- grep
- grep命令选项
- 文本处理工具sed
- 本章内容
- 处理文本的工具sed
- sed工具
- sed示例
- 高级编辑命令
- sed示例
- 练习
- AWK
- 本章内容
- awk介绍
- awk语言
- awk工作原理
- awk
- awk变量
- printf命令
- [.#]:第一个数字控制显示的宽度;第二个#表示小数点后精度,%3.1f
-:左对齐(默认右对齐)%-15s
+:显示数值的正负符号 %+d - printf示例
- 操作符
- awk PATTERN
- 示例
- awk action
- awk控制语句
- awk数组
- 去除重复的行号
- !/bin/bash
- awk脚本
- 向awk脚本传递参数
- 练习
- 模拟出ip放到web.log文件中
- 核心命令,监控到ip数量超过100丢到防火墙
- 如果防火墙中已经有该ip,则忽略
- 删除防火墙中某一条规则
- 先查看编号
- 删除要删除得那条
- grep 文本过滤(模式:pattern)工具
grep,egrep,fgrep (不支持正则表达式搜索)
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查;打印匹配到的行
模式:由正则表达式字符及文本字符所编写的过滤条件
- grep [OPTIONS] PATTERN [FILE…]
grep root /etc/passwd
grep “$USER” /etc/passwd
grep ‘$USER’ /etc/passwd
grep whoami /etc/passwd
grep命令选项
- —color=auto:对匹配到的文本着色显示
- -v:显示不被pattern匹配到的行
- -i:忽略字符大小写
- -n:显示匹配的行号
- -c:统计匹配的行数
- -o:仅显示匹配到的字符串
- -q:静默模式,不输出任何信息
- -A #:after,后#行
- -B #:before,前#行
- -e: 实现多个选项间的逻辑or关系
grep -e ‘cat’ -e ‘dog’ file
- -w:匹配整个单词
- -E:使用ERE
- -F:相当于fgrep,不支持正则表达式
- -f file:根据模式文件处理
$? 命令如果被正常执行,&?返回0 命令如果未被正常执行,&?返回非0
[root@chaitc ~]#echo $?
0
[root@chaitc ~]#pp
-bash: pp: command not found
[root@chaitc ~]#echo $?
127
[root@chaitc ~]#echo $?
0
取交集:
grep -f f1 f2
文本处理工具sed
本章内容
- Sed介绍
- Sed用法
-
处理文本的工具sed
Stream EDitor,行编辑器
- sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓存区中,称为“模式空间”( pattern space ),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。 如果没有使诸如’D’的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
- 功能:主要用来自动编辑一个或多个文件,简化对文件的反复操作,编写转换程序等
- 参考:http://www.gnu.org/software/sed/manual/sed.html
sed的工作原理
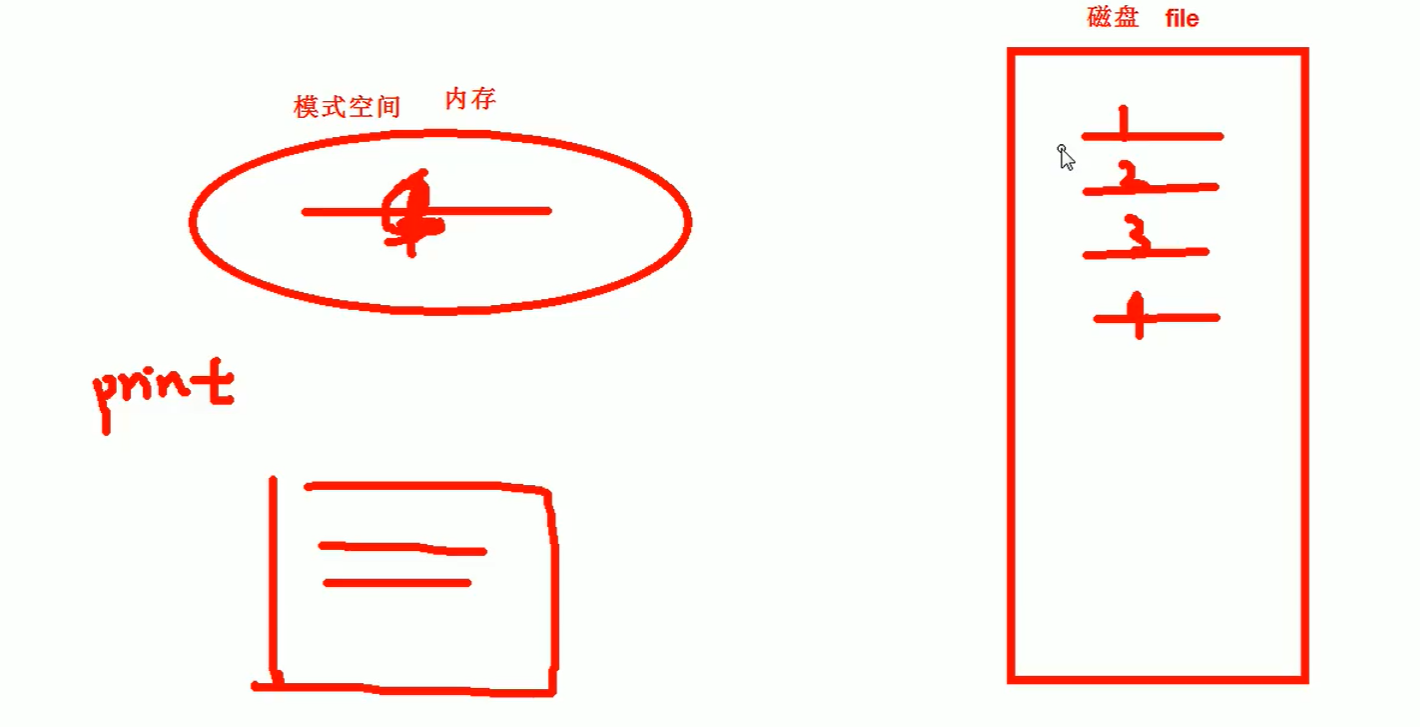
sed工具
- 用法:
sed [option]… ‘script’ inputfile…
- 常用选项:
-n:不输出模式空间内容到屏幕,即不自动打印
-e:多点编辑
-f:/PATH/SCRIPT_FILE:从指定文件中读取编辑脚本
-r:支持使用扩展正则表达式
-i.bak:备份文件并原处编辑
- script:
‘地址命令’
- 地址定界:
(1)不给地址:对全文进行处理
(2)单地址:
#:指定的行,$:最后一行
/pattern/:被所处模式所能够匹配到的每一行
(3)地址范围:
#,#
#,+#
/pat1/,/pat2/
(4)~:步进
1~2 奇数行
2~2 偶数行
- 编辑命令:
d:删除模式空间匹配的行,并立即启用下一轮循环
p:打印当前模式空间内容,追加到默认输出之后
a[]text:在指定行后面追加文本
支持使用\n实现多行追加
i[]text:在行前面插入文本
c[]text:替换行为单行或多行文本
w /path/somefile:保存模式匹配的行至指定文件
r /path/somefile:读取指定文件的文本至模式空间中
匹配到的行后
=:为模式空间的行打印行号
!:模式空间匹配行取反处理
- s///:查找替换,支持使用其他分隔符,s@@@,s###
- 替换标记:
g:行内全局替换
p:显示替换成功的行
w:/PATH/TO/SOMEFILE:将替换成功的行保存至文件中
给/etc/default/grub 下这一行GRUB_CMDLINE_LINUX=”crashkernel=auto spectre_v2=retpoline rhgb quiet”的引号前增加xyz:
方式1:
sed -r ‘s/(GRUB_CMDLINE_LINUX.)”$/\1 xyz”/‘ /etc/default/grub
方式2:
sed -r ‘/GRUB_CMDLINE_LINUX/s/“$/ xyz”/‘ /etc/default/grub
方式3:
sed -r ‘/GRUB_CMDLINE_LINUX/s/(.)”$/\1 xyz”/‘ /etc/default/grub
取出ipv4的IP:
方式1:
ifconfig ens33 |sed -r ‘2!d;s@(.inet )(.)( net.)@\2@’
方式2
ifconfig ens33 | sed -n ‘2p’ | sed -r ‘s/.inet (.) netmask./\1/‘
方式3:
ifconfig ens33 | sed -n ‘2p’| sed -r ‘s/.inet //‘ | sed -r ‘s/ netmask.//‘
方式4:
ifconfig ens33 | sed -n ‘2p’| sed -e ‘s/.inet //‘ -e ‘s/ netmask.//‘
取基名和文件名:
echo “/etc/sysconfig/network/“ | sed -r ‘s/(.\/)([^/]+\/?$)/\1/‘
echo “/etc/sysconfig/network/“ | sed -r ‘s/(.\/)([^/]+\/?$)/\2/‘
sed示例
sed ‘2p’ /etc/passwd
sed -n ‘2p’ /etc/passwd
sed -n ‘1,4p’ /etc/passwd
sed -n ‘/root/p’ /etc/passwd
sed -n ‘2,/root/p’ /etc/passwd 从第二行到下一个匹配到root的行
sed -n ‘/^$/=’ /etc/fstab 显示/etc/fstab的空行行号
sed -n -e ‘/^$/p’ -e ‘/^$/=’ /etc/fstab
sed ‘/root/a\chaitc’ /etc/passwd 行后添加一行chaitc
sed ‘/root/i\chaitc’ /etc/passwd 行前添加一行chaitc
sed ‘/root/c\chaitc’ /etc/passwd 代替匹配到的那行
sed ‘/^$/d’ file
sed ‘1,10d’ file
nl /etc/passwd |sed ‘2,5d’
nl /etc/passwd |sed ‘2a tea’
sed ‘s/test/mytest/g’ example
sed -n ‘s/root/&superman/p’ /etc/passwd 单词后
sed -n ‘s/root/superman&/p’ /etc/passwd 单词前
sed -e ‘s/dog/cat/‘ -e ‘s/hi/lo/‘ pets
sed -i.bak ‘s/dog/cat/g’ pets
高级编辑命令
- P:打印模式空间开端至\n内容,并追加到默认输出之前
- h:把模式空间中的内容覆盖至保持空间中
- H:把模式空间中的内容追加至保持空间中
- g:从保持空间取出数据覆盖至模式空间
- G:从保持空间取出内容追加至模式空间
- x:把模式空间的内容与保持空间中的内容进行互换
- n:读取匹配到的行的下一行覆盖至模式空间
- N:读取匹配到的行的下一行追加至模式空间
- d:删除模式空间中的行
D:如果模式空间包含换行符,则删除直到第一个换行符的模式空间中的文本,并不会读取新的输入行,而使用合成的模式空间重新启动循环。如果模式空间不包含换行符,则会像发出d命令那样启动正常的新循环
sed示例
取出偶数行 sed -n ‘n;p’ FILE
- 倒叙排序 sed ‘1!G;h;$!d’ FILE
- sed ‘N;D ‘ FILE
- sed ‘$!N;$!D’ FILE
- sed ‘$!d’ FILE
- sed ‘G’ FILE
- sed ‘g’ FILE
- sed ‘/^ $/d;G’ FILE
- sed ‘n;d’ FILE
- sed -n ‘1!G;h;$p’ FILE
练习
1、删除centos7系统/etc/grub2.cfg文件中所有以空白开头的行行首的空白字符
2、删除/etc/fstab文件中所有以#开头,后面至少跟一个空白字符的行的行首的#和空白字符
3、在centos6系统/root/install.log每一行行首增加#号
7、统计centos安装光盘中Package目录下的所有rpm文件以.分割倒数第二个字段的重复次数
8、统计/etc/init.d/functions文件中每个单词的出现次数,并排序(用grep和sed两种方式分别实现)


9、
AWK
本章内容
- awk介绍
- awk基本用法
- awk变量
- awk格式化
- awk操作符
- awk循环
- awk数组
- awk函数
-
awk介绍
awk:Aho,Weinberger,Kernighan,报告生成器,格式化文本输出
- 有多种版本:New awk(nawk),GNU awk (gawk)
- gawk:模式扫描和处理语言
- 基本用法:
awk [option] ‘program’ var=value file…
awk [option] -f programfile var=value file…
awk [options] ‘BEGIN{action;… } pattern{action;… }END{action;… }’ file…
awk程序通常由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块,共3部分组成
program通常是放在单引号或双引号中
- 选项:
-F 指明输入时用到的字段分隔符
-v var=value:自定义变量
awk语言
- 基本格式:awk [option] ‘program’ file…
- program:pattern{action statements;…}
- pattern和action:
- pattern部分决定动作语句何时触发及触发事件
BEGIN,END
- action statements对数据进行处理,放在{}内指明
print,printf
分隔符、域和记录
第一步:执行BEGIN{action;…}语句块中的语句
- 第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{action;…}语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
- 第三步:当读至输入流末尾时,执行END{action;…}语句块
- BEGIN语句块在awk开始从输入流中读取行被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
- END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果,这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
awk
print格式:print item1,item2,…
- 要点:
(1)逗号分隔符
(2)输出的各item可以字符串,也可以是数值;当前记录的字段、变量或awk的表达式
(3)如省略item,相当于print $0
- 示例:
awk ‘{print “hello,awk”}’
awk -F: ‘{print}’ /etc/passwd
awk -F: ‘{print “wang” }’ /etc/passwd
awk -F: ‘{print $1}’ /etc/passwd
awk -F: ‘{print $0}’ /etc/passwd
awk -F: ‘{print $1” \t” $3}’ /etc/passwd
tail -3 /etc/fstab | awk ‘{print $2,$4}’
awk变量
- 变量:内置和自定义变量
FS:输入字段分隔符,默认为空白字符
awk -v FS=':' '{print $1,FS,$3}' /etc/passwdawk -F: '{print $1,$3,$7}' /etc/passwd
OFS:输出字段间隔符,默认为空白字符
awk -v FS=':' -v OFS=':' '{print $1,$3,$7}' /etc/passwd
- RS:输入记录分隔符,指定输入时的换行符
awk -v RS='' '{print $1,$2}' /etc/passwd
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin
- ORS:输出记录分隔符,输出时用指定符号代替换行符
awk -v RS='' -v ORS='###' '{print $1}' /etc/passwd
root:x:0:0:root:/root:/bin/bash###[root@Centos6 ~]#awk -v RS='' -v ORS='###' '{print $1,$2}' /etc/passwd
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin###[root@Centos6 ~]#
- NF:字段数量
awk -F: '{print NF}' /etc/passwdawk -F':' '{print $(NF-1)}' /etc/passwd
- NR:记录号
awk '{print NR}' /etc/fstab ;awk END'{print NR}' /etc/fstab

printf命令
- 格式化输出:printf “FORMAT”,item1,item2,…
- 必须指定FORMAT
- 不会自动换行,需要显式给出换行控制符,\n
- FORMAT中需要分别为后面每个item指定格式符
- 格式符:与item一一对应
%c:显示字符的ASCII码
%d,%i:显示十进制整数
%e,%E:显示科学计数法数值
%f:显示为浮点数
%g,%G:以科学计数法或浮点形式显示数值
%s:显示字符串
%u:无符号整数
%%:显示%自身
- 修饰符:
[.#]:第一个数字控制显示的宽度;第二个#表示小数点后精度,%3.1f
-:左对齐(默认右对齐)%-15s
+:显示数值的正负符号 %+d
printf示例

操作符



awk PATTERN


示例

awk action

awk控制语句

awk控制语句
条件判断if-else
语法:
if(condition){statement;...}[else statement]if(condition1){statement1}else if(condition2){statement2}else{statement3}
使用场景:对awk取得的整行或某个字段做条件判断
范列:
awk -F: '{if($3>=1000)print $1,$3}' /etc/passwdawk -F: '{if($NF == "/bin/bash"){print $1}}' /etc/passwdawk '{if(NF > 5)print $0}' /etc/fstabawk -F: '{if($3 >= 1000){printf "Common user:%s\n",$1} \else{printf "root or Systemuser:%s\n",$1}}' /etc/passwdawk -F: '{if($3 >= 1000) printf "Common user:%s\n",$1; \else printf "root or Systemuser:%s\n",$1}' /etc/passwddf -h | awk -F% '/^\/dev\/sd/{print $1}' | awk '$NF>80{print $1,$NF}'df -h | awk -F'[[:space:]]+|%' '/^\/dev\/sd/{if($5 > 80) print $1,$5}'awk 'BEGIN{test = 100; if(test >= 90)print "very good";\else if(test > 60)print "good";else print "no pass"}'
switch语句
语法:
switch(expression){case VALUE1 or /REGEXP/:statement1; \case VALUE2 or /REGEXP2/:statement2;...;default:statementn}
循环while
- 语法:
while(condition){statement;…}
- 条件”真”,进入循环;条件”假”,退出循环
- 使用场景:
对一行内的多个字段逐一类似处理时使用
对数组中各个元素逐一处理时使用
- 示例:
awk '/^[[:space:]]*linux16/{i=1;while(i <= NF){print $i,length($i);i++}}' /etc/grub2.cfgawk '/^[[:space:]]*linux16/{i=1;while(i <= NF){if(length($i) > 10){print $i,length($i)} i++}}' /etc/grub2.cfgawk 'BEGIN{total=0;i=1;while(i<=100){total += i;i++}print total}'
awk '/^[[:space:]]*linux16/{i=1;while(i <= NF){print $i,length($i);i++}}' /etc/grub2.cfglinux16 7/vmlinuz-3.10.0-1062.el7.x86_64 31root=UUID=79ebf19f-ea48-4cee-af62-79e933f4b058 46ro 2crashkernel=auto 16spectre_v2=retpoline 20rhgb 4quiet 5LANG=en_US.UTF-8 16linux16 7/vmlinuz-0-rescue-eca42489f56743429b149bb5924fcb43 50root=UUID=79ebf19f-ea48-4cee-af62-79e933f4b058 46ro 2crashkernel=auto 16spectre_v2=retpoline 20rhgb 4quiet 5awk '/^[[:space:]]*linux16/{i=1;while(i <= NF){if(length($i) > 10){print $i,length($i)} i++}}' /etc/grub2.cfg/vmlinuz-3.10.0-1062.el7.x86_64 31root=UUID=79ebf19f-ea48-4cee-af62-79e933f4b058 46crashkernel=auto 16spectre_v2=retpoline 20LANG=en_US.UTF-8 16/vmlinuz-0-rescue-eca42489f56743429b149bb5924fcb43 50root=UUID=79ebf19f-ea48-4cee-af62-79e933f4b058 46crashkernel=auto 16spectre_v2=retpoline 20awk 'BEGIN{total=0;i=1;while(i<=100){total += i;i++}print total}'
循环do-while
- 语法:do {statement;…}while(condition)
- 意义:无论真假,至少执行一次循环体
- 示例:
awk 'BEGIN{total=0;i=1;do{total += i;i++}while(i<=100)print total}'
循环for
- 语法:
for(expr1;expr2;expr3){statement;...}
- 常见用法:
for(variable assignment;condition;iteration process)
{for-body}
- 特殊用法:能够遍历数组中的元素
语法:for(var in array){for-body}
- 示例:
awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++){print $i,length($i)}}' /etc/grub2.cfgawk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++){if(length($i)>=10){print $i,length($i)}}}' /etc/grub2.cfg
[root@centos7 ~]#awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++){print $i,length($i)}}' /etc/grub2.cfglinux16 7/vmlinuz-3.10.0-1062.el7.x86_64 31root=UUID=79ebf19f-ea48-4cee-af62-79e933f4b058 46ro 2crashkernel=auto 16spectre_v2=retpoline 20rhgb 4quiet 5LANG=en_US.UTF-8 16linux16 7/vmlinuz-0-rescue-eca42489f56743429b149bb5924fcb43 50root=UUID=79ebf19f-ea48-4cee-af62-79e933f4b058 46ro 2crashkernel=auto 16spectre_v2=retpoline 20rhgb 4quiet 5[root@centos7 ~]#awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++){if(length($i)>=10){print $i,length($i)}}}' /etc/grub2.cfg/vmlinuz-3.10.0-1062.el7.x86_64 31root=UUID=79ebf19f-ea48-4cee-af62-79e933f4b058 46crashkernel=auto 16spectre_v2=retpoline 20LANG=en_US.UTF-8 16/vmlinuz-0-rescue-eca42489f56743429b149bb5924fcb43 50root=UUID=79ebf19f-ea48-4cee-af62-79e933f4b058 46crashkernel=auto 16spectre_v2=retpoline 20awk 'BEGIN{for(i=1;i<=100;i++){total+=i};print total}'5050
性能比较(从1加到100万)
time ( for ((total=0,i=1;i<=1000000;i++)) do let total+=i;done; echo $total )time awk 'BEGIN{for(i=1;i<=1000000;i++){total+=i};print total}'time echo {1..1000000} | tr ' ' + | bctime seq -s+ 1000000 | bc
#第一名:time awk 'BEGIN{for(i=1;i<=1000000;i++){total+=i};print total}'500000500000real 0m0.058suser 0m0.056ssys 0m0.001s#第二名:time seq -s+ 1000000 | bc500000500000real 0m0.252suser 0m0.243ssys 0m0.013s#第三名:time echo {1..1000000} | tr ' ' + | bc500000500000real 0m0.818suser 0m0.795ssys 0m0.103s#第四名:time ( for ((total=0,i=1;i<=1000000;i++)) do let total+=i;done; echo $total )500000500000real 0m5.143suser 0m4.636ssys 0m0.504s极限测试:[root@centos7 ~]#time awk 'BEGIN{for(i=1;i<=100000000;i++){total+=i};print total}'5000000050000000real 0m5.237suser 0m5.234ssys 0m0.000s[root@centos7 ~]#time ( for ((total=0,i=1;i<=100000000;i++)) do let total+=i;done; echo $total )5000000050000000real 10m55.077suser 9m52.678ssys 1m1.966s[root@centos7 ~]#echo '(10*60+55)/5' |bc131# 使用awk和shell脚本的效率相差131倍
continue和break
格式:continue [n]break [n]
范列:
[root@centos7 ~]#awk 'BEGIN{total=0; \for(i=1;i<=100;i++) \{if(i%2 == 1){continue}total += i};print total}'2550[root@centos7 ~]#awk 'BEGIN{total=0; \for(i=1;i<=100;i++) \{if(i == 50){break}total += i};print total}'1225
next
next可以提前结束对本行处理而直接进入下一行处理(awk自身循环)awk -F: '{if($3%2 != 0) next; print $1,$3}' /etc/passwd
awk数组
- 关联数组:array[index-expression]
- index-expression:
(1)可使用任意字符串;字符串要使用双引号括起来
(2)如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并其值初始化为”空串”
若要判断数组是否存在某元素,要使用”index in array”格式进行遍历
示例: ```bash awk ‘BEGIN{weekdays[“mon”]=”Mondy”; \ weekdays[“tue”]=”Tuesday”;print weekdays[“tue”]}’
去除重复的行号
awk ‘!arr[$0]++’ abcd.txt
[root@centos7 ~]#cat > abcd.txt aaa bbb aaa bbb abc 123 123 abc abc 123 321 3321 3212 123 213 123 [root@centos7 ~]#awk ‘!arr[$0]++’ abcd.txt aaa bbb abc 123 123 abc 321 3321 3212 123 213 [root@centos7 ~]#awk ‘{!arr[$0]++;print $0,arr[$0]}’ abcd.txt aaa 1 bbb 1 aaa 2 bbb 2 abc 123 1 123 abc 1 abc 123 2 321 1 3321 1 3212 1 123 1 213 1 123 2
- 注意:var会遍历array的每个索引- 示例:判断数组索引是否存在```bash[root@centos7 ~]#awk 'BEGIN{array["i"]="x"; \array["j"]="y";print "i" in array, "y" in array }'1 0[root@centos7 ~]#awk 'BEGIN{array["i"]="x"; \array["j"]="y";if("i" in array) print "存在" }'存在[root@centos7 ~]#awk 'BEGIN{array["i"]="x"; \array["j"]="y";if("y" in array) print "存在"; \else print "不存在" }'不存在
- 若要遍历数组中的每个元素,要使用for循环
for(var in array) {for-body}
- 示例: ```bash awk -F: ‘{user[$1]=$3} \ END{for(i in user) print “username is:”i, \ “userid is:”user[i]}’ /etc/passwd
awk ‘BEGIN{weekdays[“mon”]=”Mondy”; \ weekdays[“tue”]=”Tuesday”; \ for(i in weekdays){print weekdays[i]}}’
awk ‘BEGIN { \
a[“x”] = “welecome” b[“y”] = “to” a[“y”] = “to” a[“z”] = “ctc_gongzuoshi” for (i in a) { print i,a[i] } }’ x welecome y to z ctc_gongzuoshi ```
- 示例:打印连接状态出现次数 ```bash ss -nta | sed -nr ‘1!s/^([^0-9]+) .*/\1/p’ \ |sort | uniq -c | awk ‘{print $2,$1}’ ESTAB 1 LISTEN 11
ss -tan | awk ‘NR!=1{state[$1]++} \ END{for (i in state){print i,state[i]}}’ LISTEN 11 ESTAB 1
netstat -tan | awk ‘/^tcp/{state[$NF]++}END{for (i in state) {print i,state[i]}}’ LISTEN 11 ESTABLISHED 1
- 示例:获取访问日志中最多的ip地址```bashcat > access_log172.192.10.1 fsfdfdddfdssssss172.192.12.3 sfddddddddddd172.192.10.1 sfdfsdfawk '{ip[$1]++}END{for (i in ip){print i,ip[i]}}' \access_log | sort -k2 -nr | head -1172.192.10.1 2
范列:多维数组
awk 'BEGIN{> array[1][1] = 11> array[1][2] = 12> array[1][3] = 13> array[2][1] = 21> array[2][2] = 22> array[2][3] = 23> for (i in array)> for (j in array[i])> print array[i][j]> }'111213212223
把访问量大于 某个值的ip丢到防火墙 ```bash cat 083_deny_dos.sh
!/bin/bash
for i in
awk '{ip[$1]++}END{for (i in ip){if (ip[i] > 39000) print i}}' access_log;do iptables -A INPUT -s $i -j REJECT
iptables -vnL
方式2: netstat -tn | awk ‘/^tcp>/{split($5,ip,”:”);count[ip[1]]++} \ END{for(i in count){if(count[i]>=3){ \ system(“iptables -A INPUT -s “i” -j REJECT”)}}}’
<a name="dSdSm"></a># awk函数- 数值处理:rand():返回0和1之间一个随机数<br />srand():配合rand()函数,生成随机数的种子<br />int():返回整数<br />范列:<br />`awk 'BEGIN{srand();for (i=0;i<10;i++) print int(rand()*100)}'`- 字符串处理:length([s]):返回指定字符串的长度<br />sub(r,s,[t]):对t字符串进行搜索r表示的模式匹配的内容,并将**第一个匹配**的内容替换为s<br />范列:<br />`echo "2008:08:08 08:08:08" | awk 'sub(/:/,"-",$1)'`<br />`echo "2008:08:08 08:08:08" | awk '{sub(/:/,"-",$1);print $0}'`<br />gsub(r,s,[t]):对t字符串进行搜索r表示的模式匹配的内容,并**全部替换**为s所表示的内容<br />范列:<br />`echo "2008:08:08 08:08:08" | awk 'gsub(/:/,"-",$0)'`<br />`echo "2008:08:08 08:08:08" | awk '{gsub(/:/,"-",$0);print $0}'`<br />split(s,array,[r]):以r为分隔符,切割字符串s,并将切割后的结果保存至array所表示的数组中,第一个索引值为1,第2个索引值为2,...<br />`netstat -tan | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++}END{for(i in count){print i,count[i]}}'`- system函数:可以awk中调用shell命令空格是awk中字符串连接符,如果system中需要使用awk中的变量可以使用空格分割,或者说除了awk的变量外一律用""引用起来。<br />`awk 'BEGIN{system("hostname")}'`<br />`awk 'BEGIN{system("rm -rf /data/*")}' `<br />`awk 'BEGIN{ score=100; system("echo your score is: " score) }' ` <br />your score is: 100- 统计一篇文章中每个单词出现的次数`awk '{for(i=1;i<=NF;i++){word[$i]++}}END{for(j in word){print j,word[j]}}' /etc/rc.sysinit`<br />- 自定义函数格式:<br />function name (parameter,parameter,...) {<br />statements<br />return expression<br />}- 示例:```bash[root@centos7 ~]# awk -v a=10 -v b=12 -f fuc.awk12[root@centos7 ~]# cat fuc.awkfunction max(x,y) {x>y?var=x:var=yreturn var}BEGIN{print max(a,b)}[root@centos7 ~]# awk -F: -f passwd.awk /etc/passwdnfsnobody 65534chaitc 1000[root@centos7 ~]# cat passwd.awk{if($3>=1000)print $1,$3}
awk脚本
- 将awk程序写成脚本,直接调用或执行
示例:
[root@centos7 ~]# cat func2.awk#!/bin/awk -f# this is a awk script{if($3>=1000){print $1,$3}}[root@centos7 ~]# chmod +x func2.awk[root@centos7 ~]# ./func2.awk -F: /etc/passwdnfsnobody 65534chaitc 1000
向awk脚本传递参数
格式:
awkfile var=value var2=value2… Inputfile
- 注意:在BEGIN过程中不可用。直到首行输入完成以后,变量才可用。
可以通过-v参数,让awk在执行BEGIN之前得到变量的值。命令行中每一个指定的变量都需要一个-v参数
- 示例:
[root@centos7 ~]# cat test.awk#!/bin/awk -f{if($3 >= min && $3 <= max){print $1,$3}}[root@centos7 ~]# chmod +x test.awk[root@centos7 ~]# ./test.awk -F: min=500 max=1000 /etc/passwdpolkitd 999libstoragemgmt 998colord 997saslauth 996setroubleshoot 995gluster 994chrony 993unbound 992geoclue 991saned 990gnome-initial-setup 989chaitc 1000
练习
1、文件ip_list如下格式,请提取”.mageedu.com”前面的主机名部分并写入到回到该文件中
1 www.magedu.com
2 blog.magedu.com
3 study.magedu.com
4 linux.magedu.com
…
999 ctc.magedu.com
2、统计/etc/fstab文件中每个文件系统类型出现的次数[root@centos7 ~]# cat ip_list.txt1 www.magedu.com2 blog.magedu.com3 study.magedu.com4 linux.magedu.com5 ctc.magedu.com[root@centos7 ~]# awk -F"[ .]" '{print $2}' ip_list.txt \>> ip_list.txt[root@centos7 ~]# cat ip_list.txt1 www.magedu.com2 blog.magedu.com3 study.magedu.com4 linux.magedu.com5 ctc.magedu.comwwwblogstudylinuxctc
3、统计/etc/fstab文件中每个单词出现的次数awk '/^UUID/{fs[$3]++}END{for(i in fs){print i,fs[i]}}' /etc/fstabswap 1xfs 3
awk '{for(i=1;i<=NF;i++){words[$i]++}}END{for(j in words){print j,words[j]}}' /etc/fstab
4、提取出字符串Yd$C@M05MB%9&Bdhq+YVixp3vpw中所有数字echo 'Yd$C@M05MB%9&Bdhq+YVixp3vpw' | grep -o '[0-9]'echo 'Yd$C@M05MB%9&Bdhq+YVixp3vpw' | awk '{gsub(/[^0-9]/,"",$0);print $0}'
0593
5、有一文件记录了1-100000之间随机的整数共5000个,存储的格式100,50,35,89…请取出其中最大和最小的整数
6、解决DOS攻击生产案例:根据web日志或者网络连接数,监控当某个IP并发连接数或短时内PV达到100,即调用防火墙命令封掉对应得ip,监控频率每隔5分钟。防火墙命令为:iptables -A INPUT -s IP -j REJECT ```bashawk 'BEGIN{srand();for (i=0;i<5000;i++) \print int(rand()*100000)}' | tr '\n' ',' > rand_5000.txtcat rand_5000.txtawk -F, '{min=$1;max=$1;for(i=2;i<NF-1;i++) \{if(min>$i)min=$i;if(max<$i)max=$i}; \> print "min is:"min,",max is:"max}' rand_5000.txtmin is:4 ,max is:99981
模拟出ip放到web.log文件中
for i in {1..300};do echo ‘192.168.123.123’ \web.log;sleep 1; done wc -l web.log for((i=1;i<300;i++)) do echo '192.168.123.124' >> web.log; \ sleep 1; done
核心命令,监控到ip数量超过100丢到防火墙
cat web.log | awk ‘{count[$0]++} \ END{for(i in count){if(count[i]>=100) \ {system(“iptables -A INPUT -s “i” -j REJECT”)}}}’
如果防火墙中已经有该ip,则忽略
cat web.log | awk ‘{count[$0]++} \ END{for(i in count){if(count[i]>=100) \ {system(“iptables -vnL | grep “i” > /dev/null \ || iptables -A INPUT -s “i” -j REJECT”)}}}’
删除防火墙中某一条规则
先查看编号
iptables -L -n —line-number
删除要删除得那条
iptables -D INPUT 5
<br />7、将以下文件内容中FQDN取出并根据其进行计数从高到低排序<br />[http://mail.magedu.com/index.html](http://mail.magedu.com/index.html)<br />[http://www.magedu.com/index.html](http://www.magedu.com/index.html)<br />[http://linux.magedu.com/index.html](http://linux.magedu.com/index.html)<br />[http://study.magedu.com/image.html](http://study.magedu.com/image.html)<br />[http://mail.magedu.com/2345.jpg](http://mail.magedu.com/2345.jpg)<br />[http://blog.magedu.com/logo.png](http://blog.magedu.com/logo.png)<br />[http://www.magedu.com/index.html](http://www.magedu.com/index.html)<br />[http://mail.magedu.com/index.html](http://mail.magedu.com/index.html)<br />[http://www.magedu.com/index.html](http://www.magedu.com/index.html)<br />[http://linux.magedu.com/index.html](http://linux.magedu.com/index.html)<br />[http://study.magedu.com/image.html](http://study.magedu.com/image.html)<br />[http://mail.magedu.com/2345.jpg](http://mail.magedu.com/2345.jpg)<br />[http://blog.magedu.com/logo.png](http://blog.magedu.com/logo.png)<br />[http://www.magedu.com/index.html](http://www.magedu.com/index.html)```bash[root@centos7 ~]#cat url.loghttp://mail.magedu.com/index.htmlhttp://www.magedu.com/index.htmlhttp://linux.magedu.com/index.htmlhttp://study.magedu.com/image.htmlhttp://mail.magedu.com/2345.jpghttp://blog.magedu.com/logo.pnghttp://www.magedu.com/index.htmlhttp://mail.magedu.com/index.htmlhttp://www.magedu.com/index.htmlhttp://linux.magedu.com/index.htmlhttp://study.magedu.com/image.htmlhttp://mail.magedu.com/2345.jpghttp://blog.magedu.com/logo.pnghttp://www.magedu.com/index.html[root@centos7 ~]#awk -F/ '{print $3}' url.logmail.magedu.comwww.magedu.comlinux.magedu.comstudy.magedu.commail.magedu.comblog.magedu.comwww.magedu.commail.magedu.comwww.magedu.comlinux.magedu.comstudy.magedu.commail.magedu.comblog.magedu.comwww.magedu.com[root@centos7 ~]#awk -F/ '{url[$3]++} \END{for(i in url){print url[i],i}}' url.log | sort -nr4 www.magedu.com4 mail.magedu.com2 study.magedu.com2 linux.magedu.com2 blog.magedu.com
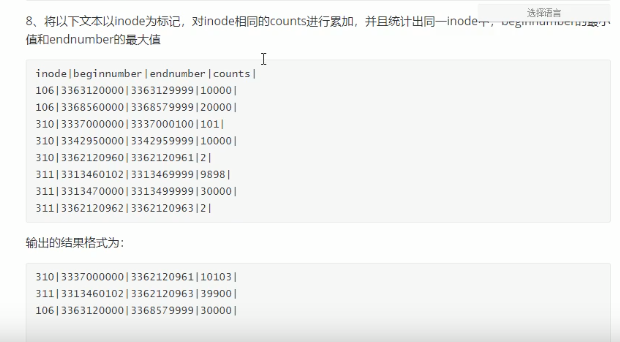
8、将以下文本以inode为标记,对inode相同的counts进行累加,并且统计出同inode中beginnumber的最小值和endnumber 的最大值
inode | beginnumber | endnumber | counts |
106 | 3363120000 | 3363129999 | 10000 |
106 | 3368560000 | 3368579999 | 20000 |
310 | 3337000000 | 3337000100 | 101 |
310 | 3342950000 | 3342959999 | 10000 |
310 | 3362120960 | 3362120961 | 21 |
311 | 3313460102 | 3313469999 | 9898 |
311 | 3313470000 | 3313499999 | 30000 |
311 | 3362120962 | 3362120963 | 2 |
输出的结果格式为:
awk -F'|' '/^[^[:alpha:]]/{if(NR=1){beginnumber[$1]=$2;endnumber[$1]=$3};if(beginnumber[$1]>$2){beginnumber[$1]=$2};if(endnumber[$1]<$3){endnumber[$1]=$3}counts[$1]+=$4;}END{for(i in counts){print i,beginnumber[i],endnumber[i],counts[i]}}' inode.txt | tr -s ' ' '|'106|3368560000|3368579999|30000310|3362120960|3362120961|10122311|3362120962|3362120963|39900

若有收获,就点个赞吧
0 人点赞
