- 先把坑放在着,大家注意踩一下
- 一、准备服务器镜像
- https://hub.docker.com/">1、docker镜像仓库地址,可以在这里检索你所需要的镜像版本,本次集群搭建使用是的centos7.5 https://hub.docker.com/
- 2、为hadoop集群单独构建虚拟网络
- 3、查看 Docker 中的网络
- 4、查看已经下载的镜像
- 5、根据镜像启动一个容器,可以看出 shell 已经是容器的 shell 了(第二行开头,已经是root用户了):
- 6、退出虚拟机:输入exit
- 二、安装JDK和hadoop
- 三、安装SSHD和network_tools
- 四、配置服务器环境变量以及hadoop核心配置文件
- 五、docker中启动集群
- 六、网页访问、Hadoop命令
先把坑放在着,大家注意踩一下
1、修改浏览器所在系统的host文件 Mac可以安装 switchhosts 配置系统的hosts 127.0.0.1 hadoop001 127.0.0.1 hadoop002 127.0.0.1 hadoop003 2、启动doker容器时尽量暴露相关的必要端口 docker run -it —network hadoop -h hadoop003 —name “hadoop003” -p 9868:9868 modelhadoop:2.0 /bin/bash docker run -it —network hadoop -h hadoop002 —name “hadoop002” —iptables false -p 8088:8088 -p 9864:9864 modelhadoop:2.0 /bin/bash docker run -it —network hadoop -h hadoop001 —name “hadoop001” —iptables false -p 9870:9870 -p 19888:19888 -p 9866:9866 -p 9820:9820 -p 10020:10020 -p 8042:8042 modelhadoop:2.0 /bin/bash -v /Users/iflytek/Documents/dockersoft:/usr/local/software docker run -d —name centos7 —privileged=true modelhadoop:2.0 /usr/sbin/init 3、集群中三个节点主要部署方式 hadoop001 hadoop002 hadoop003 NameNode DataNode SecondaryNameNode DataNode NodeManager DataNode NodeManager ResourceManager NodeManager historyserver
一、准备服务器镜像
1、docker镜像仓库地址,可以在这里检索你所需要的镜像版本,本次集群搭建使用是的centos7.5 https://hub.docker.com/
docker pull centos:7.5.1804
2、为hadoop集群单独构建虚拟网络
docker network create --driver=bridge hadoop
3、查看 Docker 中的网络
docker network lsNETWORK ID NAME DRIVER SCOPEe1b9158cfb33 bridge bridge local4f6e1564b511 hadoop bridge localdab2ec29b3c6 host host localbd255529ccad none null local
4、查看已经下载的镜像
iflytek@iflytek ~ % dodocker imagesREPOSITORY TAG IMAGE ID CREATED SIZEmodelhadoop 2.0 dd78b33dfe4a 17 hours ago 1.87GBdocker/desktop-git-helper 5a4fca126aadcd3f6cc3a011aa991de982ae7000 efe2d67c403b 7 months ago 44.2MBcentos centos7.5.1804 cf49811e3cdb 2 years ago 200MBredis 3.2 87856cc39862 3 years ago 76MB
5、根据镜像启动一个容器,可以看出 shell 已经是容器的 shell 了(第二行开头,已经是root用户了):
iflytek@iflytek ~ % docker run -it centos:centos7.5.1804 /bin/bash[root@a605e443c2b7 /]#
6、退出虚拟机:输入exit
[root@a605e443c2b7 /]# exitexitiflytek@iflytek ~ %
二、安装JDK和hadoop
1、启动容器
由于镜像中不包含wget,也没有预先安装sshd,传统的scp与http方式均无法传输,需要通过bind mount的方式启动镜像,来完成文件传输.
此处使用本机的/Users/iflytek/Documents/dockersoft目录
docker run -it --name hadoop -v /Users/iflytek/Documents/dockersoft:/usr/local/software modelhadoop:2.0
2、软件安装
将软件包放置到/Users/iflytek/Documents/dockersoft可以在容器/usr/local/software看到对应安装包
目录规划:
/usr/local/bigdata/jdk 作为jdk目录/usr/local/bigdata/hadoop hadoop的目录 包含jar包 启动脚本 hadoop配置等/usr/local/bigdata/logs 存放日志,方便查阅 这个后边用hadoop用户创建
解压软件包:
## 创建目录并拷贝软件包mkdir /usr/local/bigdatacp /usr/local/software /usr/local/bigdatacd /usr/local/bigdata## 解压后重命名tar -zxvf hadoop-3.1.3.tar.gztar -zxvf jdk-8u161-linux-x64.tar.gzmv hadoop-3.1.3 hadoopmv jdk1.8.0_281/ jdk## 清理安装包 减小容器大小rm -f hadoop-3.1.3.tar.gzrm -f jdk-8u161-linux-x64.tar.gz
三、安装SSHD和network_tools
hadoop节点间通过ssh操作,默认镜像中并不包含sshd服务,因为需要安装.
yum update#一路Y回车.更新完yum后安装sshdyum install -y openssl openssh-serveryum install openssh*#一路回车,创建密钥并启动ssh服务ssh-keygen -t rsassh-keygen -t dsassh-keygen -t ecdsassh-keygen -t ed25519cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
修改sshd的配置文件:
vi /etc/ssh/sshd_config
修改部分为:
### 原内容HostKey /etc/ssh/ssh_host_rsa_keyHostKey /etc/ssh/ssh_host_ecdsa_keyHostKey /etc/ssh/ssh_host_ed25519_key### 修改为HostKey /root/.ssh/id_rsaHostKey /root/.ssh/id_ecdsaHostKey /root/.ssh/id_ed25519HostKey /root/.ssh/id_dsa
允许远程登陆:
vi /etc/pam.d/sshd# 使用#注释掉此行# account required pam_nologin.so
启动sshd服务并查看状态:
/usr/sbin/sshdps -ef | grep sshdroot 411 1 0 05:02 ? 00:00:00 /usr/sbin/sshdroot 8168 8038 0 08:04 pts/7 00:00:00 grep --color=auto sshd
安装net-tools
yum install net-tools
四、配置服务器环境变量以及hadoop核心配置文件
1、环境变量配置
vi ~/.bash_profile替换内容如下# .bashrc# Source global definitionsif [ -f /etc/bashrc ]; then. /etc/bashrcfi# User specific environmentif ! [[ "$PATH" =~ "$HOME/.local/bin:$HOME/bin:" ]]thenPATH="$HOME/.local/bin:$HOME/bin:$PATH"fiexport JAVA_HOME=/usr/local/bigdata/jdkexport CLASSPATH=$JAVA_HOME/libexport PATH=$PATH:$JAVA_HOME/bin# hadoop envexport HADOOP_HOME=/usr/local/bigdata/hadoopexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec#export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH#export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoopexport HDFS_DATANODE_USER=rootexport HDFS_DATANODE_SECURE_USER=rootexport HDFS_SECONDARYNAMENODE_USER=rootexport HDFS_NAMENODE_USER=rootexport YARN_RESOURCEMANAGER_USER=rootexport YARN_NODEMANAGER_USER=rootPATH=$PATH:$HOME/binexport PATH# Uncomment the following line if you don't like systemctl's auto-paging feature:# export SYSTEMD_PAGER=# User specific aliases and functions
:wq保存,更新环境变量
source ~/.bash_profile
2、配置Hadoop环境(重点来了)
Hadoop配置中,有5个文件是重点配置的,分别是:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers,下面就一个个开始配置:
hadoop相关组件的配置文件所在目录如下:/usr/local/bigdata/hadoop/etc/hadoop
1、修改core-site.xml
<configuration> <!--指定nameNode的地址--><property><name>fs.defaultFS</name><value>hdfs://hadoop001:8020</value></property><!--指定Hadoop数据的存储目录--><property><name>hadoop.tmp.dir</name><value>/usr/local/bigdata/hadoop/data</value></property><!--配置HDFS网页登陆使用的静态用户,配置这个之后才有权限可以在网页端删除文件、文件夹--><property><name>hadoop.http.staticuser.user</name><value>root</value></property></configuration>
2、修改 hadoop-env.sh 文件,在文件末尾添加以下信息(JAVA_HOME根据自己的修改)
export JAVA_HOME=/usr/local/bigdata/jdkexport HDFS_NAMENODE_USER=rootexport HDFS_DATANODE_USER=rootexport HDFS_SECONDARYNAMENODE_USER=rootexport YARN_RESOURCEMANAGER_USER=rootexport YARN_NODEMANAGER_USER=root
3、修改hdfs-site.xml,修改为:
<configuration> <!--文件的存储个数--><property><name>dfs.replication</name><value>3</value></property> <!--nn web端访问地址,使用网页访问HDFS文件系统就是这个端口--><property><name>dfs.namenode.http-address</name><value>hadoop001:9870</value></property> <!--2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop001:9868</value></property> <!--网页查看HDFS文件内容,出现Couldn‘t preview the file报错,需要配置的参数--><property><name>dfs.webhdfs.enabled</name><value>true</value></property></configuration>
4、修改mapred-site.xml,修改为
<configuration> <!--指定MapReduce程序运行在Yarn上--><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
5、修改yarn-site.xml,修改为
<configuration><!--指定MR走 shuffle--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop001</value></property><!--环境变量的继承--><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property></configuration>
6、修改workers,修改为:
hadoop001hadoop002hadoop003
注意:hadoop001这些后面不要有空格!hadoop003后面,不要有空的行!自己准备起多少集群,就在这里写几个,要是准备起5个集群,就写到hadoop005。
五、docker中启动集群
1、先将当前容器 导出为镜像(使用自己的centos容器id),并查看当前镜像
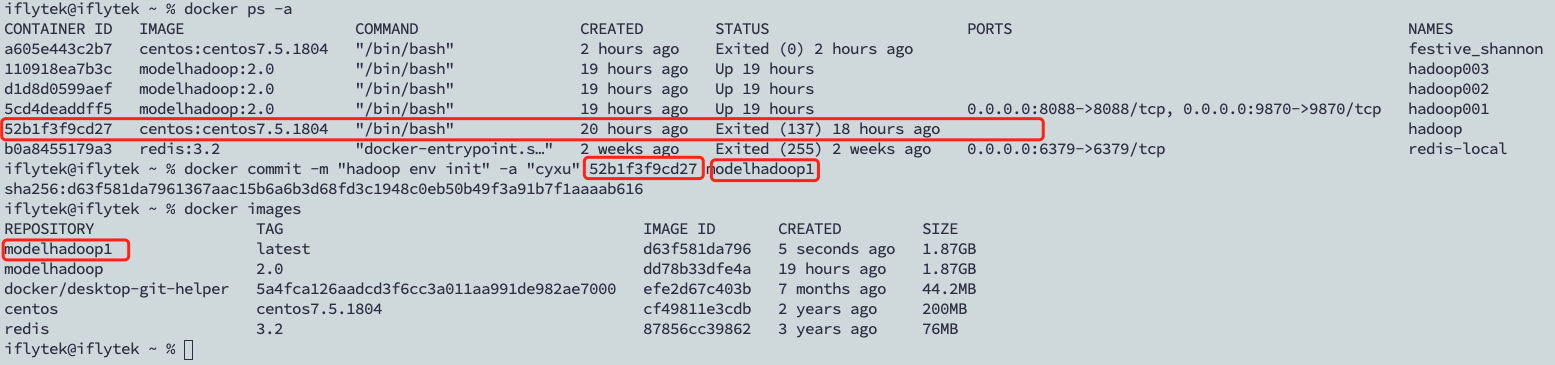
2、启动3个终端(注意,是要开3个终端!!!)
第一条命令启动的是 hadoop001 是做 master 节点的,所以暴露了端口,以供访问 web 页面
docker run -it --network hadoop -h hadoop001 --name "hadoop001" -p 9870:9870 -p 19888:19888 -v /Users/iflytek/Documents/dockersoft:/usr/local/software hadoop001:2.0 /bin/bash
后面几条命令就基本类似,第二条命令
docker run -it --network hadoop -h hadoop002 --name "hadoop002" -p 8088:8088 -pm 8032:8032 hadoop001:2.0 /bin/bash
第三条命令
docker run -it --network hadoop -h hadoop003 --name "hadoop003" modelhadoop /bin/bash
3、在 hadoop001主机中,启动 Haddop 集群
先进行格式化操作,不格式化操作,hdfs起不来:
[root@hadoop001 hadoop]# ./bin/hdfs namenode -format
然后启动HDFS集群:
[root@hadoop001 hadoop]# ./sbin/start-dfs.sh
最后,启动yarn集群管理节点:
[root@hadoop001 hadoop]# ./sbin/start-yarn.sh
都启动完成后,使用 jps 命令查看:
[root@hadoop001 hadoop]# jps7328 NodeManager8336 Jps2709 NameNode3084 SecondaryNameNode2876 DataNode7181 ResourceManager
可以看到,除了Jps,一共有5个进程,因为这里没有将 nameNode、ResourceManager、SecondaryNameNode分开部署,所以都在 h01这一台机器上,实际生产中,应该是需要分开部署的。
至此,Hadoop 集群已经构建好了。六、网页访问、Hadoop命令
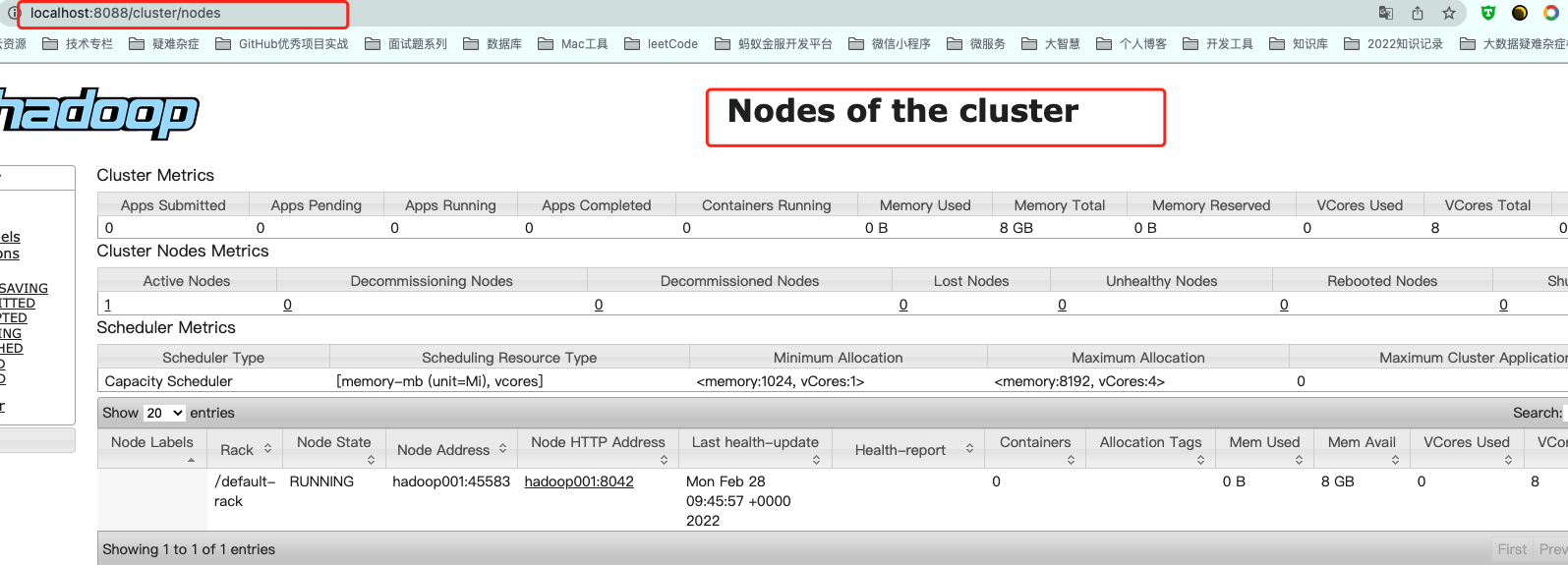
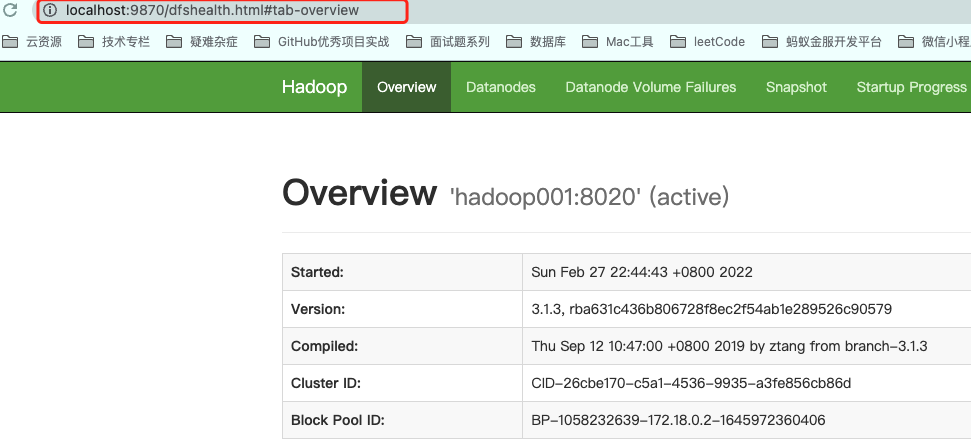
1.浏览器访问本机的9870端口,可以看到Hadoop的文件管理系统:
2.浏览器访问本机的8088端口,可以看到Hadoop中 Yarn的资源调度系统:
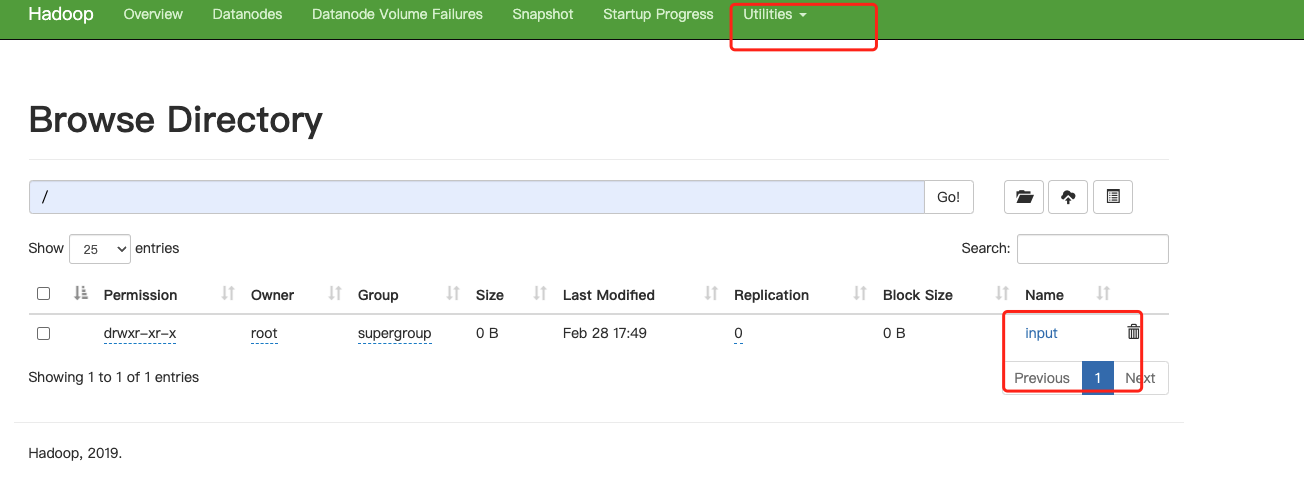
3.在 HDFS 中创建 input 文件夹:
4、上传文件
[root@hadoop001 hadoop]# lsLICENSE.txt NOTICE.txt README.txt bin data etc include lib libexec logs sbin share[root@hadoop001 hadoop]# ./bin/hadoop fs -put ./README.txt /input

若有收获,就点个赞吧
0 人点赞
