1. pandas数据结构
1.1 创建
SeriesSeries是类似于一维数组的数据结构import pandas as pd
pd.Series(data=None, index=None, dtype=None)
- `data`:传入的数据,可以是`ndarray`、`**list**`等- `index`:索引,**必须是唯一的**,且与数据的长度相等。如果没有传入索引参数,则默认会自动**创建一个从`0-n`的整数索引**。- `dtype`:数据的类型
- 示例
注:data也可以传入字典数据,此时字典的key为索引
DataFrameSeries
index:返回Series的索引values:返回Series的值,一个array类型数组。(也可以直接用数组的索引来获取数据)pd.DataFrame(data=None, index=None, columns=None)index:行标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。columns:列标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
DataFrame
data.index = stu
> # 必须整体全部修改,不能单独修改一个索引的值
<a name="V0B9s"></a>
## 2.2 重设索引
- `reset_index(drop=False)`
- 设置新的下标索引
- `drop`:默认为`False`,**不删除原来索引**,在索引左边添加一列新的索引,之前的索引变成数据,数据的列索引名叫做`index`。如果为`True`,删除原来的索引值
<a name="YFFzQ"></a>
## 2.3 以某列值设置为新的索引
- `set_index(keys, drop=True)`
- `**keys**`` `: 列索引名称或者列索引名称的列表
- `**drop**`` `: boolean, `default True`.当做新的索引,删除原来的列
- 示例
```python
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
# month year sale
# 0 1 2012 55
# 1 4 2014 40
# 2 7 2013 84
# 3 10 2014 31
df.set_index(keys='year') # dropout都默认为True
# month sale
#year
#2012 1 55
#2014 4 40
#2013 7 84
#2014 10 31
df.set_index(keys=['year','sale']) # 索引名称列表
# month
#year sale
#2012 55 1
#2014 40 4
#2013 84 7
#2014 31 10
3. 筛选查询
3.1 根据索引来查询
DataFrame.reindex(index=None,columns=None)
可以根据传入的索引列表或表头列表来筛选对应的数据,如果index或columns里存在原先DataFrame里没有的索引或表头,则会自动生成一条数据,值为NaN,不会报错
data
股票代码 当前价 涨跌额 涨跌幅
股票名称
N晶科 SH601778 6.29 +1.92 +43.94%
吉贝尔 SH688566 52.66 +6.96 +15.23%
华特气体 SH688268 88.80 +11.72 +15.20%
实达集团 SH600734 2.60 +0.24 +10.17%
凌云B股 SH900957 0.36 +0.033 +10.09%
data.reindex(index=['N晶科','实达集团','没有'])
股票代码 当前价 涨跌额 涨跌幅
股票名称
N晶科 SH601778 6.29 +1.92 +43.94%
实达集团 SH600734 2.60 +0.24 +10.17%
没有 NaN NaN NaN NaN
data.reindex(index=['N晶科','实达集团'],columns=['当前价','股票代码'])
当前价 股票代码
股票名称
N晶科 6.29 SH601778
实达集团 2.60 SH600734
3.2 根据条件来筛选
data
股票代码 当前价 涨跌额 涨跌幅
股票名称
N晶科 SH601778 6.29 +1.92 +43.94%
吉贝尔 SH688566 52.66 +6.96 +15.23%
华特气体 SH688268 88.80 +11.72 +15.20%
实达集团 SH600734 2.60 +0.24 +10.17%
凌云B股 SH900957 0.36 +0.033 +10.09%
data[data['当前价']>10]
股票代码 当前价 涨跌额 涨跌幅
股票名称
吉贝尔 SH688566 52.66 +6.96 +15.23%
华特气体 SH688268 88.80 +11.72 +15.20%
4. 对表里的字符串数据进行操作
Series.str.****可以对每一个字符串数据进行操作,****可以是任何字符串可以使用的函数
示例
data
股票代码 当前价 涨跌额 涨跌幅
股票名称
N晶科 SH601778 6.29 +1.92 +43.94%
吉贝尔 SH688566 52.66 +6.96 +15.23%
华特气体 SH688268 88.80 +11.72 +15.20%
实达集团 SH600734 2.60 +0.24 +10.17%
凌云B股 SH900957 0.36 +0.033 +10.09%
data['涨跌幅'].str.strip('%').astype('float')
0 43.94
1 15.23
2 15.20
3 10.17
4 10.09
Name: 涨跌幅, dtype: float64
4.1 查询字符串中是否包含某些字符串
Series.str.contains('')
data
股票代码 当前价 涨跌额 涨跌幅
股票名称
N晶科 SH601778 6.29 +1.92 +43.94%
吉贝尔 SH688566 52.66 +6.96 +15.23%
华特气体 SH688268 88.80 +11.72 +15.20%
实达集团 SH600734 2.60 +0.24 +10.17%
凌云B股 SH900957 0.36 +0.033 +10.09%
data[data['股票代码'].str.contains('60')
股票代码 当前价 涨跌额 涨跌幅
股票名称
N晶科 SH601778 6.29 +1.92 +43.94%
实达集团 SH600734 2.60 +0.24 +10.17%
5. 排序
5.1 sort_values
df.sort_values(by=,ascending=)
by参数可以指定根据哪一列数据进行排序,(选择多列或者多行排序要加[ ],把选择的行列转换为列表,排序方式也可以同样的操作)ascending是设置升序和降序。选择多列或者多行排序要加[ ]。True指升序
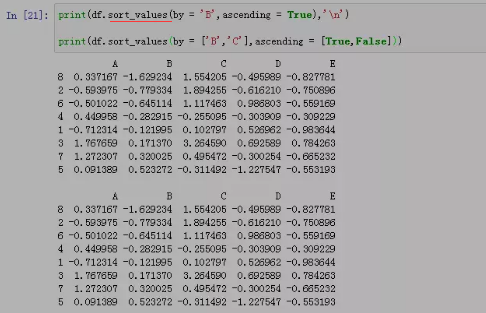
5.2 sort_index
6. loc
7. DataFrame运算
7.1 算数运算
series.add(number)
对某列数据进行加number运算
series.sub(number)
对某列数据进行减number运算
注意:是返回新的一个series,而不是在原数据上修改
7.2 逻辑运算
data[data["open"] > 23]data[(data["open"]>23)&(data["open"]<24)]
括号里的运算会返回一个对应行为bool值的series,然后data[series],会根据True,False返回对应数据
data.query("open<24 & open>23")
与之前的类似,只不过这里可以直接写行索引名字
data[data["open"].isin([23.23, 23.71])]
7.1 decribe
# 计算平均值、标准差、最大值、最小值 data.describe()open high close low volume price_change p_change turnover count 643.000000 643.000000 643.000000 643.000000 643.000000 643.000000 643.000000 643.000000 mean 21.272706 21.900513 21.336267 20.771835 99905.519114 0.018802 0.190280 2.936190 std 3.930973 4.077578 3.942806 3.791968 73879.119354 0.898476 4.079698 2.079375 min 12.250000 12.670000 12.360000 12.200000 1158.120000 -3.520000 -10.030000 0.040000 25% 19.000000 19.500000 19.045000 18.525000 48533.210000 -0.390000 -1.850000 1.360000 50% 21.440000 21.970000 21.450000 20.980000 83175.930000 0.050000 0.260000 2.500000 75% 23.400000 24.065000 23.415000 22.850000 127580.055000 0.455000 2.305000 3.915000 max 34.990000 36.350000 35.210000 34.010000 501915.410000 3.030000 10.030000 12.5600007.2 统计函数
常用的统计函数:min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差),mode(众数)结果:
count |
Number of non-NA observations |
|---|---|
sum |
Sum of values |
mean |
Mean of values |
median |
Arithmetic median of values |
min |
Minimum |
max |
Maximum |
mode |
Mode |
abs |
Absolute Value |
prod |
Product of values |
std |
Bessel-corrected sample standard deviation |
var |
Unbiased variance |
idxmax |
compute the index labels with the maximum |
idxmin |
compute the index labels with the minimum |
对于单个函数去进行统计的时候,坐标轴还是按照默认列“columns” (axis=0, default),如果要对行“index” 需要指定(axis=1)
7.3 累计统计函数
| 函数 | 作用 |
|---|---|
cumsum |
计算前1/2/3/…/n个数的和 |
cummax |
计算前1/2/3/…/n个数的最大值 |
cummin |
计算前1/2/3/…/n个数的最小值 |
cumprod |
计算前1/2/3/…/n个数的积 |
所谓累计运算即,分别求前1个数的和,前两个数的和。。。。
2015-03-02 2.62
2015-03-03 4.06
2015-03-04 5.63
2015-03-05 7.65
2015-03-06 16.16
...
2018-02-14 112.59
2018-02-22 114.23
2018-02-23 116.65
2018-02-26 119.67
2018-02-27 122.35
比如这里,分别求03-02之前的所有值的和,03-03之前的所有值的和。。。
7.4 自定义函数
- apply(func, axis=0)
- func:自定义函数
- axis=0:默认是列,axis=1为行进行运算
定义一个对列,最大值-最小值的函数
data[['open', 'close']].apply(lambda x: x.max() - x.min(), axis=0) open 22.74 close 22.85 dtype: float648. 日期处理
8.1 to_datetime
用法
pandas.to_datetime(arg,errors = 'raise',format = None,unit = 'ns)
- 参数解析
arg:int, float, str, datetime, list, tuple, 1-d array, Series, DataFrame/dict-like
需要转换的时间对象
errors:- If ‘
raise’, then invalid parsing will raise an exception. - If ‘
coerce’, then invalid parsing will be set as NaT. - If ‘
ignore’, then invalid parsing will return the input.
- If ‘
format解析时间的strftime,例如“%d /%m /%Y”,请注意,“%f”将一直解析直至纳秒。有关选择的更多信息,请参见strftime文档:https : //docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior。unit:``arg的单位(D,s,ms,us,ns)。表示传入的时间戳的单位是什么。8.2 DatetimeIndex
是一个日期对象,可以方便的对日期进行处理
- 创建
DatetimeIndex=pd.DatetimeIndex(time):time可以是数据类型为datetime的series
- 将时间拆分成各个部分
DatetimeIndex.dayDatetimeIndex.weekdayDatetimeIndex.hour<br />

若有收获,就点个赞吧
0 人点赞
