:::info
💡 根据 遗忘曲线:如果没有记录和回顾,6天后便会忘记75%的内容
读书笔记正是帮助你记录和回顾的工具,不必拘泥于形式,其核心是:记录、翻看、思考
:::
| 书名 | 高效能人士的七个习惯 |
|---|---|
| 作者 | 史蒂芬·柯维 |
| 状态 | 待开始 阅读中 已读完 |
| 简介 | 本书精选柯维博士“七个习惯”的最核心思想和方法,为忙碌人士带来超价值的自我提升体验。用最少的时间,参透高效能人士的持续成功之路。 |
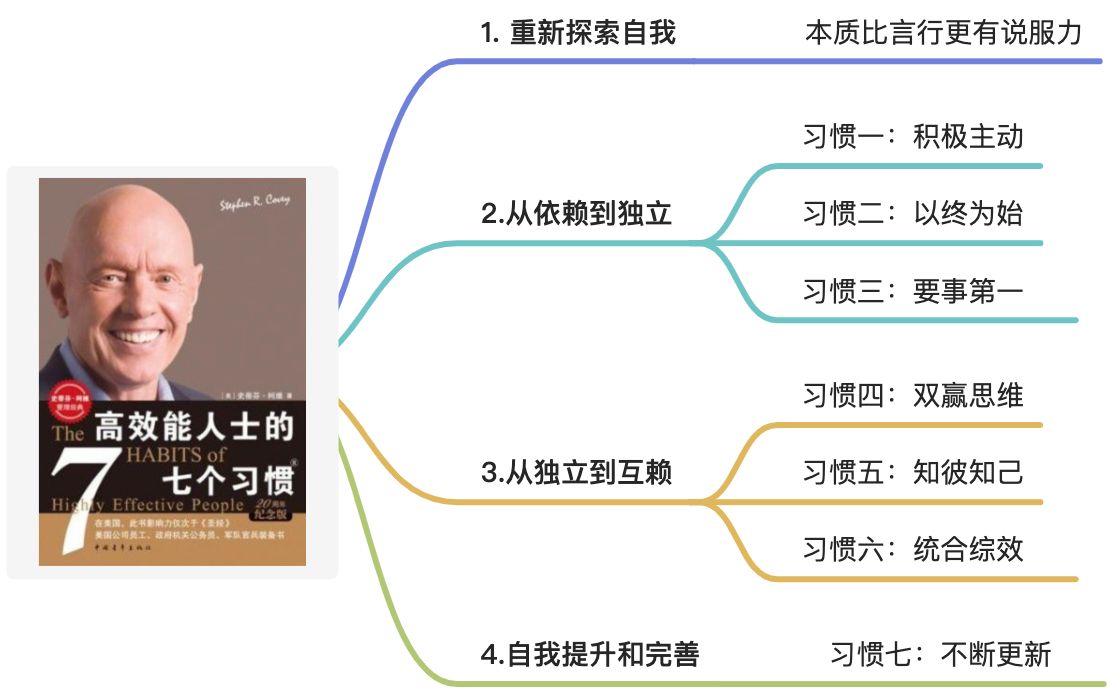
思维导图
用思维导图,结构化记录本书的核心观点。
读后感
观点1
读完该书后,受益的核心观点与说明…
观点2
读完该书后,受益的核心观点与说明…
观点3
读完该书后,受益的核心观点与说明…
书摘
beanDefinitionMap Map的key应该是beanName,value则是BeanDefinition对象
BeanFactoryPostProcessor(占位符信息,就是通过BeanFactoryPostProcessor的子类PropertyPlaceholderConfigurer进行注入进去)
实例化 (反射)-》依赖注入
初始化(工具类,去实现ApplicationContextAware接口,来获取ApplicationContext对象进而获取Spring Bean)
BeanPostProcessor AOP的关键
BeanPostProcessor相关子类的before方法执行完,则执行init相关的方法,比如说@PostConstruct、实现了InitializingBean接口、定义的init-method方法
Spring是怎么解决循环依赖的?
候选者:singletonObjects(一级,日常实际获取Bean的地方);
候选者:earlySingletonObjects(二级,还没进行属性注入,由三级缓存放进来);
候选者:singletonFactories(三级,Value是一个对象工厂);
为什么是三级缓存?
候选者:所以,三级缓存的Value是ObjectFactory,可以从里边拿到代理对象
候选者:而二级缓存存在的必要就是为了性能,从三级缓存的工厂里创建出对象,再扔到二级缓存(这样就不用每次都要从工厂里拿)
https://baijiahao.baidu.com/s?id=1682143925807971655&wfr=spider&for=pc
MySQL调优
1.是否能使用覆盖索引
2.考虑是否组建联合索引,尽量将区分度最高的放在最左边,最左匹配原则
3.对索引进行函数操作或者表达式计算会导致索引失效
4.利用子查询优化超多分页场景
5.explain命令查看SQL的执行计划
6.有意识地减少锁的持有时间(修改是更新操作,会加行锁)
Read Commit(读已提交)
可重复读,有可能因为间隙锁导致的死锁问题
MySQL的binlog没有row模式,在read commit隔离级别下会存在【主从数据不一致】的问题
即使走对了索引,线上查询还是慢?
1.考虑能不能把旧的数据给“删掉”(一般不会删)
2.走缓存(如果查询条件相对复杂且多变的话,涉及各种group by和sum)
3.是不是有【字符串】检索的场景(导入ES)
4.根据查询条件的维度,做相应的聚合表
以空间换时间,相同的数据换别的地方也存储一份
MySQL读写都有瓶颈。
主从架构,读写分离
分库分表,一般按照userId分
ACID
原子性:undolog实现
隔离性:锁实现,屏蔽了加锁的细节
持久性:redo log(物理修改,xxx页做了xxx修改)
一致性:事务的目的
行锁和表锁
SQL命中了索引,锁的是命中条件内的索引节点,如果没有命中索引,锁的就是整个索引树(表锁)
行锁又可以分为S读锁和X写锁
隔离级别:
read uncommited (读不加锁,修改加写锁)
候选者:在MySQL InnoDB引擎层面,又有新的解决方案(解决加锁后读写性能问题),叫做MVCC(Multi-Version Concurrency Control)多版本并发控制
候选者:MVCC通过生成数据快照(Snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取
read commit 语句级快照
repeatable read 事务级快照
读提交,在读取的时候生成一个”版本号”,等到其他事务commit了之后,才会读取最新已commit的”版本号”数据。(解决脏读)
不可重复读
候选者:在InnoDB引擎下的的repeatable read (可重复复读)隔离级别下,快照读MVCC影响下,已经解决了幻读的问题(因为它是读历史版本的数据)
候选者:而如果是当前读(指的是 select * from table for update),则需要配合间隙锁来解决幻读的问题。
- S锁,称为共享锁,事务在读取记录的时候获取 S 锁
- X锁,称为独占锁,事务在修改记录的时候获取 X 锁
我:确实不准确。益与 MVCC 的功劳,普通的 select 是不需要加锁的。
而 SELECT … LOCK IN SHARE MODE; 这种读取需要对记录上 S 锁。
SELECT … FOR UPDATE; 这种需要对记录上 X 锁。
面试官:行,那再来说说行锁吧,InnoDB 有几类行锁?
我:有记录锁(Record Locks)、间隙锁(Gap Locks)、Next-Key Locks。
面试官:详细说说看?
我:记录锁顾名思义就是锁住当前的记录,它是作用到索引上的。我们都知道 innodb 是肯定有索引的,即使没有主键也会创建隐藏的聚簇索引,所以记录锁总是锁定索引记录。
还有个 Next-Key Locks 就是记录锁+间隙锁,像上面间隙锁的举例,只能锁定(3,5) 这个区间,而 Next-Key Locks 是一个前开后闭的区间(3,5],这样能防止查询 id=5 的这个幻读。
系统表空间information_schema
073189529867
a,b,c b c
a<10 and b=1
辅助索引 -》主键索引
key:索引 key:主键id
value:主键id value:data
1,2,3
rdb
新开fork 子线程 rdb文件
08.事务到底是隔离的还是不隔离的?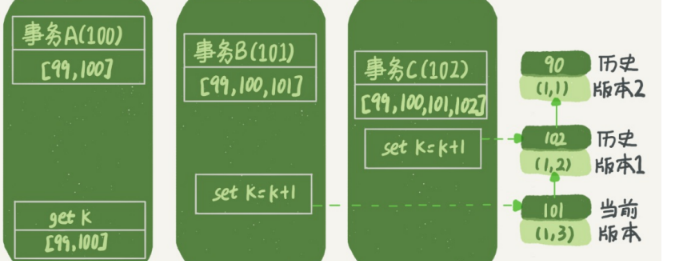
25
34
- 先更新数据库,后更新缓存
先更新数据库,后删除缓存
binlog
班级 科目 姓名 分数
每个班级各个科目最高分
select name, max(grade) groupby ban,kemu
list user id code name
10000
合并 去重
id
https://www.javashitang.com/
https://articles.zsxq.com/id_wxmikzr2pl1q.html
https://www.processon.com/mindmap/62b027aaf346fb074f5a1e90
https://mp.weixin.qq.com/s/hChgzuPAFlUQh8Rnx6EY-w
2. 清楚排查问题时能使用哪些工具
- 公司的监控系统:大部分公司都会有,可全方位监控JVM的各项指标。
- JDK的自带工具,包括jmap、jstat等常用命令:
查看堆内存各区域的使用率以及GC情况
jstat -gcutil -h20 pid 1000
# 查看堆内存中的存活对象,并按空间排序
jmap -histo pid | head -n20
# dump堆内存文件
jmap -dump:format=b,file=heap pid
- 可视化的堆内存分析工具:JVisualVM、MAT等
锐服信科技
蛤蟆云课堂
初始标记、并发标记、并发清理、重新标记、 清除
候选者:一、从Kafka拉取消息(一次批量拉取500条,这里主要看配置)时
候选者:二、为每条拉取的消息分配一个msgId(递增)
候选者:三、将msgId存入内存队列(sortSet)中
候选者:四、使用Map存储msgId与msg(有offset相关的信息)的映射关系
redisson
看门狗机制,锁续期
lua脚本,原子性
锁是唯一的,不会被别的线程解锁
可重入,阻塞

若有收获,就点个赞吧
0 人点赞
