1、MySql索引底层数据结构
在mysql中,千万级别的表为什么可以做到毫秒级查询?
思考一下,如果当几千万条数据,查找的时候通过一次次的磁盘io,一次io定位一次数据然后进行比对,这样性能会多低
而索引这种特殊的数据结构,完美的支撑了千万级表查询,原因就在于b+tree的特性以及优秀的设计。
索引为什么用b+树而不用二叉树,红黑树呢?
用二叉树的话,假如当我们存储的数据是自增的话,二叉树的特质是右边的元素总要比父元素大,如果这样的话,那么二叉树在存储连续自增的数据的时候,那么就相当于一个链表,与一次次磁盘io遍历没有任何区别。
红黑树的话,可以解决以上问题,但是红黑树的特点总是使各个节点之间变得平衡,会自动的进行分支平衡修正,假如当我们的数据有几千万的时候,红黑树的特性会让树的高度达到一定量级,虽然比第一种方式少了几乎一倍的查找次数,但树的高度也限制了查询效率。
所以mysql在b树的特性上改良了一种新的数据结构,b+树。b+树可以完美的支持千万数据查询,其原理就是因为这种数据结构具有的本质。
在b+树中,根节点不是一个元素,而是一块空间,在这块空间上可以存放n多元素,并且是排好序的连续存储,每个元素之间有一块地址存储叶子节点的地址,每一块这种空间占用16KB大小,并且只有非叶子节点上才存储对应索引所指向的数据,非叶子节点所存储的数据根据存储引擎的不同而又有区别。
所以1千万级数据在b+树这种数据结构面前,也就只有4.5个节点,并且每个叶子节点会被加载进内存,io是会在内存中计算,与磁盘io相比速度可以忽略不记,所以只需要进行几次内存中的二分查找就可以定位到对应索引元素的地址,从而获取该索引所关联的数据。
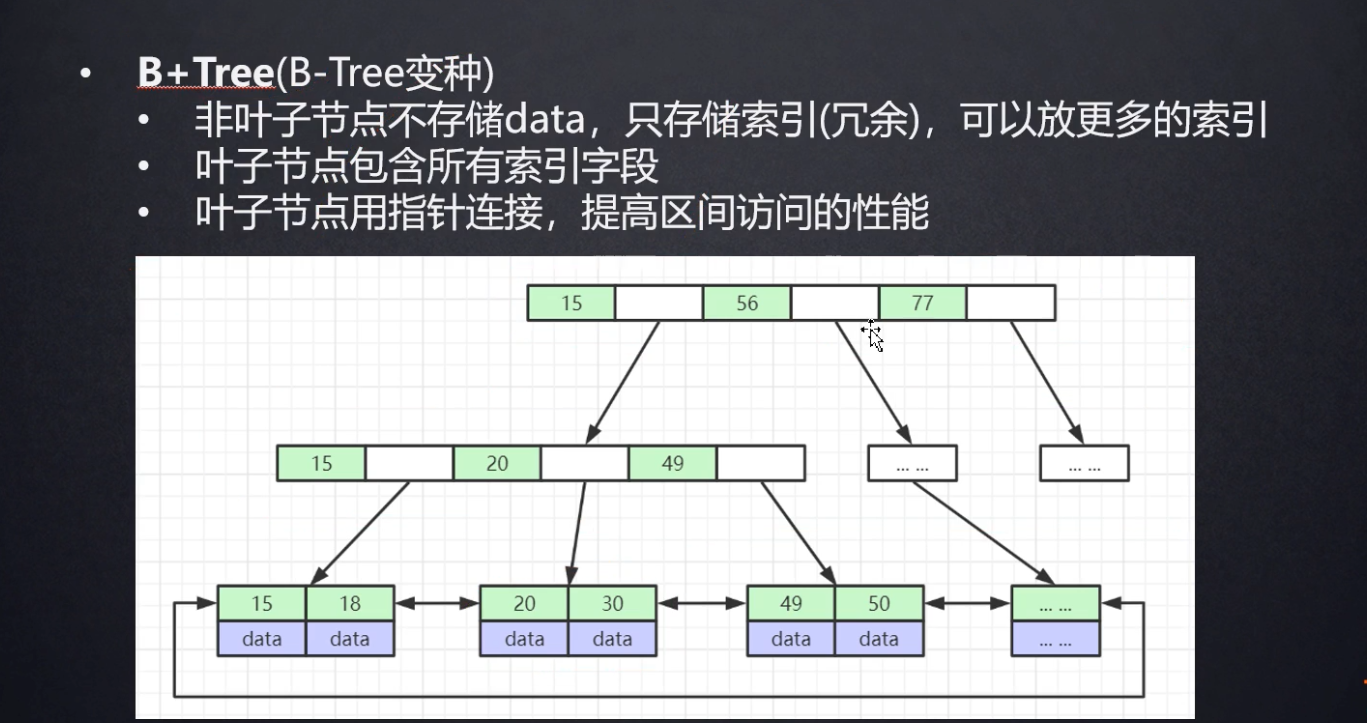
只有非叶子节点才存放数据,并且会首位相连,提高每个非叶子节点区间的访问速度,而叶子节点存在的意义是为了构建一颗完美的b+tree。
btree与b+tree最关键的区别就是b+tree的叶子节点不存储数据,因为这会影响树的高度,而b+树叶子节点不放数据,就可以放更多的子节点,这样树的高度远远会小于bTree。
聚簇索引与非聚簇索引的区别:
innodb使用的是聚簇索引,即非叶子节点中存储的是索引外其他列的数据。
而myisam使用的是非聚簇索引,在硬盘上会维护两个文件,一个是索引文件一个是数据,innodb只有一个,所以在查询效率上来说innodb比myisam存储引擎少一次跨文件磁盘io,毕竟myisam需要先检索到索引,然后根据索引中存储的对应数据的磁盘地址再去存放数据的文件中定位其他列的数据。
在mysql中还有另外一种索引,hash索引,索引列在存储的时候会进行一次哈希算法,然后得到一个index,放在哈希桶中对应的index上,那么当检索的时候就可以通过检索条件进行哈希运算定位到对应的列,这种效率只需要进行一次计算,但是这种索引的弊端就是只支持等于和in条件,如果是模糊检索,比如>< like运算,也要进行全表扫描。所以99.99%的情况下不推荐使用hash索引!
tips: b+树的非叶子节点间会首尾相连,其目的是为了更好的支持范围查找,由于拍好了序所以只需要定位到条件,然后取出其区间的值就好,不需要额外进行算法。
b树没有这颗指针,所以没法支撑范围查询,每次都需要从根节点开始。b+tree更高效。
二级索引也是一种非聚簇索引,除了聚簇索引,非叶子节点存储的都不是索引外的其他列,所以都会进行回表查询。
使用定义的主键索引查询,效率是最高的。
联合索引必须满足最左匹配原则。

若有收获,就点个赞吧
0 人点赞
