注意力机制的思考
<br />本文提出两种技巧,提升 NLP 任务中自注意力的效果,同时均有一定道理。方法只需几行代码,即插即用,几乎不增加运算量和不增加参数量,而且训练速度更快。估计修改后的 1 层相当于从前的 ~1.2 层。
改进一:不妨称为 “Time-weighting”
方法是,在计算 softmax(Q dot K) 后,对每个点做一次加权(这个很明显,估计肯定有人提出过,不过本文后面的改进二应该就是全新的了)。
Pytorch 代码如下,只增加少量参数:
self.time_weighting = nn.Parameter(torch.ones(self.n_head, config.window_len, config.window_len))
...
att = F.softmax(att, dim=-1) # 这是原始代码
att = att * self.time_weighting[:,:T,:T] # 只需增加这句
att = self.attn_drop(att) # 这是原始代码
这个改进,有两个原因。
第一,不同距离的 token,对于我们所关注位置的贡献,理应不同。
第二,对于训练时靠近开头的 token,由于观察窗口较小,信息量相对低,理应降低自注意力的整体权重。
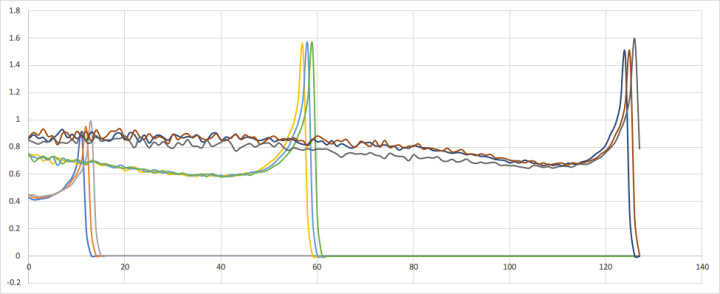
下图是典型的训练出的 time_weighting,很光滑: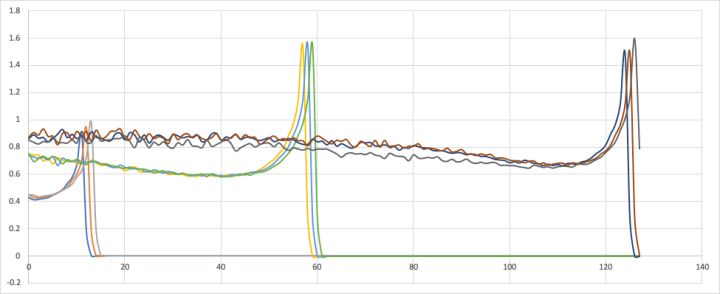
右边的凸起是 local context 效应,左边的凸起是 global context 效应。有趣的是中间略低,说明在距离20个字左右时,写作者会避免累赘重复。
进一步思考,可以精确计算出通用的加权曲线(这有人做过吗?)。留作后续研究。
改进二:不妨称为 “Time-mixing”
这个操作很特别,应该没有人提出过。它来自于我对自注意力机制的思考。
我认为,自注意力机制,其实在做三种事情:
第一,把 global context 加到每个字上。
第二,让每个字的意图逐渐统一。
第三,重复之前出现过的字组合。例如,如果最近出现了AB,我们在再遇到A时,下一个字是B的概率显然在Bayesian意义上更大了。这是一种常见的语言现象,对应语言的长程关联中的 burst 性质。
然而,如果仔细观察目前的自注意力模块的设计,会发现,它并不擅长直接完成任务三,而是只能用拐弯抹角的方法完成。这会降低学习效率,网络还可能会用过拟合的错误方式完成此任务。
通过使用这里的 “Time-mixing” 机制,可让模块直接学会任务三。
我用一个特别的 trick 解决了这个问题,代码也很简单:
self.time_shift = nn.ZeroPad2d((0,0,1,0))
......
x = torch.cat([self.time_shift(x)[:,:T,:C//2], x[:,:T,C//2:]], dim=2) # 只需增加这句
q = self.query(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # 这是原始代码
k = self.key(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # 这是原始代码
v = self.value(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # 这是原始代码
你能看出来它在干什么吗?
这不但解决了任务三,而且相当于引入了额外的 local attention 层,效果也很明显。
改进后的效果
Perplexity 曲线,训练更快,最终效果更好: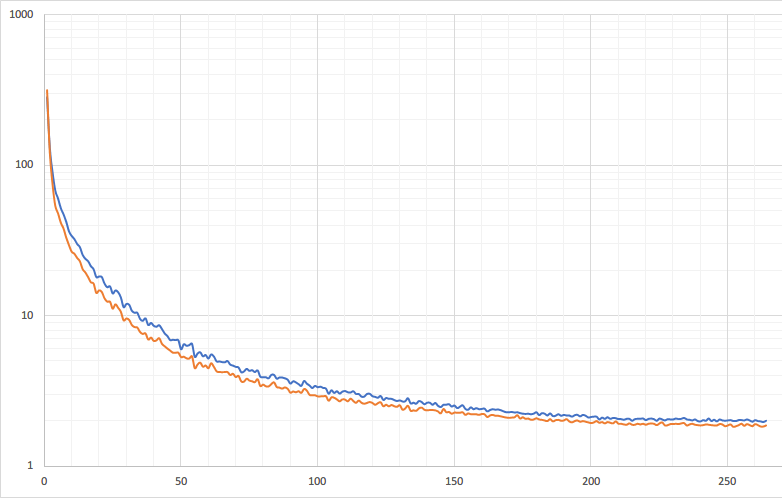
欢迎关注项目:

若有收获,就点个赞吧
0 人点赞
