ConcurrentLinkedQueue 是线程安全的无界非阻塞队列,其底层数据结构使用单向链表实现,对于入队和出队操作使用 CAS 来实现线程安全。下面我们来看具体实现。
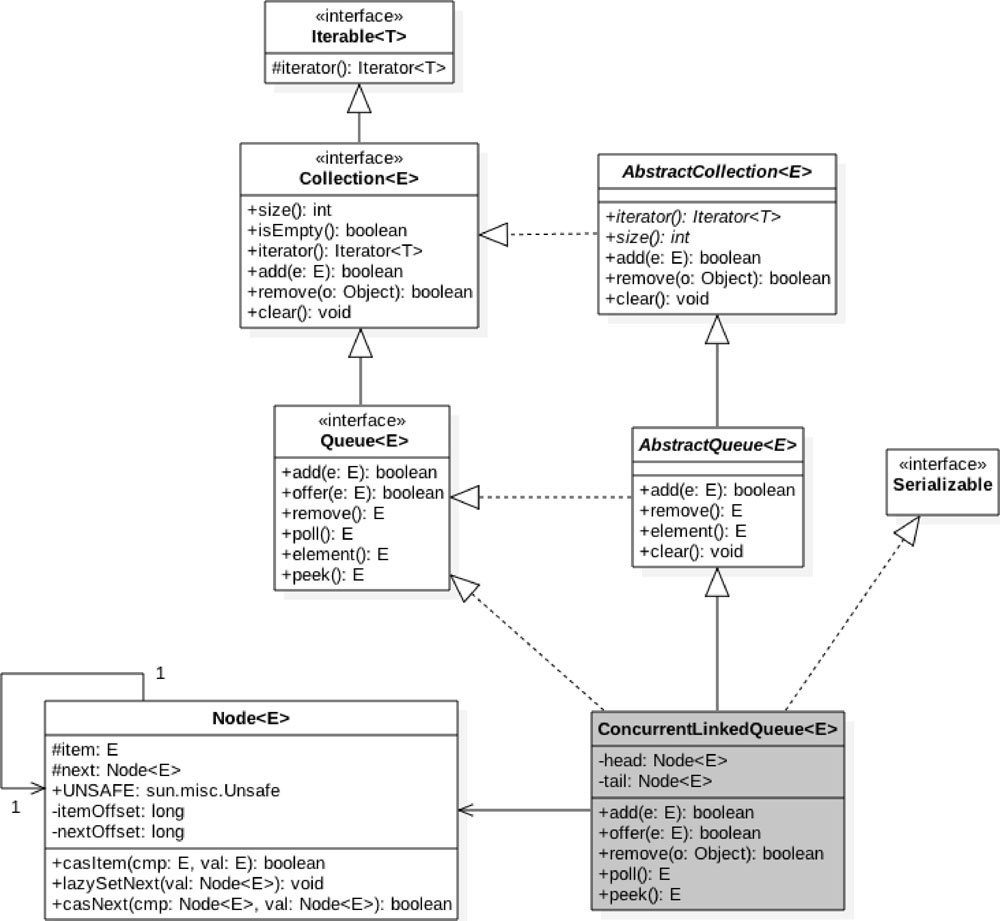
类图结构
为了能从全局直观地了解 ConcurrentLinkedQueue 的内部构造,先简单介绍 ConcurrentLinkedQueue 的类图结构,如图 7-1 所示。
ConcurrentLinkedQueue 内部的队列使用单向链表方式实现,其中有两个 volatile 类型的 Node 节点分别用来存放队列的首、尾节点。从下面的无参构造函数可知,默认头、尾节点都是指向 item 为 null 的哨兵节点。新元素会被插入队列末尾,出队时从队列头部获取一个元素。
public ConcurrentLinkedQueue() {head = tail = new Node<E>(null);}
在 Node 节点内部则维护一个使用 volatile 修饰的变量 item,用来存放节点的值;next 用来存放链表的下一个节点,从而链接为一个单向无界链表。其内部则使用 UNSafe 工具类提供的 CAS 算法来保证出入队时操作链表的原子性。
ConcurrentLinkedQueue 原理介绍
本节介绍 ConcurrentLinkedQueue 的几个主要方法的实现原理。
1.offer 操作
offer 操作是在队列末尾添加一个元素,如果传递的参数是 null 则抛出 NPE 异常,否则由于 ConcurrentLinkedQueue 是无界队列,该方法一直会返回 true。另外,由于使用 CAS 无阻塞算法,因此该方法不会阻塞挂起调用线程。下面具体看下实现原理。
public boolean offer(E e) {//(1)e 为 null 则抛出空指针异常checkNotNull(e);//(2)构造 Node 节点,在构造函数内部调用 unsafe.putObjectfinal Node<E> newNode = new Node<E>(e);//(3)从尾节点进行插入for (Node<E> t = tail, p = t; ; ) {Node<E> q = p.next;//(4)如果 q==null 说明 p 是尾节点,则执行插入if (q == null) {//(5)使用 CAS 设置 p 节点的 next 节点if (p.casNext(null, newNode)) {//(6)CAS 成功,则说明新增节点已经被放入链表,然后设置当前尾节点(包含 head,第//1,3,5...个节点为尾节点)if (p ! = t)casTail(t, newNode); // Failure is OK.return true;}}else if (p == q)//(7)//多线程操作时,由于 poll 操作移除元素后可能会把 head 变为自引用,也就是 head 的 next 变//成了 head,所以这里需要//重新找新的 headp = (t ! = (t = tail)) ? t : head;else//(8)寻找尾节点p = (p ! = t && t ! = (t = tail)) ? t : q;}}
下面结合图来讲解该方法的执行流程。
(1)首先看当一个线程调用 offer(item)时的情况。首先代码(1)对传参进行空检查,如果为 null 则抛出 NPE 异常,否则执行代码(2)并使用 item 作为构造函数参数创建一个新的节点,然后代码(3)从队列尾部节点开始循环,打算从队列尾部添加元素,当执行到代码(4)时队列状态如图 7-2 所示。
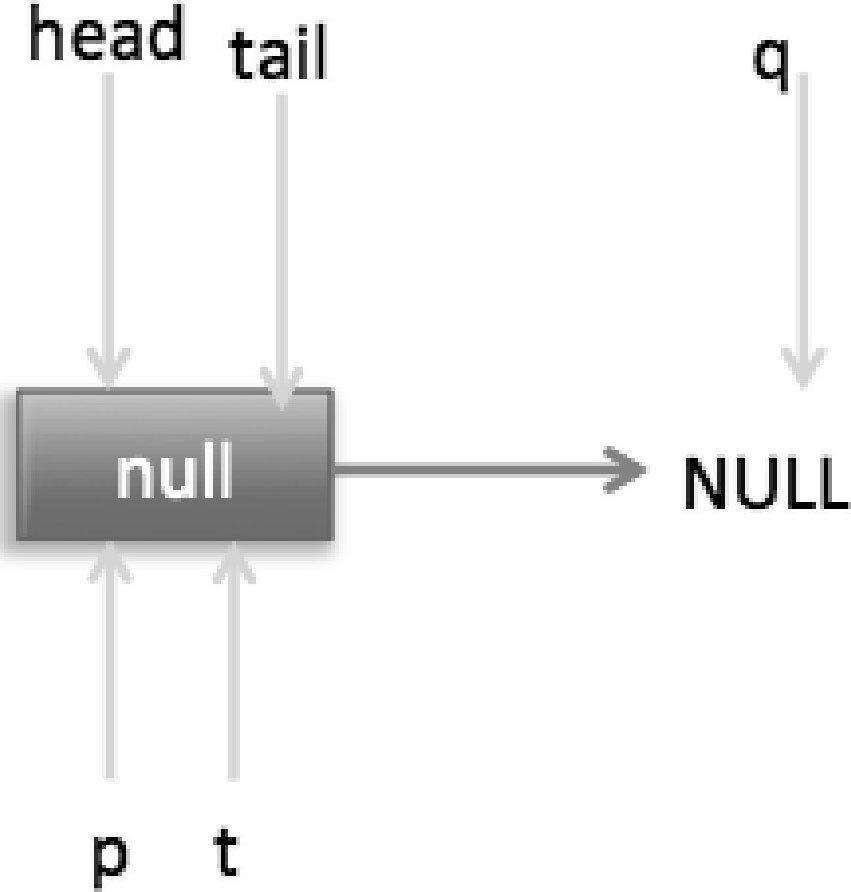
这时候节点 p、t、head、tail 同时指向了 item 为 null 的哨兵节点,由于哨兵节点的 next 节点为 null,所以这里 q 也指向 null。代码(4)发现 q==null 则执行代码(5),通过 CAS 原子操作判断 p 节点的 next 节点是否为 null,如果为 null 则使用节点 newNode 替换 p 的 next 节点,然后执行代码(6),这里由于 p==t 所以没有设置尾部节点,然后退出 offer 方法,这时候队列的状态如图 7-3 所示。
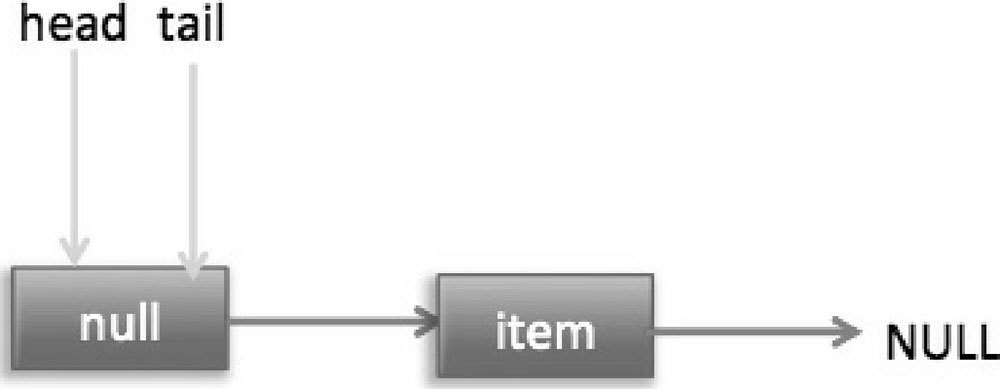
(2)上面是一个线程调用 offer 方法的情况,如果多个线程同时调用,就会存在多个线程同时执行到代码(5)的情况。假设线程 A 调用 offer(item1),线程 B 调用 offer(item2),同时执行到代码(5)p.casNext(null, newNode)。由于 CAS 的比较设置操作是原子性的,所以这里假设线程 A 先执行了比较设置操作,发现当前 p 的 next 节点确实是 null,则会原子性地更新 next 节点为 item1,这时候线程 B 也会判断 p 的 next 节点是否为 null,结果发现不是 null(因为线程 A 已经设置了 p 的 next 节点为 item1),则会跳到代码(3),然后执行到代码(4),这时候的队列分布如图 7-4 所示。
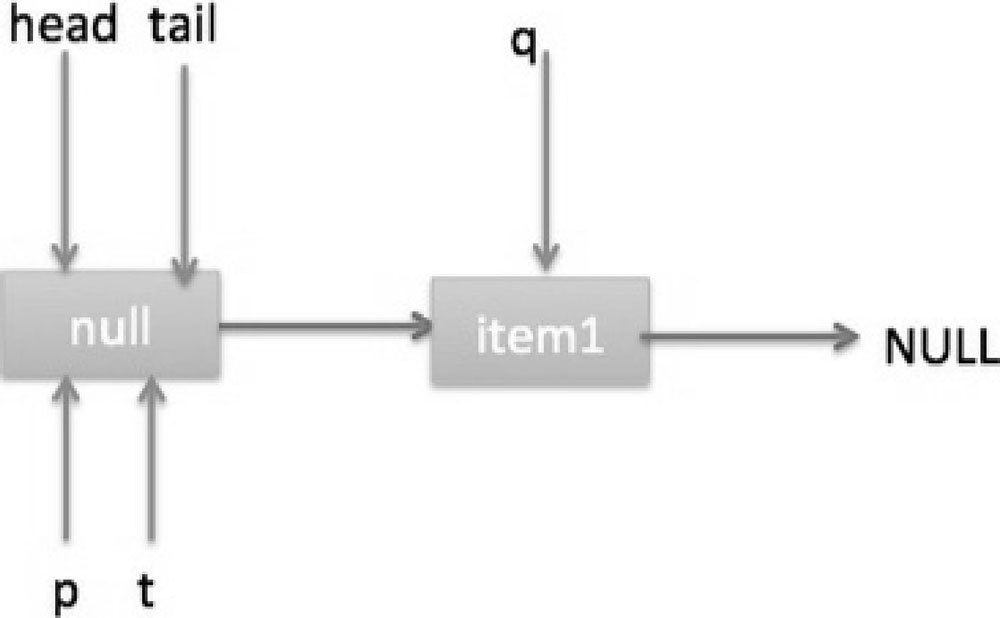
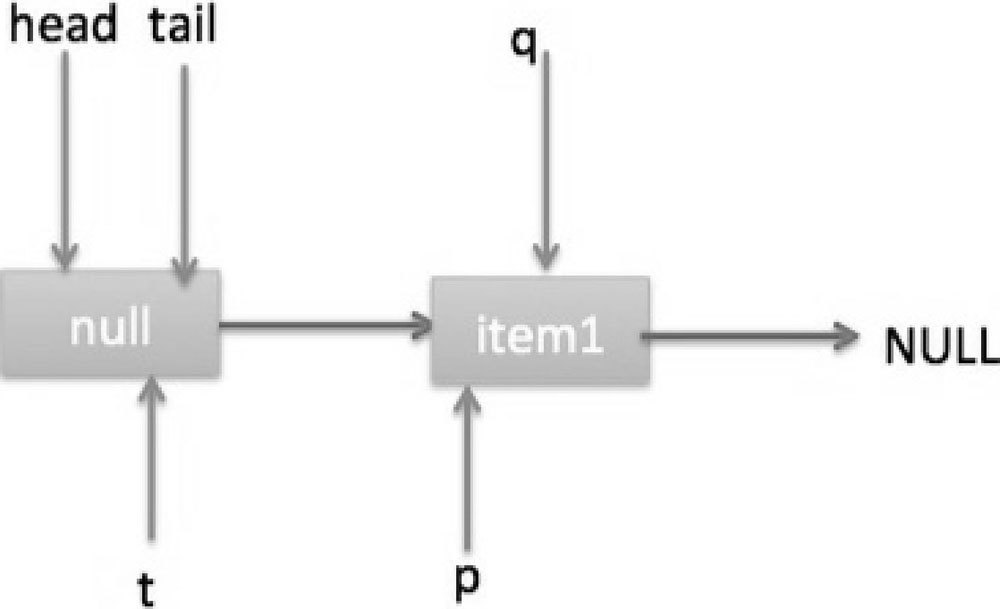
根据上面的状态图可知线程 B 接下来会执行代码(8),然后把 q 赋给了 p,这时候队列状态如图 7-5 所示。
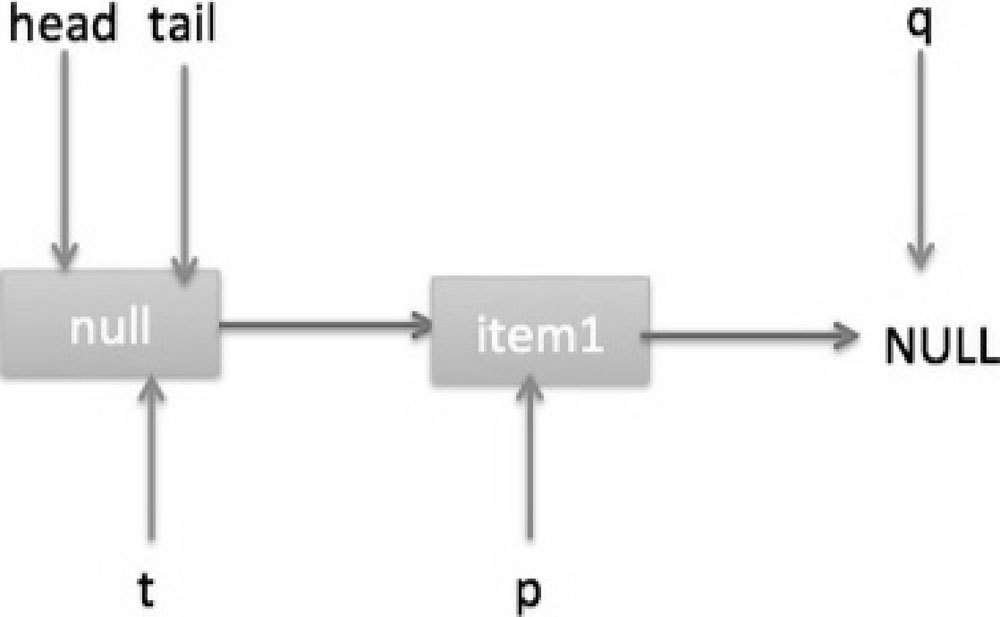
然后线程 B 再次跳转到代码(3)执行,当执行到代码(4)时队列状态如图 7-6 所示。
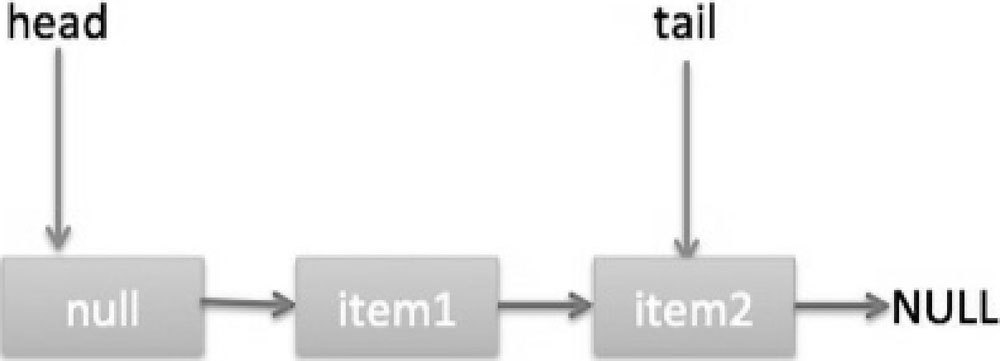
由于这时候 q==null,所以线程 B 会执行代码(5),通过 CAS 操作判断当前 p 的 next 节点是否是 null,不是则再次循环尝试,是则使用 item2 替换。假设 CAS 成功了,那么执行代码(6),由于 p!=t,所以设置 tail 节点为 item2,然后退出 offer 方法。这时候队列分布如图 7-7 所示。
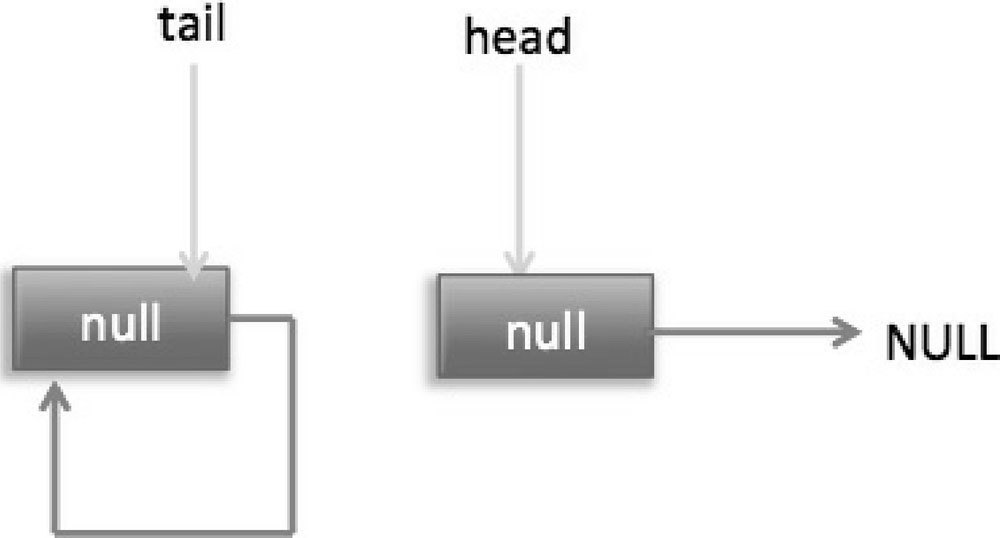
分析到现在,就差代码(7)还没走过,其实这一步要在执行 poll 操作后才会执行。这里先来看一下执行 poll 操作后可能会存在的一种情况,如图 7-8 所示。
下面分析当队列处于这种状态时调用 offer 添加元素,执行到代码(4)时的状态图(见图 7-9)。
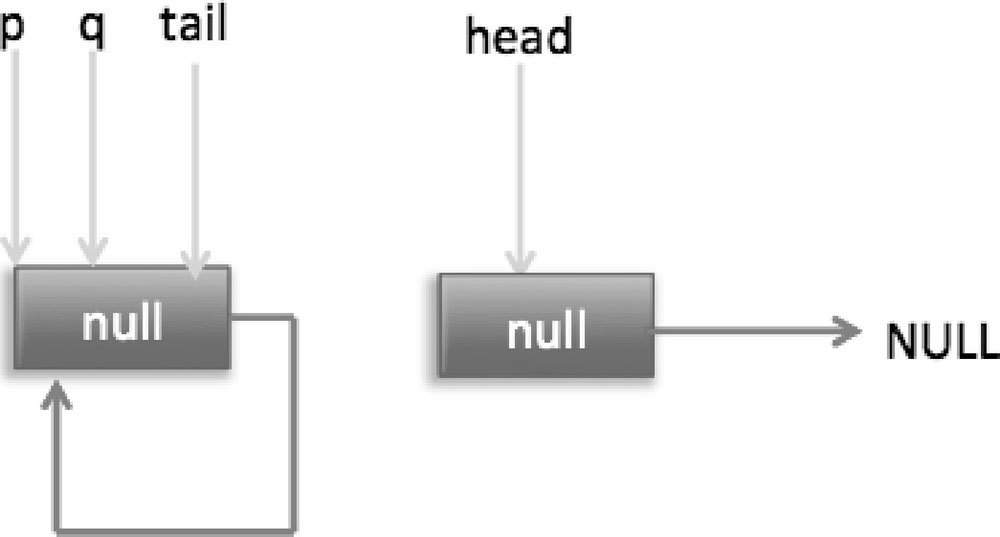
这里由于 q 节点不为空并且 p==q 所以执行代码(7),由于t==tail 所以 p 被赋值为 head,然后重新循环,循环后执行到代码(4),这时候队列状态如图 7-10 所示。
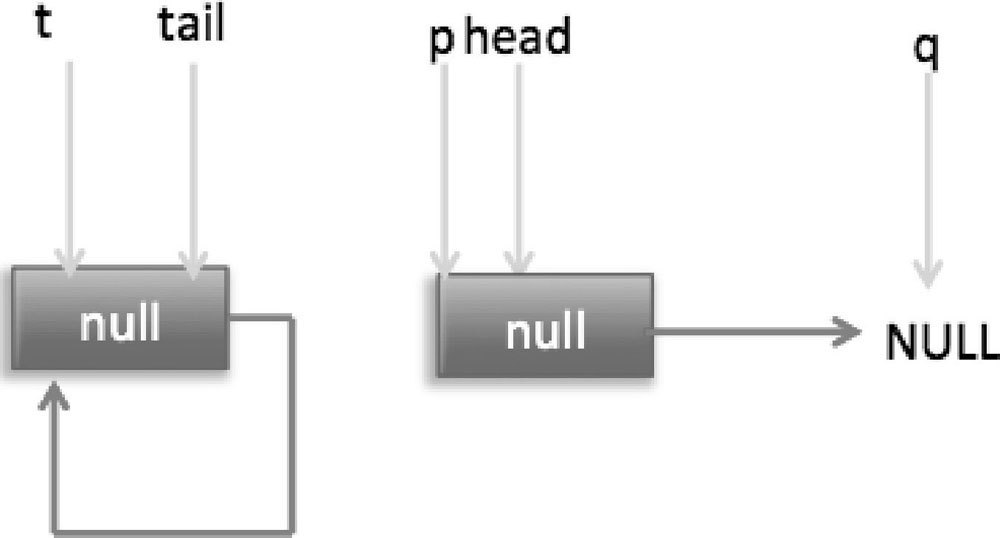
这时候由于 q==null,所以执行代码(5)进行 CAS 操作,如果当前没有其他线程执行 offer 操作,则 CAS 操作会成功,p 的 next 节点被设置为新增节点。然后执行代码(6),由于 p!=t 所以设置新节点为队列的尾部节点,现在队列状态如图 7-11 所示。
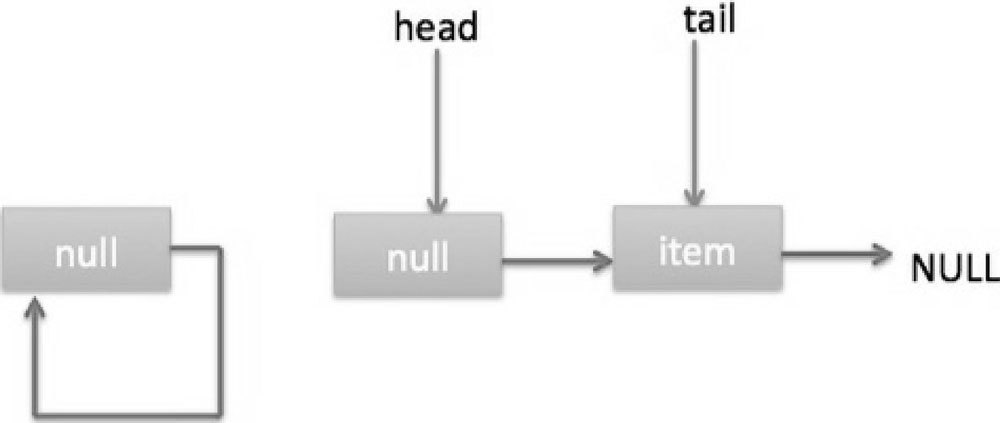
需要注意的是,这里自引用的节点会被垃圾回收掉。
可见,offer 操作中的关键步骤是代码(5),通过原子 CAS 操作来控制某时只有一个线程可以追加元素到队列末尾。进行 CAS 竞争失败的线程会通过循环一次次尝试进行 CAS 操作,直到 CAS 成功才会返回,也就是通过使用无限循环不断进行 CAS 尝试方式来替代阻塞算法挂起调用线程。相比阻塞算法,这是使用 CPU 资源换取阻塞所带来的开销。
2.add 操作
add 操作是在链表末尾添加一个元素,其实在内部调用的还是 offer 操作。
public boolean add(E e) {return offer(e);}
3.poll 操作
poll 操作是在队列头部获取并移除一个元素,如果队列为空则返回 null。下面看看它的实现原理。
public E poll() {//(1) goto 标记restartFromHead://(2)无限循环for (; ; ) {for (Node<E> h = head, p = h, q; ; ) {//(3)保存当前节点值E item = p.item;//(4)当前节点有值则 CAS 变为 nullif (item ! = null && p.casItem(item, null)) {//(5)CAS 成功则标记当前节点并从链表中移除if (p ! = h)updateHead(h, ((q = p.next) ! = null) ? q : p);return item;}//(6)当前队列为空则返回 nullelse if ((q = p.next) == null) {updateHead(h, p);return null;}//(7)如果当前节点被自引用了,则重新寻找新的队列头节点else if (p == q)continue restartFromHead;else//(8)p = q;}}}final void updateHead(Node<E> h, Node<E> p) {if (h ! = p && casHead(h, p))h.lazySetNext(h);}
同样,也结合图来讲解代码执行逻辑。
I.poll 操作是从队头获取元素,所以代码(2)内层循环是从 head 节点开始迭代,代码(3)获取当前队列头的节点,队列一开始为空时队列状态如图 7-12 所示。
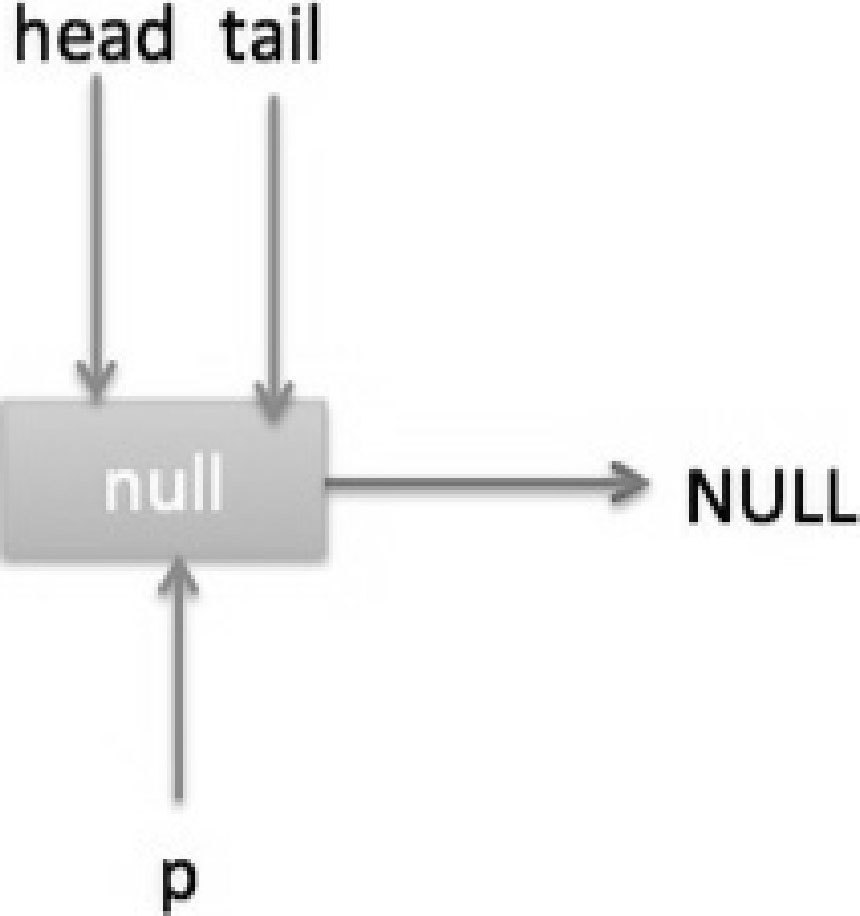
由于 head 节点指向的是 item 为 null 的哨兵节点,所以会执行到代码(6),假设这个过程中没有线程调用 offer 方法,则此时 q 等于 null,这时候队列状态如图 7-13 所示。
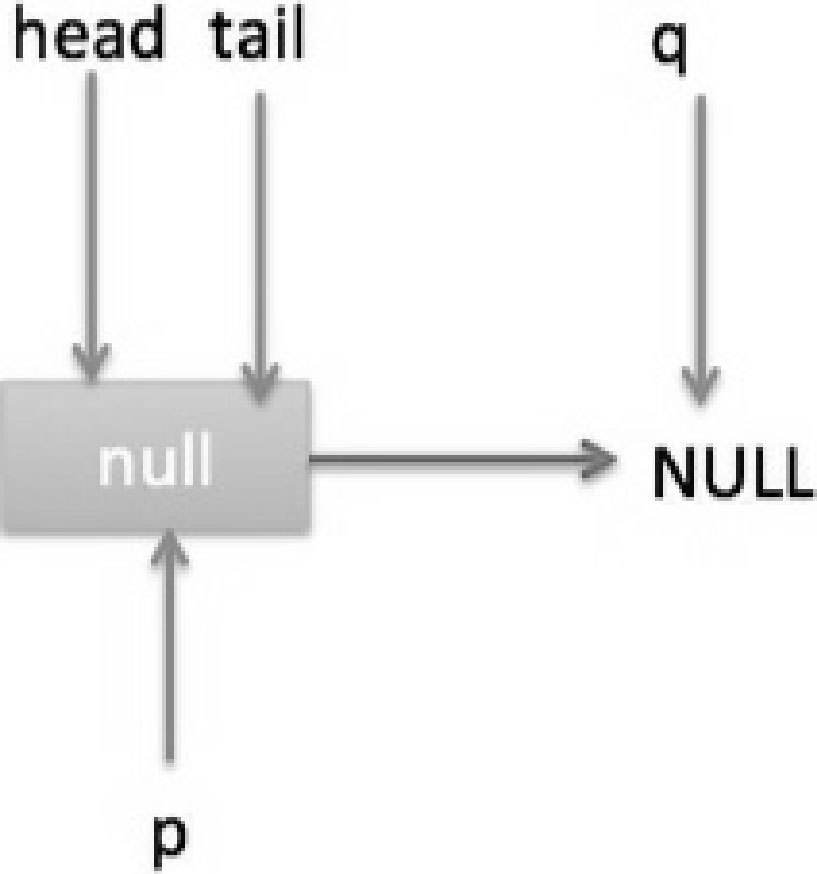
所以会执行 updateHead 方法,由于 h 等于 p 所以没有设置头节点,poll 方法直接返回 null。
II.假设执行到代码(6)时已经有其他线程调用了 offer 方法并成功添加一个元素到队列,这时候 q 指向的是新增元素的节点,此时队列状态如图 7-14 所示。
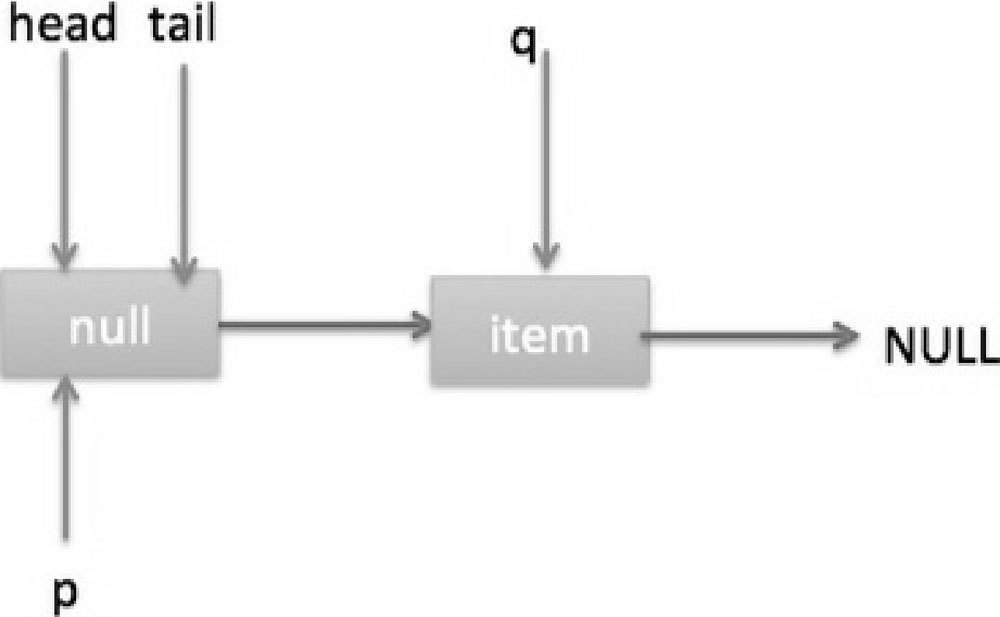
所以代码(6)判断的结果为 false,然后会转向执行代码(7),而此时 p 不等于 q,所以转向执行代码(8),执行的结果是 p 指向了节点 q,此时队列状态如图 7-15 所示。
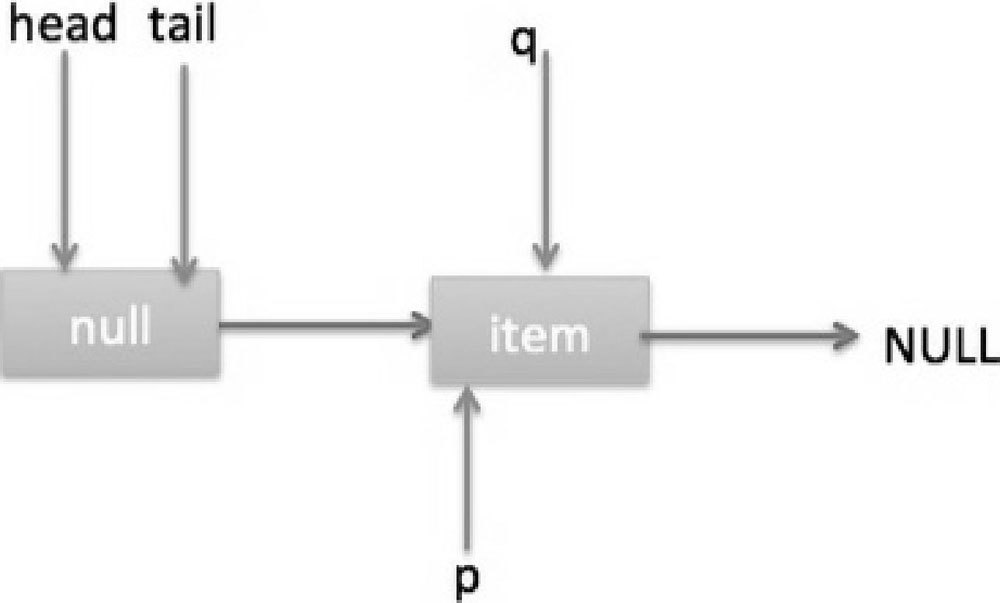
然后程序转向执行代码(3),p 现在指向的元素值不为 null,则执行 p.casItem(item, null)通过 CAS 操作尝试设置 p 的 item 值为 null,如果此时没有其他线程进行 poll 操作,则 CAS 成功会执行代码(5),由于此时 p!=h 所以设置头节点为 p,并设置 h 的 next 节点为 h 自己,poll 然后返回被从队列移除的节点值 item。此时队列状态如图 7-16 所示。
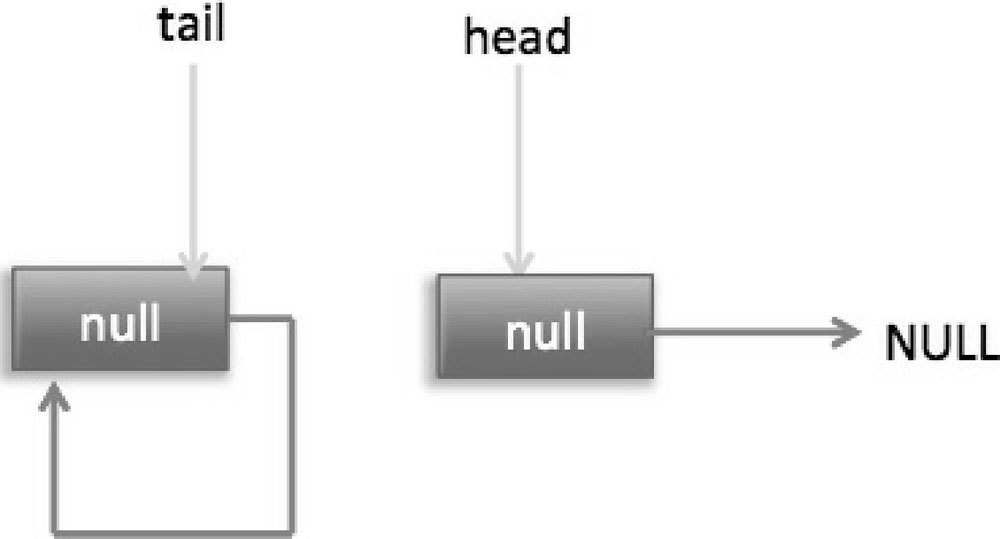
这个状态就是在讲解 offer 操作时,offer 代码的执行路径(7)的状态。
III.假如现在一个线程调用了 poll 操作,则在执行代码(4)时队列状态如图 7-17 所示。
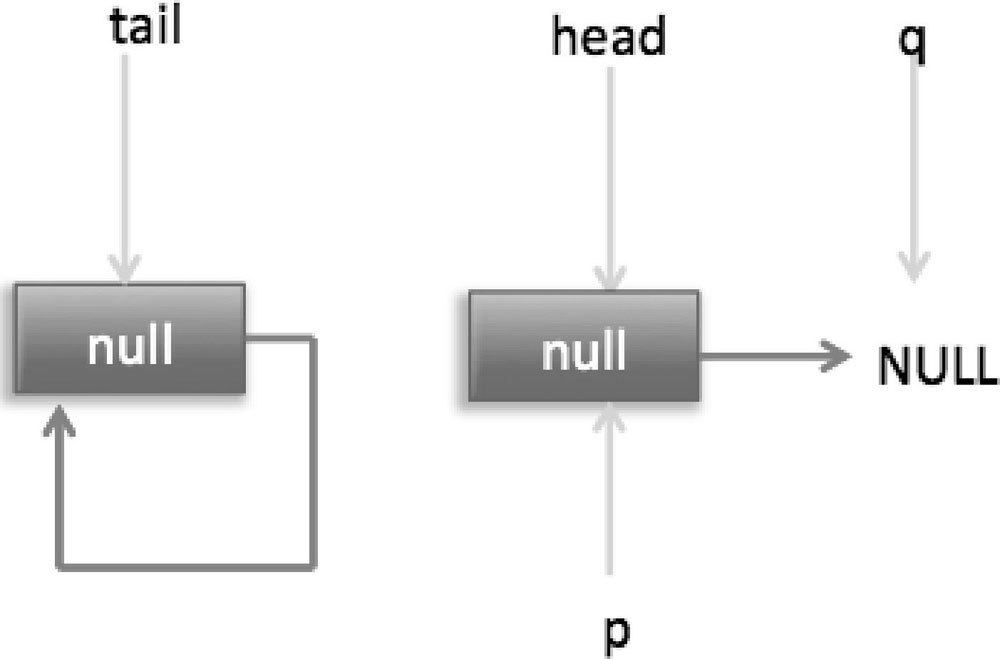
这时候执行代码(6)返回 null。
IV.现在 poll 的代码还有分支(7)没有执行过,那么什么时候会执行呢?下面来看看。假设线程 A 执行 poll 操作时当前队列状态如图 7-18 所示。
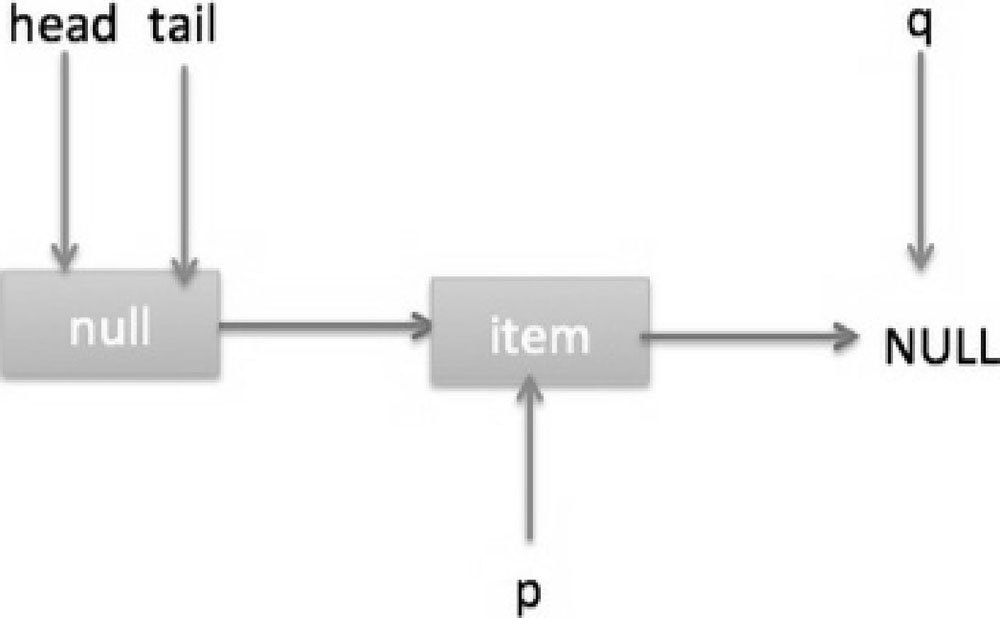
那么执行 p.casItem(item, null)通过 CAS 操作尝试设置 p 的 item 值为 null,假设 CAS 设置成功则标记该节点并从队列中将其移除,此时队列状态如图 7-19 所示。
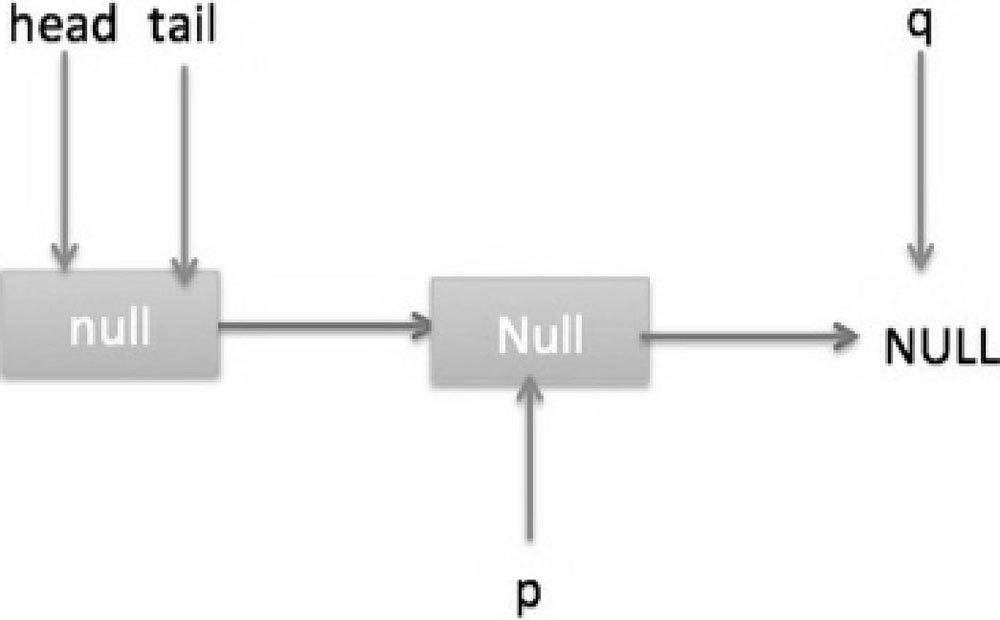
然后,由于 p!=h,所以会执行 updateHead 方法,假如线程 A 执行 updateHead 前另外一个线程 B 开始 poll 操作,这时候线程 B 的 p 指向 head 节点,但是还没有执行到代码(6),这时候队列状态如图 7-20 所示
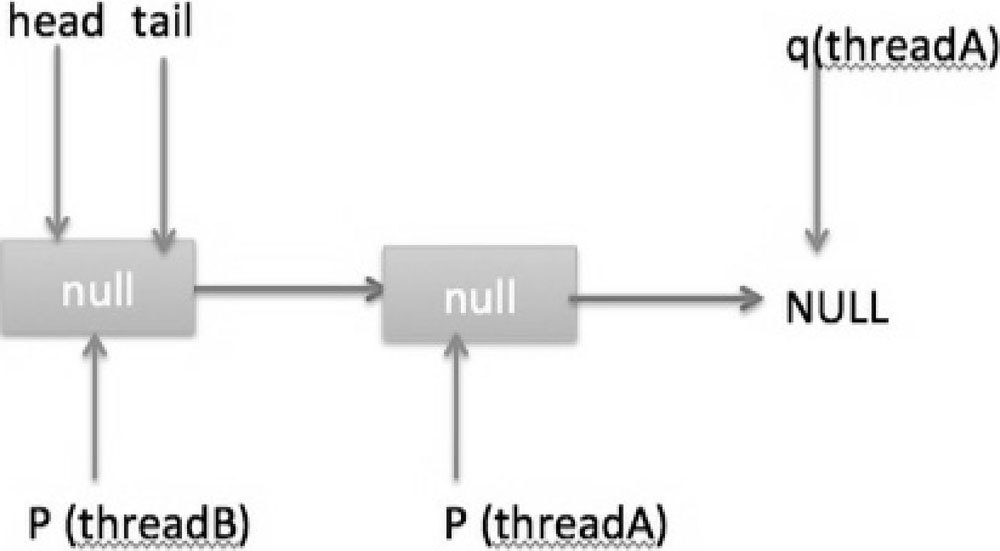
然后线程 A 执行 updateHead 操作,执行完毕后线程 A 退出,这时候队列状态如图 7-21 所示。
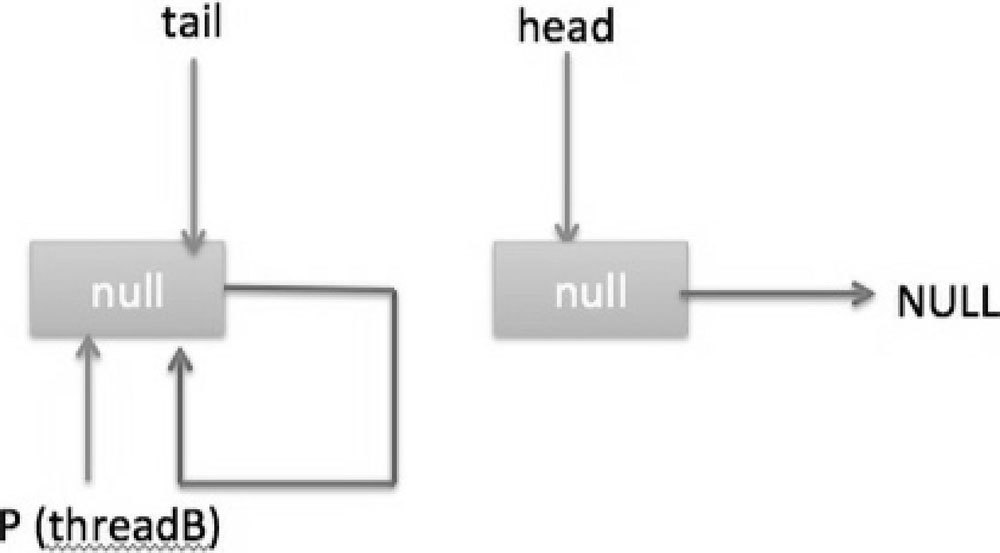
然后线程 B 继续执行代码(6),q=p.next,由于该节点是自引用节点,所以 p==q,所以会执行代码(7)跳到外层循环 restartFromHead,获取当前队列头 head,现在的状态如图 7-22 所示。
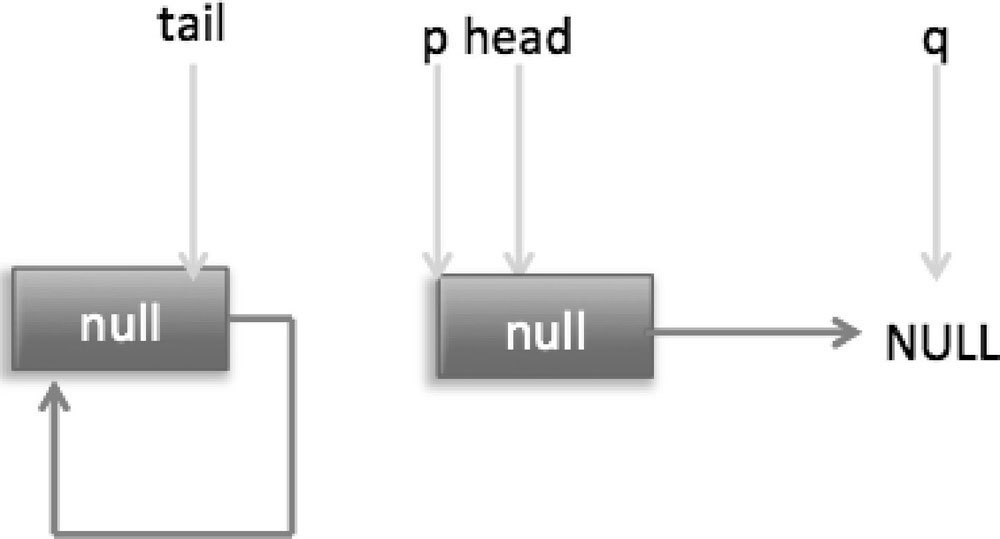
总结:poll 方法在移除一个元素时,只是简单地使用 CAS 操作把当前节点的 item 值设置为 null,然后通过重新设置头节点将该元素从队列里面移除,被移除的节点就成了孤立节点,这个节点会在垃圾回收时被回收掉。另外,如果在执行分支中发现头节点被修改了,要跳到外层循环重新获取新的头节点。
4.peek 操作
peek 操作是获取队列头部一个元素(只获取不移除),如果队列为空则返回 null。下面看下其实现原理。
public E peek() {//(1)restartFromHead:for (; ; ) {for (Node<E> h = head, p = h, q; ; ) {//(2)E item = p.item;//(3)if (item ! = null || (q = p.next) == null) {updateHead(h, p);return item;}//(4)else if (p == q)continue restartFromHead;else//(5)p = q;}}}
Peek 操作的代码结构与 poll 操作类似,不同之处在于代码(3)中少了 castItem 操作。其实这很正常,因为 peek 只是获取队列头元素值,并不清空其值。根据前面的介绍我们知道第一次执行 offer 后 head 指向的是哨兵节点(也就是 item 为 null 的节点),那么第一次执行 peek 时在代码(3)中会发现 item==null,然后执行 q=p.next,这时候 q 节点指向的才是队列里面第一个真正的元素,或者如果队列为 null 则 q 指向 null。
当队列为空时队列状态如图 7-23 所示。
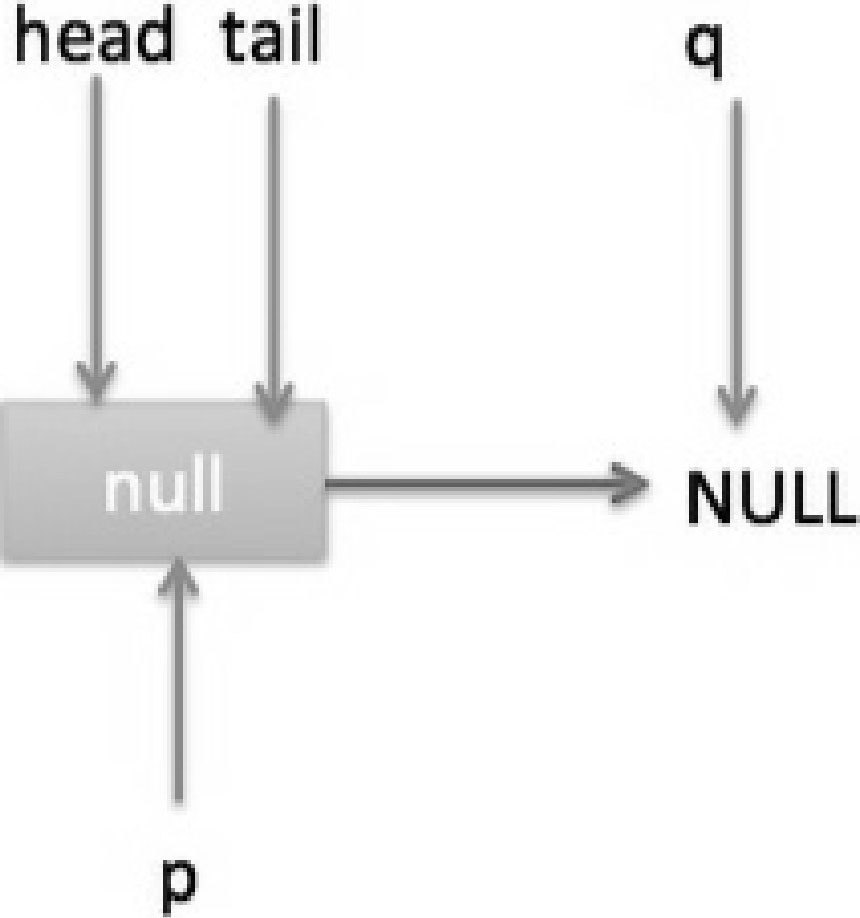
这时候执行 updateHead,由于 h 节点等于 p 节点,所以不进行任何操作,然后 peek 操作会返回 null。
当队列中至少有一个元素时(这里假设只有一个),队列状态如图 7-24 所示。
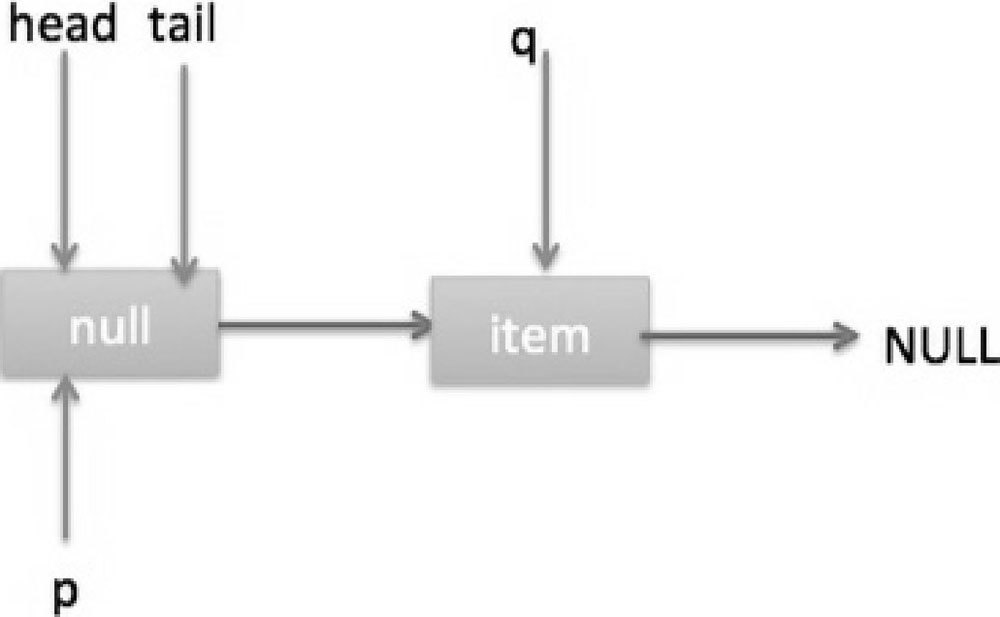
这时候执行代码(5),p 指向了 q 节点,然后执行代码(3),此时队列状态如图 7-25 所示。
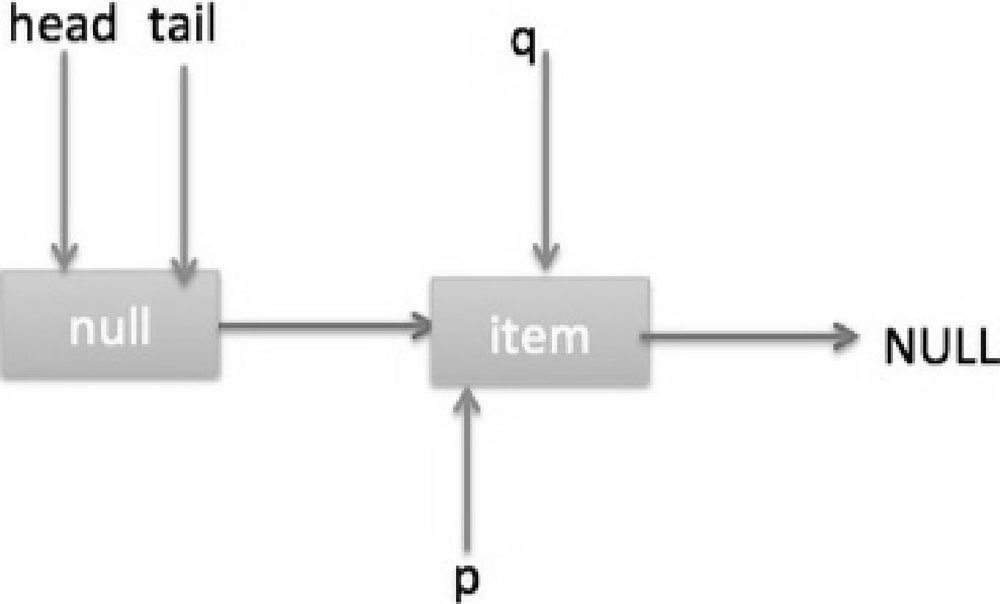
执行代码(3)时发现 item 不为 null,所以执行 updateHead 方法,由于 h!=p,所以设置头节点,设置后队列状态如图 7-26 所示。
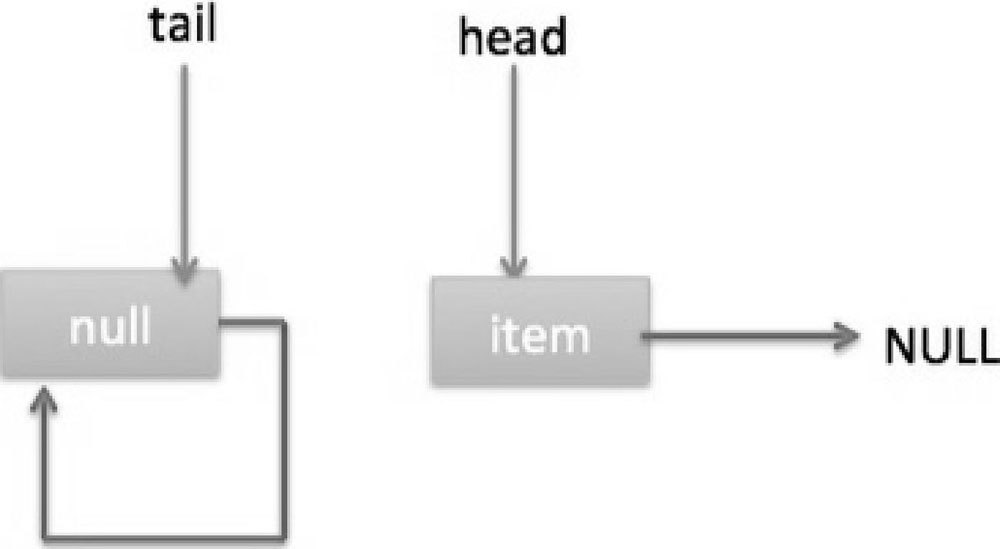
也就是剔除了哨兵节点。
总结:peek 操作的代码与 poll 操作类似,只是前者只获取队列头元素但是并不从队列里将它删除,而后者获取后需要从队列里面将它删除。另外,在第一次调用 peek 操作时,会删除哨兵节点,并让队列的 head 节点指向队列里面第一个元素或者 null。
5.size 操作
计算当前队列元素个数,在并发环境下不是很有用,因为 CAS 没有加锁,所以从调用 size 函数到返回结果期间有可能增删元素,导致统计的元素个数不精确。
public int size() {int count = 0;for (Node<E> p = first(); p ! = null; p = succ(p))if (p.item ! = null)// 最大值 Integer.MAX_VALUEif (++count == Integer.MAX_VALUE)break;return count;}//获取第一个队列元素(哨兵元素不算),没有则为 nullNode<E> first() {restartFromHead:for (; ; ) {for (Node<E> h = head, p = h, q; ; ) {boolean hasItem = (p.item ! = null);if (hasItem || (q = p.next) == null) {updateHead(h, p);return hasItem ? p : null;}else if (p == q)continue restartFromHead;elsep = q;}}}//获取当前节点的 next 元素,如果是自引入节点则返回真正的头节点final Node<E> succ(Node<E> p) {Node<E> next = p.next;return (p == next) ? head : next;}
6.remove 操作
如果队列里面存在该元素则删除该元素,如果存在多个则删除第一个,并返回 true,否则返回 false。
public boolean remove(Object o) {//为空,则直接返回 falseif (o == null) return false;Node<E> pred = null;for (Node<E> p = first(); p ! = null; p = succ(p)) {E item = p.item;//相等则使用 CAS 设置为 null,同时一个线程操作成功,失败的线程循环查找队列中是否有匹配的其他元素。if (item ! = null &&o.equals(item) &&p.casItem(item, null)) {//获取 next 元素Node<E> next = succ(p);//如果有前驱节点,并且 next 节点不为空则链接前驱节点到 next 节点if (pred ! = null && next ! = null)pred.casNext(p, next);return true;}pred = p;}return false;}
7.contains 操作
判断队列里面是否含有指定对象,由于是遍历整个队列,所以像 size 操作一样结果也不是那么精确,有可能调用该方法时元素还在队列里面,但是遍历过程中其他线程才把该元素删除了,那么就会返回 false。
public boolean contains(Object o) {if (o == null) return false;for (Node<E> p = first(); p ! = null; p = succ(p)) {E item = p.item;if (item ! = null && o.equals(item))return true;}return false;}
小结
ConcurrentLinkedQueue 的底层使用单向链表数据结构来保存队列元素,每个元素被包装成一个 Node 节点。队列是靠头、尾节点来维护的,创建队列时头、尾节点指向一个 item 为 null 的哨兵节点。第一次执行 peek 或者 first 操作时会把 head 指向第一个真正的队列元素。由于使用非阻塞 CAS 算法,没有加锁,所以在计算 size 时有可能进行了 offer、poll 或者 remove 操作,导致计算的元素个数不精确,所以在并发情况下 size 函数不是很有用。
如图 7-27 所示,入队、出队都是操作使用 volatile 修饰的 tail、head 节点,要保证在多线程下出入队线程安全,只需要保证这两个 Node 操作的可见性和原子性即可。由于 volatile 本身可以保证可见性,所以只需要保证对两个变量操作的原子性即可。
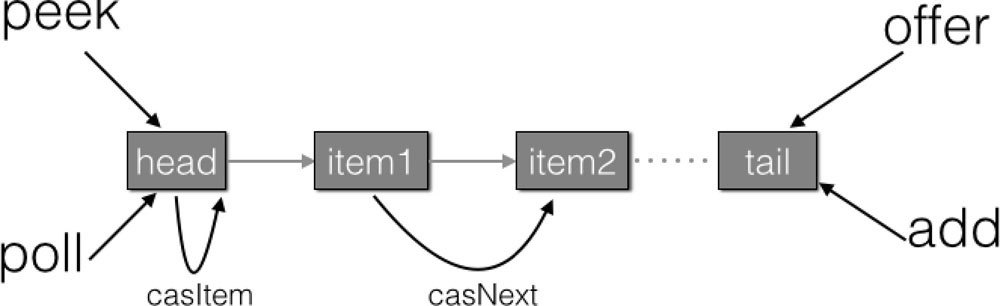
offer 操作是在 tail 后面添加元素,也就是调用 tail.casNext 方法,而这个方法使用的是 CAS 操作,只有一个线程会成功,然后失败的线程会循环,重新获取 tail,再执行 casNext 方法。poll 操作也通过类似 CAS 的算法保证出队时移除节点操作的原子性。

若有收获,就点个赞吧
0 人点赞
