首先我们访问 https://github.com/medcl/elasticsearch-analysis-ik/releases 下载与es对应版本的中文分词器。将解压后的后的文件夹放入es根目录下的plugins目录下,重启es即可使用。
我们这次加入新的参数”analyzer”:”ik_max_word”
- k_max_word:会将文本做最细粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌」,会穷尽各种可能的组合
- ik_smart:会将文本做最粗粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、国歌」
{ “tokens”: [
{ “token”: “农业银行”, “start_offset”: 0, “end_offset”: 4, “type”: “CN_WORD”, “position”: 0 },
{ “token”: “农业”, “start_offset”: 0, “end_offset”: 2, “type”: “CN_WORD”, “position”: 1 },
{ “token”: “银行”, “start_offset”: 2, “end_offset”: 4, “type”: “CN_WORD”, “position”: 2 } ] }
Mapping简介#
mapping 是用来定义文档及其字段的存储方式、索引方式的手段,例如利用mapping 来定义以下内容:
- 哪些字段需要被定义为全文检索类型
- 哪些字段包含number、date类型等
- 格式化时间格式
-
字段类型#
一种简单的数据类型,例如text、keyword、double、boolean、long、date、ip类型。
- 也可以是一种分层的json对象(支持属性嵌套)。
- 也可以是一些不常用的特殊类型,例如geo_point、geo_shape、completion
针对同一字段支持多种字段类型可以更好地满足我们的搜索需求,例如一个string类型的字段可以设置为text来支持全文检索,与此同时也可以让这个字段拥有keyword类型来做排序和聚合,另外我们也可以为字段单独配置分词方式,例如”analyzer”: “ik_max_word”,
text 类型#
text类型的字段用来做全文检索,例如邮件的主题、淘宝京东中商品的描述等。这种字段在被索引存储前先进行分词,存储的是分词后的结果,而不是完整的字段。text字段不适合做排序和聚合。如果是一些结构化字段,分词后无意义的字段建议使用keyword类型,例如邮箱地址、主机名、商品标签等。
常有参数包含以下
- analyzer:用来分词,包含索引存储阶段和搜索阶段(其中查询阶段可以被search_analyzer参数覆盖),该参数默认设置为index的analyzer设置或者standard analyzer
- index:是否可以被搜索到。默认是true
- fields:Multi-fields允许同一个字符串值同时被不同的方式索引,例如用不同的analyzer使一个field用来排序和聚类,另一个同样的string用来分析和全文检索。下面会做详细的说明
- search_analyzer:这个字段用来指定搜索阶段时使用的分词器,默认使用analyzer的设置
- search_quote_analyzer:搜索遇到短语时使用的分词器,默认使用search_analyzer的设置
keyword 类型#
keyword用于索引结构化内容(例如电子邮件地址,主机名,状态代码,邮政编码或标签)的字段,这些字段被拆分后不具有意义,所以在es中应索引完整的字段,而不是分词后的结果。
通常用于过滤(例如在博客中根据发布状态来查询所有已发布文章),排序和聚合。keyword只能按照字段精确搜索,例如根据文章id查询文章详情。如果想根据本字段进行全文检索相关词汇,可以使用text类型
date类型#
支持排序,且可以通过format字段对时间格式进行格式化。
json中没有时间类型,所以在es在规定可以是以下的形式:
- 一段格式化的字符串,例如”2015-01-01”或者”2015/01/01 12:10:30”
- 一段long类型的数字,指距某个时间的毫秒数,例如1420070400001
- 一段integer类型的数字,指距某个时间的秒数
object类型#嵌套JSON在ES中可以铺平进行检索
mapping中不用特意指定field为object类型,因为这是它的默认类型。
json类型天生具有层级的概念,文档内部还可以包含object类型进行嵌套。例如:
PUT my_index/_doc/1 { “region”: “US”, “manager”: { “age”: 30, “name”: { “first”: “John”, “last”: “Smith” } } }
在ES中,按照铺平的结果来检索
{ “region”: “US”, “manager.age”: 30, “manager.name.first”: “John”, “manager.name.last”: “Smith” }
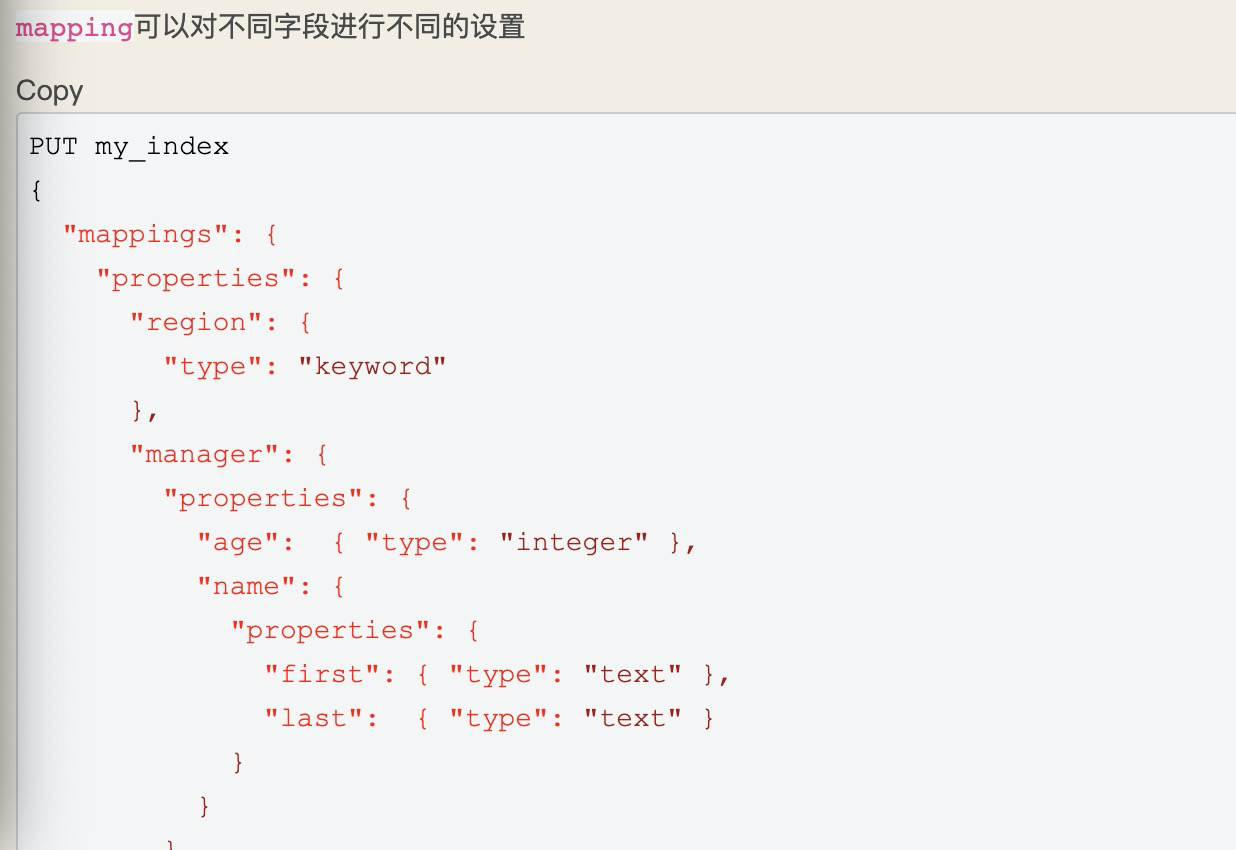
实战:同时使用keyword和text类型#

| _index | _type | _id | _score | itemId | title | desc | num | Price |
|---|---|---|---|---|---|---|---|---|
| idx_item | _doc | rvsX-W4Bo-iJGWqbQ8dk | 1 | 1 | 苏泊尔煮饭SL3200 | 让煮饭更简单,让生活更快乐 | 100 | 200 |
| idx_item | _doc | sPsY-W4Bo-iJGWqbscfU | 1 | 3 | 厨房能手威猛先生 | 你煲粥,我洗锅 | 100 | 30 |
| idx_item | _doc | r_sX-W4Bo-iJGWqbhMew | 1 | 2 | 苏泊尔煲粥好能手型号SL322 | 你煲粥,我煲粥,我们一起让煲粥更简单 | 100 | 190 |
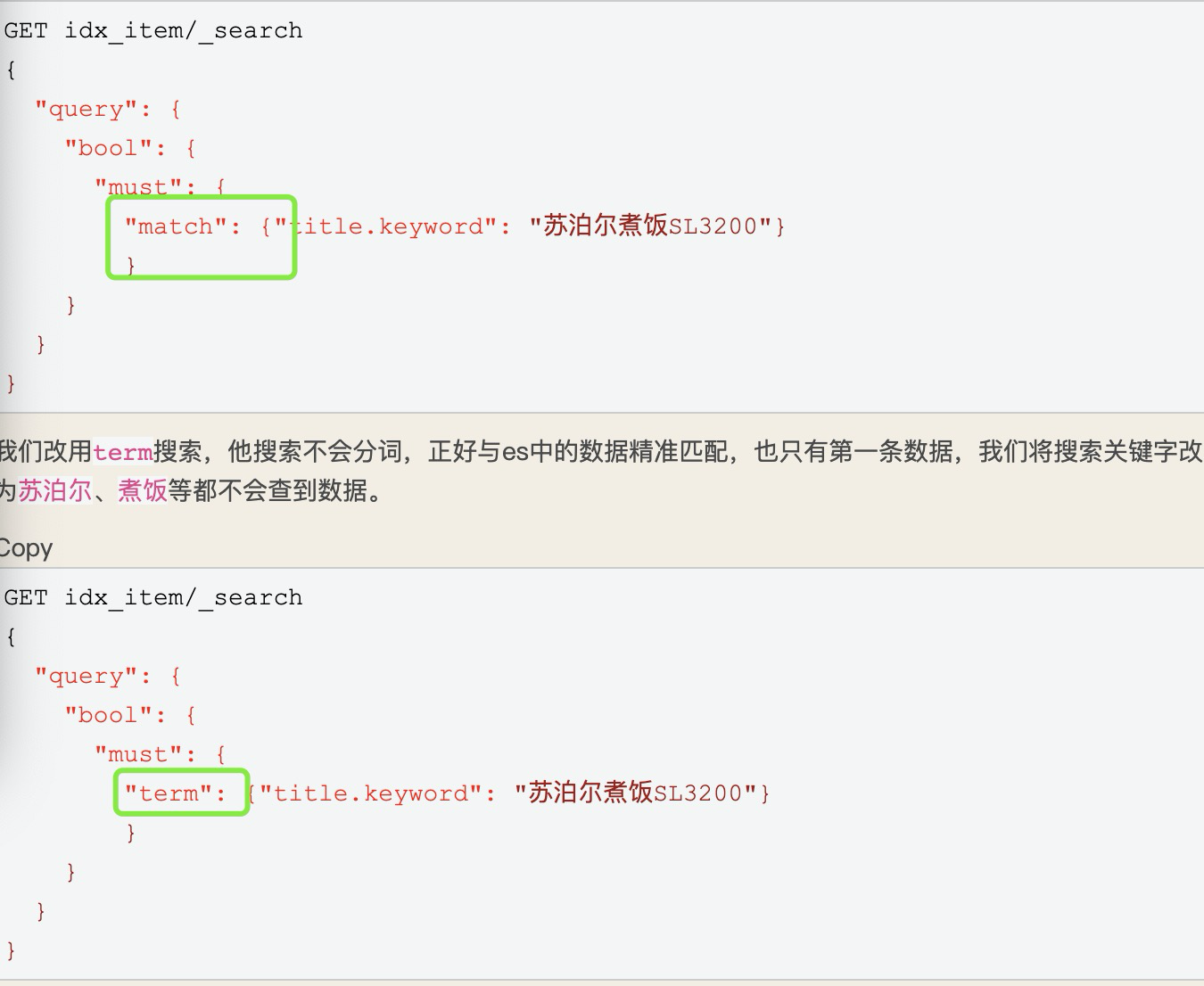
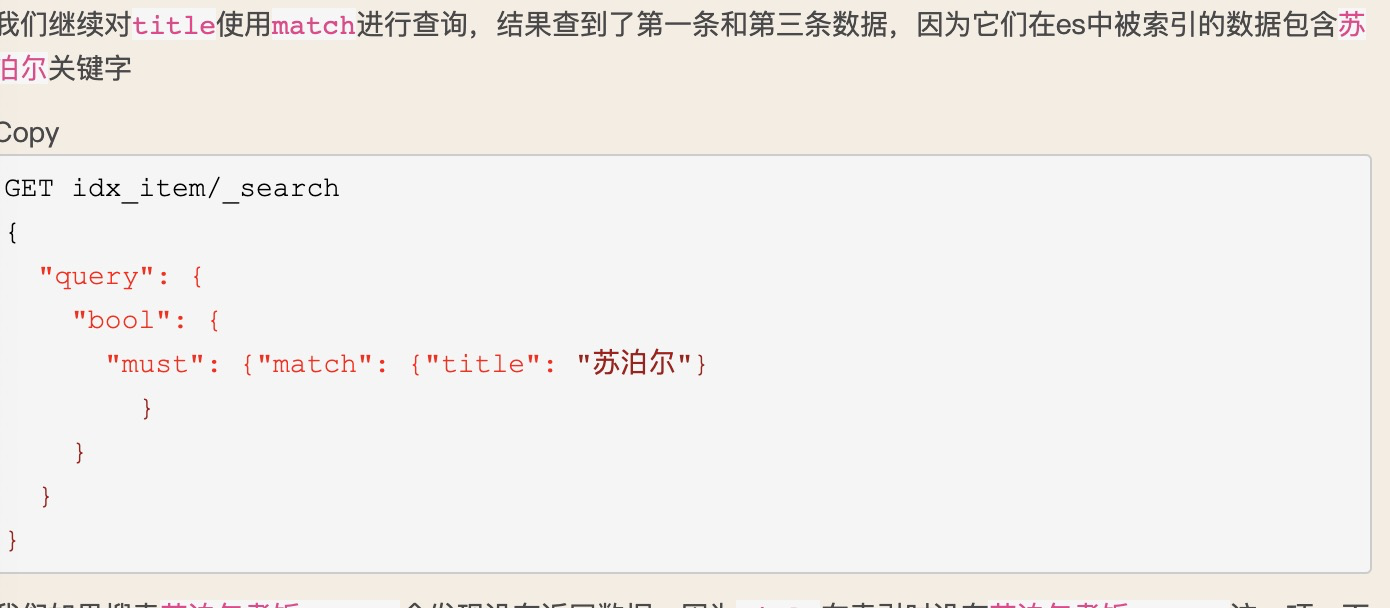
对时间的格式转化,用于时间排序。
GET idx_pro/_search {
“sort”:{“createTime”: {“order”: “asc”}},
“query”: { “bool”:
{ “must”: {“match_all”: {}
} } } }

若有收获,就点个赞吧
0 人点赞
