我们思考一个问题:分词器「a tokenizer」是如何将代码字符串「a code string」转换为token标记列表的「a list of tokens」?
几周前,我花了一些时间从头开始重建Babel编译器,以进一步了解它的内部工作机制。所以你看,我对编译器了解的是做够多的,知道如何深度的使用它们(就像在我的debugger文章中介绍的那样),但我并不知道如何从头开始去实现一个。
在这篇文章中,我们将介绍如何构建分词器(tokenizer),这正是编译器的第一个组成部分。具体来说,我们将构建一个分词器,该分词器可以理解以下的代码片段,仅此而已:
function hello() {console.log('hello, world!')}
为此,我们将深入研究:
- 什么是token标识,以及为什么需要分词器(tokenizer)
- 如何通过三个具体步骤实现分词器:
- 标记单字符tokens
- 标记标识符和关键字,以及:
- 标记字符串字面量
往我们开始吧!
编译入门
让我们先整体来讨论一下编译器是如何工作的。我认为编译器是一个管道,有四个具体步骤:
每一步的输出会作为下一步的输入,并会将其转换为其他内容。第一步是做标记的操作,将源代码作为输入,而最后一步是代码生成操作,吐出修改后的代码。
让我们回到分词器(tokenizer)!
Token是语言词汇
问题: 什么是标记(Token),以及分词器究竟是做什么的?
本质上,分词器将源代码分解为称为标记(Token)的小对象(因此得名)。在编程语言中,我喜欢把一个标记看作一个“单词”,即使是最小的字符序列也是有意义的。
例如,如果将以下的JavaScript代码做分词:
function hello() {console.log('hello, world!')}
你将获得如下的标记模块: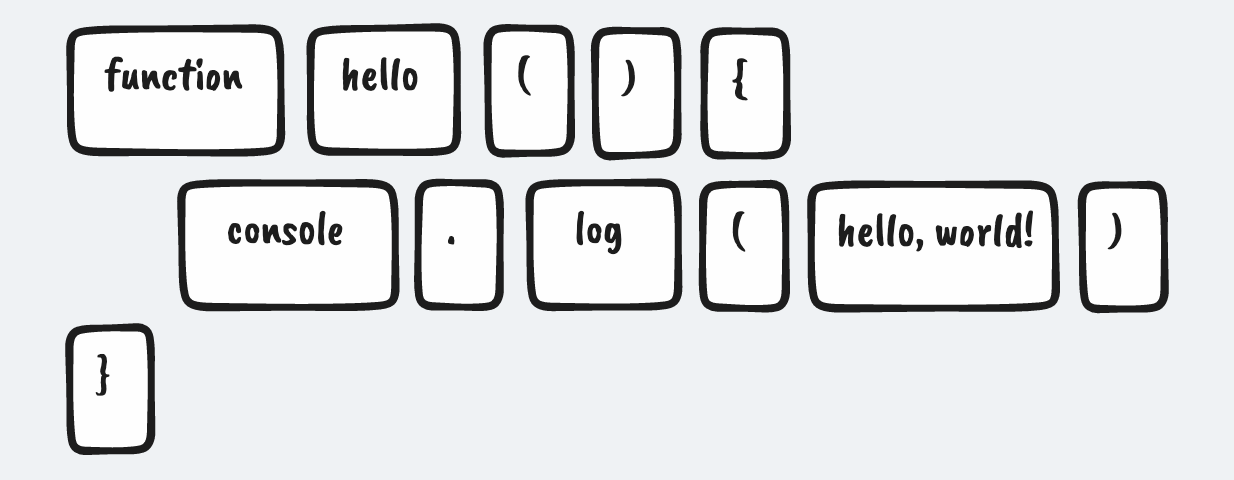
就像英语中的单词可以是名词、动词、形容词等一样,每个标记都有一个表示该标记含义的类型。在我们前面的示例中,这些类型可能类似于下图👇🏻: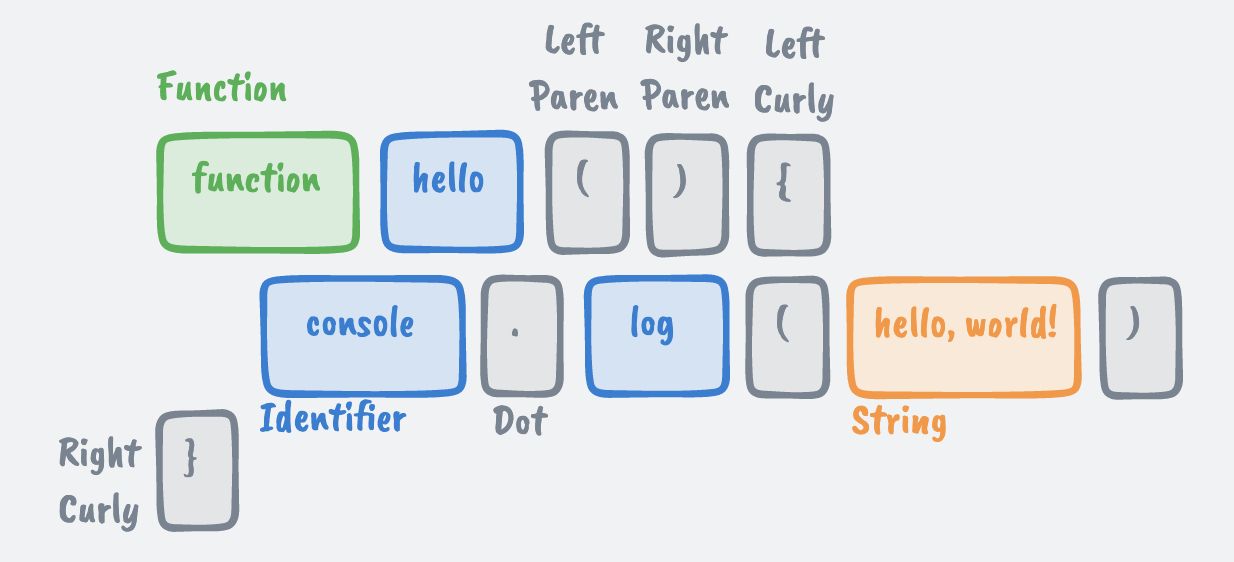
为什么要这样处理?
在我们继续之前,我想先岔开话题,谈谈为什么我们首先需要有分词器。在这里我们找不到一个能够讲的非常清楚的资源,但据我所知,有两个原因:
- 将数据组织成对机器更友好的格式;
- 将处理语言微语法的逻辑与处理常规语法的逻辑分开。
对机器友好的数据格式
当你以一种一致的方式对你在处理的数据进行结构化时,编写程序往往会容易得多。将字符串分组为标记(tokens)意味着编译器管道的其余部分不需要单独解析源代码——它们的优点是可以处理整洁的对象数组。
微语法与常规语法
- 常规语法:代码语句等
- 微语法:组成代码语句的变量、常量、字符串字面量、关键字等
另一个原因则是要将处理语言微语法的逻辑与处理常规语法的逻辑分开。当我在这里说“语法”时,我指的是控制编程语言“正确”结构的规则。
例如,在JavaScript中定义常量的正确方法是使用const关键字,如下所示:
const hello = 'world'
这是一个常规语法的例子,因为规则就是关于如何将不同单词排列在一起的正确方式,然后可以形成一行正确的代码。
另一方面,微语法(microsyntax)是一种将不同字符排列在一起组成一个单词的正确方法。一个例子是如何在JavaScript中定义字符串,即它们是被单引号或双引号包围的单词:
// valid strings'hello'"world"// invalid strings<-hello->&world&
区分处理这两种不同语法类型的代码是很重要的,因为它们涉及两种不同的东西。试图把它们混在一起的话只会导致更复杂的难以阅读和理解的代码。
简单总结
重申一下,标记器的工作是将源代码(作为字符串接收)分解为一个标记列表。这样分解代码可以让其他阶段的工作变得更加轻松:
- 将输入内容(源代码)整理成更结构化的格式,以及
- 通过将常规语法和微语法的逻辑分离,使代码变得更简单
开始实施
不管怎么样,我们回到分词器。
现在我们知道了什么是标记(tokens),以及为什么需要分词器,我们终于准备好开始实现它了!同样,我们希望重点关注以下代码片段的标记化,仅此而已:
function hello() {console.log('hello, world!')}
下面是我们正在实现的标记器的预览,通过代码片段进行介绍:
备注:作者在原文中实现了一个可视化的「挨个单词解析」的动作分解,这里近展现了最终的实现结果。实际效果可回到原文查看。
我们将实现分为3个部分:
- 解析单字符标记;
- 解析标识符和关键字;以及
- 解析字符串字面量。
让我们开始吧!
单字符标记「Single Character Tokens」
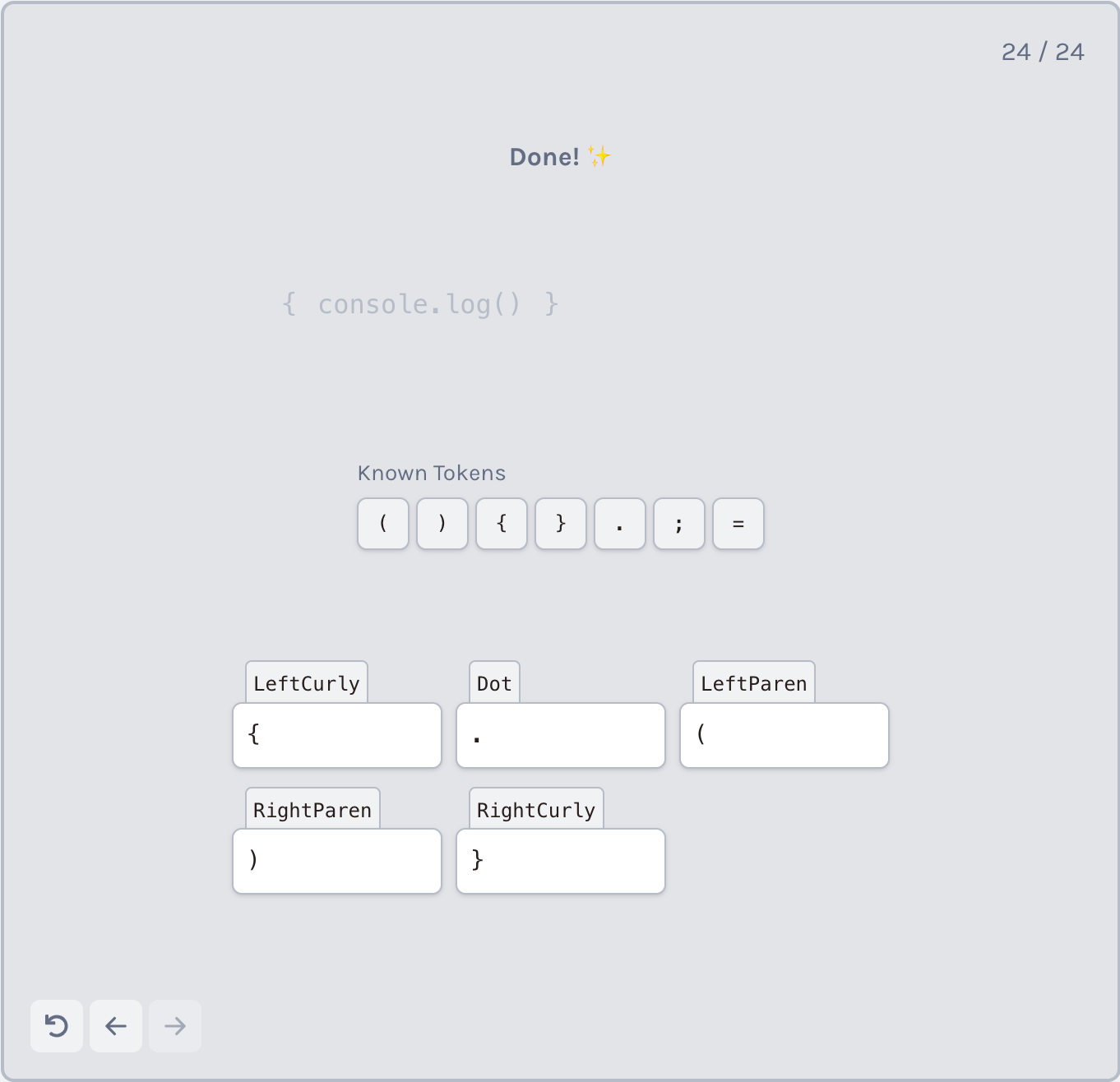
让我们首先尝试解析出最简单的标记——只有一个字符长度的标记(即单字符标记)。在我们正在分析的代码片段中,这将是以下的所有标记(包括:左右括号、点、左右大括号等):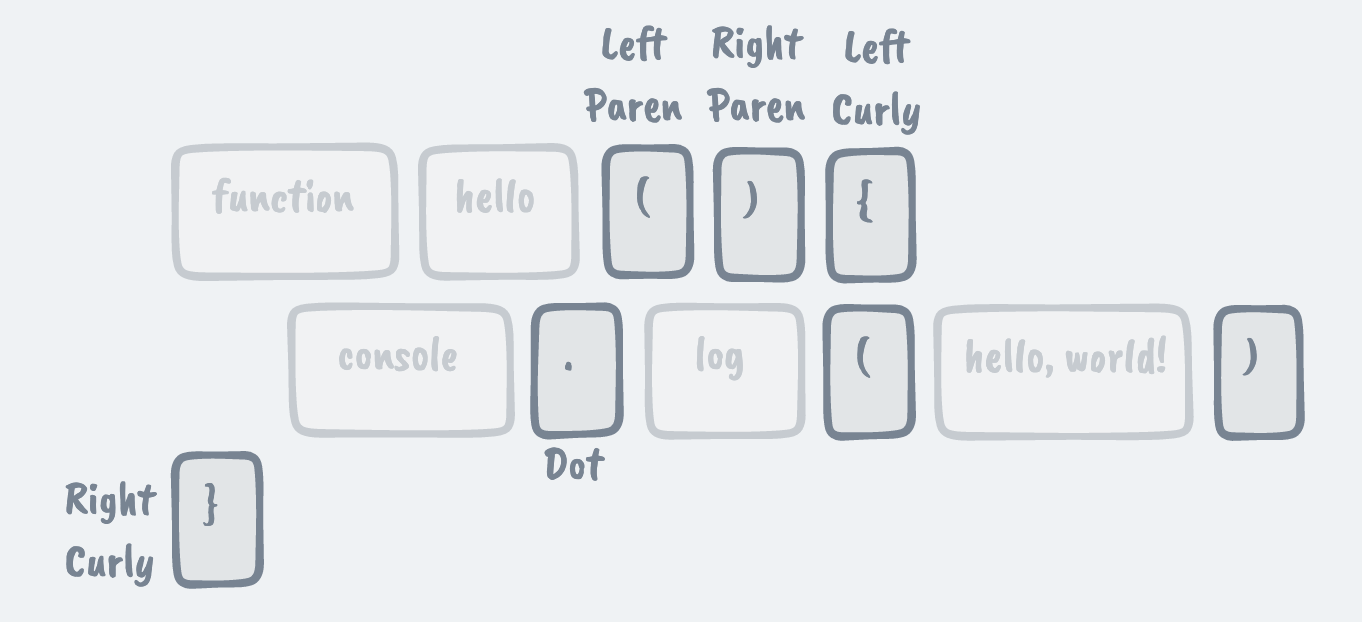
我们将从迭代输入的每个字符开始:
function hello() {\n console.log('hello, world!')\n}
什么是\n? \n字符是代表新的一行的特殊字符。当我们编辑代码或文本时,它通常是不可见的,但我选择在这里显式的展展示来,以表达计算机所看到的内容。
在遍历代码字符串时,我们检查当前字符是否是这些单字符标记中的一个。如果是,我们将该字符添加到最终的标记列表中。
检查一个字符是否为单字符标记的一种方法是:实现一个我们支持的所有单字符标记的列表,并检查该字符是否在该列表中:
备注:作者在原文中实现了一个可视化的「挨个单词解析」的动作分解,这里近展现了最终的实现结果。实际效果可回到原文查看。
标识符和关键字
有了单字符标记,接下来我们要做的就是解析标识符和关键字标记。但请稍等,标识符到底是什么?
什么是标识符?
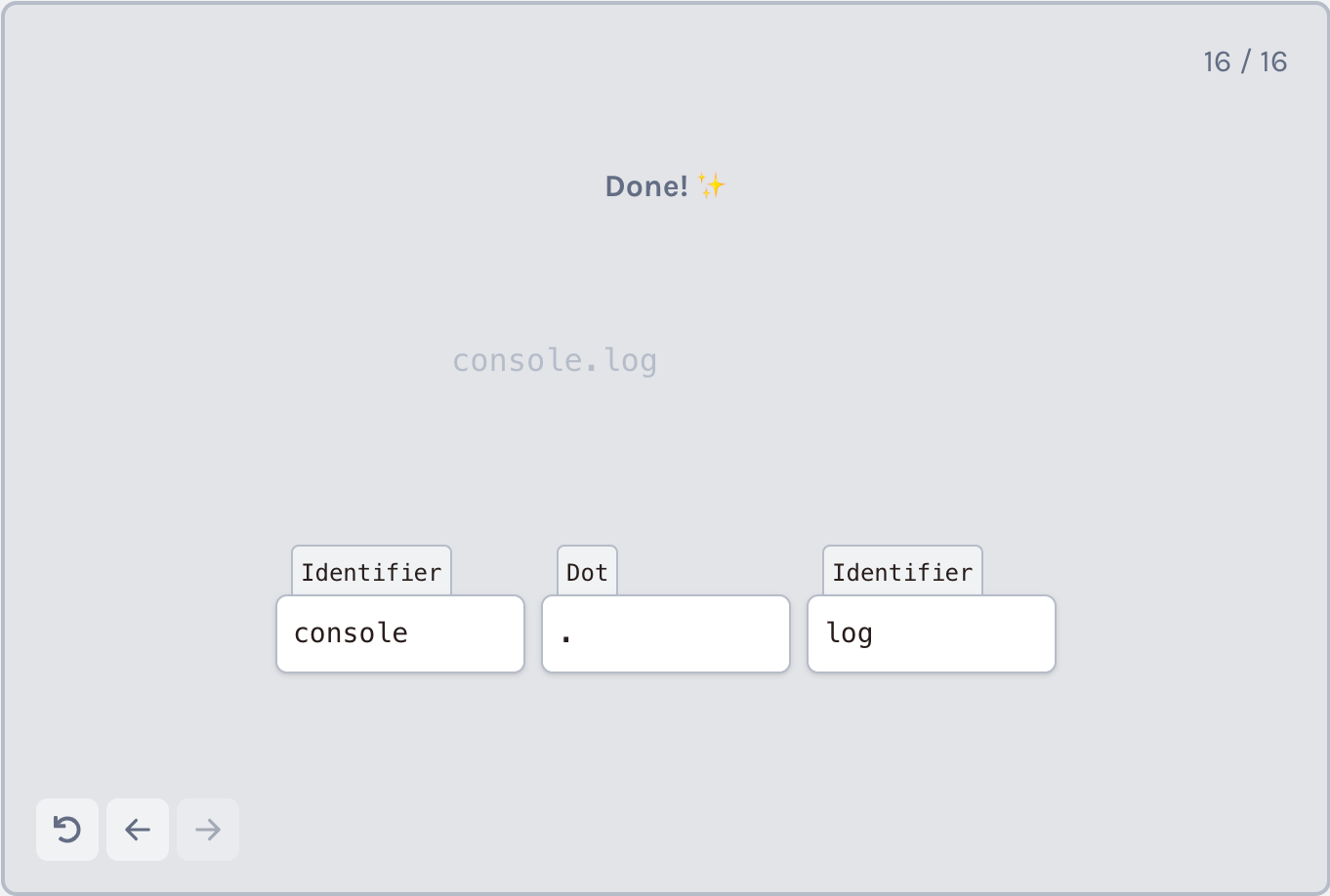
在JavaScript中,标识符是用于引用某个数据段(原文:some piece of data)的字符序列。例如,在我们的输入代码片段中,单词hello、console和log都是标识符,因为它们分别指函数定义、对象和方法(这段程序可用的所有数据)。
根据MDN上的解说,JavaScript中的有效标识符是字母数字组成的字符序列,但第一个字符不能是数字。这意味着以下字符串是有效标识符:
hello _abc abc123
但下面的是非法的:
2cool 8ball
我最初是希望能够完全支持MDN的标识符规则的,但(出于实现成本考虑)现在我选择将标识符限制为仅按字母顺序排列的字符,以便将其范围限定为输入代码片段。这意味着,在上面的所有示例中,我的标记器只会将单词hello识别为标识符。
实现
总而言之,标识符(出于我们的目的)是任何字母顺序的字符序列。为了分析它,我采用了以下方法:
- 如果当前字符按字母顺序排列,则开始解析标识符;
- 继续向当前标识符标记添加字符,直到当前字符不按字母顺序排列。
关键词
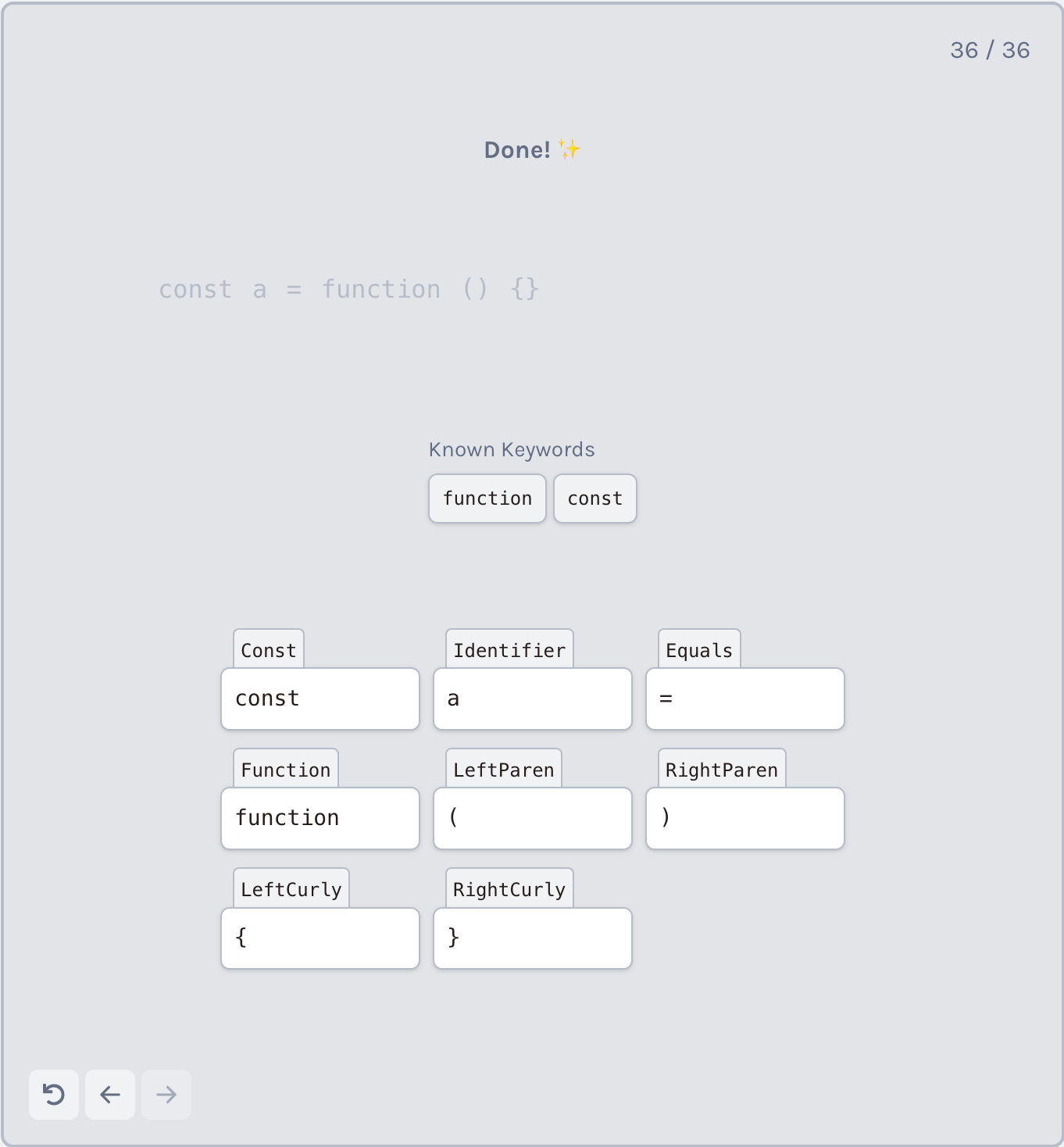
有些词,如function、while和switch,在JavaScript中有特殊含义,因此不能用作常规标识符。这组标识符称为关键字,通常有各自的标记类型。
因此,就有如下的问题:
分词器如何区分标识符和关键字呢?
一种方法是执行与单字符标记相同的操作:
- 维护一个已知的关键字的集合;
- 当我们解析完一个标识符时,检查解析的名称是否在这个集合中;
- 如果是,请将token的类型更改为关键字的类型。
字符串字面量
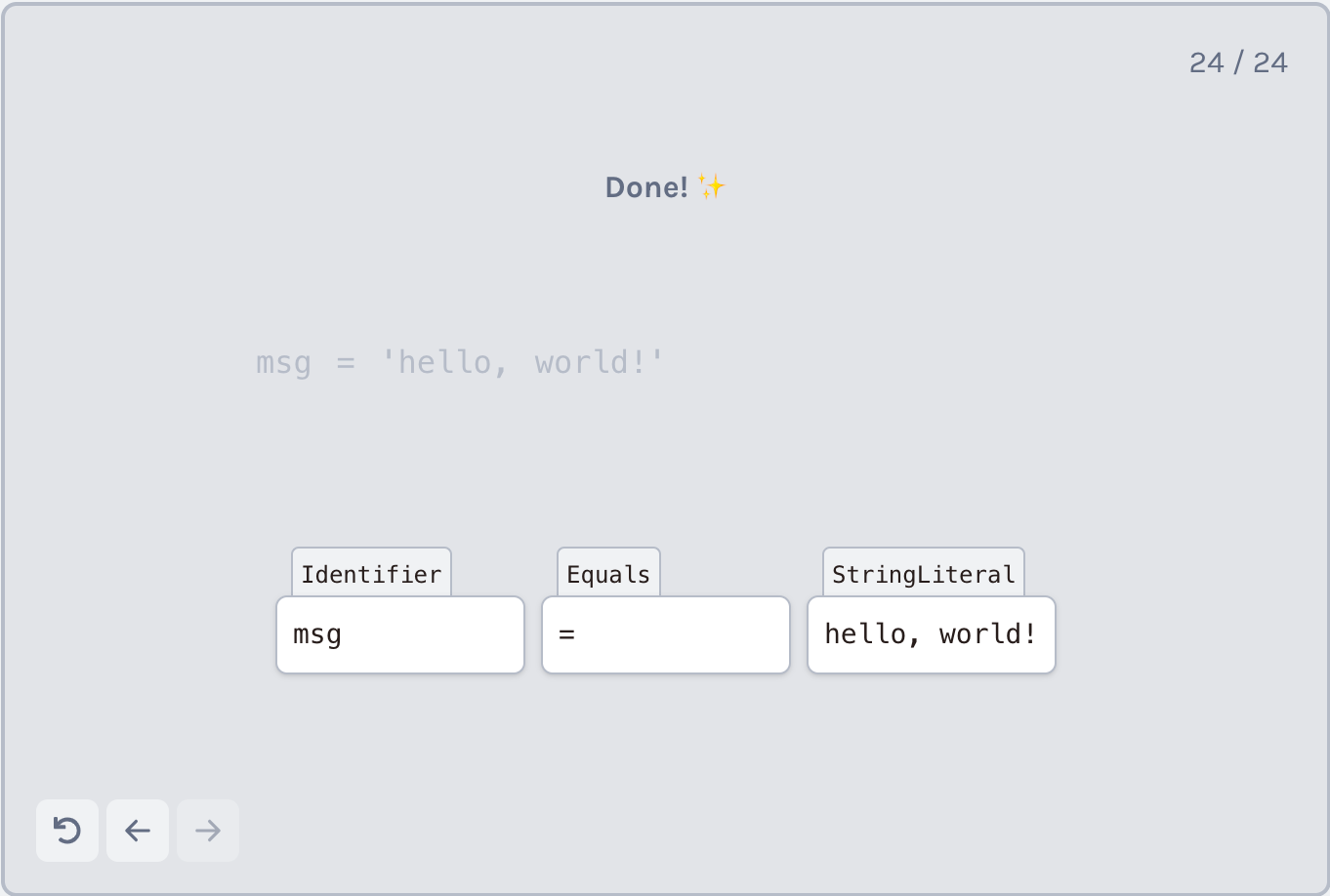
接下来是标记代码片段中的 ‘hello, world!’ 部分,也被称为字符串字面量。在JavaScript中,字符串字面量遵循以下规则:
- 以单引号(’)或双引号(“)对开始和结束,以及
- 不能跨越多行
为了简单起见,我选择了只支持单引号和多行字符串(事实证明,如果我们支持多行,实现会更简单)。
啊哈,这是microsyntax! 这就是我们早些时候关于微语法的小讨论!通过在这里处理字符串规则,编译器的其他部分不必担心这个字符串是否“正确”。
为了标记一个字符串字面量,我们将做一些类似于标记标识符的事情,除了我们只在到达另一个单引号时停止。具体操作如下:
- 如果当前字符是单引号,则开始分析字符串文字;
- 继续收集字符,直到当前字符中有一个是另一个撇号,表示字符串的结尾;或者
- 您已到达文件的结尾,但字符串未终止 - 这是一个错误的代码!
总结
这就是我们的分词!目前它做不了太多,但它能够标记我们开头使用的代码片段:
function hello(message) {console.log(message)}
我故意省略了代码实现,因为我想巩固分词器背后的概念,而不是将其绑定到任何直接实现。毕竟,实现同一件事有很多不同的方法!但是,如果您想阅读一些代码,请查看我对这个分词器的实现(用TypeScript编写)。
export function tokenize(input: string): Token[] {let current = 0;const tokens = [];function finishIdentifier() {let name = "";while (isAlpha(input[current])) {name += input[current];current++;}const builder = keywords.get(name);if (builder) {return builder();}return token.identifier(name);}function finishStringLiteral() {let value = "";while (input[current] && input[current] !== "'") {value += input[current];current++;}if (input[current] === "'") {// consume the closing tickcurrent++;return token.stringLiteral(value);}throw new Error(`Unterminated string, expected a closing '`);}while (current < input.length) {const currentChar = input[current];if (isWhitespace(currentChar)) {current++;continue;}if (isAlpha(currentChar)) {tokens.push(finishIdentifier());} else if (isSingleCharacter(currentChar)) {tokens.push(getCharToken(currentChar));current++;} else if (currentChar === "'") {// consume the first tickcurrent++;tokens.push(finishStringLiteral());} else {throw new Error(`Unknown character: ${currentChar}`);}}return tokens;}// --export enum TokenType {Function = "Function",Identifier = "Identifier",LeftParen = "LeftParen",RightParen = "RightParen",LeftCurly = "LeftCurly",RightCurly = "RightCurly",Dot = "Dot",Semicolon = "Semicolon",StringLiteral = "StringLiteral",}export type Token =| {type: TokenType;}| {type: TokenType.Identifier;name: string;}| {type: TokenType.StringLiteral;value: string;};export const token = {function() {return {type: TokenType.Function,};},identifier(name: string) {return {type: TokenType.Identifier,name,};},leftParen() {return { type: TokenType.LeftParen };},rightParen() {return { type: TokenType.RightParen };},leftCurly() {return { type: TokenType.LeftCurly };},rightCurly() {return { type: TokenType.RightCurly };},dot() {return { type: TokenType.Dot };},semicolon() {return { type: TokenType.Semicolon };},stringLiteral(value: string) {return {type: TokenType.StringLiteral,value,};},};const keywords = new Map([["function", token.function]]);// --function isAlpha(char: string) {return /[a-zA-Z]/.test(char);}function isWhitespace(char: string) {return /\s/.test(char);}type SingleCharacterToken = "(" | ")" | "{" | "}" | "." | ";";const knownSingleCharacters = new Map<SingleCharacterToken, () => Token>([["(", token.leftParen],[")", token.rightParen],["{", token.leftCurly],["}", token.rightCurly],[".", token.dot],[";", token.semicolon],]);function isSingleCharacter(char: string): char is SingleCharacterToken {return knownSingleCharacters.has(char as SingleCharacterToken);}function getCharToken(char: SingleCharacterToken) {const builder = knownSingleCharacters.get(char);return builder!();}
最后,如果您想了解更多信息,有几个练习供您尝试:
- 用你选择的语言实现这个标记器;使用文章中的可视化作为参考。
- 完成后,可以继续扩展分词器以支持你选择的JS语法——可能是async await之类的东西。
就到这里,感谢你的阅读!

若有收获,就点个赞吧
0 人点赞
