前言:
A/B测试是互联网数据分析必备的知识点,A/B测试也不仅仅只是一个假设检验这么简单,其中很多细节都表现了理论与实际运用的鸿沟。
但是之前看到的很多文章,往往细节不够,
例如给出的案例只是简单的两个数值列表,没有涉及互联网真实的pv,uv,点击率等指标,而这其中牵涉到的粒度和样本问题,也是很重要的。
给出了样本量的计算公式,却不提其中样本标准差以及effect size是如何得来的。
计算得来的样本量是否符合常识,理论上计算的样本量是点击了按钮的用户,但并不是所有用户都能浏览到这个页面,点击这个按钮。
抱着这些疑惑,我想深入学习下A/B测试,理清其中细节。
本文主要是以Kaggle上Tammy Rotem文章为主线,对于一些细节知识补充了自己工作中的理解以及其他资料的总结,作为学习记录。原文如下,其中也有自己一直难以理解的点,在末尾表明,欢迎感兴趣的同学一起讨论!
https://www.kaggle.com/tammyrotem/ab-tests-with-pythonwww.kaggle.com
文章结构:
一.实验背景
1.1 实验策略
1.2 策略目标
二.指标选择
2.1 第一类指标
2.2 第二类指标
三.估计样本的标准差
3.1 基线数据
3.2 估计指标标准差
四.计算实验样本量
五.AB实验分析-参数检验
5.1 加载A/B组实验数据
5.2 实验健康检验
5.3 核心-策略相关指标检验
六.非参数检验-符号检验
6.1 数据准备
6.2 符号检验
七.结论与存在的问题
八.补充:如何计算业务上允许的最小变化D_min
一.实验背景
这篇文章是对Udacity A/B Testing课程项目的梳理。Udacity的A/B Testing课程是由Google提供,重点是A/B测试的设计和分析。课程包括如何选择和定义衡量指标,如何设计一个具有统计功效(statistical power)的实验,以及如何分析结果并得出可靠的结论。
实验case:免费试用(Free Trial)前的筛选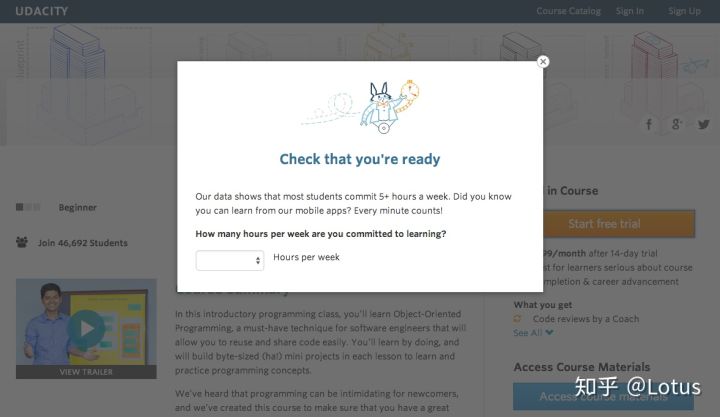
1.1 实验策略
- 实验策略:如上图所示,在点击免费试用按钮后,对照组不会出现弹窗,直接进入免费试用课程的流程。实验组加了弹窗,需要用户回答他们每周有多少时间可以投入到课程中。
- 如果学生每周表示有5个小时或者更多的时间,他们将会像往常一样通过检查流程。如果他们表示每周不到5个小时,就会出现一条信息,说需要更多的时间投入才能成功完成课程,并表明学生可以免费获得课程材料。
- 无论如何,学生都可以选择继续参加免费试用课程,或者免费获取课程材料。
1.2 策略目标
实验假设了加入弹窗填时间这个步骤可以提醒用户了解到自己的学习时间是否足以完成课程。通过让部分用户察觉到自己学习时间不足以完成任务,从而自动放弃免费试用课程,最后可以提高整体用户的课程完成率,另一方面也可以为辅助老师减压,让他们专注于那些可以投入更多时间的用户。
二.指标选择
一个成功的A/B实验应该有两种类型的指标:
2.1 第一类指标 Invariate metrics
原则上不能发生变化的指标,用来作为策略的健康检验,确保新上线的策略不会发生原则性错误。用来确保实验的变化确实是由策略造成的,就好比控制变量,在研究某一个自变量对因变量的影响时,需要控制其他变量一样。
对于每一个指标,都需要声明一个Dmin—它标志着最小的变化,这对业务来说是非常重要的。例如,任何低于2%的转化率变化,即使在统计上是显著的,对企业来说也是不实际的。
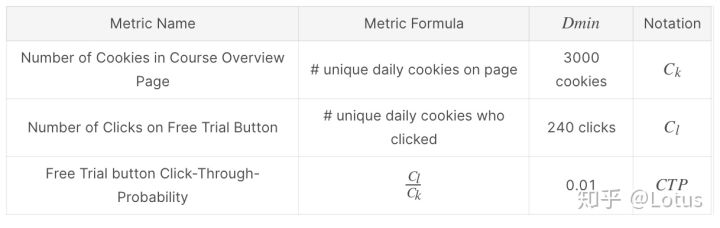
第一类指标如下,包括:
- uv 独立访客数,用去重Cookies计数
- 免费试用按钮的点击量
- 点击率
2.2 第二类指标 Evaluation metrics
第二类指标是我们希望变化的指标,这个和实验的产品或者商业目标有关。
如下:包括
- 课程登记转化率(Gross Conversion):课程登记用户数/免费试用按钮点击量
- 全流程转化率(Net Conversion):课程付费用户数/免费试用按钮点击量
ps:同一个用户id不能登记两次免费试用课程,Retention指标后续没用到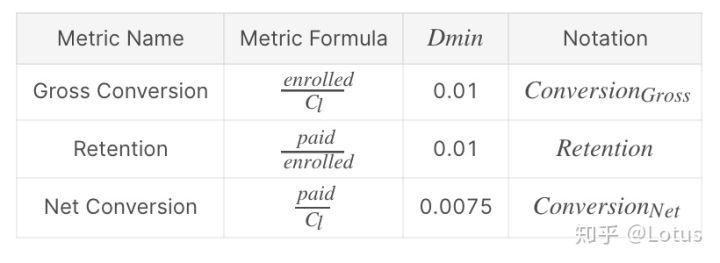
三.估计样本标准差
在开始实验之前,我们需要知道这些指标在策略上线之前的平时表现如何,即baseline values,基线值。这些数据应该是从日常数据中聚合得到的(日均)。
3.1 基线数据
#先将基线值存入字典中baseline = {"Cookies":40000,"Clicks":3200,"Enrollments":660,"CTP":0.08,"GConversion":0.20625,"NConversion":0.109313}
3.2 估计样本的标准差
估计标准差(Standard Deviation)是后续计算实验样本量和置信区间的前提。同时,如果指标变化越大,获得置信结果就越难。
(1)缩放数据(Scaling)
假设每天访问课程介绍页面的样本(cookies)大小为5000个。(这里5000是项目给出的,作为用来估计标准差的抽样样本大小,怎么得来的我也不知道…)我们希望基于5000这个数值,估计一个标准差,仅用于评估指标。这个样本量应该小于我们基线值(40000)。
因为我们用5000样本来估计标准差,所以其他的绝对量(点击量Clicks,登记数Enrollments)都应该进行等比的缩放,相对比值指标保持不变。
#Scale The counts estimatesbaseline["Cookies"] = 5000baseline["Clicks"]=baseline["Clicks"]*(5000/40000)baseline["Enrollments"]=baseline["Enrollments"]*(5000/40000)baseline
缩放后结果如下
{'CTP': 0.08,'Clicks': 400.0,'Cookies': 5000,'Enrollments': 82.5,'GConversion': 0.20625,'NConversion': 0.109313,'Retention': 0.53}
(2)估计标准差
假设转化率指标满足二项分布,就拿课程登记转化率(Gross Conversion)来说,课程登记用户数/免费试用按钮点击量,一次点击,要么登记课程,要么退回,不登记课程,所以这个转化率对应二项分布中事件成功发生的概率p,那么总体方差为np(1-p),由中心极限定理,从总体抽取一定样本,样本标准差的估计量为: (1)
(1)
注意,并不是所有转化率(比例指标)的标准差估计都可以利用式1,这里需要区分两个概念
- unit of diversion 分流单元
- unit of analysis 分析单元(通常是指标的分母)
unit of diversion(分流单元),被用来定义哪个用户或者触发那个事件会进行样本分流(实验组和对照组)。unit of diversion可以是一种独立标识,比如user_id或者cookie,也可以是一种基于事件的,比如page view(每当用户重新刷新页面时就会进行一次分流)。选择unit of diversion取决以下三种重要的因素:
用户一致性(User consistency):
如果我们上线的策略对用户是可见的(例如UI类实验,改下button颜色啥的),原则是让用户始终有一致的体验。因此,选User_ID或Cookie作为分流单元是不错的选择。如果我们上线的策略对用户是不可见的,那么基于事件的分流,如页面浏览将更有意义。因为这样,每次用户重新加载页面时,他们可能会被分配给一个新的组,即如果用户最初是在实验组,现在他们可能会在控制组中结束实验。(PS:这一点没有理解,欢迎有经验的同学探讨,为什么不可见的策略可以用事件触发分流?)
论理考量(Ethical considerations)
指标变化性(Variability of metric):这里的变化性,我认为就是变化性越大,代表样本指标值之间的波动会比较大。如果分流单元比分析单元的范围更大,则指标的变化性要高得多。分析单元一般是指标的分母。例如,对于点击率(CTR)(定义为#Click/#PV),#PV成为分析单元。因此,如果我们使用user_id作为我们的分流单元,以pv作为我们的分析单元,CTR的变化性就会变高。因为一个user_id可以对应多个pv。
回到刚才的问题,只有当实验的分流单元等于分析单元时候,才满足式1的使用条件,如果不满足,可以依据经验给定。
(PS:emmm…. 说实话,这里就看不懂了,为什么指标变动性会变高呢?如果后续理解了,来补上)
估计三种转化率的标准差
#将2.1给出的dmin与和分母与转化率对应起来conversion_dict = {'GConversion':[0.01,'Clicks'], #第一个对应d_min,第二个对应分母'NConversion':[0.0075,'Clicks']}def cal_sd(conversion,d_min,denominator):'''Conversion:转化率名称d_min:最小变化denominator:转化率的分母'''R = {}R['d_min'] = d_min #最小变化R['p'] = baseline[conversion]R['n'] = baseline[denominator]R['sd'] = round(mt.sqrt((R["p"]*(1-R["p"]))/R["n"]),4)print('{} 标准差:'.format(conversion),R['sd'])conversions = ['GConversion','NConversion']for conversion in conversions:d_min = conversion_dict[conversion][0]denominator = conversion_dict[conversion][1]cal_sd(conversion,d_min,denominator)
输出:
GConversion 标准差: 0.0202
NConversion 标准差: 0.0156
四.计算实验样本量
一旦我们估计出小流量实验(样本)的指标标准差,我们就可以计算出实验所需的样本量。太多了会浪费很多资源,太少了会因为统计灵敏度太低而得到不显著的结论。
在计算样本量之前,我们必须弄懂假设检验中的两个概念:
(1)第一类错误α:当原假设为真的时候,我们却拒绝的概率,弃真错误
也被称为Significance Level(显著性水平)
对于A/B测试,犯这个错误代表新策略没有收益,我们却认为有收益,然后上线的错误
(2)第二类错误β:当原假设为假的时候(备择假设为真),我们却接受原假设的概率,取伪错误
而Statistical Power(统计功效) = 1 -β
直观上理解,AB两组即使有差异,也不一定能被你观测出来,必须保证一定的条件(比如样本要充足)才能使你观测出统计量之间的差异;
而统计功效就是当AB两组实际有差异时,能被我们检测出来差异的概率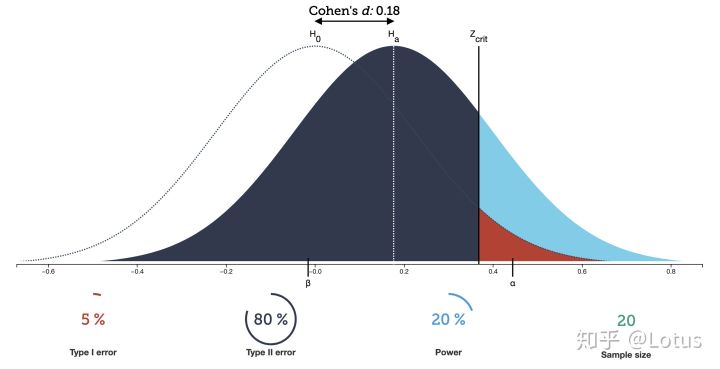
如上图所示,出现的四种因素,知道其中任意三种都可以求出第四个的值
- significance level 显著性水平
- effect size 两组样本均值的差异(Cohen’s d)
- power 统计功效
- sample size 样本量
给定α=0.05和β=0.2,对于effect size(下文公式中的d)就是第二部分给出的Dmin(业务上允许的指标最小变化),接下来,我们计算实验需要的样本量。这个值会分为两组:对照组和实验组。
原假设:
样本量n的计算公式如下 (2)
(2)
#计算sd1和sd2def get_sds(p,d):sd1=mt.sqrt(2*p*(1-p))sd2=mt.sqrt(p*(1-p)+(p+d)*(1-(p+d)))x=[sd1,sd2]return x#计算z-scoredef get_z_score(alpha):return norm.ppf(alpha)#计算样本量def get_sampSize(sds,alpha,beta,d):n=pow((get_z_score(1-alpha/2)*sds[0]+get_z_score(1-beta)*sds[1]),2)/pow(d,2)return n#指定基线数据p和dGC={}GC["p"]=baseline["GConversion"]GC["d"]=0.01NC={}NC["p"]=baseline["NConversion"]NC["d"]=0.0075
计算每个指标实验所需样本量,然后选择最大的,需要注意的是,上述计算的样本量n指的是点击了免费试用button的cookies(一次点击才代表二项分布中的一次试验)。然而,对于一次pv来说,有的用户会点击,有的不会点击,我们无法保证每个浏览这个页面的用户都会点击,所以需要修正样本量。
(1)对于课程登记转化率(Gross Conversion):课程登记用户数(enrolled)/免费试用按钮点击量(clicks)
基线数据:
页面uv = 40000
button人均点击率 = button点击量(clicks) / 页面uv = 3200 / 40000 = 0.08
SampSize = (SampSize/button人均点击率)2
(ps:这里的页面uv指的是Number of cookies *who viewed the course overview page)
GC["SampSize"]=round(get_sampSize(get_sds(GC["p"],GC["d"]),0.05,0.2,GC["d"]))GC["SampSize"]=round(GC["SampSize"]/0.08*2)GC["SampSize"]
课程登记转化率(Gross Conversion)所需样本量:645875.0
(2)全流程转化率(Net Conversion):课程付费用户数(paid)/免费试用按钮点击量(clicks)
同理(1):
NC["SampSize"]=round(get_sampSize(get_sds(NC["p"],NC["d"]),0.05,0.2,NC["d"]))NC["SampSize"]=NC["SampSize"]/0.08*2
全流程转化率(Retention)所需样本量:685325.0
可以看出685325最大,而每天日均页面uv是40000,对于这个实验,如果我们每天只用80%,即32000,那么大概需要21天(3周)时间积累样本。
这里存在一个问题,就是21天uv必然存在重复的,这样实际收集的样本量要少于实验需要的,所以我认为实验做了一个近似处理,即
Number of cookies who viewed the course overview page = PageViews
(这是无法理解的,但是从后面操作可以看出,这里近似为pv了)
五.AB实验分析
5.1 加载A/B组实验数据
实验数据可以在kaggle链接页面底部获取
control=pd.read_csv("control_data.csv")experiment=pd.read_csv("experiment_data.csv")control.head()
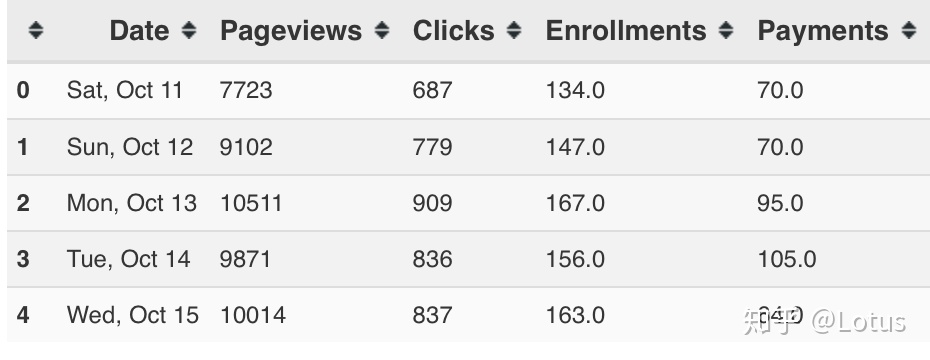
这次实验积累了37天的数据
5.2 实验健康检验
对于三种理论上不会变的指标,如下,因为策略是在这些行为之后才生效的(弹窗)。
- 页面UV(Number of Cookies in Course Overview Page)
- 免费试用按钮的点击量Number of Clicks on Free Trial Button
- 人均点击率
如果上述指标在A/B两组存在显著性差异,那么最终结果是不可靠的。
(1) 计数差异的检验
这小节是对页面UV,点击量的检查(绝对量),分析A/B两组的差异是否显著。
从以下代码直接相加可以看出这里把页面uv(样本量)近似为pv了
pageviews_cont=control['Pageviews'].sum()pageviews_exp=experiment['Pageviews'].sum()pageviews_total=pageviews_cont+pageviews_expprint ("number of pageviews in control:", pageviews_cont)print ("number of Pageviewsin experiment:" ,pageviews_exp)
number of pageviews in control: 345543
number of Pageviewsin experiment: 344660
可以从结果看到,实验组和对照组的Pageviews近似一样,接下来我们需要通过假设检验的方法验证这种差异是随机性导致的。
我们期待的对照组pv数值,应该是总pv的一半(50%)。如果将样本分配到对照组这个事件看作是伯努利试验中成功的事件,同时我们希望这个概率是0.5。那么,分配给对照组的样本量(pv)应该满足二项分布的随机变量X。
当n很大时,基于中心极限定理,二项分布可以近似为正态分布,所以 ,其中N是总pv
,其中N是总pv
原假设:
在5%的显著性水平下,边界误差和置信区间为

其中SD为标准差
p=0.5 #期待的概率值alpha=0.05p_hat=round(pageviews_cont/(pageviews_total),4)sd=mt.sqrt(p*(1-p)/(pageviews_total))ME=round(get_z_score(1-(alpha/2))*sd,4)print ("置信区间的范围在",p-ME,"和",p+ME,"之间,样本值是",p_hat,)
置信区间的范围在 0.4988 和 0.5012 之间,样本值是 0.5006
可以看出
对照组样本比例是0.5006在置信区间范围内,所以pv(页面uv)这个指标是通过检验的,不存在显著差异。
同理,对于点击量clicks
clicks_cont=control['Clicks'].sum()clicks_exp=experiment['Clicks'].sum()clicks_total=clicks_cont+clicks_expp_hat=round(clicks_cont/clicks_total,4)sd=mt.sqrt(p*(1-p)/clicks_total)ME=round(get_z_score(1-(alpha/2))*sd,4)print ("置信区间的范围在",p-ME,"和",p+ME,"之间,样本值是",p_hat)
误差置信区间的范围在 0.4959 和 0.5041 之间,样本值是 0.5005
(2) 概率差异的检验
CTP = clicks/pv
这类指标是比例值,我们期望CTP在对照组和实验组里无显著差异,即
计算其置信区间
其中
用两总体比例之差检验,原理如下(来自贾俊平的统计学)
ctp_cont=clicks_cont/pageviews_contctp_exp=clicks_exp/pageviews_expd_hat=round(ctp_exp-ctp_cont,4)p_pooled=clicks_total/pageviews_totalsd_pooled=mt.sqrt(p_pooled*(1-p_pooled)*(1/pageviews_cont+1/pageviews_exp))ME=round(get_z_score(1-(alpha/2))*sd_pooled,4)print ("置信区间的范围在",0-ME,"和",0+ME,"之间,样本值是",d_hat)
置信区间的范围在 -0.0013 和 0.0013 之间,样本值是 0.0001在范围内
CTP指标也通过检验了!
到此为止,第一类指标全部通过检验。
5.3 核心-策略相关指标检验
本小节是A/B实验的价值所在,检验策略相关指标差异的显著性,即判断策略给公司带来的收益是显著的,还是不显著的,不显著可能就不值得上线。这种显著是正收益,还是负收益。
注意:给定数据中enrollments和payments两列有缺失值,所有在检验这部分相关指标时,真正有效的数据只有23天的
包括
- 课程登记转化率(Gross Conversion):课程登记用户数(enrolled)/免费试用按钮点击量(clicks)
- 全流程转化率(Net Conversion):课程付费用户数(paid)/免费试用按钮点击量(clicks)
(1)检验课程登记转化率(Gross Conversion)如下:#统计实验组和对照组各自有效的点击量clicks_cont=control["Clicks"].loc[control["Enrollments"].notnull()].sum()clicks_exp=experiment["Clicks"].loc[experiment["Enrollments"].notnull()].sum()
这里检验仍是两总体比例之差检验
因为策略造成的指标变化: -2.06 %enrollments_cont=control["Enrollments"].sum()enrollments_exp=experiment["Enrollments"].sum()GC["d_min"] = 0.01GC_cont=enrollments_cont/clicks_contGC_exp=enrollments_exp/clicks_expGC_pooled=(enrollments_cont+enrollments_exp)/(clicks_cont+clicks_exp)GC_sd_pooled=mt.sqrt(GC_pooled*(1-GC_pooled)*(1/clicks_cont+1/clicks_exp))GC_ME=round(get_z_score(1-alpha/2)*GC_sd_pooled,4)GC_diff=round(GC_exp-GC_cont,4)print("因为策略造成的指标变化:",GC_diff*100,"%")print("置信区间: [",GC_diff-GC_ME,",",GC_diff+GC_ME,"]")
置信区间: [ -0.0292 , -0.012 ]
可以看出差异的置信区间不包括0,所有策略造成的指标变化在统计上是显著的(statistically significant)
但是是否在现实意义上是显著的(practically significant),我们需要与D_min(业务上允许的最小值)比较
GC的D_min是0.01,实验差异大于0.01,所以这个差异在现实意义上也是显著的。
课程登记转化率(Gross Conversion)指标是显著减少的(-2.06%),在点击量差异不显著的情况下,说明实验策略有效的减少了课程登记用户数(enrolled),弹窗有效的阻挡了一部分用户登记课程!
(2)全流程转化率(Net Conversion)如下:
因为策略造成的指标变化: -0.49 %#Net Conversion - number of payments divided by number of clickspayments_cont=control["Payments"].sum()payments_exp=experiment["Payments"].sum()NC_cont=payments_cont/clicks_contNC_exp=payments_exp/clicks_expNC_pooled=(payments_cont+payments_exp)/(clicks_cont+clicks_exp)NC_sd_pooled=mt.sqrt(NC_pooled*(1-NC_pooled)*(1/clicks_cont+1/clicks_exp))NC_ME=round(get_z_score(1-alpha/2)*NC_sd_pooled,4)NC_diff=round(NC_exp-NC_cont,4)print("因为策略造成的指标变化:",NC_diff*100,"%")print("置信区间: [",NC_diff-NC_ME,",",NC_diff+NC_ME,"]")
置信区间: [ -0.0116 , 0.0018]
误差的置信区间不包括0,NC的D_min是0.75%,所以指标差异在统计上是显著的,但在现实意义不显著,即收益不显著。
六.双重检验-符号检验
我们可以通过符号检验(Sign Test)获得对实验结果的另外一个视角分析。检验观察结果每天的变化趋势是否显著。我们可以通过每天的指标值,统计对照组指标数值低于实验组的次数,将对照组指标数值较低这个事件,作为伯努利试验中成功的事件。
6.1 数据准备
#连接起实验组与对照组,同时实验组指标名都加上_exp后缀,对照组一样full=control.join(other=experiment,how="inner",lsuffix="_cont",rsuffix="_exp")#不要有缺失值的数据full=full.loc[full["Enrollments_cont"].notnull()]full.count()
结果如下:
Date_cont 23Pageviews_cont 23Clicks_cont 23Enrollments_cont 23Payments_cont 23Date_exp 23Pageviews_exp 23Clicks_exp 23Enrollments_exp 23Payments_exp 23dtype: int64
对于GC和NC指标,比较每天实验组与对照组指标数值的大小
x=full['Enrollments_cont']/full['Clicks_cont']y=full['Enrollments_exp']/full['Clicks_exp']full['GC'] = np.where(x<y,1,0)# The same now for net conversionz=full['Payments_cont']/full['Clicks_cont']w=full['Payments_exp']/full['Clicks_exp']full['NC'] = np.where(z<w,1,0)print(full[['Date_cont','GC','NC']])
结果示例如下
Date_cont GC NC0 Sat, Oct 11 0 01 Sun, Oct 12 0 12 Mon, Oct 13 0 03 Tue, Oct 14 0 04 Wed, Oct 15 0 15 Thu, Oct 16 0 06 Fri, Oct 17 0 07 Sat, Oct 18 0 08 Sun, Oct 19 0 19 Mon, Oct 20 0 110 Tue, Oct 21 0 011 Wed, Oct 22 0 012 Thu, Oct 23 0 1...
计算实验组比对照组指标值更高的天数
GC_x=full.GC[full["GC"]==1].count()NC_x=full.NC[full["NC"]==1].count()n=full.NC.count()print("GC:",GC_x,'\n'," NC:",NC_x,'\n',"total days",n)
GC: 4
NC: 10
total days 23
6.2 符号检验
当我们计算出实验组比对照组指标值更高的天数后,接下来,就是检验这个值是否显著。我们假设每天产生这种结果是随机的(50%)。因此,根据p=0.5和n=天数的二项分布,  表示这个事件(实验组的指标值更高)成功发生的天数,这也是检验统计量。
表示这个事件(实验组的指标值更高)成功发生的天数,这也是检验统计量。

这次,我们用p值作为检验,p值的定义为:当原假设为真的时候,出现样本观察结果或者更极端的概率。例如GC指标,上文已经计算出实验组GC指标值高于对照组的天数是4天,那么
计算p值代码如下
#first a function for calculating probability of x=number of successesdef get_prob(x,n):p=round(mt.factorial(n)/(mt.factorial(x)*mt.factorial(n-x))*0.5**x*0.5**(n-x),4)return p#next a function to compute the pvalue from probabilities of maximum xdef get_2side_pvalue(x,n):p=0for i in range(0,x+1):p=p+get_prob(i,n)return 2*p
与显著性水平0.05进行比较
print ("GC Change is significant if",get_2side_pvalue(GC_x,n),"is smaller than 0.05")print ("NC Change is significant if",get_2side_pvalue(NC_x,n),"is smaller than 0.05")
GC Change is significant if 0.0026 is smaller than 0.05
NC Change is significant if 0.6774 is smaller than 0.05
从上发现GC指标变化显著,NC指标变化不显著,结合上文参数检验结果,可以确认结论。
七.结论与存在的问题
(1)对于三个预期不会变的指标,全部通过检验,说明除了策略影响外,A/B两组没有受到外界不可知因素影响,这是后面结论可靠的前提。
(PS:实际AB实验中会可能出现抽样不均的情况,为了保证实验数据的变化仅仅是实验本身引起的,可以一次性抽取4,5组流量,选择任意两组不加策略空跑,监控核心指标数据,选取两组数据最接近的上实验(控制变量),即AA实验,相比之后检验,AA实验是预先控制好变量,减少不确定因素带来的误差)
(2)对于第二类评估指标的检验结果:
课程登记转化率(Gross Conversion)变化显著,即实验组课程登记数减少显著。
全流程转化率(Net Conversion)变化不显著(参数检验统计显著,现实业务不显著,符号检验不显著),说明策略没有影响到付费用户。
(3)存在的理解问题:
1.本次项目作为课设,虽然结合了实际的业务场景,但是数据,指标仍不足。例如策略目标是提高课程完成率,但是整个实验都没有这方面的数据…
2.5000作为估计标准差的样本量,怎么得来的?
3.在计算样本量时,Number of cookies who viewed the course overview page = PageViews 这个近似着实没看懂,到底是存在逻辑错误,还是实践与理论的鸿沟所致,毕竟运用的时候总追求那么精确和严谨。
4.未能理解pv作为分流单元的意义,即每当用户刷新一次页面,同一个cookie下的用户这次进入实验组,下次就可能进入对照组。
这也衍生另外一个问题,就是对照组和实验组样本独不独立的问题,在实习的时候,公司A/B测试用的是配对样本t检验,这篇文章是双总体样本比例之差检验。前者将实验组和对照组近似为独立的,将每一天的数据看作配对,然后检验差值是否显著(可以参照之前写的文章),用t检验;后者汇总全部的数据,最后求总的比例,用z检验。
两个看似都有道理,但是我也没有真正弄懂,不知道谁对谁错….。欢迎理解的同学告知!
八.补充:如何计算业务上允许的最小变化D_min
D_min:业务上允许的最小变化,即A/B实验除P值,置信区间外另外一个阈值。
也被称为effect size,两组样本均值的差异(Cohen’s d)
D_min计算方法如下:
正态分布算法:
- 假设有k天数据,则每份流量在对应指标上取k天的均值。
- 将n份流量对应指标两两相减,共得
 个差值,将差值样本记为
个差值,将差值样本记为 
- 差值总体分布 vs 0,做z检验。
- 在α=0.05下,求得拒绝阈值

中间部分参考链接:
https://towardsdatascience.com/what-i-learned-from-udacitys-course-on-a-b-testing-by-google-45f6d3297f42towardsdatascience.com
https://zhuanlan.zhihu.com/p/128435866

若有收获,就点个赞吧
0 人点赞
