整体链路
自然语言查询 -> 实时分析服务 -> 数据缓存计算服务 -> 自然语言查询服务
问题记录
- flink统计分析任务要能跑起来
- flink跑起来之后,到底能不能支撑9111产生的消息分析
- 主condition传递的queryMac 相互映射关系,有没有更好的传递介质可以分析
- 分析任务的top50 是怎么产生的
- 要做到top50的变化缓存更新及现存的缓存更新比如10s,5s更新
- 在高频的更新时,更新服务的负载,redis的负载是否吃得消
详细流程
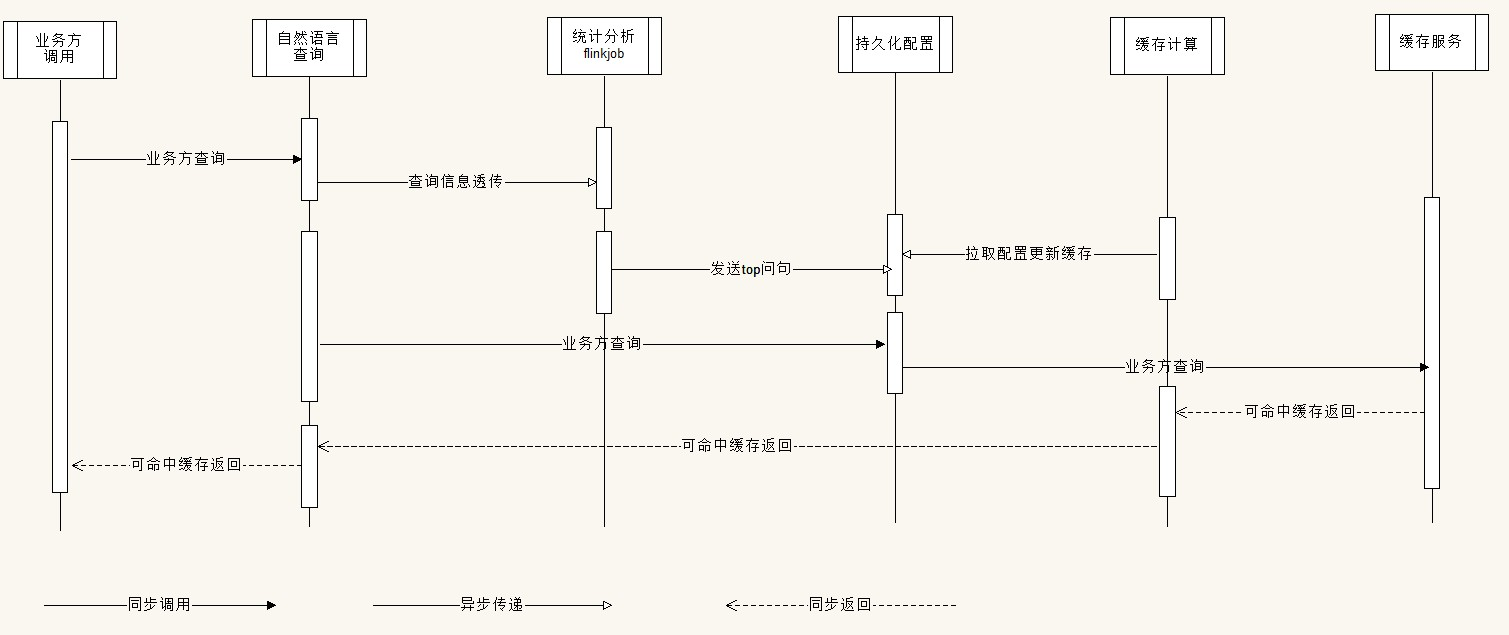
流程分析
上述时序图目前针对于问句缓存可用,但问句缓存就存在不能附加参数的限制,我们这次是希望缓存maincondition的形式提高不同变化形式的问句缓存命中,因此需要在上述流程之上做进一步改动,改动需考虑情况:
- 查询信息 ->maincondition -> 问句结果(main结果)映射
- 是否要用缓存服务(意味着使用哪个redis)
- redis查询是否够用
- 消息量级控制
- 开关降级方案考虑
改进流程时序图
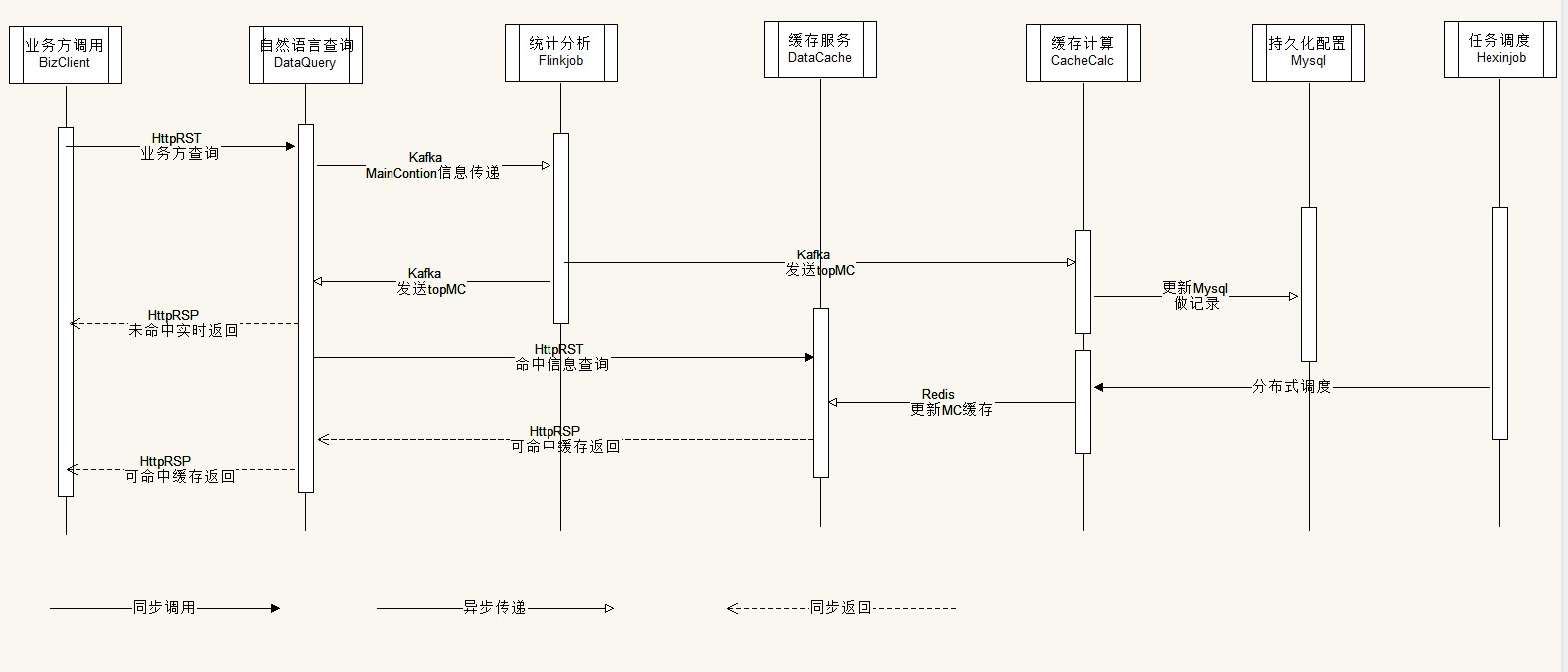
- 持久化到Mysql 是为了能直观看到当前缓存配置信息
- 缓存更新时间给固定 给一个默认更新时间 比如1分钟,在分布式调度平台动态配置
- 依然走datacache 中台redis 这个流程成熟可控
- datacache 单独做一套更新缓存策略,HTTP取MainCondition结果,供这个流程使用
问题:
- FlinkJob 分析算法如何设置,才能拿到最优缓存命中率
- 如果做到5S内缓存更新一次难度有点大,链路有些长,再加上配置一多更新不过来
- 在dataquery拿到Kafka热点信息是否需要有个延迟生效策略
实现过程中遇到的问题:
- 如果缓存过程DataValueReuslt 结果,只能通过解析结果JSON 与此对应,不然保证不了condition 与 DataValueResult 的 匹配关系
- 只有这样才能有一个更新的途径,在9111新开一个HTTP专门返回用JSONcondition 请求的DataValueResult结果,用来分布式更新
- 这个更新的结果 可能数据量级比较大,诊股问句起步在几百k,其中除4千只股票外,包含condition 列表列表信息,请求信息,表信息,chunkInfoList,columnInfos,detailInfos等
- 如果使用这个更新结果在9111替换maincondition时 string 再转DataValueResult 要花费 10到40ms时间本机测试,这恐怕是个问题
- 改动:中台Kafka不具备广播通知的能力,因此从Flink分析的结果,9111先从mysql 主动拉去更新配置,这个后期依然没有广播能力的话,可以再改成定时从redis拉去效率会更好些
- 因为使用condition作为热点key,其中像时间就会存在变化,这样会降低热key的聚集度
1. 改进链路

本次可以看到引入了Nacos 做配置的动态推送,提高topN配置应用的及时性
2. 具体改动
- 原来在写入Mysql的同时将 相关配置的Md5 信息写入到Nacos
- 利用Nacos 的动态推送能力,分别推送到9111(做请求过滤)、缓存计算(更新缓存的配置信息,更新缓存的消息)
增强改动
一、现阶段情况
经过上一次改进版,缓存流程基本确认下来。目前上线观察情况如下:
- 缓存命中率
- hot cond 220509 灰度单台top100 命中率 3.7% 184w, cache 缓存命中率 18%
- hot cond 220512 灰度单台top150 命中率 5% 184w, 早高峰 命中率在 10% 下午在 12%
- hot cond 220518 灰度单台top150 命中率 5.3% 177w, 早高峰9.30 到 10点10 命中率在 13% 下午1点到3点在 10%
- 情况综述
- 缓存命中率需要提升
- 当前是根据所有请求信息的condition信息做key来分析
- 这样会存在这种情况,一个问句或者一种条件会一个股票一个股票来请求,这样其实把这个条件的聚集度打散
- 计算资源成本需要节约
- 计算资源成本需要节约
- 实现集群单节点或多节点而非整个集群计算
- 具体实现
- 使用Nacos这种高可用能保证一致性的服务注册发现组件来定时获取当前集群健康的节点
- 基于共识算法,结合redis做分布式锁,实现选举出一定数量作为发送cond信息的节点,基本保证选举结果一致性
- 能根据集群情况动态变化选举结果,保证集群中存在可发送信息的节点
- 缓存命中率需要提升
- topN的计算做调试
- 将类似类似于同条件单股票请求的情况统计起来,提升聚集度

若有收获,就点个赞吧
0 人点赞
