张三对李四做了行为,对李四造成了伤害,李四在当天就能感受到伤害,而且,这个伤害明天,后头都还是有的,但是,时间是最好的良药,随着时间的推移,李四对于张三对自己造成的伤害感觉没有那么大了,会有一个wei折扣,用 来表示。故真正的回报表示为:
%0A#card=math&code=%5Clarge%0AGt%20%3D%20R%7Bt%2B1%7D%20%2B%20%5Cgamma%20R%7Bt%2B2%7D%2B%5Cgamma%5E2%20R%7Bt%2B3%7D%20%5C%20…%5C%20%2B%5Cgamma%5E%7BT-t-1%7DRT%20%3D%20%5Csum%7Bi%3D0%7D%5E%7B%5Cinfty%7D%5Cgamma%5Ei%20R_%7Bt%2Bi%2B1%7D%20%5Cquad%20%5Cquad%20%5Cgamma%5Cin%5B0%2C1%5D%2C%5Cquad%20%28T%5Crightarrow%5Cinfty%29%0A&id=M7nv9)
用 来衡量一个策略的好坏,
大的策略就好,反之。
但是使用 也不能很好的衡量策略的好坏,比如一个最大的问题是,在给定一个状态后,选择一个确定的action后(这里还是在随机策略的角度),进入的下一个状态也是随机的。如下图所示:把左侧的过程放大,只给出a3下的随机状态,a1,a2也是有同样的情况,这里胜率。

举个例子,就像我们给一盆花浇水,水是多了还是少了,对于这盆花来说我们是不得知的,可能会少,也可能会多。这个花的状态变化也就是随机的了。从上面的例子得知,如果还是用 来对一个策略来进行评估的话,至少有9中情况(随机策略,3个action选一种)。
只能评估的是一个“分叉”而已(图中
绿色分支)。而不能更好的进行评估。如下图所示:

因为回报不能很好的对策略进行一个评估,由此引入了另外一个概念——价值函数。
价值函数(Value Function )
在指定一个状态 ,采取一个
随机策略 ,然后加权平均,以上图为例,把9 个分叉(
)加权平均。也就是期望
。故得出价值函数:
%20%3D%20E%5Cpi%5BG_t%5Cmid%20S_t%20%3D%20s%5D%0A#card=math&code=%5Clarge%0AV%5Cpi%28s%29%20%3D%20E_%5Cpi%5BG_t%5Cmid%20S_t%20%3D%20s%5D%0A&id=GHhb9)
Summary

MDP贝尔曼期望方程
价值函数分类
上面提到的的价值函数其实是其中的一种,确切的可以称为 状态价值函数,用#card=math&code=v%5Cpi%28s%29&id=mqCFl) 来表示只和状态有关系。初次之外还有另外一种价值函数,那就是
状态动作价值函数,用#card=math&code=q_%5Cpi%28s%2Ca%29&id=Zukto)这里引入的action。故价值函数可以分为下面的两种:
%20%3D%20E%5Cpi%5BG_t%5Cmid%20S_t%20%3D%20s%5D%2C%20%26%20%5Ctext%20%7Bonly%20%24s%24%20is%20independent%20variable%7D%20%5C%5C%20q%5Cpi(s%2Ca)%20%3D%20E%5Cpi%5BG_t%5Cmid%20S_t%20%3D%20s%2CA_t%20%3D%20a%5D%2C%20%26%20%5Ctext%7BBoth%20%24s%24%20and%20a%20are%20independent%20variable%7D%20%5Cend%7Bcases%7D%0A#card=math&code=Value%20%5Cquad%20Function%20%3D%20%5Cbegin%7Bcases%7D%20v%5Cpi%28s%29%20%3D%20E%5Cpi%5BG_t%5Cmid%20S_t%20%3D%20s%5D%2C%20%26%20%5Ctext%20%7Bonly%20%24s%24%20is%20independent%20variable%7D%20%5C%5C%20q%5Cpi%28s%2Ca%29%20%3D%20E_%5Cpi%5BG_t%5Cmid%20S_t%20%3D%20s%2CA_t%20%3D%20a%5D%2C%20%26%20%5Ctext%7BBoth%20%24s%24%20and%20a%20are%20independent%20variable%7D%20%5Cend%7Bcases%7D%0A&id=VmQGR)
从上面的公式中,我们可以得知,在 #card=math&code=v%5Cpi%28s%29&id=HMqdc) 中,只有
是自变量,一个
其实就是一个状态
和一个action的一个映射。故,只要
确定了,那么
也就确定了,即此时的
对状态
是有限制作用的。但是,在 #card=math&code=q%5Cpi%28s%2Ca%29&id=lETOJ) 中,子变量为
两个,这两个自变量之间是没有特定的关系的。也就是说,
和
都在变,无法确定一个映射(策略)
,那么也就是说在  中的
对于
是没有约束的。
两种价值函数之间的关系
#card=math&code=v%5Cpi%28s%29&id=u1ivw) 和 #card=math&code=q_%5Cpi%28s%2Ca%29&id=ew1J8) 之间的关系

还是以上图为例,对于 s 状态,在随机策略中有三种 action 选择,分别是 #card=math&code=%5Cpi%28a1%20%5Cmid%20s%29&id=iz9as),
 ,
, ,三种action(行为)对应的价值函数(此时为动作价值函数)为 #card=math&code=q%5Cpi%28s%2Ca1%29&id=LhbqD), #card=math&code=q%5Cpi%28s%2Ca2%29&id=kIMLP), #card=math&code=q%5Cpi%28s%2Ca3%29&id=qzajD)。那么此时的 #card=math&code=v_%5Cpi%28s%29&id=wOt4M) 就等于各个action的动作状态价值函数的加和,即:
,三种action(行为)对应的价值函数(此时为动作价值函数)为 #card=math&code=q%5Cpi%28s%2Ca1%29&id=LhbqD), #card=math&code=q%5Cpi%28s%2Ca2%29&id=kIMLP), #card=math&code=q%5Cpi%28s%2Ca3%29&id=qzajD)。那么此时的 #card=math&code=v_%5Cpi%28s%29&id=wOt4M) 就等于各个action的动作状态价值函数的加和,即:
%20%3D%20%5Cpi(a1%20%5Cmid%20s)%C2%B7q%5Cpi(s%2Ca1)%20%2B%20%20%5Cpi(a_2%20%5Cmid%20s)%C2%B7q%5Cpi(s%2Ca2)%20%2B%20%20%5Cpi(a_3%20%5Cmid%20s)%C2%B7q%5Cpi(s%2Ca3)%0A#card=math&code=v%5Cpi%28s%29%20%3D%20%5Cpi%28a1%20%5Cmid%20s%29%C2%B7q%5Cpi%28s%2Ca1%29%20%2B%20%20%5Cpi%28a_2%20%5Cmid%20s%29%C2%B7q%5Cpi%28s%2Ca2%29%20%2B%20%20%5Cpi%28a_3%20%5Cmid%20s%29%C2%B7q%5Cpi%28s%2Ca_3%29%0A&id=xApMr)
这样一来我们就得出了 #card=math&code=v%5Cpi%28s%29&id=UDwuA) 和 #card=math&code=q%5Cpi%28s%2Ca%29&id=ZSqXR) 之间的关系,若条件已知,就可以直接计算出 。
%20%3D%20%5Csum%7Ba%5Cin%20A%7D%20%5Cpi(a%5Cmid%20s)%20%C2%B7q%5Cpi(s%2Ca)%0A#card=math&code=%5Clarge%0Av%5Cpi%28s%29%20%3D%20%5Csum%7Ba%5Cin%20A%7D%20%5Cpi%28a%5Cmid%20s%29%20%C2%B7q_%5Cpi%28s%2Ca%29%0A&id=wGJVO)
对于某个状态 来说,
#card=math&code=v%5Cpi%20%5Cleq%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29&id=iv40e) ,
#card=math&code=v%5Cpi%28s%29&id=nEWpJ) 是一个加权平均,实际上就是一个平均值,当然要小于等于#card=math&code=%5C%20q%5Cpi%28s%2Ca%29&id=KBi00)的最大值。#card=math&code=v_%5Cpi%28s%29&id=NGsYq)只有全部是最大值的时候,两者才有可能相等。比如 5,5,5,平均值是5,最大值也是5;3,4,5而言,平均值为4,但是最大值为5。注意的是,4是乘上权值后的值,换句话说也就是乘了一个概率(
#card=math&code=%5Cpi%28a%5Cmid%20s%29&id=qZTHG))。
#card=math&code=q%5Cpi%28s%2Ca%29&id=NLYHI) 和 #card=math&code=v_%5Cpi%28s%27%29&id=LDmyE) 之间的关系
从下面图中可得,在 #card=math&code=q%5Cpi%28s%2Ca%29&id=pBi6I) 位置,(一个action)状态转移只能向“箭头”方向转移,而不能向上。如果想从下面的状态转移到上面的状态,那必须还要另外一个action。情况是一样的,就按下图来说明,经过a3后到达状态s’,此时的状态函数就是 。

上面的图可知: 在确定了s 后,由随机策略action,引起“分叉”,同理,以a3为例,因为系统状态转移的随机性,也会引起分叉,也就是 s’ 的状态也是不确定的。还有一点 r 也又不确定性,如下图蓝色虚线部分。

由我们前面提到的公式也可得知:s’ 和 r 都是随机的。比如说s,a ,s’ 都是给定的,r也是不确定的。
%20%5Cdot%7B%3D%7D%20Pr%5Clbrace%20S%7Bt%2B1%7D%3Ds’%2CR%7Bt%2B1%7D%20%3D%20r%20%5Cmid%20S%7Bt%7D%20%3Ds%2CA%7Bt%7D%3Da%20%5Crbrace%0A#card=math&code=%5Clarge%20p%28s%27%2Cr%5Cmid%20s%2Ca%29%20%5Cdot%7B%3D%7D%20Pr%5Clbrace%20S%7Bt%2B1%7D%3Ds%27%2CR%7Bt%2B1%7D%20%3D%20r%20%5Cmid%20S%7Bt%7D%20%3Ds%2CA%7Bt%7D%3Da%20%5Crbrace%0A&id=ngsXW)
这样一来,可得一条蓝色通路的回报:
%20%3D%20r%20%2B%20%5Cgamma%20v%5Cpi(s’)%20%20%5Cquad%5Cquad%5Cquad%20(1)%0A#card=math&code=%5Clarge%0Aq%5Cpi%28s%2Ca%29%20%3D%20r%20%2B%20%5Cgamma%20v_%5Cpi%28s%27%29%20%20%5Cquad%5Cquad%5Cquad%20%281%29%0A&id=h75fm)
(1)式是怎么来的呢?以上图为例,在 #card=math&code=q%5Cpi%28s%2Ca%29&id=B6Vga) 处往下走,选定一个 r ,再往下到达一个状态s’, 此时在往下还是同样的状态,就是俄罗斯套娃,以此类推。关于其中的 $\gamma v\pi(s’) $ ,来自于
。看下面的式子:
%20%5C%5C%0AGt%20%3D%20R%7Bt%2B1%7D%20%2B%20%5Cgamma(R%7Bt%2B2%7D%2B%5Cgamma%20R%7Bt%2B3%7D%2B%5Cgamma%5E2%20R%7Bt%2B4%7D%2B%20…)%0A%7D%0A#card=math&code=%5Clarge%7B%0AG_t%20%3D%20R%7Bt%2B1%7D%20%2B%20%5Cgamma%20R%7Bt%2B2%7D%2B%5Cgamma%5E2%20R%7Bt%2B3%7D%20%5C%20…%5C%20%2B%5Cgamma%5E%7BT-t-1%7DRT%20%5Cquad%5Cquad%20%20%5Cgamma%5Cin%5B0%2C1%5D%2C%5Cquad%20%28T%5Crightarrow%5Cinfty%29%20%5C%5C%0AG_t%20%3D%20R%7Bt%2B1%7D%20%2B%20%5Cgamma%28R%7Bt%2B2%7D%2B%5Cgamma%20R%7Bt%2B3%7D%2B%5Cgamma%5E2%20R_%7Bt%2B4%7D%2B%20…%29%0A%7D%0A&id=H5x2x)
因为 #card=math&code=v_%5Cpi%28s%29&id=FdD9t) 来自
,故类比得(1)式。
因为走每条蓝色的通路也都是由概率的,故我们需要乘上概率,同时累加求和,一个是多条蓝色通路另一个是多个s’。故得:#card=math&code=q%5Cpi%28s%2Ca%29&id=DQTvT) 和 #card=math&code=v_%5Cpi%28s%27%29&id=kllne) 之间的关系 如下:
%20%3D%5Csum%7Bs’%2Cr%7DP(s’%2Cr%20%5Cmid%20s%2Ca)%5Br%2B%20%5Cgamma%20v%5Cpi(s’)%5D%20%5Cquad%5Cquad%5Cquad%20(2)%0A#card=math&code=%5Clarge%0Aq%5Cpi%28s%2Ca%29%20%3D%5Csum%7Bs%27%2Cr%7DP%28s%27%2Cr%20%5Cmid%20s%2Ca%29%5Br%2B%20%5Cgamma%20v_%5Cpi%28s%27%29%5D%20%5Cquad%5Cquad%5Cquad%20%282%29%0A&id=E3nEV)
贝尔曼期望等式(方程)
这样我们得到两个式子:
%20%3D%20%5Csum%7Ba%5Cin%20A%7D%20%5Cpi(a%5Cmid%20s)%20%C2%B7q%5Cpi(s%2Ca)%20%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5C%20(3)%20%5C%5C%0A%0Aq%5Cpi(s%2Ca)%20%3D%5Csum%7Bs’%2Cr%7DP(s’%2Cr%20%5Cmid%20s%2Ca)%5Br%2B%20%5Cgamma%20v%5Cpi(s’)%5D%20%5Cquad%5Cquad%5Cquad%20(4)%0A%7D%0A#card=math&code=%5Clarge%7B%0Av%5Cpi%28s%29%20%3D%20%5Csum%7Ba%5Cin%20A%7D%20%5Cpi%28a%5Cmid%20s%29%20%C2%B7q%5Cpi%28s%2Ca%29%20%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5C%20%283%29%20%5C%5C%0A%0Aq%5Cpi%28s%2Ca%29%20%3D%5Csum%7Bs%27%2Cr%7DP%28s%27%2Cr%20%5Cmid%20s%2Ca%29%5Br%2B%20%5Cgamma%20v_%5Cpi%28s%27%29%5D%20%5Cquad%5Cquad%5Cquad%20%284%29%0A%7D%0A&id=syCQM)
(4)式带入(3)得:
%20%3D%20%5Csum%7Ba%5Cin%20A%7D%20%5Cpi(a%5Cmid%20s)%20%5Csum%7Bs’%2Cr%7DP(s’%2Cr%20%5Cmid%20s%2Ca)%5Br%2B%20%5Cgamma%20v%5Cpi(s’)%5D%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%20(5)%0A#card=math&code=%5Clarge%0Av%5Cpi%28s%29%20%3D%20%5Csum%7Ba%5Cin%20A%7D%20%5Cpi%28a%5Cmid%20s%29%20%5Csum%7Bs%27%2Cr%7DP%28s%27%2Cr%20%5Cmid%20s%2Ca%29%5Br%2B%20%5Cgamma%20v_%5Cpi%28s%27%29%5D%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%20%285%29%0A&id=HjWLM)
(3)式带入(4)得:
%20%3D%5Csum%7Bs’%2Cr%7DP(s’%2Cr%20%5Cmid%20s%2Ca)%5Br%2B%20%5Cgamma%20%5Csum%7Ba’%5Cin%20A%7D%20%5Cpi(a’%5Cmid%20s’)%20%20%C2%B7q%5Cpi(s’%2Ca’)%20%5D%20%5Cquad%5Cquad%20(6)%0A#card=math&code=%5Clarge%0Aq%5Cpi%28s%2Ca%29%20%3D%5Csum%7Bs%27%2Cr%7DP%28s%27%2Cr%20%5Cmid%20s%2Ca%29%5Br%2B%20%5Cgamma%20%5Csum%7Ba%27%5Cin%20A%7D%20%5Cpi%28a%27%5Cmid%20s%27%29%20%20%C2%B7q_%5Cpi%28s%27%2Ca%27%29%20%5D%20%5Cquad%5Cquad%20%286%29%0A&id=RRrWC)
关于(6)式可以看下图,更容易理解:

(5)式和(6)式 被称为贝尔曼期望方程。
- 一个实例:
例子是一个学生学习考试的MDP。里面实心圆位置是起点,方框那个位置是终点。上面的动作有study, Pub, Facebook, Quit, Sleep,每个状态动作对应的即时奖励R已经标出来了。我们的目标是找到最优的状态动作价值函数或者状态价值函数,进而找出最优的策略。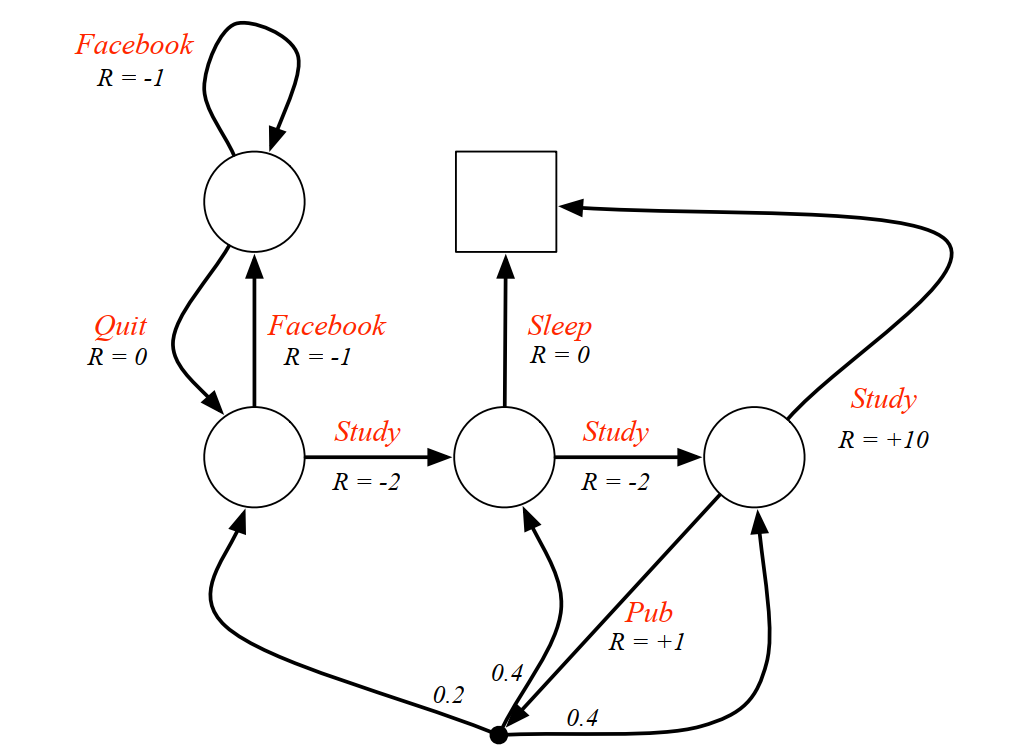
为了方便,我们假设衰减因子%20%3D%200.5#card=math&code=%5Cgamma%20%3D1%2C%20%5Cpi%28a%7Cs%29%20%3D%200.5&id=OgCZX) 。对于终点方框位置,由于其没有下一个状态,也没有当前状态的动作,因此其状态价值函数为0,对于其他的状态(圆圈)按照从上到下,从左到右的顺序定义其状态价值函数分别是
,根据(5)式 :
对于位置,我们有:
%20%2B0.5(0%2Bv_2)#card=math&code=v_1%20%3D%200.5%2A%28-1%2Bv_1%29%20%2B0.5%2A%280%2Bv_2%29&id=mtVTI)
对于位置,我们有:%20%2B0.5(-2%2Bv_3)#card=math&code=v_2%20%3D%200.5%2A%28-1%2Bv_1%29%20%2B0.5%2A%28-2%2Bv_3%29&id=N2oo8)
对于位置,我们有:%20%2B0.5(-2%2Bv_4)#card=math&code=v_3%20%3D%200.5%2A%280%2B0%29%20%2B0.5%2A%28-2%2Bv_4%29&id=WQ6HJ)
对于位置,我们有:%20%2B0.5(1%2B0.2v_2%2B0.4v_3%2B0.4v_4)#card=math&code=v_4%20%3D%200.5%2A%2810%2B0%29%20%2B0.5%2A%281%2B0.2%2Av_2%2B0.4%2Av_3%2B0.4%2Av_4%29&id=I94QV)
解出这个方程组可以得到, 即每个状态的价值函数如下图:
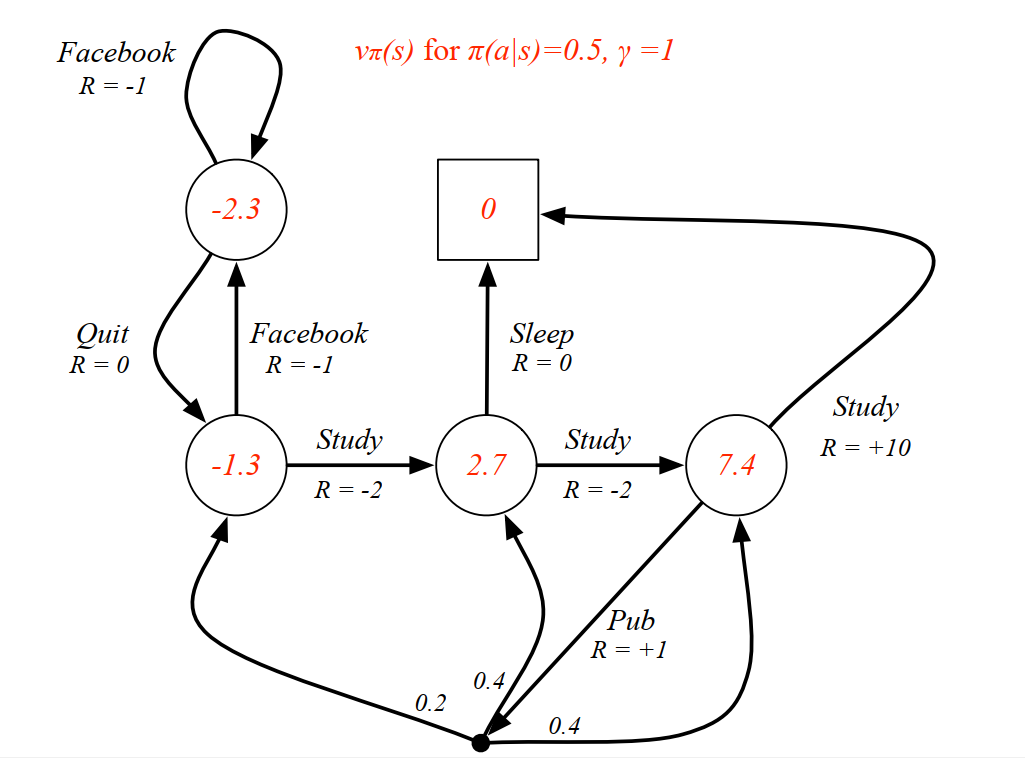
从上面可以看出,针对一个特定状体,状态价值函数计算都是基于下一个状态而言的,通俗的讲,按照“出箭头”的方向计算当前状态的价值函数。
Summary
MDP贝尔曼最优方程
最优价值函数
能够使得 达到最大值的那个
,这个
被成为最优策略,进而得到最优状态价值函数。同理得到最优状态动作价值函数。
%5C%20%5Cdot%7B%3D%7D%5C%20%5C%20%5Cunderset%7B%5Cpi%7D%7Bmax%7D%20%5C%20v%5Cpi(s)%20%26%20%5Ctext%7B%7D%20%5C%5C%0Aq*(s%2Ca)%5C%20%5Cdot%7B%3D%7D%5C%20%5C%20%5Cunderset%7B%5Cpi%7D%7Bmax%7D%20%5C%20q%5Cpi(s%2Ca)%20%26%20%5Ctext%7B%7D%20%26%20%5Ctext%20%7B%7D%20%5Cend%7Bcases%7D%0A#card=math&code=%5Clarge%0A%5Cbegin%7Bcases%7D%20v%2A%28s%29%5C%20%5Cdot%7B%3D%7D%5C%20%5C%20%5Cunderset%7B%5Cpi%7D%7Bmax%7D%20%5C%20v%5Cpi%28s%29%20%26%20%5Ctext%7B%7D%20%5C%5C%0Aq%2A%28s%2Ca%29%5C%20%5Cdot%7B%3D%7D%5C%20%5C%20%5Cunderset%7B%5Cpi%7D%7Bmax%7D%20%5C%20q_%5Cpi%28s%2Ca%29%20%26%20%5Ctext%7B%7D%20%26%20%5Ctext%20%7B%7D%20%5Cend%7Bcases%7D%0A&id=UNWOo)
记 %20%3D%20%5Cunderset%7B%5Cpi%7D%7Bargmax%7D%20%5C%20q%5Cpi(s%2Ca)#card=math&code=%5Cpi%2A%20%3D%20%5Cunderset%7B%5Cpi%7D%7Bargmax%7D%20%5C%20v%5Cpi%28s%29%20%3D%20%5Cunderset%7B%5Cpi%7D%7Bargmax%7D%20%5C%20q%5Cpi%28s%2Ca%29&id=fMR47),含义是
可以使得 $ v_*(s)$达到最大值,同样的,也可以使得
#card=math&code=q_%5Cpi%28s%2Ca%29&id=WuYFx) 达到最大值。
由以上公式得:
%3D%5Cunderset%7B%5Cpi%7D%7Bmax%7D%5C%20v%5Cpi(s)%3D%20v%7B%5Cpi*%7D(s)%20%26%20%5Ctext%7B(7)%7D%20%5C%5C%20%0Aq(s%2Ca)%3D%5Cunderset%7B%5Cpi%7D%7Bmax%7D%5C%20q%5Cpi(s%2Ca)%3D%20q%7B%5Cpi_%7D(s%2Ca)%20%26%20%5Ctext%7B%7D%20%26%20%5Ctext%20%7B(8)%7D%20%5Cend%7Bcases%7D%0A#card=math&code=%5Clarge%0A%5Cbegin%7Bcases%7Dv%2A%28s%29%3D%5Cunderset%7B%5Cpi%7D%7Bmax%7D%5C%20v%5Cpi%28s%29%3D%20v%7B%5Cpi%2A%7D%28s%29%20%26%20%5Ctext%7B%287%29%7D%20%5C%5C%20%0Aq%2A%28s%2Ca%29%3D%5Cunderset%7B%5Cpi%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29%3D%20q%7B%5Cpi%2A%7D%28s%2Ca%29%20%26%20%5Ctext%7B%7D%20%26%20%5Ctext%20%7B%288%29%7D%20%5Cend%7Bcases%7D%0A&id=CpWGN)
值得注意的一点是$ v*(s)$ 强调的是,不管你采用的是什么策略,只要状态价值函数达到最大值,而 #card=math&code=v%7B%5Cpi_%2A%7D%28s%29&id=BfS48) 则更为强调的是
,达到最大的状态价值函数所采取的最优的那个
此时,我们再探讨一下#card=math&code=v%7B%5Cpi%2A%7D%28s%29&id=aaUed) 和
#card=math&code=q%7B%5Cpi%2A%7D%28s%2Ca%29&id=Ee8Me) 的关系。在贝尔曼期望方程中,我们提到过
%20%5Cleq%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi(s%2Ca)#card=math&code=v%5Cpi%28s%29%20%5Cleq%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29&id=JDCio) ,那么在这里是不是也由类似的关系%5Cleq%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi(s%2Ca)#card=math&code=v%7B%5Cpi%2A%7D%28s%29%5Cleq%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29&id=aufF8) 成立?我们知道 #card=math&code=v%7B%5Cpi%2A%7D%28s%29&id=gPYRd) 是一种策略,并且是最优的策略,#card=math&code=q%7B%5Cpi%2A%7D%28s%2Ca%29&id=HPjbf) 是代表一个“分支”,因为 #card=math&code=v%7B%5Cpi%2A%7D%28s%29&id=e7q5E) 是一个加权平均值,但同样的,和#card=math&code=v%5Cpi%28s%29&id=XlwaL) 不同的是,#card=math&code=v%7B%5Cpi_%2A%7D%28s%29&id=Ba0ji) 是最优策略的加权平均,那么是不是可以把小于号去掉,写成下面的形式:
%3D%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi(s%2Ca)%0A#card=math&code=%5Clarge%0Av%7B%5Cpi%2A%7D%28s%29%3D%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29%0A&id=hlVwX)
假定 %5Cleq%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi(s%2Ca)#card=math&code=v%7B%5Cpi%2A%7D%28s%29%5Cleq%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29&id=h82SW) 中的
还是一个普通的策略,那么一定满足
%5Cleq%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi(s%2Ca)#card=math&code=v%7B%5Cpi%2A%7D%28s%29%5Cleq%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29&id=bg5ct) ,这一点我们已经提到过,如果说
%3C%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi(s%2Ca)#card=math&code=v%7B%5Cpi%2A%7D%28s%29%3C%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29&id=qPHjq) ,说明
#card=math&code=v%7B%5Cpi%2A%7D%28s%29&id=K6pss) 还有提高的空间,并不是最优策略,这和条件矛盾了。所以这个小于不成立,得证:
%3D%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi(s%2Ca)#card=math&code=v%7B%5Cpi%2A%7D%28s%29%3D%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29&id=lDLL5)
详细证明过程如下:

其实,上面的式子是由 (3)式
%20%3D%20%5Csum%7Ba%5Cin%20A%7D%20%5Cpi(a%5Cmid%20s)%20%C2%B7q%5Cpi(s%2Ca)%20%20%5Cquad%5Cquad%20(3)%0A#card=math&code=v%5Cpi%28s%29%20%3D%20%5Csum%7Ba%5Cin%20A%7D%20%5Cpi%28a%5Cmid%20s%29%20%C2%B7q_%5Cpi%28s%2Ca%29%20%20%5Cquad%5Cquad%20%283%29%0A&id=G8exu)
演变而来的。#card=math&code=v%7B%5Cpi%2A%7D%28s%29&id=DbyHK) 直接取最大值时候和
#card=math&code=%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29&id=x1adJ) 的最大值是相等的。也就是此时不用加权平均了,直接是 %20%3D%20q%5Cpi(s%2Ca)#card=math&code=v%5Cpi%28a%29%20%3D%20q_%5Cpi%28s%2Ca%29&id=XLYMk) 。那么从原先的(4)式能不能也得出相似
%20%3D%5Csum%7Bs’%2Cr%7DP(s’%2Cr%20%5Cmid%20s%2Ca)%5Br%2B%20%5Cgamma%20v%5Cpi(s’)%5D%20%5Cquad%5Cquad%20(4)%0A#card=math&code=q%5Cpi%28s%2Ca%29%20%3D%5Csum%7Bs%27%2Cr%7DP%28s%27%2Cr%20%5Cmid%20s%2Ca%29%5Br%2B%20%5Cgamma%20v_%5Cpi%28s%27%29%5D%20%5Cquad%5Cquad%20%284%29%0A&id=geVW3)
的结论,把求和符号去掉,直接等于最大值呢?答案是否定的,因为%3D%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi(s%2Ca)#card=math&code=v%7B%5Cpi%2A%7D%28s%29%3D%20%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%5Cpi%28s%2Ca%29&id=uYzSY) 是作用在
action上的,在公式中也可以看出,换句话说,我们对于下图的a1,a2,a3这里是可以控制的。但是对于下图中的蓝色虚线部分,系统状态转移是无法控制的。

所以,原先的两组公式(3)、(4)并 结合(7)、(8)
%20%3D%20%5Csum%7Ba%5Cin%20A%7D%20%5Cpi(a%5Cmid%20s)%20%C2%B7q%5Cpi(s%2Ca)%20%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5C%20(3)%20%5C%5C%0A%0Aq%5Cpi(s%2Ca)%20%3D%5Csum%7Bs’%2Cr%7DP(s’%2Cr%20%5Cmid%20s%2Ca)%5Br%2B%20%5Cgamma%20v%5Cpi(s’)%5D%20%5Cquad%5Cquad%5Cquad%20(4)%0A%7D%0A#card=math&code=%5Clarge%7B%0Av%5Cpi%28s%29%20%3D%20%5Csum%7Ba%5Cin%20A%7D%20%5Cpi%28a%5Cmid%20s%29%20%C2%B7q%5Cpi%28s%2Ca%29%20%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5C%20%283%29%20%5C%5C%0A%0Aq%5Cpi%28s%2Ca%29%20%3D%5Csum%7Bs%27%2Cr%7DP%28s%27%2Cr%20%5Cmid%20s%2Ca%29%5Br%2B%20%5Cgamma%20v_%5Cpi%28s%27%29%5D%20%5Cquad%5Cquad%5Cquad%20%284%29%0A%7D%0A&id=mw9oe)
并进行一个推导,得出另外的两组公式(9)、(10)如下:
%3D%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q*(s%2Ca)%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%20(9)%20%5C%5C%0Aq(s%2Ca)%3D%20%5Csum%7Bs’%2Cr%7DP(s’%2Cr%20%5Cmid%20s%2Ca)%5Br%2B%5Cgamma%20v(s’)%5D%20%5Cquad%5Cquad%5Cquad%20(10)%0A%7D%0A#card=math&code=%5Clarge%7B%0Av%2A%28s%29%3D%5Cunderset%7Ba%7D%7Bmax%7D%5C%20q%2A%28s%2Ca%29%20%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%20%289%29%20%5C%5C%0Aq%2A%28s%2Ca%29%3D%20%5Csum%7Bs%27%2Cr%7DP%28s%27%2Cr%20%5Cmid%20s%2Ca%29%5Br%2B%5Cgamma%20v_%2A%28s%27%29%5D%20%5Cquad%5Cquad%5Cquad%20%2810%29%0A%7D%0A&id=gwhAg)
贝尔曼最优方程
(10)式带入(9)式得:
%3D%5Cunderset%7Ba%7D%7Bmax%7D%5Csum%7Bs’%2Cr%7DP(s’%2Cr%20%5Cmid%20s%2Ca)%5Br%2B%5Cgamma%20v%5Cpi(s’)%5D%20%5Cquad%5Cquad(11)%20%5C%5C%0A%0A%0A%7D%0A#card=math&code=%5Clarge%7B%0Av%2A%28s%29%3D%5Cunderset%7Ba%7D%7Bmax%7D%5Csum%7Bs%27%2Cr%7DP%28s%27%2Cr%20%5Cmid%20s%2Ca%29%5Br%2B%5Cgamma%20v_%5Cpi%28s%27%29%5D%20%5Cquad%5Cquad%2811%29%20%5C%5C%0A%0A%0A%7D%0A&id=iaHrV)
(9)式带入(10)式得:
%3D%20%5Csum%7Bs’%2Cr%7DP(s’%2Cr%20%5Cmid%20s%2Ca)%5Br%2B%5Cgamma%20%5Cunderset%7Ba’%7D%7Bmax%7D%5C%20q*(s’%2Ca’)%20%5D%20%5Cquad%5Cquad%20(12)%0A#card=math&code=%5Clarge%0Aq%2A%28s%2Ca%29%3D%20%5Csum%7Bs%27%2Cr%7DP%28s%27%2Cr%20%5Cmid%20s%2Ca%29%5Br%2B%5Cgamma%20%5Cunderset%7Ba%27%7D%7Bmax%7D%5C%20q_%2A%28s%27%2Ca%27%29%20%5D%20%5Cquad%5Cquad%20%2812%29%0A&id=le439)
(11)、(12)被称为贝尔曼最优方程。
- 一个实例:还是以上面的例子讲解,我们这次以动作价值函数
#card=math&code=q%2A%28s%2Ca%29&id=tTtrW) 为例来求解 $v(s),q_(s,a) $
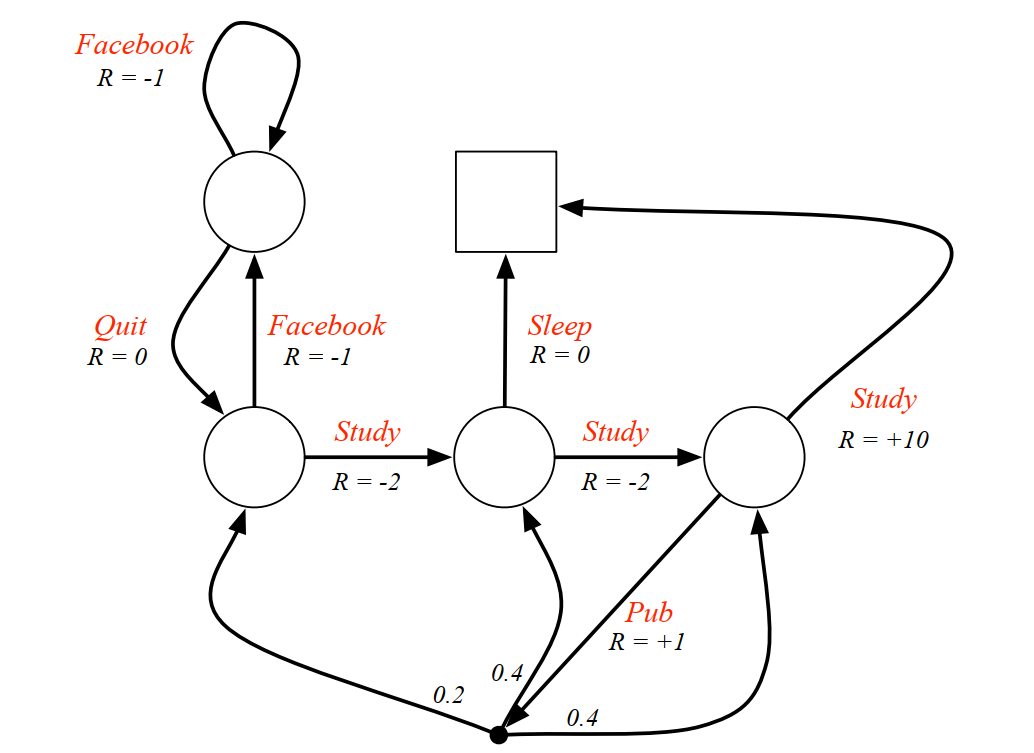
根据(12)式
%3D%20%5Csum%7Bs’%2Cr%7DP(s’%2Cr%20%5Cmid%20s%2Ca)%5Br%2B%5Cgamma%20%5Cunderset%7Ba’%7D%7Bmax%7D%5C%20q*(s’%2Ca’)%20%5D%20%5Cquad%5Cquad%20(12)%0A#card=math&code=%5Clarge%0Aq%2A%28s%2Ca%29%3D%20%5Csum%7Bs%27%2Cr%7DP%28s%27%2Cr%20%5Cmid%20s%2Ca%29%5Br%2B%5Cgamma%20%5Cunderset%7Ba%27%7D%7Bmax%7D%5C%20q_%2A%28s%27%2Ca%27%29%20%5D%20%5Cquad%5Cquad%20%2812%29%0A&id=K7WAJ)
可得方程组如下:
%20%26%20%3D%2010%20%5C%5C%0Aq(s_4%2C%20pub)%20%26%20%3D%201%20%2B%200.2%20%20%5Cunderset%7Ba’%7D%7Bmax%7Dq(s_2%2C%20a’)%20%2B%200.4%20%20max%7Ba’%7Dq(s_3%2C%20a’)%20%2B%200.4%20%20%5Cunderset%7Ba’%7D%7Bmax%7Dq*(s_4%2C%20a’)%20%5C%5C%0Aq(s3%2C%20sleep)%20%26%20%3D%200%20%20%5C%5C%0Aq(s3%2C%20study)%20%26%20%3D%20-2%20%2B%20%5Cunderset%7Ba’%7D%7Bmax%7Dq(s4%2C%20a’)%20%5C%5C%0Aq(s2%2C%20study)%20%26%20%3D%20-2%20%2B%20%5Cunderset%7Ba’%7D%7Bmax%7Dq(s3%2C%20a’)%20%5C%5C%0Aq(s2%2C%20facebook)%20%26%20%3D%20-1%20%2B%20%5Cunderset%7Ba’%7D%7Bmax%7Dq(s1%2C%20a’)%20%5C%5C%0Aq(s1%2C%20facebook)%20%26%20%3D%20-1%20%2B%20%5Cunderset%7Ba’%7D%7Bmax%7Dq(s1%2C%20a’)%20%5C%5C%0Aq(s1%2C%20quit)%20%26%20%3D%200%20%2B%20%5Cunderset%7Ba’%7D%7Bmax%7Dq*(s2%2C%20a’)%0A%5Cend%7Balign%7D%7D%0A#card=math&code=%5Clarge%7B%5Cbegin%7Balign%7D%0Aq%2A%28s4%2C%20study%29%20%26%20%3D%2010%20%5C%5C%0Aq%2A%28s4%2C%20pub%29%20%26%20%3D%201%20%2B%200.2%20%2A%20%5Cunderset%7Ba%27%7D%7Bmax%7Dq%2A%28s2%2C%20a%27%29%20%2B%200.4%20%2A%20max%7Ba%27%7Dq%2A%28s_3%2C%20a%27%29%20%2B%200.4%20%2A%20%5Cunderset%7Ba%27%7D%7Bmax%7Dq%2A%28s4%2C%20a%27%29%20%5C%5C%0Aq%2A%28s3%2C%20sleep%29%20%26%20%3D%200%20%20%5C%5C%0Aq%2A%28s3%2C%20study%29%20%26%20%3D%20-2%20%2B%20%5Cunderset%7Ba%27%7D%7Bmax%7Dq%2A%28s4%2C%20a%27%29%20%5C%5C%0Aq%2A%28s2%2C%20study%29%20%26%20%3D%20-2%20%2B%20%5Cunderset%7Ba%27%7D%7Bmax%7Dq%2A%28s3%2C%20a%27%29%20%5C%5C%0Aq%2A%28s2%2C%20facebook%29%20%26%20%3D%20-1%20%2B%20%5Cunderset%7Ba%27%7D%7Bmax%7Dq%2A%28s1%2C%20a%27%29%20%5C%5C%0Aq%2A%28s1%2C%20facebook%29%20%26%20%3D%20-1%20%2B%20%5Cunderset%7Ba%27%7D%7Bmax%7Dq%2A%28s1%2C%20a%27%29%20%5C%5C%0Aq%2A%28s1%2C%20quit%29%20%26%20%3D%200%20%2B%20%5Cunderset%7Ba%27%7D%7Bmax%7Dq%2A%28s_2%2C%20a%27%29%0A%5Cend%7Balign%7D%7D%0A&id=PQPOX)
然后求出所有的 #card=math&code=q%2A%28s%2Ca%29&id=Zy0Io),然后再利用 %20%3D%20%5Cunderset%7Ba’%7D%7Bmax%7Dq_(s%2Ca)#card=math&code=v%2A%28s%29%20%3D%20%5Cunderset%7Ba%27%7D%7Bmax%7Dq%2A%28s%2Ca%29&id=eMTeG),就可以求出所有的
#card=math&code=v_%2A%28s%29&id=dHPFA),最终结果如下图所示:
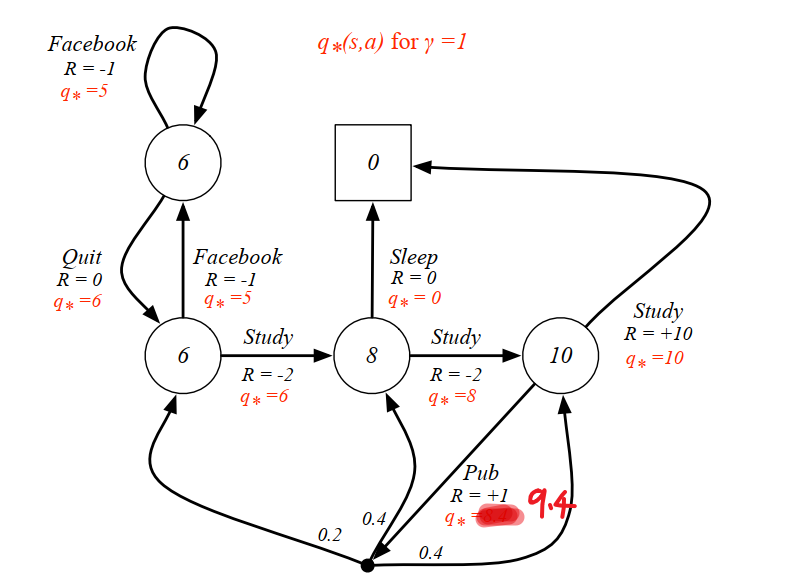
详细的计算过程可以看下视频 的简单分析。https://www.bilibili.com/video/BV1Fi4y157vR/
点击查看【bilibili】
Summary

PDF版本
参考文献
https://www.bilibili.com/video/BV1RA411q7wt
https://www.cnblogs.com/pinard/p/9426283.html
https://www.davidsilver.uk/wp-content/uploads/2020/03/MDP.pdf

若有收获,就点个赞吧
0 人点赞
