文章总结来自:
https://blog.csdn.net/weixin_42667608/article/details/111360617
什么是Redis Cluster?
Redis Cluster 是由多个主从架构组合在一起对外提供服务。Redis Cluster 是要求至少3个 master 节点,每个 master 下至少有一个 slave 节点。
节点负载均衡
这么多 master 节点,存储的时候,会落在哪个节点下呢?一般负载均衡算法,会算则哈希算法。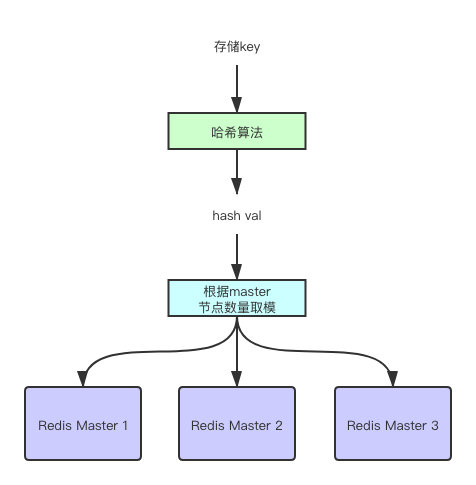
首先将一个key进行哈希算法,得到一个hash值,然后用哈希值对 master 节点数取模,由此可以将key负载均衡到每一个节点上,这就是简单的哈希算法。
Redis Cluster 没有采用上面的算法,为什么?
因为某一个 master 节点宕机后,master 的节点数量会发生变化,取模值就会变化。这样会导致 redis 中所有的缓存失效。
一致性哈希
简单哈希算法是对 master 节点数取模,而一致性哈希是对 2^32 取模,也就是值的范围在[0, 2^32 -1]。一致性哈希将取值范围抽象成一个圆环,使用CRC16算法计算出来的哈希值,会落在圆环的某个位置。
redis 实例也分布在圆环上,我们在圆环上按照顺时针的顺序找到第一个Redis实例,这样就完成了对key的节点分配。举个例子: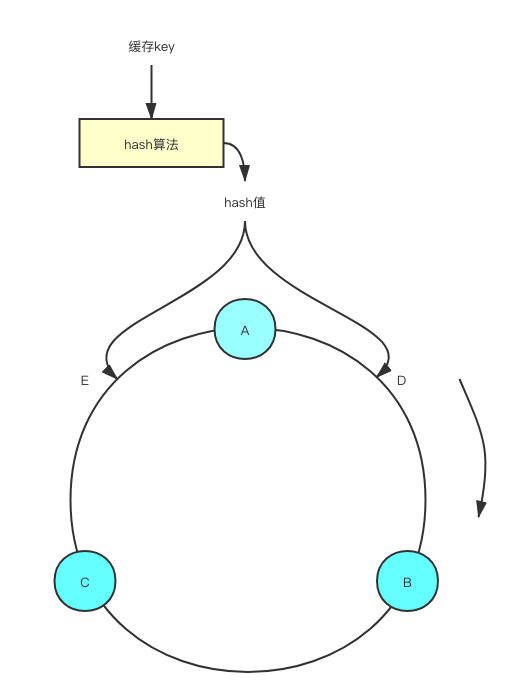
假设我们有A、B、C三个Redis实例按照如图所示的位置分布在圆环上,此时计算出来的hash值,取模之后位置落在了位置D,那么我们按照顺时针的顺序,就能够找到我们这个key应该分配的Redis实例B。同理如果我们计算出来位置在E,那么对应选择的Redis的实例就是A。
即使这个时候Redis实例B挂了,也不会影响到实例A和C的缓存。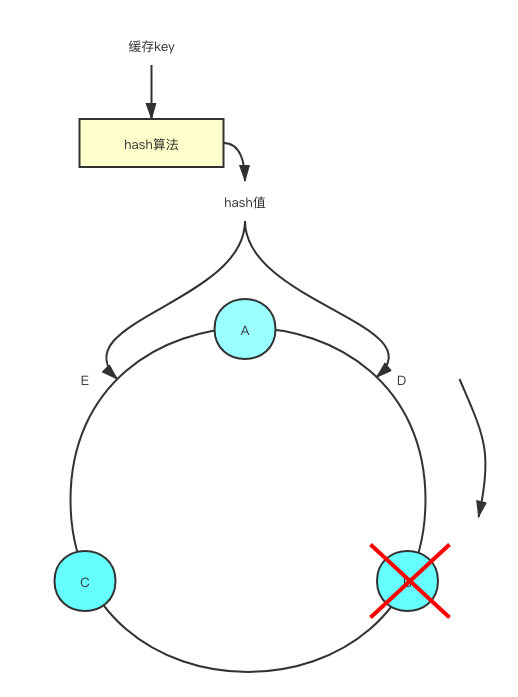
例如此时节点B挂了,那之前计算出来在位置D的key,此时会按照顺时针的顺序,找到节点C。相当于自动的把原来节点B的流量给转移到了节点C上去。而其他原本就在节点A和节点C的数据则完全不受影响。
这就是一致性哈希,能够在我们后续需要新增节点或者删除节点的时候,不影响其他节点的正常运行。
虚拟节点机制
但是一致性哈希也存在自身的小问题,例如当我们的Redis节点分布如下时,就有问题了。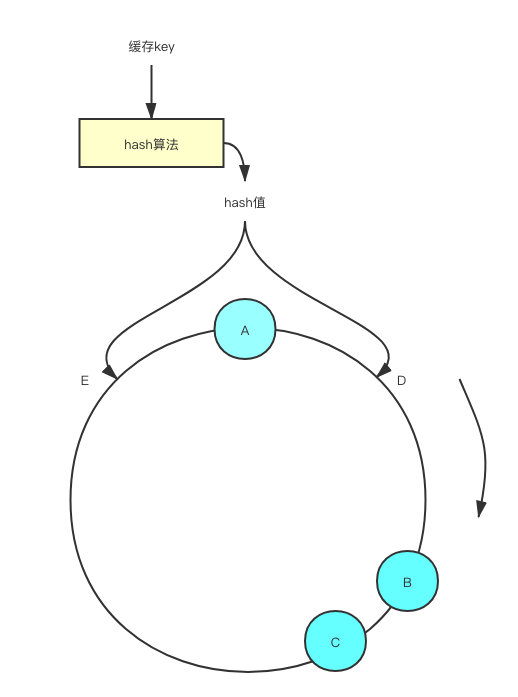
此时数据落在节点A上的概率明显是大于其他两个节点的,其次落在节点C上的概率最小。这样一来会导致整个集群的数据存储不平衡,AB节点压力较大,而C节点资源利用不充分。为了解决这个问题,一致性哈希算法引入了虚拟节点机制。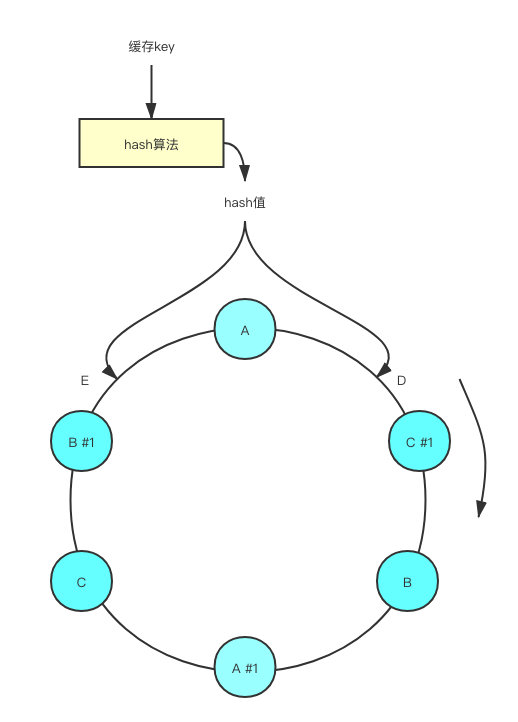
在圆环中,增加了对应节点的虚拟节点,然后完成了虚拟节点到真实节点的映射。假设现在计算得出了位置D,那么按照顺时针的顺序,我们找到的第一个节点就是C #1,最终数据实际还是会落在节点C上。
通过增加虚拟节点的方式,使ABC三个节点在圆环上的位置更加均匀,平均了落在每一个节点上的概率。这样一来就解决了上文提到的数据存储存在不均匀的问题了,这就是一致性哈希的虚拟节点机制。
Redis Cluster采用的什么算法
上面提到过,Redis Cluster采用的是类一致性哈希算法,之所以是类一致性哈希算法是因为它们实现的方式还略微有差别。
例如一致性哈希是对2^32取模,而Redis Cluster则是对2^14(也就是16384)取模。Redis Cluster将自己分成了16384个Slot(槽位)。通过CRC16算法计算出来的哈希值会跟16384取模,取模之后得到的值就是对应的槽位,然后每个Redis节点都会负责处理一部分的槽位,就像下表这样。
| 节点 | 处理槽位 |
|---|---|
| A | 0 - 5000 |
| B | 5001 - 10000 |
| C | 10001 - 16383 |
每个Redis实例会自己维护一份slot - Redis节点的映射关系,假设你在节点A上设置了某个key,但是这个key通过CRC16计算出来的槽位是由节点B维护的,那么就会提示你需要去节点B上进行操作。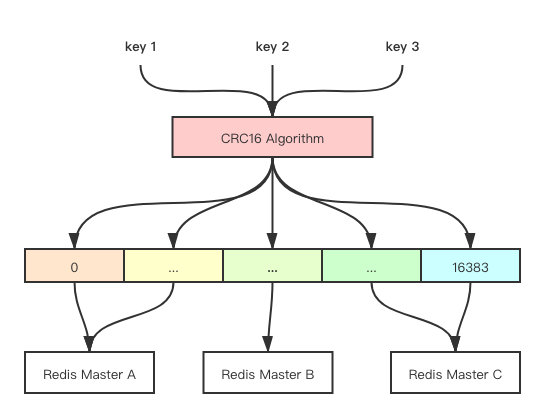
Redis Cluster如何做到高可用
不知道你思考过一个问题没,如果Redis Cluster中的某个master节点挂了,它是如何保证集群自身的高可用的?如果这个时候我们集群需要扩容节点,它该负责哪些槽位呢?我们一个一个问题的来看一下。
集群如何进行扩容
我们开篇聊过,Redis Cluster可以很方便的进行横向扩容,那当新的节点加入进来的时候,它是如何获取对应的slot的呢?
答案是通过reshard(重新分片)来实现。reshard可以将已经分配给某个节点的任意数量的slot迁移给另一个节点,在Redis内部是由redis-trib负责执行的。你可以理解为Redis其实已经封装好了所有的命令,而redis-trib则负责向获取slot的节点和被转移slot的节点发送命令来最终实现reshard。
假设我们需要向集群中加入一个D节点,而此时集群内已经有A、B、C三个节点了。
此时redis-trib会向A、B、C三个节点发送迁移出槽位的请求,同时向D节点发送准备导入槽位的请求,做好准备之后A、B、C这三个源节点就开始执行迁移,将对应的slot所对应的键值对迁移至目标节点D。最后redis-trib会向集群中所有主节点发送槽位的变更信息。
高可用及故障转移
简单来说,针对A节点,某一个节点认为A宕机了,那么此时是主观宕机。而如果集群内超过半数的节点认为A挂了, 那么此时A就会被标记为客观宕机。
一旦节点A被标记为了客观宕机,集群就会开始执行故障转移。其余正常运行的master节点会进行投票选举,从A节点的slave节点中选举出一个,将其切换成新的master对外提供服务。当某个slave获得了超过半数的master节点投票,就成功当选。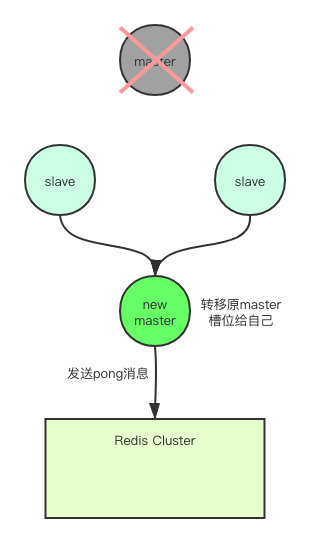
当选成功之后,新的 master 会执行slaveof no one来让自己停止复制A节点,使自己成为 master。然后将A节点所负责处理的 slot,全部转移给自己,然后就会向集群发PONG消息来广播自己的最新状态。
按照一致性哈希的思想,如果某个节点挂了,那么就会沿着那个圆环,按照顺时针的顺序找到遇到的第一个Redis实例。
而对于Redis Cluster,某个key它其实并不关心它最终要去到哪个节点,他只关心他最终落到哪个slot上,无论你节点怎么去迁移,最终还是只需要找到对应的slot,然后再找到slot关联的节点,最终就能够找到最终的Redis实例了。

若有收获,就点个赞吧
0 人点赞
