class JdItem(scrapy.Item):bookName = scrapy.Field()sellPrice = scrapy.Field()authors = scrapy.Field()coverUrl = scrapy.Field()bookId = scrapy.Field()definePrice = scrapy.Field()publisher = scrapy.Field()discount = scrapy.Field()
import scrapyimport jsonfrom jd.items import JdItemclass JdShopSpider(scrapy.Spider):name = 'jd_shop'# allowed_domains = ['jd.com']# start_urls = ['http://jd.com/']def start_requests(self):url = 'https://gw-e.jd.com/client.action?callback=func&body=%7B%22moduleType%22%3A1%2C%22page%22%3A4%2C%22pageSize%22%3A20%2C%22scopeType%22%3A1%7D&functionId=bookRank&client=e.jd.com&_=1650724495119'yield scrapy.Request(url=url,callback=self.parse)def parse(self, response):data = response.text.lstrip('func(')data = data.rstrip(')')all_books = json.loads(data)['data']['books']for book in all_books:item = JdItem()item['bookName'] = book['bookName']item['sellPrice'] = book['sellPrice']item['authors'] = book['authors']item['coverUrl'] = book['coverUrl']item['bookId'] = book['bookId']item['definePrice'] = book['definePrice']item['publisher'] = book['publisher']item['discount'] = book['discount']yield item
from scrapy.crawler import CrawlerProcessfrom scrapy.utils.project import get_project_settingsif __name__ == '__main__':process = CrawlerProcess(get_project_settings())process.crawl('jd_shop')process.start()
from itemadapter import ItemAdapterimport pymysqlimport jsonclass JdPipeline(object):# 初始化数据库参数def __init__(self,host,database,user,password,port):self.host = hostself.database = databaseself.user = userself.password = passwordself.port = port@classmethoddef from_crawler(cls,crawler):return cls(host = crawler.settings.get('SQL_HOST'),user = crawler.settings.get('SQL_USER'),password = crawler.settings.get('SQL_PASSWORD'),database = crawler.settings.get('SQL_DATABASE'),port = crawler.settings.get('SQL_PORT'),)# 打开爬虫时调用def open_spider(self,spider):self.db = pymysql.connect(host=self.host, user=self.user, password=self.password, database=self.database, port=self.port,autocommit=True)self.cursor = self.db.cursor() # 创建游标# 关闭爬虫时调用def close_spider(self,spider):self.db.close()# 重写process_item()方法,首先先将item对象转换为字典类型的数据,然后将数据通过zip()函数转换为每条数据为# ['book_name','press','author']类型的数据,然后提交并返回item对象def process_item(self, item, spider):data = dict(item)authors = json.dumps(data['authors'])query = """insert into ranking (bookName,sellPrice,authors,coverUrl,bookId,definePrice,publisher,discount) values (%s,%s,%s,%s,%s,%s,%s,%s)"""values = (str(data["bookName"]), str(data["sellPrice"]), str(authors),str(data["coverUrl"]),str(data["bookId"]),str(data["definePrice"]),str(data["publisher"]),str(data["discount"]))self.cursor.execute(query, values)self.db.commit()return item
SQL_HOST = 'localhost'SQL_USER = 'root'SQL_PASSWORD = 'root'SQL_DATABASE = 'mysoft'SQL_PORT = 3306ITEM_PIPELINES = {'jd.pipelines.JdPipeline': 300,}
表结构: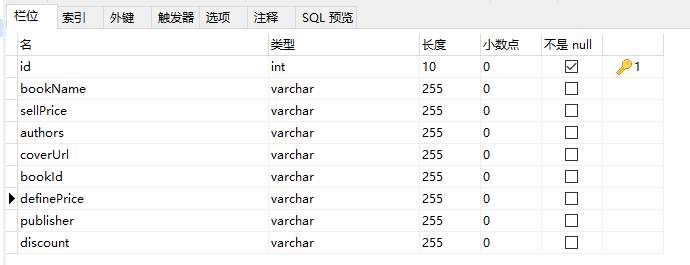

若有收获,就点个赞吧
0 人点赞
