有调试过Spring的童靴都会发现,Spring的堆栈很绕(下图所示),createBean之后调getBean,getBean调完之后调doCreateBean,然后调完又会调回createBean,整个堆栈都是各种bean,实际上为啥会有这种情况呢,这个其实就是Spring最核心的地方就是依赖注入,通过递归的方式解析出整个依赖树,然后自底向上将所有依赖到的成员变量进行实例化,以防真正用时出现未注入导致的空指针等。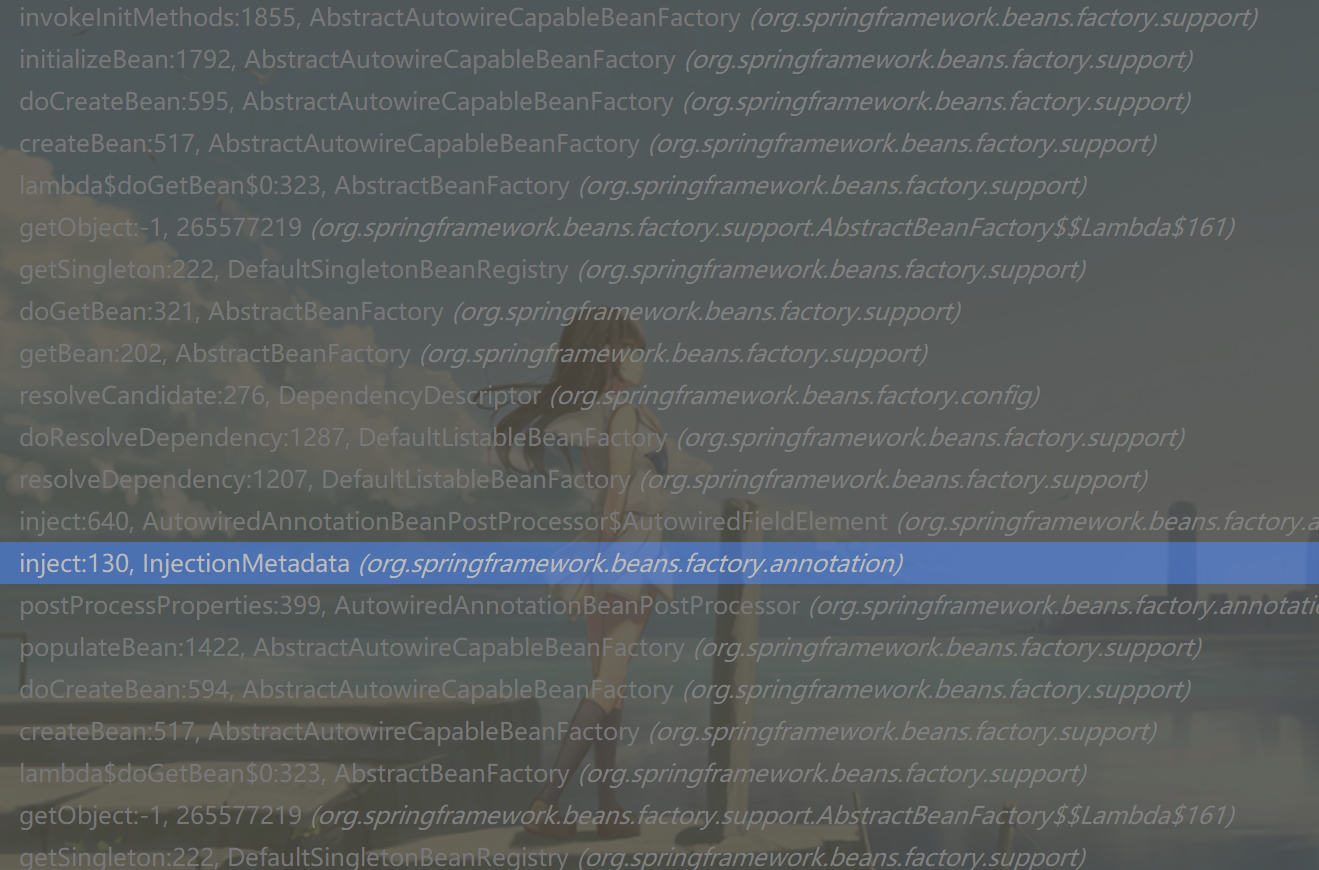
从上面的堆栈可以发现实例化bean的时候会有一个装饰过程,入口就是populateBean通过InstantiationAwareBeanPostProcessor后置器进行,具体查看AutowiredAnnotationBeanPostProcessor (核心实现)
AutowiredAnnotationBeanPostProcessor
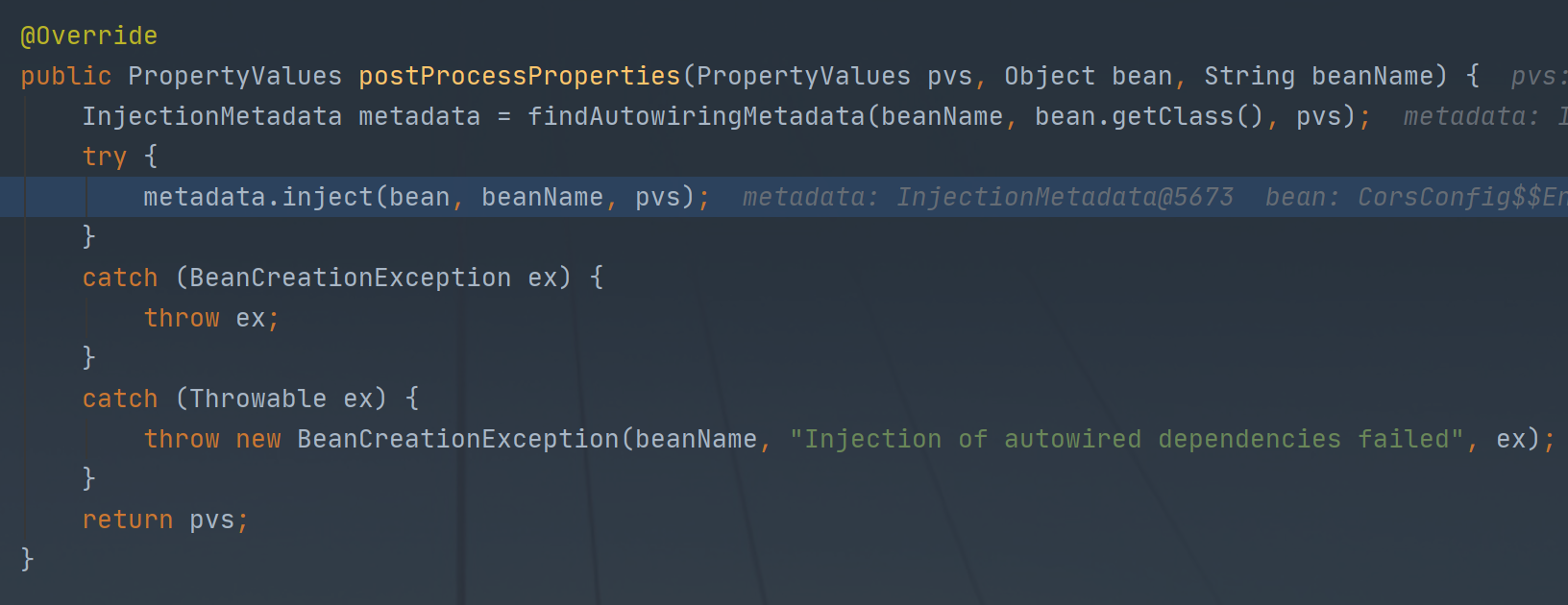
这里逻辑还是比较清晰的,就是找到有@Autowired、@Value、@Inject注解的成员变量或者方法,然后拼装成一个注入的元数据类型(InjectionMetadata),然后执行该类型的inject方法进行数据注入。
这里继续详细一点介绍整个查找过程(findAutowiringMetadata->buildAutowiringMetadata)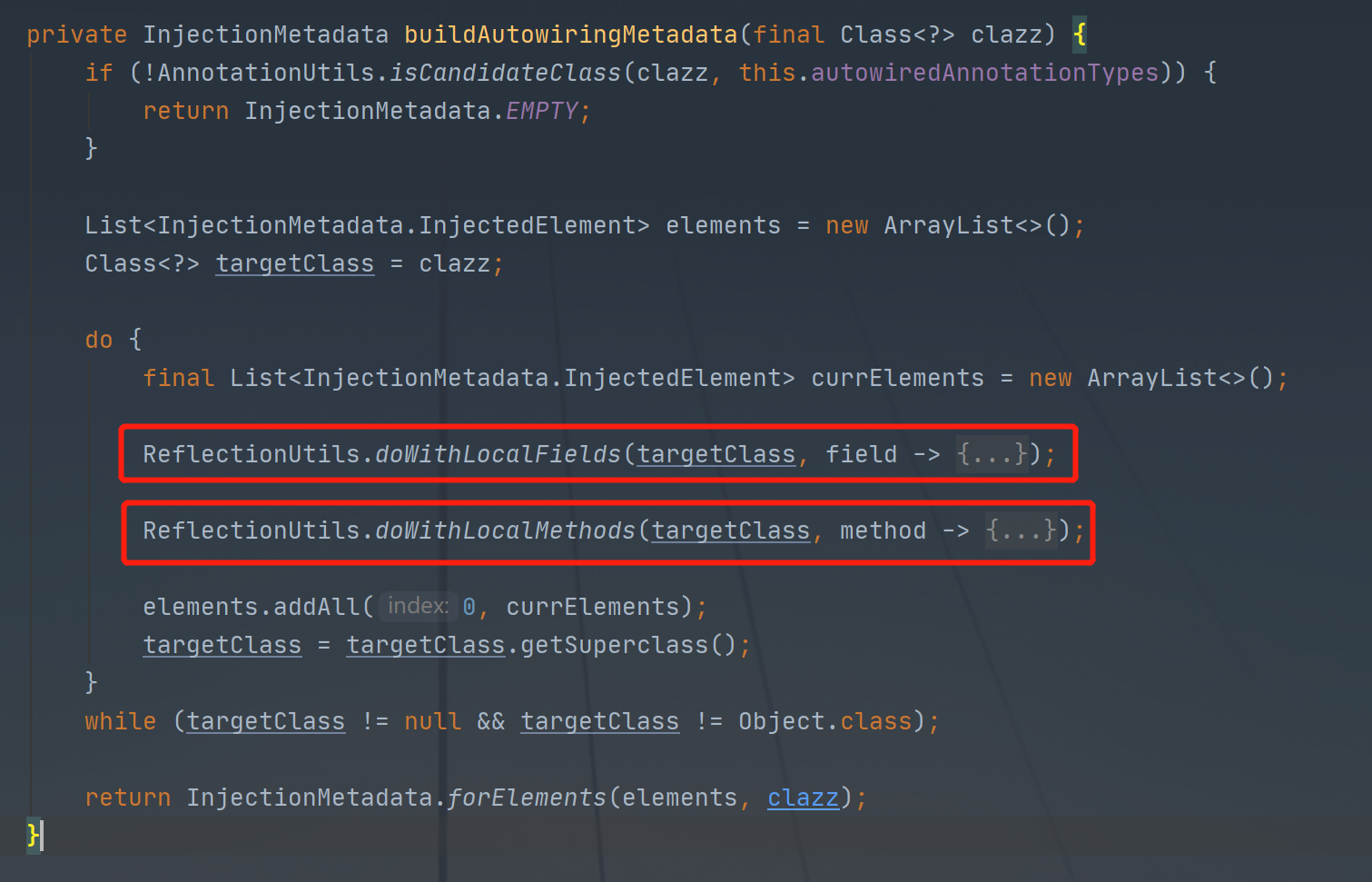
这里分成两种情况进行查找,一个是找成员变量(最常见),另一种是通过查方法如下图: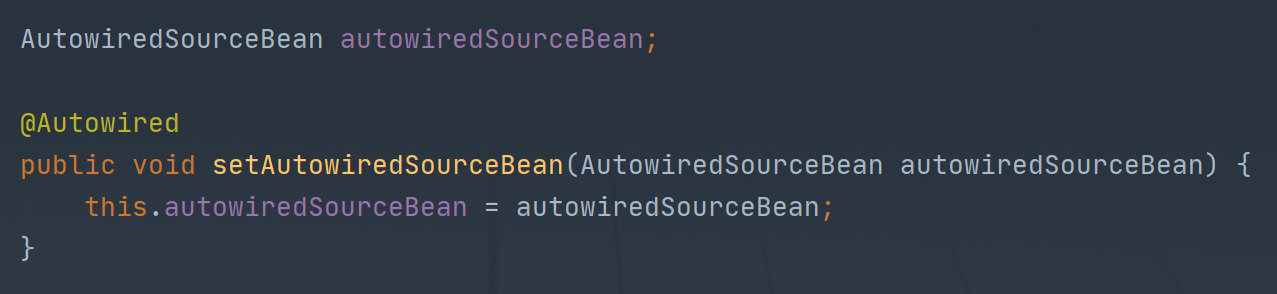
根据查找类型不同,生成两种不同的注入元数据类型(InjectionMetadata):
- AutowiredFieldElement
- AutowiredMethodElement
这两种不同的InjectionMetadata核心逻辑其实大同小异,区别最多就是赋值方式不一样,而依赖注入最主要的获取到合适的值进行注入这个核心逻辑是一样的。整个依赖解析是通过DefaultListableBeanFactory的resolveDependency方法进行的。我们看下doResolveDependency方法: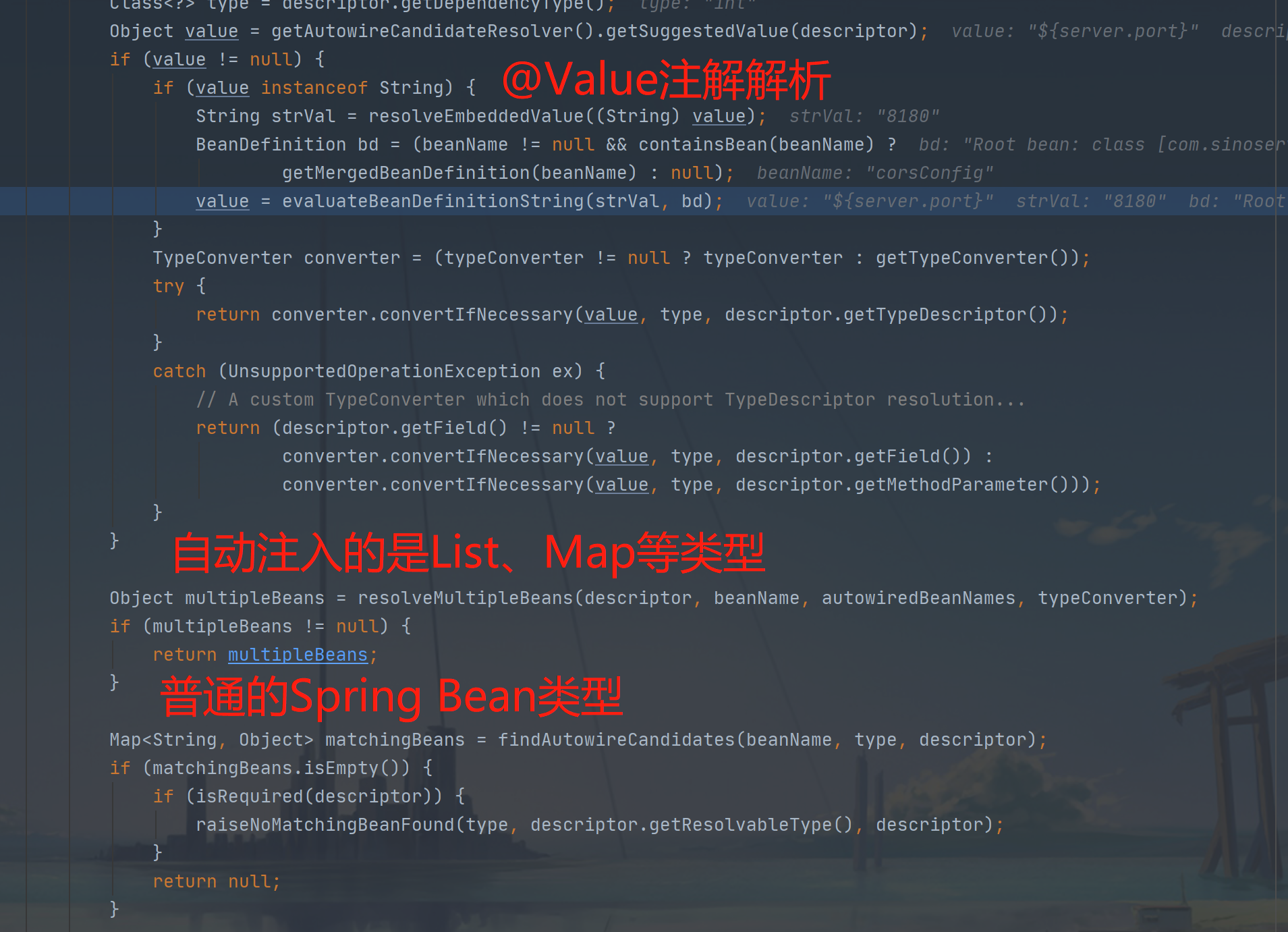
这里分了多种情况,实际上最核心的也就是两个:
- 解析出@Value注解的值
- 调用BeanFactory.getBean方法获取实例bean,若未找到则进行实例化,重复上面的依赖注入步骤。

关于BeanDefinition的一点理解(重要)
Spring 启动过程中会通过Scanner扫描出符合条件的类(查看相关文章),然后组装成一个BeanDefinition,注意此时并不会去实例化,而是等到我们上面的这个依赖注入的时候才进行初始化,依赖注入的时候会根据beanName获取对应的Bean实例,如果没有获取到则通过上面一开头讲的通过createBean等方法去实例化Bean然后返回给对应成员变量。

若有收获,就点个赞吧
0 人点赞
