HBase 简介
HBase是什么
HBase 基于 Google的BigTable论而来,可以提供超大规模数据集的实时随机读写
HBase的特点

总结:HBase适合海量明细数据的存储,并且后期需要有很好的查询性能(单表超千万、上亿,且并发要求高)
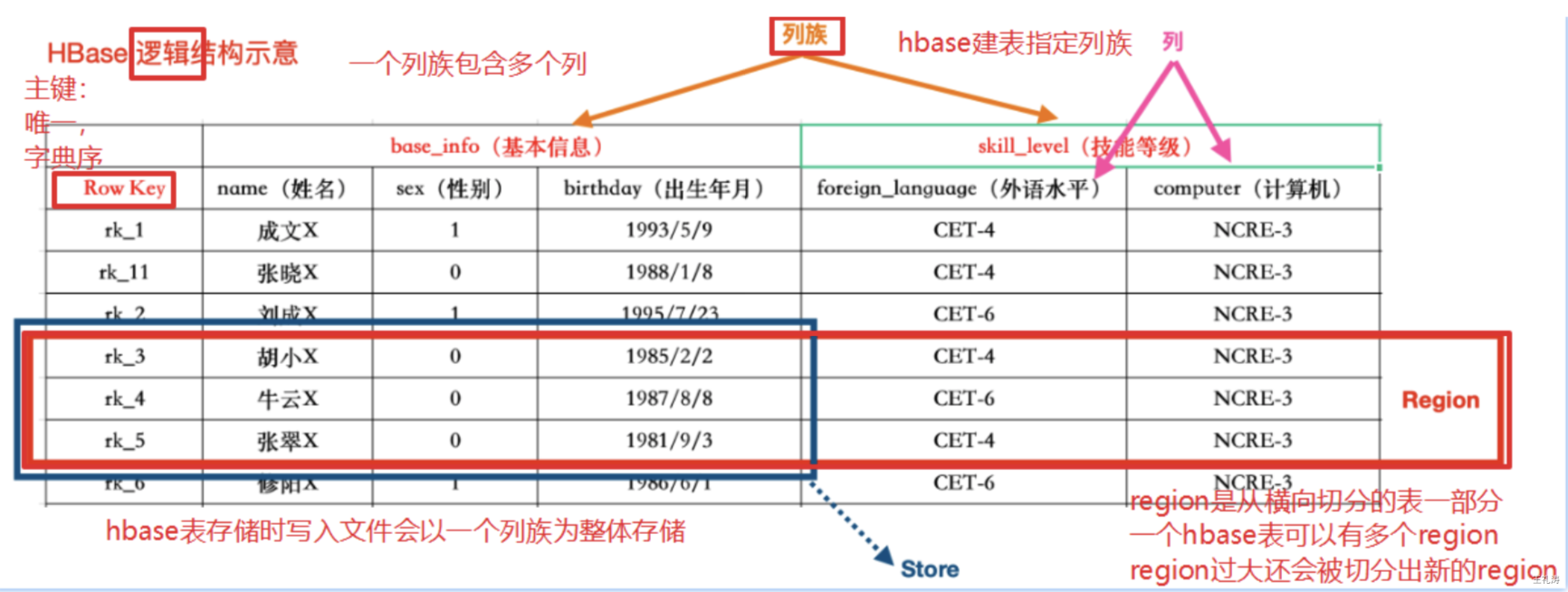
HBase数据模型
HBase的数据也是以表(有行有列)的形式存储
HBase逻辑架构
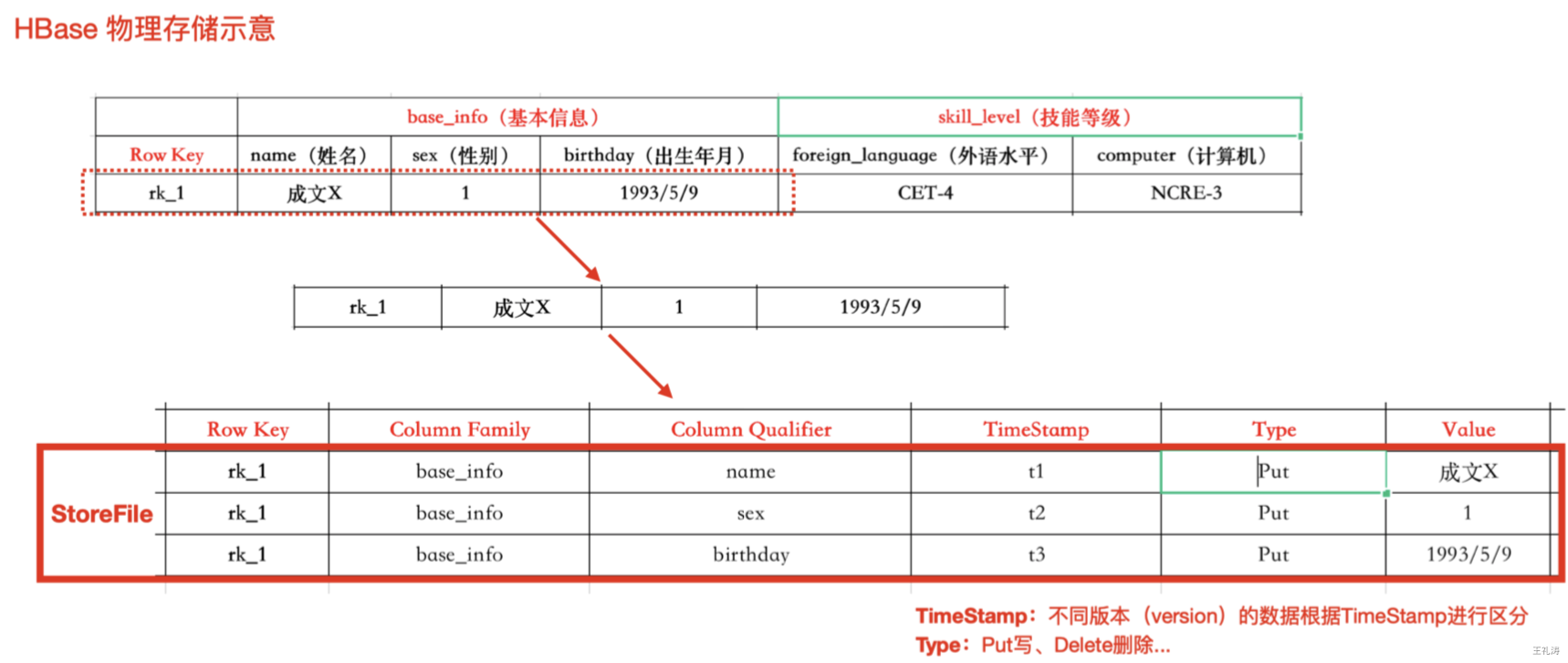
HBase物理存储
| 概念 | 描述 |
|---|---|
| NameSpace(数据库) | 命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。一个表可以自由选择是否有命名空间,如果创建表的时候加上了命名空间后,这个表名字以:作为区分! |
| Table | 类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,数据属性,比如超时时间(TTL),压缩算法 (COMPRESSION)等,都在列族的定义中定义,不需要声明具体的列。 |
| Row(每行逻辑数据) | HBase表中的每行数据都由一个RowKey和多个Column(列)组成。一个行包含了多个列,这些列通过列族来分类,行中的数据所属列族只能从该表所定义的列族中选取,不能定义这个表中不存在的列族,否则报错NoSuchColumnFamilyException。 |
| RowKey(每行数据主键) | Rowkey由用户指定的一串不重复的字符串定义,是每行的唯一标识!数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据 RowKey进行检索,所以RowKey的设计十分重要。如果使用了之前已经定义的RowKey,那么会将之前的数据更新掉! |
| Column Family(列族) | 列族是多个列的集合。一个列族可以动态地灵活定义多个列。表的相关属性大部分都定义在列族上,同一个表里的不同列族可以有完全不同的属性配置,但是同一个列族内的所有列都会有相同的属性。列族存在的意义是HBase会把相同列族的列尽量放在同一台机器器上,所以说,如果想让某几个列被放到一起,你就给他们定义相同的列族。 |
| Column Qualifier(列) | Hbase中的列是可以随意定义的。每行的列不限名字、不限数量,只限定列族。因此列必须依赖于列族存在!列的名称前必须带着其所属的列族!例如info:name,info:age |
| TimeStamp(时间戳->版本) | 用于标识数据的不同版本(version)。时间戳默认由系统指定,也可以由用户显式指定。在读取单元格的数据时,版本号可以省略,如果不指定,Hbase默认会获取最后一个版本的数据返回! |
| Cell | 每个列中可以存储多个版本的数据。每个版本就称为每个单元格(Cell)。 |
| Region(表的分区) | Region由一个表的若干行组成!在Region中行的排序按照行键(rowkey)字典排序。Region不能跨RegionSever,且当数据量大的时候, HBase会拆分Region。 |
HBase整体架构
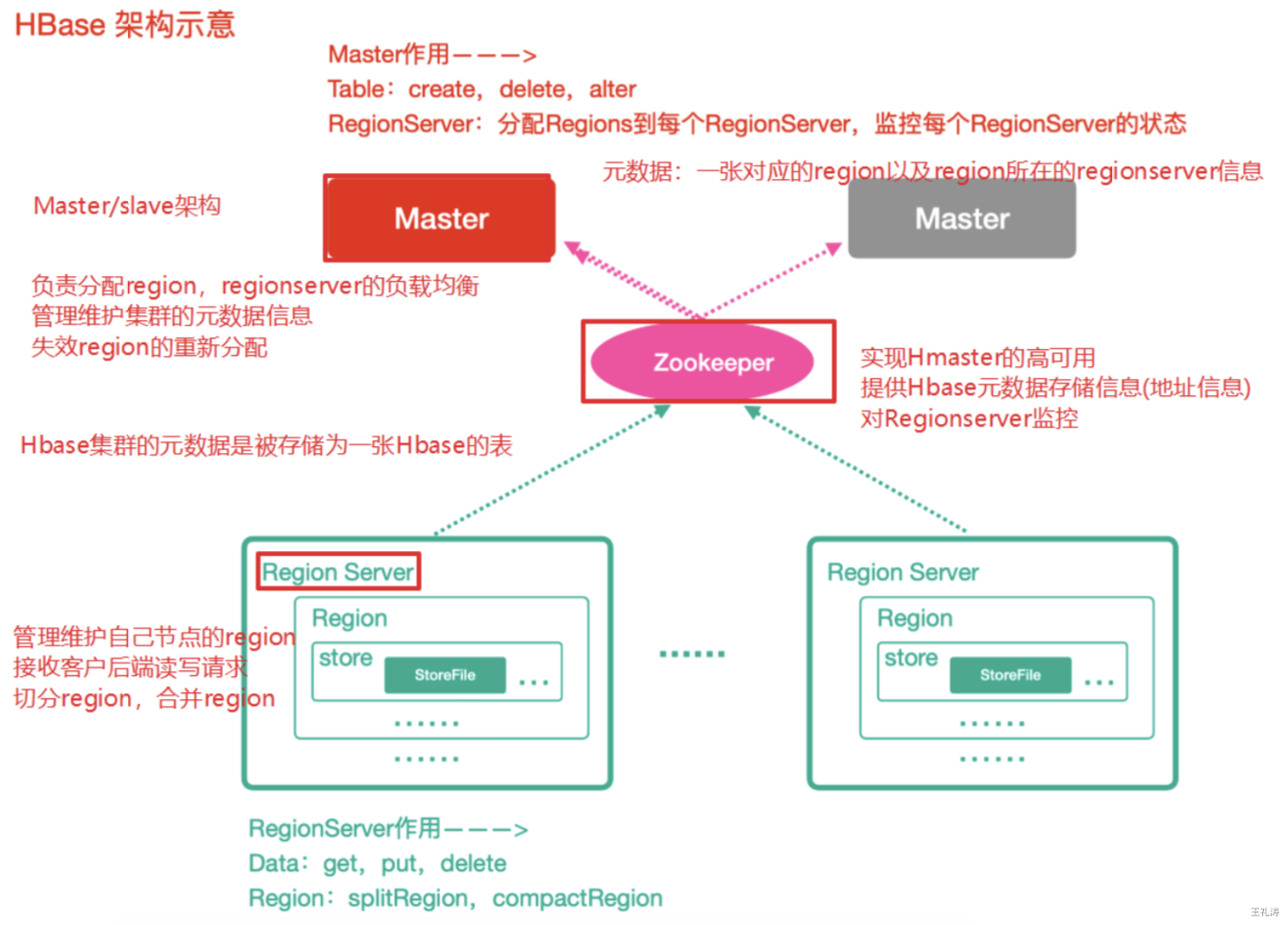
Zookeeper
- 实现了HMaster的高可用
- 保存了HBase的元数据信息,是所有HBase表的寻址入口
- 对HMaster和HRegionServer实现了监控
HMaster(Master)
- 为HRegionServer分配Region
- 维护整个集群的负载均衡
- 维护集群的元数据信息
发现失效的Region,并将失效的Region分配到正常的HRegionServer上
HMaster 是 HBase 集群中的主服务器,负责监控集群中的所有 RegionServer,并且是所有元数据更改的接口在分布式集群中,HMaster 服务器通常运行在 HDFS 的 NameNode上,HMaster 通过 ZooKeeper 来避免单点故障,在集群中可以启动多个 HMaster,但 ZooKeeper 的选举机制能够保证同时只有一个 HMaster 处于 Active 状态,其他的 HMaster 处于热备份状态HMaster 主要负责表和 Region 的管理工作1) 管理用户对表的增、删、改、查操作HMaster 提供了下表中的一些基于元数据方法的接口,便于用户与 HBase 进行交互2) 管理 RegionServer 的负载均衡,调整 Region 的分布3) Region 的分配和移除4) 处理 RegionServer 的故障转移当某台 RegionServer 出现故障时,总有一部分新写入的数据还没有持久化地存储到磁盘中,因此在迁移该 RegionServer 的服务时,需要从修改记录中恢复这部分还在内存中的数据,HMaster 需要遍历该 RegionServer 的修改记录,并按 Region 拆分成小块移动到新的地址下另外,当 HMaster 节点发生故障时,由于客户端是直接与 RegionServer 交互的,且 Meta 表也是存在于 ZooKeeper 当中,整个集群的工作会继续正常运行,所以当 HMaster 发生故障时,集群仍然可以稳定运行。但是 HMaster 还会执行一些重要的工作,例如,Region 的切片、RegionServer 的故障转移等,如果 HMaster 发生故障而没有及时处理,这些功能都会受到影响,因此 HMaster 还是要尽快恢复工作。 ZooKeeper 组件提供了这种多 HMaster 的机制,提高了 HBase 的可用性和稳健性
HRegionServer(RegionServer)
负责管理Region
- 接受客户端的读写数据请求
切分在运用过程中变大的Region
在 HDFS 中,DataNode 负责存储实际数据。RegionServer 主要负责响应用户的请求,向 HDFS 读写数据。一般在分布式集群中,RegionServer 运行在 DataNode 服务器上,实现数据的本地性每个 RegionServer 包含多个 Region,它负责的功能如下:1、处理分批给它的 Region2、处理客户端读写请求3、刷新缓存到 HDFS 中4、处理 Region 分片5、执行压缩
Region
每个HRegion由多个Store构成
- 每个Store保存一个列族(Columns Family),表有几个列族,则有几个Store
- 每个Store由一个MemStore和多个StoreFile组成,MemStore是Store在内存中的内容,写到文件后就是StoreFile。StoreFile底层是以HFile的格式保存。

若有收获,就点个赞吧
0 人点赞
