Celery是什么
celery是一个基于分布消息传递的异步任务队列。定义很简单,但是这里隐含了一个条件就是celery不是单独存在的,它一定需要建立在一个分布的消息传递机制上,这个消息传递机制就是celery文档里常说的broker。
生产者/消费者模式
- broker
- RabbitMQ
- Redis
- producer(publisher)
- consumer
- backend
- RabbitMQ: 4.0以后版本不再推荐使用
- Redis
- MySQL
- Mongo
- … …
思考: 消息中间件如何选择?Kafka or RabbitMQ or 其他
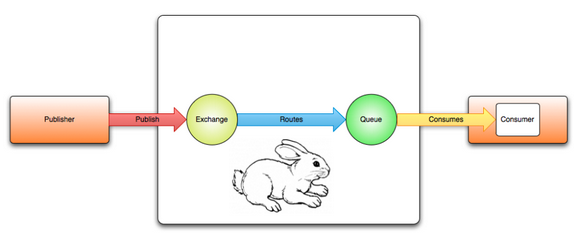
生产者消费者原理图
Celery隐藏了RabbitMQ接口的实现细节,既充当了publisher(client)又充当了consumer (worker)的角色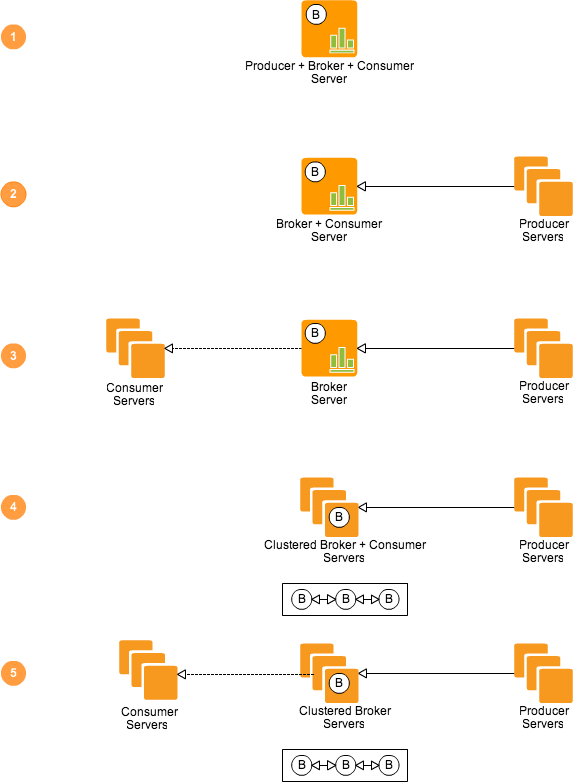
五种分布式部署模型图
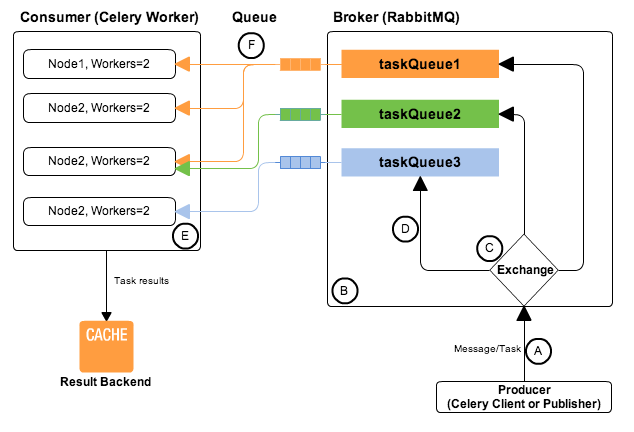
Celery+RabbitMQ工作流程图
连接相关
AMQP
- 概述
高级消息队列协议即Advanced Message Queuing Protocol(AMQP)是面向消息中间件提供的开放的应用层协议,其设计目标是对于消息的排序、路由(包括点对点和订阅-发布)、保持可靠性、保证安全性。AMQP规范了消息传递方和接收方的行为,以使消息在不同的提供商之间实现互操作性,就像SMTP,HTTP,FTP等协议可以创建交互系统一样。与先前的中间件标准(如Java消息服务)不同的是,JMS在特定的API接口层面和实现行为上进行了统一,而高级消息队列协议则关注于各种消息如何以字节流的形式进行传递。因此,使用了符合协议实现的任意应用程序之间可以保持对消息的创建、传递。
高级消息队列协议是一种二进制应用层协议,用于应对广泛的面向消息应用程序的支持。协议提供了消息流控制,保证的一个消息对象的传递过程,如至多一次、保证多次、仅有一次等,和基于SASL和TLS的身份验证和消息加密.
高级消息队列协议对于实现有如下规定
- 类型系统
- 对称的异步消息传递
- 标准的、可扩展的消息格式
- 标准的、可扩展的消息存储池
- 典型实现
- RabbitMQ
- ActiveMQ
Connection(连接)
Connection是RabbitMQ的socket链接,它封装了socket协议相关部分逻辑。
无论是生产者还是消费者,都需要和 RabbitMQ Broker 建立连接,这个连接就是一条 TCP 连接,也就是 Connection。
Channel(信道/通道)
一旦 TCP 连接建立起来,客户端紧接着可以创建一个 AMQP 通道(Channel),每个通道都会被指派一个唯一的 ID。
Channel是我们与RabbitMQ打交道的最重要的一个接口,我们大部分的业务操作是在Channel这个接口中完成的,包括定义Queue、定义Exchange、绑定Queue与Exchange、发布消息等。如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也较低。Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel Id帮助客户端和message broker识别channel,所以channel之间是完全隔离的。Channel作为轻量级的Connection极大减少了操作系统建立TCP connection的开销。
AMQP 0-9-1 提供了一种通过单个 TCP 连接连接到多路复用的方法。这意味着应用程序可以在单个连接上打开多个称为通道的”轻量级连接”。AMQP 0-9-1 客户端在通道上连接并执行协议操作(管理拓扑、发布、使用)后打开一个或多个通道。
代码实现
参考cloudify-plugins-common/cloudify.amqp_client:AMQPClient
Celery app生命周期
Celery最重要的概念:app(celery实例)
celery app是线程安全的
- create
app = Celery()
- configure
app.conf.update()
- register task
@app.taskdef dispatch():pass
- start
- close
Celery worker启动命令解析
/opt/mgmtworker/env/bin/python \/opt/mgmtworker/env/bin/celery worker \-Ofair \--include=cloudify.dispatch \# Comma separated list of additional modules to import--hostname cloudify.management \# Set custom hostname--config=cloudify.broker_config \# Name of the configuration module--app=cloudify_agent.app.app \# app instance to use (e.g. module.attr_name)--events \# Send events that can be captured by monitors like celery events, celerymon, and others.--loglevel=debug \# Logging level, choose between DEBUG, INFO, WARNING, ERROR, CRITICAL, or FATAL.--queues=cloudify.management \# List of queues to enable for this worker, separated by comma. By default all configured queues are enabled. Example: -Q video,image--logfile=/var/log/mgmtworker/cloudify.management_worker.log \# Path to log file. If no logfile is specified, stderr is used.--autoscale=100,2 \# Enable autoscaling by providing max_concurrency, min_concurrency. Example:: --autoscale=10,3 (always keep 3 processes, but grow to 10 if necessary)--maxtasksperchild=10 \# Maximum number of tasks a pool worker can execute before it's terminated and replaced by a new worker.# The --maxtasksperchild option is used for user tasks leaking resources, like memory or file descriptors# With this option you can configure the maximum number of tasks a worker can execute before it’s replaced by a new process.--without-gossip \# Do not subscribe to other workers events.--without-mingle \# Do not synchronize with other workers at startup.--with-gate-keeper \# Enable gate keeper, implement in cloudify--gate-keeper-bucket-size=5 \# The gate keeper bucket size, implement in cloudify--with-logging-server \# Enable logging server, implement in cloudify--logging-server-logdir=/var/log/mgmtworker/logs \# logdir location, implement in cloudify--logging-server-handler-cache-size=100# Maximum number of file handlers that can be open at any given time, implement in cloudify
Start worker instance.Examples::celery worker --app=proj -l infocelery worker -A proj -l info -Q hipri,lopricelery worker -A proj --concurrency=4celery worker -A proj --concurrency=1000 -P eventletcelery worker --autoscale=10,0Options:-A APP, --app=APP app instance to use (e.g. module.attr_name)-b BROKER, --broker=BROKERurl to broker. default is 'amqp://guest@localhost//'--loader=LOADER name of custom loader class to use.--config=CONFIG Name of the configuration module--workdir=WORKING_DIRECTORYOptional directory to change to after detaching.-C, --no-color-q, --quiet-c CONCURRENCY, --concurrency=CONCURRENCYNumber of child processes processing the queue. Thedefault is the number of CPUs available on yoursystem.-P POOL_CLS, --pool=POOL_CLSPool implementation: prefork (default), eventlet,gevent, solo or threads.--purge, --discard Purges all waiting tasks before the daemon is started.**WARNING**: This is unrecoverable, and the tasks willbe deleted from the messaging server.-l LOGLEVEL, --loglevel=LOGLEVELLogging level, choose between DEBUG, INFO, WARNING,ERROR, CRITICAL, or FATAL.-n HOSTNAME, --hostname=HOSTNAMESet custom hostname, e.g. 'w1.%h'. Expands: %h(hostname), %n (name) and %d, (domain).-B, --beat Also run the celery beat periodic task scheduler.Please note that there must only be one instance ofthis service.-s SCHEDULE_FILENAME, --schedule=SCHEDULE_FILENAMEPath to the schedule database if running with the -Boption. Defaults to celerybeat-schedule. The extension".db" may be appended to the filename. Applyoptimization profile. Supported: default, fair--scheduler=SCHEDULER_CLSScheduler class to use. Default iscelery.beat.PersistentScheduler-S STATE_DB, --statedb=STATE_DBPath to the state database. The extension '.db' may beappended to the filename. Default: None-E, --events Send events that can be captured by monitors likecelery events, celerymon, and others.--time-limit=TASK_TIME_LIMITEnables a hard time limit (in seconds int/float) fortasks.--soft-time-limit=TASK_SOFT_TIME_LIMITEnables a soft time limit (in seconds int/float) fortasks.--maxtasksperchild=MAX_TASKS_PER_CHILDMaximum number of tasks a pool worker can executebefore it's terminated and replaced by a new worker.-Q QUEUES, --queues=QUEUESList of queues to enable for this worker, separated bycomma. By default all configured queues are enabled.Example: -Q video,image-X EXCLUDE_QUEUES, --exclude-queues=EXCLUDE_QUEUES-I INCLUDE, --include=INCLUDEComma separated list of additional modules to import.Example: -I foo.tasks,bar.tasks--autoscale=AUTOSCALEEnable autoscaling by providing max_concurrency,min_concurrency. Example:: --autoscale=10,3 (alwayskeep 3 processes, but grow to 10 if necessary)--autoreload Enable autoreloading.--no-execv Don't do execv after multiprocessing child fork.--without-gossip Do not subscribe to other workers events.--without-mingle Do not synchronize with other workers at startup.--without-heartbeat Do not send event heartbeats.--heartbeat-interval=HEARTBEAT_INTERVALInterval in seconds at which to send worker heartbeat-O OPTIMIZATION-D, --detach-f LOGFILE, --logfile=LOGFILEPath to log file. If no logfile is specified, stderris used.--pidfile=PIDFILE Optional file used to store the process pid. Theprogram will not start if this file already exists andthe pid is still alive.--uid=UID User id, or user name of the user to run as afterdetaching.--gid=GID Group id, or group name of the main group to change toafter detaching.--umask=UMASK Effective umask (in octal) of the process afterdetaching. Inherits the umask of the parent processby default.--executable=EXECUTABLEExecutable to use for the detached process.--version show program's version number and exit-h, --help show this help message and exit
gate_keeper.py
并发任务的限制:通过一个三个参数来控制
- max_concurrencies 默认值100
- gate_keeper_bucket_size 默认值5
- gate_keeper_max_top_flows 默认值20
if autoscale:self.max_concurrencies = int(autoscale.split(',')[0])else:self.max_concurrencies = 100self.max_top_flows = gate_keeper_max_top_flowsworker.gate_keeper = selfself.enabled = with_gate_keeperself.bucket_size = gate_keeper_bucket_sizeself._current = collections.defaultdict(lambda: Queue.Queue(self.bucket_size))self._on_hold = collections.defaultdict(Queue.Queue)self._pending_workflows = Queue.Queue()
bucketkey:
//‘’
task_type: workflow/operation
Celery components
- worker
- Timer
- Hub
- Beat
- StateDB
- Consumer
Celery Consumer blueprint
default_steps = ['celery.worker.consumer.connection:Connection','celery.worker.consumer.mingle:Mingle','celery.worker.consumer.events:Events','celery.worker.consumer.gossip:Gossip','celery.worker.consumer.heart:Heart','celery.worker.consumer.control:Control','celery.worker.consumer.tasks:Tasks','celery.worker.consumer.consumer:Evloop','celery.worker.consumer.agent:Agent',]
- Mingle
Bootstep syncing state with neighbor workers. At startup, or upon consumer restart, this will:
- Sync logical clocks.
- Sync revoked tasks.
- Events
Service used for sending monitoring events
- Heart
Bootstep sending event heartbeats. This service sends a
worker-heartbeatmessage every n seconds. Note:
Not to be confused with AMQP protocol level heartbeats.
- Control
Worker Remote Control Bootstep.
Control-> :mod:celery.worker.pidbox-> :mod:kombu.pidbox. The actual commands are implemented in :mod:celery.worker.control.
- Tasks
Worker Task Consumer
- Evloop
Event loop service. Note:
This is always started last.
- Agent
Agent starts :pypi:
cellactors.
Celery task生命周期
- start
- stop(cancel)
- shutdown(close channel)
Celery中一些常用配置
# 中间件 urlbroker_url = 'amqp://{username}:{password}@{hostname}:{port}//{options}'# 任务结果存储 urlresult_backend = broker_url# 任务结果过期时间(单位:秒)result_expires = 600# How many messages to prefetch at a time multiplied by the number of concurrent processes.# The default is 4 (four messages for each process).# The default setting is usually a good choice,# however – if you have very long running tasks waiting in the queue and you have to start the workers,# note that the first worker to start will receive four times the number of messages initially.# Thus the tasks may not be fairly distributed to the workers.# To disable prefetching, set worker_prefetch_multiplier to 1. Changing that setting to 0 will allow the worker to keep consuming as many messages as it wants.worker_prefetch_multiplier = 0# Late ack means the task messages will be acknowledged after the task has been executed,# not just before (the default behavior).task_acks_late = True# 事件超时(单位:秒)event_queue_expires = 60# 事件TTLevent_queue_ttl = 30# Broker 心跳 (单位:秒)broker_heartbeat = 60# Broker 心跳检查频率broker_heartbeat_checkrate = 2# 任务序列化格式task_serializer = 'json'# 结果序列化格式result_serializer = 'json'# 消息格式白名单accept_content = ['json', 'pickle']
Celery signal(信号)有什么作用
1:信号(signal)机制是Linux系统中最为古老的进程之间的通信机制,解决进程在正常运行过程中被中断的问题,导致进程的处理流程会发生变化
2:信号是软件中断
3:信号是异步事件
Celery定义了如下信号
有多种类型的事件可以触发信号,你可以连接到这些信号,使得在他们触发的时候执行自定义操作。
__all__ = ('before_task_publish', 'after_task_publish','task_prerun', 'task_postrun', 'task_success','task_retry', 'task_failure', 'task_revoked', 'celeryd_init','celeryd_after_setup', 'worker_init', 'worker_process_init','worker_process_shutdown', 'worker_ready', 'worker_shutdown','worker_shutting_down', 'setup_logging', 'after_setup_logger','after_setup_task_logger', 'beat_init', 'beat_embedded_init','heartbeat_sent', 'eventlet_pool_started', 'eventlet_pool_preshutdown','eventlet_pool_postshutdown', 'eventlet_pool_apply',)
Cloudify Celery App注册了如下两个signal
@signals.worker_process_init.connectdef declare_fork(**kwargs):try:import Crypto.RandomCrypto.Random.atfork()except ImportError:pass# This is a ugly hack to restart the hub event loop# after the Celery mainProcess started...@signals.worker_ready.connectdef reset_worker_tasks_state(sender, *args, **kwargs):if sender.loop is not asynloop:returninspector = app.control.inspect(destination=[sender.hostname])def callback(*args, **kwargs):try:inspector.stats()except BaseException:passsender.hub.call_soon(callback=callback)
Celery failover工作原理
Celery, Kombu, Pika有什么关系
- Celery: 分布式任务执行系统
- Kombu:封装消息中间件传输协议,提供connection client。包括:AMQP,Redis,QPID,Zookeeper,Consul,Etcd,SLMQ,SQS等等。
Kombu从属于Celery项目。 - pika:封装AMQP0-9-1传输协议,提供connection client。
扩展阅读:StackOverflow: Kombu vs. Pika
Celery中Pidbox做什么的
Worker mailbox (remote control)
Pidbox is the broadcast messaging system used by celery to support remote control of workers.
以下是曾经排查过的pidbox消息堆积问题
- 现象:celery@Server_yncx0p.celery.pidbox队列中消息数量600+
{"arguments": {}, "matcher": null, "reply_to": {"routing_key": "db0f1641-5317-3efb-a0e0-decc122912fa", "exchange": "reply.celery.pidbox"}, "pattern": null, "ticket": "82f2655d-0714-4a97-b878-31d33c8db1ec", "destination": ["celery@cloudify.management"], "method": "ping"}
问题排查:所有ping消息会发送给celery.pidbox这个exchange,该exchange类型为‘fanout’(广播给所有绑定的队列)。
结论:ping类型的消息是广播类型。当某个队列无consumer,pidbox消息会堆积。
测试代码
from celery import Celery# 如果RabbitMQ有认证,注意修改一下broker_url = 'amqp://guest:guest@127.0.0.1:5672//'def get_celery_client(broker_url=broker_url,broker_ssl_enabled=False,broker_ssl_cert_path=None,max_retries=None):from celery import Celerycelery_client = Celery(broker=broker_url,backend=broker_url)celery_client.conf.update(CELERY_TASK_RESULT_EXPIRES=600)if broker_ssl_enabled:import sslcelery_client.conf.BROKER_USE_SSL = {'ca_certs': broker_ssl_cert_path,'cert_reqs': ssl.CERT_REQUIRED,}celery_client.pool.connection.ensure_connection(max_retries=max_retries)return celery_clientdef ping(worker=None):app = get_celery_client(broker_url, max_retries=3)try:destination = [worker] if worker else []inspect = app.control.inspect(destination=[worker],timeout=10)resp = inspect.ping()except BaseException:return Nonefinally:if app:app.close()return respresp = ping('celery@test_queue')print(resp)
Celery如何支持并发的
- 多进程:Prefork
Mgmtworker使用该模式工作 - 协程:Eventlet,Gevent
celery -A proj worker -P eventlet -c 10celery -A proj worker -P gevent -c 10 - 横向扩展
- autoscale
- 多服务器/多容器实例
思考: Mgmtworker是否能够使用协程来实现并发?为什么?如何做?
Celery监控
- Celery flower(Python项目)
Celery的版本
最新版本: 5.0.2, 不再支持Python2
Cloudify社区代码使用的版本:3.1.17
我们Mgmtworker使用的版本:4.4.2
Agent使用的版本:3.1.26
Celery 难解之谜
- 任务执行hang住
- 任务并发量大,死锁
- 任务不多,amqp连接死了
- Celery Heartbeat丢失异常重启
- RabbitMQ每隔一定周期,打印heartbeat丢失信息,将connection 断开,Celery worker被动重启
- Celery Worker接收不到Heartbeat主动重启
Celery有什么替代方案
Python生态的悲哀:没有好的替代品
RQ?Huey
扩展阅读:StackOverflow: Pros and cons to use Celery vs. RQ
参考文档

若有收获,就点个赞吧
0 人点赞
