一、MyBatis是什么
MyBatis 是一款优秀的半自动化持久层(和数据库交互)框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。【MyBatis中文网】
二、为什么要使用MyBatis
在学习持久层框架之前,我们也使用过很多和数据库交互的小工具:JDBC——>DBUtils(QueryRunner)——>JdbcTemplate

使用这些小工具,需要完整编写上图的步骤,才能实现与数据库的交互。这些小工具代码编写复杂,可实现的功能简单,sql语句编写在Java代码中,硬编码高耦合,维护起来很困难,而且可能需要频繁修改。
之后,我们接触过Hibernate框架,Hibernate框架是全自动全映射框架,旨在消除sql,只需要告诉Hibernate,我们的JavaBean对应的是数据库的哪一个数据源,中间编写sql到封装结果,都是黑箱操作。

Hibernate的缺点很明显,由于sql是Hibernate自己生成,所以对于长难复杂的sql,不好处理,而且我们很难对sql进行特殊优化。另外由于Hibernate是全映射框架,假设一张表中有100个字段,我们每次查询该表,返回的都是这100个字段,没有办法指定返回其中某一个字段,数据库性能下降。(可以指定,需要学习HQL)
MyBatis刚好解决了Hibernate的缺点,MyBatis没有黑箱操作,每一步都是透明的,并且把编写sql这一步提取到配置文件中,sql与Java编码分开,并且sql由开发人员自己编写。后续预编译到封装结果由MyBatis实现。更加的灵活。

三、HelloWord
先用一个HelloWord看看要使用MyBatis与数据库进行交互,需要完成哪些最基本的配置。
1. 数据准备
在数据库中创建一个Employee表,并编写相对应的Model文件
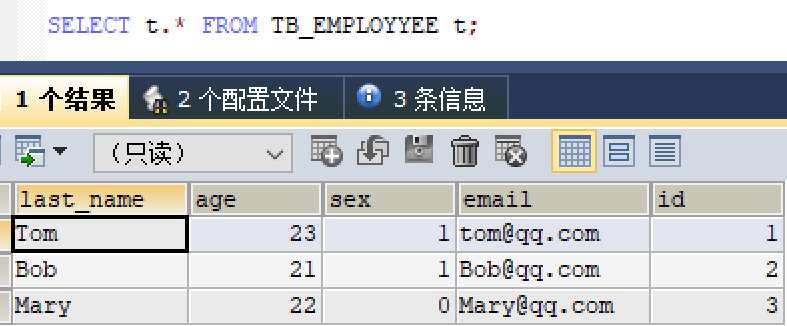
public class Employee {private Integer id;private Integer age;private String sex;private String lastName;private String email;public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public String getSex() {return sex;}public void setSex(String sex) {this.sex = sex;}public String getLastName() {return lastName;}public void setLastName(String lastName) {this.lastName = lastName;}public String getEmail() {return email;}public void setEmail(String email) {this.email = email;}@Overridepublic String toString() {return "Employee{" +"age=" + age +", sex='" + sex + '\'' +", lastName='" + lastName + '\'' +", email='" + email + '\'' +'}';}}
2. 编写全局配置文件
编写一个全局配置文件mybatis-config.xml(这个名字随意取),在文件中配置数据库连接信息。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://192.168.1.100:3306/db_mybatis"/>
<property name="username" value="root"/>
<property name="password" value="yaosy123"/>
</dataSource>
</environment>
</environments>
<!-- 写好的sql文件一定要注册到全局配置文件中-->
<mappers>
<mapper resource="employee.xml"/>
</mappers>
</configuration>
3. 编写SQL映射文件
根据业务需求,编写sql,并创建sql映射文件,这个映射文件必须到全局配置文件中注册。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ysy.learn.employee">
<!--
namespace:名称空间
id:唯一标识
resultType:查出结果的返回值类型
#{id}:从传递过来的参数中取出id值
-->
<select id="selectEmp" resultType="com.ysy.learn.model.Employee">
select id,age,sex,last_name lastName,email from TB_EMPLOYYEE where id = #{id}
</select>
</mapper>
如果表中的列名和Model类的变量名不一致,就查不到当前列的值,后面会详细讲具体的处理方法
4. 编写测试类
public class TestModel {
/**
* 每个基于 MyBatis 的应用都是以一个 SqlSessionFactory 的实例为核心的。
* SqlSessionFactory 的实例可以通过 SqlSessionFactoryBuilder 获得。而SqlSessionFactoryBuilder
* 则可以从 XML 配置文件或一个预先配置的 Configuration 实例来构建出 SqlSessionFactory实例
*/
@Test
public void getEmployeeById() throws IOException {
/**
* 1. 根据全局配置文件(mybatis-config.xml)创建一个sqlSessionFactory对象
*/
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
/**
* 2. 从sqlSessionFactory中获取一个SqlSession实例,SqlSession实例可以执行已经映射的sql语句
*/
SqlSession sqlSession = sqlSessionFactory.openSession();
try {
/**
* 我们在sql映射文件中以名称空间 "com.ysy.learn.employee" 定义了一个名为 "selectEmp"
* 的映射语句,这样我们就可以用全限定名 "com.ysy.learn.employee.selectEmp" 来调用映射的sql
*
* 3. @param statement SQL的唯一标识,Unique identifier matching the statement to use.
* @param parameter 执行SQL要用的参数,A parameter object to pass to the statement.
*/
Employee emp = sqlSession.selectOne("com.ysy.learn.employee.selectEmp", 1);
System.out.println(emp);
} finally {
sqlSession.close();
}
}
使用上述方式,我们已经可以根据com.ysy.learn.employee.selectEmp找到我们在sql映射文件中配置的sql,并且通过sql在数据库中查出数据。但是这种直接传字符串字面值得方式很容易出错,并且参数类型可以随意传,容易引起类型错误。所以MyBatis提供了接口式编程的方式来完成sql映射,并进行数据库操作这一过程。
接口式编程
首先定义一个查询Employee的接口,并根据业务需求定义好增删改查各种方法。
public interface EmployeeDao {
public Employee queryEmployeeById(Integer id);
}
之后在sql映射文件中配置映射关系,将名称空间映射到我们的Dao接口,id映射到我们接口的方法名
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ysy.learn.dao.EmployeeDao">
<!--
namespace:名称空间,接口全类名
id:唯一标识,接口方法
resultType:查出结果的返回值类型
#{id}:从传递过来的参数中取出id值
-->
<select id="queryEmployeeById" resultType="com.ysy.learn.model.Employee">
select id,age,sex,last_name lastName,email from TB_EMPLOYYEE where id = #{id}
</select>
</mapper>
然后通过接口方法进行数据库操作。这种方式,代码看起来更加简洁,并且接口定义了参数类型和返回值类型,更加类型安全,还不用担心可能出错的字符串字面值以及强制类型转换。
public void getEmployee() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
/**
* 2. 从sqlSessionFactory中获取一个SqlSession实例,SqlSession实例可以执行已经映射的sql语句
*/
SqlSession sqlSession = sqlSessionFactory.openSession();
try {
EmployeeDao empDao = sqlSession.getMapper(EmployeeDao.class);
Employee emp = empDao.queryEmployeeById(1);
System.out.println(emp);
} finally {
sqlSession.close();
}
}
四、MyBatis配置文件
1. 全局配置文件
MyBatis的全局配置文件是对MyBatis核心行为的控制,这个配置文件的名称是可以随意命名的。配置文件包含以下标签,这些标签在配置的时候,必须严格按照这个顺序进行设置(比如settings不能放在properties之前,mappers不能放在environments之前,标签可以没有,但是顺序不能换,否则就会报错)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
// properties标签可以用来进行属性配置
<properties resource="dbconfig.properties" url=""></properties>
<settings>
<setting name="" value="" />
</settings>
<typeAliases>
<typeAlias type="" alias=""></typeAlias>
<package name="" />
</typeAliases>
<typeHandlers>
<typeHandler handler="" javaType="" jdbcType=""></typeHandler>
<package name="" />
</typeHandlers>
<objectFactory type="">
<property name="" value="" />
</objectFactory>
<plugins>
<plugin interceptor=""></plugin>
</plugins>
<environments default="">
<environment id="">
<transactionManager type=""></transactionManager>
<dataSource type=""></dataSource>
</environment>
</environments>
<databaseIdProvider type="">
<property name="" value=""/>
</databaseIdProvider>
<!--
用class的时候要注意:
1. 必须有sql映射文件,映射文件名必须与接口同名,并且必须与接口放在同一个目录下
2. 没有sql映射文件,所有sql都是写在注解上面,不需要sql映射文件,直接注册class就行
重要复杂的Dao接口用映射文件的方式
不重要简单的Dao接口可以用注解方式
用package批量注册的时候,sql映射文件也必须与接口在同一个包下,
如果觉得把xml和java文件放在一起看起来复杂,可以在resource文件夹下建一个和Dao接口相同的包,
然后把配置文件放在resource文件夹下,这样在视觉上看起来是分开的
-->
<mappers>
<mapper resource="" url="" class=""></mapper>
<package name=""/>
</mappers>
</configuration>
具体每个标签的作用看官网吧,官网讲的非常清楚。【MyBatis官网】
2. SQL映射文件
官网理解不清楚的部分在下面进行补充,其他部分看官网:【MyBatis官网】
2.1 参数处理
假设我们有一张table表,需要通过id查询表中数据:select * from table where id = #{id} ,这种只传一个参数的查询,MyBatis不会对参数做特殊处理,可以通过id取到参数的值,然后查到符合条件的数据。
但是如果我们传多个参数,按照一个参数的逻辑,我们的sql应该是这样的:select * from table where id = #{id} and last_name = #{lastName} ,但是执行这个sql之后,我们发现会报如下异常:

这是因为如果传多个参数,MyBatis会把传入的多个参数封装成一个Map,Map的key用param1………paramN来定义,所以如果想要取到参数值,需要将上述sql修改成:select * from table where id = #{param1} and last_name = #{param2}但是这种参数命名的方式在我们编码的时候不够明确,造成理解困难,所以MyBatis提供了一个@Param注解,来指定MyBatis封装参数时Map的key取什么值,这样我们就可以直接以#{id},#{lastName}的方式来取参数值
public interface EmployeeDao {
public Employee getEmployeeByIdAndName(@Param("id") Integer id, @Param("lastName") String name);
}
但是如果参数非常多,直接在方法中定义一长串的参数,代码看起来不够简洁,我们也可以通过以下方式来进行传参:
a> 如果多个参数正好是业务逻辑的数据模型,我们可以直接传入pojo
/**
* Employee e = new Employee();
* e.setId(2);
* e.setLastName("Bob");
* Employee employee = empDao.getEmployee(e);
*/
public interface EmployeeDao {
public Employee getEmployee(Employee e);
}
在sql映射文件中,直接用#{属性名}就可以取出传入的pojo的参数值
<select id="getEmployee" resultType="com.ysy.learn.model.Employee">
select id,age,sex,last_name lastName,email from TB_EMPLOYYEE where id = #{id}
and last_name = #{lastName}
</select>
b> 如果多个参数不是业务逻辑的数据模型,没有对应的pojo,并且参数不经常使用,我们可以定义一个Map
/**
* Map<String,Object> map = new HashMap<>();
* map.put("id",2);
* map.put("lastName","Bob");
* Employee employee = empDao.getEmployeeByMap(map);
*/
public interface EmployeeDao {
public Employee getEmployeeByMap(Map<String,Object> map);
}
在sql映射文件中,直接用#{key}就可以取出传入的Map的参数值
<select id="getEmployeeByMap" resultType="com.ysy.learn.model.Employee">
select id,age,sex,last_name lastName,email from TB_EMPLOYYEE where id = #{id}
and last_name = #{lastName}
</select>
c> 如果多个参数不是业务逻辑的数据模型,没有对应的pojo,而且经常用这些参数查询,我们可以定义一个数据传输对象
// 比如说分页查询时,我们没有专门的业务逻辑Page类型,就可以定义一个Page类型,用来做数据传输对象
public class Page{
private int size;
private int count;
}
public interface PageDao {
public Page getPage(Page p);
}
通过以下几个参数的取值,来加深理解上述提到的几种参数取值方式:
// id ===> #{id} / #{param1}
// lastName ===> #{param2}
1. public Employee getEmployeeByIdAndName(@Param("id") Integer id, String lastName);
// id ===> #{param1}
// lastName ===> #{param2.lastName} / #{e.lastName}
2. public Employee getEmployee(Integer id, @Param("e") Employee e);
特别注意:参数传集合或者数组
3. public Employee getEmployeeByList(List<Integer> ids);
如果参数传的是一个list集合,想要取出第一个id,通过#{ids[0]} 或者#{param1[0]}是取不到参数值的,因为如果是Collection(List、Set)类型或者是数组,MyBatis会把传入的list或者数组封装到Map中,而且Map的key不再是param1,而是collection。所以如果传入的参数是Set类型,在sql映射文件中,可以用#{collection[0]}取出传入参数值;如果传入的参数是List类型,在sql映射文件中,可以用#{collection[0]}或者#{list[0]}取出传入参数值;如果传入的参数是Array类型,在sql映射文件中,可以用#{array[0]}取出传入参数值
<select id="getEmployeeByList" resultType="com.ysy.learn.model.Employee">
select id,age,sex,last_name lastName,email from TB_EMPLOYYEE where id = #{list[0]}
</select>
2.1.1 参数处理#{}与${}取值的区别
#{}:可以获取map和pojo对象属性的值,以预编译的形式,将参数设置到sql语句中
SELECT * FROM TABLE WHERE id = #{id}
执行sql之后语句是这样的:
SELECT * FROM TABLE WHERE id = ?
${}:可以获取map和pojo对象属性的值,取出的值直接拼装在sql语句中,会有安全问题
SELECT * FROM TABLE WHERE id = ${id}
执行sql之后语句是这样的:
SELECT * FROM TABLE WHERE id = 2
大多数情况下,都应该使用#{},原生jdbc不支持占位符的地方可以使用${}进行取值
2.2 select
2.2.1 resultType
a> 返回List
如果需要返回一个List,只需要在查询方法定义的时候,将返回值定义为List,sql映射文件中resultType为我们要返回的对象类型,MyBatis就会自动为我们封装
<!-- public List<Employee> getEmployeesBySex(String sex);-->
<select id="getEmployeesBySex" resultType="com.ysy.learn.model.Employee">
SELECT * FROM TB_EMPLOYYEE WHERE SEX = #{sex}
</select>
b> 返回Map
如果要返回一个Key为指定的列,Value为查询对象的Map,将sql映射文件中resultType定义为我们要返回的对象类型,在查询方法上使用@MapKey注解来指定哪一列数据作为Map的Key
@MapKey("id")
public Map<Integer,Employee> getEmployeesForMap(String sex);
<!-- public Map<Integer,Employee> getEmployeesForMap(String sex);-->
<select id="getEmployeesForMap" resultType="com.ysy.learn.model.Employee" >
SELECT * FROM TB_EMPLOYYEE WHERE SEX = #{sex}
</select>
2.2.3 resultMap
之前说过,在查询的时候,如果JavaBean的属性名和数据库的列名不一致,就查不到数据。比如:JavaBean的属性名是lastName,数据库的列名是LAST_NAME,如果没有特殊处理,就查不到lastName的值。可以通过下面的方式解决这个问题:
在查询的时候给数据库的列起别名,只要别名和JavaBean的属性名一致,就可以查到数据
select id,last_name lastName from table where id = #{id}如果数据库的列名和JavaBean的属性名符合驼峰命名法,可以开启MyBatis的设置项:mapUnderscoreToCamelCase,是否开启驼峰命名自动映射,即从经典数据库列名 A_COLUMN 映射到经典 Java 属性名 aColumn,默认取值是false
<settings> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings>自定义resultMap,resultMap可以自定义结果集映射规则,但是resultMap和resultType只能使用其中一个 ```xml
使用association指定联合的JavaBean对象:xml
— public Employee getEmpAndDept(Integer id);
使用association进行分步查询:员工表和部门表通过部门ID关联,我们可以先根据员工ID查员工表,然后根据员工表中记录的部门ID查部门表。xml
— public Department getDepartmentById(Integer id);
— public Employee getEmpAndDeptStep(Integer id);既然级联属性也可以很方便的实现功能,为什么我们还要使用分步查询呢?
因为通过分步查询,我们可以组合已有的方法进行查询,不用写新的sql,另外分步查询可以使用延迟加载。
什么叫延迟加载?
级联属性中,我们每次查询,都要查EMPLOYYEE和DEPARTMENT两张表,使用延迟加载后,我们可以先查员工表,在我们需要使用部门信息的时候,再去查部门表。开启延时加载,只需要在全局配置文件中进行配置就可:xml
collection的分步查询:xml
不论是封装单个对象的association,还是封装集合对象的collection,在使用时都要用column来指定将上一步查出的哪一列的值传递给当前的方法,如果要传递多个值,可以将多列的值封装成Map:column={key1=column1,key2=column2}
在association和collection中还有一个属性:fetchType,fetchType有两个值:lazy表示立即执行;eager表示延迟加载,就算在全局配置文件中配置了延迟加载,也可以使用这个属性进行更改
<a name="en1aV"></a>
# 五、动态SQL
具体看官网吧,官网讲的非常清楚。[【MyBatis官网】](https://mybatis.net.cn/configuration.html)
<a name="jrfBj"></a>
# 六、缓存
MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。缓存可以极大的提升查询效率。MyBatis中默认两级缓存:
<a name="teRTk"></a>
## 1. 一级缓存
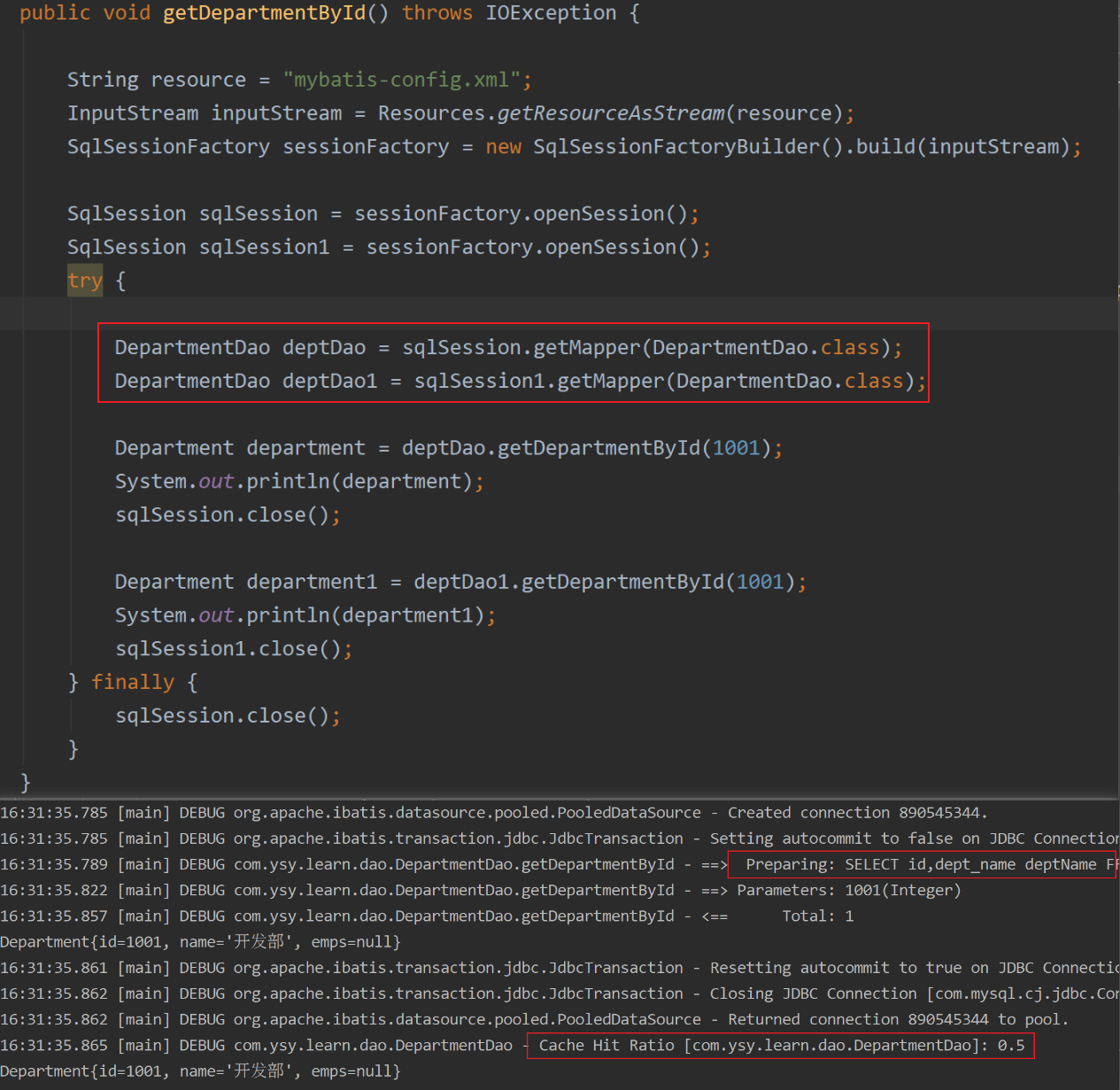
**一级缓存(本地缓存):**sqlSession级别的缓存,一级缓存是一直开启的;同一次会话期间查询到的数据会放在本地缓存中,以后如果需要获取相同数据,直接从缓存中取,没必要再查询数据库。
如下图,同一个sqlSession,两次查询id为1001的数据,只发送了一次SQL,因为第二次是从缓存中取的。

什么情况下一级缓存会失效呢?
1. sqlSession不同:两个不同的sqlSession,虽然查询的是同一条数据,但是由于缓存是sqlSession级别,当sqlSession不同,缓存就会失效,所以还是会发送两次sql。

2. sqlSession相同,两次查询条件不同:虽然是同一个sqlSession,但是两次查询的条件不同,就算两个条件查询的是同一条数据,也会发送两次sql,进行两次查询。

3. sqlSession相同,两次查询之间执行了增删改操作:因为这次增删改可能对当前查询的数据有影响,所以两次查询之间如果执行了增删改,那么一级缓存也会失效

4. sqlSession相同,手动清除了一级缓存

<a name="TXVFO"></a>
## 2. 二级缓存
**二级缓存(全局缓存):**基于namespace级别的缓存;一个namespace对应一个二级缓存,不同的namespace查出的数据会放在自己对应的缓存中。二级缓存默认是没有开启的,所以正常情况下,一个会话查询了一条数据,这个数据会被放在当前会话的一级缓存中。如果开启了二级缓存,当会话关闭或者提交的时候,一级缓存中的数据会被保存到二级缓存中,新的会话信息,就可以参照二级缓存。
那么要如何开启二级缓存呢?
首先在全局配置文件中,开启二级缓存的配置,之后在sql映射文件中配置<cache></cache>标签。<cache></cache>几个默认策略的具体解析看官网,另外我们的POJO**必须实现序列化接口**
```xml
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
eviction:缓存的回收策略
flushInterval:缓存刷新间隔;缓存多长时间清空一次,默认不清空,设置毫秒值
readOnly:true:只读,mybatis认为所有从缓存中获取数据的操作都是只读操作,不会修改数据
mybatis为了加快获取速度,会将数据在缓存中的引用交给用户,不安全,速度快
false:非只读,mybatis认为从缓存中获取的数据可能会被修改
mybatis会利用序列化&反序列化的技术克隆一份数据交给用户,所以非只读的话我们的model对象都需要实现序列化接口
size:缓存中存放多少元素
type:指定自定义缓存的全类名
-->
<mapper namespace="com.ysy.learn.dao.DepartmentDao">
<cache blocking="" eviction="" flushInterval="" readOnly="" size="" type=""></cache>
</mapper>
开了二级缓存后,就算是两个不同的sqlSession,也只会进行查询一次,第二次的数据是从二级缓存中取的。另外查出的数据都默认先放入一级缓存,只有会话关闭或者提交,数据才会转移到二级缓存。
3. 和缓存相关的设置/属性
cacheEnabled:true:开启二级缓存;false:关闭二级缓存,一级缓存依然可以用
<setting name="cacheEnabled" value="true"/>
useCache:每个标签中,flushCache默认值为false,如果让flushCache=true,每次查询之后都会清空缓存,意味着缓存没有被使用
<select id="getDeptAndEmpById" flushCache="false">
sqlSession.clearCache():只是清除当前session的一级缓存
4. 第三方缓存整合
- 导入第三方缓存包
- 导入第三方缓存的适配包
- 在mapper.xml中使用自定义缓存

若有收获,就点个赞吧
0 人点赞
