VSOURCE是我从学生时代一直到现在业余一直在维护的远程调用的分布式算法平台,用户可以从客户端直接远程调用算法,其算法的参数会被转发到具体的计算服务器计算,然后计算的结果会被转发到客户端。
例如一个人脸生成的算法,用户在自己的电脑上只需要调用一个face_generation的命令,然后这个请求会发送到中央服务器,中央服务器转发到具体部署人脸算法的计算服务器,计算出人脸后,这个人脸数据会被转发到中央服务器,然后转发到客户端,客户端拿到这个生成的人脸图像。从客户端的角度来讲,这个调用仿佛在自己的机器上进行了人脸生成一样。
在整个远程调用过程中,涉及到了算法的调用端的调度问题,这里介绍一下VSOURCE采用的调用算法,是我原创出的一种调度方法,当然复杂程度并不高。我们先总结一下算法调用的特点,第一,算法调用很消耗资源,尽量是单独部署在计算服务器上;第二,算法调用时间往往不是瞬时的。这两个特点决定了高并发的时候资源会非常的吃紧,乃至于很容易把整个平台服务击穿。
所以平台的端,分为了三个部分,第一个部分是客户端Client,只是用来发送算法请求和参数的,第二个端是中央服务器Center,用来预处理和转发请求,第三个端是计算端Calculator,专门用来进行算法的调用。那么这里涉及到的算法调度问题是,一个算法服务部署了多个可能在不同机器上的调用端,当请求进来的时候,如何去进行这样的分布式调度。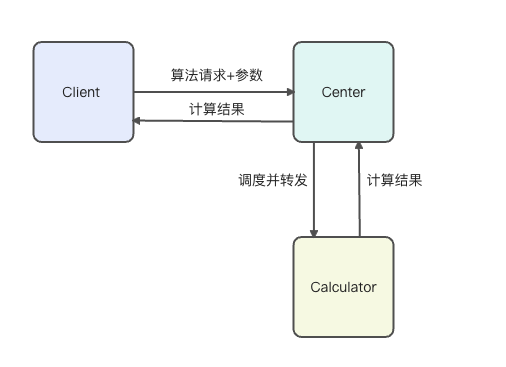
三个端的通信如上图所述,例如对于人脸生成算法,有大量用户在使用这个算法,那么我会在多台计算机器上部署这个算法,并且注册进Center中,当请求进来的时候,调度哪一个Calculator是目前的问题。
在现实生活中,我们假装自己是一个Leader,大量的需求会到我这里,然后我手下可能有多个Worker,我会具体的去寻找里面的较为“空闲”一个Worker去处理这个需求。在分布式的环境下,假设存在Leader的情况下,我如何去发现我的具体的Worker,往往采用心跳检测的方式,也就是Worker会持续的向Leader发送心跳包,Leader再向Worker进行收到的确认,然后Worker再向Leader发送一个“我已准备就绪”的信号建立了双方的连接,这也是一个经典的三次握手。
那么我是一个Leader,手上攒了一些需求,这个时候我和一个Worker建立了心跳连接,而且当我发现这个Worker并不忙的时候,完全可以把我手上的需求给他一个让他来进行计算。所以VSOURCE的算法调度,是直接包含在心跳检测中的。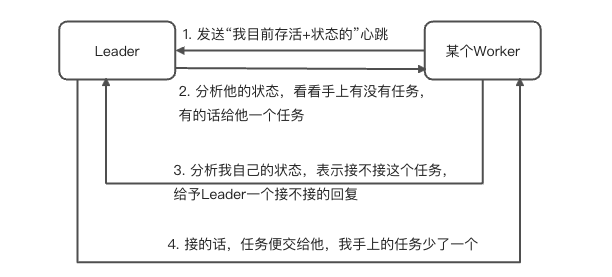
上图便是一个Leader和Worker通信的过程,VSOURCE的做法是一致的,算法Leader(Center的注册算法服务)会持久化的维护该算法的任务队列,Calculator部署后会持续的发送心跳,在发送后,Leader接收到心跳,会分析要不要把任务给它,要的话在返回心跳回复的时候会把任务带上,Worker再来决定接不接这个任务,如果接的话,会消费掉Leader手上的任务,并且在计算结束后返回结果,那么返回结果的过程也是类似的。
在Calculator数量较多的情况下,心跳包的发送是非常的频繁的,Leader的处理量会非常的大,那么分布式的一致性如何解决?这里的解决方法便是维持Leader本身任务队列的互斥即可,而所有的分析、思考、计算的过程都不需要考虑分布式的一致性问题,因为只要Worker的状态是正常的,任务本身会被持续的消费,且一个任务会被一个状态正常的Worker接收,在高并发的环境下,每一个Worker都不是无辜的,都会持续的在计算算法,如果算法调用的人数持续的增加,我只需要直接弹性的增加Worker,而不需要进行任何的人为处理。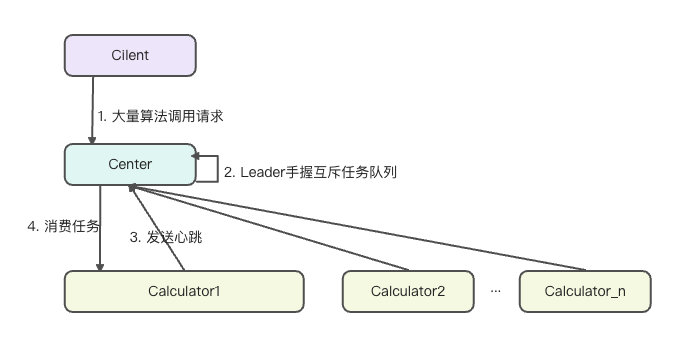
最后,你会发现只需要写好Leader的处理逻辑,以及Worker的处理逻辑,整个算法过程是全自动的,Worker可以无限的弹性扩张,只需要Leader本身能够支持高并发的请求队列和心跳,而Leader本身也是可以进行分布式扩展的,因为每一个算法本身,可以人为的拆成多个不同的Leader,但实际上可以连接同一批的Worker,所以整个过程数据是一致的,且很大程度的利用了整个集群的计算资源来完成高并发的算法请求。
其优点是显而易见的:
- 大量的算法请求不会击穿服务器,哪怕算法的计算资源非常的大。
- 整个过程注册算法Leader,弹性扩容Calculator都是非常的容易的,而且是全自动化的调度。
- 可以人为的去判断Worker“空闲”的状态,从而更方便进行一些手工的权重操作。
持续答复一些同学的问题:
- 我如何判断一个算法调用的人是多是少,怎么才能知道我的A算法部署的资源是满足目前的服务需求的?
答:这里只需要将Center的任务队列存余量进行透出即可,如何往往一直都是一个很小的数字,说明是满足服务需求的,如果在不停的增长,说明算法的调用端是需要扩容的。那么这里有一个风险就是可能会一直持续的增长,这个时候你的队列要考虑性能问题,如果是用缓存做的话需要增设一个阈值,达到阈值后写入DB,而不是继续增长,但在逻辑上还是要维持整个队列的性质,要用逻辑调度方式让任务不会丢失,且顺序不会乱。

若有收获,就点个赞吧
0 人点赞
